O Zabbix é um sistema de monitoramento. Como qualquer outro sistema, ele enfrenta três problemas principais em todos os sistemas de monitoramento: coleta e processamento de dados, armazenamento de histórico e limpeza.
As etapas de aquisição, processamento e gravação de dados levam tempo. Não é muito, mas para um sistema grande, isso pode resultar em grandes atrasos. O problema de armazenamento é um problema de acesso a dados. Eles são usados para relatórios, verificações e gatilhos. Atrasos no acesso a dados também afetam o desempenho. Quando o banco de dados cresce, dados irrelevantes devem ser excluídos. A remoção é uma operação difícil que também consome alguns dos recursos.

Os problemas de atrasos durante a coleta e o armazenamento no Zabbix são resolvidos através do cache: vários tipos de caches, cache no banco de dados. Para resolver o terceiro problema, o armazenamento em cache não é adequado; portanto, o Zabbix usou o TimescaleDB.
Andrey Gushchin , engenheiro de suporte técnico da
Zabbix SIA, falará sobre isso. Andrey apoia o Zabbix há mais de 6 anos e está enfrentando diretamente o desempenho.
Como o TimescaleDB funciona, qual desempenho ele pode oferecer em comparação com o PostgreSQL comum? Qual o papel do Zabbix no TimescaleDB? Como executar a partir do zero e como migrar com o PostgreSQL e qual desempenho é melhor? Sobre tudo isso sob o corte.
Desafios de desempenho
Cada sistema de monitoramento enfrenta desafios específicos de desempenho. Vou falar sobre três deles: coleta e processamento de dados, armazenamento, histórico de limpeza.
Rápida coleta e processamento de dados. Um bom sistema de monitoramento deve receber rapidamente todos os dados e processá-los de acordo com as expressões de gatilho - de acordo com seus próprios critérios. Após o processamento, o sistema também deve salvar rapidamente esses dados no banco de dados para usá-los posteriormente.
Mantendo uma história. Um bom sistema de monitoramento deve armazenar o histórico no banco de dados e fornecer acesso conveniente às métricas. É necessária uma história para usá-la em relatórios, gráficos, gatilhos, limites e itens de dados calculados para alertas.
Limpar histórico. Às vezes chega um dia em que você não precisa armazenar métricas. Por que você precisa dos dados coletados há 5 anos, um mês ou dois: alguns nós são excluídos, alguns hosts ou métricas não são mais necessários, porque estão desatualizados e pararam de coletar. Um bom sistema de monitoramento deve armazenar dados históricos e excluí-los de tempos em tempos, para que o banco de dados não cresça.
A limpeza de dados desatualizados é um problema importante que tem um grande impacto no desempenho do banco de dados.
Cache do Zabbix
No Zabbix, a primeira e a segunda chamadas são resolvidas usando o cache. A RAM é usada para coleta e processamento de dados. Para armazenamento - histórias em gatilhos, gráficos e elementos de dados calculados. No lado do banco de dados, há um certo armazenamento em cache para as principais amostras, por exemplo, gráficos.
O armazenamento em cache na lateral do servidor Zabbix é:
- ConfigurationCache;
- ValueCache;
- HistoryCache;
- TrendsCache.
Vamos considerá-los com mais detalhes.
ConfigurationCache
Esse é o principal cache no qual armazenamos métricas, hosts, elementos de dados, gatilhos - tudo o que é necessário para o Pré-processamento e a coleta de dados.
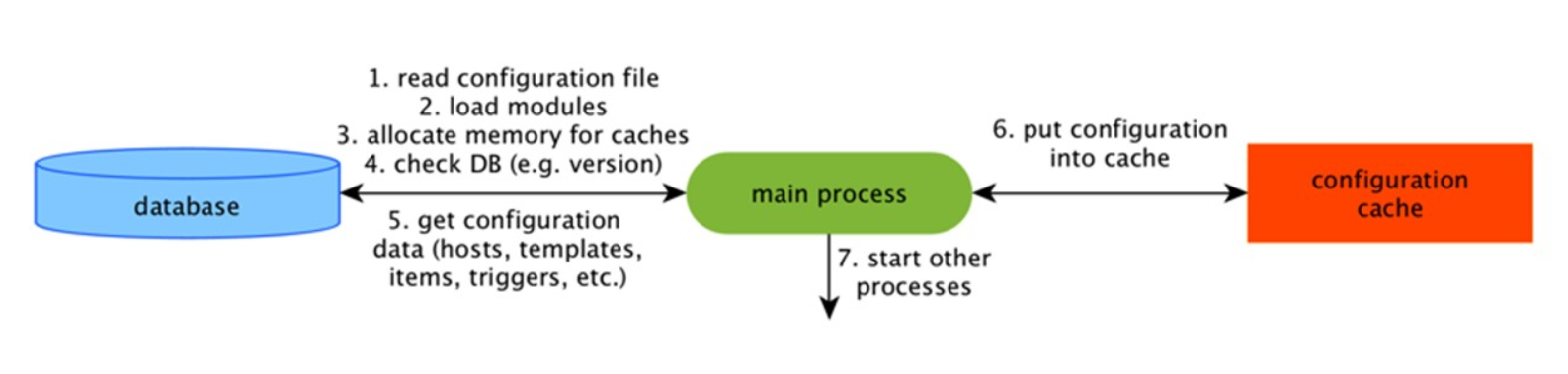
Tudo isso é armazenado no ConfigurationCache para não criar consultas desnecessárias no banco de dados. Após o início do servidor, atualizamos esse cache, criamos e atualizamos periodicamente as configurações.
Coleta de dados
O esquema é bastante amplo, mas o principal é os
montadores . Estes são os vários "pollers" - processos de montagem. Eles são responsáveis por diferentes tipos de montagem: eles coletam dados via SNMP, IPMI e transferem tudo para o Pré-processamento.
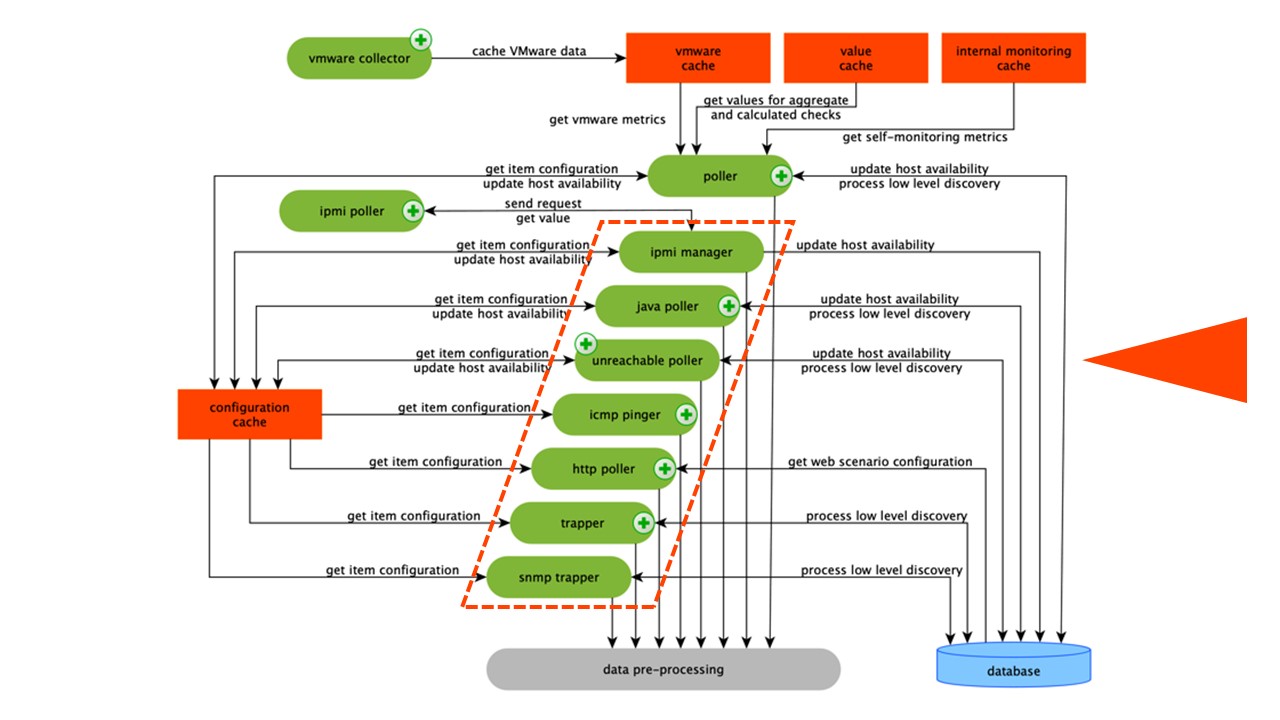 Os coletores são circulados em laranja.
Os coletores são circulados em laranja.O Zabbix calculou os elementos de dados de agregação necessários para agregar validações. Se os tivermos, coletamos os dados diretamente do ValueCache.
Histórico de Pré-ProcessamentoCache
Todos os coletores usam o ConfigurationCache para receber trabalhos. Em seguida, eles os passam para o pré-processamento.

O pré-processamento usa o ConfigurationCache para receber as etapas de pré-processamento. Ele processa esses dados de várias maneiras.
Depois de processar os dados usando o Pré-processamento, salvamos no HistoryCache para processá-los. Isso encerra a coleta de dados e seguimos para o processo principal no Zabbix -
sincronizador de histórico , pois é uma arquitetura monolítica.
Nota: O pré-processamento é uma operação bastante difícil. Desde a versão 4.2, ele foi enviado para proxy. Se você possui um Zabbix muito grande com um grande número de elementos de dados e uma frequência de coleta, isso facilita muito o trabalho.Cache do ValueCache, histórico e tendências
O sincronizador de histórico é o principal processo que processa atomicamente cada elemento de dados, ou seja, cada valor.
O sincronizador de histórico obtém valores do HistoryCache e verifica na Configuração os gatilhos para cálculos. Se forem, ele calcula.
O sincronizador de histórico cria um evento, uma escalação para criar alertas, se necessário pela configuração, e registros. Se houver gatilhos para processamento subseqüente, ele se lembrará desse valor no ValueCache para não acessar a tabela de histórico. Portanto, o ValueCache é preenchido com dados necessários para o cálculo de gatilhos, elementos calculados.
O sincronizador de histórico grava todos os dados no banco de dados e é gravado no disco. O processo de processamento termina aqui.
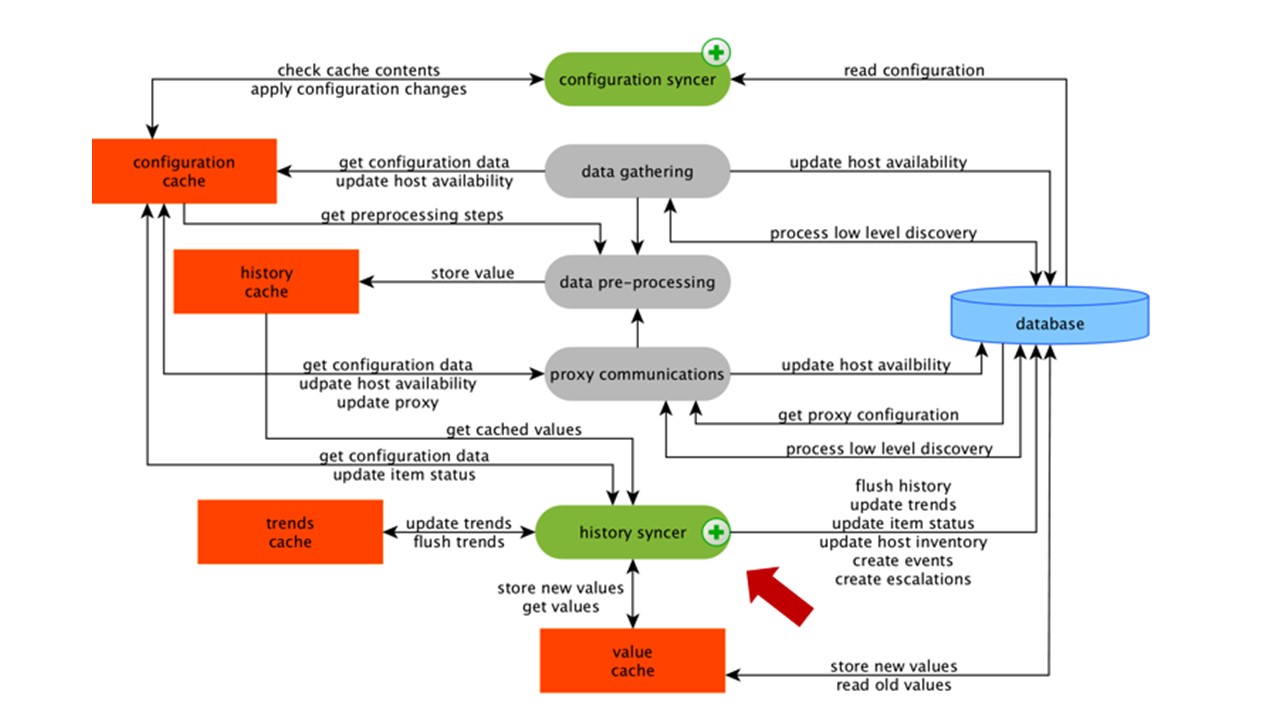
Armazenamento em cache do banco de dados
No lado do banco de dados, existem vários caches quando você deseja assistir a gráficos ou relatórios de eventos:
Innodb_buffer_pool no lado do MySQL;shared_buffers no lado do PostgreSQL;effective_cache_size no lado do Oracle;shared_pool no lado do DB2.
Existem muitos outros caches, mas esses são os principais para todos os bancos de dados. Eles permitem que você mantenha na memória os dados que geralmente são necessários para consultas. Eles têm suas próprias tecnologias para isso.
O desempenho do banco de dados é crítico
O Zabbix-server constantemente coleta dados e os grava. Ao reiniciar, ele também lê o histórico para preencher o ValueCache. Scripts e relatórios usam a
API do
Zabbix , construída com base na interface da Web. A API do Zabbix entra em contato com o banco de dados e recebe os dados necessários para gráficos, relatórios, listas de eventos e problemas recentes.
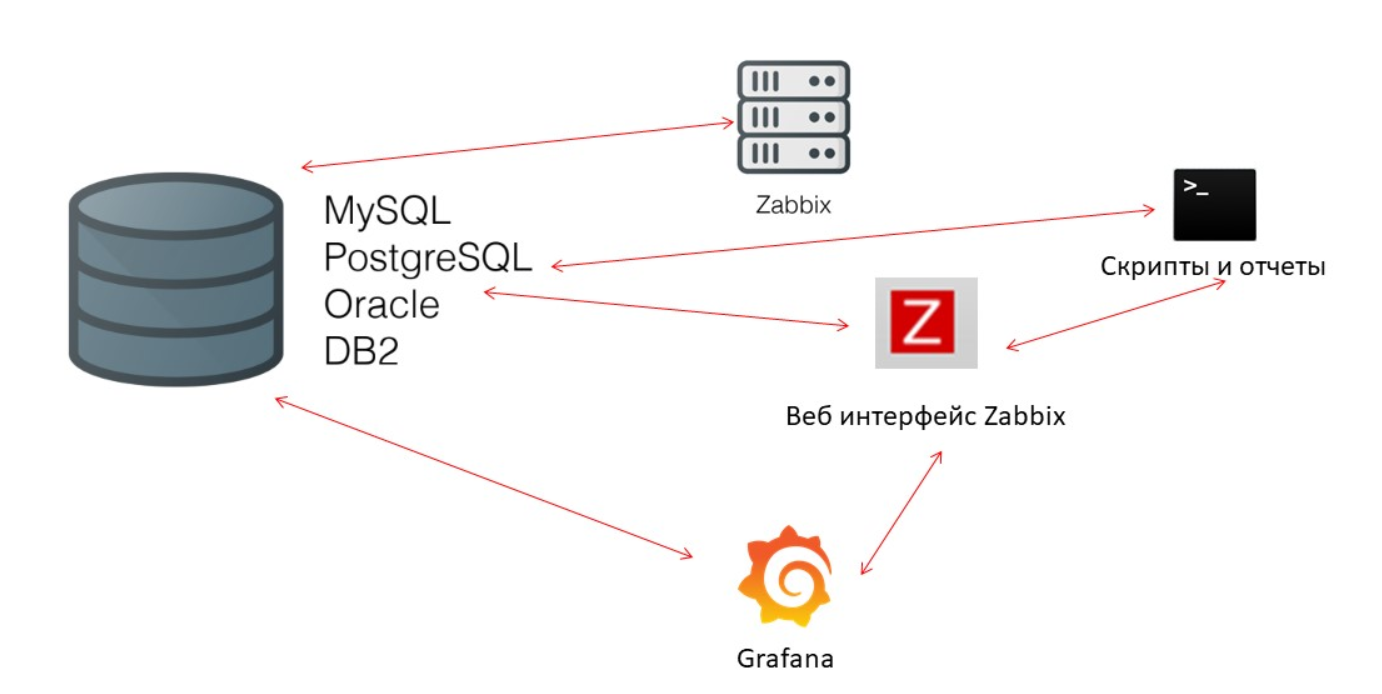
Para visualização -
Grafana . Entre nossos usuários, esta é uma solução popular. Ele pode enviar solicitações diretamente pela API do Zabbix e para o banco de dados, além de criar certa competitividade para o recebimento de dados. Portanto, precisamos de um ajuste mais refinado e melhor do banco de dados para corresponder à rápida produção de resultados e testes.
Governanta
O terceiro desafio de desempenho no Zabbix é limpar a história com a governanta. Ele segue todas as configurações - os elementos de dados indicam quanto manter a dinâmica das mudanças (tendências) em dias.
Computamos o TrendsCache em tempo real. Quando os dados chegam, agregamos em uma hora e os escrevemos em tabelas para a dinâmica das mudanças de tendência.
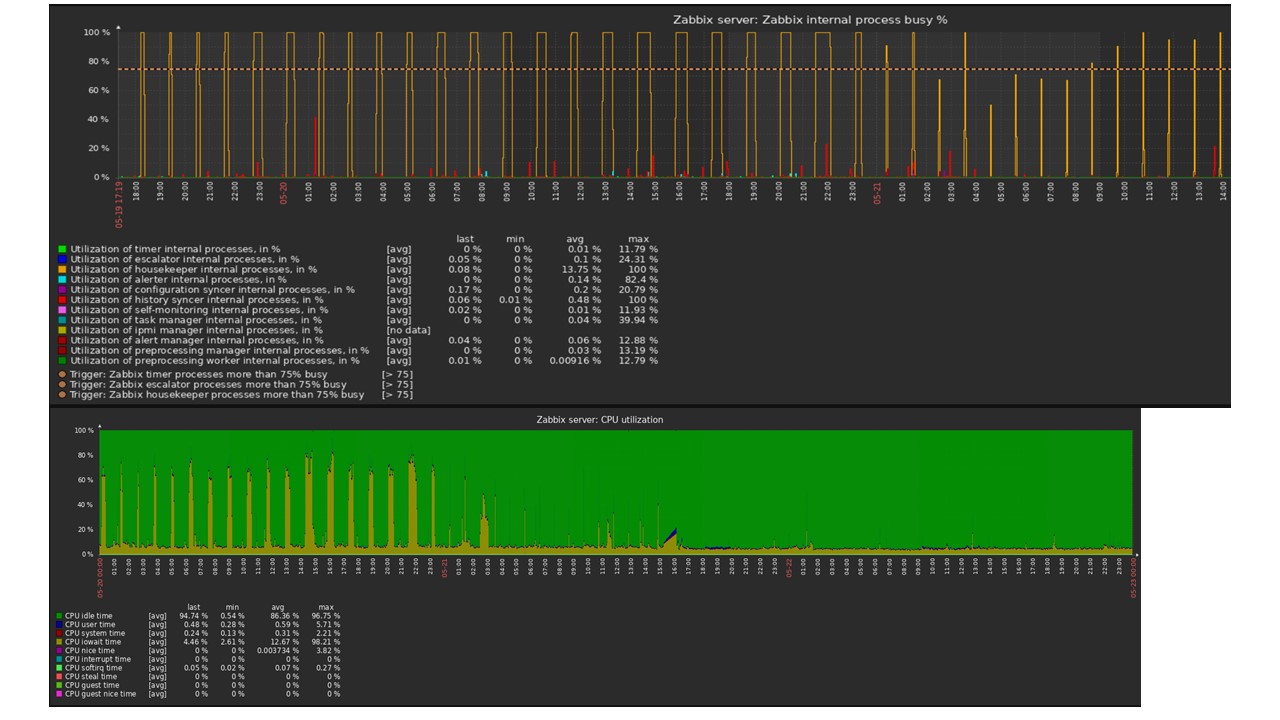
Governanta inicia e exclui informações do banco de dados com os "seletores" habituais. Isso nem sempre é eficaz, o que pode ser entendido a partir dos gráficos de desempenho dos processos internos.
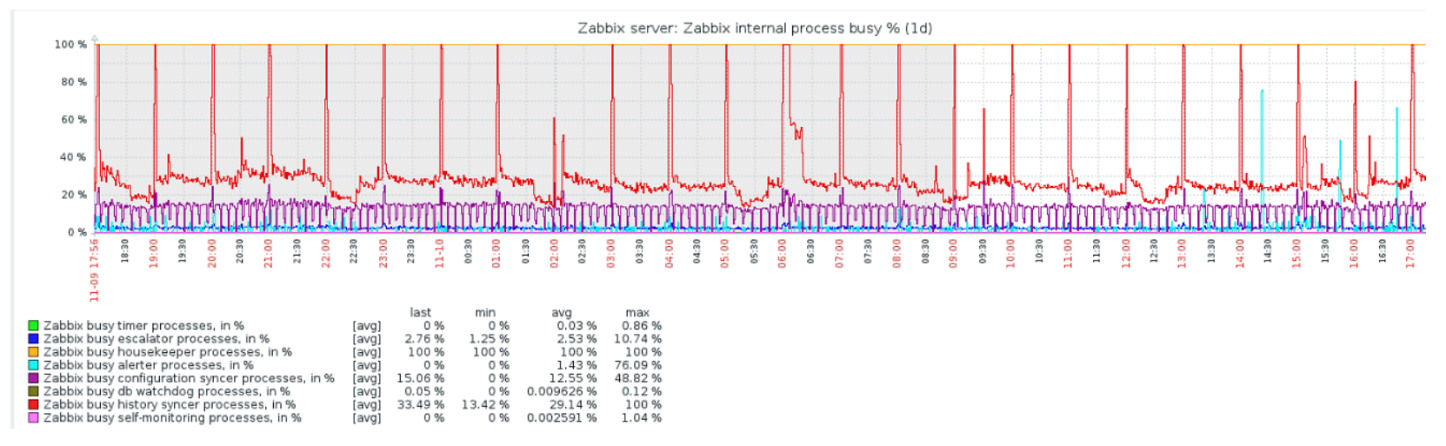
Um gráfico vermelho indica que o sincronizador de histórico está constantemente ocupado. O gráfico laranja acima é Governanta, que está em execução constante. Ele espera que o banco de dados exclua todas as linhas que ele especificou.
Quando desligar a governanta? Por exemplo, existe um "ID do item" e você precisa excluir as últimas 5 mil linhas em um determinado período de tempo. Obviamente, isso acontece por índice. Mas geralmente o conjunto de dados é muito grande e o banco de dados ainda lê do disco e o eleva para o cache. Essa sempre é uma operação muito cara para o banco de dados e, dependendo do tamanho do banco de dados, pode levar a problemas de desempenho.
Governanta é apenas uma desconexão. Na interface da Web, há uma configuração no "Administração geral" para Governanta. Desative a limpeza interna para o histórico de tendências interno e ele não gerencia mais isso.
A governanta foi desligada, os gráficos foram nivelados - qual poderia ser o problema nesse caso e o que poderia ajudar na solução da terceira chamada de desempenho?
Particionamento - particionamento ou particionamento
Normalmente, o particionamento é configurado de maneira diferente em cada banco de dados relacional listado. Cada um tem sua própria tecnologia, mas são semelhantes, em geral. Criar uma nova partição geralmente leva a certos problemas.
As partições geralmente são configuradas dependendo da "configuração" - a quantidade de dados criados em um dia. Como regra, o particionamento é exposto em um dia, isso é o mínimo. Para tendências da nova partição - por 1 mês.
Os valores podem mudar no caso de uma "configuração" muito grande. Se a pequena "configuração" for de até 5.000 nvps (novos valores por segundo), a média é de 5.000 a 25.000, e a grande estará acima de 25.000 nvps. Estas são instalações grandes e muito grandes que requerem uma configuração cuidadosa do banco de dados.
Em instalações muito grandes, uma execução de um dia pode não ser a ideal. Eu vi no MySQL partições de 40 GB ou mais por dia. Essa é uma quantidade muito grande de dados que pode levar a problemas e precisa ser reduzida.
O que dá o particionamento?
Tabelas de Particionamento . Geralmente, esses são arquivos separados no disco. O plano de consulta seleciona melhor uma partição. O particionamento geralmente é usado em um intervalo - para o Zabbix, isso também é verdade. Usamos lá "timestamp" - tempo desde o início da época. Temos números comuns. Você define o início e o fim do dia - esta é uma partição.
Exclusão rápida -
DELETE . Um único arquivo / subtabela é selecionado, não uma seleção de linhas a serem excluídas.
Visivelmente acelera a recuperação de dados SELECT - usa uma ou mais partições, não a tabela inteira. Se você solicitar dados há dois dias, eles serão selecionados no banco de dados mais rapidamente, pois você precisará carregar no cache e emitir apenas um arquivo, não uma tabela grande.
Muitas vezes, muitos bancos de dados também aceleram inserções
INSERT na tabela filho.
Timescaledb
Para a v 4.2, voltamos nossa atenção para o TimescaleDB. Esta é uma extensão para o PostgreSQL com uma interface nativa. A extensão funciona efetivamente com dados de séries temporais, sem perder os benefícios dos bancos de dados relacionais. O TimescaleDB também particiona automaticamente.
O TimescaleDB tem o conceito de uma
hipertabela que você cria. Ele contém
pedaços - partições. Os pedaços são fragmentos controlados automaticamente de uma hipertabela que não afetam outros fragmentos. Cada pedaço tem seu próprio intervalo de tempo.
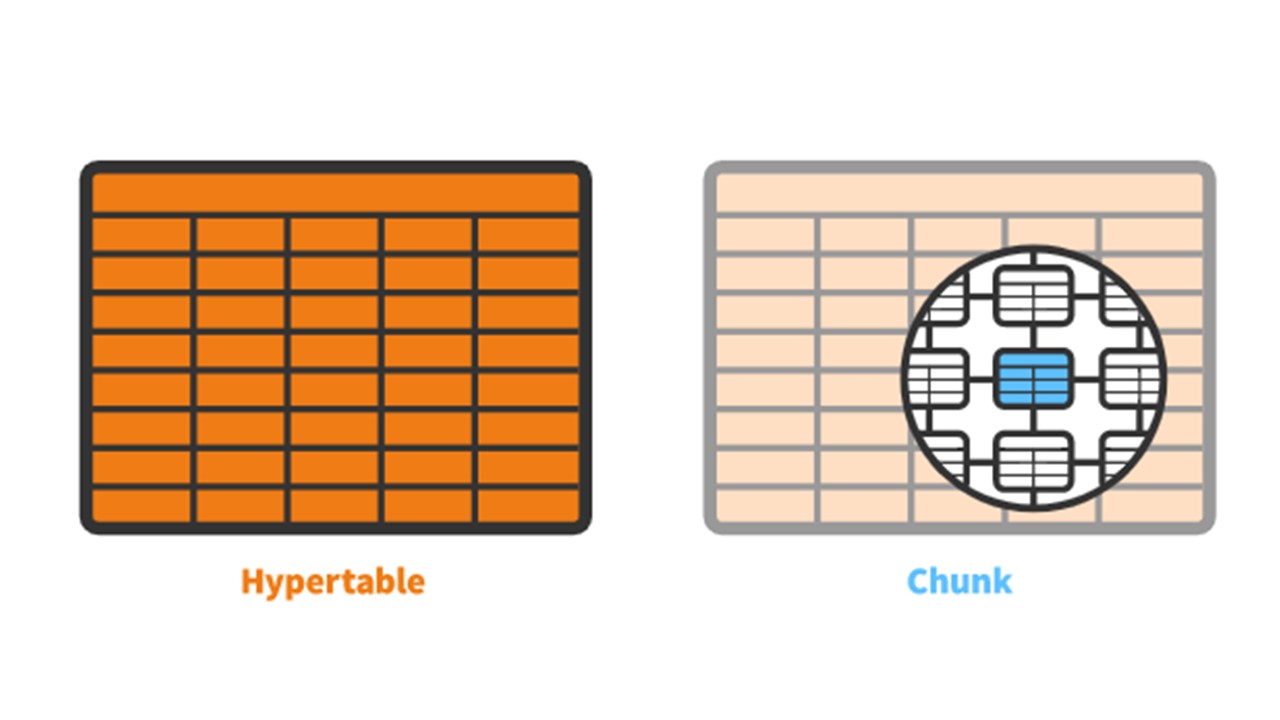
TimescaleDB vs PostgreSQL
O TimescaleDB funciona realmente eficientemente. Os fabricantes de extensões afirmam que usam um algoritmo de processamento de solicitação mais correto, em particular, <code> insere </code>. Quando as dimensões da inserção do conjunto de dados aumentam, o algoritmo mantém um desempenho constante.
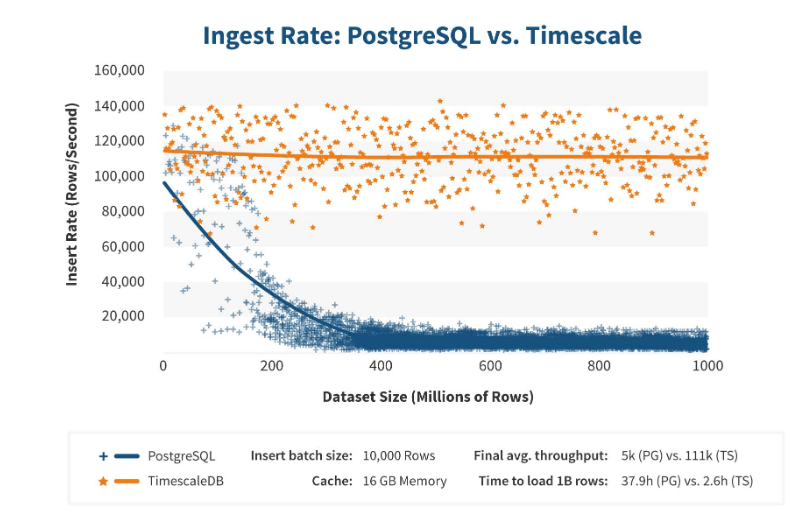
Depois de 200 milhões de linhas, o PostgreSQL geralmente começa a ceder bastante e perde desempenho até 0. O TimescaleDB permite que você insira “inserções” com eficiência para qualquer quantidade de dados.
Instalação
A instalação do TimescaleDB é fácil o suficiente para qualquer pacote. A
documentação descreve tudo em detalhes - depende dos pacotes oficiais do PostgreSQL. O TimescaleDB também pode ser compilado e compilado manualmente.
Para o banco de dados Zabbix, simplesmente ativamos a extensão:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
Você ativa a
extension e a cria para o banco de dados Zabbix. O passo final é criar uma hipertabela.
Migrando Tabelas de Histórico para o TimescaleDB
Existe uma função especial
create_hypertable :
SELECT create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); UPDATE config SET db_extension='timescaledb', hk_history_global=1, hk_trends_global=1
A função possui três parâmetros. A primeira é uma
tabela no banco de
dados para a qual você precisa criar uma hipertabela. O segundo é o
campo pelo qual criar
chunk_time_interval - o intervalo dos blocos de partições que você deseja usar. No meu caso, o intervalo é de um dia - 86.400.
O terceiro parâmetro é
migrate_data . Se definido como
true , todos os dados atuais serão transferidos para os pedaços criados anteriormente. Eu mesmo usei
migrate_data . Eu tinha cerca de 1 TB, o que levou mais de uma hora. Mesmo em alguns casos, ao testar, excluí os dados históricos dos tipos de caracteres opcionais para armazenamento, para não transferi-los.
A última etapa é
UPDATE : definimos
timescaledb em
db_extension para que o banco de dados entenda que existe essa extensão. O Zabbix o ativa e usa corretamente a sintaxe e as consultas já existentes no banco de dados - os recursos necessários para o TimescaleDB.
Configuração de ferro
Eu usei dois servidores. A primeira é uma
máquina VMware . É pequeno o suficiente: 20 processadores Intel® Xeon® E5-2630 v 4 a 2.20GHz, 16 GB de RAM e um SSD de 200 GB.
Eu instalei o PostgreSQL 10.8 nele com o Debian 10.8-1.pgdg90 + 1 e o sistema de arquivos xfs. Eu configurei tudo minimamente para usar esse banco de dados específico, menos o que o próprio Zabbix usará.
Na mesma máquina, havia um servidor Zabbix, PostgreSQL e
agentes de carregamento . Eu tinha 50 agentes ativos que usavam o
LoadableModule para gerar rapidamente vários resultados: números, strings. Entupi o banco de dados com muitos dados.
Inicialmente, a configuração continha
5.000 itens de dados por host. Quase todos os elementos continham um gatilho, parecendo instalações reais. Em alguns casos, houve mais de um gatilho. Havia
3.000 a 7.000 gatilhos por nó de rede.
O intervalo para atualizar itens de dados é de
4-7 segundos . Regulei a carga em si, usando não apenas 50 agentes, mas também adicionando mais. Além disso, com a ajuda de elementos de dados, ajustei dinamicamente a carga e reduzi o intervalo de atualização para 4 s.
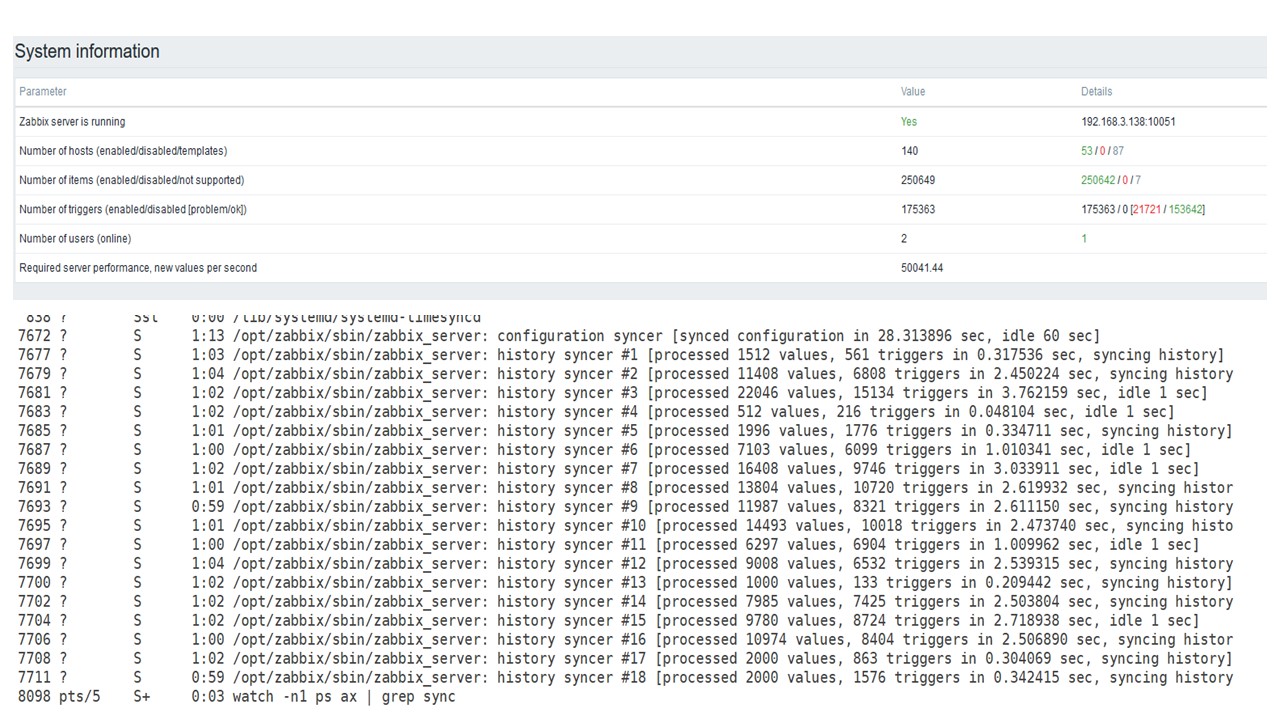
PostgreSQL 35.000 nvps
A primeira execução neste hardware que tive no PostgreSQL puro - 35 mil valores por segundo. Como você pode ver, a inserção de dados leva frações de segundo - tudo está bem e rápido. A única coisa que um SSD de 200 GB está sendo preenchido rapidamente.
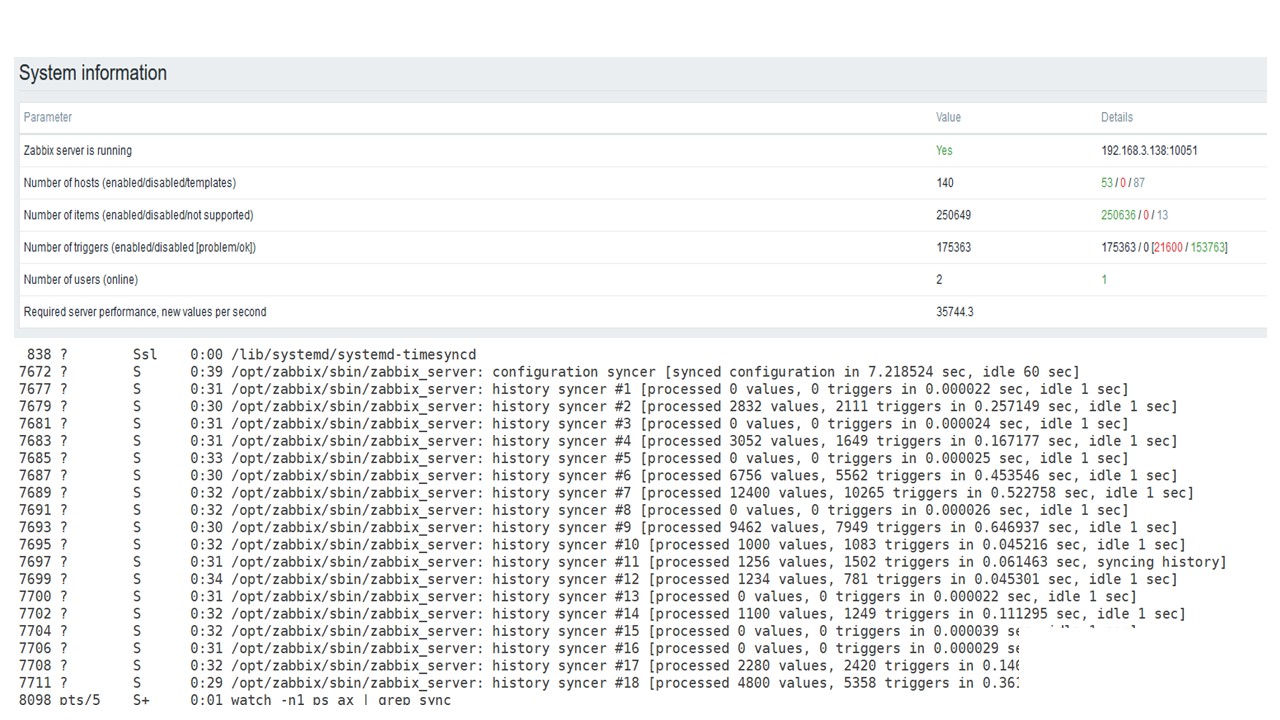
Este é o painel de desempenho padrão do servidor Zabbix.
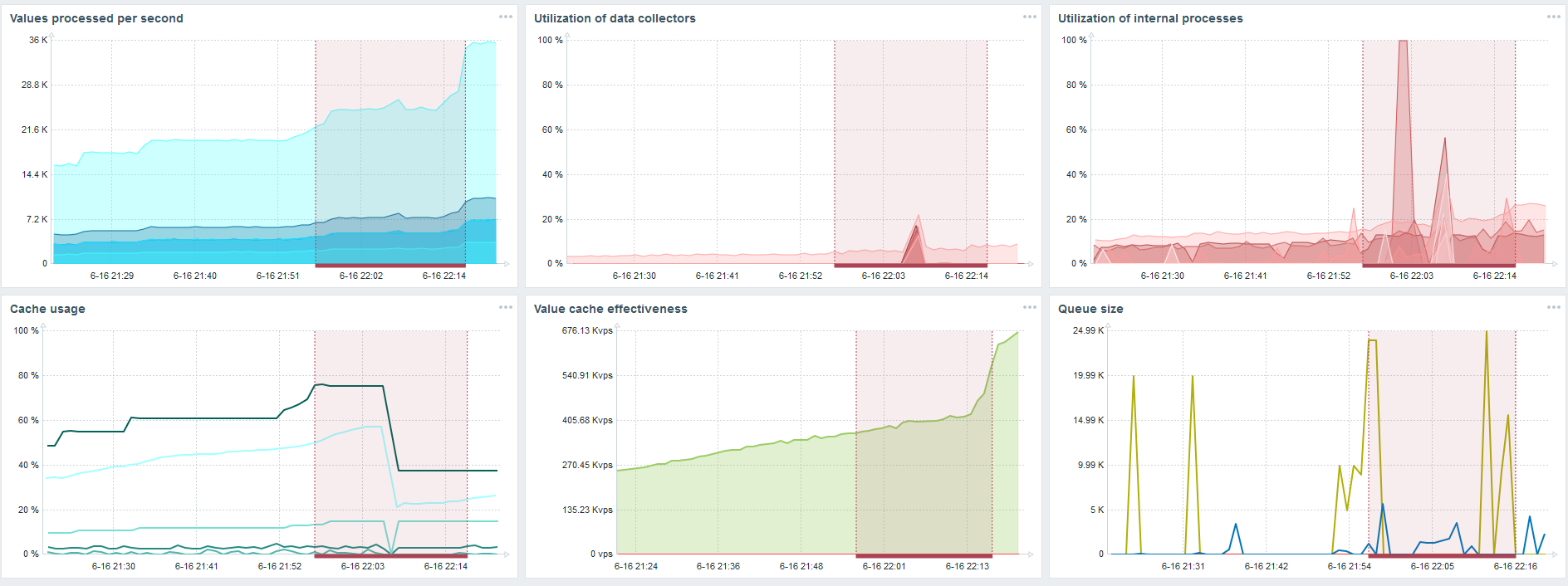
O primeiro gráfico azul é o número de valores por segundo. O segundo gráfico à direita é o carregamento dos processos de montagem. O terceiro está carregando os processos internos de montagem: sincronizadores de histórico e Governanta, que já está em execução há algum tempo.
O quarto gráfico mostra o uso do HistoryCache. Este é um buffer antes de inserir no banco de dados. O quinto gráfico verde mostra o uso do ValueCache, ou seja, quantas ocorrências do ValueCache para acionadores são vários milhares de valores por segundo.
PostgreSQL 50.000 nvps
Aumentei a carga para 50 mil valores por segundo no mesmo hardware.
Ao carregar do Governanta, uma inserção de 10 mil valores foi registrada por 2-3 s.
 Governanta já está começando a atrapalhar.
Governanta já está começando a atrapalhar.O terceiro gráfico mostra que, em geral, o carregamento de caçadores e sincronizadores de histórico ainda está em 60%. No quarto gráfico, o HistoryCache já começa a se encher de maneira bastante ativa durante o trabalho de Governanta. Está 20% cheio - é cerca de 0,5 GB.
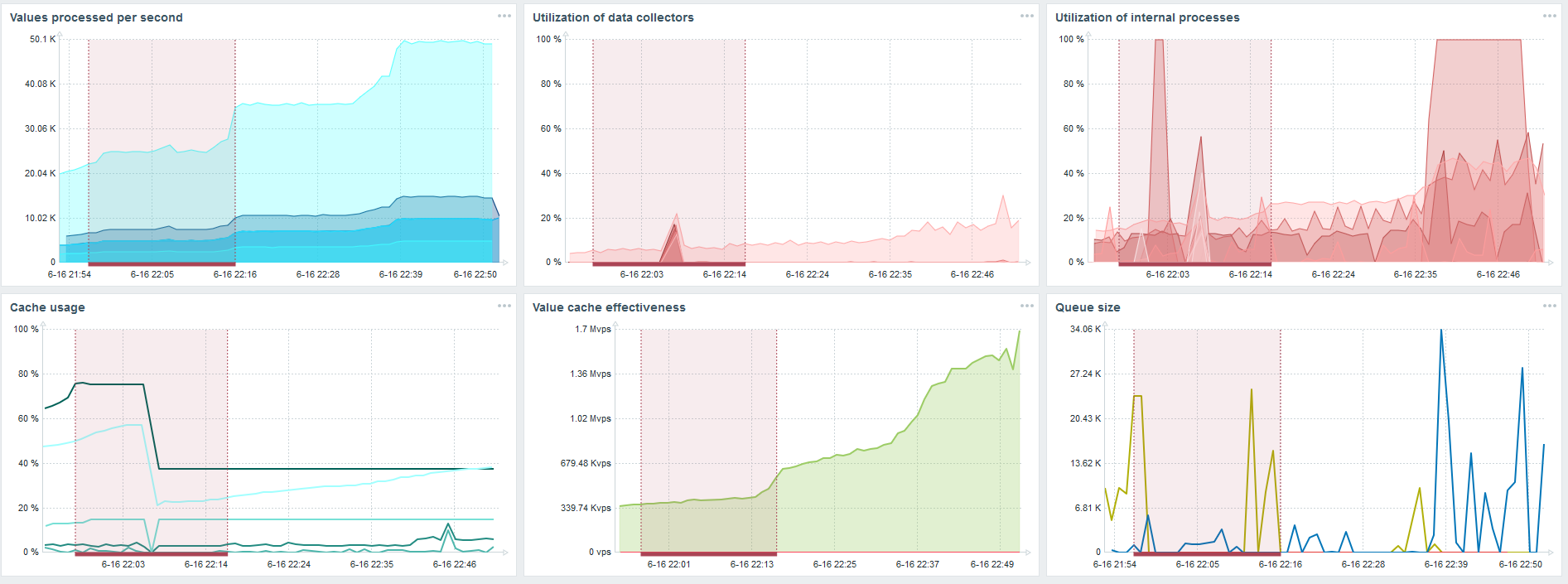
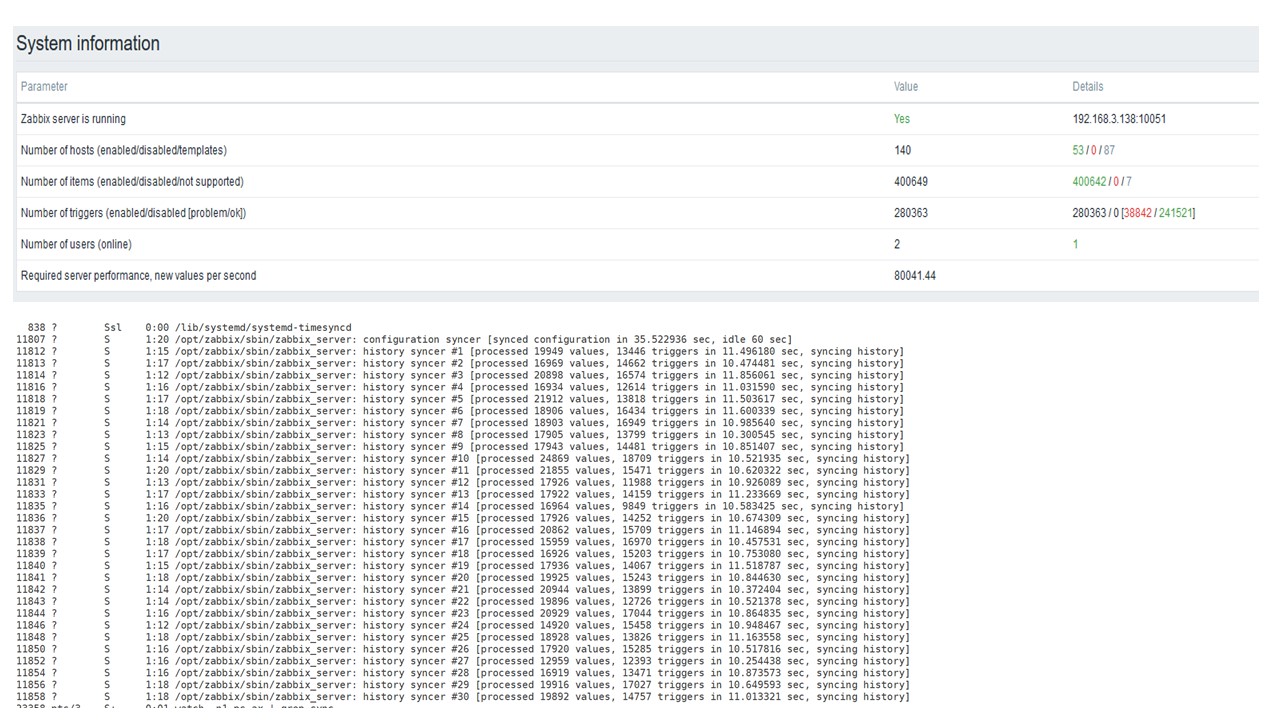
PostgreSQL 80.000 nvps
Aumentei a carga para 80 mil valores por segundo. São aproximadamente 400 mil elementos de dados e 280 mil gatilhos.
 A inserção para carregar trinta sincronizadores de histórico já é bastante alta.
A inserção para carregar trinta sincronizadores de histórico já é bastante alta.Também aumentei vários parâmetros: sincronizadores de histórico, caches.
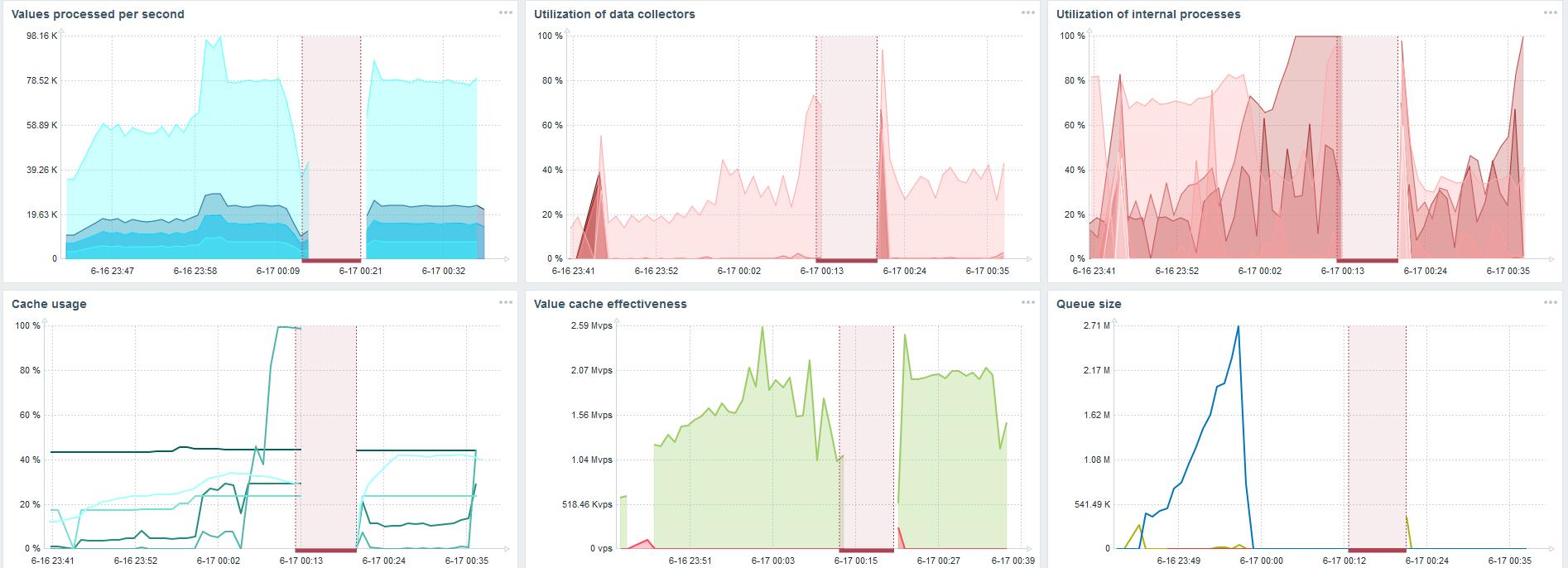
No meu hardware, a carga dos sincronizadores de histórico aumentou ao máximo. O HistoryCache foi preenchido rapidamente com dados - os dados para processamento acumulados no buffer.
Durante todo esse tempo, observei como o processador, a RAM e outros parâmetros do sistema eram usados e descobri que a utilização do disco era maximizada.
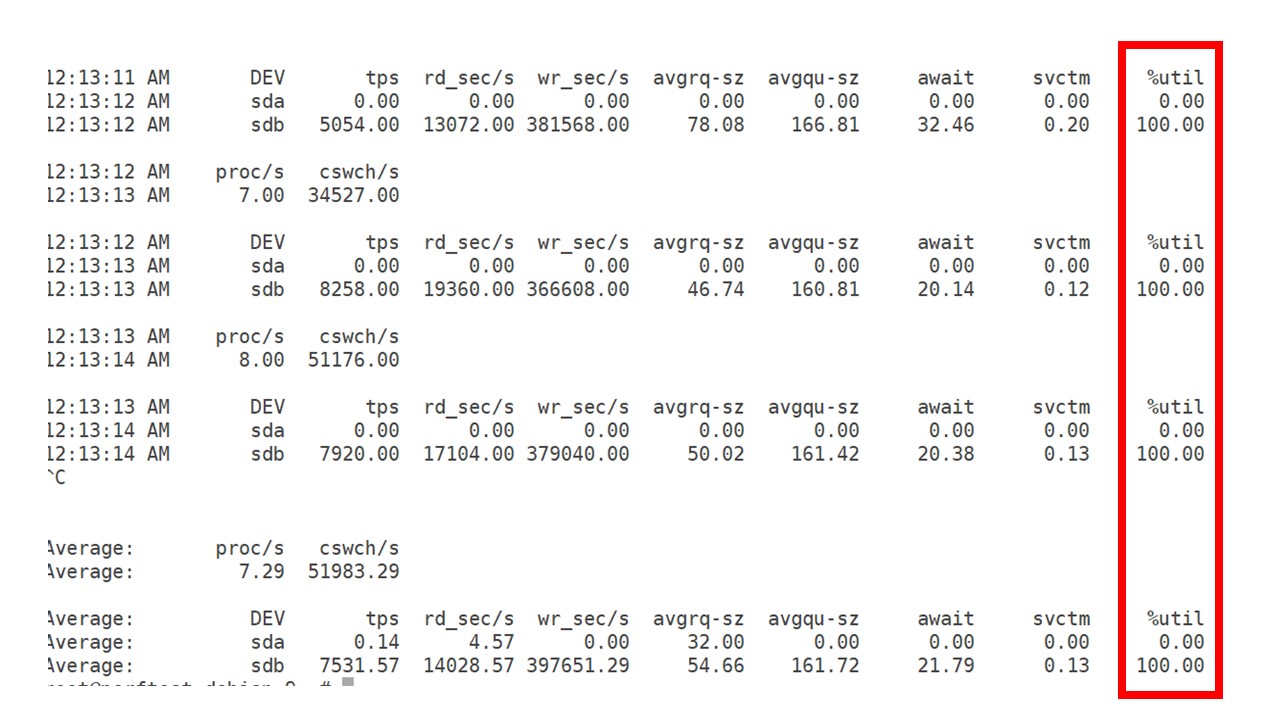
Tirei o
máximo proveito da unidade neste hardware e nesta máquina virtual. Nessa intensidade, o PostgreSQL começou a despejar dados de maneira bastante ativa, e o disco não teve mais tempo para trabalhar na escrita e na leitura.
Segundo servidor
Peguei outro servidor que já tinha 48 processadores e 128 GB de RAM. Ajuste - configure 60 sincronizadores de histórico e tenha um desempenho aceitável.
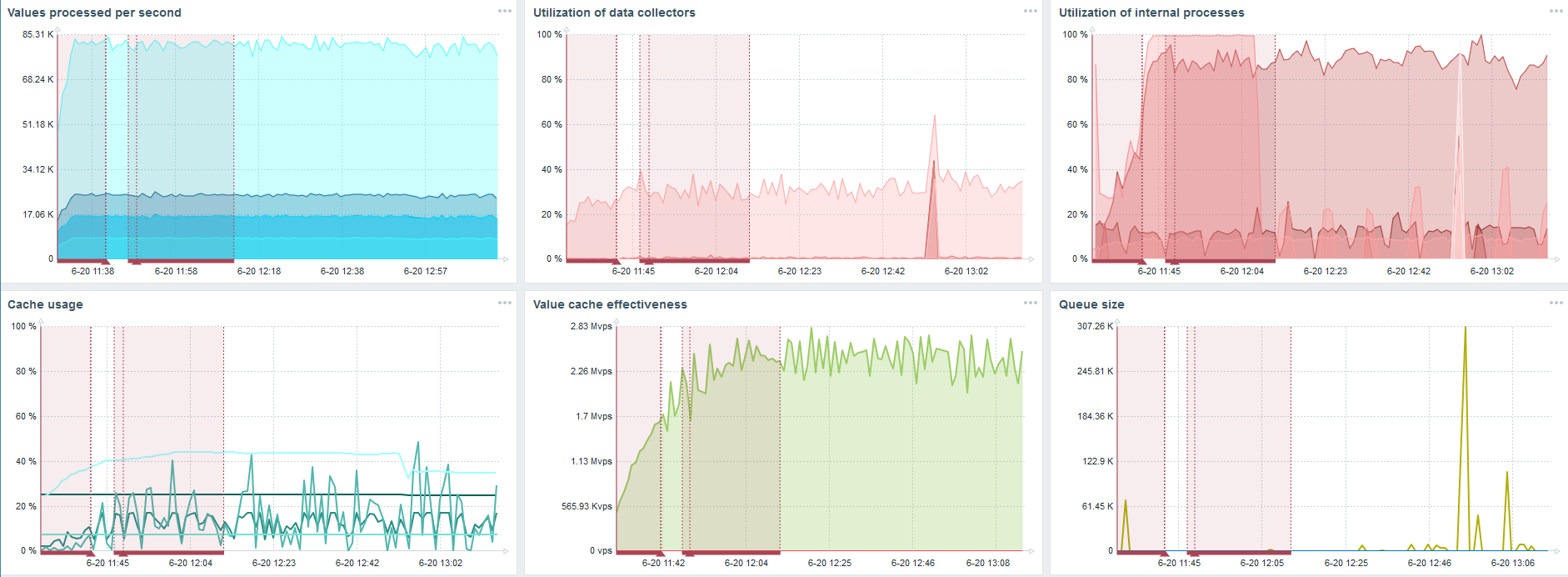
De fato, esse já é um limite de desempenho em que algo precisa ser feito.
TimescaleDB. 80.000 nvps
Minha principal tarefa é testar os recursos do TimescaleDB a partir do carregamento do Zabbix. 80 mil valores por segundo é muito, a frequência de coleta de métricas (exceto Yandex, é claro) e uma "configuração" bastante grande.
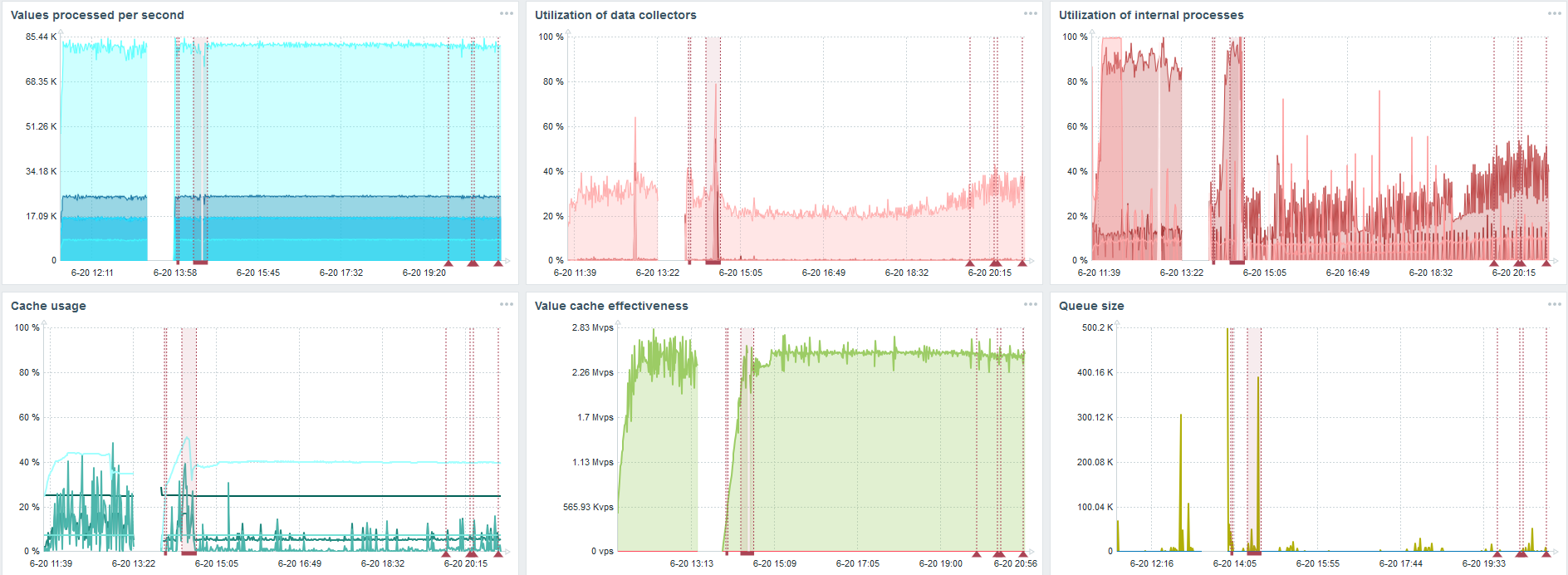
Há uma falha em cada gráfico - isso é apenas migração de dados. Após falhas no servidor Zabbix, o perfil de inicialização do sincronizador de histórico mudou muito - caiu três vezes.
O TimescaleDB permite inserir dados quase três vezes mais rápido e usar menos HistoryCache.
Consequentemente, os dados serão entregues a você em tempo hábil.
TimescaleDB. 120.000 nvps
Aumentei o número de elementos de dados para 500 mil. A principal tarefa era verificar os recursos do TimescaleDB - obtive o valor calculado de 125 mil valores por segundo.
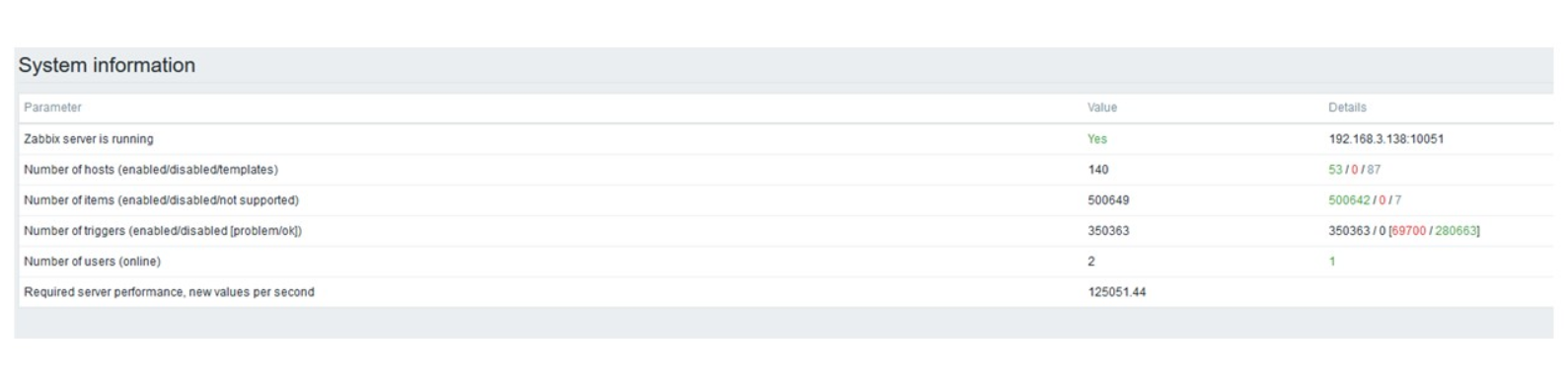
Esta é uma "configuração" funcional que pode funcionar por um longo tempo. Mas como meu disco tinha apenas 1,5 TB, eu o preenchi em alguns dias.
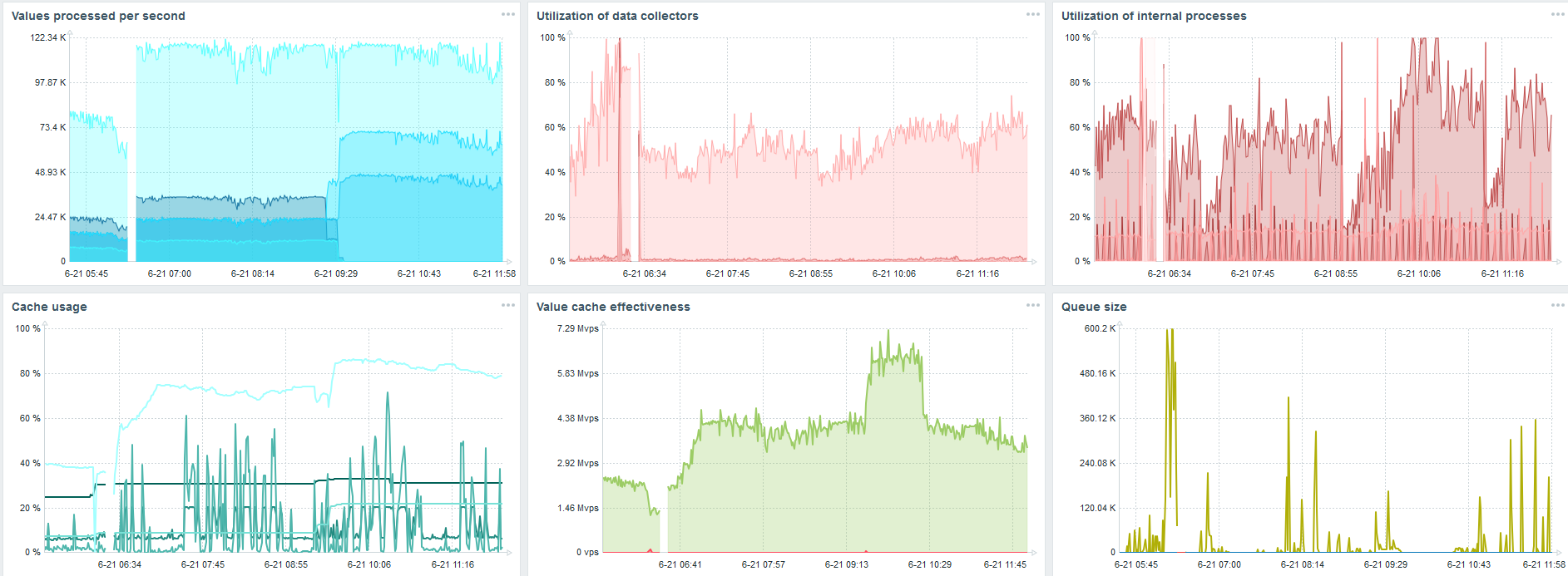
Mais importante, ao mesmo tempo, novas partições do TimescaleDB foram criadas.
Para desempenho, isso é completamente invisível. Quando partições são criadas no MySQL, por exemplo, tudo é diferente. Geralmente isso acontece à noite, porque bloqueia a inserção geral, trabalhando com tabelas e pode criar degradação do serviço. No caso do TimescaleDB, não é.
Por exemplo, mostrarei um gráfico do conjunto na comunidade. O TimescaleDB está incluído na imagem, devido a isso a carga no uso de io.weight no processador caiu. O uso de elementos de processos internos também diminuiu. E essa é uma máquina virtual comum em discos de panqueca comuns, não um SSD.
Conclusões
O TimescaleDB é uma boa solução para pequenas "configurações" que dependem do desempenho do disco. Isso permitirá que você continue trabalhando bem até que o banco de dados seja migrado para o ferro mais rapidamente.
O TimescaleDB é fácil de configurar, fornece um aumento de desempenho, funciona bem com o Zabbix e
possui vantagens sobre o PostgreSQL .
Se você usa o PostgreSQL e não planeja alterá-lo, recomendo
usar o PostgreSQL com a extensão TimescaleDB em conjunto com o Zabbix . Esta solução funciona de forma eficaz para a "configuração" média.
Dizemos "alto desempenho" - queremos dizer HighLoad ++ . Esperando para se familiarizar com as tecnologias e práticas que permitem que os serviços atendam a milhões de usuários, muito brevemente. Já compilamos uma lista de relatórios para 7 e 8 de novembro, mas ainda podemos oferecer mitaps .
Assine a nossa newsletter e telegrama , na qual revelamos as fichas da próxima conferência e saiba como tirar o máximo proveito dela.