Oi Habr.
Este artigo estará em um formato um pouco "sexta-feira", hoje trataremos da PNL. Não é a PNL sobre quais livros são vendidos em passagens inferiores, mas a que o
Natural Language Processing está processando idiomas naturais. Como exemplo desse processamento, será usada a geração de texto usando uma rede neural. Podemos criar textos em qualquer idioma, do russo ou do inglês ao C ++. Os resultados são muito interessantes, você provavelmente pode adivinhar a partir da imagem.

Para aqueles que estão interessados no que acontece, os resultados e o código fonte estão ocultos.
Preparação de dados
Para o processamento, usaremos uma classe especial de redes neurais - as chamadas redes neurais recorrentes (RNN). Essa rede difere da usual, pois além das células usuais, possui células de memória. Isso nos permite analisar dados de uma estrutura mais complexa e, de fato, mais próxima da memória humana, porque também não iniciamos todos os pensamentos "do zero". Para escrever código, usaremos
redes LSTM (Long Short-Term Memory), uma vez que elas já são suportadas pelo Keras.
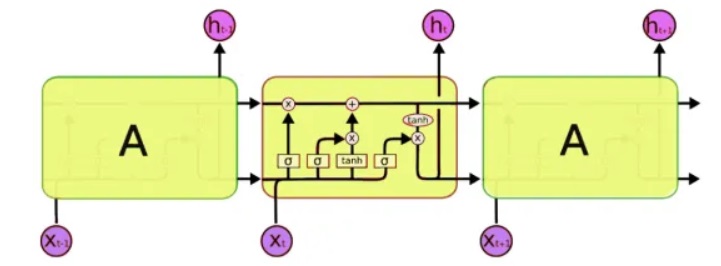
O próximo problema que precisa ser resolvido é, de fato, trabalhar com texto. E aqui há duas abordagens - para enviar símbolos ou as palavras inteiras para a entrada. O princípio da primeira abordagem é simples: o texto é dividido em blocos curtos, onde as "entradas" são um fragmento do texto e a "saída" é o próximo caractere. Por exemplo, para a última frase, 'inputs é um pedaço de texto':
input: output: ""
input: : output: ""
input: : output:""
input: : output: ""
input: : output: "".
E assim por diante Assim, a rede neural recebe fragmentos de texto na entrada e na saída os caracteres que deve formar.
A segunda abordagem é basicamente a mesma, apenas palavras inteiras são usadas em vez de palavras. Primeiro, um dicionário de palavras é compilado e os números são inseridos em vez de palavras na entrada da rede.
Esta, é claro, é uma descrição bastante simplificada. Keras
já tem exemplos de geração de texto, mas, em primeiro lugar, eles não são descritos em detalhes e, em segundo lugar, todos os tutoriais em inglês usam textos bastante abstratos, como Shakespeare, que são difíceis de entender pelo nativo. Bem, estamos testando uma rede neural na nossa grande e poderosa, que, é claro, será mais clara e compreensível.
Treinamento em rede
Como texto de entrada, usei ... os comentários de Habr, o tamanho do arquivo de origem é de 1 MB (na verdade, existem mais comentários, é claro, mas eu tive que usar apenas uma parte; caso contrário, a rede neural teria sido treinada por uma semana e os leitores não teriam visto esse texto até sexta-feira). Deixe-me lembrá-lo de que apenas as letras são alimentadas na entrada de uma rede neural; a rede “não sabe” nada sobre o idioma ou sua estrutura. Vamos começar o treinamento em rede.
5 minutos de treinamento:Até agora, nada está claro, mas você já pode ver algumas combinações reconhecíveis de letras:
. . . «
15 minutos de treinamento:O resultado já é visivelmente melhor:
« » — « » » —Por alguma razão, todos os textos ficaram sem pontos e sem letras maiúsculas, talvez o processamento utf-8 não tenha sido feito corretamente. Mas no geral, isso é impressionante. Analisando e lembrando apenas códigos de símbolos, o programa realmente aprendeu “independentemente” as palavras russas e pode gerar um texto com aparência bastante crível.
Não menos interessante é o fato de o programa memorizar muito bem o estilo do texto. No exemplo a seguir, o texto de alguma lei foi usado como ensino. Tempo de treinamento em rede 5 minutos.
"" , , , , , , , ,
E aqui, as anotações médicas para medicamentos foram usadas como um conjunto de entradas. Tempo de treinamento em rede 5 minutos.
, ,
Aqui vemos frases quase inteiras. Isso se deve ao fato de o texto original ser curto e a rede neural realmente "memorizar" algumas frases como um todo. Esse efeito é chamado de "reciclagem" e deve ser evitado. Idealmente, você precisa testar uma rede neural em grandes conjuntos de dados, mas o treinamento nesse caso pode levar muitas horas e, infelizmente, não tenho um supercomputador extra.
Um exemplo divertido de usar essa rede é a geração de nomes. Depois de enviar uma lista de nomes masculinos e femininos para o arquivo, obtive novas opções bastante interessantes que seriam bastante adequadas para um romance de ficção científica: Rlar, Laaa, Aria, Arera, Aelia, Ninran, Air. Algo neles parece o estilo de Efremov e da Nebulosa de Andrômeda ...
C ++
O interessante é que, em geral, uma rede neural é como lembrar. O próximo passo foi verificar como o programa lida com o código fonte. Como teste, peguei diferentes fontes C ++ e as combinei em um arquivo de texto.
Honestamente, o resultado surpreendeu ainda mais do que no caso da língua russa.
5 minutos de treinamentoPorra, é quase real C ++.
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } }
30 minutos de treinamento void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate);
Como você pode ver, o programa "aprendeu" a escrever funções inteiras. Ao mesmo tempo, separou completamente "humanamente" as funções com um comentário com asteriscos, colocou comentários no código e tudo mais. Gostaria de aprender uma nova linguagem de programação com tanta velocidade ... É claro que há erros no código e, é claro, não será compilado. E, a propósito, eu não formatei o código, o programa também aprendeu a colocar colchetes e recuo "eu mesmo".
Certamente, esses programas não têm o principal
significado - e, portanto, parecem surreais, como se tivessem sido escritos em um sonho, ou não tivessem sido escritos por uma pessoa completamente saudável. No entanto, os resultados são impressionantes. E talvez um estudo mais profundo da geração de textos diferentes ajude a entender melhor algumas das doenças mentais de pacientes reais. A propósito, como sugerido nos comentários, existe uma doença mental na qual uma pessoa fala em um texto gramaticalmente relacionado, mas completamente sem sentido (
esquizofasia ).
Conclusão
As redes neurais recreativas são consideradas muito promissoras, e esse é realmente um grande avanço em comparação com redes "comuns" como a MLP, que não têm memória. De fato, as capacidades das redes neurais para armazenar e processar estruturas bastante complexas são impressionantes. Foi após esses testes que pensei pela primeira vez que Ilon Mask provavelmente estava certo quando escrevi que a IA no futuro poderia ser "o maior risco para a humanidade" - mesmo que uma simples rede neural possa se lembrar e se reproduzir facilmente padrões bastante complexos, o que uma rede de bilhões de componentes pode fazer? Mas, por outro lado, não esqueça que nossa rede neural não pode
pensar , ela se lembra apenas mecanicamente de seqüências de caracteres, sem entender seu significado. Esse é um ponto importante - mesmo se você treinar uma rede neural em um supercomputador e um enorme conjunto de dados, na melhor das hipóteses, ele aprenderá a gerar frases gramaticalmente 100% corretas, mas completamente sem sentido.
Mas não será removido na filosofia, o artigo é ainda mais para os profissionais. Para aqueles que querem experimentar por conta própria, o
código-fonte do Python 3.7 está sob o spoiler. Esse código é uma compilação de vários projetos do github e não é uma amostra do melhor código, mas parece executar sua tarefa.
O uso do programa não requer habilidades de programação, basta saber como instalar o Python. Exemplos de partida na linha de comando:
- Criação e treinamento de modelos e geração de texto:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000
- Somente geração de texto sem treinamento de modelo:
python. \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000 --generate
Acho que acabou sendo um gerador de texto funcional, muito
útil para escrever artigos sobre o Habr . Particularmente interessante é o teste de textos grandes e um grande número de iterações de treinamento; se alguém tiver acesso a computadores rápidos, seria interessante ver os resultados.
Se alguém quiser estudar o tópico com mais detalhes, uma boa descrição do uso da RNN com exemplos detalhados pode ser encontrada em
http://karpathy.imtqy.com/2015/05/05/21/rnn-effectiveness/ .
PS: E, finalmente, alguns versículos;) É interessante notar que tanto a formatação do texto quanto a adição de estrelas não foram feitas por mim, "é ela mesma". O próximo passo é interessante para verificar a possibilidade de pintar e compor músicas. Eu acho que as redes neurais são bastante promissoras aqui.
xxx
para alguns, ser pego em biscoitos - tudo de boa sorte em uma quadra de pão.
e à noite de tamaki
sob uma vela, pegue uma montanha.
xxx
logo filhos mons em petachas no bonde
a luz invisível cheira a alegria
é por isso que eu bato juntos cresce
você não ficará doente por causa de um desconhecido.
coração para arrancar em ogora escalonada
não é tão velho que o cereal está comendo,
Eu guardo a ponte para a bola para roubar.
da mesma maneira que Darina em Doba,
Eu ouço no meu coração de neve na minha mão.
nosso cantar branco quantas dumina suave
Afastei o volume de fera de minério.
xxx
veterinários crucificadores com um feitiço
e derramado sob o esquecido.
e você coloca, como nos galhos de Cuba
brilhe nele.
o divertido em zakoto
com o vôo do leite.
oh você é uma rosa, luz
nuvem de luz na mão:
e rolou no amanhecer
como vai meu cavaleiro!
ele está servindo à noite, não ao osso,
à noite em Tanya a luz azul
como uma espécie de tristeza.E os últimos versos em aprender pelo modo palavra. Aqui a rima desapareceu, mas algum significado apareceu (?).
e você, da chama
as estrelas.
falou com indivíduos distantes.
preocupa você rus ,, você ,, amanhã.
"Pomba chuva,
e lar dos assassinos,
para a princesa menina
o rosto dele.
xxx
oh pastor, acene as câmaras
em um bosque na primavera.
Estou atravessando o coração da casa para a lagoa
e ratos alegres
Sinos de Nizhny Novgorod.
mas não temas, o vento da manhã,
com um caminho, com um taco de ferro,
e pensei com a ostra
abrigado em uma lagoa
em rakit empobrecido.