
Dois anos atrás, ao ligar a TV acidentalmente, vi uma história interessante no programa Vesti. Foi dito que o Departamento de Tecnologia da Informação de Moscou está criando uma rede neural que lê as leituras dos hidrômetros das fotografias. Na história, o apresentador de TV pediu às pessoas da cidade que ajudassem o projeto e enviassem imagens de seus medidores para o portal mos.ru, a fim de treinar uma rede neural sobre eles.
Se você é um departamento de Moscou, liberar um vídeo no canal federal e pedir às pessoas para enviarem imagens de medidores não é um problema muito grande. Mas e se você é uma pequena startup e não pode fazer propaganda em um canal de TV? Como obter 50.000 imagens de contadores neste caso? Yandex.Toloka vem em socorro!
O Yandex.Toloka é uma plataforma de crowdsourcing na qual pessoas de todo o mundo realizam tarefas simples, recebendo dinheiro por isso. Por exemplo, os tolokers podem encontrar pedestres na imagem, treinar assistentes de voz e muito mais . Ao mesmo tempo, não apenas os funcionários da Yandex, mas qualquer pessoa que desejar pode postar tarefas no Toloka.
Declaração do problema
Então, queremos criar uma rede neural que, a partir da foto, determine as leituras dos contadores. Por onde começar, de que dados precisamos?
Após consultar os colegas, concluímos que, para criar o MVP, precisamos de 1000 imagens contrárias. Além disso, para cada contador, queremos saber as leituras atuais, bem como as coordenadas da janela com números. 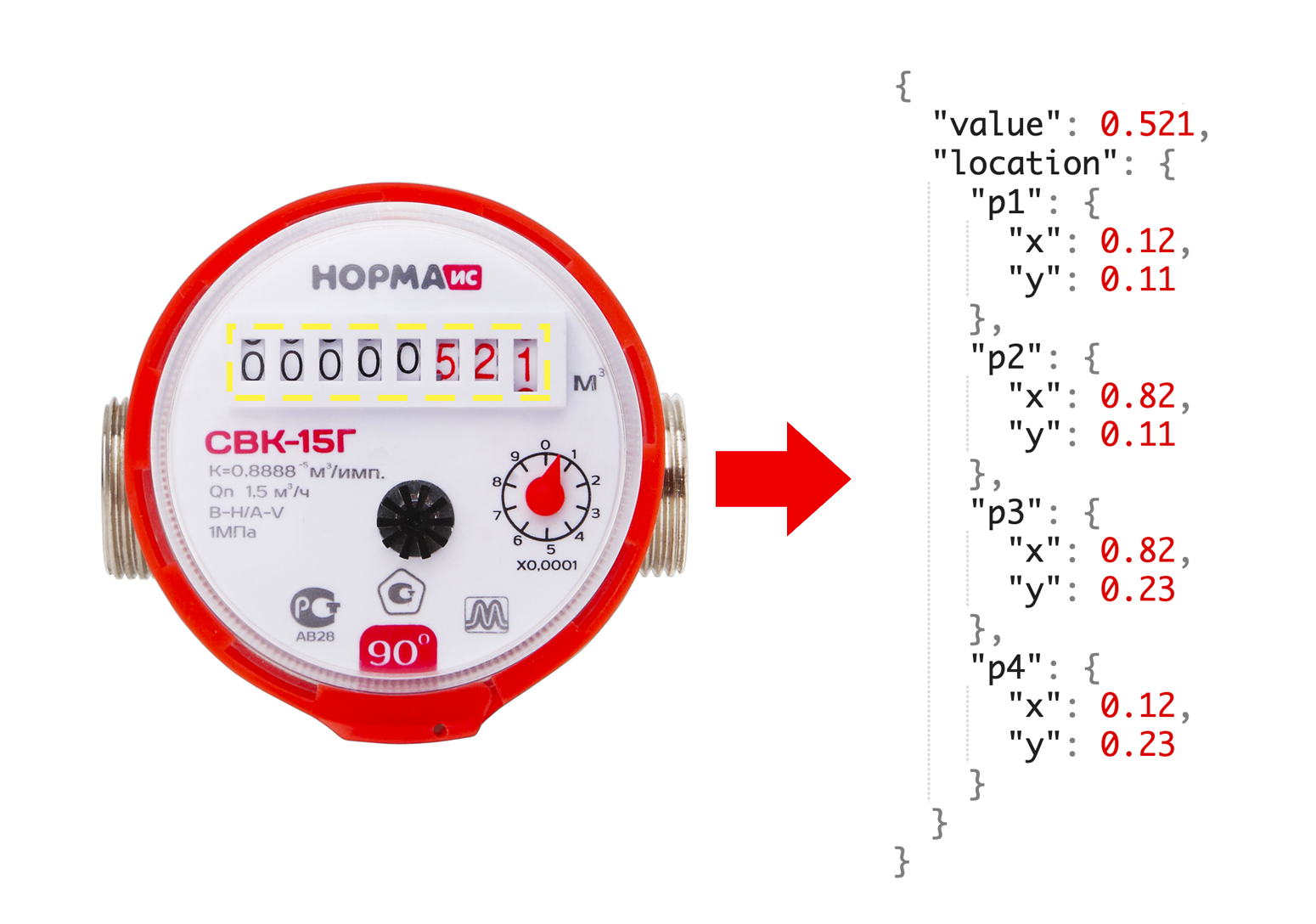
Se você nunca trabalhou com Toloka, recomendo que leia o artigo que escrevi há um ano. Como o artigo atual será tecnicamente mais complicado, omitirei alguns pontos descritos em detalhes no artigo anterior.
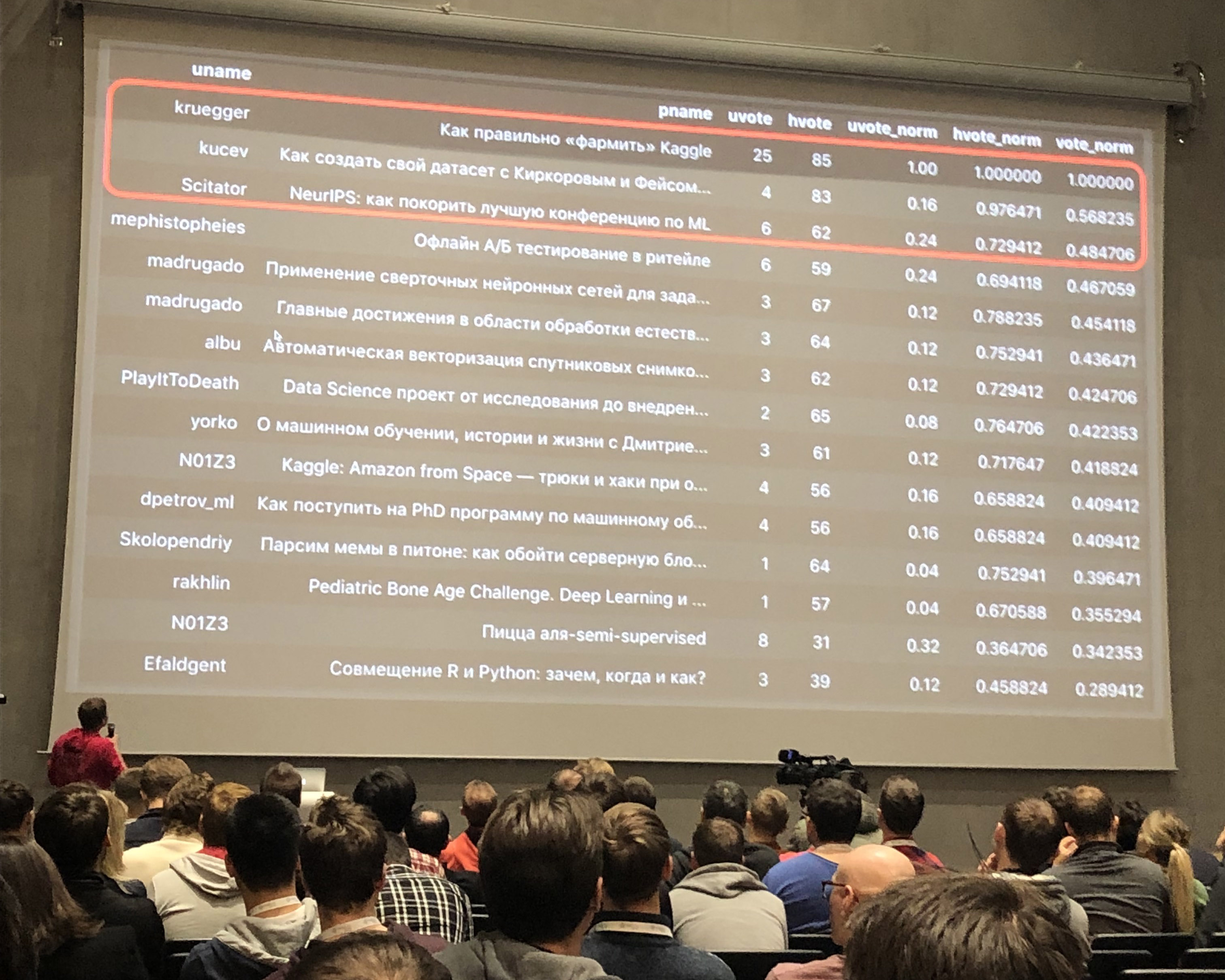
AgradecimentosO artigo anterior se tornou o TOP-2 no ranking de artigos da comunidade ODS . Obrigado por comentar e colocar os profissionais!)
Parte 1. Aquisição de imagens
O que poderia ser mais fácil? Basta pedir à pessoa para abrir o aplicativo Yandex.Tolok no telefone e tirar uma foto do balcão. Se eu não trabalhasse com Toloka por vários anos, minhas instruções seriam: "Você precisa fotografar seu hidrômetro (quente ou frio) e nos enviar uma imagem" .
Infelizmente, com essa declaração do problema, um bom conjunto de dados não pode ser coletado. O fato é que as pessoas podem interpretar esse TK de maneiras diferentes, pois as instruções não possuem critérios claros para uma tarefa concluída corretamente. Os Tolockers podem enviar:
- imagens borradas;
- Imagens que não mostram evidências
- Imagens com vários contadores.
O blog da Toloka tem um ótimo tutorial sobre como escrever instruções. Seguindo-o, recebi esta instrução: 
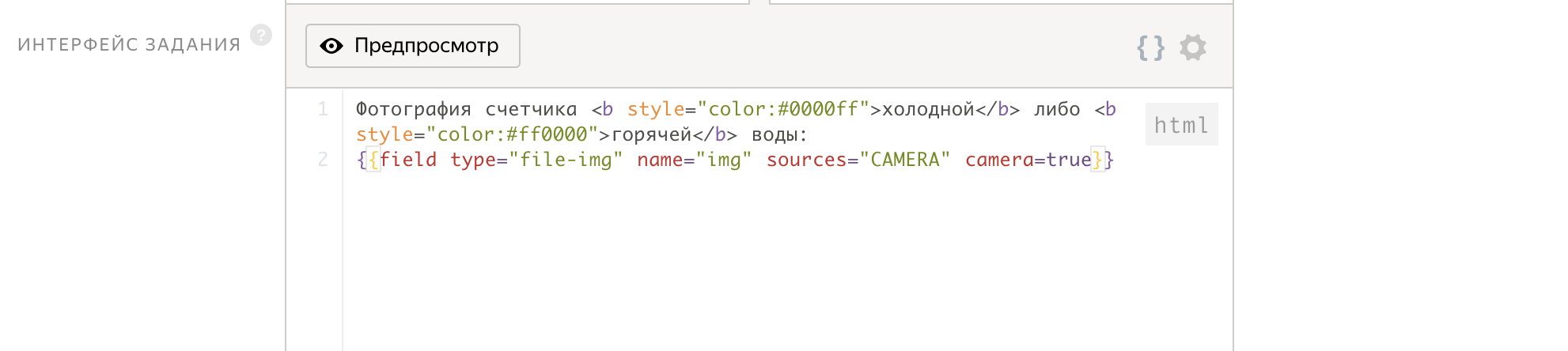
Como parâmetros de entrada, passamos o ID da tarefa e, na saída, obtemos o arquivo img, que conterá a imagem do contador.

A interface do trabalho é escrita em apenas 2 linhas!
Ao criar um pool, indicamos o tempo para concluir a tarefa, a aceitação atrasada e o preço da tarefa 0,01 $.
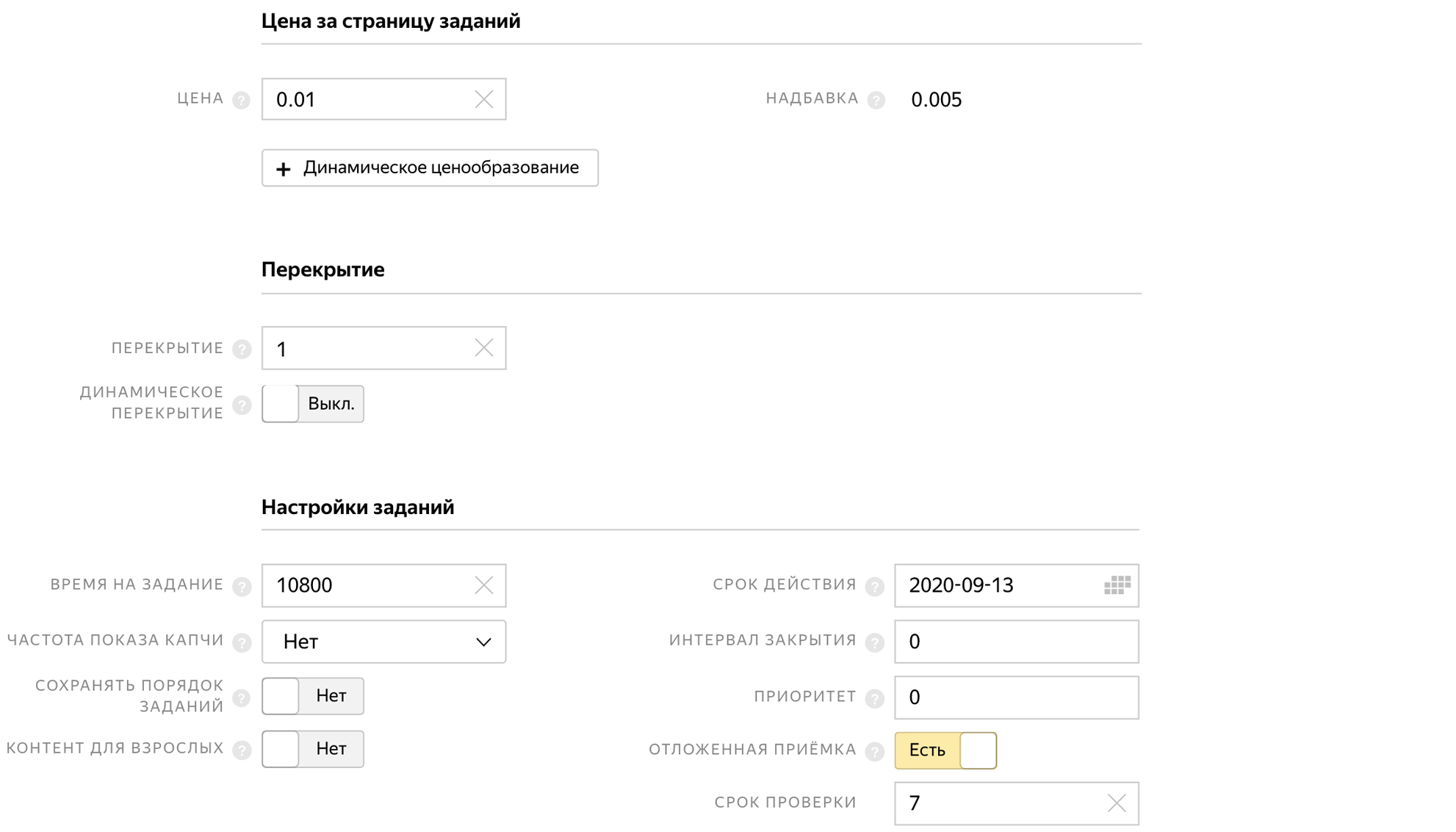
E para que as pessoas não concluam a tarefa várias vezes e não enviem as mesmas fotos, proibimos a execução repetida da tarefa no bloco de controle de qualidade.
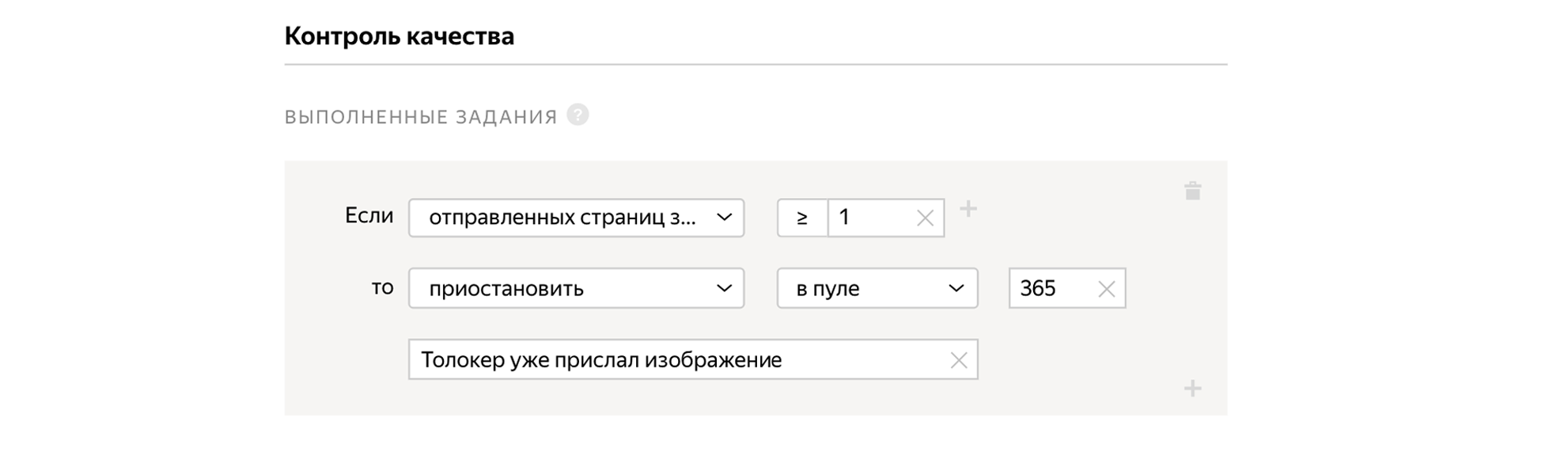
Indicamos que precisamos de usuários de língua russa que concluam a tarefa por meio do aplicativo móvel Yandex.Tolok.
Download de tarefas para o pool.
Começamos a piscina, nos alegramos e aguardamos as respostas dos usuários! É assim que nossa tarefa fica do lado do toloker:
Parte 2. Aceitação de tarefas
Depois de esperar algumas horas, vemos que os tolkers concluíram a tarefa. Como com a aceitação atrasada, o prêmio não é pago ao contratado imediatamente, mas é congelado no balanço do cliente, agora precisamos verificar todas as imagens enviadas. Para que artistas de boa-fé aceitem tarefas e artistas que enviaram imagens inadequadas para os critérios, recuse e escreva o motivo da recusa.
Se não houvesse muitas imagens, poderíamos visualizar e verificar todas as imagens enviadas por nós. Mas queremos obter milhares e dezenas de milhares de imagens! A verificação desse volume de tarefas exigirá uma quantidade significativa de tempo. Além disso, esse processo requer nossa participação diretamente.
Toloka vem em socorro novamente! Podemos criar uma nova tarefa "Verificando imagens do contador" e pedir a outros tolkers que respondam se a imagem se encaixa nos nossos critérios ou não. Ao configurar o processo uma vez, obtemos coleta e validação de dados totalmente automáticas! Ao mesmo tempo, a coleta de dados é facilmente escalável e, se precisarmos aumentar o tamanho do conjunto de dados várias vezes, basta clicar em alguns botões.
Parece incrível e grandioso, não é?
Então é hora de colocar a idéia em prática!
Primeiro, definiremos os critérios pelos quais consideraremos a foto boa.
Uma foto é boa se:
- Na foto, há exatamente um balcão de água fria ou quente;
- As leituras no balcão são claramente visíveis.
Em outros casos, a foto é considerada ruim.
Nós resolvemos os critérios, agora estamos escrevendo uma instrução! 
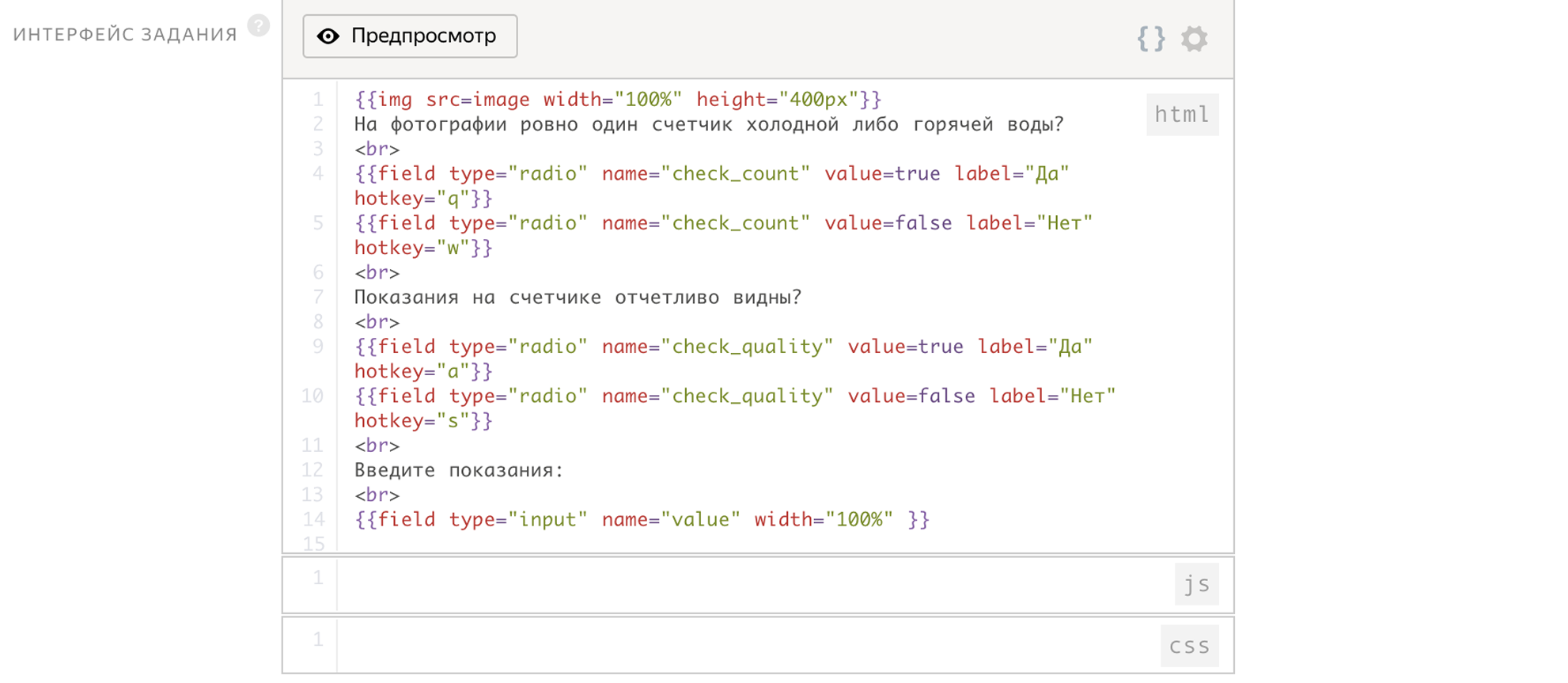
Como parâmetros de entrada, passamos o link para a imagem. A saída será dois sinalizadores:
- check_count - responda à primeira pergunta
- check_quality - responda à segunda pergunta
O contador será gravado na variável value.
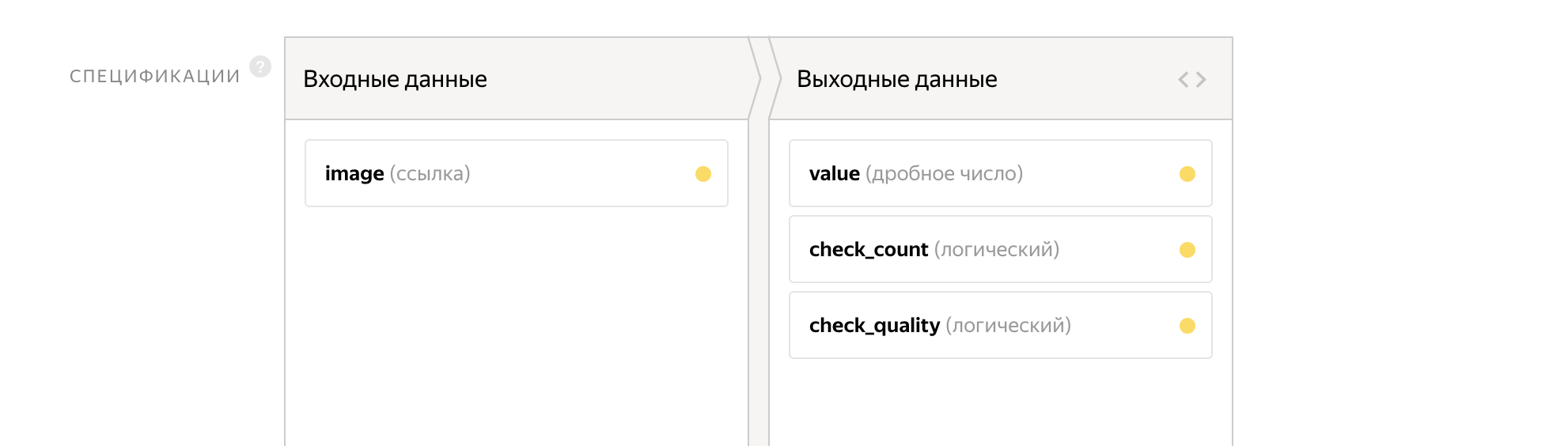
A interface desta tarefa já ocupa 14 linhas.
Para aumentar a precisão, uma imagem será verificada independentemente por 5 marcadores, e por isso colocaremos uma sobreposição de 5. Depois disso, veremos como 5 pessoas responderam e assumiremos que a resposta correta é aquela pela qual a maioria votou. Essa tarefa não terá mais atraso na aceitação.
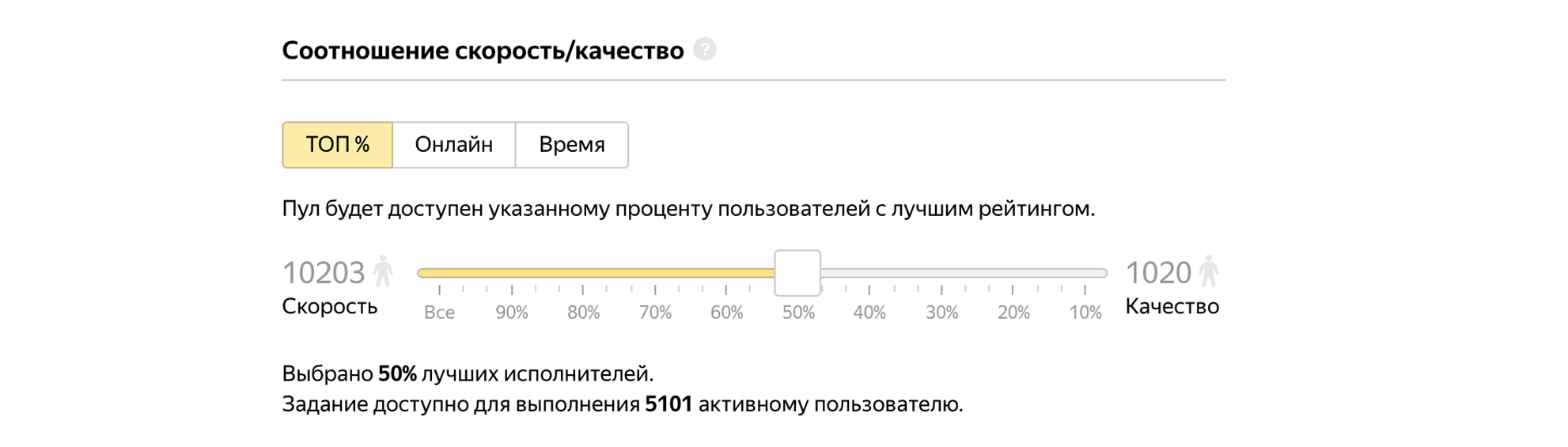
Vamos admitir 50% dos melhores desempenhos para a tarefa.
Nas tarefas sem aceitação tardia, todos recebem pagamento, independentemente de executarem a tarefa corretamente ou não. Mas queremos que os tolokers leiam cuidadosamente as instruções, tentem e concluam a tarefa corretamente. Como isso pode ser alcançado?
Existem duas ferramentas principais no Tolok que permitem manter a boa qualidade:
- Treinamento. Antes de concluir a tarefa principal, podemos solicitar aos treinadores que sejam treinados. No grupo de treinamento, as pessoas recebem tarefas para as quais sabemos as respostas corretas com antecedência. Se uma pessoa respondeu incorretamente, um erro é mostrado e explicado como responder. Depois de concluir o treinamento, vemos qual a porcentagem de tarefas que o executante concluiu e só podemos permitir aqueles que foram bem-sucedidos no conjunto principal de tarefas.
- Blocos de controle de qualidade. Pode haver uma situação em que a piscina de treinamento do artista foi excelente, fomos autorizados a fazê-lo, mas cinco minutos depois ele saiu para jogar futebol, deixando seu irmão de três anos no computador. Felizmente, existem muitos métodos no Tolok que permitem acompanhar como as pessoas concluem tarefas.
Com o pool de treinamento, tudo é simples: basta adicionar tarefas, marcá-las na interface Yandex.Tolki e especificar o limite de aprovação, a partir do qual permitimos que as pessoas executem a tarefa principal.
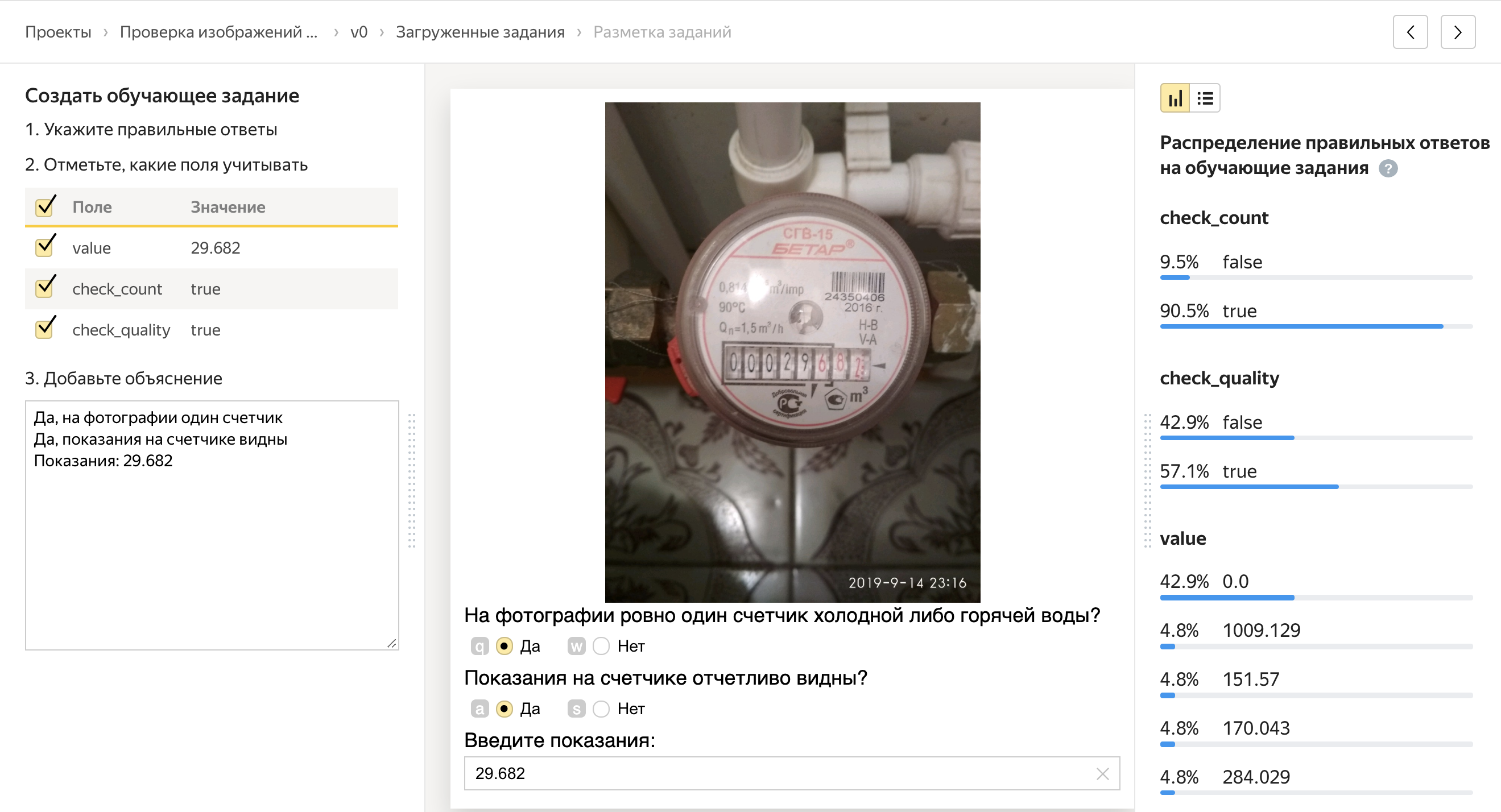
Com as unidades de controle de qualidade, tudo é mais interessante: existem muitas, mas vou me concentrar nas duas mais importantes.
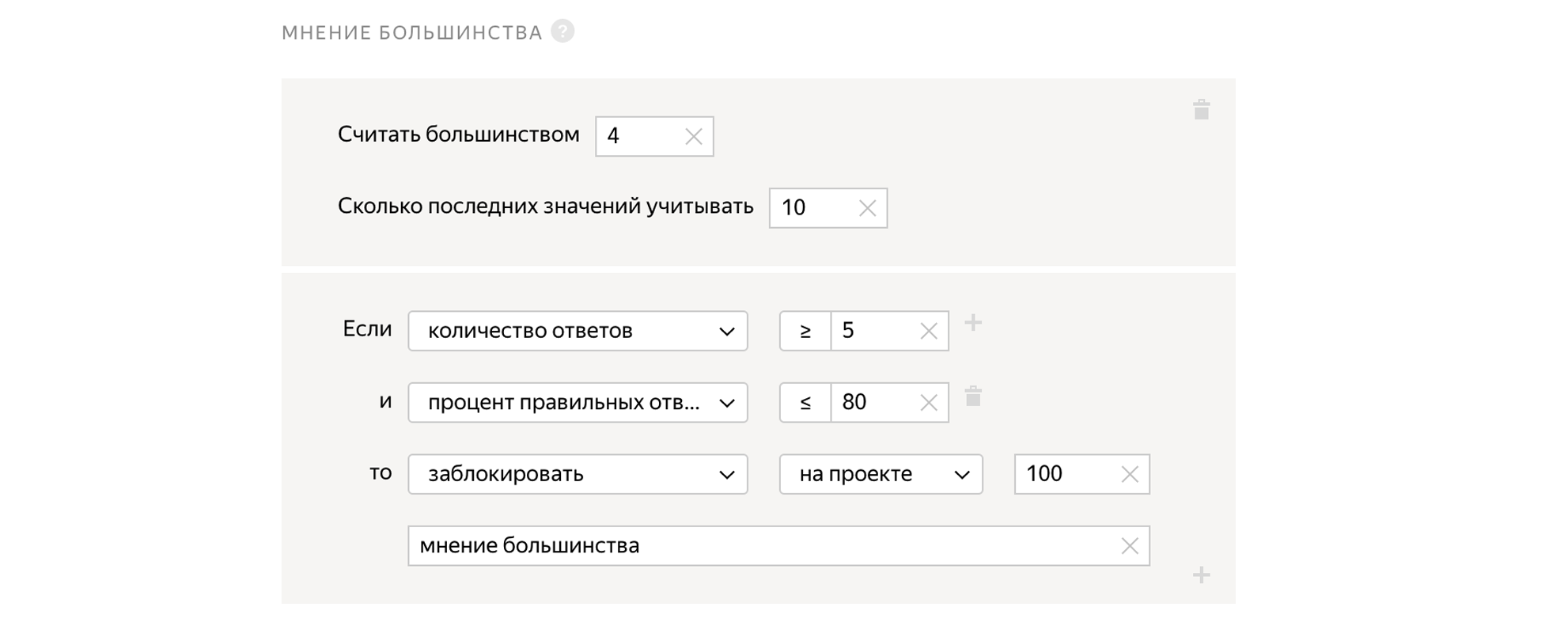
Parecer da maioria
Damos a tarefa a 5 pessoas independentes. E se quatro pessoas respondem "Sim" à pergunta e a quinta responde "Não", então a quinta provavelmente cometeu um erro. Assim, podemos observar como as respostas da pessoa são consistentes com as de outras pessoas e bloquear usuários que respondem de maneira diferente das outras.
Tarefas de controle
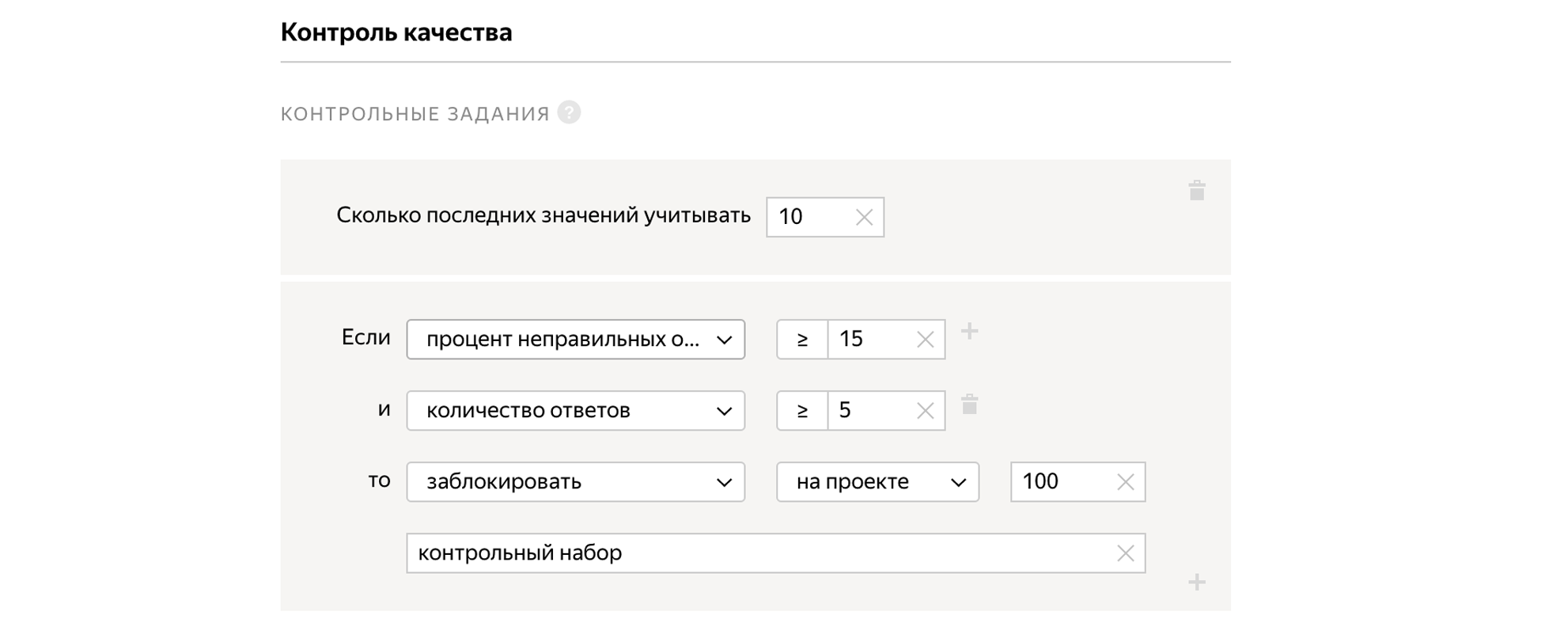
Podemos misturar tarefas no pool, para as quais sabemos a resposta correta com antecedência. Ao mesmo tempo, as tarefas de controle de qualidade têm a mesma aparência que as tarefas regulares. Com base no fato de uma pessoa responder corretamente às tarefas de controle, podemos extrapolar e assumir, corretamente ou não, que ele resolve todas as outras tarefas para as quais não sabemos as respostas. Se uma pessoa responder mal às tarefas de controle, podemos bloqueá-la e, se for boa, dar um bônus.
Viva, tarefa criada! É assim que a interface se parece com o executor:
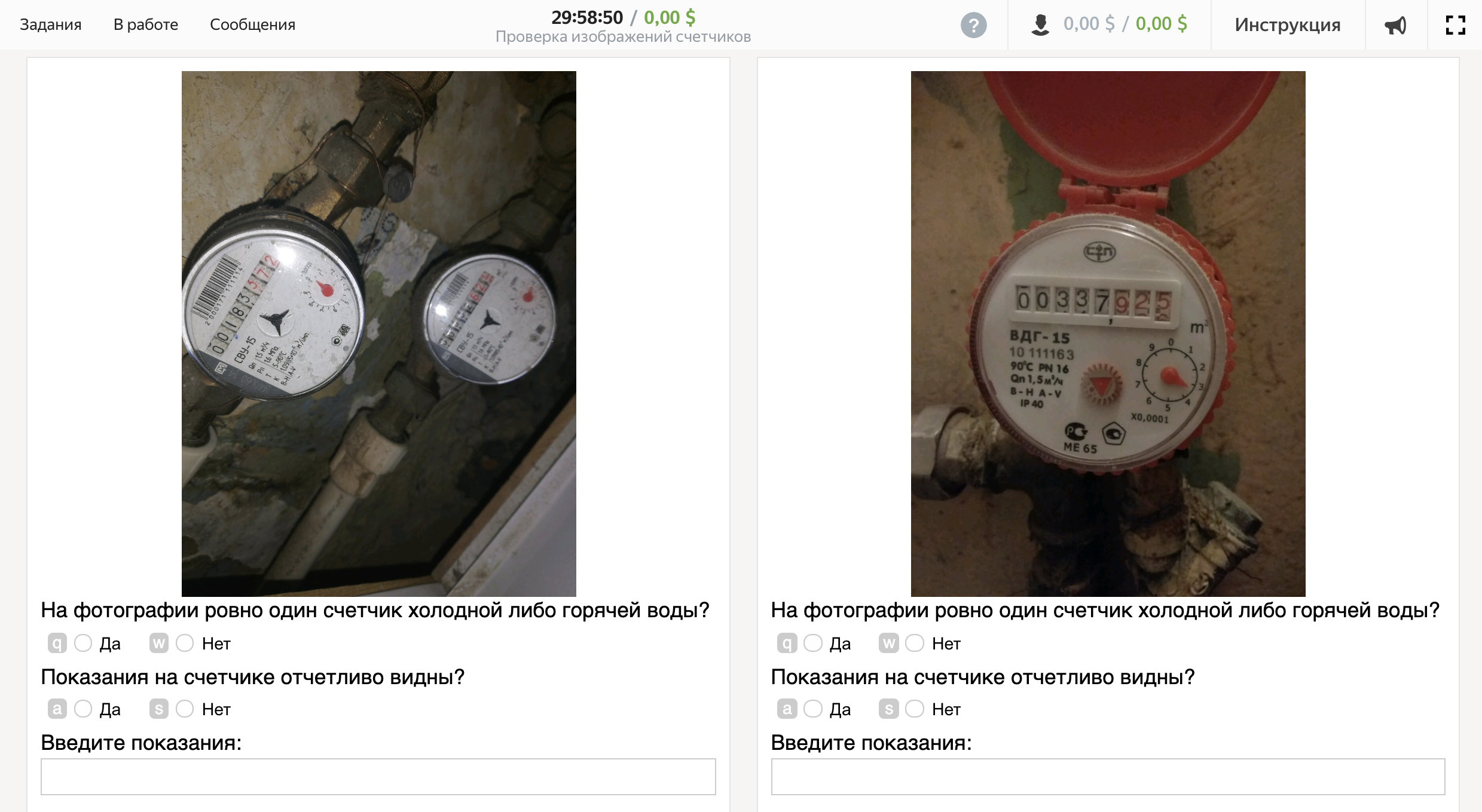
Parte 3. Entrando em trabalhos
Ótimo, as tarefas estão prontas! Mas surge a pergunta: como conectar tarefas entre si? Como fazer a segunda execução após a primeira tarefa?
Obviamente, você pode tocar com um pandeiro e fazê-lo manualmente através da interface Toloka, mas existe uma maneira mais simples e rápida! Yandex.Tolok tem uma API , use-a e escreva um script python!
Eu sei que muitos de vocês não gostam de ler código, então eu o escondi sob um spoilerimport pandas as pd import numpy as np import requests import boto3
Executamos o código e aqui está o resultado esperado: o conjunto de dados de 871 imagens de contador está pronto.

Preço
Vamos avaliar o componente econômico do projeto.
Para a imagem enviada na primeira tarefa, oferecemos US $ 0,01.
Infelizmente, se pagarmos ao artista $ 0,01, teremos que pagar $ 0,018.
Como isso é feito?
- A comissão do Yandex é mínima (0,005,20%). Para uma tarefa com preço de 0,01 $, a comissão será de 50%;
- O IVA é de 20%.
Para verificar 10 imagens dos contadores, pagamos US $ 0,01. Nesse caso, uma imagem é verificada 5 vezes por pessoas independentes. No total, damos a verificação de uma imagem: (0,01 x 5/10) x 1,2 x 1,5 = $ 0,009.
Das 1000 inscrições enviadas, 871 imagens foram recebidas e 129 foram rejeitadas. Portanto, para obter um conjunto de dados de 871 imagens, pagamos:
0,018 $ x 871 + 0,009 $ x 1000 = $ 25 e você precisa de 92.000 rublos para obter um conjunto de dados de 50.000 imagens. Definitivamente, é mais barato do que encomendar anúncios no canal federal!
Mas esse número pode realmente ser reduzido várias vezes. Você pode:
- Sugira na primeira tarefa para tirar não uma foto, mas várias. Ao mesmo tempo, aumente o preço, a comissão Yandex não será de 50%, mas de 20%;
- Use sobreposição dinâmica na segunda tarefa. Se 4 de 5 pessoas deram a mesma resposta, não faz sentido entregar a tarefa à quinta pessoa;
- Trabalhe com a Toloka como uma entidade legal estrangeira. Nesse caso, você não paga o IVA.
Como havia tanto material, decidi dividir o artigo em duas partes. Da próxima vez, falaremos sobre como selecionar objetos em imagens usando o Toloka e criar conjuntos de dados para tarefas no Computer Vision. E para não perder, assine e curta!
PS
Depois de ler o artigo, pode parecer que você é um anúncio oculto do Yandex.Tolki, mas não, não é. Yandex não me pagou nada e provavelmente não pagará. Eu só queria mostrar em um exemplo fictício, mas relevante e interessante, como usar esse serviço, você pode montar um conjunto de dados de maneira rápida e barata para qualquer tarefa, seja para reconhecer gatos ou treinar veículos não tripulados.