Meu nome é Ivan Bondarenko. Trabalho com algoritmos de aprendizado de máquina para análise de texto e linguagem falada desde 2005. Agora, trabalho em Moscou, a PhysTech, como desenvolvedora científica líder do laboratório de soluções de negócios baseado no NTI Competence Center for Artificial Intelligence MIPT e na empresa Data Monsters, que lida com o desenvolvimento prático de sistemas interativos para resolver vários problemas do setor. Eu também ensino um pouco na nossa universidade. Minha história será dedicada ao que é um robô de bate-papo, como algoritmos de aprendizado de máquina e outras abordagens são usados para automatizar a comunicação humano-computador e onde pode ser implementado.
A versão completa do meu discurso na “Noite das Histórias Científicas” pode ser vista no
vídeo , e farei breves resumos no texto abaixo.

Recursos de algoritmo
Primeiro de tudo, algoritmos de interação humana são usados com sucesso em call centers. O trabalho de um operador de call center é muito difícil e caro. Além disso, em muitas situações, é quase impossível resolver completamente o problema da comunicação humano-computador. Uma coisa é trabalharmos com um banco, que geralmente tem vários milhares de clientes. Você pode recrutar a equipe do call center, que atenderia esses clientes e conversaria com eles. Mas quando resolvemos tarefas mais ambiciosas (por exemplo, produzimos smartphones ou outros produtos eletrônicos de consumo), nossos clientes não são muitos milhares, mas várias dezenas de milhões em todo o mundo. E queremos entender que problemas as pessoas têm com nossos produtos. Os usuários, em regra, compartilham informações entre si nos fóruns ou gravam no serviço de suporte do fabricante do smartphone. Os operadores ao vivo não serão capazes de lidar com o trabalho em uma enorme base de clientes, e aqui os algoritmos vêm em socorro, que podem funcionar no modo multicanal, atendendo a um grande número de pessoas.
Para resolver esses problemas, criar algoritmos para sistemas de diálogo que possam interagir com uma pessoa e extrair significado, informações importantes de mensagens arbitrárias, existe toda uma área no campo da linguística de computadores - a análise de textos em linguagem natural. Um robô deve ser capaz de ler, entender, ouvir, falar e assim por diante. Esta área - Processamento de linguagem natural - divide-se em várias partes.
Compreendendo o texto (Natural Language Understanding, NLU).
Quando um bot se comunica com uma pessoa e uma pessoa escreve algo para o bot, você precisa entender o que está escrito, o que o usuário queria, o que ele mencionou em seu discurso. Entendendo as intenções do usuário, a chamada intenção - o que uma pessoa deseja: reemitir um cartão bancário ou pedir pizza. E a alocação de entidades nomeadas, isto é, coisas das quais o usuário fala especificamente: se for pizza, então “Margarita” ou “havaiano”, se o cartão, então qual sistema - MasterCard, World e assim por diante.

E, finalmente, uma compreensão da tonalidade da mensagem - em que estado emocional uma pessoa está. O algoritmo deve ser capaz de detectar em qual chave a mensagem está gravada, ou se trata de um texto de notícias ou de uma pessoa que se comunica com nosso bot para responder adequadamente à chave.
 Geração do texto (Geração de linguagem natural)
Geração do texto (Geração de linguagem natural) - uma resposta adequada a uma solicitação humana na mesma linguagem humana (natural), e não um prato complexo e nem frases formais.
Reconhecimento de voz e síntese de fala (Fala em texto e Texto em fala). Se o chatbot não corresponder apenas à pessoa, mas falar e escutar, você precisará ensiná-la a entender a linguagem falada, converter vibrações sonoras em texto, analisar esse texto com um módulo de compreensão de texto e gerar vibrações sonoras a partir do texto de resposta. qual a pessoa que o assinante ouvirá.
Tipos de bots de bate-papo
Os chatbots incluem várias arquiteturas importantes.
O chatbot que responde às perguntas mais frequentes (FAQ-chatbot) é a opção mais fácil. Sempre podemos formular um conjunto de perguntas-modelo que as pessoas fazem. Para um site para entrega de alimentos acabados, em regra, são perguntas: “quanto custará a entrega”, “você entrega no distrito de Pervomaisky” etc. Você pode agrupá-los de acordo com várias classes, intenções e intenções do usuário. E para cada intenção, selecione respostas típicas.
Bot de bate-papo direcionado (bot orientado a objetivos). Aqui, tentei mostrar a arquitetura desse chatbot, implementada no projeto iPavlov. iPavlov é um projeto para criar inteligência artificial conversacional. Em particular, um chatbot focado ajuda o usuário a atingir algum objetivo (por exemplo, reservar uma mesa em um restaurante ou pedir pizza, ou aprender algo sobre problemas no banco). Não se trata apenas da resposta à pergunta (pergunta-resposta - sem qualquer contexto). O chatbot direcionado possui um módulo para entender texto, gerenciamento de diálogo e um módulo para gerar respostas.
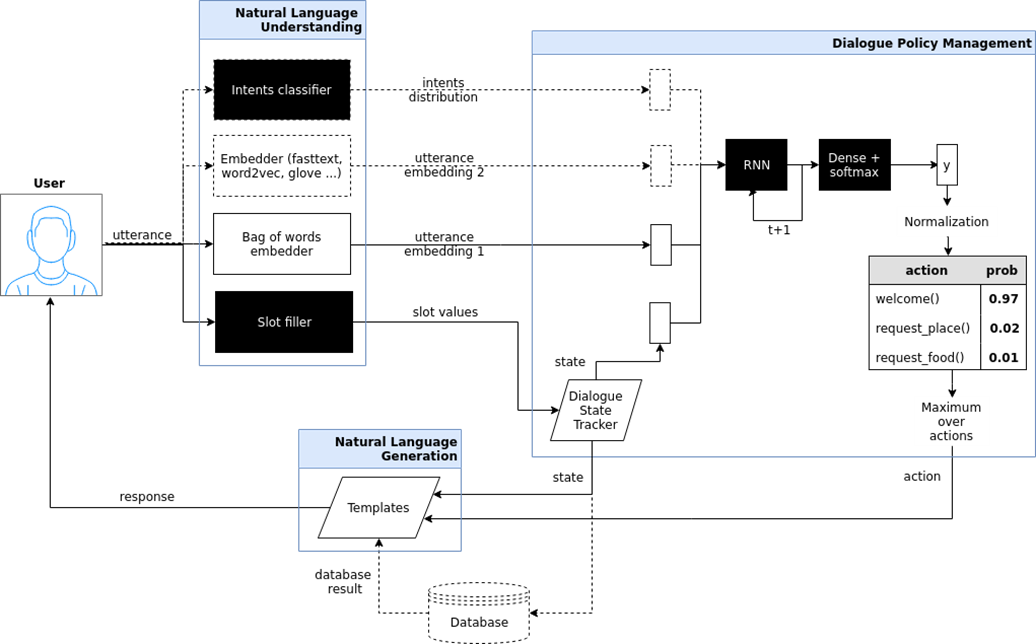 Bots de bate-papo do sistema de resposta de perguntas do sistema de resposta de perguntas e apenas "conversadores" (chit chat bot).
Bots de bate-papo do sistema de resposta de perguntas do sistema de resposta de perguntas e apenas "conversadores" (chit chat bot). Se os dois tipos anteriores de bots de bate-papo responderem às perguntas mais frequentes ou levarem o usuário pela caixa de diálogo, no final, ajudando a reservar um restaurante, descobrindo o que o usuário deseja, culinária chinesa ou italiana etc., então a resposta à pergunta um sistema é outro tipo de bot de bate-papo. O objetivo desse robô de bate-papo não é percorrer a coluna do diálogo e não apenas classificar as intenções do usuário, mas fornecer uma pesquisa de informações - para encontrar o documento mais relevante que corresponda à pergunta da pessoa e o local no documento em que a resposta está contida. Por exemplo, funcionários de um grande revendedor, em vez de memorizarem as instruções que regem o trabalho ou procuram uma resposta para colocar trigo sarraceno, fazem uma pergunta para esse chatbot com base em um sistema de perguntas e respostas.
Tipos de aprendizado de máquina
O reconhecimento de intenções, a alocação de entidades nomeadas, a busca de documentos e a busca de lugares em um documento que correspondam à semântica de uma pergunta - tudo isso sem aprendizado de máquina, sem algumas análises estatísticas, é impossível de implementar. Portanto, a base dos modernos bots de bate-papo é o aprendizado de máquina - métodos de tarefas, aproximações de alguns padrões ocultos existentes em grandes conjuntos de dados e a identificação desses padrões. Faz sentido aplicar essa abordagem quando existem padrões, tarefas, mas é impossível criar uma fórmula simples, formalismo para descrever esse padrão.
Existem vários tipos de aprendizado de máquina: com um professor (aprendizado supervisionado), sem um professor (aprendizado não supervisionado), com reforço (aprendizado por reforço). Estamos interessados principalmente na tarefa de ensinar com um professor - quando houver imagens e instruções de entrada (rótulos) do professor e a classificação dessas imagens. Ou insira sinais de fala e sua classificação. E ensinamos nosso bot, nosso algoritmo a reproduzir o trabalho de um professor.
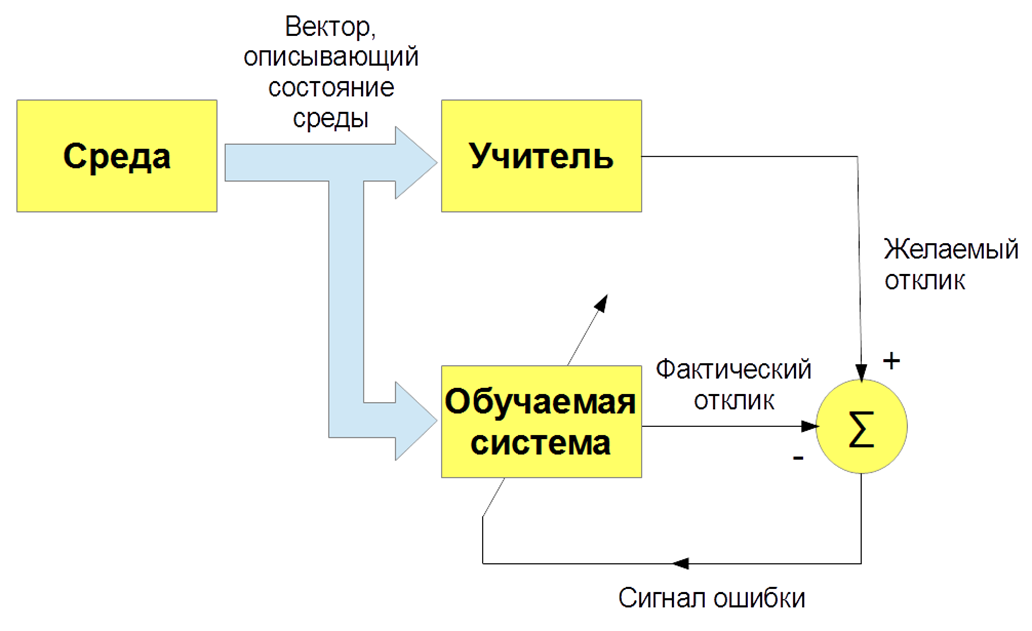
Ok, tudo parece ser legal. E como ensinar um computador a entender textos? O texto é um objeto complexo, e como as letras se transformam em números e apresentam uma descrição vetorial do texto? Existe a opção mais simples - um "saco de palavras". Pedimos ao dicionário de todo o sistema, por exemplo, todas as palavras que estão no idioma russo e formulamos vetores muito esparsos com frequências de palavras. Essa opção é boa para perguntas simples, mas para tarefas mais complexas não é adequada.
Em 2013, ocorreu uma espécie de revolução na modelagem de palavras e textos. Thomas Mikolov propôs uma abordagem especial para a representação efetiva de vetores de palavras com base na hipótese de distribuição. Se palavras diferentes são encontradas no mesmo contexto, elas têm algo em comum. Por exemplo: "Os cientistas realizaram uma análise dos algoritmos" e "Os cientistas realizaram um estudo dos algoritmos". Portanto, "Análise" e "pesquisa" são sinônimos e significam aproximadamente a mesma coisa. Portanto, você pode ensinar uma rede neural especial a prever uma palavra por contexto ou contexto por palavra.
Finalmente, como treinamos? Para treinar o bot para entender intenções, verdadeiras intenções, você precisa marcar manualmente um monte de textos usando programas especiais. Para ensinar o bot a entender as entidades nomeadas - o nome da pessoa, o nome da empresa, a localização - você também precisa colocar textos. Por conseguinte, por um lado, o algoritmo de aprendizado com o professor é o mais eficaz, permite criar um sistema de reconhecimento eficaz, mas, por outro lado, surge um problema: você precisa de conjuntos de dados grandes e rotulados, que podem ser caros e demorados. No processo de marcação dos conjuntos de dados, pode haver erros causados pelo fator humano.
Para resolver esse problema, os chatbots modernos usam o chamado aprendizado de transferência - aprendizado de transferência. Quem conhece muitas línguas estrangeiras provavelmente notou uma nuance tão grande que é mais fácil aprender outra língua estrangeira que a primeira. Na verdade, quando você estuda alguma nova tarefa, está tentando usar sua experiência passada para isso. Portanto, a transferência de aprendizado é baseada neste princípio: ensinamos o algoritmo a resolver um problema para o qual temos um grande conjunto de dados. E então esse algoritmo treinado (ou seja, pegamos o algoritmo não do zero, mas treinado para resolver outro problema), treinamos para resolver nosso problema. Assim, obtemos uma solução eficaz usando uma pequena variedade de dados.
Um desses modelos é o ELMo (Embeddings from Language Models), como o ELMo da Vila Sésamo. Usamos redes neurais recorrentes, elas têm memória e podem processar seqüências. Por exemplo: “O programador Vasya adora cerveja. Todas as noites depois do trabalho, ele vai ao Jonathan e sente falta de um ou dois copos. " Então quem é ele? Ele está esta noite, é uma cerveja ou é um programador Vasya? Uma rede neural que processa palavras como elementos de uma sequência, dado o contexto, uma rede neural recorrente, pode entender os relacionamentos, resolver esse problema e destacar alguma semântica.
Nós treinamos uma rede neural tão profunda para modelar textos. Formalmente, esta é a tarefa de aprender com um professor, mas o professor é o próprio texto não colocado. A próxima palavra no texto é professora em relação a todas as anteriores. Assim, podemos usar gigabytes, dezenas de gigabytes de texto, treinar modelos eficazes que a semântica desses textos enfatiza. E então, quando usamos os Embeddings from Language Models (ELMo) no modo de saída, fornecemos a palavra com base no contexto. Não é apenas um pedaço de pau, mas vamos ficar. Observamos o que a rede neural gera neste momento, que sinaliza. Nós catanizamos esses sinais e obtemos uma representação vetorial da palavra em um texto específico, levando em consideração seu significado somático específico.
Na análise de textos, há mais uma característica: quando a tarefa de tradução automática é resolvida, o mesmo significado pode ser transmitido por um número de palavras em inglês e outro número de palavras em russo. Portanto, não há comparação linear e precisamos de um mecanismo que se concentre em certas partes do texto para traduzi-las adequadamente em outro idioma. Inicialmente, a atenção foi inventada para a tradução automática - a tarefa de converter um texto em outro com sistemas neurais recorrentes convencionais. A isso, acrescentamos uma camada especial de atenção, que, a cada momento, avalia qual palavra é importante para nós agora.
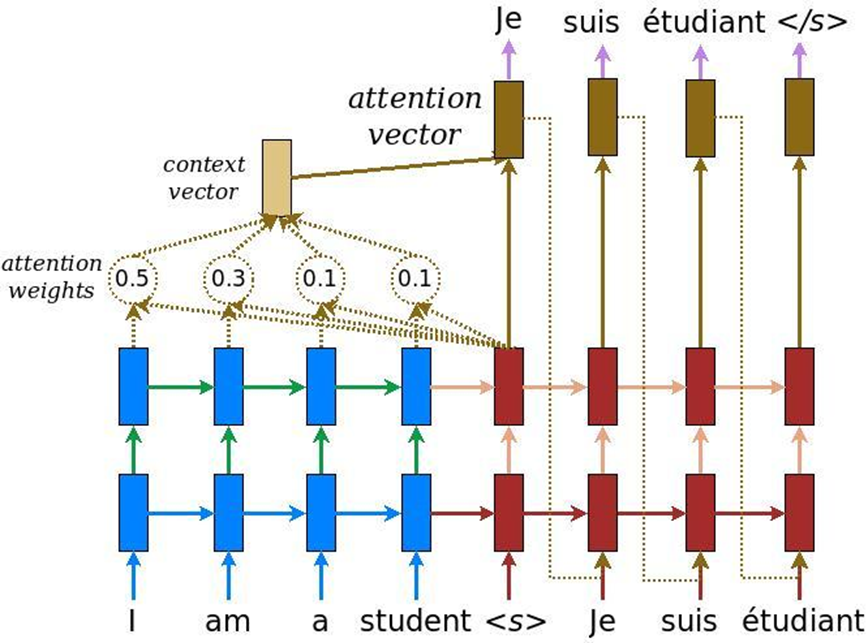
Mas os caras do Google pensaram: por que não usar o mecanismo de atenção sem redes neurais recorrentes - apenas atenção. E eles criaram uma arquitetura chamada transformador (BERT (Representações de codificadores bidirecionais dos transformadores)).
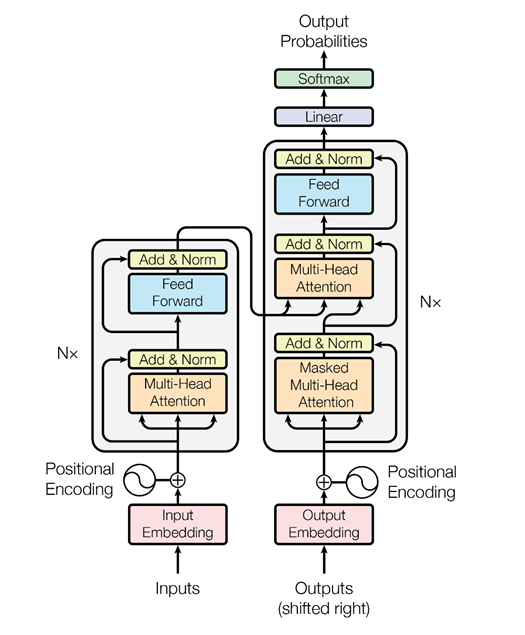
Com base nessa arquitetura, quando há apenas atenção múltipla, foram inventados algoritmos especiais que também podem analisar a relação das palavras nos textos, a relação dos textos entre si - como o ELMo faz, de maneira mais astuta. Em primeiro lugar, é uma rede mais legal e complexa. Em segundo lugar, resolvemos dois problemas simultaneamente, e não um, como no caso da modelagem de linguagem ELMo, previsão. Estamos tentando restaurar palavras ocultas no texto e restaurar links entre textos. Ou seja, digamos: “O programador Vasya adora cerveja. Toda noite ele vai ao bar. Dois textos estão interconectados. “O programador Vasya adora cerveja. Guindastes voam para o sul no outono ”- esses são dois textos não relacionados. Novamente, essas informações podem ser extraídas de textos não alocados, treinado BERT e obter resultados muito interessantes.
Isso foi publicado em novembro passado no artigo "Atenção é tudo o que você precisa", que eu recomendo a leitura. No momento, esse é o resultado mais interessante no campo da análise de texto para solucionar vários problemas: para classificação de texto (reconhecimento de tonalidade, intenções do usuário); para sistemas de perguntas e respostas; para reconhecer entidades nomeadas e assim por diante. Os sistemas de diálogo modernos usam BERT, inserções contextuais pré-treinadas (ELMo ou BERT) para entender o que o usuário deseja. Mas o módulo de gerenciamento de diálogo ainda é frequentemente projetado com base em regras, porque um diálogo específico pode ser muito dependente do assunto ou mesmo da tarefa.