
Tínhamos 4 contas da Amazon, 9 VPCs e 30 ambientes de desenvolvimento, estágios, regressões mais poderosos - no total, mais de 1000 instâncias do EC2 de todas as cores e tons. Desde que comecei a coletar soluções em nuvem para os negócios, preciso seguir meu hobby até o fim e pensar em como automatizar tudo isso.
Oi Meu nome é Kirill Kazarin, trabalho como engenheiro no DINS. Estamos desenvolvendo soluções de comunicação comercial baseadas na nuvem. Em nosso trabalho, usamos ativamente o Terraform, com o qual gerenciamos com flexibilidade nossa infraestrutura. Vou compartilhar minha experiência com esta solução.
O artigo é longo, portanto,
compre chá de
pipoca e pronto!
E mais uma nuance - o artigo foi escrito com base na versão 0.11, em novos 0,12 muito mudou, mas as principais práticas e dicas ainda são relevantes. A questão da migração de 0,11 para 0,12 merece um artigo separado!
O que é o Terraform
Terraform é uma ferramenta Hashicorp popular que apareceu em 2014.
Esse utilitário permite gerenciar sua infraestrutura de nuvem na
infraestrutura como um paradigma de
código em uma linguagem declarativa muito amigável e de fácil leitura. Seu aplicativo fornece a você um tipo unificado de recursos e aplicação de práticas de código para gerenciamento de infraestrutura, que há muito tempo são desenvolvidas pela comunidade de desenvolvedores. O Terraform suporta todas as plataformas de nuvem modernas, permite alterar a infraestrutura com segurança e previsibilidade.
Quando lançado, o Terraform lê o código e, usando os plug-ins fornecidos pelos provedores de serviços em nuvem, leva sua infraestrutura ao estado descrito, fazendo as chamadas de API necessárias.
Nosso projeto está localizado inteiramente na Amazon, implantado com base nos serviços da AWS e, portanto, escrevo sobre o uso do Terraform nesse sentido. Separadamente, observo que ele pode ser usado não apenas na Amazon. Permite gerenciar tudo o que possui uma API.
Além disso, gerenciamos configurações de VPC, políticas do IAM e funções. Gerenciamos tabelas de roteamento, certificados, ACLs de rede. Gerenciamos as configurações de nosso firewall de aplicativo da web, S3-bucket, SQS-filas - tudo o que nosso serviço pode usar na Amazon. Ainda não vi recursos com a Amazon que a Terraform não pudesse descrever em termos de infraestrutura.
Acontece uma infraestrutura bastante grande, com as mãos é fácil de suportar. Mas com o Terraform é conveniente e simples.
De que é feito o Terraform
Provedores são plugins para trabalhar com a API de um serviço. Eu contei a eles
mais de 100 . Entre eles estão fornecedores para Amazon, Google, DigitalOcean, VMware Vsphere, Docker. Eu até encontrei um provedor nesta lista oficial que permite
gerenciar as regras do Cisco ASA !
Entre outras coisas, você pode controlar:
E esses são apenas provedores oficiais, existem ainda mais provedores não oficiais. Durante os experimentos, deparei-me com o GitHub de terceiros, não incluído no provedor de lista oficial, que
permitia trabalhar com o DNS do GoDaddy e com os
recursos do Proxmox .
Em um projeto Terraform, você pode usar provedores diferentes e, consequentemente, os recursos de diferentes provedores ou tecnologias de serviço. Por exemplo, você pode gerenciar sua infraestrutura na AWS, com DNS externo do GoDaddy. E amanhã, sua empresa comprou uma startup hospedada no DO ou Azure. E enquanto você decide migrar isso para a AWS ou não, também pode oferecer suporte com a mesma ferramenta!
Recursos. Essas são entidades de nuvem que você pode criar usando o Terraform. Sua lista, sintaxe e propriedades dependem do provedor usado, de fato - da nuvem usada. Ou não apenas nuvens.
Módulos Essas são as entidades com as quais o Terraform permite modelar sua configuração. Assim, os modelos permitem diminuir o seu código, reutilizá-lo. Bem, eles ajudam a trabalhar confortavelmente com ele.
Por que escolhemos a Terraform
Para nós mesmos, identificamos 5 razões principais. Talvez do seu ponto de vista, nem todos eles pareçam significativos:
- Terraform é um utilitário de suporte a múltiplas nuvens
agnóstico em nuvem (obrigado pelo valioso comentário nos comentários) . Quando escolhemos essa ferramenta, pensamos: - E o que acontecerá se o gerenciamento de amanhã ou uma semana chegar até nós e disser: " Pessoal, pensamos - não vamos apenas implantar na Amazon. Temos algum tipo de projeto, onde precisamos obter a infraestrutura no Google Cloud. Ou no Azure - bem, você nunca sabe ". Decidimos que gostaríamos de ter uma ferramenta que não esteja rigidamente vinculada a nenhum serviço de nuvem. - Código aberto . Terraform é uma solução de código aberto . O repositório do projeto tem uma classificação de mais de 16 mil estrelas, esta é uma boa confirmação da reputação do projeto.
Mais de uma ou duas vezes, descobrimos o fato de que em algumas versões existem erros ou um comportamento pouco compreensível. Ter um repositório aberto permite garantir que isso seja realmente um bug, e podemos resolver o problema simplesmente atualizando o mecanismo ou a versão do plugin. Ou que isso seja um bug, mas "Pessoal, espere, literalmente, dois dias depois, uma nova versão será lançada e nós a corrigiremos". Ou: "Sim, isso é algo incompreensível, estranho, eles resolvem o problema, mas há uma solução alternativa". É muito conveniente - Control . Terraform como um utilitário está completamente sob seu controle. Ele pode ser instalado em um laptop, em um servidor, e pode ser facilmente integrado ao seu pipeline, o que pode ser feito com base em qualquer ferramenta. Por exemplo, usamos no GitLab CI.
- Verificando o status da infraestrutura . O Terraform pode e faz uma boa verificação do estado da sua infraestrutura.
Suponha que você começou a usar o Terraform em sua equipe. Você cria uma descrição de algum recurso na Amazon, por exemplo, Grupo de Segurança, aplica-o - ele é criado para você, está tudo bem. E aqui - bam! Seu colega que voltou de férias ontem e ainda não está ciente de que você organizou tudo de maneira tão bonita aqui, ou até mesmo um colega de outro departamento entra e altera as configurações deste Grupo de Segurança por alças.
E sem se encontrar com ele, sem conversar ou sem ter enfrentado um determinado problema, você nunca saberá sobre isso em uma situação normal. Porém, se você usar o Terraform, mesmo executando um plano ocioso nesse recurso mostrará que há mudanças no ambiente de trabalho.
Quando o Terraform olha para o seu código, ele chama simultaneamente a API do provedor de nuvem, recebe o estado dos objetos e compara: "E agora há a mesma coisa que eu fiz antes, o que eu lembro?" Então ele compara com o código, olha o que mais precisa ser mudado. E, por exemplo, se tudo estiver igual em sua história, em sua memória e em seu código, mas houver mudanças lá, ele mostrará a você e se oferecerá para revertê-lo. Na minha opinião, também uma propriedade muito boa. Portanto, esse é outro passo, pessoalmente para nós, para garantir que tenhamos uma infraestrutura imutável. - Outra característica muito importante são os módulos que mencionei e que contam. Eu vou falar sobre isso um pouco mais tarde. Quando vou comparar com as ferramentas.
E também uma cereja no bolo: o Terraform tem uma
lista bastante grande de funções internas . Essas funções, apesar da linguagem declarativa, permitem implementar algumas, para não dizer programáticas, mas lógicas.
Por exemplo, alguns cálculos automáticos, linhas de divisão, conversão para maiúsculas e minúsculas, removendo caracteres dessa linha. Estamos usando-o ativamente. Eles tornam a vida muito mais fácil, especialmente quando você escreve um módulo que será reutilizado posteriormente em diferentes ambientes.
Terraform vs CloudFormation
A rede geralmente compara o Terraform ao CloudFormation. Também fizemos essa pergunta ao escolher. E aqui está o resultado da nossa comparação.
Como começar com o Terraform
De um modo geral, começar é bastante simples. Aqui estão os primeiros passos brevemente:
- Primeiro, crie um repositório Git e comece imediatamente a armazenar todas as suas alterações, experimentos e tudo.
- Leia o guia de introdução . É pequeno, simples, bastante detalhado e descreve bem como começar com este utilitário.
- Escreva alguma demo, código de trabalho. Você pode até copiar algum tipo de exemplo para brincar com ele mais tarde.
Nossa prática com a Terraform
Código fonte
Você iniciou seu primeiro projeto e salvou tudo em um grande arquivo main.tf.
Aqui está um exemplo típico (honestamente, peguei o primeiro do GitHub).
Nada de errado, mas o tamanho da base de código tende a aumentar com o tempo. As dependências entre recursos também estão crescendo. Depois de algum tempo, o arquivo se torna enorme, complexo, ilegível, com pouca manutenção - e uma mudança descuidada em um local pode causar problemas.
A primeira coisa que recomendo é destacar o chamado repositório principal, ou estado principal do seu projeto, seu ambiente. Assim que você começar a criar uma infraestrutura usando o Terraform, ou importá-la, você encontrará imediatamente o fato de ter algumas entidades que, uma vez implantadas, configuradas, raramente mudam. Por exemplo, essas são configurações de VPC ou a própria VPC. São redes, grupos de segurança básicos e gerais, como acesso SSH - você pode compilar uma lista bastante grande.
Não faz sentido manter isso no mesmo repositório dos serviços que você altera com freqüência. Selecione-os em um repositório separado e encaixe-os através de um recurso Terraform, como estado remoto.
- Você está reduzindo a base de código daquela parte do projeto com a qual trabalha frequentemente diretamente.
- Em vez de um arquivo tfstate grande que contém uma descrição do estado de sua infraestrutura, dois arquivos menores e, em um determinado momento, você está trabalhando com um deles.
Qual é o truque? Quando o Terraform faz um plano, ou seja, calcula, calcula o que deve ser alterado, aplica - ele reconta completamente esse estado, verifica o código, verifica o status na AWS. Quanto maior o seu estado, mais tempo o plano levará.
Chegamos a essa prática quando levamos 20 minutos para construir um plano para todo o ambiente em produção. Devido ao fato de termos reunido em um núcleo separado tudo o que não estamos sujeitos a mudanças frequentes, reduzimos o tempo para construir um plano pela metade. Temos uma ideia de como isso pode ser reduzido ainda mais, dividindo-se não apenas em núcleo e não núcleo, mas também em subsistemas, porque os temos conectados e geralmente mudam juntos. Assim, dizemos, transformaremos 10 minutos em 3. Mas ainda estamos no processo de implementação dessa solução.
Menos código - mais fácil de ler
O código pequeno é mais fácil de entender e mais conveniente de se trabalhar. Se você tem uma equipe grande e ela tem pessoas com diferentes níveis de experiência - faça o que raramente muda, mas globalmente, em um nabo separado, e ofereça acesso mais restrito.
Digamos que você tenha juniores em sua equipe e não lhes dê acesso ao repositório global que descreve as configurações da VPC - dessa forma, você se protege contra erros. Se um engenheiro comete um erro ao escrever a instância, e algo é criado errado - isso não é assustador. E se ele cometer um erro nas opções que estão instaladas em todas as máquinas, interrompe ou faz algo com as configurações das sub-redes, com o roteamento - isso é muito mais doloroso.
A seleção do repositório principal ocorre em várias etapas.
Etapa 1 . Crie um repositório separado. Armazene todo o código nele, separadamente - e descreva as entidades que devem ser reutilizadas em um repositório de terceiros usando essa saída. Digamos que criamos um recurso de sub-rede da AWS no qual descrevemos onde ele está localizado, qual zona de disponibilidade e espaço de endereço.
resource "aws_subnet" "lab_pub1a" { vpc_id = "${aws_vpc.lab.id}" cidr_block = "10.10.10.0/24" Availability_zone = "us-east-1a" ... } output "sn_lab_pub1a-id" { value = "${aws_subnet.lab_pub1a.id}" }
E então dizemos que enviamos o id deste objeto para a saída. Você pode fazer a saída para cada parâmetro que precisar.
Qual é o truque aqui? Quando você descreve um valor, o Terraform o salva separadamente no núcleo do estado. E quando você se volta para ele, ele não precisa sincronizar, recontar - ele poderá imediatamente lhe dar esse assunto a partir deste estado. Além disso, no repositório, que não é essencial, você descreve uma conexão com o estado remoto: você tem um estado remoto tal e tal, está no balde S3 tal e tal, tal e tal chave e região.
Etapa 2 . Em um projeto não básico, criamos um link para o estado do projeto principal, para que possamos nos referir aos parâmetros exportados pela saída.
data "terraform_remote_state" "lab_core" { backend = "s3" config { bucket = "lab-core-terraform-state" key = "terraform.tfstate" region = "us-east-1" } }
Etapa 3 . Começando! Quando preciso implantar uma nova interface de rede para uma instância em uma sub-rede específica, digo: aqui está o estado remoto dos dados, encontre o nome desse estado, encontre esse parâmetro nele, que, de fato, corresponde a esse nome.
resource "aws_network_interface" "fwl01" { ... subnet_id = "${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}" }
E quando eu construir um plano de mudanças no meu repositório não essencial, esse valor para o Terraform se tornará uma constante para ele. Se você deseja alterá-lo, é necessário fazê-lo no repositório deste, é claro, núcleo. Mas como isso raramente muda, não incomoda muito.
Módulos
Deixe-me lembrá-lo de que um módulo é uma configuração independente que consiste em um ou mais recursos relacionados. É gerenciado como um grupo:
Um módulo é uma coisa extremamente conveniente devido ao fato de você raramente criar um recurso assim, no vácuo, geralmente é logicamente conectado a algo.
module "AAA" { source = "..." count = "3" count_offset = "0" host_name_prefix = "XXX-YYY-AAA" ami_id = "${data.terraform_remote_state.lab_core.ami-base-ami_XXXX-id}" subnet_ids = ["${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}", "${data.terraform_remote_state.lab_core.sn_lab_pub1b-id}"] instance_type = "t2.large" sgs_ids = [ "${data.terraform_remote_state.lab_core.sg_ssh_lab-id}", "${aws_security_group.XXX_lab.id}" ] boot_device = {volume_size = "50" volume_type = "gp2"} root_device = {device_name = "/dev/sdb" volume_size = "50" volume_type = "gp2" encrypted = "true"} tags = "${var.gas_tags}" }
Por exemplo: quando implantamos uma nova instância do EC2, criamos uma interface de rede e anexamos a ela, geralmente criamos um endereço IP Elastic, gravamos o registro da rota 53 e algo mais. Ou seja, temos pelo menos 4 entidades.
Cada vez, descrevê-los em quatro partes do código é inconveniente. Além disso, eles são bastante típicos. Ele implora - crie um modelo e, em seguida, apenas consulte este modelo, passando parâmetros para ele: algum nome, em qual grade empurrar, qual grupo de segurança pendurar nele. É muito conveniente
Terraform possui um recurso Count, que permite reduzir ainda mais seu estado. Você pode descrever um grande pacote de instâncias com um pedaço de código. Digamos que eu precise implantar 20 máquinas do mesmo tipo. Eu não escreverei 20 pedaços de código mesmo de um modelo, escreverei 1 pedaço de código, indicarei Count e o número nele - quanto preciso fazer.
Por exemplo, existem alguns módulos que referenciam um modelo. Eu passo apenas parâmetros específicos: sub-rede de ID; AMI para implantar; tipo de instância; configurações de grupo de segurança; qualquer outra coisa e indique quantas dessas ações devem ser feitas comigo. Ótimo, pegou e virou!
Amanhã, os desenvolvedores vêm até mim e dizem: "Escute, queremos experimentar a carga, por favor, dê-nos mais duas." O que preciso fazer: altero um dígito para 5. A quantidade de código permanece exatamente a mesma.
Convencionalmente, os módulos podem ser divididos em dois tipos - recursos e infraestrutura. Do ponto de vista do código, não há diferença, mas os conceitos de nível superior que o próprio operador introduz.
Os módulos de recursos fornecem uma coleção de recursos padronizada, parametrizada e logicamente relacionada. O exemplo acima é um módulo de recurso típico. Como trabalhar com eles:
- Indicamos o caminho para o módulo - a fonte de sua configuração, através da diretiva Source.
- Indicamos a versão - sim, e a operação com o princípio de "mais recente e melhor" não é a melhor opção aqui. Você não inclui a versão mais recente da biblioteca todas as vezes em seu projeto? Mas mais sobre isso mais tarde.
- Passamos argumentos para ele.
Estamos anexados à versão do módulo e apenas o último - a infraestrutura deve ser versionada (os recursos não podem ser versionados, mas o código pode). Um recurso pode ser criado excluído ou recriado. Isso é tudo! Também devemos saber claramente qual versão criamos cada parte da infraestrutura.
Os módulos de infraestrutura são bastante simples. Eles consistem em recursos e incluem padrões da empresa (por exemplo, tags, listas de valores padrão, padrões aceitos etc.).
Quanto ao nosso projeto e nossa experiência, mudamos muito e firmemente o uso de módulos de recursos para tudo o que é possível com um processo de versão e revisão muito rigoroso. E agora estamos introduzindo ativamente a prática de módulos de infraestrutura no nível do laboratório e da preparação.
Recomendações para o uso de módulos
- Se você não pode escrever, mas usa os já prontos, não escreva. Especialmente se você é novo nisso. Confie nos módulos prontos ou pelo menos veja como eles fizeram isso com você. No entanto, se você ainda precisar escrever o seu, não use a chamada para provedores internamente e tenha cuidado com os provedores de serviços.
- Verifique se o Terraform Registry não contém um módulo de recursos pronto.
- Se você estiver escrevendo seu módulo, oculte os detalhes sob o capô. O usuário final não precisa se preocupar com o que e como você implementa internamente.
- Faça parâmetros de entrada e valores de saída do seu módulo. E é melhor se forem arquivos separados. Tão conveniente.
- Se você escrever seus módulos, armazene-os no repositório e na versão. Melhor um repositório separado para o módulo.
- Não use módulos locais - eles não são versionados ou reutilizados.
- Evite usar descrições de provedor no módulo, porque as credenciais de conexão podem ser configuradas e aplicadas de maneira diferente para pessoas diferentes. Alguém usa variáveis de ambiente para isso, e alguém implica armazenar suas chaves e segredos em arquivos com caminhos prescritos para eles. Isso deve ser indicado em um nível superior.
- Use o fornecedor local com cuidado. É executado localmente, na máquina em que o Terraform está sendo executado, mas o ambiente de execução para diferentes usuários pode ser diferente. Até você incorporá-lo no CI, você pode encontrar vários artefatos: por exemplo, exec local e executando ansible. E alguém tem uma distribuição diferente, outro shell, uma versão diferente do ansible ou mesmo do Windows.
Sinais de um bom módulo (aqui está um
pouco mais detalhado ):
- Bons módulos têm documentação e exemplos. Se cada um foi projetado como um repositório separado, é mais fácil fazer isso.
- Eles não têm configurações codificadas permanentemente (por exemplo, região da AWS).
- Use padrões razoáveis, projetados como padrões. Por exemplo, por padrão, o módulo para a instância do EC2 não criará uma máquina virtual do tipo m5d.24xlarge para você, ele usa um dos tipos mínimos de t2 ou t3 para isso.
- O código é "limpo" - estruturado, fornecido com comentários, não desnecessariamente confusos, projetado no mesmo estilo.
- É altamente desejável que seja equipado com testes, embora seja difícil. Infelizmente, ainda não chegamos a isso.
Marcação
Tags são importantes.
Etiquetar é faturar. A AWS possui ferramentas que permitem ver quanto dinheiro você gasta em sua infraestrutura. E nossa gerência realmente queria ter uma ferramenta na qual eles pudessem vê-la deterministicamente. Por exemplo, quanto dinheiro tais e tais componentes consomem, ou tal e tal subsistema, tal e tal equipe, tal e tal ambiente
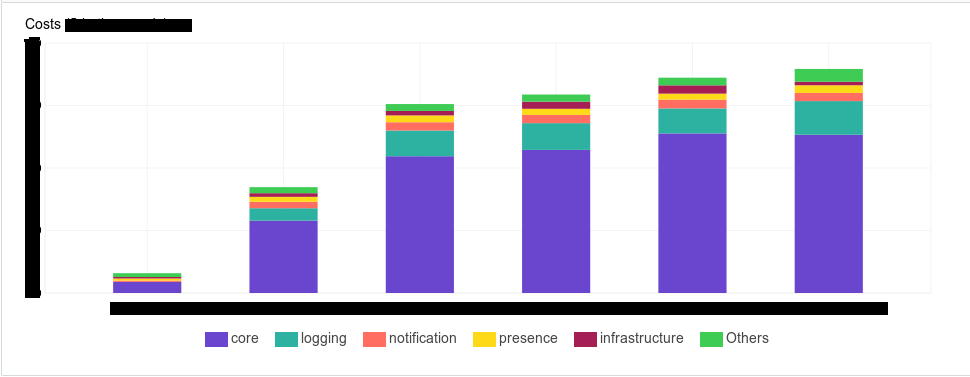
A marcação é a documentação do seu sistema. Com isso, você simplifica sua pesquisa. Mesmo apenas no console da AWS, onde essas tags são exibidas perfeitamente na tela, fica mais fácil entender a que esse ou aquele tipo de instância se refere. Se novos colegas vierem, é mais fácil explicar isso, mostrando: "Olha, é isso aqui." Começamos a criar tags da seguinte maneira - criamos uma matriz de tags para cada tipo de recurso.
Um exemplo:
variable "XXX_tags" { description = "The set of XXX tags." type = "map" default = { "TerminationDate" = "03.23.2018", "Environment" = "env_name_here", "Department" = "dev", "Subsystem" = "subsystem_name", "Component" = "XXX", "Type" = "application", "Team" = "team_name" } }
Aconteceu que em nossa empresa mais de uma de nossas equipes usa a AWS, e há uma lista de tags necessárias.
- Equipe - qual equipe usa quantos recursos.
- Departamento - semelhante a um departamento.
- Ambiente - os recursos batem em "ambientes", mas você, por exemplo, pode substituí-lo por um projeto ou algo assim.
- Subsistema - o subsistema ao qual o componente pertence. Os componentes podem pertencer a um subsistema. Por exemplo, queremos ver quanto temos este subsistema e suas entidades começaram a consumir. De repente, por exemplo, no mês anterior, ele cresceu significativamente. Precisamos ir até os desenvolvedores e dizer: “Pessoal, é caro. O orçamento já está próximo, vamos otimizar a lógica de alguma forma. ”
- Tipo - tipo de componente: balanceador, armazenamento, aplicativo ou banco de dados.
- Componente - o componente em si, seu nome em notação interna.
- Data de término - horário em que deve ser excluído, no formato da data. Se a remoção não for esperada, defina como "Permanente". Nós o introduzimos porque em ambientes de desenvolvimento, e mesmo em alguns estágios, temos um estágio de teste de estresse que aumenta durante as sessões de estresse, ou seja, não mantemos essas máquinas regularmente. Indicamos a data em que o recurso deve ser destruído. Além disso, você pode fixar a automação com base no lambda, alguns scripts externos que funcionam por meio da AWS Command Line Interface, que destruirão esses recursos automaticamente.
Agora - como marcar.
Decidimos que faríamos nosso próprio mapa de tags para cada componente, no qual listaríamos todas as tags especificadas: quando finalizá-lo, a que ele se refere. Eles rapidamente perceberam que era inconveniente. Porque a base de código está crescendo, porque temos mais de 30 componentes, e 30 desses trechos de código são inconvenientes. Se você precisar alterar alguma coisa, execute e altere.
Para marcar bem, usamos a entidade
Locals .
locals { common_tags = {"TerminationDate" = "XX.XX.XXXX", "Environment" = "env_name", "Department" = "dev", "Team" = "team_name"} subsystem_1_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_1_name"))}" subsystem_2_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_2_name"))}" }
Nele, você pode listar um subconjunto e usá-los um com o outro.
Por exemplo, removemos algumas tags comuns dessa estrutura e depois as específicas dos subsistemas. Dizemos: “Pegue esse bloco e adicione, por exemplo, o subsistema 1. E para o subsistema 2, adicione o subsistema 2”. Dizemos: "Tags, por favor, pegue as gerais e adicione tipo, aplicativo, nome, componente e quem é a elas". Acontece uma mudança muito breve, clara e centralizada, se de repente for necessária.
module "ZZZ02" { count = 1 count_offset = 1 name = "XXX-YYY-ZZZ" ... tags = "${merge(local.core_tags, map("Type", "application", "Component", "XXX"))}" }
Controle de versão
Seus módulos de modelo, se você os usar, devem ser armazenados em algum lugar. A maneira mais fácil que provavelmente todos iniciam é o armazenamento local. Apenas no mesmo diretório, apenas algum subdiretório no qual você descreve, por exemplo, um modelo para algum tipo de serviço. Este não é um bom caminho. É conveniente, pode ser rapidamente corrigido e testado rapidamente, mas é difícil reutilizá-lo mais tarde e difícil de controlar
module "ZZZ02" { source = "./modules/srvroles/ZZZ" name = "XXX-YYY-ZZZ" }
Suponha que os desenvolvedores tenham procurado você e dito: "Então, precisamos de uma entidade dessas e de uma configuração dessas em nossa infraestrutura". Você escreveu, fez na forma de um módulo local no repositório do projeto deles. Implantado - excelente. Eles testaram, disseram: “Vai! Em produção. " Chegamos ao palco, testes de estresse, produção. Cada vez que Ctrl-C, Ctrl-V; Ctrl-C, Ctrl-V. Enquanto chegávamos à venda, nosso colega pegou, copiou o código do ambiente do laboratório, transferiu para outro local e o mudou para lá. E temos um estado já inconsistente. Com a escala horizontal, quando você tem tantos ambientes de laboratório quanto os nossos, é apenas uma loucura.
Portanto, uma boa maneira é criar um repositório Git separado para cada um dos seus módulos e depois apenas fazer referência a ele. Mudamos tudo em um só lugar - bom, conveniente, controlado.
module "ZZZ" { source = "git::ssh://git@GIT_SERVER_FQDN/terraform/modules/general-vm/2-disks.git" host_name_prefix = "XXX-YYY-ZZZ"
Antecipando a pergunta, como seu código alcança a produção. Para isso, é criado um projeto separado que reutiliza os módulos preparados e testados.
Ótimo, temos uma fonte de código que muda centralmente. Peguei, escrevi, preparei e me preparei para amanhã de manhã que vou implantar na produção. Construiu um plano, testado - ótimo, vamos lá. Nesse momento, meu colega, guiado exclusivamente por boas intenções, foi e otimizou algo, adicionado a este módulo. E aconteceu que essas alterações quebram a compatibilidade com versões anteriores.
Por exemplo, ele adicionou os parâmetros necessários, os quais ele deve passar, caso contrário o módulo não será montado. Ou ele mudou os nomes desses parâmetros. Eu chego de manhã, tenho tempo estritamente limitado para mudanças, começo a construir um plano, e a Terraform pega módulos de estado do Git, começa a construir um plano e diz: "Opa, não posso. Não é o suficiente para você, você renomeou. " Estou surpreso: "Mas não fiz, como lidar com isso?" E se esse é um recurso criado há muito tempo, após essas alterações, você terá que percorrer todos os ambientes, de alguma forma, mudar e levar a uma olhada. Isso é inconveniente.
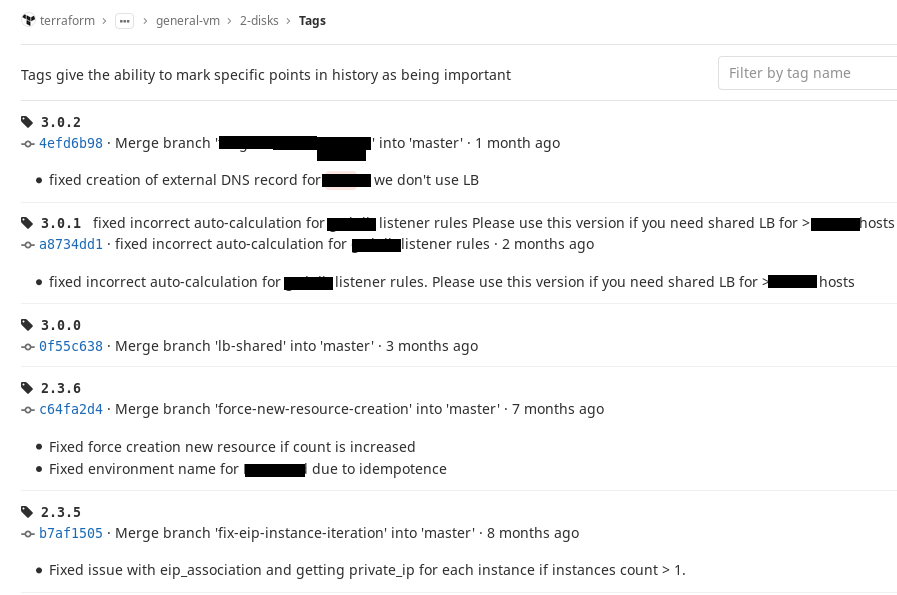
Isso pode ser corrigido usando tags Git. Decidimos por nós mesmos que
usaríamos a notação SemVer e
elaboramos uma regra simples: assim que a configuração do nosso módulo atingir um certo estado estável, ou seja, podemos usá-lo, colocamos um tag nesse commit. Se fizermos alterações e elas não quebrarem a compatibilidade com versões anteriores, alteramos o número menor na tag; se elas quebrarem, alteramos o número principal.
Portanto, no endereço de origem, anexe-o a uma tag específica e, se pelo menos forneça algo que você tinha antes, ela sempre será coletada. Deixe a versão do módulo seguir em frente, mas no momento certo chegaremos e, quando realmente precisarmos, mudaremos. E o que estava funcionando antes disso, pelo menos, não vai quebrar. Isso é conveniente. É assim que parece no nosso GitLab.
Ramificação
Usar ramificação é outra prática importante. Nós desenvolvemos uma regra para nós mesmos de que você deve fazer alterações somente do mestre. Mas, para qualquer alteração que você queira fazer e testar, faça um ramo separado, brinque com ele, experimente, faça planos e veja como está indo. E, em seguida, faça uma solicitação de mesclagem e deixe um colega ver o código e ajudar.

Onde armazenar tfstate
Você não deve armazenar seu estado localmente. Você não deve armazenar seu estado no Git.
Ficamos impressionados com isso quando alguém, ao lançar os galhos de um não-mestre, obtém seu estado, no qual o estado é salvo - então ele o ativa por meio de mesclagem, alguém adiciona o seu, resultando em conflitos de mesclagem. Ou acontece sem eles, mas um estado inconsistente, porque "ele já o possui, ainda não o tenho", e consertar tudo isso é uma prática desagradável. Portanto, decidimos armazená-lo em um local seguro, com versão, mas estaria fora do Git.
O S3 se encaixa perfeitamente com isso: está disponível, possui HA, tanto quanto me lembro
exatamente quatro noves, talvez cinco . Ele fornece versões prontas para uso, mesmo que você quebre seu estado, você sempre poderá reverter. E ele também dá uma coisa muito importante em combinação com o DynamoDB, que, na minha opinião, aprendeu esse Terraform desde a versão 0.8. No DynamoDB, você tem uma placa de identificação na qual o Terraform registra que está bloqueando o estado.
Ou seja, suponha que eu queira fazer algumas alterações. Estou começando a construir um plano ou a aplicá-lo, o Terraform acessa o DynamoDB e diz que informa nesta placa que esse estado está bloqueado; usuário, computador, hora. Nesse momento, meu colega, que trabalha remotamente ou talvez em algumas mesas minhas, mas se concentrou no trabalho e não vê o que estou fazendo, também decidiu que algo precisa ser mudado. Ele faz um plano, mas o lança um pouco mais tarde.
O Terraform entra na dinâmica, vê - Bloqueia, interrompe e diz ao usuário: "Desculpe, o estado está bloqueado por alguma coisa". Um colega vê que estou trabalhando agora, pode vir até mim e dizer: "Escute, meu trocador é mais importante, ceda a mim, por favor". Eu digo: “Bom”, cancelo o plano, retiro o bloco; até mesmo ele é removido automaticamente se você o fizer corretamente, sem interromper o Ctrl-C. Um colega vai e faz. Assim, nos seguramos contra uma situação em que vocês dois estão mudando alguma coisa.
Solicitação de mesclagem
Usamos ramificação no Git. Atribuímos nossos pedidos de mesclagem aos colegas. Além disso, no Gitlab, usamos quase todas as ferramentas disponíveis para trabalharmos juntas, para solicitações de mesclagem ou até mesmo alguns pools: discutir seu código, revisá-lo, definir andamento ou questão, algo assim. É muito útil, ajuda no trabalho.
Além disso, nesse caso, a reversão também é mais fácil, você pode retornar ao commit anterior ou, se você disser que decidiu não apenas aplicar as alterações do assistente, pode simplesmente mudar para um branch estável. Por exemplo, você fez uma ramificação de recurso e decidiu que faria as alterações primeiro a partir da ramificação de recurso. E então as mudanças, depois que tudo funcionou bem, fazem para o mestre. Você aplicou as alterações em sua filial, percebeu que algo estava errado, mudou para o mestre - nenhuma alteração, disse aplicar - ele retornou.
Tubulações
Decidimos que precisávamos usar o processo de IC para aplicar nossas alterações. Para fazer isso, com base no Gitlab CI, estamos escrevendo um pipeline que automatiza a aplicação de alterações. Até agora, temos dois tipos deles:
- Pipeline para a ramificação mestre (pipeline mestre)
- Pipeline para todas as outras filiais (pipeline da filial)
O que o pipeline de brunch faz? ( , ). . , merge-request, — , . . .
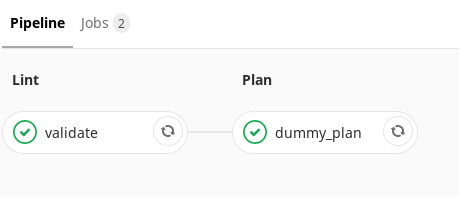
. , , . Terraform- , , . , merge-request . . . , , , .
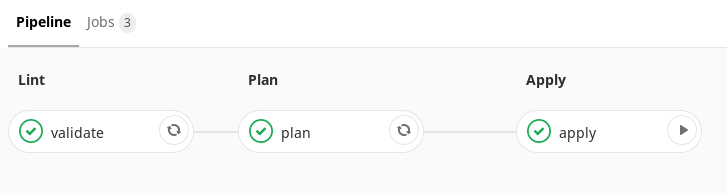
, . .
Terraform
. Terraform , , .
, «» — , .
, , count — , , , , availability-. , , , . . , AZ . , count .
, 4 AZ 5 , AZ — 4, , . : « ». ! , . Terraform .
. —
. . - - If Else. , — , .
. , , , , Terraform- , CI.
CI . , , , — merge, . .
, . . , , Terraform , , tfstate Terraform : «, , ». , , .
CI, , pipeline — , .
, . , . , target , . , : «Terraform apply target instance», -. - (, - ), .
, . . CI — , Terraform , . , - . , , , . .
Terraform —
:
- Terraform , . , , . , , , . , , , .
, — Tfstate, , . . « , » — .
, -, , - — . , . , — . - Terraform , . Terraform . Porque , . . , , AZ - -. , North Virginia, 6 . . , , : «, ». — . — , , Terraform .
- Terraform . , — 200 , 198 , 5. . , API . Infelizmente.
- , . , S3 bucket. , — , - . Terraform – , , : «, - ». . - , .
, Terraform — , . , .