- Qual o tamanho de um cluster que eu preciso?
- Bem, depende ... (risada zangada)
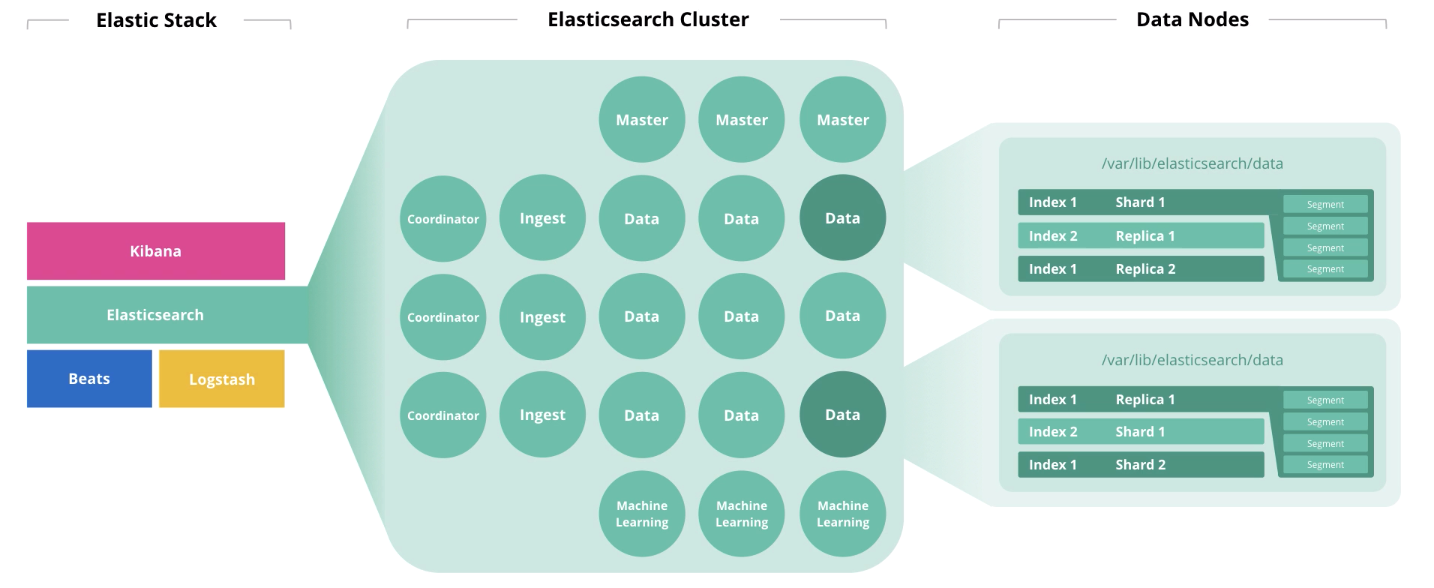
O Elasticsearch é o coração do Elastic Stack, no qual toda a magia dos documentos ocorre: emissão, recebimento, processamento e armazenamento. O desempenho depende do número correto de nós e da arquitetura da solução. E o preço, a propósito, também, se sua assinatura for Gold ou Platinum.
As principais características do hardware são disco (armazenamento), memória (memória), processadores (computação) e rede (rede). Cada um desses componentes é responsável pela ação que o Elasticsearch executa nos documentos, que são, respectivamente, armazenamento, leitura, computação e recebimento / transmissão. Vamos falar sobre os princípios gerais de dimensionamento e revelar o próprio "depende". E no final do artigo há links para webinars e artigos relacionados. Vamos lá!
Este artigo é baseado no
dimensionamento e no planejamento de capacidade do webinar de David Moore . Complementamos seu raciocínio com links e comentários para torná-lo um pouco mais claro. No final do artigo, uma faixa bônus é um link para materiais elásticos para quem deseja mergulhar melhor no tópico. Se você tem uma boa experiência com o Elasticsearch, compartilhe nos comentários como criar um cluster. Nós e todos os colegas estaríamos interessados em saber sua opinião.
Arquitetura e operações do Elasticsearch
No início do artigo, falamos sobre quatro componentes que formam o hardware: disco, memória, processadores e rede. A função de um nó afeta o descarte de cada um desses componentes. Um nó pode executar várias funções ao mesmo tempo, mas com o crescimento do cluster, essas funções devem ser distribuídas entre nós diferentes.
Nós mestres monitoram a integridade do cluster como um todo. No trabalho do nó mestre, um quorum deve ser observado, ou seja, seu número deve ser ímpar (talvez 1, mas melhor 3).
Nós de dados executam funções de armazenamento. Para aumentar o desempenho do cluster, os nós devem ser divididos em
"quente", "quente" e "frio" (congelado) . O primeiro é para acesso online, o segundo para armazenamento e o terceiro para arquivamento. Assim, para "quente" é razoável usar unidades SSD locais, e para HDD "quente" e "frio" é adequado localmente ou em SAN.
Para determinar a capacidade de armazenamento dos nós para armazenamento, a Elastic recomenda o uso da seguinte lógica: "quente" → 1:30 (30 GB de espaço em disco por gigabyte de memória), "quente" → 1: 100, "frio" → 1: 500). Sob o
JVM Heap, não mais que 50% da memória total e não mais que 30 GB para evitar o ataque ao coletor de lixo. A memória restante será usada como cache do sistema operacional.
Os indicadores de desempenho da instância do Elastisearch, como
conjuntos de threads e filas de threads, são mais afetados pela
utilização do núcleo do processador. Os primeiros são formados com base nas ações que o nó executa: pesquisa, análise, gravação e outras. O segundo é a fila de solicitações correspondentes de vários tipos. O número de processadores Elasticsearch disponíveis para uso é determinado automaticamente, mas você pode especificar esse valor manualmente nas configurações (pode ser útil quando houver 2 ou mais instâncias do Elasticsearch em execução no mesmo host). O número máximo de conjuntos de threads e filas de threads de cada tipo pode ser definido nas configurações. A métrica de conjuntos de encadeamentos é a principal métrica de desempenho do Elasticsearch.
Os nós de entrada recebem informações dos coletores (Logstash, Beats, etc.), realizam conversões neles e gravam no índice de destino.
Nós de aprendizado de máquina destinam-se à análise de dados. Como escrevemos no
artigo sobre aprendizado de máquina no Elastic Stack , o mecanismo é escrito em C ++ e funciona fora da JVM, na qual o próprio Elasticsearch está girando, portanto, é razoável executar essas análises em um nó separado.
Os nós do coordenador aceitam uma solicitação de pesquisa e a encaminham. A presença desse tipo de nó acelera o processamento de consultas de pesquisa.
Se considerarmos a carga nos nós em termos de capacidade de infraestrutura, a distribuição será algo como isto:
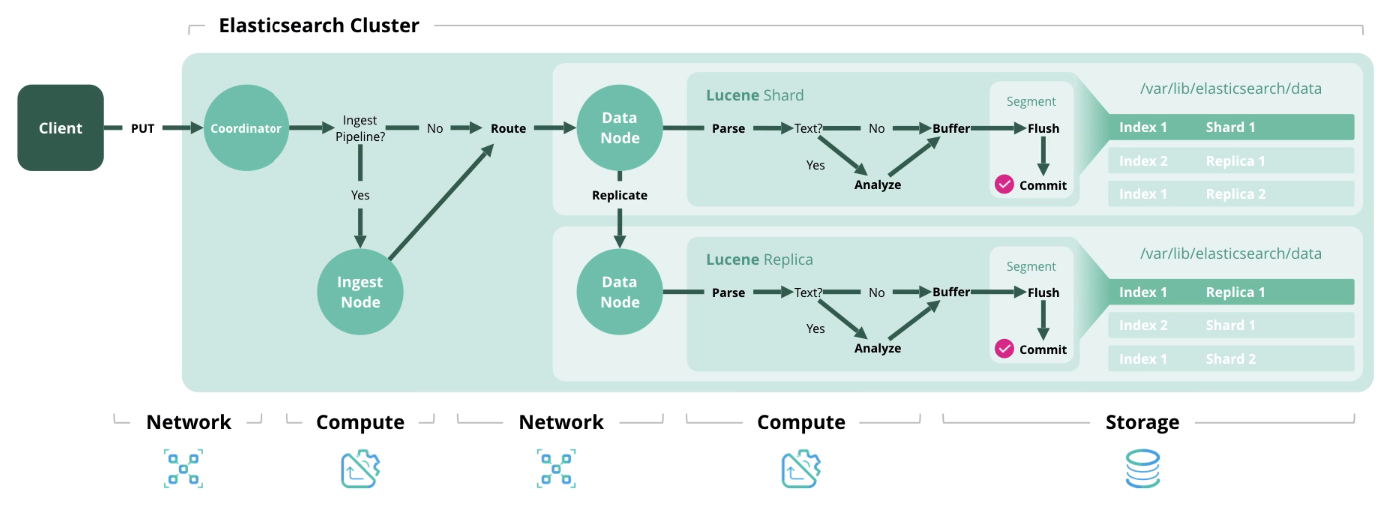
A seguir, apresentamos 4 tipos principais de operações no Elasticsearch, cada um dos quais requer um determinado tipo de recurso.
Índice - processando e salvando um documento no índice. O diagrama abaixo mostra os recursos utilizados em cada estágio.
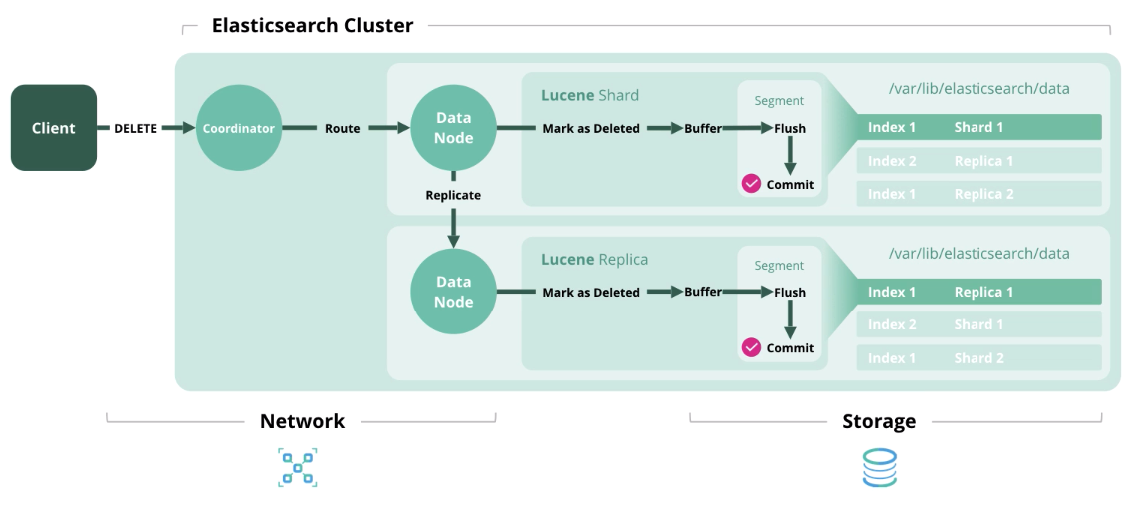
 Excluir
Excluir - exclua um documento do índice.
 Atualizar
Atualizar - funciona como Index e Delete, porque os documentos no Elasticsearch são imutáveis.
Pesquisa - obtendo um ou mais documentos ou sua agregação de um ou mais índices.
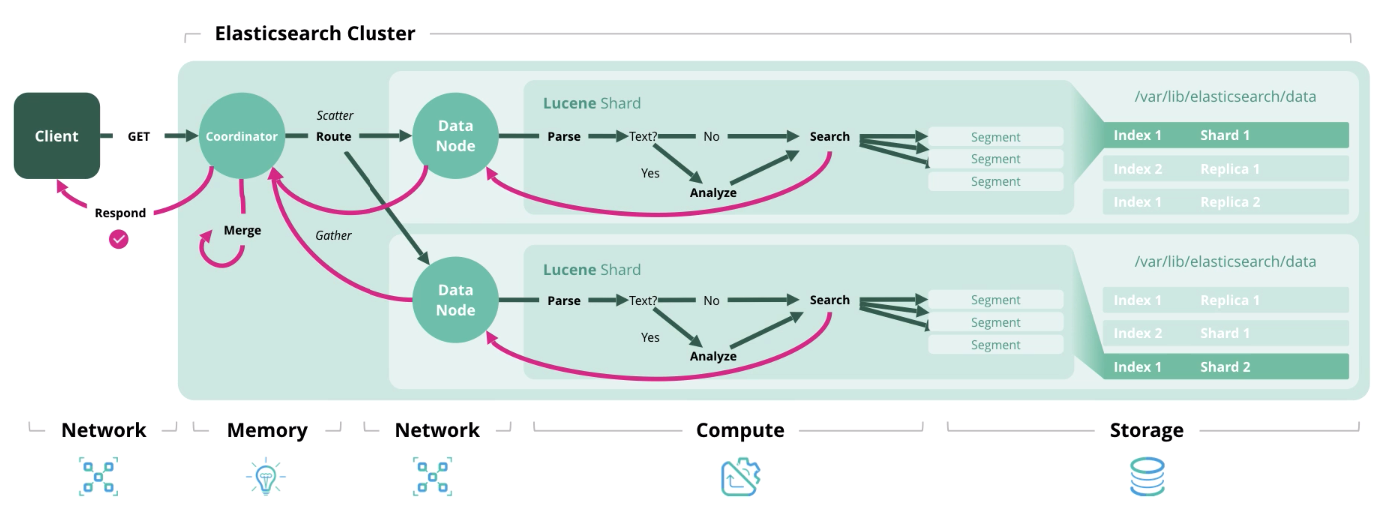
Nós descobrimos a arquitetura e os tipos de cargas, agora vamos para a formação de um modelo de dimensionamento.
Dimensionamento Elasticsearch e perguntas antes de sua formação
A Elastic recomenda o uso de duas estratégias de dimensionamento: orientada ao armazenamento e taxa de transferência. No primeiro caso, os recursos de disco e a memória são de suma importância e, no segundo, memória, potência do processador e rede.
Dimensionamento da arquitetura do Elasticsearch com base no tamanho do armazenamento
Antes dos cálculos, obtemos os dados iniciais. Necessidade:
- A quantidade de dados brutos por dia;
- O período de armazenamento de dados em dias;
- Fator de Transformação de Dados (fator json + fator de indexação + fator de compressão);
- Número de replicação de fragmento;
- A quantidade de nós de dados da memória;
- A proporção de memória para dados (1:30, 1: 100, etc.).
Infelizmente, o fator de transformação de dados é calculado apenas empiricamente e depende de várias coisas: o formato dos dados brutos, o número de campos nos documentos, etc. Para descobrir, você precisa carregar uma parte dos dados de teste no índice. Sobre o tema de tais testes, há um
vídeo interessante da conferência e uma
discussão na comunidade Elastic . Em geral, você pode deixá-lo igual a 1.
Por padrão, o
Elasticsearch compacta dados usando o algoritmo LZ4, mas também há DEFLATE, que pressiona 15% a mais. Em geral, é possível obter uma compressão de 20 a 30%, mas isso também é calculado empiricamente. Ao alternar para o algoritmo DEFLATE, a carga na energia da computação aumenta.
Ainda existem recomendações adicionais:
- Deposite 15% para ter uma reserva em espaço em disco;
- Prometer 5% para necessidades adicionais;
- Estabeleça 1 equivalente a um nó de dados para garantir uma migração rápida.
Agora vamos para as fórmulas. Não há nada complicado aqui e, acreditamos, será interessante verificar seu cluster quanto à conformidade com essas recomendações.
Quantidade total de dados (GB) = Dados brutos por dia * Número de dias de armazenamento * Fator de transformação de dados * (número de réplicas - 1)
Armazenamento total de dados (GB) = Dados totais (GB) * (1 + 0,15 estoque + 0,05 necessidades adicionais)
Número total de nós = OK (Armazenamento total de dados (GB) / Volume de memória por nó / proporção de memória para dados + 1 equivalente ao nó de dados)
Dimensionamento da arquitetura do Elasticsearch para determinar o número de shards e nós de dados, dependendo do tamanho do armazenamento
Antes dos cálculos, obtemos os dados iniciais. Necessidade:
- O número de padrões de índice que você criará;
- O número de shards e réplicas principais;
- Após quantos dias a rotação do índice será executada, se houver;
- O número de dias para armazenar os índices;
- A quantidade de memória para cada nó.
Ainda existem recomendações adicionais:
- Não exceda 20 shards por 1 GB de JVM Heap em cada nó;
- Não exceda 40 GB de espaço em disco fragmentado.
As fórmulas são as seguintes:
Número de shards = Número de padrões de índice * Número de shards principais * (Número de shards replicados + 1) * Número de dias de armazenamento
Número de nós de dados = OK (Número de shards / (20 * Memória para cada nó))
Dimensionamento da largura de banda do Elasticsearch
O caso mais comum em que é necessária alta largura de banda é frequente e em grandes números consultas de pesquisa.
Dados iniciais necessários para o cálculo:
- Pesquisas de pico por segundo;
- Tempo de resposta médio permitido em milissegundos;
- O número de núcleos e threads por núcleo de processador nos nós de dados.
Valor máximo de threads = OK (número máximo de consultas de pesquisa por segundo * número médio de tempo para responder a uma consulta de pesquisa em milissegundos / 1000 milissegundos)
Conjunto de encadeamentos de volume = OKRUP ((número de núcleos físicos por nó * número de encadeamentos por núcleo * 3/2) +1)
Número de nós de dados = OK (Valor máximo do encadeamento / volume do conjunto de encadeamentos)
Talvez nem todos os dados iniciais estejam em suas mãos ao projetar a arquitetura, mas, depois de examinar o
webinar ou ler este artigo, parecerá entender que, em princípio, afeta a quantidade de recursos de hardware.
Observe que não é necessário aderir à arquitetura fornecida (por exemplo, crie nós de coordenação e de manipulador). É suficiente saber que essa arquitetura de referência existe e pode dar um aumento no desempenho que você não conseguiria por outros meios.
Em um dos seguintes artigos, publicaremos uma lista completa de perguntas que precisam ser respondidas para determinar o tamanho do cluster.
Para entrar em contato conosco, você pode usar mensagens pessoais no Habré ou o
formulário de comentários no site .
Materiais adicionaisWebinar "Dimensionamento do Elasticsearch e planejamento de capacidade"Seminário on-line sobre planejamento de capacidade do ElasticsearchDiscurso na ElasticON com o tema “Quantitative Cluster Sizing”Webinar sobre o utilitário Rally para determinar os indicadores de desempenho do clusterArtigo de dimensionamento do ElasticsearchSeminário on-line sobre pilha elástica