O pprof é a principal ferramenta de criação de perfil no Go. O criador de perfil está incluído na biblioteca padrão Go e muito foi escrito sobre isso ao longo dos anos. Para conectar o pprof a um aplicativo existente, basta adicionar uma linha de código:
import _ “net/http/pprof”
No servidor HTTP padrão - net/http.DefaultServeMux - os manipuladores que enviarem resultados de criação de perfil serão registrados no caminho /debug/pprof/ .
curl -o cpu-profile.pb.gz http://<server-addr>/debug/pprof/profile
(para mais detalhes, consulte https://godoc.org/net/http/pprof )
Mas, por experiência, nem sempre é tão simples e, na prática, usando o pprof em batalha, existem armadilhas.
Para começar, não queremos que os manipuladores de perfis apareçam na Internet. A criação de perfil é barata, em termos de sobrecarga, mas não é gratuita, e o próprio perfil contém informações sobre a estrutura interna do aplicativo, que geralmente não é aconselhável abrir para pessoas de fora. Você precisa garantir que o caminho /debug não esteja acessível para usuários não autorizados. O acesso pode ser limitado no servidor proxy ou o servidor pprof pode ser movido para uma porta separada, cujo acesso será aberto apenas por meio do host privilegiado.
Mas e se o aplicativo não envolver acesso HTTP - por exemplo, é um processador de filas offline?
Dependendo do estado da infra-estrutura na empresa, um servidor HTTP "repentino" dentro do processo do aplicativo pode levantar dúvidas do departamento de operações;) O servidor limita adicionalmente os recursos de escala horizontal, como não funcionará apenas para executar várias instâncias do aplicativo no mesmo host - os processos entrarão em conflito, tentando abrir a mesma porta TCP para o servidor pprof.
É "simples" resolver isolando cada processo de aplicativo no contêiner (ou executando o servidor pprof em uma porta exclusiva ou soquete UNIX). Você não surpreenderá mais ninguém com um serviço horizontalmente escalado em centenas de instâncias, "espalhadas" por vários data centers. Em uma infraestrutura muito dinâmica, os contêineres com o aplicativo podem aparecer e desaparecer periodicamente. E ainda precisamos entrar em contato com o criador de perfil. E isso significa que, independentemente do método de dimensionamento selecionado, são necessários mecanismos de pesquisa para uma instância de aplicativo específica e a porta do servidor pprof correspondente.
Dependendo das características da empresa, a própria existência da capacidade de acessar algo que não está relacionado à principal atividade de produção do serviço pode levantar questões do departamento de segurança;) Eu trabalhei em uma empresa onde, por razões objetivas, o acesso a qualquer coisa está do lado A produção foi exclusivamente no departamento de operações. A única maneira de executar o criador de perfil em um aplicativo em execução era abrir uma tarefa no rastreador de erros de operação, com uma descrição de qual comando curl, em qual controlador de domínio, em qual servidor você deseja executar, qual resultado esperar e o que fazer com ele.
Ou imagine uma situação: uma manhã de trabalho. Você abriu o Slack e descobriu que, à noite, em um dos processos do serviço de produção "algo deu errado", "em algum lugar, algo" desligou "," a memória começou a fluir "," os gráficos da CPU subiram "ou o aplicativo começou a entrar em pânico. As equipes operacionais de serviço (ou OOM Killer) não se aprofundaram e simplesmente reiniciaram o aplicativo ou reverteram a versão mais recente do dia anterior.
Após o fato, não é fácil entender essas situações. É ótimo se o problema puder ser reproduzido em um ambiente de teste (ou em uma parte isolada da produção à qual você tem acesso). Você pode coletar os dados necessários com todas as ferramentas disponíveis e depois descobrir qual componente é o problema.
Mas, se não houver uma maneira óbvia de reproduzir o problema, ficamos apenas com os registros e métricas de ontem? Nessas situações, é sempre uma pena que você não possa retroceder o tempo para o momento em que o problema estava visível na produção e coletar rapidamente todos os perfis necessários, para que mais tarde, em um modo silencioso, faça análises.
Mas se o pprof é relativamente barato, por que não coletar dados de criação de perfil automaticamente, em alguns intervalos, e armazená-los em algum lugar separado da produção, onde você pode dar acesso a todos os interessados?
Em 2010, o Google publicou o documento Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers , que descreve uma abordagem para o perfil contínuo de sistemas da empresa. Depois de alguns anos, a empresa lançou um serviço de criação de perfil contínuo - Stackdriver Profiler - disponível para todos.
O princípio da operação é simples: em vez de um servidor pprof, um agente stackdriver é conectado ao aplicativo, que, usando a API runtime/pprof , coleta periodicamente diferentes tipos de perfil do aplicativo e envia perfis para a nuvem. Tudo o que o desenvolvedor precisa, usando o painel de controle Stackdriver, seleciona a instância do aplicativo desejada no AZ desejado e, após o fato, você pode analisar o aplicativo a qualquer momento no passado.
Outros provedores de SaaS fornecem funcionalidade semelhante. Porém, as regras de segurança da sua empresa podem proibir a exportação de dados além de sua própria infraestrutura. E os serviços que permitem implantar um sistema de criação de perfil contínuo em seus próprios servidores, eu não vi.
Todas as dificuldades e idéias descritas acima estão longe de serem novas e específicas, não apenas para o Go. Com eles, de uma forma ou de outra, os desenvolvedores são confrontados com quase todas as empresas em que trabalhei.
Em algum momento, eu estava curioso para tentar criar um análogo do Stackdriver Profiler para um serviço Go arbitrário que pudesse resolver os problemas descritos. Como um projeto de hobby, no meu tempo livre, trabalho no profefe ( https://github.com/profefe/profefe ) - um serviço aberto de criação de perfil contínuo. O projeto ainda está em estágio de experimentos e discussões periódicas, mas já é adequado para testes.
As tarefas que defini para o projeto:
- O serviço será implantado na infraestrutura interna da empresa.
- O serviço será usado como uma ferramenta interna da empresa. Você pode confiar em fornecedores e consumidores de dados: nos estágios iniciais, você pode omitir a autorização de solicitações de gravação / leitura e não tentar se proteger antecipadamente do uso malicioso.
- O serviço não deve ter expectativas especiais em relação à infraestrutura da empresa: tudo pode viver na nuvem ou em seus próprios CDs; aplicativos perfilados podem ser executados dentro de contêineres ("tudo é controlado pelo Kubernetes") ou podem ser executados em metal puro.
- O serviço deve ser fácil de operar (parece até certo ponto, Prometheus é um bom exemplo).
- Deve-se entender que a arquitetura selecionada pode não atender às condições em que o serviço será usado. Provavelmente, você precisará expandir / substituir os componentes do sistema para dimensionar "no local".
- De acordo com (4), devemos tentar minimizar as dependências externas necessárias. Por exemplo, um serviço deve, de alguma forma, procurar instâncias de aplicativos com perfil, mas, pelo menos nos estágios iniciais, eu quero ficar sem uma descoberta explícita de serviço.
- O serviço armazenará e catalogará perfis de aplicativos Go. Esperamos que um arquivo pprof ocupe 100 KB - 2 MB ( perfis de heap geralmente são muito maiores que perfis de CPU ). Em uma instância com perfil, não faz sentido enviar mais de N perfis por minuto (um agente do Stackdriver envia, em média, 2 perfis por minuto). Vale a pena calcular imediatamente que um único aplicativo pode ter de várias a várias centenas de instâncias.
- Por meio do serviço, os usuários pesquisam diferentes tipos de perfis (CPU, heap, mutex etc.) do aplicativo ou uma instância específica do aplicativo por um determinado período de tempo.
- No serviço, o usuário solicitará um perfil pprof separado dos resultados da pesquisa.
Agora o profefe consiste em dois componentes:
O profefe-collector é um coletor de serviços com uma API RESTful simples.
A tarefa do coletor é obter o arquivo pprof e alguns metadados e salvá-los no armazenamento permanente. A API também permite que os clientes pesquisem perfis por metadados em uma determinada janela de tempo ou leiam um perfil específico (ou um grupo de perfis do mesmo tipo) da loja.
agent - uma biblioteca opcional que deve ser conectada ao aplicativo em vez do servidor pprof. Dentro do aplicativo, em uma goroutina separada, o agente inicia periodicamente o processo de criação de perfil (usando o runtime/pprof ) e envia os perfis do pprof recebidos, juntamente com os metadados ao coletor.
Os metadados são um conjunto de valores-chave arbitrário que descreve um aplicativo ou sua instância individual. Por exemplo: nome do serviço, versão, data center e host em que o aplicativo está sendo executado.

Diagrama de interação do componente Profefe
Eu mencionei acima que o agente é um componente opcional. Se não for possível conectá-lo a um aplicativo existente, mas o servidor net/http/pprof já estiver conectado ao aplicativo, os perfis poderão ser removidos usando qualquer ferramenta externa e enviar os arquivos pprof ao coletor por meio da API HTTP.
Por exemplo, nos hosts, você pode configurar uma tarefa cron que periodicamente colecionará perfis das instâncias em execução e os enviará ao profefe para armazenamento;)
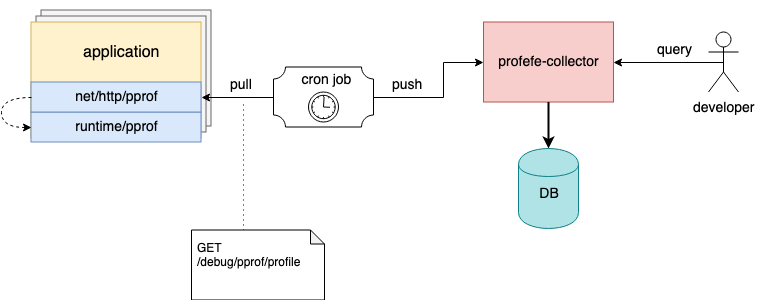
A tarefa Cron coleta e envia perfis de aplicativos para o coletor profefe
Você pode ler mais sobre a API profefe na documentação do GitHub .
Planos
Até o momento, a única maneira de interagir com o coletor de profefe é a API HTTP. Uma das tarefas para o futuro é montar um serviço de interface do usuário separado por meio do qual será possível mostrar visualmente os dados armazenados: resultados da pesquisa, uma visão geral do desempenho do cluster, etc.
Coletar e armazenar dados de criação de perfil não é ruim, mas "sem aplicativo, os dados são inúteis". A equipe em que trabalho possui um conjunto de ferramentas experimentais para coletar estatísticas básicas para vários perfis de pprof do serviço. Isso ajuda muito na análise das consequências da atualização das principais dependências do aplicativo ou dos resultados de uma grande refatoração ( infelizmente, o desempenho na produção nem sempre atende às expectativas com base no lançamento de benchmarks isolados e na criação de perfis em um ambiente de teste ). Desejo adicionar funcionalidades semelhantes para comparar e analisar perfis armazenados na API profefe.
Apesar de o foco principal do profefe ser o perfil contínuo dos serviços Go, o formato do perfil do pprof não está de todo vinculado ao Go. Para Java, JavaScript, Python, etc., existem bibliotecas que permitem obter dados de criação de perfil nesse formato. Talvez o profefe possa se tornar um serviço útil para aplicativos escritos em outros idiomas.
Entre outras coisas, o repositório tem várias perguntas em aberto descritas no rastreador de projetos no GitHub .
Conclusão
Nos últimos anos, uma ideia popular foi consolidada entre os desenvolvedores: para alcançar a “ observabilidade ” de um serviço, são necessários três componentes: métricas, logs e rastreamento (“ três pilares da observabilidade ”). Parece-me que a visibilidade é a capacidade de responder efetivamente a perguntas sobre a saúde do sistema e seus componentes. Métricas e rastreio tornam possível entender o sistema como um todo. Os logs cobrem as partes deliberadamente descritas do sistema. A criação de perfil é outro sinal para obter visibilidade, permitindo entender o sistema no nível micro. A criação de perfil contínuo durante um período de tempo também ajuda a entender como os componentes individuais e o ambiente influenciam e afetam a operacionalidade e a produtividade de todo o sistema.