Olá Habr! Nossos amigos da Softpoint prepararam um artigo interessante sobre o Microsoft SQL Server. Ele analisa dois exemplos práticos de uso da pesquisa de texto completo:
- Pesquise em linhas “infinitas” (por exemplo, Comentários) em oposição a uma pesquisa regular através do LIKE;
- Pesquise por números de documentos com prefixos. Onde geralmente a pesquisa de texto completo não pode ser usada: prefixos constantes interferem nela. Duas abordagens são analisadas: pré-processando o número do documento e adicionando seu próprio separador de palavras da biblioteca.
Inscreva-se agora!
 Dou a palavra ao autor
Dou a palavra ao autorUma pesquisa eficaz em gigabytes de dados acumulados é uma espécie de "santo graal" dos sistemas de contabilidade. Todo mundo quer encontrá-lo e obter glória imortal, mas no processo de procurar repetidas vezes, verifica-se que não existe uma solução milagrosa.
A situação é complicada pelo fato de os usuários geralmente quererem procurar uma substring - em algum lugar, o número do contrato desejado é "enterrado" no meio do comentário; em algum lugar, o operador não lembra exatamente o nome do cliente, mas lembra que o nome dele é "Alexey Evgrafovich"; em algum lugar, basta omitir a forma recorrente de propriedade do BYUBL e pesquisar imediatamente pelo nome da organização. Para DBMSs relacionais clássicos, essa pesquisa é uma notícia muito ruim. Na maioria das vezes, essa pesquisa de substring é reduzida à rolagem metódica de cada linha da tabela. Não é a estratégia mais eficaz, especialmente se o tamanho da tabela aumentar para várias dezenas de gigabytes.
Em busca de uma alternativa, lembro-me frequentemente da "pesquisa de texto completo". A alegria de encontrar uma solução geralmente passa rapidamente após uma revisão superficial da prática existente. Acontece rapidamente que, de acordo com a opinião popular, a pesquisa de texto completo:
- Difícil de configurar
- Atualizado lentamente
- Trava o sistema ao atualizar
- Tem algum tipo de sintaxe incomum
estúpida - Não encontra o que eles pedem
O conjunto de mitos pode ser continuado por um longo tempo, mas mesmo Platão nos ensinou a ser céticos e a não aceitar cegamente a opinião de alguém sobre a fé. Vamos ver se o diabo é tão terrível quanto ele é pintado?
E, embora não estejamos profundamente imersos no estudo,
concordaremos imediatamente com uma condição importante . O mecanismo de pesquisa de texto completo pode fazer muito mais do que uma pesquisa de string comum. Por exemplo, você pode definir um dicionário de sinônimos e usar a palavra "contato" para encontrar "telefone". Ou pesquise palavras sem considerar a forma e os finais. Essas opções podem ser muito úteis para os usuários, mas neste artigo consideramos a pesquisa de texto completo apenas como uma alternativa à pesquisa de linha clássica. Ou seja,
procuraremos apenas a substring que será especificada na barra de pesquisa , sem levar em conta sinônimos, sem trazer palavras para a forma "normal" e outras magias.
Como funciona a pesquisa de texto completo do MS SQL
A funcionalidade de pesquisa de texto completo no MS SQL foi parcialmente removida do serviço DBMS principal (próximo ao final do artigo, veremos por que isso pode ser extremamente útil). Para a pesquisa, um índice especial é formado com sua estrutura, diferente das árvores balanceadas usuais.
É importante que, para criar um índice de pesquisa de texto completo, seja necessário que exista um índice exclusivo na tabela de chaves, consistindo em apenas uma coluna - é a pesquisa de texto completo que será usada para identificar as linhas da tabela. Freqüentemente, a tabela já possui esse índice na Chave Primária, mas às vezes precisará ser criada adicionalmente.
O índice de pesquisa de texto completo é preenchido de forma assíncrona e fora de transação. Após alterar uma linha da tabela, ela é colocada na fila para processamento. O processo de atualização do índice recebe da linha da tabela (linha) todos os valores da string "subscritos" no índice e os divide em palavras separadas. Depois disso, as palavras podem ser reduzidas a um determinado formulário "padrão" (por exemplo, sem finais), para que seja mais fácil pesquisar por formulários de palavras. "Stop words" são jogadas fora (preposições, artigos e outras palavras que não têm significado). As correspondências restantes do link palavra a sequência são gravadas no índice de pesquisa de texto completo.
Acontece que cada coluna da tabela incluída no índice passa por esse pipeline:
Linha longa -> quebra de palavras -> conjunto de partes (palavras) -> stemmer -> palavras normalizadas -> [opcional] exceção de palavra de parada -> gravação no índice
Como mencionado, o processo de atualização do índice é assíncrono. Segue-se disso:
- A atualização não bloqueia ações do usuário
- A atualização aguarda a conclusão da transação de alteração de linha e começa a aplicar as alterações antes da confirmação
- Alterações no índice de texto completo são aplicadas com algum atraso em relação à transação principal. Ou seja, entre adicionar uma linha e o momento em que ela pode ser encontrada, haverá um atraso, dependendo do tamanho da fila de atualização do índice
- O número de elementos contidos no índice pode ser monitorado pela consulta:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
Testes práticos. Pesquisa física pessoas por nome
Preenchendo a tabela com dados
Para experimentos, criaremos uma nova base vazia com uma tabela onde as “contrapartes” serão armazenadas. Dentro do campo "descrição", haverá uma linha com o nome do contrato, onde o nome da contraparte será mencionado. Algo assim:
"Contrato com Borovik Demyan Emelyanovich"
Ou então:
Cão. com Borovik-Romanov Anatoly Avdeevich "
Sim, quero me afastar imediatamente dessa "arquitetura", mas, infelizmente, essa aplicação de "comentários" ou "descrições" geralmente está entre os usuários corporativos.
Além disso, adicionamos alguns campos “para peso”: se houver apenas 2 colunas na tabela, uma simples varredura irá lê-lo em alguns momentos. Precisamos "inflar" a tabela para que a verificação seja longa. Isso nos aproxima de casos reais de negócios: não apenas armazenamos a "descrição" na tabela, mas também muitas outras informações úteis [do diabo].
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
A próxima pergunta é onde obter tantos sobrenomes, nomes e patronímicos exclusivos? Eu, de acordo com um velho hábito, agia como um estudante russo normal, ou seja, foi para a wikipedia:
- Nomes retirados da página Categoria: Nomes masculinos russos
- Reescrever manualmente nomes do meio a partir de nomes, alterando finais
- Com sobrenomes, acabou sendo um pouco mais complicado. No final, foi encontrada a categoria "namesakes". Um pouco de xamanismo com Python e em uma tabela separada resultou em 46,5 mil nomes. (um script para baixar sobrenomes está disponível aqui)
Obviamente, houve variações estranhas entre os sobrenomes, mas, para os propósitos do estudo, isso foi bastante aceitável.
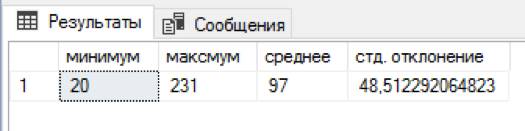
Eu escrevi um script sql que anexa um número aleatório de nomes e nomes patronímicos a cada sobrenome. 5 minutos de espera e em uma mesa separada já havia 4,5 milhões de combinações. Nada mal! Para cada sobrenome havia de 20 a 231 combinações do nome + nome do meio, foram obtidas, em média, 97 combinações. A distribuição por nome e patronímico acabou sendo levemente tendenciosa "para a esquerda", mas parecia redundante criar um algoritmo mais equilibrado.
Os dados são preparados, podemos começar nossos experimentos.
Configuração de pesquisa de texto completo
Crie um índice de texto completo no nível do MS SQL. Primeiro, precisamos criar um repositório para esse índice - um catálogo de texto completo.
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
Existe um catálogo, estamos tentando adicionar um índice de texto completo para a nossa tabela ... e nada funciona.
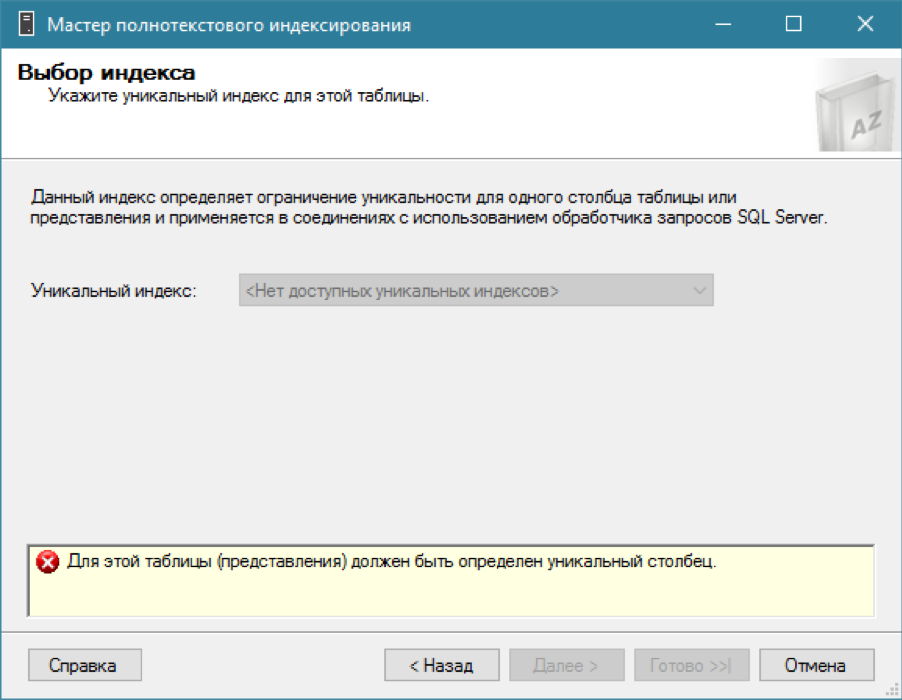
Como eu disse, para um índice de texto completo, você precisa de um índice regular com uma coluna única. Lembramos que já temos o campo obrigatório - um ID de identificador exclusivo. Vamos criar um índice de cluster exclusivo nele (embora um não clusterizado seja suficiente):
create unique clustered index ndx1 on partners (id)
Depois de criar um novo índice, podemos finalmente adicionar o índice de pesquisa de texto completo. Vamos esperar alguns minutos até que o índice esteja cheio (lembre-se de que ele é atualizado de forma assíncrona!). Você pode prosseguir para os testes.
Teste
Vamos começar com o cenário mais simples, próximo à aplicação real da pesquisa. Simulamos uma "exibição de lista" - uma seleção de janela de 45 linhas com seleção por máscara de pesquisa. Executamos a solicitação com um novo índice de texto completo, observamos o tempo - 0 segundos - excelente!
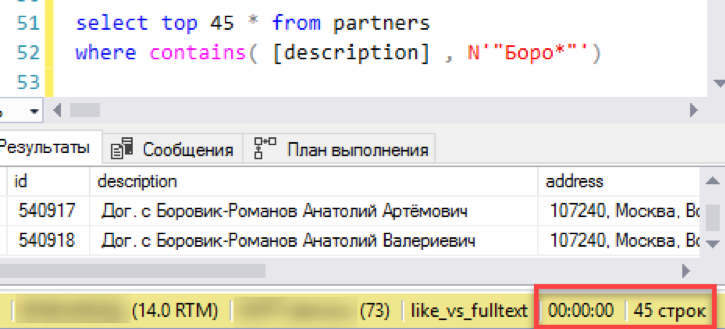
Agora, uma pesquisa antiga e comprovada por "curtir". Demorou 3 segundos para formar o resultado. Não é tão ruim, a derrota total não funcionou. Talvez não faça sentido configurar uma pesquisa de texto completo - tudo funciona bem?
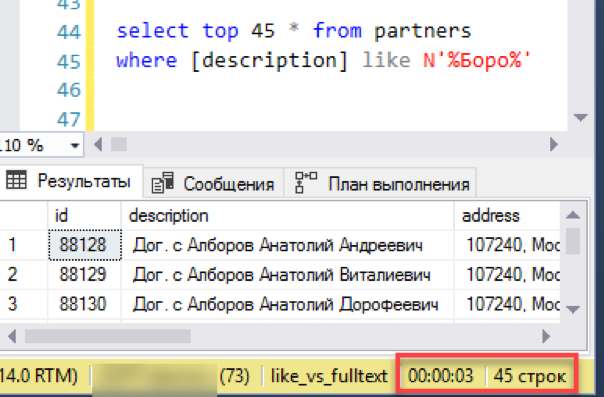
De fato, perdemos um detalhe importante: a solicitação foi executada sem classificação. Em primeiro lugar, essa consulta combinada com "selecionando os primeiros N registros" retorna um resultado injustificado. Cada partida pode retornar registros N aleatórios e não há garantia de que duas partidas consecutivas fornecerão o mesmo conjunto de dados. Em segundo lugar, se estamos falando de "visualizar a lista com uma janela deslizante" - geralmente essa mesma "janela" é classificada por qualquer coluna, por exemplo, por nome. Afinal, o operador precisa saber o que obterá quando passar para a próxima "janela".
Corrija o experimento. Adicione a classificação, digamos, pelo número de telefone:
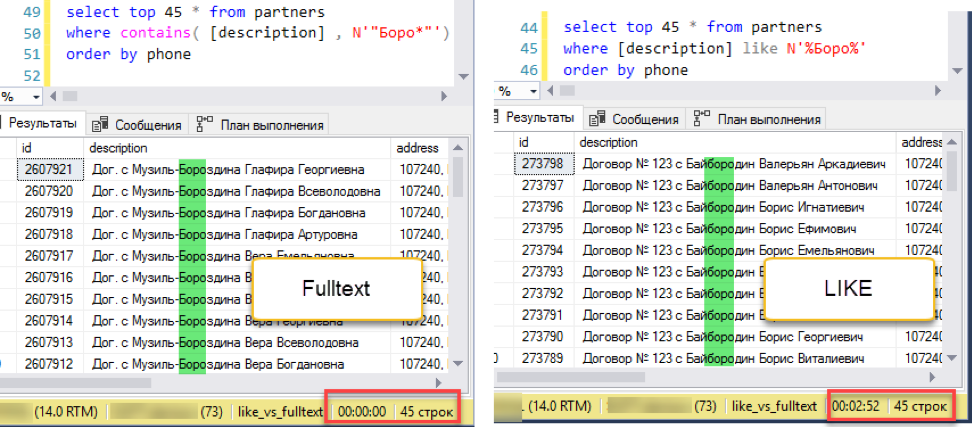 A pesquisa de texto completo vence com uma pontuação ensurdecedora: 0 segundos versus 172 segundos!
A pesquisa de texto completo vence com uma pontuação ensurdecedora: 0 segundos versus 172 segundos!Se você observar os planos de consulta, fica claro por que isso acontece. Devido à adição de pedidos ao texto da consulta, uma operação de classificação apareceu durante a execução. Essa é a chamada operação de "bloqueio", que não pode concluir a solicitação até receber toda a quantidade de dados para classificação. Não podemos coletar os primeiros 45 registros que temos, precisamos ordenar todo o conjunto de dados.
E no estágio de obtenção de dados para classificação, ocorre uma diferença dramática. Uma pesquisa com "curtir" precisa navegar por toda a tabela disponível. Isso leva 172 segundos. Mas a pesquisa de texto completo tem sua própria estrutura otimizada, que retorna imediatamente os links para todas as entradas necessárias.
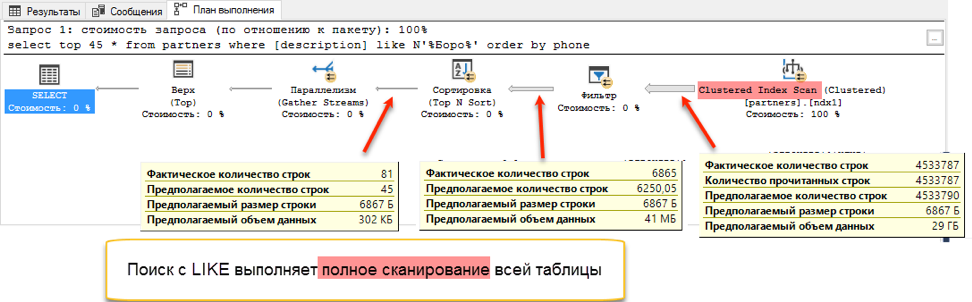
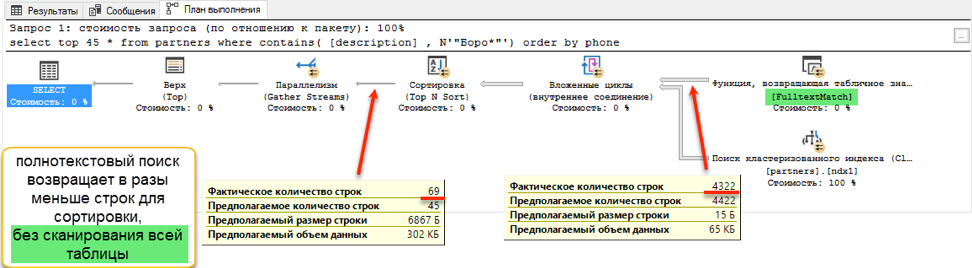
Mas deve haver uma mosca na pomada? Existe um. Conforme declarado no início, uma pesquisa em texto completo só pode pesquisar a partir do início de uma palavra. E se quisermos encontrar "Ivan Poddubny" pela substring "* oak *", uma pesquisa em texto completo não mostrará nada de útil.
Felizmente, para pesquisar por nome, esse não é o cenário mais popular.
Pesquise um documento por número
Vamos tentar algo mais complicado. O segundo caso de uso popular para pesquisa é encontrar um documento por parte de seu número. Além disso, muitas vezes o número do documento consiste em duas partes: o prefixo da letra e o número real contendo zeros à esquerda.
Não há espaços ou caracteres de serviço entre essas partes. Ao mesmo tempo, pesquisar pelo número inteiro é monstruosamente inconveniente - você precisa lembrar quantos zeros à esquerda após o prefixo devem estar antes do início da parte significativa. Acontece que a pesquisa de texto completo "pronta para uso" é simplesmente inútil nesse cenário. Vamos tentar consertar isso.
Para o teste, criei uma nova tabela chamada document, na qual adicionei 13,5 milhões de registros com números exclusivos do tipo "ORG". A numeração foi ordenada, todos os números começaram com "ORG". Você pode começar.
Pré-dividindo um número
A pesquisa de texto completo pode pesquisar palavras com eficiência. Bem, vamos ajudá-lo e dividir o número "desconfortável" em palavras convenientes com antecedência. O plano de ação é o seguinte:
- Adicione uma coluna adicional à tabela de origem onde o número especialmente convertido será armazenado
- Adicione um gatilho que, ao alterar o número, o divida em várias partes pequenas, separadas por um espaço
- A pesquisa de texto completo já sabe como dividir uma sequência em partes por espaços, para indexar nosso número modificado sem problemas
Vamos ver como isso vai funcionar.
Adicione uma coluna adicional à tabela.
alter table document add number_parts nvarchar(128) not null default ''
Um gatilho que preenche uma nova coluna pode ser escrito "testa", ignorando possíveis duplicatas (quantos triplos repetidos estão no número "0000012"?) E você pode adicionar um pouco de mágica em XML e gravar apenas partes únicas. A primeira implementação será mais rápida, a segunda fornecerá um resultado mais compacto. De fato, a escolha é entre velocidade de gravação e velocidade de leitura, escolha o que é mais importante em sua situação. Agora basta passar por um
script que processa os números existentes.
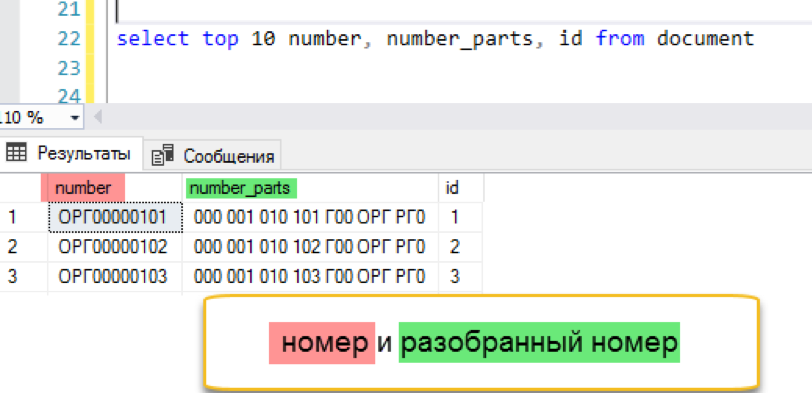
Adicionar índice de texto completo
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
E verifique o resultado. O experimento é o mesmo - modelando uma seleção de "janela" a partir de uma lista de documentos. Não repetimos os erros anteriores e executamos imediatamente a solicitação com classificação, neste caso por data.
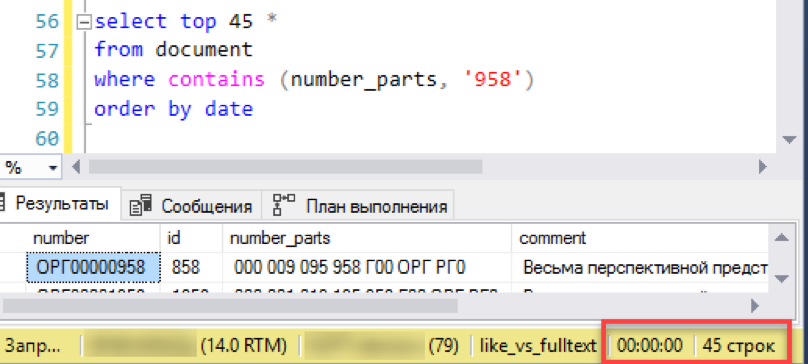
Isso funciona! Agora vamos tentar um número mais autêntico:
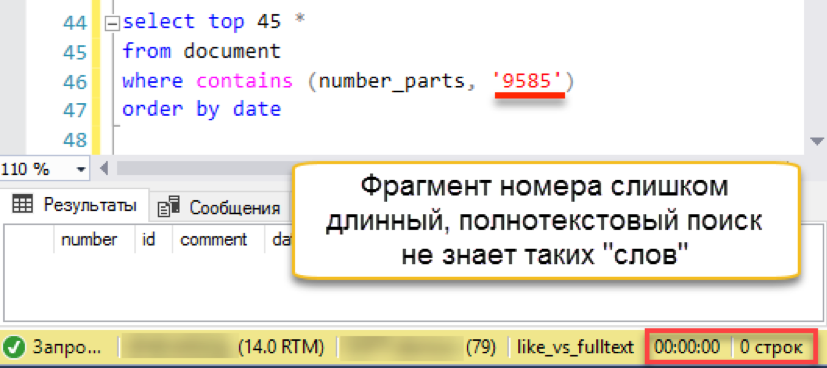
E então uma falha de ignição acontece. O comprimento da string de pesquisa é maior que o comprimento das "palavras" armazenadas. De fato, o banco de dados de pesquisa simplesmente não possui uma única linha de 4 caracteres, portanto, honestamente, retorna um resultado vazio. Teremos que dividir a sequência de pesquisa em partes:
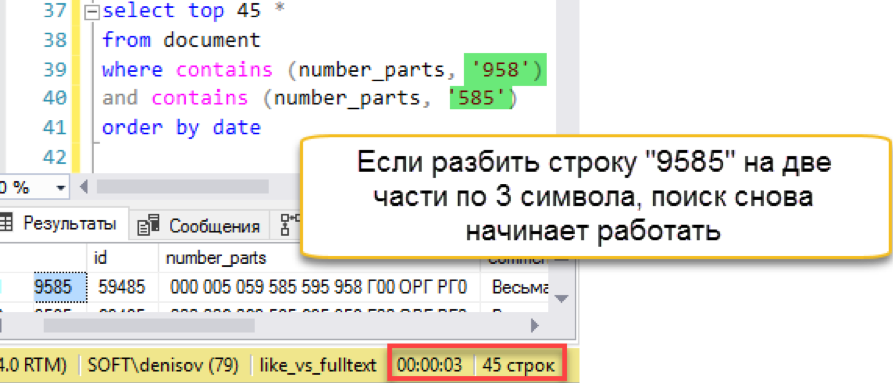
Outra coisa! Novamente, temos uma pesquisa rápida. Sim, ele impõe sua sobrecarga à manutenção, mas o resultado é centenas de vezes mais rápido que a pesquisa clássica. Observamos a tentativa contada, mas tentamos simplificar a manutenção de alguma forma - na próxima seção.
Vamos dividi-lo em palavras à nossa maneira!
De fato, quem disse que as palavras deveriam ser separadas por espaços? Talvez eu queira zeros entre as palavras! (e, se possível, o prefixo para que ele também seja ignorado e não interfira nos pés). Em geral, não há nada impossível nisso. Vamos relembrar o esquema da operação de pesquisa de texto completo desde o início do artigo - um componente separado, o wordbreaker, é responsável por dividir as palavras e, felizmente, a Microsoft permite que você implemente seu próprio "separador de palavras".
E aqui começa o interessante. O Wordbreaker é uma dll separada que se conecta ao mecanismo de pesquisa de texto completo. A
documentação oficial diz que fazer esta biblioteca é muito simples - basta implementar a interface IWordBreaker. E aqui estão algumas listagens curtas de inicialização em C ++. Com muito sucesso, acabei de encontrar um tutorial adequado!

(
fonte )
Sério, a documentação para criar seu próprio worbreaker na Internet é muito pequena. Ainda menos exemplos e modelos. Mas ainda encontrei o
projeto de uma pessoa gentil que escreveu em C ++ uma implementação que divide as palavras não por separadores, mas simplesmente por triplos (sim, como na seção anterior!) Além disso, a pasta do projeto já contém um binário cuidadosamente compilado, do qual você só precisa conecte-se ao mecanismo de pesquisa.
Apenas ligando ... Na verdade, não é muito fácil. Vamos seguir as etapas:
Você precisa copiar a biblioteca para a pasta com o SQL Server:

Registre um novo "idioma" na pesquisa de texto completo
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
Edite manualmente várias chaves no registro (o autor automatizaria o processo, mas não há notícias desde 2016. No entanto, esse era originalmente um "exemplo de implementação", obrigado por isso também)
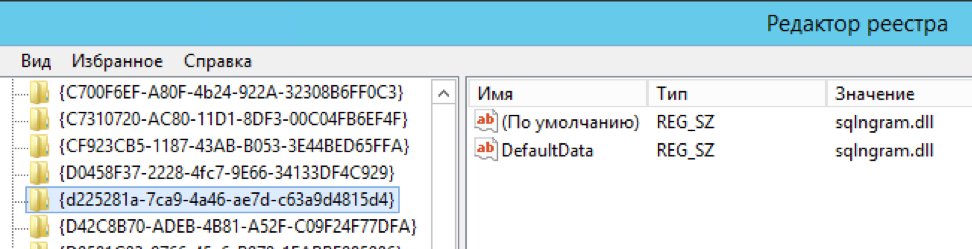
As etapas são descritas em detalhes na página do projeto.
Feito. Vamos excluir o antigo índice de texto completo, porque não pode haver dois índices de texto completo para uma tabela. Crie um novo e indexe nossos números de documentos. Como coluna principal, indicamos os próprios números, não são necessárias mais colunas pré-quebradas substitutas. Certifique-se de especificar o “idioma número 1” para usar o quebra-palavras instalado recentemente.
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
Verificar?
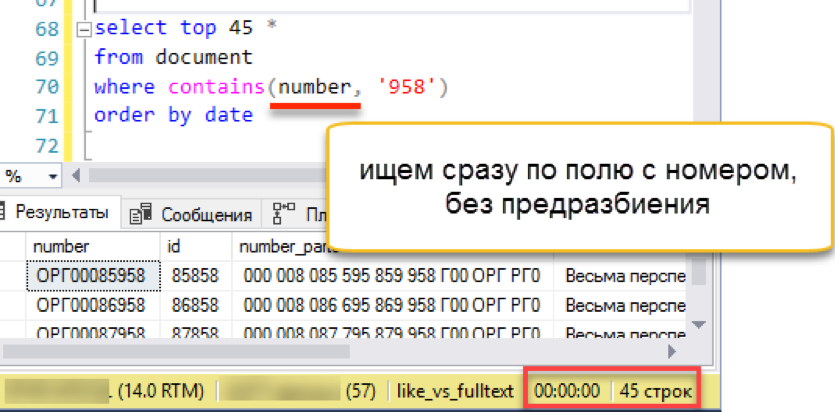
Isso funciona! Funciona tão rápido quanto todos os exemplos discutidos acima.
Vamos verificar a longa fila na qual a opção anterior tropeçou:
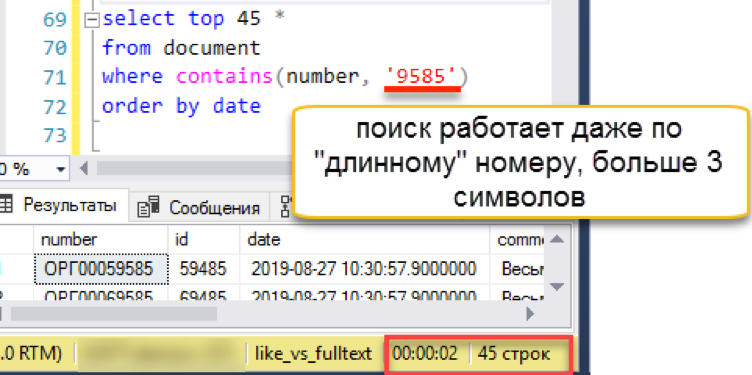
A pesquisa funciona de forma transparente para o usuário e o programador. O Wordbreaker divide independentemente a sequência de pesquisa em pedaços e encontra o resultado desejado.
Acontece que agora não precisamos de colunas e gatilhos adicionais, ou seja, a solução é mais simples (leia-se: mais confiável) do que nossa tentativa anterior. Bem, em termos de suporte, essa implementação é mais simples e transparente, há menos chances de erros.
Então, pare, eu disse "mais confiável"? Acabamos de conectar uma biblioteca de terceiros ao nosso DBMS! E o que acontecerá se ela cair? Mesmo inadvertidamente, arrasta todo o serviço de banco de dados!
Aqui, você precisa se lembrar de como, no início do artigo, mencionei o serviço de pesquisa de texto completo, separado do processo principal do DBMS. É aqui que fica claro por que isso é importante. A biblioteca se conecta ao serviço de indexação de texto completo, que pode operar com direitos reduzidos. E, mais importante, se componentes de terceiros caírem, apenas o serviço de indexação cairá. A pesquisa será interrompida por um tempo (mas já é assíncrona) e o mecanismo de banco de dados continuará funcionando como se nada tivesse acontecido.
Para resumir. Adicionar seu próprio separador de palavras pode ser um grande desafio. Mas, quando se joga "no tempo", esses esforços são recompensados com maior flexibilidade e facilidade de manutenção. A escolha, como sempre, é sua.
Por que tudo isso é necessário?
Um leitor curioso provavelmente se perguntou mais de uma vez: "tudo isso é ótimo, mas como posso usar esses recursos se não consigo alterar as consultas de pesquisa do meu aplicativo?" Pergunta razoável. A inclusão da pesquisa em MS SQL com texto completo requer alteração da sintaxe das consultas, e geralmente isso simplesmente não é possível na arquitetura existente.
Você pode tentar enganar o aplicativo "deslizando" uma função com o valor de tabela com o mesmo nome em vez de uma tabela regular, que já executará a pesquisa da maneira que desejamos. Você pode tentar vincular a pesquisa como um tipo de fonte de dados externa. Existe outra solução - Softpoint Data Cluster - um serviço especial que instala um "encaminhamento" entre o aplicativo de origem e o serviço do SQL Server, escuta o tráfego e pode alterar solicitações dinamicamente de acordo com regras especiais. Usando essas regras, podemos encontrar consultas regulares com LIKE e convertê-las em CONTAINS com pesquisa de texto completo.
Por que essas dificuldades? Ainda assim, a velocidade da pesquisa é cativante. Em um sistema muito carregado, em que os operadores geralmente buscam registros em milhões de tabelas, a velocidade de resposta é crítica. Economizar tempo na operação mais frequente resulta em dezenas de aplicativos processados adicionais, e isso é dinheiro real, com o qual qualquer empresa está satisfeita. No final, alguns dias ou até semanas para estudar e implementar a tecnologia serão recompensados com maior eficiência do operador.
Todos os scripts mencionados no artigo estão disponíveis no repositório
github.com/frrrost/mssql_fulltextSobre o autor
 Alexander Denisov
Alexander Denisov - Analista de Desempenho de Banco de Dados do MS SQL Server. Nos últimos 6 anos, como parte da equipe da Softpoint, tenho ajudado a encontrar gargalos nas solicitações de outras pessoas e a extrair o máximo dos bancos de dados dos clientes.