
Olá leitores da Habr. Com este artigo, estamos abrindo um ciclo que abordará o sistema hiperconvergente AERODISK vAIR que desenvolvemos. Inicialmente, queríamos que o primeiro artigo contasse tudo sobre tudo, mas o sistema é bastante complexo, portanto, comeremos um elefante em partes.
Vamos começar a história com a história do sistema, aprofundar o sistema de arquivos ARDFS, que é a base do vAIR, e também falar um pouco sobre o posicionamento dessa solução no mercado russo.
Em artigos futuros, falaremos mais sobre diferentes componentes arquiteturais (cluster, hypervisor, balanceador de carga, sistema de monitoramento etc.), o processo de configuração, levantaremos problemas de licenciamento, mostraremos separadamente os testes de falha e, é claro, escreveremos sobre testes de carga e dimensionamento. Também dedicaremos um artigo à versão comunitária do vAIR.
Um airdisc é uma história sobre armazenamento? Ou por que começamos a hiperconvergência?
Inicialmente, a idéia de criar nosso próprio hiperconvergente surgiu em algum momento do ano de 2010. Então não havia Aerodisk e soluções similares (sistemas hiperconvergentes em caixas comerciais) no mercado. Nossa tarefa foi a seguinte: de um conjunto de servidores com discos locais conectados por uma interconexão Ethernet, tivemos que fazer armazenamento estendido e executar máquinas virtuais e uma rede de software no mesmo local. Tudo isso era necessário para ser implementado sem sistemas de armazenamento (porque simplesmente não havia dinheiro para armazenamento e sua ligação, mas ainda não tínhamos inventado nosso próprio sistema de armazenamento).
Tentamos muitas soluções de código aberto e ainda resolvemos esse problema, mas a solução era muito complicada e difícil de repetir. Além disso, essa decisão foi da categoria “Trabalhos? Não toque! " Portanto, tendo resolvido esse problema, não desenvolvemos mais a idéia de transformar o resultado do nosso trabalho em um produto completo.
Após esse incidente, nos afastamos dessa idéia, mas ainda tínhamos a sensação de que esse problema era completamente solucionável, e os benefícios de tal solução eram mais do que óbvios. Posteriormente, os produtos HCI de empresas estrangeiras lançadas apenas confirmaram esse sentimento.
Portanto, em meados de 2016, retornamos a essa tarefa como parte da criação de um produto completo. Como ainda não tínhamos relações com investidores, tivemos que comprar um estande de desenvolvimento por nosso dinheiro não muito grande. Depois de digitar os servidores e comutadores Avito BU-shyh, começamos a trabalhar.

A principal tarefa inicial foi criar seu próprio sistema de arquivos, embora simples, mas com capacidade de distribuir dados de forma automática e uniforme na forma de blocos virtuais no enésimo número de nós do cluster interconectados via Ethernet. Nesse caso, o FS deve ser bem e facilmente dimensionado e independente dos sistemas adjacentes, ou seja, ser alienado do vAIR na forma de "apenas armazenamento".

Primeiro conceito VAIR

Recusamos intencionalmente o uso de soluções de código aberto prontas para organizar o armazenamento estendido (ceph, gluster, brilho e similares) em favor do nosso desenvolvimento, pois já tínhamos muita experiência com o projeto. Obviamente, essas soluções são maravilhosas e, antes de trabalharmos no Aerodisk, implementamos mais de um projeto de integração com eles. Mas uma coisa é realizar a tarefa específica de um cliente, treinar funcionários e, possivelmente, adquirir suporte para um grande fornecedor, e outra coisa é criar um produto facilmente replicável que será usado para várias tarefas, as quais nós, como fornecedor, podemos conhecer a nós mesmos nós não vamos. Para o segundo objetivo, os produtos de código aberto existentes não eram adequados para nós, por isso decidimos ver o sistema de arquivos distribuídos.
Dois anos depois, vários desenvolvedores (que combinaram o trabalho no vAIR com o trabalho no clássico Storage Engine) alcançaram um certo resultado.
Até o ano de 2018, escrevemos o sistema de arquivos mais simples e o complementamos com a ligação necessária. O sistema integrou discos físicos (locais) de diferentes servidores em um pool simples por meio de uma interconexão interna e os "corta" em blocos virtuais. Em seguida, os dispositivos de bloco com graus variados de tolerância a falhas foram criados a partir de blocos virtuais, nos quais os hipervisores KVM virtuais foram criados e executados carros.
Nós não nos incomodamos com o nome do sistema de arquivos e o chamamos sucintamente de ARDFS (adivinhe como ele descriptografa)
Esse protótipo parecia bom (não visualmente, é claro, não havia design visual na época) e mostrava bons resultados em desempenho e dimensionamento. Após o primeiro resultado real, definimos o rumo do projeto, tendo organizado um ambiente de desenvolvimento completo e uma equipe separada, envolvida apenas no vAIR.
Naquele momento, a arquitetura geral da solução havia amadurecido, que até agora não havia sofrido grandes mudanças.
Mergulhando no sistema de arquivos ARDFS
O ARDFS é a base do vAIR, que fornece armazenamento de failover distribuído de todo o cluster. Um (mas não o único) recurso distintivo do ARDFS é que ele não usa nenhum servidor dedicado adicional para meta e gerenciamento. Originalmente, isso pretendia simplificar a configuração da solução e sua confiabilidade.
Estrutura de armazenamento
Em todos os nós do cluster, o ARDFS organiza um pool lógico de todo o espaço em disco disponível. É importante entender que um pool ainda não é de dados e nem de espaço formatado, mas simplesmente de marcação, ou seja, todos os nós com vAIR instalados quando adicionados ao cluster são automaticamente adicionados ao pool ARDFS compartilhado e os recursos de disco são automaticamente compartilhados em todo o cluster (e disponíveis para armazenamento futuro de dados). Essa abordagem permite adicionar e remover nós em tempo real sem nenhum impacto sério em um sistema já em execução. I.e. o sistema é muito fácil de escalar com "tijolos", adicionando ou removendo nós no cluster, se necessário.
Os discos virtuais (objetos de armazenamento para máquinas virtuais) são adicionados à parte superior do pool ARDFS, construído a partir de blocos virtuais de 4 megabytes de tamanho. Discos virtuais armazenam dados diretamente. No nível do disco virtual, também é definido um esquema de tolerância a falhas.
Como você deve ter adivinhado, para a tolerância a falhas do subsistema de disco, não usamos o conceito de RAID (matriz redundante de discos independentes), mas usamos RAIN (matriz redundante de nós independentes). I.e. a tolerância a falhas é medida, automatizada e gerenciada com base em nós, não em discos. Os discos, é claro, também são um objeto de armazenamento; eles, como todo o resto, são monitorados, é possível executar todas as operações padrão com eles, incluindo a criação de RAID de hardware local, mas o cluster opera com nós.
Em uma situação em que você realmente deseja RAID (por exemplo, um cenário que oferece suporte a várias falhas em pequenos clusters), nada impede que você use controladores RAID locais e faça armazenamento estendido e uma arquitetura RAIN no topo. Esse cenário é bastante dinâmico e é suportado por nós; portanto, falaremos sobre isso em um artigo sobre cenários típicos para o uso do vAIR.
Esquemas de failover de armazenamento
Pode haver dois esquemas de resiliência de disco virtual vAIR:
1) Fator de replicação ou apenas replicação - esse método de tolerância a falhas é simples "como um pau e uma corda". A replicação síncrona entre nós com um fator de 2 (2 cópias por cluster) ou 3 (3 cópias, respectivamente) é executada. O RF-2 permite que um disco virtual resista a uma falha de um nó em um cluster, mas "consome" metade do volume utilizável, e o RF-3 suporta uma falha de 2 nós em um cluster, mas reservará 2/3 do volume utilizável para suas necessidades. Esse esquema é muito semelhante ao RAID-1, ou seja, um disco virtual configurado no RF-2 é resistente a falhas de qualquer nó do cluster. Nesse caso, os dados estarão corretos e até a E / S não será interrompida. Quando um nó em queda retorna à operação, a recuperação / sincronização automática de dados será iniciada.
A seguir, são apresentados exemplos da distribuição dos dados de RF-2 e RF-3 no modo normal e em uma situação de falha.
Temos uma máquina virtual com capacidade de 8 MB de dados exclusivos (úteis) que são executados em 4 nós vAIR. É claro que, na realidade, é improvável que exista uma quantidade tão pequena, mas para um esquema que reflete a lógica do ARDFS, este exemplo é mais compreensível. AB são blocos virtuais de 4 MB que contêm dados exclusivos da máquina virtual. Com o RF-2, duas cópias desses blocos A1 + A2 e B1 + B2 são criadas, respectivamente. Esses blocos são "dispostos" pelos nós, evitando a interseção dos mesmos dados no mesmo nó, ou seja, a cópia A1 não estará na mesma nota que a cópia A2. Com B1 e B2 é semelhante.
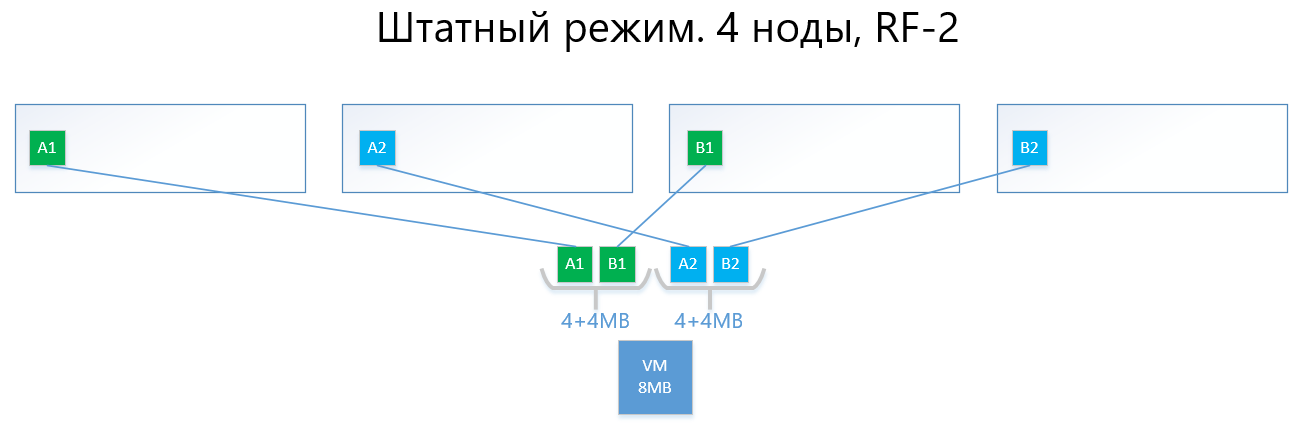
No caso de uma falha de um dos nós (por exemplo, nó 3, que contém uma cópia de B1), essa cópia é ativada automaticamente no nó em que não há cópia de sua cópia (ou seja, cópia B2).
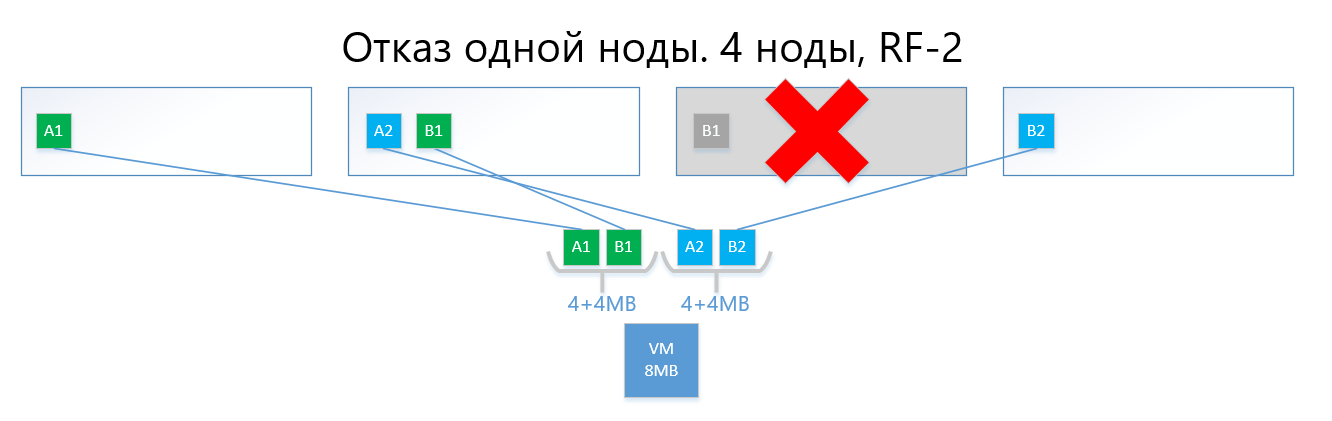
Assim, o disco virtual (e VMs, respectivamente) sobreviverá facilmente à falha de um nó no esquema RF-2.
Um circuito com replicação, com sua simplicidade e confiabilidade, sofre da mesma dor do RAID1 - há pouco espaço utilizável.
2) A codificação de apagamento ou exclusão (também conhecida como “codificação redundante”, “codificação apagada” ou “código de redundância”) existe apenas para resolver o problema acima. O EC é um esquema de redundância que fornece alta disponibilidade de dados com menos sobrecarga de disco em comparação com a replicação. O princípio de operação desse mecanismo é semelhante ao RAID 5, 6, 6P.
Ao codificar, o processo EC divide o bloco virtual (4 MB por padrão) em várias "partes de dados" menores, dependendo do esquema EC (por exemplo, um esquema 2 + 1 divide cada bloco de 4 MB em 2 partes de 2 MB). Além disso, esse processo gera "blocos de paridade" para "pedaços de dados" de não mais do que uma das partes separadas anteriormente. Ao decodificar, o EC gera as peças ausentes, lendo os dados "sobreviventes" em todo o cluster.
Por exemplo, um disco virtual com um esquema EC 2 + 1, implementado em 4 nós de um cluster, pode suportar facilmente uma falha de nó único em um cluster da mesma maneira que o RF-2. Ao mesmo tempo, os custos indiretos serão mais baixos, em particular, o fator de capacidade com RF-2 é 2 e, com EC 2 + 1, será 1,5.
Se for mais fácil descrever, o resultado final é que o bloco virtual é dividido em 2 a 8 (por que de 2 a 8 veja abaixo) "pedaços" e, para esses pedaços, os "pedaços" de paridade do mesmo volume são calculados.
Como resultado, os dados e a paridade são distribuídos igualmente em todos os nós do cluster. Ao mesmo tempo, como na replicação, o ARDFS distribui automaticamente os dados entre os nós de forma a impedir o armazenamento dos mesmos dados (cópias dos dados e sua paridade) em um nó, a fim de eliminar a chance de perda de dados devido ao fato de que os dados e seus dados de repente, a paridade acabará no mesmo nó de armazenamento, o que falhará.
Abaixo está um exemplo, com a mesma máquina virtual em 8 MB e 4 nós, mas já com o esquema EC 2 + 1.
Os blocos A e B são divididos em duas partes de 2 MB cada (duas porque 2 + 1), ou seja, A1 + A2 e B1 + B2. Diferentemente da réplica, A1 não é uma cópia de A2, é um bloco virtual A, dividido em duas partes, também com o bloco B. No total, obtemos dois conjuntos de 4 MB, cada um contendo duas peças de dois megabytes. Além disso, para cada um desses conjuntos, a paridade é calculada com um volume não superior a uma parte (ou seja, 2 MB), obtemos mais + 2 partes de paridade (AP e BP). Total, temos dados 4x2 + paridade 2x2.
Em seguida, as partes são "dispostas" pelos nós para que os dados não se sobreponham à sua paridade. I.e. A1 e A2 não estarão no mesmo nó do AP.

No caso de uma falha de um nó (por exemplo, também o terceiro), o bloco caído B1 será automaticamente restaurado da paridade BP, que é armazenada no nó nº 2, e será ativado no nó onde não há paridade B, ou seja, pedaços de BP. Neste exemplo, este é o nó # 1

Estou certo de que o leitor tem uma pergunta:
"Tudo o que você descreveu foi implementado há muito tempo pelos concorrentes e pelas soluções de código aberto. Qual é a diferença entre sua implementação do EC no ARDFS?"
E então haverá características interessantes do trabalho do ARDFS.
Codificação de apagamento com ênfase na flexibilidade
Inicialmente, fornecemos um esquema EC X + Y bastante flexível, em que X é igual a um número de 2 a 8 e Y é igual a um número de 1 a 8, mas sempre menor ou igual a X. Esse esquema é fornecido para flexibilidade. Aumentar o número de dados (X) nos quais a unidade virtual é dividida permite reduzir a sobrecarga, ou seja, aumentar o espaço utilizável.
Um aumento no número de blocos de paridade (Y) aumenta a confiabilidade do disco virtual. Quanto maior o valor Y, mais nós no cluster podem falhar. Obviamente, um aumento na paridade reduz a quantidade de capacidade utilizável, mas isso é uma cobrança pela confiabilidade.
A dependência do desempenho em circuitos CE é quase direta: quanto mais "peças", menor o desempenho, aqui, é claro, você precisa de uma aparência equilibrada.
Essa abordagem permite aos administradores a maneira mais flexível de configurar o armazenamento estendido. Dentro do pool ARDFS, você pode usar qualquer esquema de tolerância a falhas e suas combinações, o que também é, em nossa opinião, muito útil.
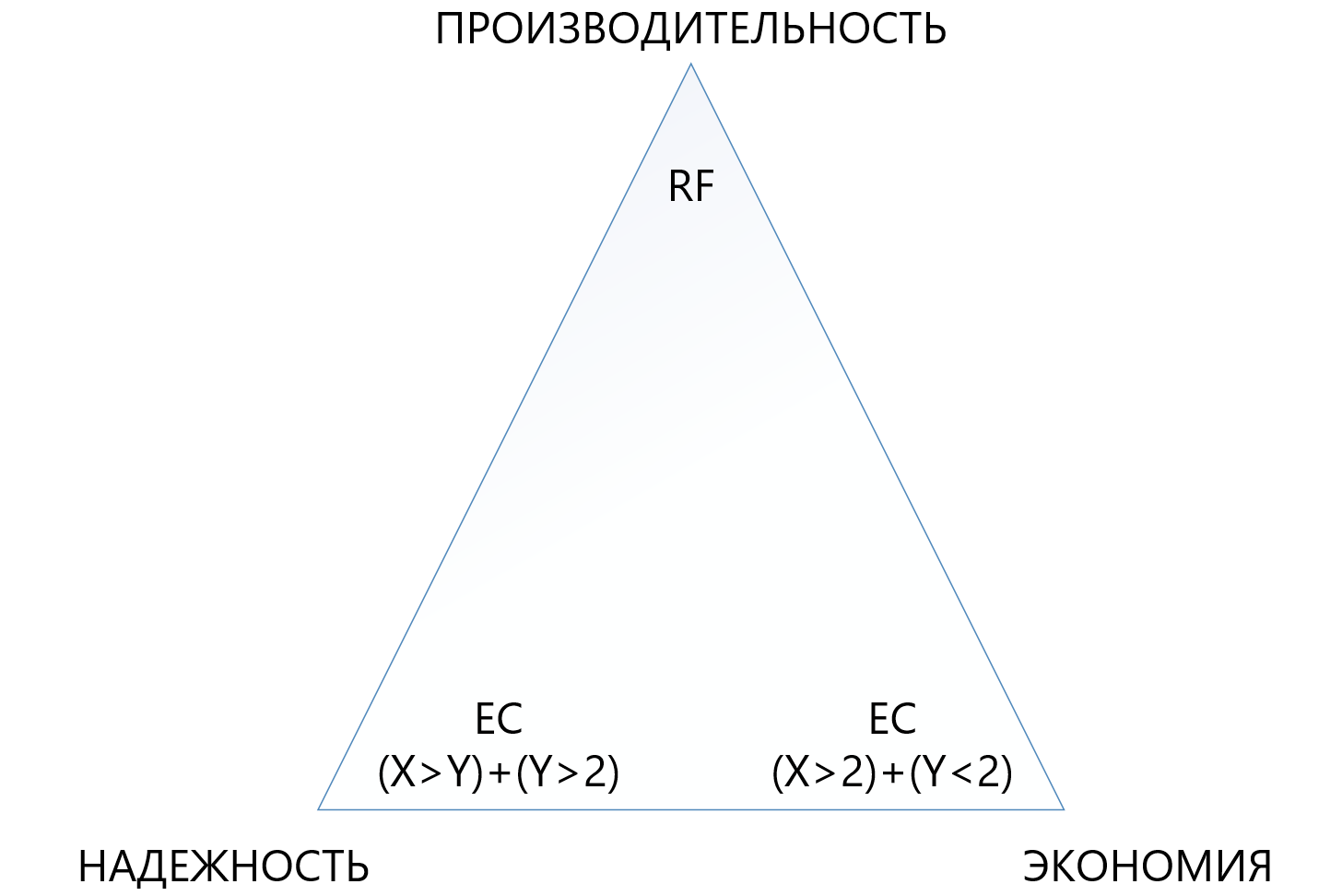
A tabela abaixo compara vários circuitos de RF e EC (nem todos possíveis).

A tabela mostra que mesmo a combinação mais "terry" do EC 8 + 7, que permite a perda de até 7 nós por vez em um cluster, "consome" menos espaço útil (1,875 versus 2) do que a replicação padrão e protege 7 vezes melhor, o que torna esse mecanismo de proteção, embora mais complexo, mas muito mais atraente em situações em que você precisa garantir a máxima confiabilidade nas condições de falta de espaço em disco. Ao mesmo tempo, você precisa entender que cada “mais” a X ou Y será uma sobrecarga adicional para a produtividade; portanto, você deve escolher com muito cuidado no triângulo entre confiabilidade, economia e desempenho. Por esse motivo, dedicaremos um artigo separado à codificação de exclusão de tamanho.
Confiabilidade e autonomia do sistema de arquivos
O ARDFS é executado localmente em todos os nós do cluster e os sincroniza por seus próprios meios através de interfaces Ethernet dedicadas. Um ponto importante é que o ARDFS sincroniza independentemente não apenas dados, mas também metadados relacionados ao armazenamento. Enquanto trabalhamos no ARDFS, estudamos simultaneamente várias soluções existentes e descobrimos que muitas realizam a meta-sincronização do sistema de arquivos usando um DBMS externo distribuído, que também usamos para sincronizar, mas apenas configurações, não os metadados do FS (sobre este e outros subsistemas relacionados no próximo artigo).
A sincronização dos metadados do FS usando um DBMS externo é, obviamente, uma solução funcional, mas a consistência dos dados armazenados no ARDFS dependeria do DBMS externo e de seu comportamento (e ela, francamente, é uma dama caprichosa), o que é ruim em nossa opinião. Porque Se os metadados do FS estiverem danificados, os dados do FS também poderão ser considerados "adeus", por isso decidimos seguir um caminho mais complicado, mas confiável.
Criamos o subsistema de sincronização de metadados para o ARDFS de forma independente e ele vive completamente independente dos subsistemas adjacentes. I.e. nenhum outro subsistema pode corromper os dados do ARDFS. Em nossa opinião, esta é a maneira mais confiável e correta, e é realmente assim - o tempo dirá. Além disso, com essa abordagem, uma vantagem adicional aparece. O ARDFS pode ser usado independentemente do vAIR, assim como o armazenamento estendido, que certamente usaremos em produtos futuros.
Como resultado, tendo desenvolvido o ARDFS, obtivemos um sistema de arquivos flexível e confiável que permite a você escolher onde você pode economizar capacidade ou doar tudo no desempenho ou tornar o armazenamento altamente confiável por uma taxa moderada, mas reduzindo os requisitos de desempenho.
Juntamente com uma política de licenciamento simples e um modelo de entrega flexível (olhando para o futuro, é licenciado pelo vAIR por nós e é entregue por software ou como um PAC), isso permite que você adapte com precisão a solução aos mais diferentes requisitos dos clientes e, no futuro, é fácil manter esse equilíbrio.
Quem precisa desse milagre?
Por um lado, podemos dizer que já existem players no mercado que tomam decisões sérias no campo da hiperconvergência e para onde estamos indo. Esta afirmação parece verdadeira, MAS ...
Por outro lado, saindo para o campo e se comunicando com os clientes, nós e nossos parceiros vemos que esse não é o caso. Existem muitos problemas para os hiperconvergentes, em algum lugar as pessoas simplesmente não sabiam que existiam tais soluções, em algum lugar parecia caro, em algum lugar havia testes sem êxito de soluções alternativas, mas em algum lugar eles geralmente proíbem a compra por causa de sanções. Em geral, o campo não era arado, então fomos aumentar as terras virgens))).
Quando o armazenamento é melhor que o GCS?
Durante o trabalho com o mercado, muitas vezes nos perguntam quando é melhor usar o esquema clássico com sistemas de armazenamento e quando é hiperconvergente? Muitas empresas - fabricantes de GCS (especialmente aquelas que não têm armazenamento em seu portfólio) afirmam: "O armazenamento é mais duradouro, apenas hiperconvergente!" Esta é uma afirmação ousada, mas não reflete bem a realidade.
Na verdade, o mercado de armazenamento, de fato, nada em busca de soluções hiperconvergentes e similares, mas sempre existe um "mas".
Em primeiro lugar, os datacenters e as infraestruturas de TI construídas de acordo com o esquema clássico com sistemas de armazenamento não podem ser facilmente reconstruídos dessa maneira; portanto, a modernização e a conclusão de tais infraestruturas ainda é um legado de 5 a 7 anos.
Em segundo lugar, essas infraestruturas que estão sendo construídas agora em grande parte (ou seja, a Federação Russa) estão sendo construídas de acordo com o esquema clássico usando sistemas de armazenamento e não porque as pessoas não conhecem hiperconvergente, mas porque o mercado hiperconvergente é novo, soluções e padrões ainda não foram estabelecidos , Os funcionários de TI ainda não foram treinados, há pouca experiência e precisamos construir data centers aqui e agora. E essa tendência é de mais 3-5 anos (e depois outro legado, veja o parágrafo 1).
Em terceiro lugar, uma limitação puramente técnica em pequenos atrasos adicionais de 2 milissegundos por gravação (excluindo o cache local, é claro), que são taxas pelo armazenamento distribuído.
Bem, não vamos esquecer o uso de grandes servidores físicos que adoram o dimensionamento vertical do subsistema de disco.
Existem muitas tarefas necessárias e populares em que o sistema de armazenamento se comporta melhor que o GCS. Aqui, é claro, os fabricantes que não possuem sistemas de armazenamento em seu portfólio de produtos discordarão de nós, mas estamos prontos para argumentar razoavelmente. Obviamente, nós, como desenvolvedores de ambos os produtos em uma das futuras publicações, faremos definitivamente uma comparação entre sistemas de armazenamento e GCS, onde demonstraremos claramente o que é melhor sob quais condições.
E onde as soluções hiperconvergentes funcionarão melhor que os sistemas de armazenamento?
Com base nas teses acima, existem três conclusões óbvias:
- Onde 2 milissegundos adicionais de atrasos na gravação que ocorrem de maneira estável em qualquer produto (agora não estamos falando de sintéticos, você pode mostrar nanossegundos em sintéticos) são não críticos, o que será um hiperconvergente.
- Onde a carga de grandes servidores físicos pode ser transformada em muitos pequenos servidores virtuais e distribuída por nós, o hiperconvergente também funcionará bem lá.
- Onde a escala horizontal é mais importante que a vertical, o GCS também funcionará bem lá.
Quais são essas soluções?
- Todos os serviços de infraestrutura padrão (serviço de diretório, correio, EDS, servidores de arquivos, pequenos ou médios sistemas ERP e BI, etc.). Chamamos isso de "computação geral".
- A infraestrutura dos provedores de nuvem, onde é necessário expandir rápida e padronizar horizontalmente e "dividir" facilmente um grande número de máquinas virtuais para os clientes.
- Infraestrutura de área de trabalho virtual (VDI), onde muitas pequenas máquinas virtuais de usuário são iniciadas e "flutuam" silenciosamente dentro de um cluster uniforme.
- , , , 15-20 .
- (big data-, ). , «», «».
- , , , .
AERODISK vAIR ( ). , , .. .
…
, .
, .