Olá pessoal! Meu nome é Lyudmila, estou envolvido em teste de carga, quero compartilhar como realizamos a automação da análise comparativa do perfil de regressão do teste de carga do sistema no banco de dados sob o DBMS Oracle junto com um de nossos clientes.
O objetivo do artigo não é descobrir uma abordagem "nova" para comparar o desempenho do banco de dados, mas descrever nossa experiência e tentar automatizar a comparação dos resultados obtidos e
Reduza as chamadas para os DBAs do Oracle.
Realizando testes de carga de qualquer banco de dados, estamos interessados principalmente em:
- Algo quebrou após a instalação de uma nova montagem?
- A dinâmica do banco de dados durante o teste.
A comparação dos relatórios AWR por si só não é suficiente para atingir seus objetivos.
O armazenamento centralizado de despejos AWR também é uma boa prática. Os dumps do AWR mantêm todas as visualizações históricas (dba_hist).
Esta prática já foi aplicada pelo nosso cliente.
Após a próxima sessão de teste de carga, comparamos os resultados:
- despejo de teste atual com despejo industrial;
- o despejo de teste atual com o despejo de teste anterior.
Por que isso é necessário?
Os objetivos são diferentes:
- Às vezes, preencher a própria base em um ambiente de teste é diferente do operacional, o que significa que haverá diferenças que interferem na análise ("interferência" para responder à pergunta principal, "algo está quebrado?"). Eu quero identificar essas diferenças;
- A comparação do teste atual com o trabalho da base industrial ajuda a entender o quão corretos são os testes de estresse atuais (em algum lugar carregamos muito, mas esquecemos alguma coisa);
- Comparar o teste atual com o teste anterior ajuda a entender se o comportamento atual do sistema é normal. Alguma coisa mudou no comportamento do sistema em comparação com o teste anterior.
Para atingir todos esses objetivos, geralmente resolvemos o problema de comparar diferentes lixões entre si. As datas geralmente são muito limitadas quando deveriam ser apresentadas ontem! Falta muito tempo para verificar completamente cada teste de regressão. E se você executar o teste de confiabilidade por um dia, poderá gastar muito tempo analisando o resultado ...
Obviamente, você pode assistir a tudo on-line no Enterprise Manager (ou com solicitações de gv $ views) durante o teste: não vá fumar, comer e dormir ...

Talvez você também tenha sua própria ferramenta personalizada, feita para você? Você pode compartilhar nos comentários. E compartilharemos o que usamos para nossas tarefas.
Os relatórios do AWR têm muitas informações úteis:

Há informações úteis aqui, por exemplo: quanto a consulta está executando, sql_id, module e texto reduzido. Embora o texto esteja lá, ele está truncado e a versão completa pode ser obtida no parágrafo Lista Completa de Texto SQL.
Quanto às desvantagens: no relatório AWR, não está claro quando essas solicitações ocorreram, em que momento houve mais e em que menos ... Afinal, analisar os resultados dos testes, entender o que aconteceu e em que momento aproximadamente é importante: uniformemente para todo teste ou pico / pico como se estivesse em um horário. Também veremos apenas um top limitado aqui. Isso pode ser visualizado mais facilmente consultando tabelas históricas.
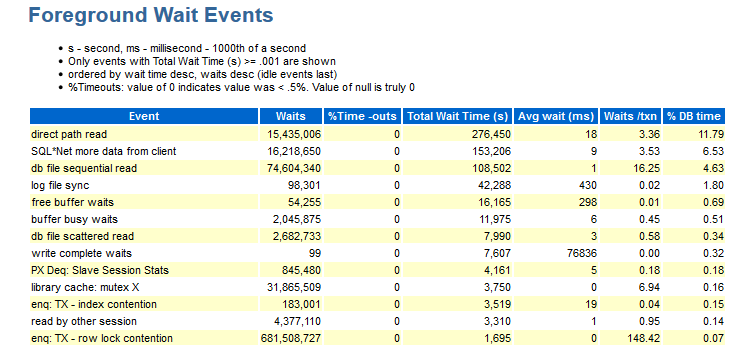
Aqui você pode ver quais eventos foram durante o teste. Os dados nesta seção são ordenados por hora do banco de dados.
Para mim, nesta seção, as seguintes informações estão ausentes:
- Wait_class (sim, você se lembra com experiência a que tipo de expectativa esse evento pertence).
- Distribuições por módulos (se eu ver, por exemplo, aguardando enq: TX - contenção de bloqueio de linha: são necessárias informações, sob qual módulo isso aconteceu).
Existem trabalhos em que existem números que não contêm uma parte semântica, ou seja, é necessário agrupar os mesmos módulos e obter uma resposta para o grupo, por exemplo: module_A_1, module_A_2, module_A_3 e module_B_1, module_ B_2, module_ B_3. Ou seja, havia dois módulos semânticos, mas todos eles tinham nomes diferentes.
- O objeto ao qual estamos nos referindo (CURRENT_OBJ # - se, por exemplo, o evento enq: TX - contenção de índice ocorrer, seria bom saber qual índice é o culpado).
- Sql_id - que solicita a execução do texto dessa solicitação.
- Informações sobre a distribuição de quantidades por instantâneo (como descrito acima ...).
Para comparar os dois testes, você pode usar a comparação dos relatórios AWR:
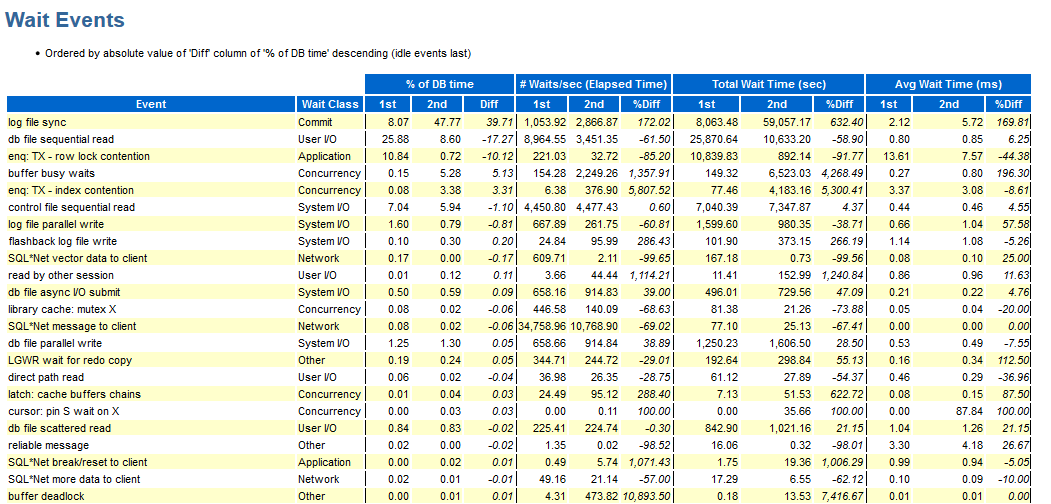
Hooray, aqui temos wait_class exibido; caso contrário, os menos são os mesmos que os descritos acima.
Às vezes, não há Enterprise Manager em projetos, e você pode, por exemplo, usar o Enterprise Manager Express ou o ASH Viewer. No Enterprise Manager, muitos usam a Atividade principal para dados históricos, mas para mim, muitas coisas são mais fáceis de ver com as próprias consultas. Todos os itens acima devem ser comparados com outros testes / carga de trabalho. Já tínhamos uma comparação personalizada em termos de tempo de execução, mas não tínhamos uma comparação personalizada e verificamos manualmente com consultas em tabelas históricas.
Após cada teste de regressão, era necessário comparar os resultados em tabelas históricas com consultas ao banco de dados, visualizar relatórios do AWR, localizar a expectativa problemática (em qual módulo ocorre, em que horários e em que objeto estava pendurado), para que, como resultado, um erro pudesse ser gerado para a equipe de desenvolvimento correta.
O banco de dados do cliente atingiu 190 TB, um grande número de solicitações é processado no sistema: o número de módulos paralelos é 16237.
E então eu tive uma idéia de como simplificar o processo de comparação de despejos AWR. Com essa ideia, fui ao
Fred . Juntos, criamos um portal conveniente.
No início, a declaração do problema de minha parte era assim:

Decidi, então, sistematizar, para começar, quais consultas às tabelas históricas mais usadas ... Fred começou a fixar isso no portal e, em seguida, começou ...
Antes de tudo, eu estava interessado em uma comparação de eventos, pois já existia uma comparação da velocidade de execução da consulta. Na próxima etapa, eu precisava de informações detalhadas sobre cada evento: por exemplo, se o evento é contenção de índice, você precisa entender em qual índice estamos realmente pendentes.
Então, fiquei interessado em que momentos desses eventos eram mais, pois na implementação havia muitas tarefas (tarefas) agendadas e era necessário entender em que momento tudo estava quebrando nas costuras.
Em geral, aqui está o que eu queria obter:
- comparação quantitativa de eventos entre diferentes testes (sem agachamentos adicionais);
- todas as informações relacionadas necessárias para análise: sql_id, texto da consulta, distribuição durante o teste, que objeto das sessões mencionadas, módulo;
- filtros convenientes para você ver o que mudou;
- GUI GUI, tudo é tão colorido que fica imediatamente visível (você pode selecionar as partes interessadas do lado do desenvolvimento)
- agrupamento de módulos: como descrito anteriormente, 16237 módulos, mas, do ponto de vista das funções executadas, muitas vezes menos.
Fred e eu fizemos um portal conveniente para o nosso uso na comparação de despejos AWR de testes de carga, que discutiremos em mais detalhes abaixo.
Sobre o portal
Portanto, os dumps do AWR são criados no sistema, que são despejados no banco de dados e comparados no portal.
Usamos a seguinte pilha:
- Oracle DB - para armazenar despejos AWR
- Python 2+
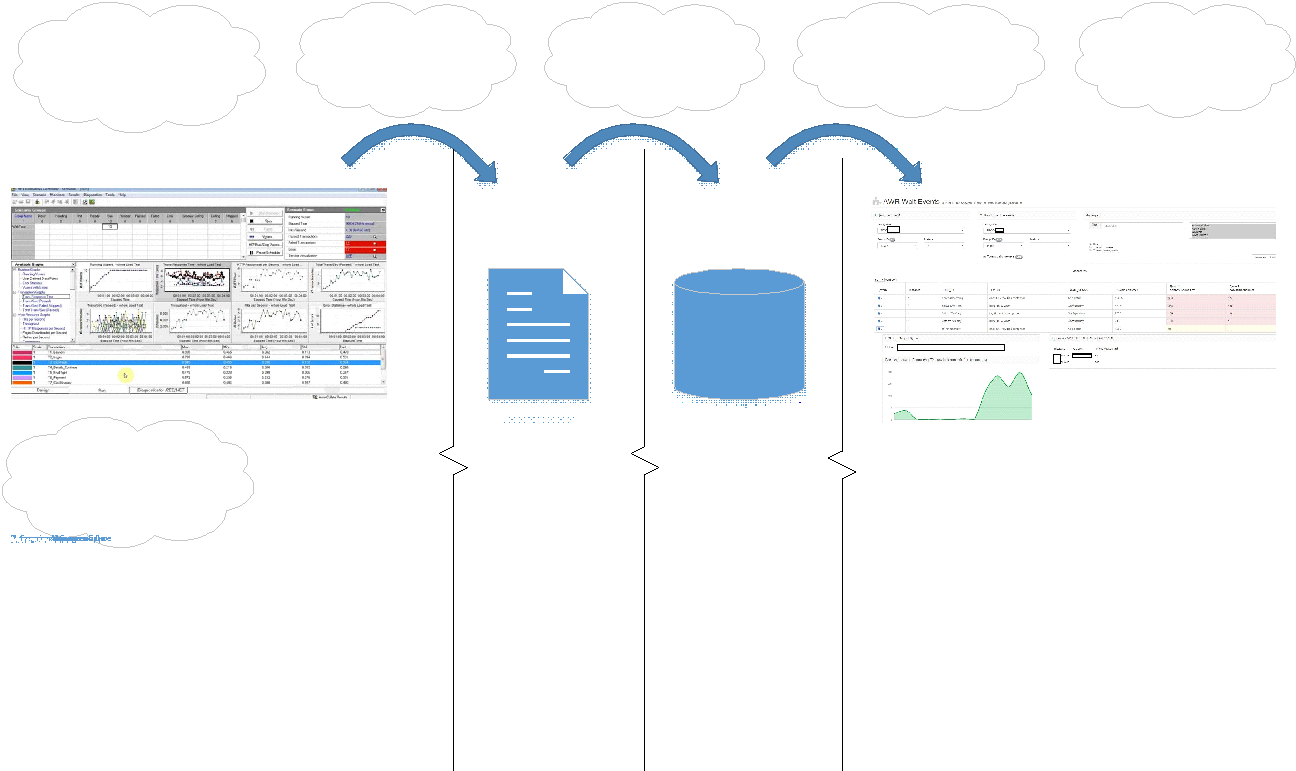
A interface do portal fica assim:

No portal, você pode escolher os tipos de dumps comparados, teste de teste ou teste-baile.
Cada despejo possui seu próprio identificador exclusivo - DBID.
Você também pode filtrar pelos seguintes parâmetros:
- Instância (instância) - tínhamos um banco de dados de cluster;
- Pedido (Sql_id);
- Tipo de espera (Wait_Class);
- Evento
No canto superior esquerdo, você seleciona despejos e, à direita, pode definir os filtros necessários para selecionar imediatamente o módulo desejado - isso permite identificar problemas na funcionalidade que foi alterada / aprimorada, para que não haja problemas de degradação na versão anterior.
A tabela no meio é o resultado da comparação dos lixões. Os títulos das colunas mostram imediatamente quais dados estão sendo produzidos. As duas colunas da direita mostram as diferenças entre os dois dumps:
- eventos destacados em vermelho são mais do que em comparação com um dump comparativo para instantâneo;
- amarelo - novos eventos;
- verde - eventos que já estavam no despejo original.
É imediatamente óbvio o quão bem testamos. Se o evento ocorreu com muita frequência, provavelmente:
- sobrecarregou o sistema;
- ou as condições para a execução de tarefas em segundo plano mudaram e o evento começou a ser reproduzido com mais frequência. Assim, foi encontrado um erro no código: o evento ocorreu constantemente, e não no ramo de condição desejado.
Se temos um novo evento - amarelo -, isso indica algum tipo de mudança no sistema e precisamos analisar suas conseqüências. Aqui você pode ver a distribuição dos eventos por instantâneos e exibir informações detalhadas sobre a espera.
Houve um caso: um novo evento foi descoberto, o que era bastante raro e não foi incluído nos principais eventos, mas, por causa disso, houve lentidão no funcional, que tinha SLAs críticos. A análise apenas das principais consultas no relatório AWR não pôde revelar isso.
Para cada solicitação, você pode obter informações mais detalhadas:
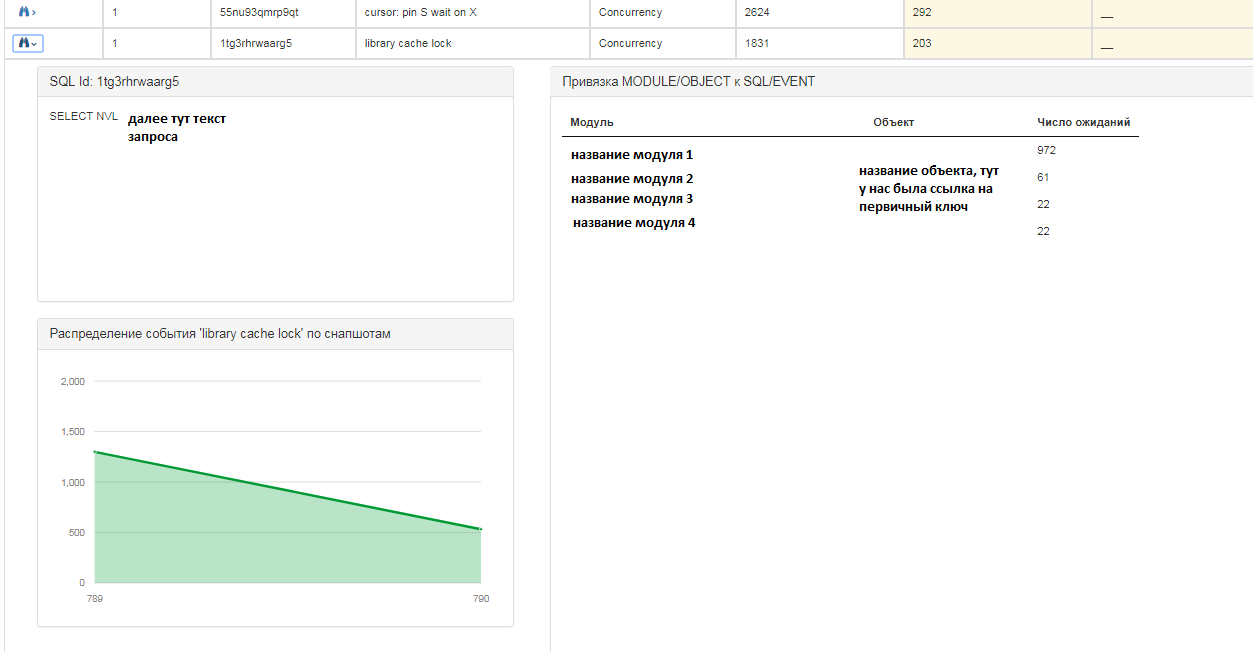
Para cada entrada, você também pode ver as seguintes informações:
- consulta texto sql;
- a distribuição de eventos em um instantâneo em uma proporção quantitativa, ou seja, em que momento houve mais / menos eventos;
- em quais módulos e objetos a espera "suspensa".
As visualizações do sistema da Oracle estão envolvidas na comparação dos resultados:
DBA_HIST_ACTIVE_SESS_HISTORY, DBA_HIST_SEG_STAT, DBA_HIST_SNAPSHOT, DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED - sua própria tabela de serviço (já foi implementada pelo cliente), contém informações sobre dumps carregados.
Algumas consultas:
Distribuição de eventos nas fotos:
SELECT S.SNAP_ID, COUNT(*) RCOUNT FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V. WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 GROUP BY S.SNAP_ID ORDER BY S.SNAP_ID ASC
Agrupando por módulo (módulos que são um único grupo lógico são combinados nele), o objeto sendo bloqueado:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT (SELECT CASE (WHEN INSTR(S.MODULE, ' 1')>0 THEN ' 1' WHEN INSTR(S.MODULE, ' 2')>0 THEN ' 2' … ELSE S.MODULE END) MODULE, O.OBJECT_NAME FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 AND S.CURRENT_OBJ
O que você conseguiu no final?
O portal nos permitiu economizar tempo comparando despejos AWR. A comparação manual levou 4-6 horas e agora gastamos 2-3 horas. Sempre temos em mãos a oportunidade de comparar rapidamente os resultados de diferentes testes entre si e com um despejo industrial, além de definir os filtros que precisamos agora. Ou seja, podemos comparar convenientemente os dados históricos entre nós, e não apenas assistir o resultado atual on-line.
Anteriormente, após cada regressão, era necessário comparar os resultados em tabelas históricas com consultas ao banco de dados, visualizar relatórios AWR, localizar a expectativa problemática (em qual módulo ocorre, em que horas ocorreu, em que objeto estava pendurado), para que, no final, pudesse levar a um defeito na equipe de desenvolvimento correta. E agora basta selecionar os dumps para comparação, definir os filtros - e os resultados da comparação estão imediatamente prontos. Você também pode enviar aos desenvolvedores um link para o portal indicando o DBID do dump de teste, e eles próprios serão filtrados por seu módulo.
Demorou apenas duas semanas para criar o portal, porque uma parte dele já estava pronta: carregando despejos no banco de dados. Obviamente, essa solução de portal não é necessária para nenhum projeto com uma base Oracle. É útil para produtos divididos em vários módulos com nomes diferentes. Para sistemas simples ou para sistemas nos quais eles não deram importância ao preenchimento do módulo, o portal será redundante.
Como o portal analisa imagens tiradas uma vez em um determinado período, o portal não isenta completamente o monitoramento on-line do banco de dados, pois alguns eventos podem não conseguir entrar na imagem.
Essa é uma ferramenta conveniente para analisar dados históricos dos resultados dos testes, mas pode ser útil em outras situações quando muitas imagens são criadas e grandes volumes de dados precisam ser verificados. Graças à combinação de filtros e gráficos, é possível ver imediatamente rajadas de eventos que, nos relatórios normais do AWR (que não devem ser confundidos com despejos), ficam ocultos nas informações agrupadas. Basta selecionar dumps para comparação, definir filtros - e os resultados da comparação estão imediatamente prontos, ou você pode enviar um link para os desenvolvedores no portal indicando o DBID do dump de teste, eles próprios serão filtrados por seu módulo.
Se você decidir desenvolver um portal semelhante para o seu projeto, selecione o conjunto de filtros adequado para você. Se você filtrar de acordo com diferentes condições a cada vez, será muito mais fácil criar um filtro apropriado para isso.
A solução resultante ainda pode ser finalizada, por exemplo:
- comparar a duração da solicitação;
- comparando planos de consulta;
- comparar solicitações com o mesmo plano, mas com texto diferente;
- descarregar em relatórios de teste (execução como um documento Word / Exel).
Ou, em geral, diga ao portal para conectar-se ao banco de dados testado, de forma a criar imagens semelhantes on-line usando visualizações na memória, e não apenas dados históricos. E salve-os no seu banco de dados.
Estamos usando o portal há mais de um ano. Fred, muito obrigado!
Postado por Lyudmila Matskus,
Jet Infosystems