A. A. A. A. A. A. A.
Você já pensou na influência do metrô mais próximo no preço do seu apartamento? A.
A. A. Que tal vários jardins de infância em torno do seu apartamento? Você está pronto para mergulhar no mundo dos dados geoespaciais?
A. 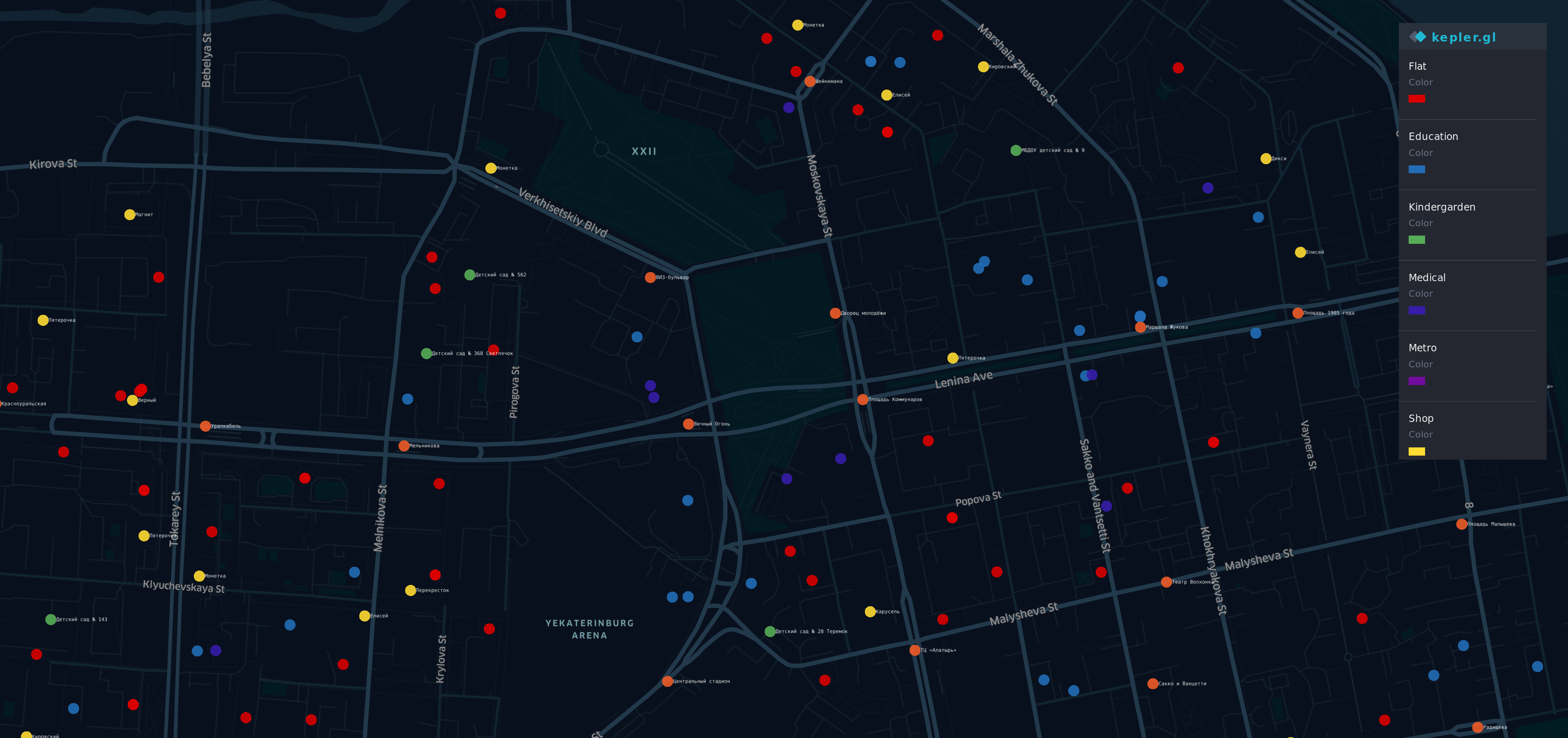 A.
A.
A. A.
A.
O que é isso tudo?
A.
Na parte anterior , tínhamos alguns dados e tentamos encontrar uma oferta suficientemente boa no mercado imobiliário em Ecaterimburgo.
Chegamos a um ponto em que a precisão da validação cruzada era próxima de 73%. No entanto, cada moeda tem 2 lados. E 73% de precisão são 27% de erro. Como poderíamos fazer isso menos? Qual é o próximo passo?
A.
Os dados espaciais estão chegando para ajudar
Que tal obter mais dados do ambiente? Podemos usar o contexto geográfico e alguns dados espaciais.
A.
Raramente as pessoas passam a vida inteira em casa. A. Às vezes eles vão às lojas, levam crianças da creche. Seus filhos crescem e vão para a escola, universidade, etc. A.
Ou ... Às vezes, eles precisam de ajuda médica e procuram um hospital. E uma coisa muito importante é o transporte público, metrô pelo menos. A. Em outras palavras, há muitas coisas por perto, que afetam os preços.
Deixe-me mostrar uma lista deles:
- Paragens de transportes públicos
- Lojas
- Jardins de infância
- Hospitais / instituições médicas A. A. A. A. A. A. A. A. A.
- Instituições educacionais A. A. A. A. A. A. A. A. A.
- Metro
Visualização para novos dados
Depois de obter essas informações de A. Fontes diferentes A. A. , Fiz uma visualização.
A.
A.  A. A. A. A.
A. A. A. A.
Existem alguns pontos no mapa no distrito mais prestigiado (e caro) de Yek aterinburg. A. A. A. A. A.
A. A.
- A. A. A. A. Pontos redondos - apartamentos
- O correu ge - para
- Y ellow - lojas
- G reen - jardins de infância
- B lue - educação
- I ndigo - médico
- V iolet - Metrô
Sim, um arco-íris está aqui.
Visão geral
Agora temos um conjunto de dados delimitado com dados geográficos e com algumas informações novas
df.head(10)

df.describe()

Um bom modelo antigo
Tente da mesma maneira que antes
y = df.cost X = df.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
Depois treinamos nosso modelo novamente, cruzamos os dedos e tentamos prever o preço do apartamento novamente.
from sklearn.linear_model import LinearRegression regressor = LinearRegression() model = regressor.fit(X_train, y_train) do_cross_validation(X_test, y_test, model)

Hmm ... parece melhor que o resultado anterior, com 73% de precisão.
E quanto a tentar interpretar? Nosso modelo anterior tinha uma capacidade suficientemente boa para explicar o preço fixo.
estimate_model(regressor)

Ops ... Nosso novo modelo funciona bem com os recursos antigos, mas o comportamento com os novos parece estranho.
Por exemplo, o maior número de instituições educacionais ou médicas leva a uma diminuição no preço do apartamento. Consequentemente, o número de paradas nas proximidades do apartamento é uma situação idêntica e deve ganhar uma contribuição adicional para o preço do apartamento.
O novo modelo é mais preciso, mas não se encaixa na vida real.
Algo está quebrado
Vamos considerar o que aconteceu.
Antes de tudo, quero lembrá-lo de que a principal característica de nossa regressão linear é ... erm ... linearidade. Sim, o capitão Óbvio está aqui.
Se seus dados forem compatíveis com a idéia "Quanto maior / concessão for X, maior / concessão será Y" - a regressão linear será uma boa ferramenta. Mas os dados geográficos são mais complexos do que esperávamos.
Por exemplo:
- Quando fica perto de um ponto de ônibus, é bom, mas se a quantidade é de cerca de 5, leva a uma rua barulhenta e as pessoas gostariam de evitar comprar um apartamento nas proximidades.
- Se existe uma universidade, ela deve ter uma boa influência no preço,
ao mesmo tempo, uma multidão de estudantes perto de sua casa não fica tão satisfeita se você não é uma pessoa muito sociável. - O metrô perto de sua casa é bom, mas se você mora em uma hora a pé
do metro mais próximo - não deve fazer sentido.
Como você vê - depende de muitos fatores e pontos de vista. E a natureza dos nossos geodados não é linear, não podemos extrapolar o impacto deles.
Ao mesmo tempo, por que o modelo com coeficientes bizarros funciona melhor que o anterior?
plot.figure(figsize=(10,10)) corr = df.corr()*100.0 sns.heatmap(corr[['cost']], cmap= sns.diverging_palette(220, 10), center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")

Parece interessante. Vimos a imagem semelhante na parte anterior.
Existe uma correlação negativa entre a distância do metrô e o preço mais próximo. E esse fator afeta mais a precisão do que alguns mais antigos.
Enquanto isso , nosso modelo funciona confuso e não vê dependências entre dados agregados e variável de destino. A simplicidade da regressão linear tem seus próprios limites. A.
O rei está morto, viva o rei!
E se uma regressão linear não é adequada para o nosso caso, o que pode ser melhor? Se apenas o nosso modelo pudesse ser "mais inteligente" ...
Felizmente, temos uma abordagem que deve ser melhor por causa disso ... mais flexível e tem um mecanismo interno "faça se isso fizer isso ou faça isso".
Árvore de decisão aparece em cena.
from sklearn.tree import DecisionTreeRegressor A decision tree can have a different depth, usually, it works well when depth is 3 and bigger. And the parameter of max depth has the biggest influence on the result. Let's do some code for checking depth from 3 to 32 data = [] for x in range(3,32): regressor = DecisionTreeRegressor(max_depth=x,random_state=42) model = regressor.fit(X_train, y_train) accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) ax = sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

Bem ... para uma situação em que m A. Ax_depth de uma árvore é igual a 8, a precisão está acima de 77.
E seria uma boa conquista se não pensássemos nos limites dessa abordagem. Vamos dar uma olhada em como ele irá funcionar A. A. M ax_depht = 2 A. A. A.
from IPython.core.display import Image, SVG from sklearn.tree import export_graphviz from graphviz import Source 2_level_regressor = DecisionTreeRegressor(max_depth=2, random_state=42) model = 2_level_regressor.fit(X_train, y_train) graph = Source(export_graphviz(model, out_file=None , feature_names=X.columns , filled = True)) SVG(graph.pipe(format='svg'))

Nesta foto, podemos ver que existem apenas 4 variantes de previsão. Quando você usa o DecisionTreeRegressor , ele funciona de maneira diferente da regressão linear . Apenas diferente. Ele não usa uma contribuição de fatores (coeficientes), em vez de o DecisionTreeRegressor usar "probabilidade". E o preço de um apartamento será o mesmo que o apartamento mais semelhante ao previsto.
Podemos mostrá-lo prevendo o nosso preço com essa árvore.
y = two_level_regressor.predict(X_test) errors = pd.DataFrame(data=y,columns=['errors']) f, ax = plot.subplots(figsize=(12, 12)) sns.countplot(x="errors", data=errors)

E todas as suas previsões corresponderão a um desses valores. E quando estamos usando max_depth = 8, não podemos esperar mais que 256 opções diferentes para mais de 2000 apartamentos. Talvez seja bom para os problemas de classificação, mas não é suficientemente flexível para o nosso caso.
Sabedoria da multidão
Se você tentar prever o placar na final da Copa do Mundo - há uma grande probabilidade de você estar enganado. Ao mesmo tempo, se você pedir a opinião de todos os juízes do campeonato - terá melhores chances de adivinhar. Se você perguntar a especialistas independentes, treinadores, juízes e depois fazer alguma mágica com respostas - suas chances aumentarão significativamente. Parece uma eleição de um presidente.
Um conjunto de várias árvores "primitivas" pode dar mais do que cada uma delas. E rando mForestRegressor é uma ferramenta que vamos usar
Primeiro de tudo, vamos considerar os parâmetros básicos - max_depth , max_features e várias árvores no modelo.
A.
Número de árvores
De acordo com "Quantas árvores em uma floresta aleatória?" a melhor escolha será 128 árvores . O aumento adicional do número de árvores não leva a uma melhoria significativa na precisão, mas aumenta o tempo de treinamento.
Número máximo de recursos
No momento, nosso modelo possui 12 recursos. Metade deles são antigos, relacionados a características de flat, outros relacionados ao contexto geográfico. Então eu decidi dar uma chance para cada um deles. Que sejam 6 recursos para uma árvore.
Profundidade máxima de uma árvore
Para esse parâmetro, podemos analisar uma curva de aprendizado.
from sklearn.ensemble import RandomForestRegressor data = [] for x in range(1,32): regressor = RandomForestRegressor(random_state=42, max_depth=x, n_estimators=128,max_features=6)model = regressor.fit(X_train, y_train)accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

Whoa ... mais de 86% de precisão em max_depth = 16 contra 77% em uma árvore de design. Parece incrível, não é?
Conclusão
Bem ... agora temos um resultado melhor em previsões do que as anteriores, 86% está perto da linha de chegada. O último passo para verificar - vejamos a importância do recurso. Os dados geográficos deram algum benefício ao nosso modelo?
feat_importances = model.feature_importances_ feat_importances = pd.Series(feat_importances, index=X.columns) feat_importances.nlargest(5).plot(kind='barh')

Alguns recursos antigos ainda afetaram o resultado. Ao mesmo tempo, a distância até o metrô e jardins de infância mais próximos também foi afetada. E isso parece lógico.
Sem dúvida, os geodados nos ajudaram a melhorar nosso modelo.
Obrigado pela leitura!
PS
Nossa jornada ainda não terminou. 86% de precisão é um tremendo resultado para dados reais. Enquanto isso, aqui está uma pequena diferença entre 14% e 10% do erro médio, o que esperamos. No próximo capítulo de nossa história, tentaremos superar essa barreira ou, pelo menos, diminuir esse erro. A. A. A. A. A. A. A. A.
Existe o notebook IPython