Parece que o campo da publicidade on-line deve ser o mais tecnológico e automatizado possível. De fato, gigantes e especialistas em suas áreas de atuação, como Yandex, Mail.Ru, Google e Facebook, trabalham lá. Mas, como se viu, não há limite para a perfeição e sempre há algo para automatizar.
 Fonte
FonteO grupo de comunicação
Dentsu Aegis Network Russia é o maior player no mercado de publicidade digital e investe ativamente em tecnologia, tentando otimizar e automatizar seus processos de negócios. Um dos problemas não resolvidos do mercado de publicidade on-line era a tarefa de coletar estatísticas sobre campanhas publicitárias de diferentes sites on-line. A solução para esse problema acabou resultando na criação do produto
D1.Digital (lido como DiVan), sobre o qual queremos falar sobre o desenvolvimento.
Porque
1. No momento do início do projeto, não havia um único produto acabado no mercado que resolvesse a tarefa de automatizar a coleta de estatísticas em campanhas publicitárias.
Isso significa que ninguém além de nós mesmos fechará nossas necessidades.Serviços como Improvado, Roistat, Supermetrics, SegmentStream, oferecem integração com sites, redes sociais e Google Analitycs, além de oferecer a capacidade de criar painéis analíticos para uma análise e controle convenientes das campanhas publicitárias. Antes de começar a desenvolver nosso produto, tentamos usar alguns desses sistemas em nosso trabalho para coletar dados de sites, mas, infelizmente, eles não conseguiram resolver nossos problemas.
O principal problema era que os produtos testados eram repelidos a partir de fontes de dados, exibindo as estatísticas de veiculações em seções por sites e não permitiam a agregação de estatísticas em campanhas publicitárias. Essa abordagem não permitiu ver estatísticas de sites diferentes em um só lugar e analisar o estado da campanha como um todo.
Outro fator foi que, nos estágios iniciais, os produtos eram orientados para o mercado ocidental e não suportavam a integração com sites russos. E para os sites com os quais a integração foi implementada, nem sempre foram carregadas todas as métricas necessárias com detalhes suficientes, e a integração nem sempre foi conveniente e transparente, especialmente quando era necessário obter algo que não estava na interface do sistema.
Em geral, decidimos não nos adaptar a produtos de terceiros, mas começamos a desenvolver nossos próprios ...
2. O mercado de publicidade on-line está crescendo de ano para ano e, em 2018, tradicionalmente superava o maior mercado de publicidade de TV em termos de orçamento de publicidade.
Portanto, há uma escala .
3. Diferentemente do mercado de publicidade na TV, onde a venda da publicidade comercial é monopolizada, a massa de proprietários individuais de equipamentos de publicidade de vários tamanhos com seus escritórios de publicidade trabalha na Internet. Como a campanha publicitária, em regra, é executada em vários sites ao mesmo tempo, para entender o estado da campanha publicitária, é necessário coletar relatórios de todos os sites e reuni-los em um grande relatório que mostrará toda a imagem.
Portanto, há potencial para otimização.4. Pareceu-nos que os proprietários de inventário de publicidade na Internet já tinham uma infraestrutura para coletar estatísticas e exibi-las em escritórios de publicidade, e eles poderiam fornecer uma API para esses dados.
Portanto, existe uma viabilidade técnica. Diremos imediatamente que não foi tão simples.
Em geral, todos os pré-requisitos para a implementação do projeto eram óbvios para nós, e corremos para implementá-lo ...
Grande plano
Primeiro, formamos a visão de um sistema ideal:
- Ele deve carregar automaticamente campanhas publicitárias do sistema corporativo 1C com seus nomes, períodos, orçamentos e canais em várias plataformas.
- Para cada canal dentro da campanha publicitária, todas as estatísticas possíveis dos sites em que o canal está em andamento devem ser baixadas automaticamente, como o número de impressões, cliques, visualizações etc.
- Algumas campanhas publicitárias são monitoradas pelo monitoramento de terceiros pelos chamados sistemas de serviço de anúncios, como Adriver, Weborama, DCM, etc. Há também um medidor de Internet industrial na Rússia - Mediascope. De acordo com nossa ideia, os dados do monitoramento independente e industrial também devem ser automaticamente carregados nas campanhas publicitárias correspondentes.
- A maioria das campanhas de publicidade na Internet é direcionada a determinadas ações direcionadas (compra, ligação, gravação para um test drive, etc.), que são rastreadas usando o Google Analytics e estatísticas nas quais também são importantes para entender o status da campanha e devem ser carregadas em nossa ferramenta .
A primeira panqueca é irregular
Considerando nosso compromisso com princípios flexíveis de desenvolvimento de software (ágil, tudo), decidimos primeiro desenvolver o MVP e depois avançar iterativamente para o objetivo pretendido.
Decidimos construir o MVP com base no nosso produto
DANBo (Dentsu Aegis Network Board) , que é um aplicativo da web com informações gerais sobre as campanhas publicitárias de nossos clientes.
Para o MVP, o projeto foi simplificado ao máximo em termos de implementação. Selecionamos uma lista limitada de sites para integração. Essas foram as principais plataformas, como Yandex.Direct, Yandex.Display, RB.Mail, MyTarget, Adwords, DBM, VK, FB e os principais sistemas de serviço de anúncios Adriver e Weborama.
Para acessar as estatísticas dos sites por meio da API, usamos uma única conta. O gerente do grupo de clientes, que desejava usar a coleção automática de estatísticas na campanha publicitária, primeiro delegou o acesso às campanhas publicitárias necessárias nos sites na conta da plataforma.
Em seguida, o usuário do sistema
DANBo teve que enviar um arquivo de um determinado formato para o sistema Excel, no qual todas as informações sobre a veiculação (campanha publicitária, site, formato, período de veiculação, indicadores planejados, orçamento etc.) e os identificadores das campanhas publicitárias correspondentes nas plataformas e contadores em sistemas de serviço de anúncios.
Parecia francamente aterrorizante:

Os dados baixados foram armazenados no banco de dados e, em seguida, serviços individuais coletaram identificadores de campanha deles nos sites e baixaram estatísticas sobre eles.
Um serviço do Windows separado foi gravado para cada site, que uma vez por dia passava por uma conta de serviço na API do site e fazia o download de estatísticas nos identificadores de campanha especificados. O mesmo aconteceu com os sistemas de serviço de anúncios.
Os dados baixados foram exibidos na interface na forma de um pequeno painel auto-escrito:
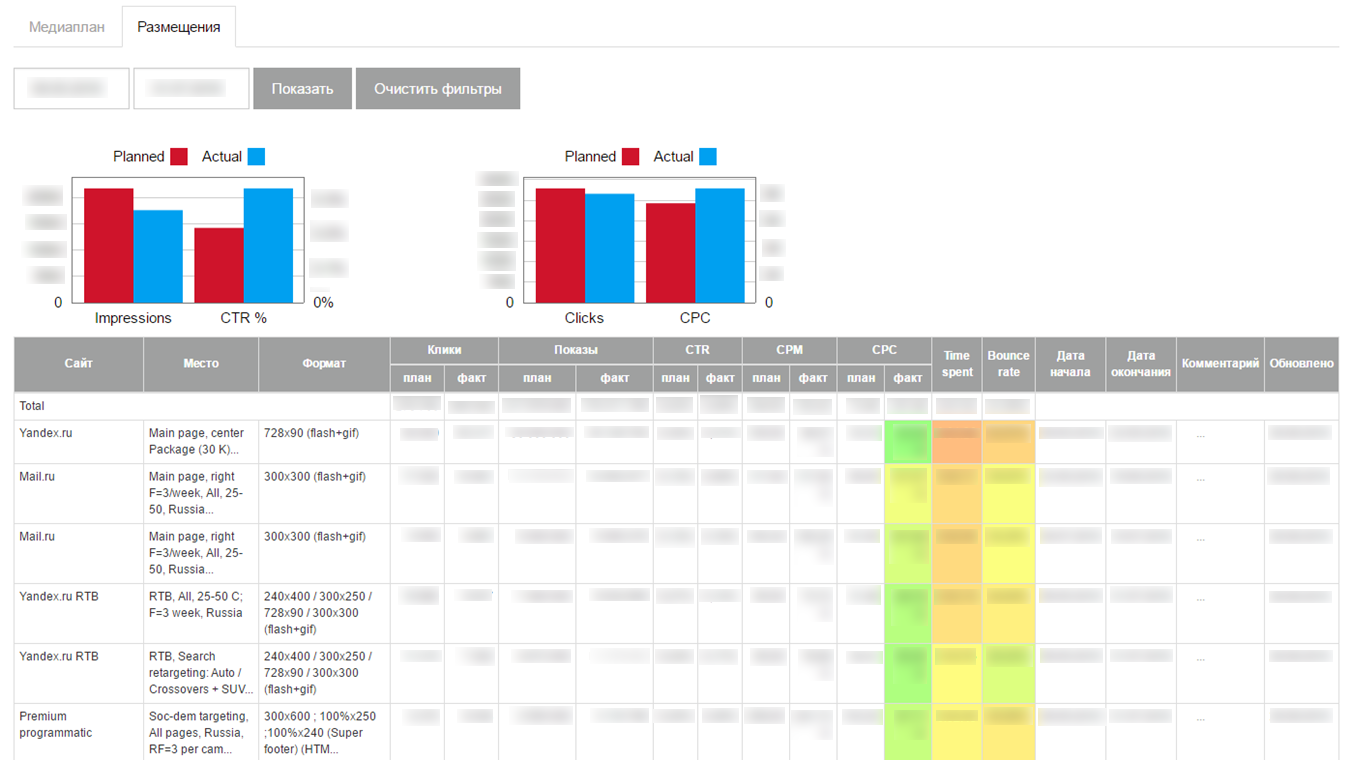
Inesperadamente, para nós, o MVP ganhou e começou a baixar as estatísticas atuais de campanhas publicitárias na Internet. Implementamos o sistema em vários clientes, mas quando tentamos escalar, tivemos sérios problemas:
- O principal problema foi a laboriosa preparação de dados para carregamento no sistema. Além disso, os dados do canal precisavam ser reduzidos para um formato estritamente fixo antes do download. No arquivo para carregamento, era necessário registrar os identificadores de entidades de diferentes sites. Estamos diante do fato de que é muito difícil para usuários tecnicamente não treinados explicar onde encontrar esses identificadores no site e onde colocá-los no arquivo. Considerando o número de funcionários nas divisões que realizam campanhas nos sites e a rotatividade, isso resultou em uma enorme quantidade de apoio do nosso lado, o que categoricamente não nos convinha.
- Outro problema era que nem todas as plataformas de publicidade tinham mecanismos para delegar o acesso a campanhas de publicidade em outras contas. Mas, mesmo que o mecanismo de delegação estivesse disponível, nem todos os anunciantes estavam dispostos a fornecer acesso à conta de terceiros para suas campanhas.
- Um fator importante foi a indignação que causou aos usuários que todos os indicadores planejados e detalhes de posicionamento que eles já contribuem para o nosso sistema contábil 1C deveriam ser reinseridos no DANBo .
Isso nos deu a ideia de que a principal fonte de informações sobre a localização deveria ser o nosso sistema 1C, no qual todos os dados são inseridos com precisão e no prazo (o ponto é que, com base nos dados 1C, as contas são formadas, portanto, a entrada correta dos dados em 1C é para todos KPI). Então um novo conceito de sistema apareceu ...
Conceito
A primeira coisa que decidimos fazer foi separar o sistema de coleta de estatísticas de campanhas publicitárias na Internet em um produto separado -
D1.Digital .
No novo conceito, decidimos carregar informações sobre campanhas e canais de publicidade dentro deles de 1C para
D1.Digital e, em
seguida ,
extraímos estatísticas dos sites e dos sistemas AdServing para esses canais. Isso deveria simplificar bastante a vida dos usuários (e, como de costume, adicionar trabalho aos desenvolvedores) e reduzir a quantidade de suporte.
O primeiro problema que encontramos foi de natureza organizacional e estava relacionado ao fato de não conseguirmos encontrar uma chave ou atributo pelo qual pudéssemos comparar entidades de diferentes sistemas com campanhas e veiculações da 1C. O fato é que o processo em nossa empresa é organizado de tal maneira que as campanhas publicitárias são inseridas em diferentes sistemas por pessoas diferentes (players de mídia, compras, etc.).
Para resolver esse problema, tivemos que inventar uma chave de hash exclusiva, DANBoID, que conectaria entidades em diferentes sistemas e que poderia ser identificada de maneira fácil e inequívoca nos conjuntos de dados carregados. Esse identificador é gerado no sistema interno 1C para cada canal individual e se lança em campanhas, canais e contadores em todas as plataformas e em todos os sistemas AdServing. A implementação da prática de afixar o DANBoID em todos os canais levou algum tempo, mas nós o fizemos :)
Em seguida, descobrimos que nem todos os sites têm uma API para coleta automática de estatísticas, e mesmo aqueles que possuem uma API não retornam todos os dados necessários.
Nesse estágio, decidimos reduzir significativamente a lista de sites para integração e focar nos principais sites envolvidos na grande maioria das campanhas publicitárias. Esta lista inclui todos os maiores players do mercado de publicidade (Google, Yandex, Mail.ru), redes sociais (VK, Facebook, Twitter), os principais sistemas de análise e serviço de anúncios (DCM, Adriver, Weborama, Google Analytics) e outras plataformas.
A maior parte dos sites que selecionamos tinha uma API que nos fornecia as métricas necessárias. Nesses casos, quando a API não estava lá, ou não possuía os dados necessários, para usar os dados que usamos relatórios que chegavam diariamente no correio comercial (em alguns sistemas é possível configurar esses relatórios, em outros, concordamos em desenvolver esses relatórios para nós).
Ao analisar dados de sites diferentes, descobrimos que a hierarquia de entidades não é a mesma em sistemas diferentes. Além disso, informações de diferentes sistemas devem ser carregadas em diferentes detalhes.
Para resolver esse problema, o conceito SubDANBoID foi desenvolvido. A ideia de SubDANBoID é bastante simples, marcamos a essência principal da campanha no site com o DANBoID gerado e carregamos todas as entidades aninhadas com identificadores exclusivos do site e formamos o SubDANBoID de acordo com o princípio DANBoID + identificador da entidade aninhada do primeiro nível + identificador da entidade aninhada do segundo nível + ... Essa abordagem nos permitiu associar ... campanhas publicitárias em diferentes sistemas e fazer upload de estatísticas detalhadas sobre elas.
Também tivemos que resolver o problema do acesso a campanhas em sites diferentes. Como escrevemos acima, o mecanismo de delegar o acesso à campanha em uma conta técnica separada nem sempre é aplicável. Portanto, tivemos que desenvolver uma infraestrutura para autorização automática por meio do OAuth usando tokens e atualizar mecanismos para esses tokens.
Ainda neste artigo, tentaremos descrever com mais detalhes a arquitetura da solução e os detalhes técnicos da implementação.
Arquitetura de Solução 1.0
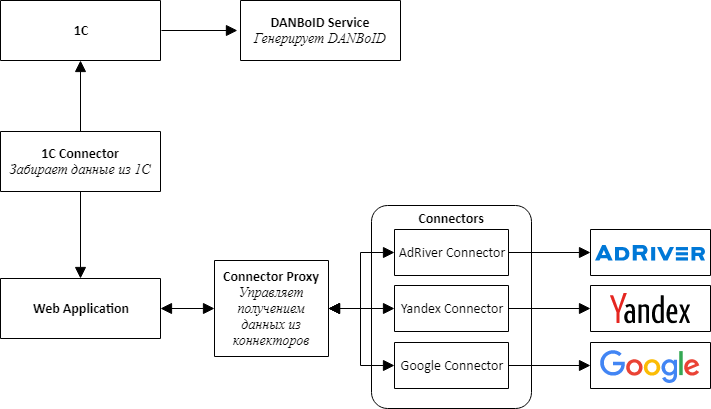
Iniciando a implementação de um novo produto, entendemos que era imediatamente necessário prever a possibilidade de conectar novos sites, por isso decidimos seguir o caminho da arquitetura de microsserviço.
Ao projetar a arquitetura, destacamos em conectores de serviços separados para todos os sistemas externos - 1C, plataformas de publicidade e sistemas de serviço de anúncios.
A idéia principal é que todos os conectores dos sites tenham a mesma API e sejam adaptadores que tragam as APIs do site para a nossa interface conveniente.
No centro de nosso produto, há um aplicativo da web, que é um monólito, projetado para que possa ser facilmente desmontado em serviços. Este aplicativo é responsável pelo processamento dos dados baixados, comparando estatísticas de diferentes sistemas e apresentando-os aos usuários do sistema.
Para comunicar conectores com um aplicativo da Web, tivemos que criar um serviço adicional, que chamamos de Connector Proxy. Ele executa as funções do Service Discovery e do Task Scheduler. Este serviço executa tarefas de coleta de dados para cada conector todas as noites. Escrever uma camada de serviço era mais fácil do que conectar um intermediário de mensagens e, para nós, era importante obter o resultado o mais rápido possível.
Para simplificar e acelerar o desenvolvimento, também decidimos que todos os serviços seriam uma API da Web. Isso tornou possível montar rapidamente uma prova de conceito e verificar se todo o projeto estava funcionando.
Uma tarefa separada, bastante difícil, era configurar o acesso para coletar dados de gabinetes diferentes, que, como decidimos, deveriam ser executados pelos usuários por meio de uma interface da web. Consiste em duas etapas separadas: primeiro, o usuário através do OAuth adiciona um token para acessar a conta e, em seguida, configura a coleta de dados para o cliente a partir de uma conta específica. É necessário obter um token através do OAuth, porque, como já escrevemos, nem sempre é possível delegar o acesso ao gabinete desejado no site.
Para criar um mecanismo universal para escolher um gabinete de sites, tivemos que adicionar um método à API de conectores que processa o JSON Schema, que é renderizado no formulário usando um componente JSONEditor modificado. Assim, os usuários puderam escolher as contas para baixar os dados.
Para cumprir os limites de solicitação existentes nos sites, combinamos a solicitação de configurações no mesmo token, mas podemos processar tokens diferentes em paralelo.
Escolhemos o MongoDB como repositório de dados para download, tanto para aplicativos da Web quanto para conectores, o que nos permitiu não nos preocupar muito com a estrutura de dados nos estágios iniciais de desenvolvimento, quando o modelo de aplicativo muda após um dia.
Logo descobrimos que nem todos os dados se encaixam bem no MongoDB e, por exemplo, as estatísticas diárias são mais convenientes para armazenar em um banco de dados relacional. Portanto, para conectores cuja estrutura de dados é mais adequada para um banco de dados relacional, começamos a usar o PostgreSQL ou o MS SQL Server como armazenamento.
A arquitetura e a tecnologia selecionadas nos permitiram construir e lançar relativamente rapidamente o produto D1.Digital. Ao longo dos dois anos de desenvolvimento de produtos, desenvolvemos 23 conectores de sites, adquirimos uma experiência inestimável trabalhando com APIs de terceiros, aprendemos a ignorar as armadilhas de sites diferentes, cada um com o seu, contribuíram para o desenvolvimento da API em pelo menos três sites, baixaram automaticamente informações sobre quase 15.000 campanhas e em mais de 80.000 veiculações, coletamos muitos comentários dos usuários sobre o produto e conseguimos alterar o processo principal do produto várias vezes, com base nesse feedback.
Arquitetura de Solução 2.0
Dois anos se passaram desde o início do desenvolvimento do
D1.Digital . O aumento constante da carga no sistema e o surgimento de novas fontes de dados gradualmente revelaram problemas na arquitetura da solução existente.
O primeiro problema está relacionado à quantidade de dados baixados dos sites. Fomos confrontados com o fato de que a coleta e a atualização de todos os dados necessários dos maiores sites começaram a levar muito tempo. Por exemplo, a coleta de dados no sistema de veiculação de anúncios do AdRiver, com o qual rastreamos estatísticas para a maioria dos canais, leva cerca de 12 horas.
Para resolver esse problema, começamos a usar todos os tipos de relatórios para baixar dados dos sites, estamos tentando desenvolver suas APIs juntamente com os sites para que sua velocidade atenda às nossas necessidades e paralelize o carregamento de dados o máximo possível.
Outro problema é o processamento dos dados baixados. Agora, com a chegada de novas estatísticas de posicionamento, é iniciado um processo de recálculo de métricas em vários estágios, que inclui o carregamento de dados brutos, o cálculo de métricas agregadas para cada site, a comparação de dados de diferentes fontes entre si e o cálculo de métricas de resumo para a campanha. Isso causa uma grande carga no aplicativo Web, que executa todos os cálculos. Várias vezes, no processo de recontagem, o aplicativo consome toda a memória do servidor, cerca de 10 a 15 GB, o que tem o efeito mais prejudicial no trabalho do usuário com o sistema.
Os problemas identificados e os planos grandiosos para o desenvolvimento adicional do produto nos levaram à necessidade de revisar a arquitetura do aplicativo.
Começamos com conectores.
Percebemos que todos os conectores funcionam de acordo com o mesmo modelo; portanto, construímos um transportador de tubulação no qual, para criar o conector, era necessário apenas programar a lógica das etapas, o resto era universal. Se algum conector precisar ser aprimorado, nós o transferiremos imediatamente para uma nova estrutura enquanto finalizamos o conector.
Paralelamente, começamos a colocar conectores no docker e no Kubernetes.
Planejamos mudar para o Kubernetes por um longo tempo, experimentamos as configurações de CI / CD, mas começamos a mudar somente quando um conector começou a consumir mais de 20 GB de memória no servidor devido a um erro, quase matando o restante dos processos. Durante a investigação, o conector foi realocado para o cluster Kubernetes, onde permaneceu eventualmente, mesmo quando o erro foi corrigido.
Muito rapidamente, percebemos que o Kubernetes era conveniente e, em seis meses, transferimos 7 conectores e Proxy de Conectores para o cluster de produção, que consomem mais recursos.
Seguindo os conectores, decidimos alterar a arquitetura do restante do aplicativo.
O principal problema era que os dados vêm de conectores para proxies em pacotes grandes e, em seguida, eles batiam no DANBoID e transferidos para um aplicativo da Web central para processamento. Devido ao grande número de recálculos de métricas, ocorre uma grande carga no aplicativo.
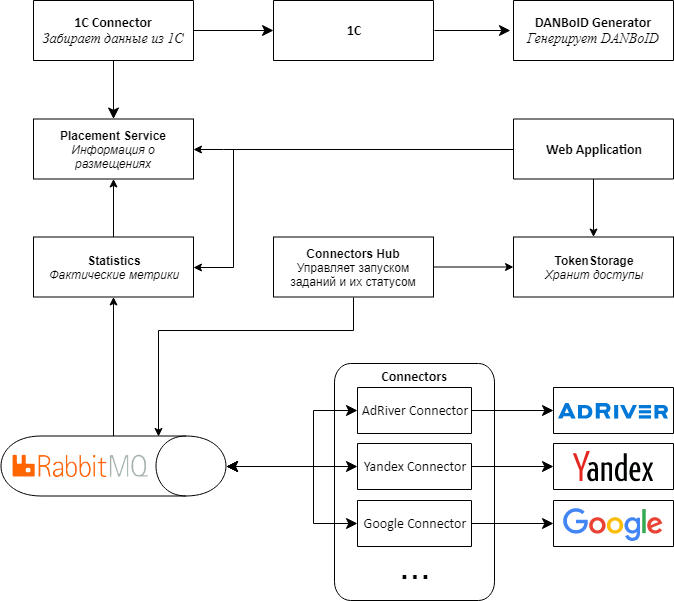
, , web , , , - .
2.0.
, Web API RabbitMQ MassTransit . Connectors Proxy, Connectors Hub. , , .
web , . .
Kubernetes, .
Proof-of-concept 2.0
D1.Digital . — 20 , , , , .
, API, .
, , adserving .
, web , Kubernetes. , , .
, MongoDB. SQL-, , , , .
, , :)
R&D Dentsu Aegis Network Russia: ( shmiigaa ), ( hitexx )