
Olá colegas! Como destacar os principais tópicos de 20.000 notícias em 30 segundos? Visão geral da modelagem temática que realizamos no TASS, com posicionamentos e código.
Para começar, as informações apresentadas nesta nota fazem parte de um protótipo que está sendo desenvolvido no Laboratório Digital ITAR-TASS, a fim de manter a digitalização dos negócios. As soluções estão melhorando constantemente. Descreverei a seção atual, obviamente não será a coroa da criação, mas um suporte para desenvolvimentos futuros.
Grande ideia
Além da agenda de notícias, na qual os escritórios editoriais da TASS trabalham diariamente, é bom entender quais tópicos mais criam o histórico de notícias na mídia online russa. Para esse fim, coletamos as últimas notícias dos 300 sites mais populares a cada poucos minutos, 24/7; então o mais interessante vem - a escolha de métodos e experimentos de modelagem.
Quando a sessão mágica terminar, meus colegas, editores e gerentes começarão a usar o relatório com tópicos de notícias. Acredito que para pessoas fora da área de desenvolvimento de software e ciência de dados, o processamento, análise e visualização automáticos de dados de texto parecem um pouco mágicos. Devido à alienação de uma pessoa da alta tecnologia, várias imperfeições em seu trabalho podem levar à falta de entendimento do que há dentro e da decepção. Para minimizar a reação negativa, tento tornar o produto mais simples e confiável. E entender a essência da modelagem temática pode ser reduzido ao fato de que as notícias relacionadas a um tópico e diferentes das notícias em qualquer outro tópico pertencem a um tópico.
Venho experimentando modelagem temática há cerca de um ano. Infelizmente, a maioria das abordagens que tentei me deu uma qualidade muito duvidosa de preencher tópicos de notícias. Ao mesmo tempo, realizei ações de acordo com a lógica da seleção de parâmetros nos métodos das bibliotecas populares de armazenamento em cluster. Mas eu não tenho um conjunto de dados rotulado. Portanto, sempre que olho para uma seleção de textos que se enquadram em um tópico específico. O caso é bastante triste e não agradecido.
Uma particular importância dessa tarefa é que vários especialistas, observando as notícias incluídas no tópico selecionado, as acharão inadequadas ou não. Por exemplo, as notícias com a declaração de Erdogan sobre o início da operação na Síria e as notícias com os primeiros relatórios após o início da operação na Síria podem ser entendidas como um ou vários tópicos. Consequentemente, a mídia, citando a TASS ou outra agência de notícias, escreverá uma série de textos sobre isso e aquilo. E o resultado do meu algoritmo tenderá a combiná-los ou separá-los com base no ... cosseno do ângulo entre os vetores de frequência das palavras, o número de a priori aceito ou o raio no método de encontrar os vizinhos mais próximos.
Em geral, toda essa grande idéia é tão frágil quanto bonita.
Por que análise fatorial?
Uma análise mais detalhada dos métodos de agrupar textos mostra que cada um deles é baseado em várias suposições. Se as suposições não corresponderem ao problema que está sendo estudado, o resultado poderá levar fortemente ao lado. As suposições da análise fatorial parecem-me - e a muitos outros pesquisadores - próximas da tarefa de modelar tópicos.
Criada no início do século XX, essa abordagem foi baseada na idéia de que, além das variáveis que caracterizam as observações da amostra, existem fatores ocultos que, falando de maneira informal, se correlacionam com algumas variáveis observáveis. Por exemplo, as respostas para a pergunta “Você acredita em Deus” e “Você vai à igreja” coincidem bastante do que diferem. Pode-se supor que exista um “fator de religiosidade”, que se manifesta em um conjunto de variáveis inter-relacionadas. Ao mesmo tempo, há também a oportunidade de medir a força com que as variáveis estão relacionadas ao fator oculto.
Para textos, a declaração do problema passa a ser a seguinte. Nas notícias que descrevem o mesmo tópico, as mesmas palavras ocorrerão. Por exemplo, as palavras "Síria", "Erdogan", "Operação", "EUA", "Condenação" serão encontradas com mais frequência nas notícias que são dedicadas ao envio de intervenções militares pela Turquia na Síria e a reação que os Estados Unidos têm a esse respeito ( como ator geopolítico no mesmo território).
Resta pescar todos os fatores importantes da agenda de notícias por um período. Estes serão tópicos de notícias. Mas isso não é tudo ...
Um pouco de matemática
Para pessoas com experiência em técnicas de modelagem de assuntos, posso fazer essa afirmação. A versão da análise fatorial que eu tentei é uma versão altamente simplificada da
metodologia ARTM .
Mas decidi experimentar métodos em que há menos graus de liberdade, para que o que acontece lá dentro seja melhor compreendido.
(Big) ARTM cresceu a partir de pLSA, análise semântica latente probabilística, que, por sua vez, foi uma alternativa ao LSA com base em uma decomposição de matriz singular - SVD.
A análise dos fatores de inteligência vai além do SVD, pois fornece uma "estrutura simples" da relação entre variáveis e fatores, que pode não ser uma questão simples para SVD, mas é limitada, pois não é projetada para calcular com precisão os valores dos fatores (pontuações), existem vetores de valores de fatores que podem substituir 2 ou mais variáveis observáveis.
Formalmente, a tarefa de análise de fatores de inteligência é a seguinte:
Onde estão as variáveis observadas
linearmente relacionado a fatores ocultos
Precisa encontrar
Isso é tudo! Esses coeficientes beta são chamados de cargas no mundo da análise fatorial. Considere a importância deles um pouco mais tarde.
Para chegar ao resultado da análise, pode-se mover de várias maneiras. Um deles que usei é encontrar os principais componentes no sentido clássico, que depois rodam para destacar a "estrutura simples". Os principais componentes são extraídos da decomposição singular da matriz ou da decomposição da matriz de covariância variacional em autovetores e valores. O problema também é resolvido maximizando a função de probabilidade. Em geral, a análise fatorial é um grande "zoológico" de métodos, pelo menos 10 que dão resultados diferentes, e é recomendável escolher o método que melhor se adequa à tarefa.
A rotação da matriz de carga também pode ser feita de diferentes maneiras, tentei varimax - rotação ortogonal.
Por que tudo é tão complicado?O fato é que, entre estatísticos e candidatos, a discussão não para sobre as diferenças e semelhanças do método dos principais componentes, análise fatorial e sua combinação. A metodologia é reabastecida com novos conhecimentos, mesmo depois de mais de 100 anos a partir do momento da descoberta. Um estatístico respeitado me trouxe a seguinte imagem para facilitar o entendimento com as palavras: "É isso, resolva isso".
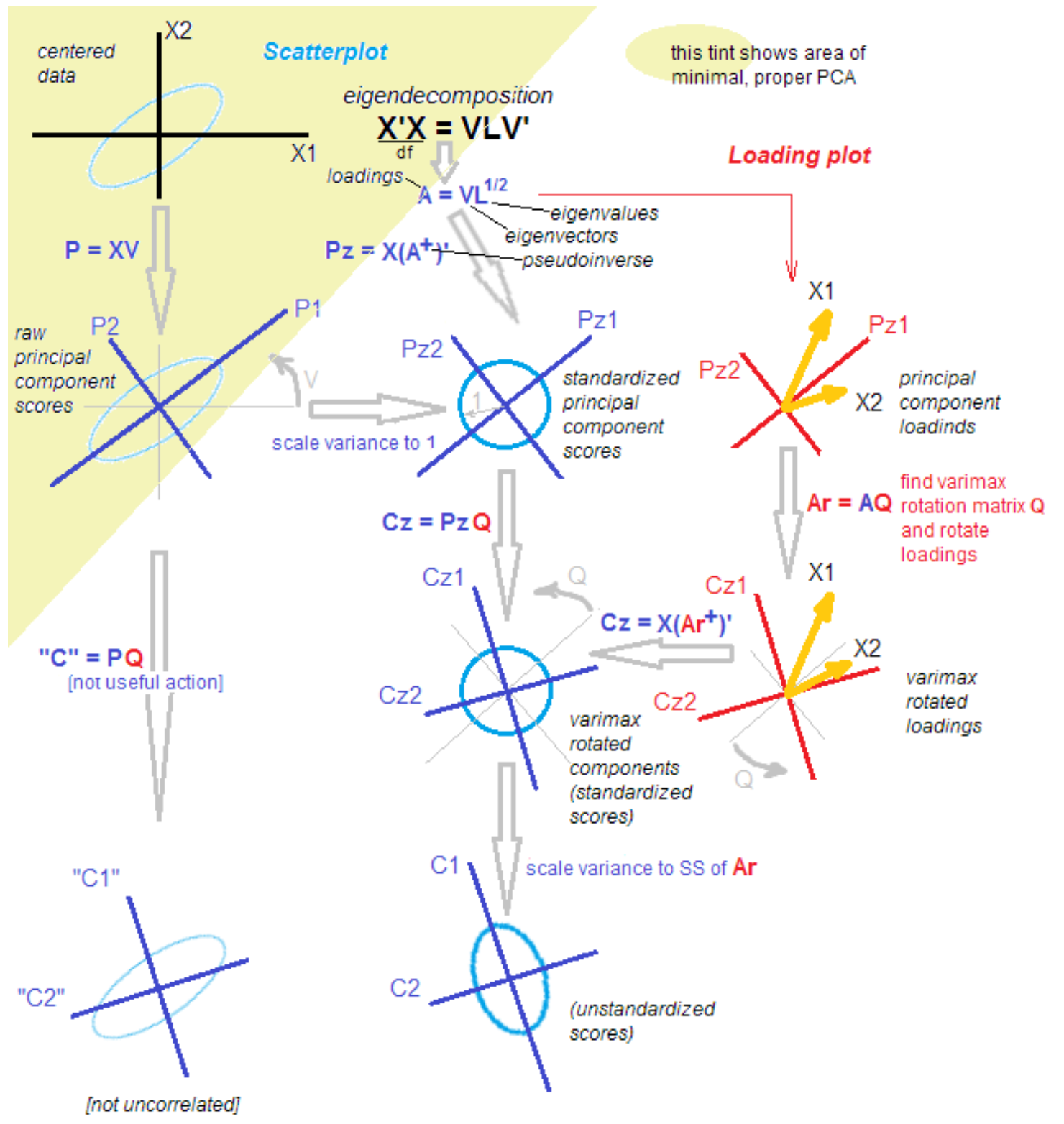 fonte
fonte .
Tudo resolvido!
Brincadeira). Para entender as próximas etapas, basta que, depois de isolar os principais componentes, os rotacionemos, passando de explicar a variação nas variáveis até explicar a covariância de variáveis e fatores.
Além disso, faço tudo isso usando funções atômicas, e não apenas pressionando um "grande botão vermelho". Essa abordagem nos permite entender a transformação nos dados em estágios intermediários.
Para onde foi a LDA?
UpdateDecidi acrescentar meus pensamentos sobre os arranjos latentes de Dirichlet. Eu tentei esse método popular, mas não consegui obter um resultado limpo em pouco tempo. Exemplos simples de como usá-lo e o “Vamos dividir as notícias em política, economia e cultura” realmente funcionam, mas ... No meu caso, tenho que dividir, digamos, a política em 50 tópicos durante o dia, onde Rússia, Putin e Irã estarão , e tópicos estreitos como "a libertação de Kokorin e Mamaev". Tudo isso, de fato, 1-2 notícias da agência de notícias, citou várias dezenas de vezes na mídia.
Além disso, a suposição sobre a natureza dos dados, característica da hipótese de que cada texto é uma distribuição de probabilidade por tópico, me parece um pouco artificial no contexto do meu trabalho. Nenhum editor concorda que as notícias da “demissão do caso contra Golunov” sejam uma mistura de temas. Para nós, este é um tópico. Talvez, escolhendo os hiperparâmetros, seja possível obter essa fragmentação do LDA, deixarei essa pergunta para o futuro.
Código
Eu mexo na linguagem R novamente, então esse pequeno experimento será ariano.
Trabalhamos com 3 pares de valores aleatórios correlacionados. Este conjunto contém 3 fatores ocultos - apenas para maior clareza.
set.seed(1) x1 = rnorm(1000) x2 = x1 + rnorm(1000, 0, 0.2) x3 = rnorm(1000) x4 = x3 + rnorm(1000, 0, 0.2) x5 = rnorm(1000) x6 = x5 + rnorm(1000, 0, 0.2) dt <- data.frame(cbind(x1,x2,x3,x4,x5,x6)) M <- as.matrix(dt) sing <- svd(M, nv = 3) loadings <- sing$v rot <- varimax(loadings, normalize = TRUE, eps = 1e-5) r <- rot$loadings loading_1 <- r[,1] loading_2 <- r[,2] loading_3 <- r[,3] plot(loading_1, type = 'l', ylim = c(-1,1), ylab = 'loadings', xlab = 'variables'); lines(loading_2, col = 'red'); lines(loading_3, col = 'blue'); axis(1, at = 1:6, labels = rep('', 6)); axis(1, at = 1:6, labels = paste0('x', 1:6))
Temos a seguinte matriz de carga:
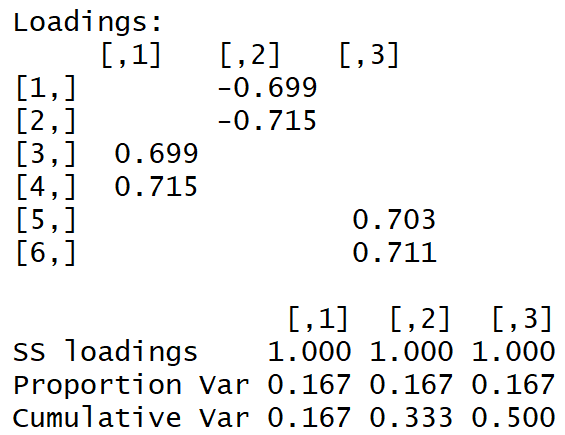
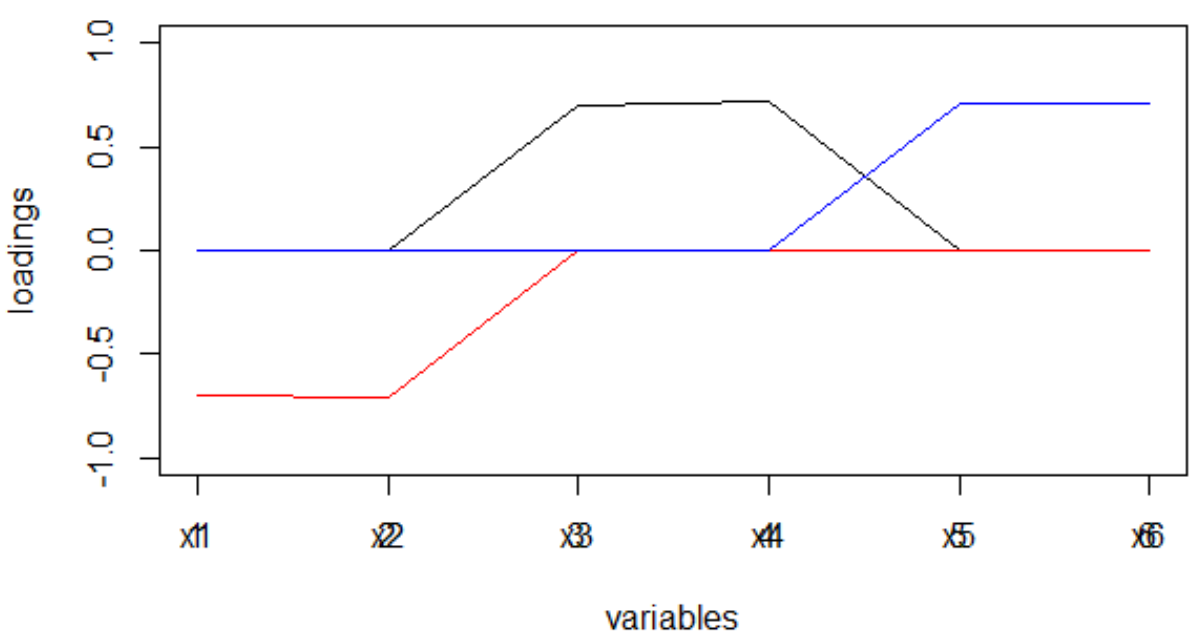
A "estrutura simples" é visível a olho nu.
E aqui está como as cargas pareciam logo após a conclusão do MGK:
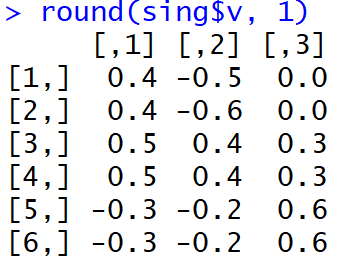
Não é muito fácil para as pessoas entenderem quais fatores estão associados a quais variáveis. Além disso, esses pesos, tomados no módulo e na interpretação da máquina, levarão a uma distribuição muito estranha de palavras sobre tópicos.
Mas, bo !, A parcela da dispersão explicada nos três primeiros componentes principais (antes da rotação) atingiu 99%.

E as notícias?
Para notícias, nossas variáveis x1, x2 ... xm se tornam a frequência (ou tf-idf) da ocorrência do token no texto. Há muitas palavras! Por exemplo, 50.000 palavras únicas por semana são normais. O bi-grama será ainda maior, compreensivelmente. A complexidade da decomposição singular é a média:
Ou seja, é enorme. A decomposição de uma matriz de 20.000 * 50.000 valores em um fluxo leva várias horas ...
Para poder ler os tópicos em tempo real e exibir o Shiny no painel, cheguei aos seguintes cortes dolorosos:
- 10% das palavras mais comuns
- seleção aleatória de textos de acordo com a fórmula autorrealizável:
onde n é todos os textos.
Como resultado, eu processo dados semanais em 30 segundos, um dia em 5 segundos. Nada mal! Mas você deve entender que as novas tendências são capturadas apenas pelos mais bem alimentados.
Tendo recebido cargas, as quais, observo, são estimativas da covariância das variáveis observadas com os fatores, libero-as do sinal (através do módulo, não através do grau), que tende a mudar dependendo do método de rotação utilizado.
Lembre-se de como a matriz de carga diferiu após a realização do MHC e após a rotação com varimax. A escassez das cargas, bem como o fato de que sua dispersão para cada fator foi maximizada: há muito grandes e muito pequenos, levará ao fato de que as palavras serão distribuídas entre os fatores com bastante clareza, o que, por sua vez, levará a mais e a distribuição de fatores no texto da notícia terá um pico pronunciado.
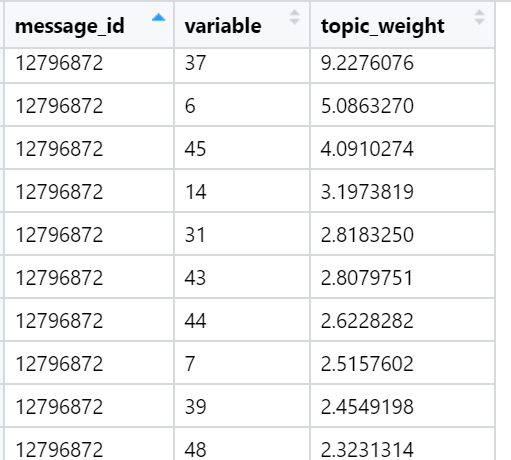
Exemplos das palavras mais carregadas em vários tópicos encontrados (selecionados aleatoriamente):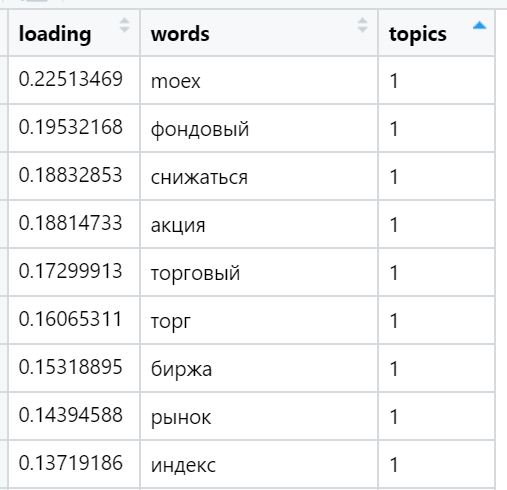
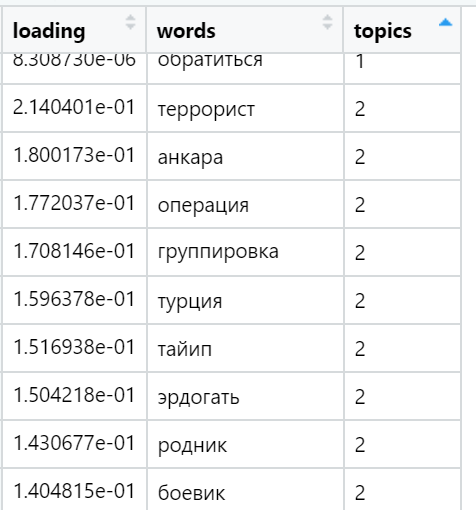

E, finalmente, considero a soma das cargas nos textos em relação a cada fator. As vitórias mais fortes: para cada texto, é selecionado um fator cuja soma de cargas é maximizada - levando em consideração o número de palavras incluídas no documento, que - como fornecemos durante a rotação - têm uma distribuição muito desigual entre os fatores de carga. Nesta iteração, todos os textos (n) já estão envolvidos, ou seja, a amostra completa.
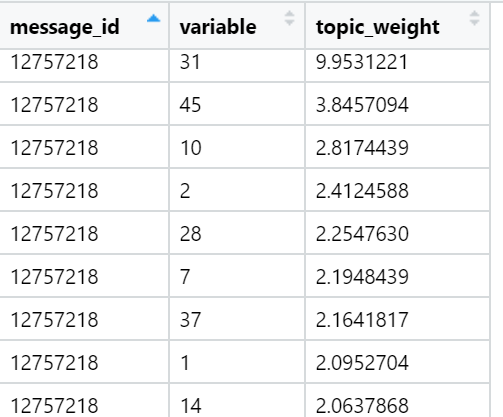
Exemplos de tópicos que são os principais em termos da soma de cargas em textos de notícias específicos (selecionados aleatoriamente):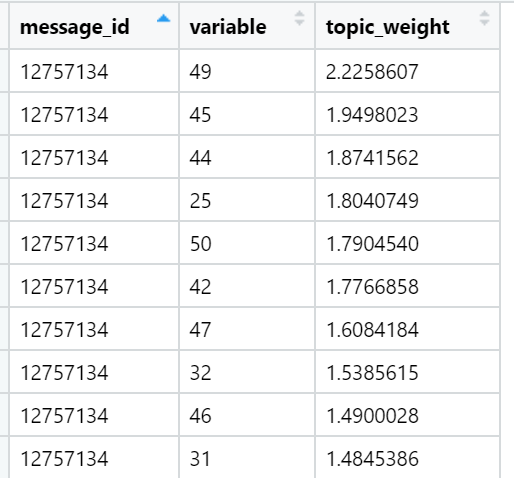
 O resultado para hoje.
O resultado para hoje. Informações adicionais.
Informações adicionais.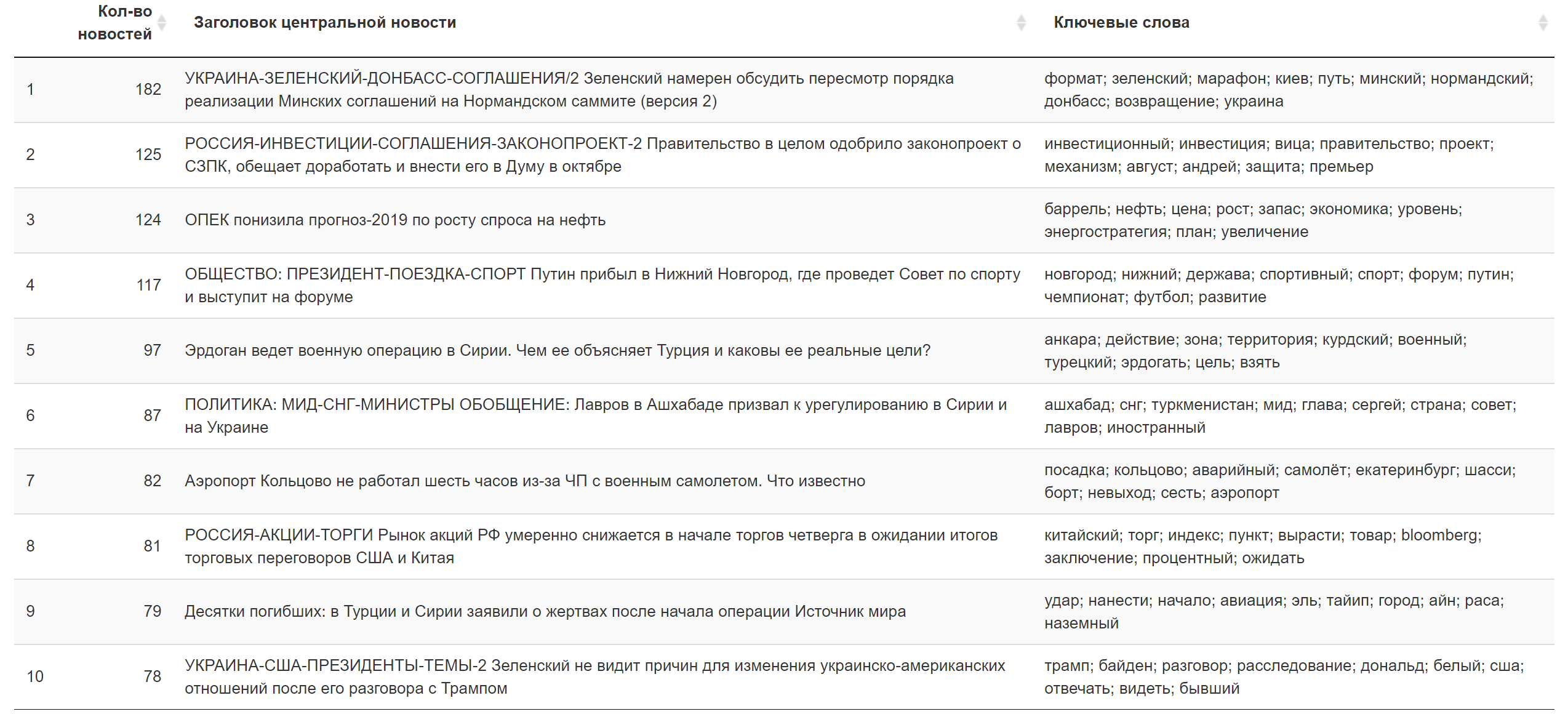
O que fazer
Aqui, a primeira coisa que farei quando ... Em geral, quando a inspiração vier, tentarei configurar o trabalho para o treinamento horário de uma rede neural com pescoço estreito, o que me dará uma aproximação não linear de fatores - componentes principais distorcidos - na forma de neurônios da camada oculta. Em teoria, o aprendizado pode ser feito rapidamente usando o aumento da velocidade de aprendizado. Depois disso, os pesos da camada oculta (de alguma forma normalizada) desempenharão o papel de cargas de token. Eles já podem ser carregados rapidamente no ambiente de processamento final a uma velocidade aceitável. Talvez esse truque possa levar ao fato de que a semana será processada em todos os textos em 10 segundos: o tempo normal para um caso tão difícil.
Em suma, isso é tudo que eu queria cobrir. Espero que esta breve excursão ao método de modelagem de tópicos permita que você entenda melhor o que está sendo feito sob o "grande botão vermelho", reduza a alienação da tecnologia e traga satisfação. Se você já sabia disso, ficarei feliz em ouvir as opiniões de um senso técnico ou de produto. Nosso experimento está evoluindo e mudando o tempo todo!