Mikhail Konovalov, Chefe do Departamento de Suporte a Projetos de Integração, Diretoria de TI do ICDBom dia, Khabrovites!
Finalidade
Uma abordagem sistemática para gerenciar downloads. Queremos dizer como otimizar e automatizar o preenchimento do repositório com informações e, ao mesmo tempo, não confundir os fluxos de várias fontes.
Preâmbulo
Mais cedo ou mais tarde, chega um momento no banco de dados corporativo de qualquer empresa, quando cresce para o tamanho que os olhos do arquiteto deixam de captar a incerteza (caos) do sistema e se transforma em uma massa incontrolável de todos os tipos de downloads de várias fontes.
Você tem sorte se o seu sistema foi desenvolvido do zero (da primeira tabela) e foi executado por um arquiteto, uma equipe de desenvolvedores e analistas. Além disso, esse arquiteto liderou com competência o modelo de data warehouse. Mas a vida é multifacetada; na maioria dos casos, a DWH cresce espontaneamente; no início, havia 30 mesas; depois, adicionamos um pouco mais, conforme necessário; depois, gostamos e começamos a adicionar todas as oportunidades, e agora temos mais de cinco mil, sim. camadas, estadiamento e vitrines ainda apareciam. E toda essa "felicidade" caiu sobre nós como resultado de um processo, mas muito conveniente, que é um relacionamento causal difícil:
- a empresa diz: “Precisamos desses dados. Precisa de um novo relatório »
- o analista está olhando
- desenvolvedor implementa
- o arquiteto coordena e contribui para o modelo de dados
Mas, como regra, o último ponto da realidade não existe. E aparece apenas em um determinado momento nas grandes empresas que cresceram até o DWH, onde um arquiteto puro gerencia com competência a integridade das informações no banco de dados. Esses repositórios são uma revisão da estrutura anterior, que foi re-documentada e, muitas vezes, reconstruída, de olho na versão anterior (não documentada).
Então, um breve resumo:- não há DWH que nasceu imediatamente e anteriormente não representava um banco de dados regular com um conjunto de tabelas;
- tudo o que existe agora e é uma estrutura claramente algorítmica e documentada foi obtido como resultado de "amarga experiência" de desenvolvimentos anteriores.
Se você é o proprietário feliz do DWH "correto" ou faz parte da equipe desse proprietário feliz, este artigo "em teoria" pode parecer interessante para você. E se você apenas precisar passar por uma revisão ou (proibi-lo) reconstruir, este artigo poderá simplificar bastante sua vida.
Como pode haver uma quantidade inimaginável de fontes de informação, há pelo menos o mesmo número de fluxos de download e sobrecarga de objetos diferentes e muitas vezes muito mais, já que cada objeto de banco de dados pode passar por mais de uma transformação antes que seus dados possam ser usados pelo usuário final para criar relatórios de negócios. Mas é para ele, para os negócios e não para seu próprio prazer que todo esse ecossistema foi construído para "transfusão de vaso em vaso".
O Oracle é usado como o banco de dados de nosso armazenamento. Uma vez, no estágio de criação, o núcleo central do nosso banco de dados consistia em algumas centenas de tabelas. Não pensamos em organizar e montras. Mas, como se costuma dizer, "tudo flui, tudo muda", e agora crescemos! O negócio determina novos requisitos, e a integração com vários bancos de dados MS SQL, SyBASE, Vertica, Access já apareceu. De onde as informações não fluem para nós, até mesmo exóticos, como trocas XML e JSON com sistemas de terceiros, apareceram, e o arquivo XLS como fonte de informações é completamente anacrônico.
A vida nos fez passar pela revisão e atualizar o modelo de dados, mantê-lo e mantê-lo. Aqui está uma das partes do núcleo principal:
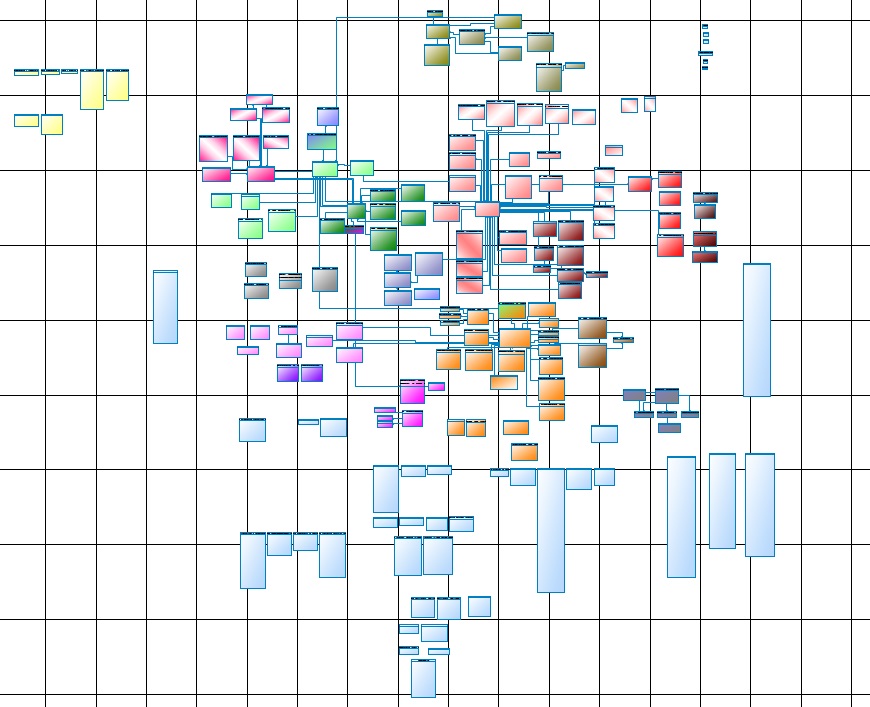 Fig. 1
Fig. 1Para quem é, mas para mim - é legível apenas em um artigo da Whatman, e A0 será um pouco pequeno, melhor que 4A0, na tela que não cede aos olhos ou à imaginação.
Agora, lembre-se de que este é apenas o núcleo (Core Data Layer), ou melhor, sua parte principal; o núcleo completo consiste em vários subsistemas que não são muito inferiores ao principal.
Camada de dados primária e
camada de data mart também são adicionadas a isso. Além disso, a camada primária recebe suas informações de fontes de dados e, como mencionado acima, vários bancos de dados e arquivos. Por outro lado, para a camada de montras, vários sistemas de relatórios são unidos pelo consumidor.
Inicialmente, quando havia poucas tabelas de banco de dados e algoritmos de carregamento implementados no PL / SQL, não havia dificuldades específicas para entender as atualizações de dados. Mas com o surgimento do DWH, uma decisão estratégica foi comprar o Informatica PowerCenter. Com toda a conveniência dessa ferramenta, tanto em termos de confiabilidade do carregamento quanto da visualização do desenvolvimento, essa ferramenta possui várias desvantagens. A figura abaixo mostra um modelo para a sequência de inicialização para carregar um DWH.
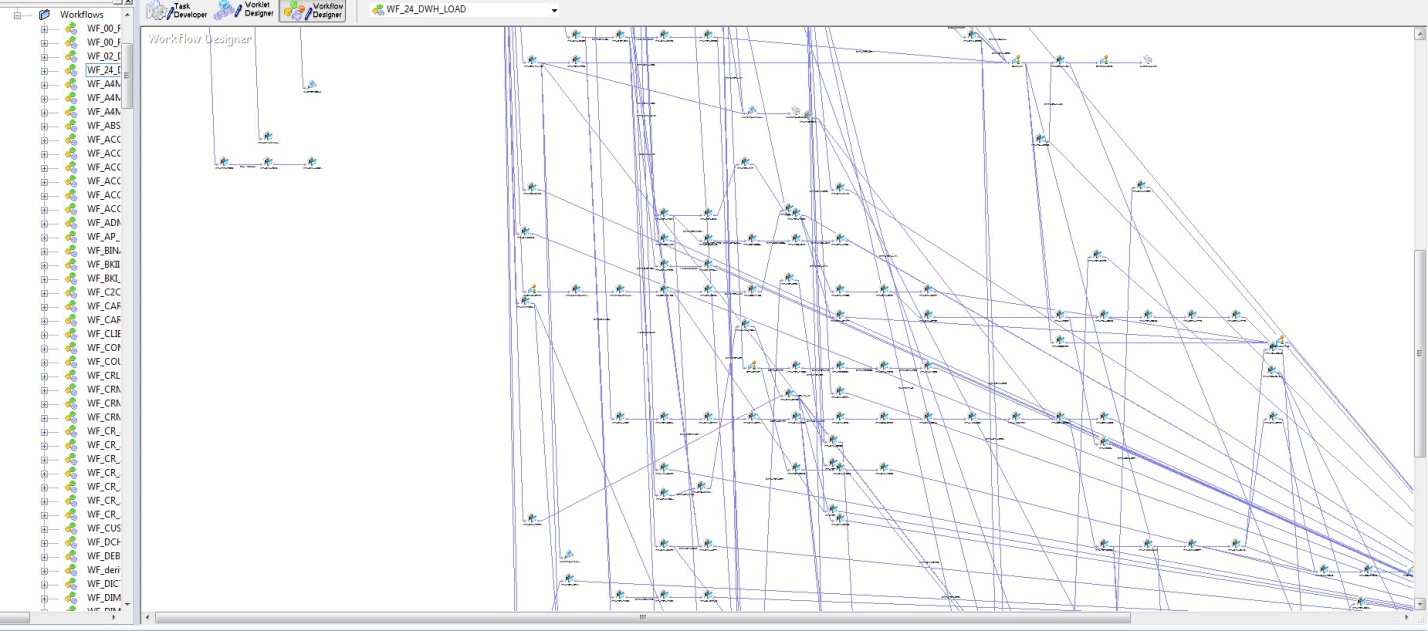 Fig. 2
Fig. 2A desvantagem mais importante é a subjetividade, ou melhor, apenas o arquiteto pode garantir que os lançamentos não sejam carregados antes das faturas. Infelizmente, com o crescimento da DWH, a entropia da informação também aumenta. Levando em consideração o modelo de dados físicos (Fig. 1) e a lógica de carregar esses dados (Fig. 2), a construção ainda é obtida.
O que fazer e como orientá-lo, você pergunta. Naturalmente: ter um arquiteto brilhante que seja capaz de entender todas as conexões desses meandros. O qual monitorará todos os fluxos, coordenará novos fluxos e impedirá que a tabela de lançamentos seja carregada antes da tabela de contas. Obviamente, tudo isso é costurado nos algoritmos e regulado pelos cortes de downloads, mas inicialmente apenas um arquiteto pode entender e definir os downloads para uma sequência estrita e, com essa ramificação, a probabilidade de erros é muito alta.
Teoria
Agora tentarei declarar as principais idéias do dicionário de modelo de dados, bem como as tarefas que ele resolve.
Como os dados no armazenamento estão em tabelas e as fontes de dados são parcialmente tabelas e parcialmente visualizações, estas últimas são tabelas. Em seguida, segue uma idéia simples - para criar uma estrutura de dependência
TABLE - TABLE . O formulário
3NF é perfeitamente adequado para isso.
Em primeiro lugar, o preenchimento dos dados da entidade DWH, que chamamos de
(target) , no caso mais geral, pode ser representado como
seleção de diferentes tabelas. Quer se trate de tabelas Oracle, SyBase, MSSQL, arquivos xls ou qualquer outra coisa, não é tão importante, tudo isso, chamamos de suas fontes
(fonte) . Ou seja, temos uma
fonte que flui para o
destino .
Em segundo lugar, cada entidade DWH tem referências uma à outra.
Em terceiro lugar, existe uma cronologia para iniciar downloads de várias entidades DWH.
Continua sendo o caso de pequenas implementações - como? Parece que é muito simples, desde a fundação do seu DWH, o arquiteto, quando a próxima tabela da entidade
(destino) aparecer, deve examinar e colocar no dicionário a entidade receptora e todas as entidades que servem como fontes. Além disso, na segunda tabela do dicionário, especifique os links entre essas fontes de entidades em select, bem como todas as tabelas subordinadas que são referenciadas por referências. Em seguida, você pode incorporar o carregamento dessa entidade na cadeia de download de armazenamento. Apenas duas tabelas - e a possibilidade de levar em consideração a sequência de preenchimento dos dados com o algoritmo no algoritmo é resolvida.
O modelo de dados do dicionário resolverá os seguintes problemas:
- Exibir dependências. Você pode ver quais dados, de onde eles são extraídos. Isso é conveniente para analistas que sempre são atormentados por perguntas: "de onde, o que está e de onde vem tudo". Apresente isso no aplicativo na forma de uma árvore, da origem ao destino e vice-versa: do destino à origem .
- Ruptura de loops. Ao incorporar a próxima carga em um fluxo compartilhado já em funcionamento, sem ter um dicionário de modelo de dados, é bem possível cometer um erro e atribuir um horário de início para carregar o próximo destino na frente de uma de sua origem. Isso cria um loop. Um dicionário de modelo de dados evitará isso facilmente.
- Você pode escrever um algoritmo para preencher o armazenamento com base no dicionário de modelo. Nesse caso, não há necessidade de incorporar o próximo download em qualquer lugar, apenas reflita-o no dicionário e o algoritmo determinará seu lugar. Resta clicar no cobiçado botão "Make ALL" . O gerenciador de inicialização iniciará downloads semelhantes a avalanche de todas as entidades de armazenamento - de simples (independente) a complexo (dependente).
Implementação
Em teoria, tudo é sempre simples e bonito; na prática, as coisas são um pouco diferentes. O que está escrito na seção anterior é uma situação ideal quando o DWH se desenvolveu do zero, quando um arquiteto estava inseparavelmente com ele. Se você não tiver sorte, tudo isso você passou "com segurança", não há arquiteto, mas há um conjunto gigantesco de tabelas; de qualquer maneira, existe uma solução.
Agora, na verdade, vou lhe contar como conseguimos atualizar, revisar e reconstruir o suficiente. Nosso DWH começou a evoluir com uma decisão de liderança sobre uma necessidade iminente (DWH). Como ferramenta, o PL / SQL foi usado pela primeira vez. Um pouco mais tarde, mudou para a Informatica. Naturalmente, a prioridade era o momento da criação. O modelo de dados no PowerDesigner apareceu algum tempo depois, quando a confiança foi claramente formada, de que ninguém conseguia imaginar claramente uma imagem completa e clara da DWH. Vivemos algum tempo com o modelo na parede, quando ficou claro que não podíamos lidar com o gerenciamento de todo esse sistema, começamos a procurar uma solução que tentarei descrever brevemente aqui.
O próprio dicionário de modelo de dados é tão simples quanto um pedaço de pau. Mas preenchê-lo é um problema. N meses de meticulosa e, mais importante, consideração cuidadosa das três partes acima:
- em que fontes (origem) cada entidade do repositório (destino) consiste;
- quais são os relacionamentos entre objetos de armazenamento (referências);
- a cronologia do início dos downloads e do preenchimento do repositório.
Felizmente, a Oracle e a Informatica nos ajudaram e, com muito sucesso, o repositório da Informatica está no banco de dados Oracle. Tomando como base que uma Sessão da Informatica é o átomo de carregamento de uma entidade DWH, cavando um pouco no repositório, encontramos todas as fontes e destinos. Ou seja, dentro da estrutura de uma sessão, para todo o seu destino (como regra, é um), todas as suas fontes são fontes. Assim, podemos preencher a primeira condição do problema. Mas não se apresse para se alegrar, a fonte pode ser apresentada na forma de uma seleção muito inteligente; portanto, você teve que escrever um analisador que retire todas as tabelas especificadas na seleção - não foi nada difícil. Mas isso não é tudo, essas próprias tabelas podem realmente ser representações. Usando DBA_VIEWS (ou através de DBA_DEPENDENCIES), esse problema também foi resolvido. Puxamos a segunda condição dessa trilogia do modelo de dados (Fig. 1) e DBA_CONSTRAINTS. Também obtivemos a terceira condição do repositório da Informatica com base em (Fig. 2).
O que aconteceu com tudo isso?- Primeiramente, desembaraçamos todos os circuitos que conseguimos enrolar na evolução do nosso DWH.
- Em segundo lugar, temos uma árvore maravilhosa para analistas:

Fig. 3 - Terceiro, nosso superloader, apresentado na fig. 2 se transformou em elegante (desculpe, colegas, mas a desfocagem da imagem é intencional, pois esses são dados de trabalho):
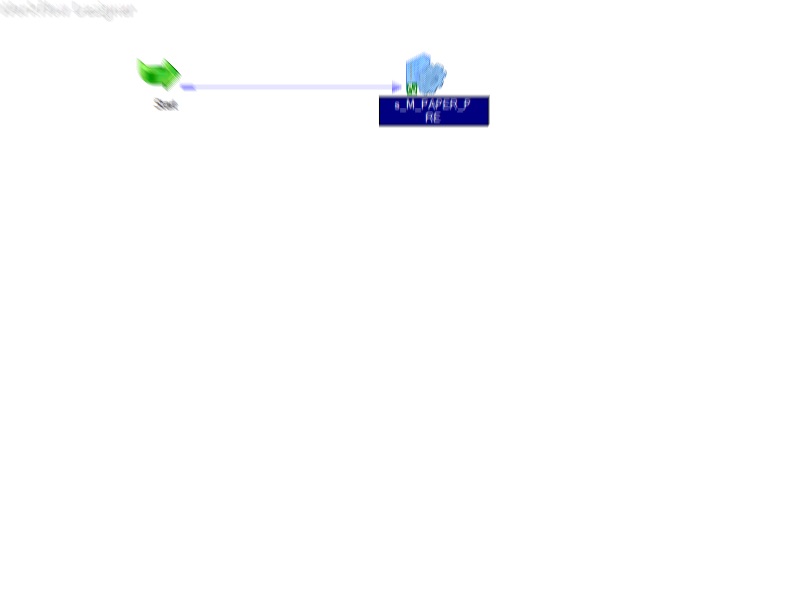
Fig. 4
Você pode ter muito mais maneiras de aplicar o dicionário de modelo de dados.
Obrigado a todos!