Quando os clusters atingem centenas e, às vezes, milhares de máquinas, surge a questão da consistência dos estados do servidor em relação um ao outro. O algoritmo de consenso distribuído da jangada fornece a garantia de consistência mais rigorosa possível. Neste artigo, consideraremos o Raft do ponto de vista de um engenheiro e tentaremos responder às perguntas "Como?" e "por que?" ele está trabalhando.

Autor do artigo: Dmitry Pavlushin (desenvolvedor Dodo Pizza Engineering).
O Raft é
um algoritmo de consenso distribuído que é necessário para que vários participantes possam decidir em conjunto se um evento ocorreu ou não e o que se seguiu.
Os dados fornecidos pelo cluster Raft são um log que consiste em registros. Quando um usuário deseja alterar os dados armazenados em um cluster, ele tenta adicionar um novo registro ao log com o comando:
Esses comandos são executados por máquinas de estado distribuídas. Por simplicidade e clareza, na estrutura deste artigo, assumiremos que esses registros são fornecidos simplesmente ao ler para um cliente que, com base nos eventos ocorridos, restaura o estado atual do sistema
(consulte Origem do evento) .
Para garantir consenso no Raft, primeiro é selecionado um líder, no qual será responsável pelo gerenciamento do log distribuído. O líder aceita solicitações de clientes e as replica para outros servidores no cluster. Se o líder falhar, um novo líder será selecionado no cluster. Isso ocorre por um tempo em três frases. Detalhes seguirão.
Conceitos básicos
- Estados do servidor No cluster Raft, cada servidor em um determinado momento está em um dos três estados:
- Líder (líder) - processa todas as solicitações do cliente, é a fonte da verdade de todos os dados no log, suporta o log do seguidor.
- O seguidor (seguidor) é um servidor passivo que apenas "escuta" novas entradas de log do líder e redireciona todas as solicitações recebidas dos clientes para o líder. Na verdade, é uma réplica do líder em espera.
- Candidato (candidato) é um estado especial do servidor, possível apenas durante a seleção de um novo líder.
Durante a operação normal em um cluster, apenas um servidor é o líder e o restante são seus seguidores.
Sobre o assincronismoVale a pena notar aqui que condição é um conceito relativo. Devido ao fato de os servidores se comunicarem de forma assíncrona, servidores diferentes podem observar as transições de outros servidores de um estado para outro em momentos diferentes.
- A jangada divide o tempo em segmentos de comprimento arbitrário, chamados prazos . Cada termo tem um número crescente monotonicamente. O termo começa com a eleição de um líder quando um ou mais servidores se tornam candidatos. Se o candidato recebe a maioria dos votos, ele se torna um líder até o final deste período. Se os votos forem divididos e nenhum dos candidatos conseguir a maioria dos votos, um tempo limite é acionado e esse período termina. Depois disso, um novo mandato começa com novos candidatos e eleições. Essa situação é chamada de votação por partes. Um exemplo é ilustrado pelo termo número três no diagrama a seguir:

O número do termo serve como um carimbo de data / hora lógico no cluster Raft. Ajuda os servidores a determinar quais informações são mais relevantes no momento.
Regras e termos de interação do servidor- Cada servidor controla o número do seu termo atual.
- O servidor inclui seu número de expiração em cada mensagem enviada.
- Se o servidor receber uma mensagem com um número de termo menor que o seu, ignorará essa mensagem.
- Se o servidor receber uma mensagem com um número de prazo mais longo que o seu, ele atualizará seu número de prazo para corresponder ao número recebido.
- Se um candidato ou líder recebe uma mensagem com um número de prazo mais longo que o seu, ele entende que outros servidores já iniciaram um novo prazo, e seu prazo não é mais relevante. Portanto, passa do estado atual para o estado “seguidor”, além de atualizar seu número.
- Comunicação do servidor. Os servidores no Raft interagem trocando solicitações e respostas. O algoritmo básico usa apenas dois tipos de chamadas:
- O RequestVote é usado pelos candidatos durante as eleições. A solicitação contém o número do termo do candidato e os metadados sobre o log do candidato, discutidos em mais detalhes abaixo. A resposta contém o número do prazo final do servidor que responde e o valor "true" se o servidor votar no candidato; Falso se o servidor votar contra o candidato.
- AppendEntries é usado pelo líder para replicação de log, bem como para o mecanismo de pulsação. A solicitação contém o número do termo do líder, uma coleção de entradas que precisam ser adicionadas ao log (ou uma coleção vazia no caso de pulsação), alguns metadados sobre o log do líder, também discutidos em mais detalhes abaixo. A resposta contém o número do termo do seguidor e o valor "true" se o seguidor tiver adicionado com êxito entradas ao seu log; “False” se a adição de entradas de log falhar.
Algoritmo de trabalho
1. Escolha um líder
Para determinar quando é hora de iniciar uma nova eleição, o Raft depende dos batimentos cardíacos. O seguidor permanece o seguidor até receber mensagens do líder ou candidato atual. O líder envia periodicamente pulsações para todos os outros servidores.
Se o seguidor não receber nenhuma mensagem por algum tempo, ele naturalmente assumirá que o líder está morto, o que significa que é hora de tomar a iniciativa em suas mãos. Nesse ponto, o ex-seguidor inicia a eleição.
Para iniciar a eleição, o seguidor aumenta seu número de mandato, alterna para o estado "candidato", vota em si mesmo e envia a solicitação "RequestVote" para todos os outros servidores. Depois disso, o candidato aguarda um dos três eventos:
- O candidato recebe a maioria dos votos (incluindo os seus) e vence a eleição. Cada servidor vota apenas uma vez em cada mandato, para que o primeiro candidato seja alcançado (com algumas exceções, discutidas abaixo); portanto, apenas um candidato pode obter a maioria dos votos em um termo específico. O servidor vencedor se torna o líder, começa a enviar pulsação e a atender solicitações de clientes ao cluster.
- O candidato recebe uma mensagem do líder atual do termo atual ou de qualquer servidor com um termo mais antigo . Nesse caso, o candidato entende que as eleições nas quais ele dirige não são mais relevantes. Ele não tem escolha a não ser reconhecer um novo líder / novo termo e entrar em um estado de seguidor.
- Um candidato não recebe a maioria dos votos por um certo tempo limite. Isso pode acontecer quando vários seguidores se tornam candidatos e os votos são divididos entre eles para que nenhum deles obtenha a maioria. Nesse caso, o mandato termina sem um líder e o candidato inicia imediatamente novas eleições para o próximo mandato.
2. Nós replicamos logs
Quando um líder é selecionado, ele é responsável por gerenciar o log distribuído. O líder aceita solicitações de clientes que contêm algumas equipes. O líder coloca em seu log um novo registro contendo o comando e envia "AppendEntries" a todos os seguidores para replicar o registro com o novo registro.
Quando o registro é replicado com sucesso na maioria dos servidores, o líder começa a considerar o registro fechado e responde ao cliente. O líder controla qual é o último registro. Ele envia o número desse registro para AppendEntries (incluindo pulsação) para que os seguidores possam confirmar o registro para si mesmos.
Caso o líder não consiga alcançar alguns seguidores, ele retornará as AppendEntries ao infinito. A figura a seguir mostra como os logs são organizados no cluster Raft:

Cada caixa é uma entrada no log. Cada registro armazena um comando, por exemplo, x ← 3 atribui o valor 3 à chave x. O registro também armazena o número do termo em que foi gerado. Na figura, isso é indicado por um número no topo do quadrado. A exibição em cores dos quadrados também significa o número do termo. Cada registro possui um número de série (índice de log).
3. Garantimos a confiabilidade do algoritmo
Até agora, pelo que examinamos, não está claro como o Raft pode dar pelo menos algumas garantias. No entanto, o algoritmo fornece um conjunto de propriedades que juntas garantem a confiabilidade de sua execução:
- Segurança Eleitoral : não é possível selecionar mais de um líder em um único mandato. Essa propriedade decorre do fato de que cada servidor vota em cada mandato apenas uma vez e, para a formação de um líder, é necessária a maioria dos votos.
- Somente acréscimo de líder: o líder nunca substitui ou apaga, não move entradas em seu log, apenas adiciona novas entradas. Essa propriedade segue diretamente da descrição do algoritmo - a única operação que um líder pode executar com seu log é adicionar entradas ao final. E é isso.
- Correspondência de Log: se os logs de dois servidores contiverem uma entrada com o mesmo número de índice e expiração, os dois logs serão idênticos até e incluindo esse registro.
Prova usando indução matemática e imagensA indução matemática é uma maneira de provar quando o primeiro passo é provar uma afirmação para um caso simples. Na segunda etapa, aceitamos a afirmação verdadeira para alguns casos X. Com base nisso, tentamos provar a afirmação para alguns casos vizinhos X + 1. Juntas, essas duas etapas ajudam a provar a afirmação para todos os casos.
Na nossa situação, um caso simples são logs vazios. Não há registros, portanto, não há nada para violar a propriedade.
Agora vamos tentar assumir que existem algumas entradas nos logs que correspondem à nossa propriedade. O Raft possui um mecanismo que impede a quebra da propriedade quando qualquer log é alterado. Esse mecanismo é chamado de
verificação de consistência . Vejamos os exemplos imediatamente.
Bom exemplo Há um líder, por exemplo, do quarto mandato, há um seguidor. Ambos têm registros correspondentes de três entradas.
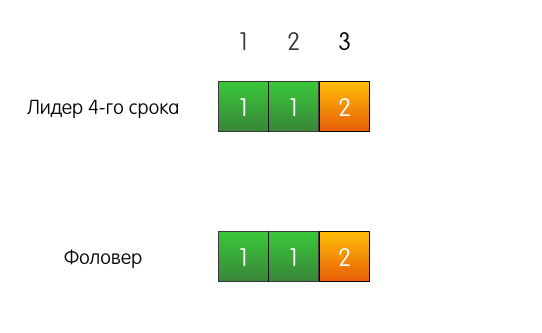
Uma solicitação do cliente chega ao líder, ele adiciona uma entrada ao seu log.

O líder envia AppendEntries para o seguidor. Mas, além do registro mais adicionado, o líder também indica na solicitação que o registro deve ser adicionado no índice 4 e no índice 3, à frente dele, deve haver um registro do termo 2.
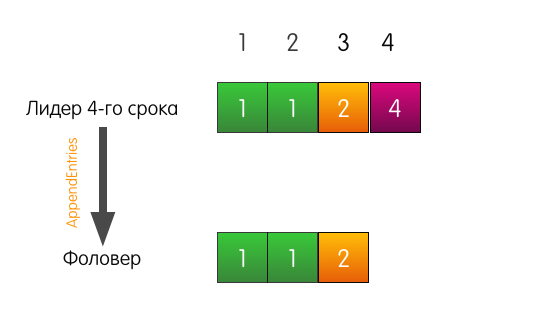
A entrada de log no índice 3 no log do seguidor corresponde à especificada na solicitação; portanto, o seguidor adiciona a entrada ao log e responde com sucesso ao líder. O fim
 Também é um bom exemplo, mas com um começo trágico.
Também é um bom exemplo, mas com um começo trágico. Agora, o registro do seguidor é diferente do registro do líder atual.

Quando o líder recebe uma solicitação para adicionar uma entrada ao log, ele envia as mesmas AppendEntries que no exemplo anterior.

No entanto, desta vez, como o seguidor não corresponde ao registro anterior, o seguidor falha.
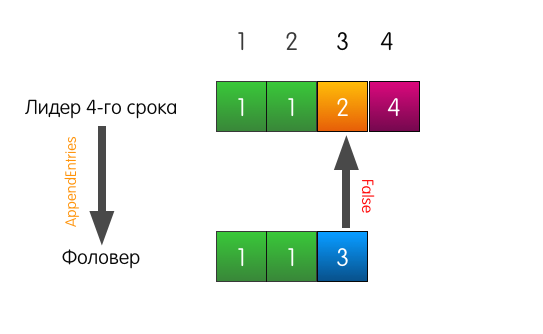
O que o líder faz neste caso? O líder simplesmente retrocede um pouco e tenta alimentar o seguidor com o registro que ele próprio considera no índice 3. Ele também inclui o registro anterior na solicitação.
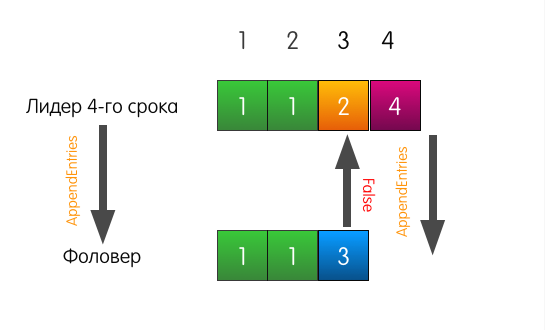
Agora o seguidor responde com sucesso e sobrescreve as entradas em seu log, começando no índice 3.
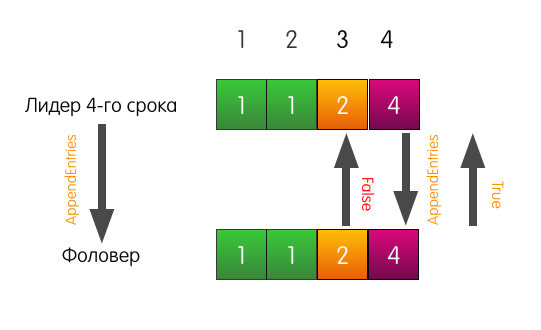
O registro do seguidor pode ser diferente do registro do líder, conforme desejado. Pode não haver entradas suficientes, mas pode haver entradas extras. De qualquer forma, a verificação de consistência garante que os registros dos seguidores, mais cedo ou mais tarde, coincidam com o registro do líder.
- Conclusão do líder : se a entrada do log for confirmada em um determinado momento, os logs dos líderes de todos os períodos subsequentes incluirão esse registro. Esta propriedade fornece garantias de durabilidade.
Prova e ImagensConsidere a seguinte situação: três servidores em um cluster. O servidor S1 é o líder do primeiro mandato atual. Todos os servidores têm três entradas de log.

O líder S1 recebe uma solicitação do cliente e adiciona um novo registro ao seu log, envia AppendEntries para outros servidores S2 e S3.
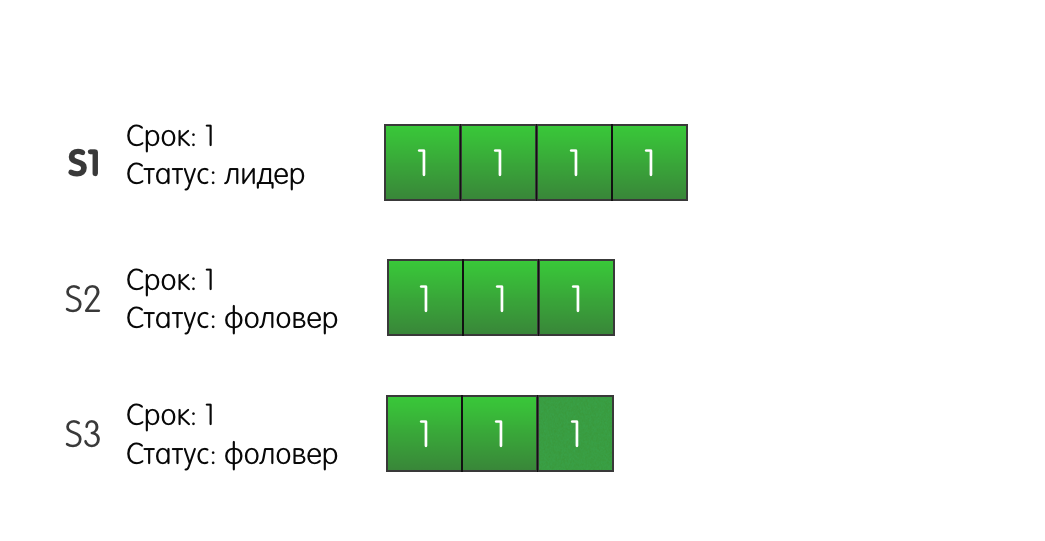
O registro alcança S2 com êxito, mas a rede entre S1 e S3 pisca e a solicitação é perdida. Como o S1 sabe que o registro está presente em dois dos três servidores, ele pode determinar que o registro foi confirmado e responder com êxito ao cliente.
O S1 também tentará adicionar uma entrada ao S3 até que seja bem-sucedida. Mas o que acontece se S1 falhar e desligar? Além disso, o que acontecerá se o S3 for o primeiro a se cansar de esperar e se tornar um candidato? S2 votará a favor, S3 se tornará o líder do segundo mandato e, na próxima solicitação para adicionar um registro, S3 substituirá nosso registro gravado?
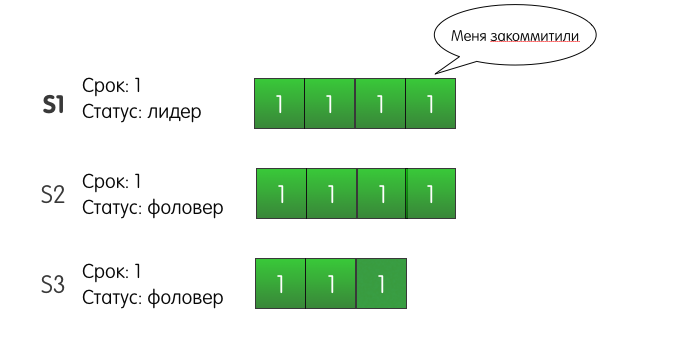
De fato, essa situação não pode acontecer no cluster Raft. O problema aqui é que o S2 não votaria no S3. Porque Como o log do servidor S3 no momento da votação é menos relevante que o log do servidor S2. Esse mecanismo é chamado de
restrição de eleição - o servidor votará em outro servidor apenas se o registro do candidato não for menos relevante que o registro do eleitor.
O Raft compara a relevância dos logs de duas maneiras:
- Número da data do último registro
- Comprimento do registro
Os candidatos incluem esses dois parâmetros na solicitação RequestVote para que os seguidores possam comparar a relevância de seu log com o log do candidato.
"Mais importante" é o log no qual o último registro é mais antigo.

Se os números do termo das últimas entradas coincidirem, o "principal" será o log mais longo.

Se os dois coincidirem, os logs serão igualmente relevantes e também, como segue a propriedade anterior, são absolutamente idênticos.
Acontece que o log do servidor no qual existe um registro protegido sempre será mais relevante do que o log no qual não é. E um servidor que possui um registro seguro não votará em um servidor que não o possui. E como há um registro gravado na maioria dos servidores, um candidato sem esse registro não poderá obter a maioria dos votos e se tornar um líder para remover esse registro de outros servidores.
- Segurança de máquinas de estado : essa propriedade é descrita no original em termos de máquinas de estado distribuídas; em termos de nosso artigo, essa propriedade pode ser descrita da seguinte maneira: quando um servidor confirma um registro com um determinado índice, nenhum outro servidor confirma outro registro para esse índice.
Esta propriedade segue do passado. Se o seguidor confirmar algum registro no índice N, o registro dele será idêntico ao registro do líder até e incluindo N. A propriedade Conclusão do líder garante que todos os líderes subsequentes também contenham esse registro seguro no índice N, o que significa que os seguidores que confirmaram um registro no índice N em períodos subsequentes confirmarão o mesmo valor.
Links para materiais para estudos adicionais