Este artigo é minha tentativa de expressar minha opinião sobre os seguintes aspectos:
- O que é um fator de velocidade de aprendizado e qual é o seu valor?
- Como escolher esse coeficiente ao treinar modelos?
- Por que é necessário alterar o coeficiente da velocidade de aprendizado durante o treinamento dos modelos?
- O que fazer com um fator de velocidade de aprendizado ao usar um modelo pré-treinado?
A maior parte deste post é baseada em materiais preparados por
fast.ai : [1], [2], [5] e [3] - representando uma versão concisa de seu trabalho, destinada ao entendimento mais rápido da essência da questão. Para se familiarizar com os detalhes, é recomendável clicar nos links abaixo.
O que é um fator de velocidade de aprendizado?
O coeficiente de velocidade de aprendizado é um hiperparâmetro que determina a ordem em que ajustaremos nossas escalas, levando em consideração a função de perda na descida do gradiente. Quanto menor o valor, mais lento nos movemos ao longo da inclinação. Embora ao usar um baixo coeficiente de velocidade de aprendizado, possamos obter um efeito positivo no sentido de que não perdemos um único mínimo local, isso também pode significar que teremos que gastar muito tempo em convergência, especialmente se estivermos na região do platô.
O relacionamento é ilustrado pela seguinte fórmula
 Descida de gradiente com fatores de velocidade de aprendizado pequenos (em cima) e grandes (em baixo). Fonte: Curso de aprendizado de máquina de Andrew Ng no Coursera
Descida de gradiente com fatores de velocidade de aprendizado pequenos (em cima) e grandes (em baixo). Fonte: Curso de aprendizado de máquina de Andrew Ng no Coursera
Na maioria das vezes, o fator de velocidade de aprendizado é definido arbitrariamente pelo usuário. Na melhor das hipóteses, para uma compreensão intuitiva de qual valor é mais adequado para determinar o coeficiente de velocidade de aprendizado, ele pode confiar em experimentos anteriores (ou em outro tipo de material de treinamento).
Basicamente, já é difícil escolher o valor certo. O diagrama abaixo ilustra vários cenários que podem surgir quando o usuário ajusta independentemente a taxa de velocidade de aprendizado.
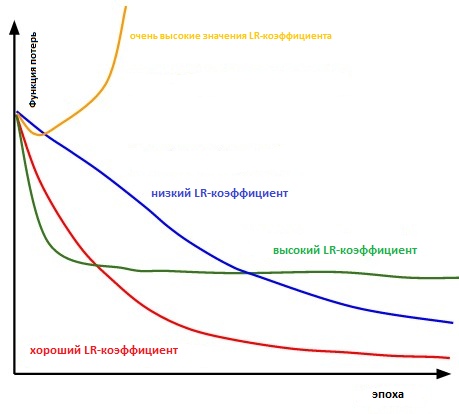 A influência de vários fatores da taxa de aprendizado na convergência. (Img de crédito: cs231n)
A influência de vários fatores da taxa de aprendizado na convergência. (Img de crédito: cs231n)
Além disso, o fator de velocidade de aprendizado afeta a rapidez com que nosso modelo atinge um mínimo local (ou seja, alcançará a melhor precisão). Assim, a escolha certa desde o início garante menos perda de tempo para o treinamento do modelo. Quanto menos tempo de treinamento, menos dinheiro é gasto no poder de computação da GPU na nuvem.
Existe uma maneira mais conveniente de determinar a taxa de coeficiente de aprendizagem?
No ponto 3.3. “
Coeficientes de taxa de aprendizado cíclico para redes neurais ” Leslie Smith defendeu o seguinte ponto: a eficácia da velocidade de aprendizado pode ser estimada treinando o modelo com uma velocidade de aprendizado baixa inicialmente definida, que depois aumenta (linear ou exponencialmente) a cada iteração.
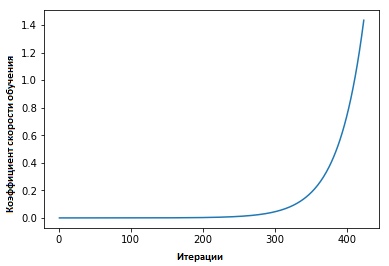 O fator de velocidade de aprendizado aumenta após cada mini-pacote.
O fator de velocidade de aprendizado aumenta após cada mini-pacote.
Fixando os valores dos indicadores em cada iteração, veremos que à medida que a velocidade de aprendizado aumenta, será atingido um ponto no qual o valor da função de perda deixa de diminuir e começa a aumentar. Na prática, nossa velocidade de aprendizado deve estar idealmente em algum lugar à esquerda do ponto inferior do gráfico (como mostrado no gráfico abaixo). Nesse caso (o valor será) de 0,001 a 0,01.
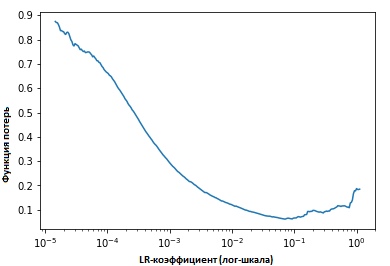
O texto acima parece útil. Como começar a usá-lo?
No momento, há uma função pronta no pacote
fast.ia desenvolvido por Jeremy Howard, esse é um tipo de abstração / complemento na parte superior da biblioteca pytorch (semelhante à maneira como é feita no caso de Keras e Tensorflow).
Só é necessário digitar o comando a seguir para iniciar a busca pelo coeficiente ideal de velocidade de aprendizado antes de (iniciar) o treinamento da rede neural.
learn.lr_find() learn.sched.plot_lr()
Melhorando o modelo
Então, conversamos sobre qual é o coeficiente de velocidade de aprendizado, qual é o seu valor e como atingir seu valor ideal antes de começar a treinar o próprio modelo.
Agora, vamos nos concentrar em como o fator de velocidade de aprendizado pode ser usado para ajustar modelos.
Sabedoria convencional
Geralmente, quando o usuário define seu coeficiente de velocidade de aprendizado e começa a treinar o modelo, ele precisa esperar até que o coeficiente de velocidade de aprendizado comece a cair e o modelo atinja o valor ideal.
No entanto, a partir do momento em que o gradiente atinge um platô, fica mais difícil melhorar os valores da função de perda ao treinar o modelo. Em [3], Dauphin expressa a opinião de que a dificuldade em minimizar a função de perda decorre do ponto de sela e não do mínimo local.
 Um ponto de sela na superfície dos erros. Um ponto de sela é um ponto do domínio de definição de uma função que é estacionária para uma determinada função, mas não é seu extremo local
Um ponto de sela na superfície dos erros. Um ponto de sela é um ponto do domínio de definição de uma função que é estacionária para uma determinada função, mas não é seu extremo local . (ImgCredit: safaribooksonline)
Então, como isso pode ser evitado?
Proponho considerar várias opções. Um deles, geral, usando a citação de [1],
... em vez de usar um valor fixo para o coeficiente de velocidade de aprendizado e diminuí-lo ao longo do tempo, se o treinamento não suavizar mais nossa perda, mudaremos o coeficiente de velocidade de aprendizado em cada iteração, de acordo com alguma função cíclica f. Cada loop possui - em termos de número de iterações - um comprimento fixo. Este método permite que o coeficiente de velocidade de aprendizado varie entre valores razoáveis de limite. Isso realmente ajuda, porque, ao ficar preso nos pontos de sela, aumentando o coeficiente de velocidade da aprendizagem, obtemos uma interseção mais rápida do platô de pontos de sela
Em [2], Leslie propõe o "método do triângulo", no qual o coeficiente de velocidade de aprendizado é revisado após cada uma das várias iterações.

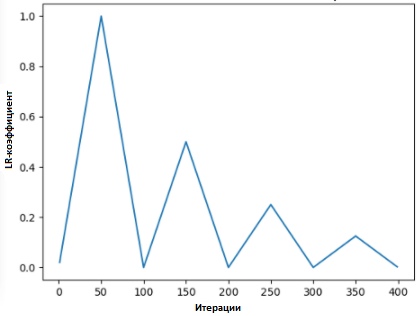 "O método dos triângulos" e o "método dos triângulos-2" são métodos para teste cíclico dos coeficientes da taxa de aprendizado, propostos por Leslie N. Smith. No gráfico superior, o Ir mínimo e o máximo são mantidos iguais.
"O método dos triângulos" e o "método dos triângulos-2" são métodos para teste cíclico dos coeficientes da taxa de aprendizado, propostos por Leslie N. Smith. No gráfico superior, o Ir mínimo e o máximo são mantidos iguais.Outro método, que não é menos popular e denominado “descida gradiente estocástica com um reset a quente”, foi proposto por Lonchilov & Hutter [6]. Este método, baseado no uso da função cosseno como uma função cíclica, reinicia o coeficiente da velocidade de aprendizado no ponto máximo de cada ciclo. A aparência do bit "Quente" se deve ao fato de que, quando o coeficiente da taxa de aprendizado é reiniciado, ele começa não a partir do nível zero, mas a partir dos parâmetros aos quais o modelo atingiu a etapa anterior.
Como esse método possui variações, o gráfico abaixo mostra um dos métodos de sua aplicação, em que cada ciclo está vinculado ao mesmo intervalo de tempo.
 SGDR - gráfico, coeficiente de taxa de aprendizado vs. iterações
SGDR - gráfico, coeficiente de taxa de aprendizado vs. iterações
Assim, temos uma maneira de reduzir a duração do treinamento simplesmente pulando os "picos" de tempos em tempos (como mostrado abaixo).
 Comparação de coeficientes de taxa de aprendizagem fixa e cíclica
Comparação de coeficientes de taxa de aprendizagem fixa e cíclica (img credit:
arxiv.org/abs/1704.00109Além de economizar tempo, esse método, de acordo com estudos, melhora a precisão da classificação sem ajuste e por menos iterações.
Taxa de transferência de aprendizado em Transferência de aprendizado
No curso de
fast.ai, a ênfase está no gerenciamento de um modelo pré-treinado na solução de problemas de inteligência artificial. Por exemplo, ao resolver problemas de classificação de imagem, os alunos são treinados no uso de modelos pré-treinados, como VGG e Resnet50, e vinculá-los à amostra de dados de imagem que precisa ser prevista.
Para resumir como o modelo é construído no programa
fast.ai (para não confundir com
o pacote fast. Ai ), o pacote do programa), abaixo estão as etapas que
executaremos em uma situação comum:
- Ativar aumento de dados e pré-calcular = True
- Use Ir_find () para encontrar o maior coeficiente de taxa de aprendizado, onde a perda ainda está claramente melhorando.
- Treine a última camada de ativações pré-calculadas para a era 1-2.
- Treine a última camada com ganho de dados (ou seja, calcule = false) por 1-2 épocas com o ciclo _len 1.
- Descongele todas as camadas.
- Coloque as camadas anteriores em um fator de velocidade de aprendizado 3x-10x abaixo da próxima camada alta
- Reutilizar Ir_find ()
- Treine uma rede completa com o ciclo _mult = 2 = 2 até começar a reciclagem.
Você pode perceber que as etapas dois, cinco e sete (acima) estão relacionadas à taxa do fator de aprendizado. Em uma parte anterior de nosso post, destacamos o ponto das segundas etapas mencionadas - onde abordamos como obter o melhor coeficiente de velocidade de aprendizado antes de começar a treinar o modelo.
No próximo parágrafo, falamos sobre como você pode reduzir o tempo de treinamento usando o SGDR e, reiniciando periodicamente o fator de velocidade de aprendizado, aprimora a precisão para evitar áreas onde o gradiente está próximo de zero.
Na última seção, abordaremos o conceito de aprendizado diferenciado e explicaremos como ele é usado para determinar o coeficiente de velocidade de aprendizado quando um modelo treinado é associado a um pré-treinado ...
O que é aprendizagem diferencial
Este é um método no qual vários fatores de velocidade de treinamento são definidos na rede durante o treinamento. Ele fornece uma alternativa à maneira pela qual os usuários geralmente ajustam os fatores de velocidade de aprendizado - ou seja, usando o mesmo fator de velocidade de aprendizado pela rede durante o treinamento.
 A razão pela qual eu amo o Twitter é uma resposta direta da própria pessoa.
A razão pela qual eu amo o Twitter é uma resposta direta da própria pessoa.
(No momento da redação deste post, Jeremy publicou um artigo com Sebastian Ruder, que se aprofundou ainda mais neste tópico. Então, acredito que o coeficiente diferencial de velocidade de aprendizado agora tem outro nome - ajuste exato discriminatório :)
Para demonstrar o conceito mais claramente, podemos nos referir ao diagrama abaixo, no qual o modelo previamente treinado é “dividido” em 3 grupos, onde cada um é ajustado com um valor crescente do coeficiente de velocidade de aprendizado.
 Exemplo da CNN com coeficiente de taxa de aprendizado diferenciado
Exemplo da CNN com coeficiente de taxa de aprendizado diferenciado . Crédito de imagem de [3]
Esse método de configuração é baseado no seguinte entendimento: as primeiras camadas geralmente contêm detalhes muito pequenos dos dados, como linhas e ângulos - dos quais não tentaremos mudar muito e salvar as informações nelas contidas. Em geral, não há necessidade séria de alterar seu peso para qualquer número grande.
Pelo contrário, para as camadas subseqüentes - como as da imagem pintadas de verde, onde obtemos sinais detalhados dos dados, como brancos dos olhos, boca ou nariz - a necessidade de salvá-las desaparece.
Como isso se compara com outros métodos de ajuste fino?
Em [9], foi provado que o ajuste fino de todo o modelo seria muito caro, uma vez que os usuários podem obter mais de 100 camadas. Na maioria das vezes, as pessoas recorrem à otimização do modelo, uma camada de cada vez.
No entanto, esse é o motivo de vários requisitos, os chamados simultaneidade interferente e requer várias entradas por meio de um conjunto de dados, o que leva ao treinamento excessivo de pequenos conjuntos
Também mostramos que os métodos apresentados em [9] são capazes de melhorar a precisão e reduzir o número de erros em várias tarefas relacionadas à classificação NRL.
 Resultados obtidos da fonte [9]
Resultados obtidos da fonte [9]Referências:
[1] Melhorando a maneira como trabalhamos com a taxa de aprendizado.
[2] A técnica da Taxa de Aprendizagem Cíclica.
[3] Transferir aprendizado usando taxas diferenciais de aprendizado.
[4] Leslie N. Smith. Taxas de aprendizado cíclico para treinamento de redes neurais.
[5] Estimando uma taxa ideal de aprendizado para uma rede neural profunda
[6] Descida estocástica de gradiente com reinicializações a quente
[7] Otimização para os destaques da aprendizagem profunda em 2017
[8] Caderno da lição 1, fast.ai Parte 1 V2
[9] Modelos de linguagem refinados para classificação de texto.