Todos os dias, um número crescente de dispositivos cria mais dados. Eles precisam ser gerenciados em vários pontos, e não em vários data centers em nuvem centralizados. Em outras palavras, o processo de gerenciamento vai além dos limites dos data centers tradicionais e passa para o local onde os dados são criados - para a periferia da rede, mais próxima dos usuários finais. Aqui, os dados são gerados por vários sensores, câmeras, gadgets e dispositivos da Internet das Coisas (IoT). Quando os resultados de seu trabalho são coletados e processados diretamente nos limites da rede, eles podem ser analisados e usados muito mais rapidamente.

Segundo os
especialistas do Gartner , até 2020, mais de 50% de todos os dados gerados pelas empresas serão processados fora dos data centers tradicionais ou do ambiente em nuvem (hoje esse número é de apenas 10%). Nessa arquitetura, 5,6 bilhões de dispositivos da Internet das Coisas (IoT) funcionarão. Ao mesmo tempo, os volumes de dados produzidos pelos dispositivos são calculados em terabytes e geralmente precisam ser interpretados e analisados em tempo real.
Para ajudar parceiros e clientes a explorar essa tendência, a Seagate se uniu a um consórcio de empresas especializadas em computação periférica e lançou o relatório
Data at the Edge . Também utilizou os resultados de um
estudo realizado pelo IDC. O objetivo do relatório era ilustrar alguns dos problemas de dados que são relevantes para as empresas atualmente e mostrar como as empresas gerenciam melhor seus recursos de TI.
Computação periférica
“Os participantes do mercado de armazenamento passaram por várias etapas no desenvolvimento de seus negócios. Algumas décadas atrás, as instalações de armazenamento para sistemas de servidores eram consideradas promissoras, e os data centers locais estavam em destaque. Isso se refletiu nas linhas de produtos dos fornecedores: eles começaram a produzir unidades para esse segmento. Então começou o desenvolvimento de armazenamento em nuvem, computação em nuvem. O próximo passo é a computação periférica ”, diz Alexander Malinin, diretor do escritório de representação da Seagate na Rússia e na CEI. - Como existem muitos dados, e eles são gerados não apenas pelas pessoas, mas também pelas máquinas, enviar tudo isso ao datacenter nem sempre é o ideal. Faz sentido fazer parte dos cálculos fora dos datacenters e transferir os resultados processados para o datacenter. De fato, esta é a criação de outro circuito de cálculos, onde os dados são acumulados, armazenados por algum tempo, processados e transferidos para o data center principal para armazenamento adicional e acesso a eles ".
À medida que bilhões de dispositivos continuam a se conectar à rede, coletando e gerando zettabytes de dados, os modernos ambientes de nuvem centralizada requerem suporte para uma nova arquitetura de TI periférica. E colocando os recursos de computação, rede e armazenamento próximos desses dispositivos, você pode analisar os dados no local.
Como os dados passam por processamento primário no mesmo local em que são criados, parte das decisões de gerenciamento (por exemplo, para ajustar o modo de operação dos equipamentos industriais) pode ser tomada localmente, com um atraso mínimo.
A periferia pode ser localizada em qualquer lugar: das oficinas às fazendas, nos telhados das casas e nas torres de celular, nos veículos em terra, no mar e no ar. Sendo a fronteira externa de uma rede, ela geralmente está localizada a centenas de quilômetros do data center corporativo ou na nuvem mais próximo e muito próximo à fonte de dados.
De acordo com um estudo da IDC, até 2020, 45% de todos os dados gerados por dispositivos IoT serão armazenados e processados nos segmentos de fronteira da rede ou próximos a eles. Existem muitos casos em que é melhor mover o processo de computação para a periferia. Portanto, em “cidades inteligentes”, o processamento e a análise de dados mais próximos de sua fonte reduzem o tempo de atraso e permitem que vários serviços respondam mais rapidamente à situação.
Em sistemas de transporte inteligentes, a computação periférica permite processar informações localmente, enviando apenas os dados mais importantes para a nuvem. Essa tecnologia já está sendo usada em sistemas de transporte inteligentes. Além disso, essa abordagem melhora a segurança e a eficiência do transporte. Os carros autônomos devem responder instantaneamente aos dados recebidos, pois até o menor atraso pode ser perigoso.
A proliferação da computação periférica exigirá uma nova infraestrutura para armazenar e gerenciar dados. Por exemplo, uma fábrica inteligente criará cerca de 5 petabytes de vídeo por dia, uma cidade inteligente com uma população de 1 milhão de pessoas - 200 petabytes de dados por dia e um carro autônomo - 4 terabytes.
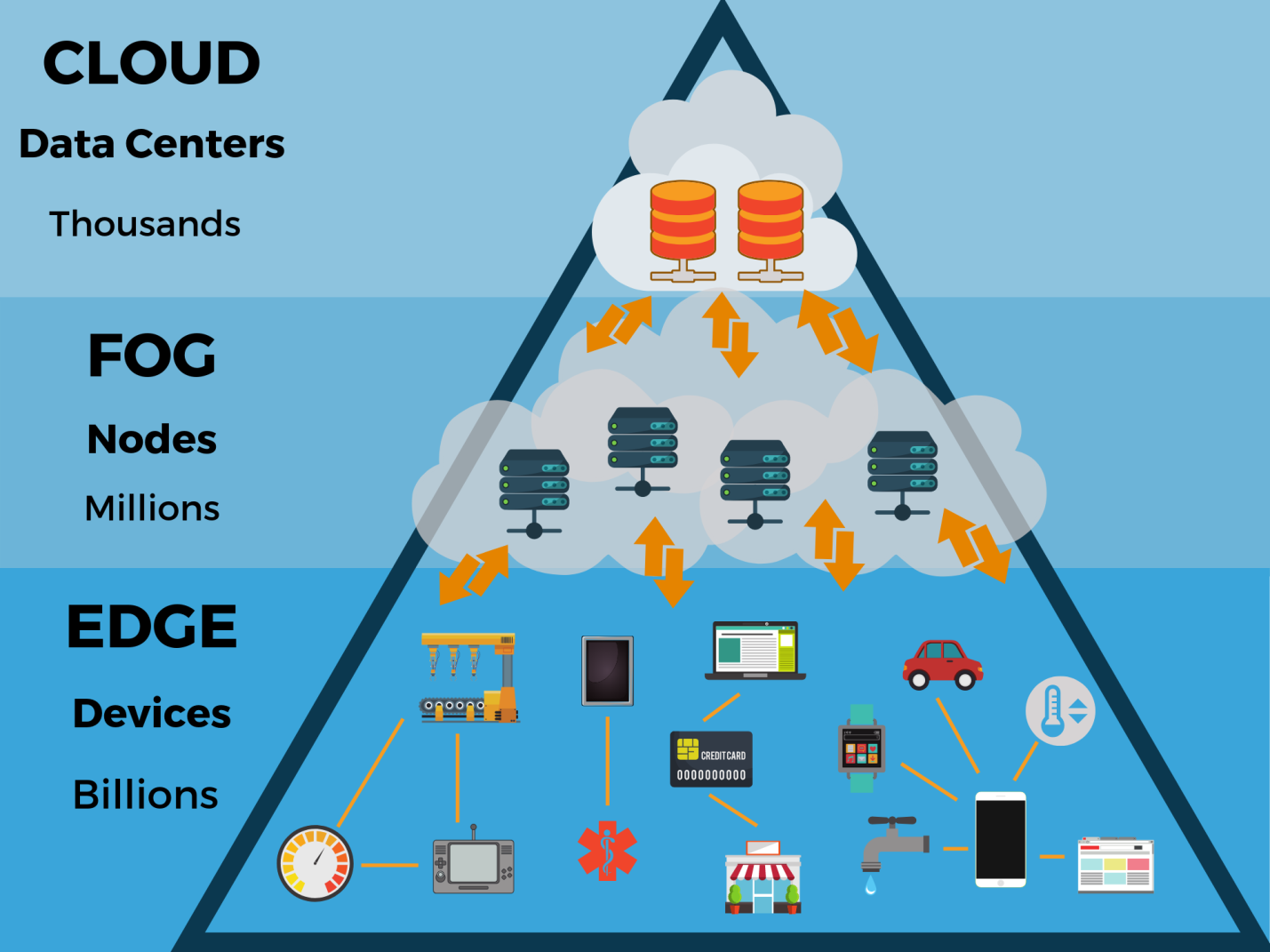
O que esses dados na fronteira significam? Como essa evolução afetará a estrutura e o funcionamento dos data centers e data centers existentes na nuvem? Poderia a computação em nuvem, que prevalece hoje, suplantar a computação periférica porque é mais flexível e escalável em termos de aplicativos?
Nuvens e periféricos
Os autores do relatório “
Data at the Edge ” enfatizam que, embora a computação periférica permita um uso mais eficiente dos dados, a infraestrutura tradicional não perderá seu significado. Como grandes quantidades de dados serão criadas fora dos centros tradicionais de processamento, a nuvem se expandirá para a periferia. Ou seja, não se trata do cenário “nuvem contra a periferia”, mas sim do “nuvem com a periferia”.
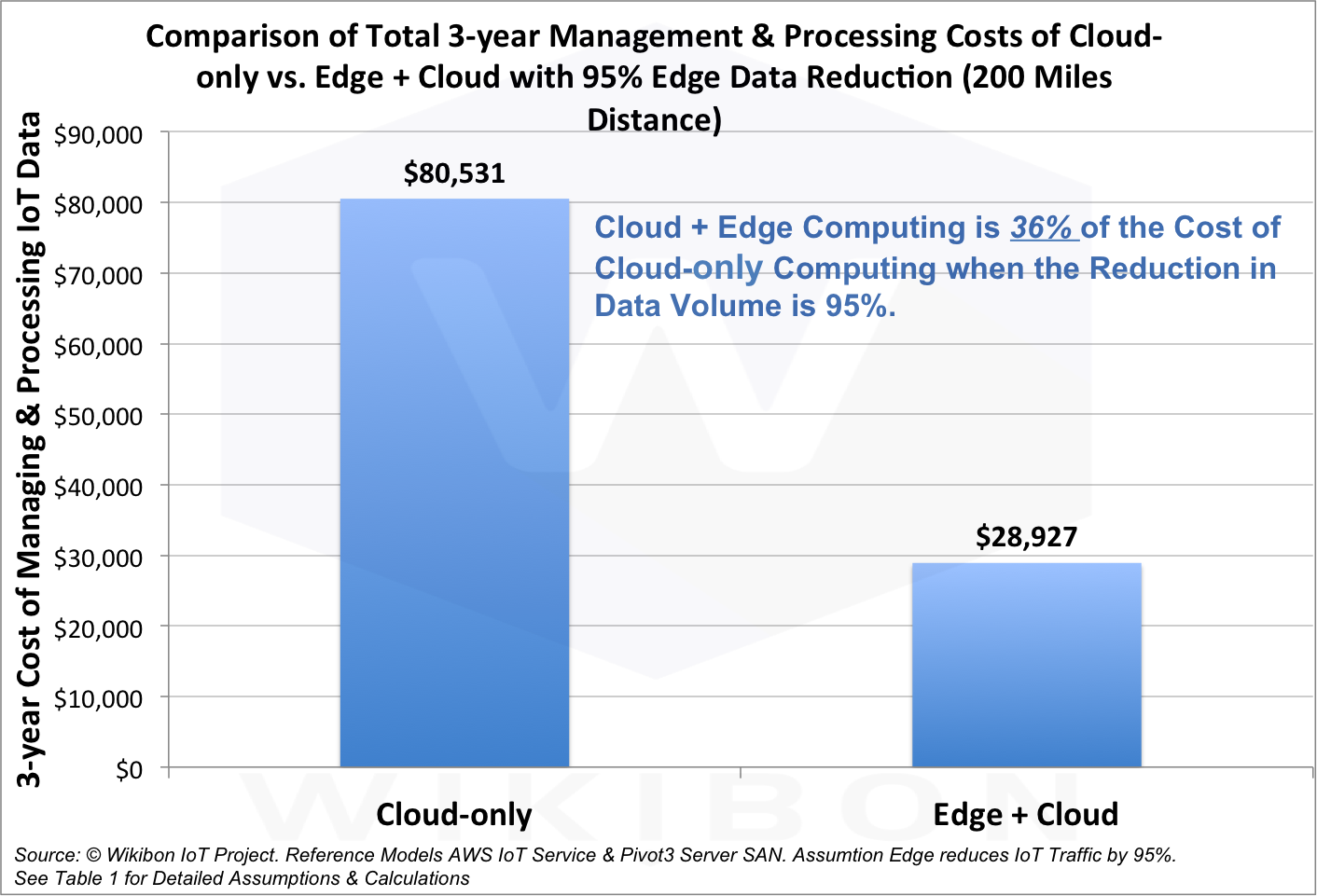
Segundo analistas, a combinação de computação em nuvem e periférica custará apenas 36% do custo de uma versão puramente em nuvem, e a quantidade de dados transmitidos será reduzida em 95%.
Assim, o futuro está no trabalho conjunto da periferia e da nuvem. Isso ajudará as empresas instantaneamente a tomar decisões mais informadas, aumentar sua produtividade, eficiência no trabalho e atender melhor às necessidades dos clientes.
Negócios baseados em dados
Hoje, quase qualquer empresa ou organização está associada ao processamento e armazenamento de dados. As inovações no gerenciamento de informações abriram o caminho para formas mais eficientes de usá-lo. Isso também se aplica aos dados periféricos.
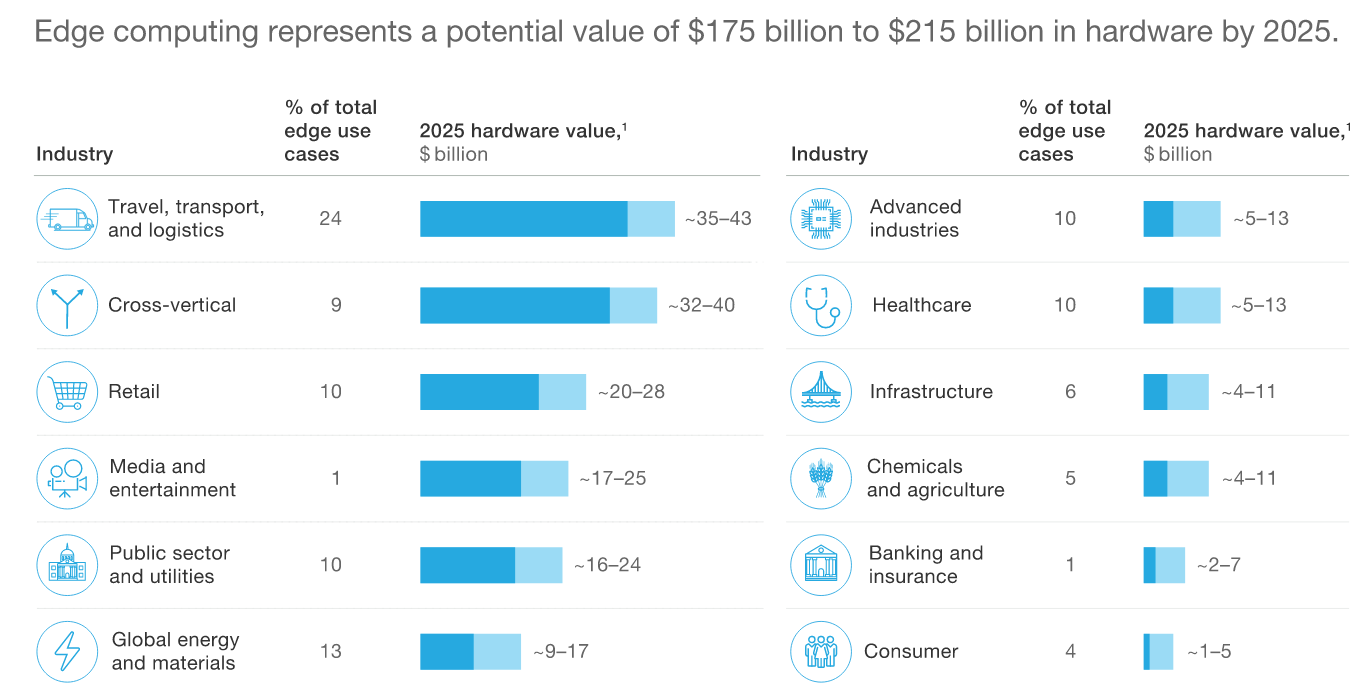
Segundo
a McKinsey , o mercado global de equipamentos de computação periféricos chegará a US $ 175 a US $ 215 bilhões até 2025.
Periféricos e Vida
O que isso significa para grandes empresas, cidades, pequenas empresas e consumidores individuais, quais são os benefícios? Como os dados na periferia nos ajudarão a trabalhar melhor, relaxar, viver, viajar? Que oportunidades para análise de dados surgem na borda da rede? Essas são as perguntas que o relatório da Seagate responde.
Os dados no Edge fornecem vários exemplos de como a computação periférica está transformando os negócios globais hoje e beneficiando as pessoas. Por exemplo, no Chile, um sistema de irrigação com inteligência artificial, equipado com sensores, reduz o consumo de água em 70%.
Mas o que acontece nas próprias fábricas da Seagate. A empresa produz milhões de unidades trimestralmente e bilhões de sensores anualmente. Isso requer a introdução de processos altamente automatizados, e o sistema deve tomar de 20 a 30 decisões por segundo. A essa velocidade, não há tempo para esperar até que os dados coletados na linha de produção sejam enviados ao centro para processamento e, em seguida, uma solução será fornecida a partir daí.

Não podemos parar a linha de produção: precisamos manter o ritmo da produção e, ao mesmo tempo, garantir sua alta qualidade. Portanto, as decisões devem ser tomadas no mesmo local em que os dados são gerados. Para fazer isso, a Seagate criou sua própria tecnologia para detectar anomalias e analisar imagens no local da fábrica. Isso reduz a latência de centenas para menos de 10 milissegundos.
Computação periférica na Rússia
“Qual a extensão da computação periférica usada na Rússia? Em primeiro lugar, a introdução de qualquer nova tecnologia leva tempo. Em segundo lugar, o próprio termo "computação periférica" ainda não foi utilizado. Ou seja, mesmo que a empresa use essa abordagem, ela a chama de maneira diferente ”, explica Alexander Malinin. - Enquanto isso, a computação periférica é frequentemente usada, por exemplo, em geodésia, na indústria de petróleo e gás. A coleta de dados é coletada e processada em um pequeno datacenter local e depois enviada para um repositório centralizado. A computação periférica também é usada na indústria de petróleo e gás, onde uma grande quantidade de dados é coletada e todos eles não precisam ser armazenados. ”
"Com o desenvolvimento das telecomunicações, com um aumento na velocidade da transferência de dados, o número de data centers periféricos só aumentará", continua Alexander Malinin. - Sim, e o próprio termo "computação periférica" será mais difundido. O setor de armazenamento de dados tem algo a oferecer. Existem várias tecnologias de armazenamento que atendem a diferentes tarefas, existem algoritmos matemáticos para análise de dados. O principal problema agora está nas tecnologias de telecomunicações, na obtenção de dados. Por exemplo, a Internet das Coisas oferece amplo uso de conexões sem fio. Isso exigirá a implantação de redes sem fio, como 5G. Processos semelhantes ocorreram com a introdução da tecnologia de big data. Eles já começaram a usá-lo, mas chamaram de maneira diferente: é uma questão de terminologia ".
Fatores de crescimento
O que impulsiona a demanda por uma nova arquitetura de computação? Com base em pesquisas e pesquisas com executivos de TI da Seagate, foram identificados
quatro fatores principais que determinam a demanda por computação periférica. Esta é a latência da rede (latência); largura de banda insuficiente dos canais de comunicação para a entrega de grandes quantidades de dados ao data center; eficiência e custo da solução; soberania e conformidade de dados.
1. Latência
O fator número um é a latência. Devido às limitações físicas da infraestrutura de TI e telecomunicações, leva muito tempo para mover os dados de onde foram criados para o site central. Assim, a latência se torna um fator-chave: o envio de dados de e para o site central pode levar de 100 a 200 milissegundos.
2. Rendimento
O fator número dois é o problema da largura de banda. O volume total de dados não é mais exabyte, mas zettabyte. E eles continuam a crescer, mesmo que apenas pelo surgimento de novos sensores - não apenas temperatura, clima, vibração ou outros sensores que coletam relativamente poucos dados, mas também câmeras, radares, lidares e outros dispositivos que geram muita informação. No futuro, haverá ainda mais sensores desse tipo. A infraestrutura 5G pode suportar milhões de dispositivos por quilômetro quadrado, mas onde posso encontrar a largura de banda para enviar todos os dados para um data center em nuvem centralizado?
3. Eficiência
Terceiro, eficiência. Mesmo que você possa enviar todos os dados para um datacenter centralizado, os custos e a complexidade da arquitetura para processar uma quantidade tão grande de informações serão tão grandes que o sistema se tornará mal gerenciado. Com um sistema que processa dados intensivamente na periferia, mais perto da fonte, as coisas ficam muito melhores.
4. Requisitos regulamentares e padrões corporativos
Finalmente, o quarto fator é a exigência de que os dados sejam processados de acordo com as normas e padrões aceitos pelos clientes. Quando você lida com segurança da informação, geralmente não é possível enviar dados de uma determinada região ou país para o exterior para processamento centralizado. Isso se aplica, por exemplo, a informações pessoais.
“A computação periférica exigirá abordagens especiais para regular o armazenamento de dados, para garantir a segurança, incluindo a segurança do acesso físico aos dados”, enfatiza Alexander Malinin. "Mas definitivamente veremos um aumento na computação periférica nos próximos dois a três anos, porque o número de solicitações das organizações por pequenos data centers está crescendo, o que atenderia a indústrias individuais e grandes empresas nacionais". Ou seja, o número de solicitações para organizar o armazenamento de dados local está aumentando. ”
Nova arquitetura
O que isso significa para os arquitetos de TI, o que eles devem fazer de diferente? Para começar, projetar a infraestrutura tradicional de um data center ou data center em nuvem é muito diferente do desenvolvimento da arquitetura periférica. Os datacenters tradicionais incluem sistemas de refrigeração e ar condicionado, fontes de alimentação ininterruptas redundantes duplas e sistemas de segurança física. Eles são atendidos por toda uma equipe de especialistas.
O data center periférico (ou melhor, o nó) do processamento de dados pode estar localizado em uma torre de telecomunicações ou em uma pequena sala. É frequentemente exposto ao ambiente externo, portanto, seu controle do clima é uma tarefa difícil.
No que diz respeito à segurança física, a arquitetura precisará incorporar proteção de dados especial em caso de desastre natural ou atos maliciosos. Além disso, devido à falta de pessoal que pode rapidamente consertar tudo, os sistemas periféricos devem ser especialmente confiáveis. Se algo acontecer, o data center periférico deve se recuperar e continuar trabalhando.
Em outras palavras, se pretendemos processar dados na periferia, precisamos aperfeiçoar a funcionalidade do data center: refrigeração, segurança etc. Arquitetos de sistemas já estão trabalhando para encontrar soluções. O objetivo é simplificar os datacenters periféricos e fornecer telemetria suficiente.
Além disso, alguns dos dados que serão processados na periferia não permanecerão lá. Eles irão ao centro para análise adicional ou armazenamento mais longo. Um arquiteto de TI é obrigado a refletir sobre esse processo, definindo uma estratégia de gerenciamento de dados.
As organizações precisarão confiar em sua arquitetura de computação em nuvem, aprender a processar e, o mais importante, armazenar com segurança mais dados nos limites.
O
relatório de dados periféricos da Seagate e do Vapor IO diz que toda organização tem um valor que nem suspeita. Estes são os seus próprios dados. A maneira como criamos dados e trabalhamos com a periferia da rede confere-lhe um significado especial. Para continuar crescendo, as empresas precisam tirar proveito disso.
“Os problemas da implementação da computação periférica agora se resumem principalmente às telecomunicações, à velocidade do acesso aos dados. Quanto mais rápida for a introdução da próxima geração de tecnologias de telecomunicações na Rússia, mais rapidamente a computação periférica se desenvolverá ”, diz Alexander Malinin. - Ao mesmo tempo, a computação periférica se desenvolverá em paralelo com os data centers existentes e os complementará. Nenhuma reestruturação radical é necessária. ”
O Gartner prevê que até 2021, 40% das empresas no mundo desenvolverão estratégias de computação periférica em larga escala. Portanto, os fornecedores agora estão com pressa de ocupar um nicho promissor. Nos próximos cinco anos, o mercado será formado ativamente, novas plataformas e soluções prontas para o uso aparecerão com foco em várias tarefas e indústrias. As empresas envolvidas no desenvolvimento da computação periférica poderão se tornar líderes em novas áreas de negócios.