
Muitos aplicativos de rede consistem em um servidor Web que processa tráfego em tempo real e um manipulador adicional que é executado em segundo plano de forma assíncrona. Há muitas ótimas dicas para verificar o status do tráfego e a comunidade não para de desenvolver ferramentas como o Prometheus que ajudam na avaliação. Mas os manipuladores às vezes não são menos - e ainda mais - importantes. Eles também precisam de atenção e avaliação, mas há pouca orientação sobre como fazer isso, evitando armadilhas comuns.
Este artigo é dedicado aos traps mais comuns no processo de avaliação de manipuladores assíncronos, usando um exemplo de um incidente em um ambiente de produção em que, mesmo com métricas, era impossível determinar exatamente o que os manipuladores estavam fazendo. O uso de métricas mudou tanto o foco que as próprias métricas mentiram abertamente, dizem eles, seus manipuladores para o inferno.
Veremos como usar métricas de forma a fornecer uma avaliação precisa e, no final , mostraremos a implementação de referência do prometheus-client-tracer de código aberto, que você pode usar em seus aplicativos.
Incidente
Os alertas chegaram a uma velocidade de metralhadora: o número de erros de HTTP aumentou bastante, e os painéis de controle confirmaram que as filas de solicitações estavam crescendo e o tempo de resposta estava acabando. Cerca de 2 minutos depois, as filas foram limpas e tudo voltou ao normal.
Após uma inspeção mais minuciosa, verificou-se que nossos servidores de API estavam em pé, aguardando uma resposta do banco de dados, o que causou a interrupção e subitamente aumentou toda a atividade. E quando você considera que a carga mais pesada cai com mais frequência no nível dos processadores assíncronos, eles se tornam os principais suspeitos. A questão lógica era: o que eles estão fazendo ali ?!
A métrica Prometheus mostra o que o processo leva tempo, aqui está:
# HELP job_worked_seconds_total Sum of the time spent processing each job class # TYPE job_worked_seconds_total counter job_worked_seconds_total{job}
Ao rastrear o tempo total de execução de cada tarefa e a frequência com que a métrica é alterada, descobriremos quanto tempo de trabalho foi gasto. Se por um período de 15 segundos. o número aumentou em 15, isso implica em 1 manipulador ocupado (um segundo para cada segundo passado), enquanto um aumento de 30 significa 2 manipuladores, etc.
Um horário de trabalho durante o incidente mostrará o que estamos enfrentando. Os resultados são decepcionantes; a hora do incidente (16: 02-16: 04) é marcada pela linha vermelha alarmante:

Atividade do manipulador durante o incidente: uma lacuna visível é visível.
Foi doloroso para mim, como pessoa que estava debugando após esse pesadelo, ver que a curva de atividade estava no fundo exatamente durante o incidente. É o momento de trabalhar com ganchos da Web, nos quais temos 20 manipuladores dedicados. Pelos registros, sei que eles estavam todos em atividade, e esperava que a curva fosse em cerca de 20 segundos, e vi uma linha quase reta. Além disso, vê este grande pico azul às 16:05? A julgar pela programação, 20 processadores single-threaded passaram 45 segundos. para cada segundo de atividade, mas isso é possível ?!
Onde e o que deu errado?
A programação do incidente é mentira: oculta a atividade de trabalho e, ao mesmo tempo, mostra o supérfluo - dependendo de onde medir. Para descobrir por que isso acontece, é necessário levar em consideração a implementação do rastreamento de métricas e como ele interage com o Prometheus coletando métricas.
Começando com a maneira como os manipuladores coletam métricas, é possível esboçar um esquema de implementação aproximado do fluxo de trabalho (veja abaixo). Nota: os manipuladores atualizam apenas as métricas após a conclusão de uma tarefa .
class Worker JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) def work job = acquire_job start = Time.monotonic_now job.run ensure # run after our main method block duration = Time.monotonic_now - start JobWorkedSecondsTotal.increment(by: duration, labels: { job: job.class }) end end
O Prometheus (com sua filosofia de extrair métricas) envia uma solicitação GET para cada manipulador a cada 15 segundos, registrando os valores das métricas no momento da solicitação. Os manipuladores atualizam constantemente as métricas das tarefas concluídas e, com o tempo, podemos exibir graficamente a dinâmica das alterações nos valores.
O problema com sub e reavaliação começa a aparecer sempre que o tempo necessário para concluir uma tarefa excede o tempo de espera de uma solicitação que chega a cada 15 segundos. Por exemplo, uma tarefa inicia 5 segundos antes da solicitação e termina 1 segundo depois. Total e geralmente dura 6 segundos, mas esse tempo é visível apenas ao estimar os custos de tempo feitos após a solicitação, enquanto 5 desses 6 segundos foram gastos antes da solicitação.
Os indicadores ficam ainda mais sem Deus, se as tarefas demorarem mais que o período do relatório (15 segundos). Durante a execução da tarefa por 1 minuto, o Prometheus terá tempo para enviar 4 solicitações aos processadores, mas a métrica será atualizada somente após a quarta.
Após traçar uma linha do tempo da atividade de trabalho, veremos como o momento em que a métrica é atualizada afeta o que Prometheus vê. No diagrama abaixo, dividimos a linha do tempo de dois manipuladores em vários segmentos que exibem tarefas de diferentes durações. As etiquetas vermelhas (15 segundos) e azuis (30 segundos) indicam 2 amostras de dados do Prometheus; As tarefas que serviram como fonte de dados para a avaliação são destacadas em cores, respectivamente.
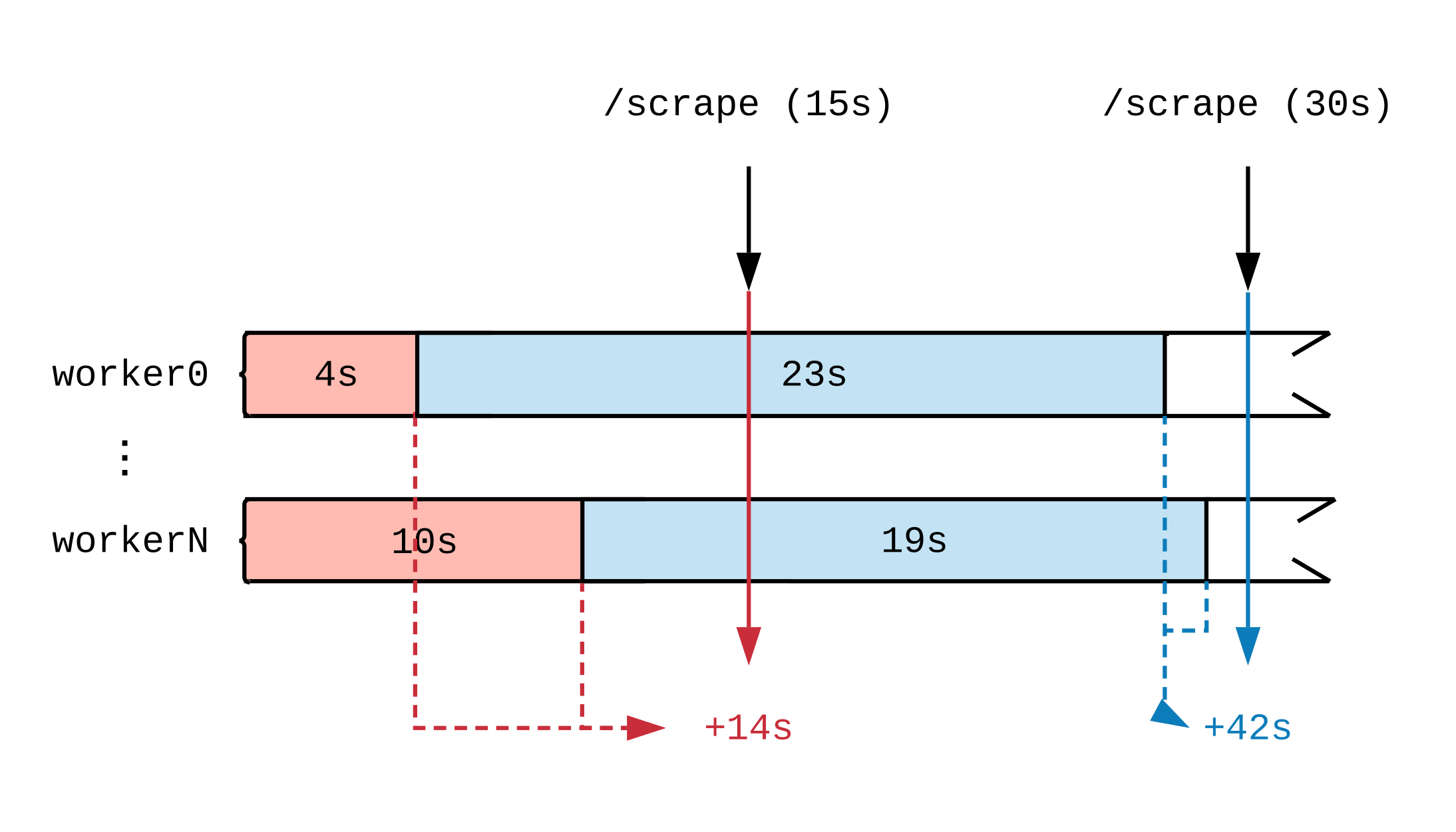
Independentemente do que os manipuladores estejam fazendo a plena carga, eles farão 30 segundos de trabalho a cada intervalo de 15 segundos. Como Prometheus não vê o trabalho até que seja concluído, a julgar pelas métricas, 14 segundos de trabalho foram concluídos no primeiro intervalo de tempo e 42 segundos no segundo. Se cada manipulador realizar uma tarefa volumosa, mesmo depois de algumas horas, até o final, não veremos relatos de que o trabalho está em andamento.
Para demonstrar esse efeito, conduzi um experimento com dez manipuladores envolvidos em tarefas cuja duração é diferente e semi-normal distribuída entre 0,1 segundos e um valor ligeiramente mais alto (consulte tarefas aleatórias ). Abaixo estão 3 gráficos representando a atividade de trabalho; a duração é mostrada em ordem crescente.
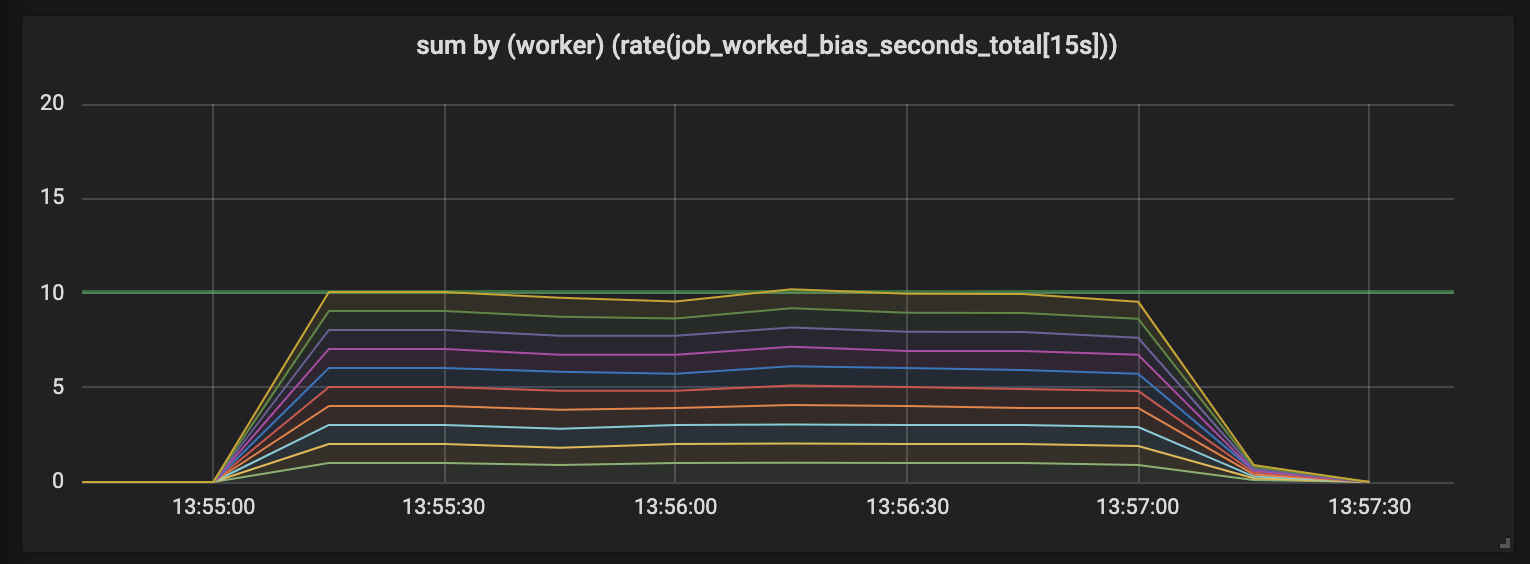
Tarefas com duração de até 1 segundo.
O primeiro gráfico mostra que cada manipulador realiza cerca de 1 segundo de trabalho a cada segundo - isso é visível em linhas planas e a quantidade total de trabalho é igual às nossas capacidades (10 manipuladores distribuem um segundo de trabalho por segundo de tempo). Na verdade, estamos esperando isso, independentemente da duração da tarefa: tanto em tarefas curtas quanto longas, os processadores com carga constante devem ceder.
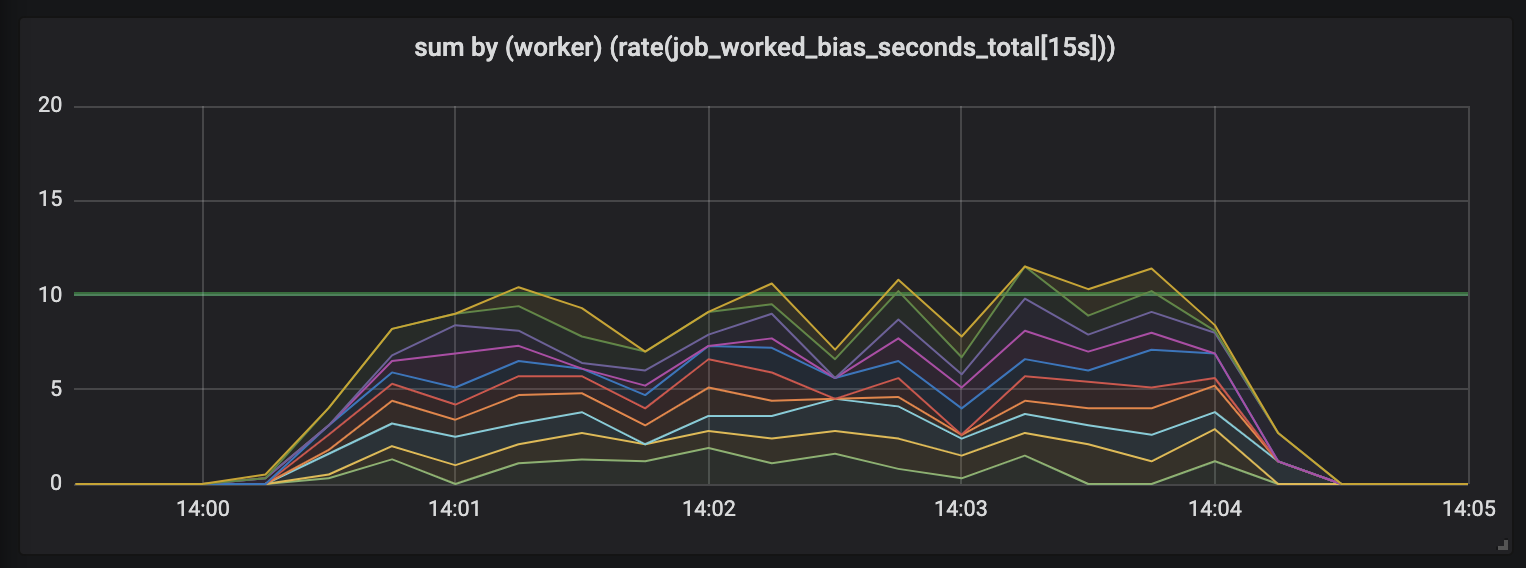
Tarefas com duração de até 15 segundos.
A duração das tarefas aumenta e uma bagunça aparece no cronograma: ainda temos 10 processadores, todos eles totalmente ocupados, mas a quantidade total de trabalho pula - menor ou maior que a borda da capacidade útil (10 segundos).
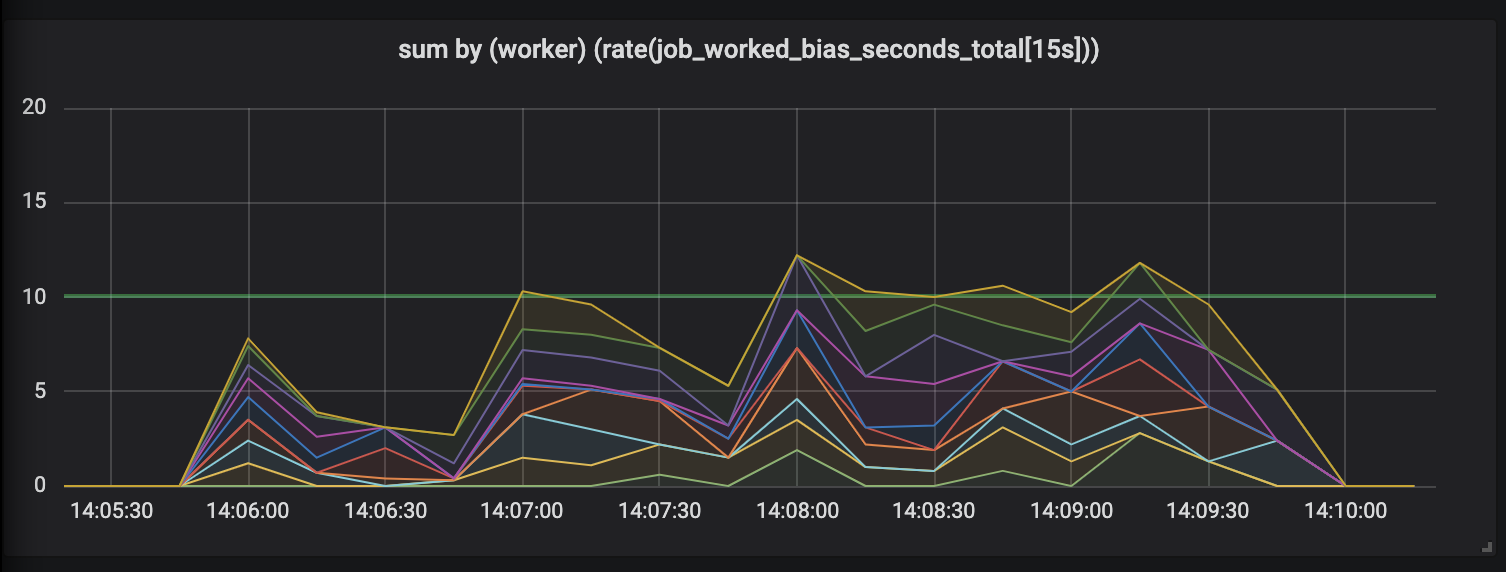
Tarefas com duração de até 30 segundos.
A avaliação de trabalhos com duração de até 30 segundos é simplesmente ridícula. Uma métrica com limite de tempo mostra atividade zero para as tarefas mais longas e, somente quando as tarefas são concluídas, gera picos de atividade.
Restaurar Confiança
Isso não foi suficiente para nós, portanto, há outro problema, muito mais insidioso, com essas tarefas de longo prazo que estragam nossas métricas. Sempre que uma tarefa de longo prazo é concluída - por exemplo, se o Kubernetes joga um pod de um pool ou quando um nó morre -, o que acontece com as métricas? Vale a pena atualizá-los imediatamente após a conclusão da tarefa, pois eles mostram que não fizeram o trabalho.
Métricas não devem mentir. O laptop uiva incrédulo, causando horror existencial e ferramentas de vigilância que distorcem a imagem do mundo são uma armadilha e são inadequadas para o trabalho.
Felizmente, o assunto é corrigível. A distorção dos dados ocorre porque o Prometheus faz medições independentemente de quando os processadores atualizam as métricas. Se pedirmos aos manipuladores que atualizem as métricas quando o Prometheus enviar solicitações, veremos que o Prometheus não é mais peculiar e mostra a atividade atual.
Apresentando ... Tracer
Uma solução para o problema de métricas distorcidas é Tracer projetada de maneira abstrata Tracer , que avalia a atividade em tarefas de longa execução, atualizando gradualmente as métricas relacionadas ao Prometheus.
class Tracer def trace(metric, labels, &block) ... end def collect(traces = @traces) ... end end
Os rastreadores fornecem um método de rastreamento que leva as métricas do Prometheus e a tarefa a rastrear. O comando trace irá executar o bloco fornecido (funções Ruby anônimas) e garante que as solicitações para tracer.collect durante a execução atualizem as métricas relacionadas de forma incremental, independentemente do tempo decorrido desde a última solicitação de collect .
Precisamos conectar o tracer aos manipuladores para rastrear a duração da tarefa e o terminal que atende às solicitações métricas do Prometheus. Começamos com os manipuladores, inicializamos um novo rastreador e pedimos que ele rastreie a execução do acquire_job.run .
class Worker def initialize @tracer = Tracer.new(self) end def work @tracer.trace(JobWorkedSecondsTotal, labels) { acquire_job.run } end # Tell the tracer to flush (incremental) trace progress to metrics def collect @tracer.collect end end
Nesse estágio, o rastreador atualizará apenas as métricas em segundos gastos na tarefa concluída - como fizemos na implementação inicial das métricas. Devemos pedir ao rastreador para atualizar nossas métricas antes de executar uma solicitação do Prometheus. Isso pode ser feito configurando o rack de middleware.
# config.ru # https://rack.imtqy.com/ class WorkerCollector def initialize(@app, workers: @workers); end def call(env) workers.each(&:collect) @app.call(env) # call Prometheus::Exporter end end # Rack middleware DSL workers = start_workers # Array[Worker] # Run the collector before serving metrics use WorkerCollector, workers: workers use Prometheus::Middleware::Exporter
Rack é uma interface para servidores Web Ruby que permite combinar vários manipuladores de rack em um único terminal. O comando config.ru determina que o aplicativo Rack - sempre que receber a solicitação - envia o comando de collect aos manipuladores primeiro e só então diz ao cliente Prometheus para desenhar os resultados da coleção.
Quanto ao nosso gráfico, atualizamos as métricas sempre que a tarefa é concluída ou quando recebemos uma solicitação de métricas. As tarefas que possuem várias consultas enviam igualmente dados em todos os segmentos: conforme mostrado pelas tarefas cuja duração foi dividida em intervalos de 15 segundos.

É melhor?
O uso do rastreador 24 horas por dia afeta o registro da atividade. Diferentemente das medições iniciais, que mostraram uma "serra", quando o número de picos excedeu o número de processadores acionados e períodos de silêncio aborrecido, o experimento com dez processadores fornece um gráfico mostrando claramente que cada processador é colocado no trabalho sendo monitorado uniformemente.

Métricas construídas na comparação (esquerda) e controladas pelo traçador (direita), tiradas de um experimento de trabalho.
Comparadas com o cronograma francamente impreciso e caótico das medições iniciais, as métricas coletadas pelo rastreador são suaves e consistentes. Agora, não apenas vinculamos o trabalho com precisão a cada solicitação de métrica, mas também não nos preocupamos com a morte súbita de qualquer um dos manipuladores: o Prometheus registra as métricas até que o manipulador desapareça, avaliando todo o seu trabalho.
Isso pode ser usado?
Sim A interface do Tracer provou ser útil para mim em muitos projetos, então essa é uma gema Ruby separada, prometheus-client-tracer . Se você usar o cliente Prometheus em seus aplicativos Ruby, basta adicionar o prometheus-client-tracer ao seu Gemfile:
require "prometheus/client" require "prometheus/client/tracer" JobWorkedSecondsTotal = Prometheus::Client::Counter.new(...) Prometheus::Client.trace(JobWorkedSecondsTotal) do sleep(long_time) end
Se isso lhe for útil e se você deseja que o cliente oficial do Prometheus Ruby apareça no Tracer , deixe um comentário no client_ruby # 135 .
E finalmente, alguns pensamentos
Espero que isso ajude outras pessoas a coletar métricas de maneira mais consciente para tarefas de longa duração e resolver um dos problemas comuns. Não se engane, ele está associado não apenas ao processamento assíncrono: se suas solicitações HTTP forem mais lentas, elas também se beneficiarão do uso do rastreador ao avaliar o tempo gasto no processamento.
Como sempre, quaisquer comentários e correções são bem-vindos: escreva no Twitter ou abra um PR . Se você deseja contribuir com a gema tracer, o código fonte está em prometheus-client-tracer-ruby .