Queremos delinear em termos gerais as primeiras conquistas com o aprendizado profundo em animação de personagens para o nosso programa
Cascadeur .
Enquanto trabalhamos no
Shadow Fight 3 , acumulamos muitas animações de combate - cerca de 1100 movimentos com uma duração média de cerca de 4 segundos. Pareceu-nos há muito tempo que este poderia ser um bom conjunto de dados para o treinamento de algum tipo de rede neural.
Uma vez que percebemos que, quando os animadores fazem os primeiros esboços de idéias no papel, eles só precisam desenhar um homem literalmente para imaginar a pose do personagem. Pensamos que, como um animador experiente pode definir uma pose bem em um padrão simples, é bem possível que a rede neural possa lidar com isso. A partir dessa observação, nasceu uma idéia simples: vamos tirar apenas 6 pontos-chave de cada pose - pulsos, tornozelos, pelve e base do pescoço. Se a rede neural conhece apenas as posições desses pontos, ela pode prever o restante da pose - a posição dos 37 pontos restantes do personagem?
Como organizar o processo de aprendizagem, ficou claro desde o início: na entrada, a rede recebe as posições de 6 pontos de uma pose específica, na saída fornece as posições dos 37 pontos restantes, e as comparamos com as posições que estavam na posição inicial. Na função de avaliação, você pode usar o método dos mínimos quadrados para as distâncias entre as posições previstas dos pontos e a fonte.
Para o conjunto de dados de treinamento, tivemos todos os movimentos dos personagens de Shadow Fight 3. Tiramos poses de cada quadro e obtivemos cerca de 115.000 poses. Mas esse conjunto era específico - o personagem quase sempre olhava ao longo do eixo X, e a perna esquerda estava sempre à frente no início do movimento. Para resolver esse problema, expandimos artificialmente o conjunto de dados gerando poses de espelho e também girando aleatoriamente cada pose no espaço. Também nos permitiu aumentar o conjunto de dados para dois milhões de poses. Usamos 95% de nosso conjunto de dados para treinamento em rede e 5% para parametrização e teste.
Adotamos uma arquitetura de rede neural bastante simples - uma rede de cinco camadas totalmente conectada com uma função de ativação e um método de inicialização de
redes neurais auto-normalizantes . Na última camada, a ativação não é usada. Tendo 3 coordenadas para cada nó, obtemos uma camada de entrada de 6 * 3 elementos e uma camada de saída de 37 * 3 elementos. Pesquisamos a arquitetura ideal para camadas ocultas e estabelecemos uma arquitetura de cinco camadas com o número de neurônios de 300, 400, 300, 200 em cada camada oculta; no entanto, redes com menos camadas ocultas também produziram bons resultados.
A regularização L2 dos parâmetros da rede também foi muito útil, tornando as previsões mais suaves e mais contínuas.
Uma rede neural com esses parâmetros prevê a posição dos pontos com um erro médio de 3,5 cm, um erro muito alto, mas as especificidades do problema devem ser levadas em consideração. Para um conjunto de valores de entrada, pode haver muitos valores de saída possíveis. Portanto, a rede neural acabou aprendendo a emitir as previsões mais prováveis e médias. No entanto, quando o número de pontos de entrada aumentou para 16, o erro diminuiu pela metade, o que na prática produziu uma previsão muito precisa da pose.
Mas, ao mesmo tempo, a rede neural não conseguiu fazer uma pose completamente correta, preservando o comprimento de todos os ossos e as articulações corretas. Portanto, lançamos adicionalmente um processo de otimização que alinha todos os corpos sólidos e articulações do nosso modelo físico.
Na prática, os resultados foram bastante convincentes - você pode vê-los em nosso vídeo. Mas também há uma especificidade devido ao fato de o conjunto de dados de treinamento ser animações de combate de um jogo de luta com armas. Por exemplo, um personagem parece assumir que ele se vira com um ombro em direção ao inimigo, como em uma postura de luta, e consequentemente vira os pés e a cabeça. E quando você estica a mão dele, o pincel não gira como se tivesse sido atingido por um punho, mas como quando atingido por uma espada.
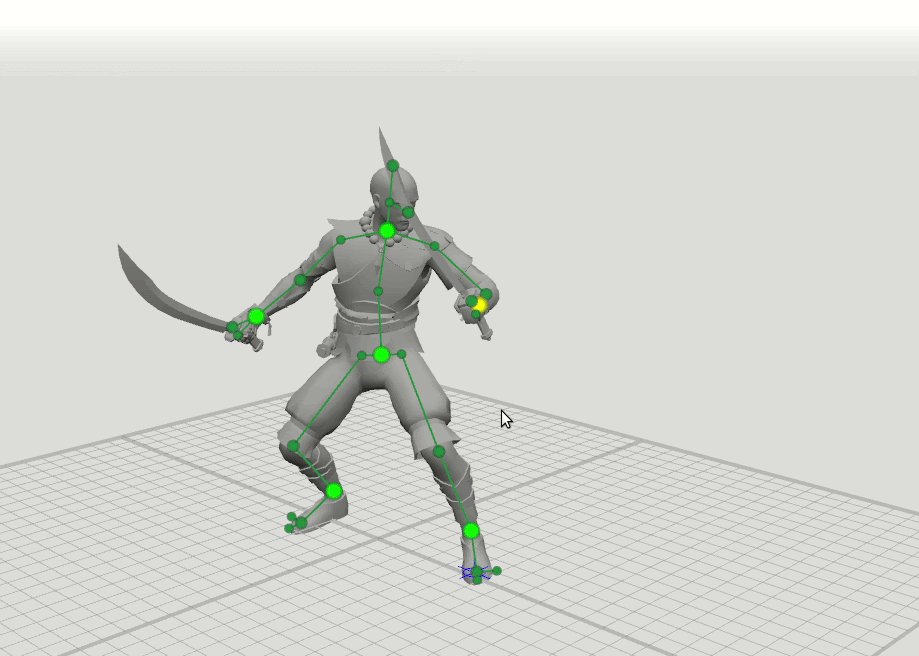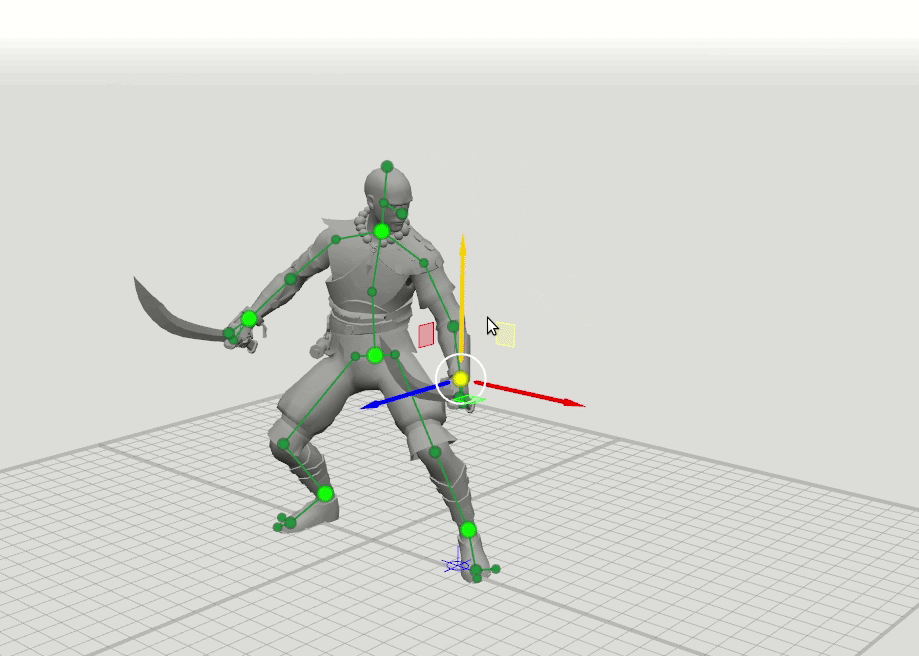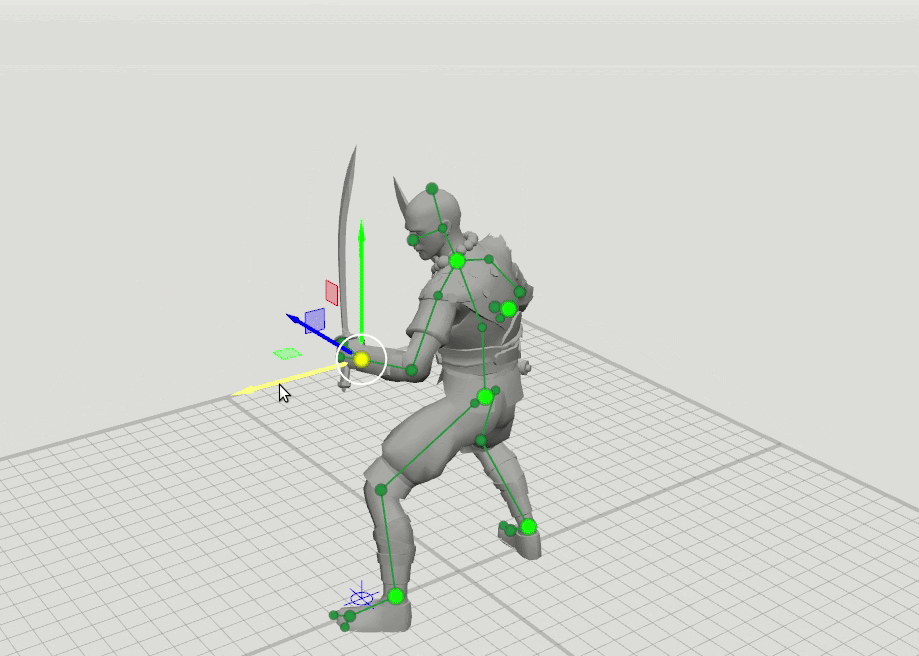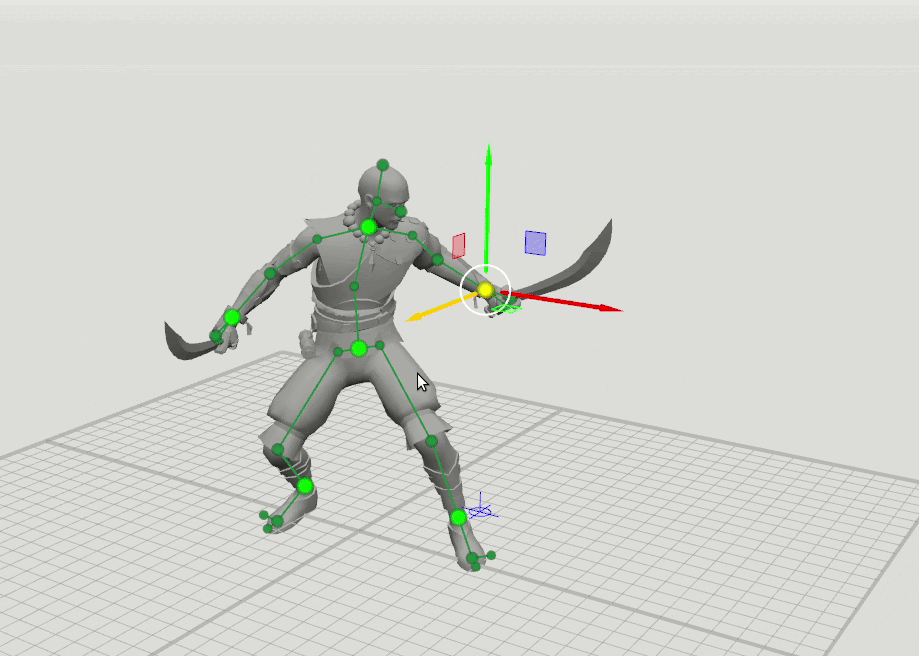
A idéia lógica do próximo passo surgiu a partir disso - treinar mais algumas redes com um conjunto expandido de pontos que especificam a orientação das mãos, pés e cabeça, bem como a posição dos joelhos e cotovelos. Adicionamos esquemas de 16 e 28 pontos. Descobriu-se que os resultados dessas redes podem ser combinados para que o usuário possa definir posições para um conjunto arbitrário de pontos. Por exemplo, o usuário decidiu mover o cotovelo esquerdo, mas não tocou o direito. Em seguida, a posição do cotovelo direito e do ombro direito é prevista em um padrão de 6 pontos, e a posição do ombro esquerdo em um padrão de 16 pontos.

Parece que isso acaba sendo uma ferramenta realmente interessante para trabalhar com a pose de um personagem. Seu potencial ainda não foi revelado até o fim, e temos idéias sobre como melhorá-lo e aplicá-lo não apenas para trabalhar com uma pose. A primeira versão desta ferramenta já está disponível na versão atual do Cascadeur. Você pode experimentá-lo se se inscrever para um teste beta fechado em nosso site
cascadeur.comTeremos o maior prazer em saber sua opinião e responder a perguntas.
A equipe dos Jogos Banzai exige um pesquisador de Deep Learning. Leia mais sobre a vaga aqui .