O aprendizado de máquina moderno permite que você faça coisas incríveis. As redes neurais trabalham em benefício da sociedade: encontram criminosos, reconhecem ameaças, ajudam a diagnosticar doenças e tomam decisões difíceis. Os algoritmos podem superar uma pessoa em criatividade: eles pintam quadros, escrevem músicas e fazem obras-primas a partir de quadros comuns. E aqueles que desenvolvem esses algoritmos são frequentemente apresentados como cientistas caricaturados.
Nem tudo é tão assustador! Qualquer pessoa familiarizada com a programação pode construir uma rede neural a partir de modelos básicos. E nem é necessário aprender Python, tudo pode ser feito em JavaScript nativo. É fácil começar e por que o aprendizado de máquina é
necessário para os
fornecedores front-end, disse
Aleksey Okhrimenko (
obenjiro ) no FrontendConf, e o transferimos para o texto para que nomes de arquitetura e links úteis estivessem à mão.
Spoiler. Alerta!
Esta história:
- Não é para quem já trabalha com Machine Learning. Algo interessante será, mas é improvável que você esteja esperando pela abertura.
- Não é sobre transferência de aprendizado. Não falaremos sobre como escrever uma rede neural em Python e depois trabalhar com ela a partir do JavaScript. Sem truques - escreveremos redes neurais profundas especificamente em JS.
- Nem todos os detalhes. Em geral, todos os conceitos não se encaixam em um artigo, mas é claro que analisaremos o necessário.
Sobre o palestrante: Alexei Okhrimenko trabalha na Avito, no departamento de Arquitetura Frontend, e em seu tempo livre realiza o Angular Moscow Meetup e lança o “Five Minute Angular”. Durante uma longa carreira, ele desenvolveu o padrão de design MALEVICH, o analisador de gramática PEG SimplePEG. O mantenedor de Alexey CSSComb compartilha regularmente conhecimentos sobre novas tecnologias em conferências e em seu
canal de telegrama de aprendizado de máquina JS.
O aprendizado de máquina é muito popular.
Assistentes de voz, Siri, Assistente do Google, Alice, são populares e frequentemente encontrados em nossas vidas. Muitos produtos passaram do processamento de dados algorítmico convencional para o aprendizado de máquina. Um exemplo impressionante é o Google Translate.
Todas as inovações e os chips mais legais em smartphones são baseados em aprendizado de máquina.

Por exemplo, o Google NightSight usa aprendizado de máquina. As fotos legais que vemos não foram obtidas com lentes, sensores ou estabilização, mas com a ajuda do aprendizado de máquina. A máquina finalmente venceu as pessoas no DOTA2, o que significa que temos poucas chances de derrotar a inteligência artificial. Portanto, devemos dominar o aprendizado de máquina o mais rápido possível.
Vamos começar com um simples
Qual é a nossa rotina diária de programação, como geralmente escrevemos funções?

Pegamos os dados e o algoritmo que nós mesmos inventamos ou tiramos dos já prontos, combinamos, fazemos um pouco de mágica e obtemos uma função que nos dá a resposta certa em uma determinada situação.
Estamos acostumados a essa ordem de coisas, mas haveria essa oportunidade, sem conhecer o algoritmo, mas simplesmente tendo os dados e a resposta, obtém o algoritmo deles.

Você pode dizer: "Sou programador, sempre posso escrever um algoritmo".
Ok, mas por exemplo, que algoritmo é necessário aqui?

Suponha que o gato tenha orelhas afiadas e as orelhas do cachorro sejam lentas, pequenas, como um pug.

Vamos tentar entender quem é quem pelos ouvidos. Mas, em algum momento, descobrimos que os cães podem ter orelhas afiadas.

Nossa hipótese não é boa, precisamos de outras características. Com o tempo, aprenderemos mais e mais detalhes, desmotivando-nos cada vez mais e, em algum momento, desejaremos encerrar completamente esse negócio.
Eu imagino uma imagem ideal como esta: com antecedência, há uma resposta (sabemos que tipo de imagem é), há dados (sabemos que um gato é desenhado), queremos obter um algoritmo que possa alimentar dados e obter respostas na saída.
Existe uma solução - isso é aprendizado de máquina, ou seja, uma de suas partes - redes neurais profundas.
Redes neurais profundas
O aprendizado de máquina é uma área enorme. Ele oferece uma quantidade gigantesca de métodos, e cada um é bom à sua maneira.
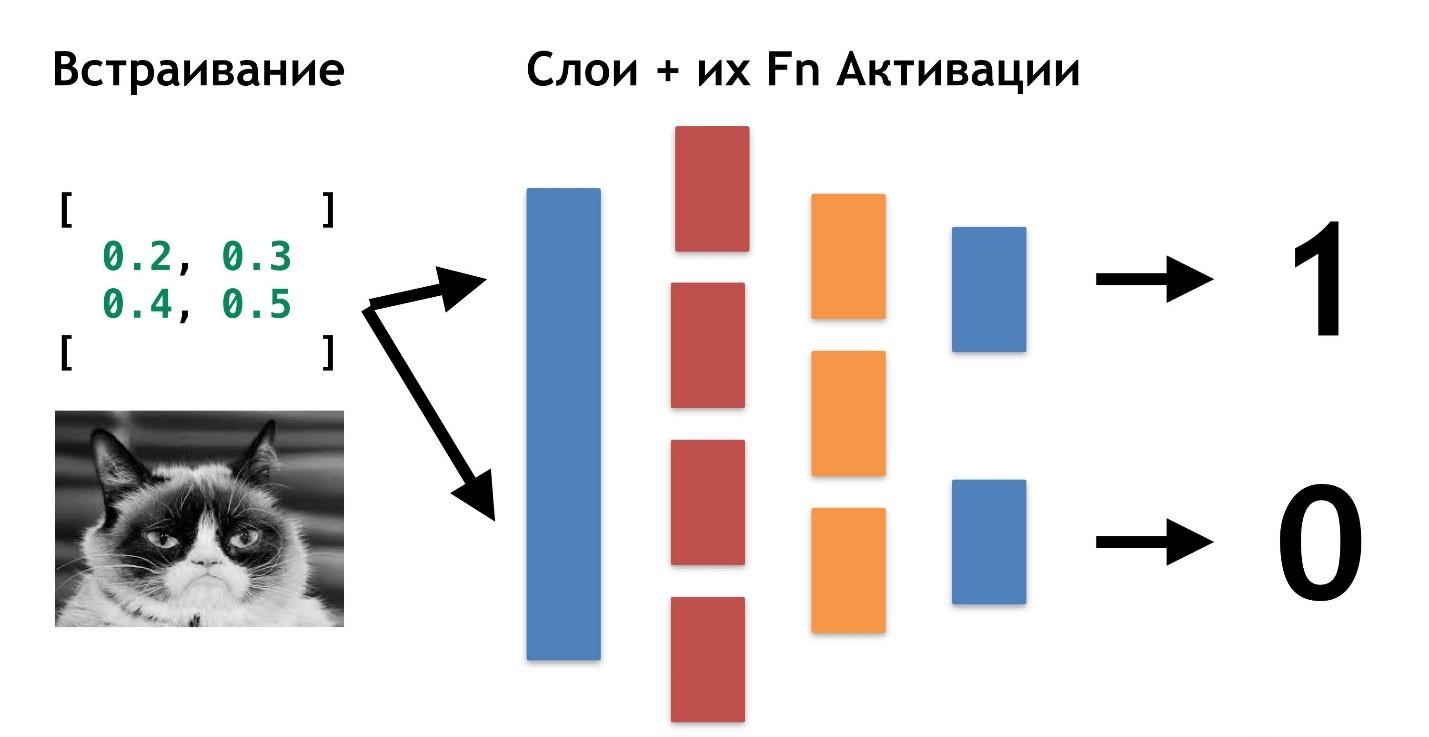
Uma delas é a Deep Neural Networks. A aprendizagem profunda tem uma vantagem inegável devido à qual se tornou popular.
Para entender essa vantagem, vejamos o problema clássico de classificação usando cães e gatos como exemplo.
Existem dados: fotos ou fotos. A primeira coisa a fazer é incorporar (incorporar), ou seja, transformar os dados para que a máquina fique confortável trabalhando com eles. É inconveniente trabalhar com fotos, o carro precisa de algo mais simples.
Primeiro, alinhe as fotos e remova a cor. Independentemente da cor do cão ou gato, é importante determinar o tipo de animal. Depois, transformamos as imagens em matrizes, onde, por exemplo, 0 é escuro, 1 é claro.

Com esta apresentação de dados, as redes neurais já podem funcionar.
Vamos criar mais duas matrizes e fundi-las em uma determinada "camada". Em seguida, multiplicaremos cada um dos elementos da camada e da matriz de dados usando uma simples multiplicação de matrizes e direcionaremos o resultado para duas funções de ativação (posteriormente analisaremos quais são essas funções). Se a função de ativação receber um número suficiente de valores, ela será "ativada" e produzirá o resultado:
- a primeira função retornará 1 se for um gato e 0 se não for um gato.
- a segunda função retornará 1 se for um cachorro e 0 se não for um cachorro.
Essa abordagem para codificar uma resposta é chamada
One-Hot Encoding .

Já são visíveis vários recursos de redes neurais profundas:
- Para trabalhar com redes neurais, você precisa codificar dados na entrada e decodificar na saída.
- A codificação nos permite abstrair dos dados.
- Alterando os dados de entrada, podemos gerar redes neurais para diferentes domínios de domínio. Mesmo aqueles em que não somos especialistas.
Não é necessário saber o que é um gato, o que é um cachorro. Basta selecionar os números necessários para uma camada adicional.
Até agora, a única coisa que permanece incerta é por que essas redes são chamadas de "profundas".
Tudo é muito simples: podemos criar outra camada (matrizes e suas funções de ativação). E transfira o resultado de uma camada para outra.
Você pode colocar um sobre o outro quantas dessas camadas e suas funções para ativação. Combinando arquitetura em camadas, obtemos uma rede neural profunda. Sua profundidade é uma infinidade de camadas. E coletivamente chamado de
"modelo" .
Agora vamos ver como os valores são selecionados para todas essas camadas. Existe uma
visualização interessante que permite entender como ocorre o processo de aprendizado.
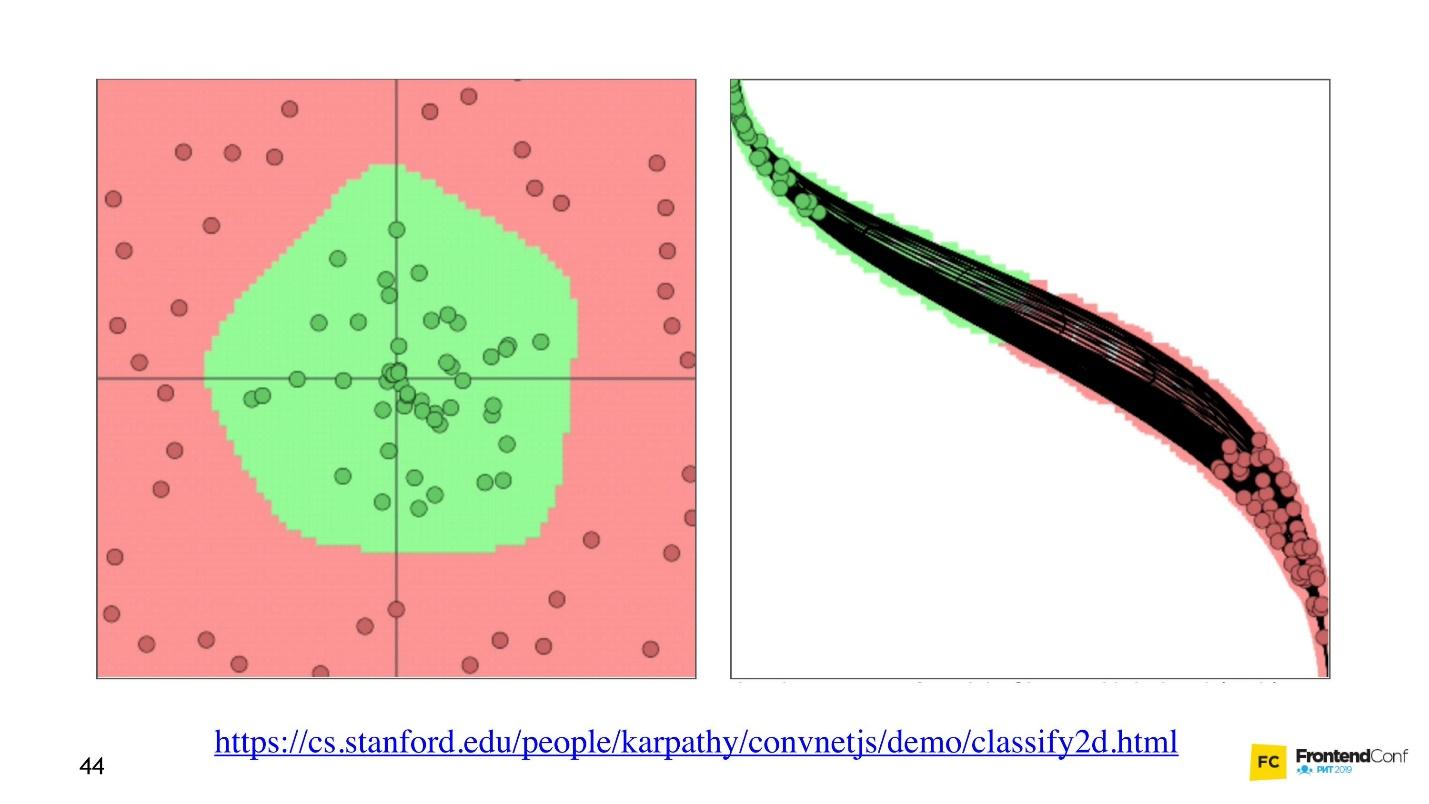
À esquerda, há dados e, à direita, uma das camadas. Pode-se observar que, alterando os valores dentro das matrizes da camada, parece que alteramos o sistema de coordenadas. Assim, adaptando-se aos dados e aprendendo. Assim, o aprendizado é o processo de seleção dos valores corretos para matrizes de camadas. Esses valores são chamados pesos ou pesos.
O aprendizado de máquina é difícil
Eu quero incomodá-lo, o aprendizado de máquina é difícil. Todas as opções acima são uma grande simplificação. No futuro, você encontrará uma enorme quantidade de álgebra linear e bastante complexa. Infelizmente, não há como escapar disso.
Claro, existem cursos, mas mesmo o treinamento mais rápido dura vários meses e não é barato. Além disso, você ainda precisa descobrir por si mesmo. O campo do aprendizado de máquina cresceu tanto que acompanhar tudo é quase impossível. Por exemplo, abaixo está um conjunto de modelos para resolver apenas uma tarefa (detecção de objeto):

Pessoalmente, eu estava muito desmotivado. Não consegui abordar as redes neurais e começar a trabalhar com elas. Mas eu encontrei um caminho e quero compartilhá-lo com você. Não é revolucionário, não há nada disso, você já está familiarizado com isso.
Blackbox - Uma abordagem simples
Não é necessário entender absolutamente todos os aspectos do aprendizado de máquina para aprender como aplicar redes neurais às suas tarefas de negócios. Vou mostrar alguns exemplos que esperamos inspirá-lo.
Para muitos, um carro também é uma caixa preta. Mas mesmo se você não sabe como isso funciona, você precisa aprender as regras. Portanto, com o aprendizado de máquina - você ainda precisa conhecer algumas regras:
- Aprenda o TensorFlow JS (biblioteca para trabalhar com redes neurais).
- Aprenda a escolher modelos.
Nós nos concentramos nessas tarefas e começamos com o código.
Aprendendo criando código
A biblioteca TensorFlow é escrita para um grande número de idiomas: Python, C / C ++, JavaScript, Go, Java, Swift, C #, Haskell, Julia, R, Scala, Rust, OCaml, Crystal. Mas definitivamente escolheremos o melhor - JavaScript.
O TensorFlow pode ser conectado à nossa página conectando um script à CDN:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
Ou use o npm:
npm install @tensorflow/tfjs-node - para o processo do nó (site);npm install @tensorflow/tfjs-node-gpu (Linux CUDA) - para a GPU, mas apenas se a máquina Linux e a placa de vídeo suportarem a tecnologia CUDA. Certifique-se de que o CUDA Compute Capability corresponda à sua biblioteca para que não aconteça que hardware caro não seja adequado.npm install @tensorflow/tfjs ( npm install @tensorflow/tfjs / Browser) - para um navegador sem usar o Node.js.
Para trabalhar com o TensorFlow JS, basta importar um dos módulos acima. Você verá muitos exemplos de código em que tudo é importado. Não é necessário fazer isso, selecione e importe apenas um.
Tensores
Quando os dados iniciais estiverem prontos, a primeira coisa a fazer é
importar o TensorFlow . Usaremos tensorflow / tfjs-node-gpu para obter aceleração devido ao poder da placa de vídeo.
Existe uma matriz de dados bidimensional - trabalharemos com ela.
A próxima coisa importante a fazer é
criar um tensor . Nesse caso, é criado um tensor de classificação 2, ou seja, de fato uma matriz bidimensional. Transferimos os dados e obtemos o tensor 2x2.
Observe que o método
print é chamado, não
console.log , porque
b (o tensor que criamos) não é um objeto comum, ou seja, o tensor. Ele tem seus próprios métodos e propriedades.
Você também pode criar um tensor a partir de uma matriz plana e manter sua forma em mente, digamos. Ou seja, declarar um formulário - uma matriz bidimensional - para transmitir simplesmente uma matriz plana e indicar diretamente a forma. O resultado será o mesmo.
Devido ao fato de que os dados e o formulário podem ser armazenados separadamente, é possível alterar a forma do tensor. Podemos chamar o método de
reshape e alterar a forma de 2x2 para 4x1.
O próximo passo importante é
produzir os dados , devolvê-los ao mundo real.
O código para todas as três etapas.O método de
data retorna promessa. Após a resolução, obtemos o valor imediato do valor bruto, mas obtemos de forma assíncrona. Se quisermos, podemos obtê-lo de forma síncrona, mas lembre-se de que aqui você pode perder desempenho; portanto, use métodos assíncronos sempre que possível.
O método
dataSync sempre retorna dados em um formato de matriz plana. E se queremos retornar os dados no formato em que eles estão armazenados no tensor, precisamos chamar
arraySync .
Operadores
Todos os operadores no TensorFlow são
imutáveis por padrão , ou seja, em cada operação sempre é retornado um novo tensor. Acima, basta pegar nossa matriz e agrupar todos os seus elementos.
Por que essas dificuldades para operações matemáticas simples? Todos os operadores de que precisamos - a soma, a mediana etc. - estão lá. Isso é necessário porque, de fato, o tensor e essa abordagem permitem criar um gráfico de cálculos e executar cálculos não imediatamente, mas no WebGL (no navegador) ou CUDA (Node.js na máquina). Ou seja, na verdade, usar a Aceleração de Hardware é invisível para nós e, se necessário, fazer fallback na CPU. O melhor é que não precisamos pensar em nada sobre isso. Nós apenas precisamos aprender a API tfjs.
Agora, o mais importante é o modelo.
Modelo
A maneira mais fácil de criar um modelo é Sequencial, ou seja, um modelo seqüencial, quando os dados de uma camada são transferidos para a próxima camada e dele para a próxima camada. As camadas mais simples usadas aqui são usadas.
A própria camada é apenas uma abstração de tensores e operadores. Grosso modo, essas são funções auxiliares que escondem uma grande quantidade de matemática de você.
Vamos tentar entender como trabalhar com o modelo sem entrar nos detalhes da implementação.
Primeiro, indicamos a forma de dados que cai na rede neural -
inputShape é um parâmetro necessário. Indicamos
units - o número de matrizes multidimensionais e a função de ativação.
A função
relu notável por ter sido encontrada por acaso - foi tentada, funcionou melhor e, durante muito tempo, eles procuraram uma explicação matemática do por que isso acontece.
Para a última camada, quando criamos uma categoria, a função softmax é frequentemente usada - é muito adequada para exibir uma resposta no formato de codificação One-Hot. Após a criação do modelo, chame
model.summary() para garantir que o modelo seja montado da maneira correta. Em situações particularmente difíceis, você pode abordar a criação de um modelo usando programação funcional.
Se você precisar criar um modelo particularmente complexo, poderá usar a abordagem funcional: sempre que cada camada for uma nova variável. Como exemplo, pegamos manualmente a próxima camada e aplicamos a camada anterior para que possamos construir arquiteturas mais complexas. Mais tarde, mostrarei a você onde isso pode ser útil.
O próximo detalhe muito importante é que passamos as camadas de entrada e saída para o modelo, ou seja, as camadas que entram na rede neural e as camadas que são camadas para a resposta.
Depois disso, uma etapa importante é
compilar o modelo . Vamos tentar entender o que é compilação em termos de tfjs.
Lembre-se, tentamos encontrar os valores certos em nossa rede neural. Não é necessário buscá-los. Eles são selecionados de uma certa maneira, como diz a função do otimizador.
Código para a descrição de camadas sequenciais e compilação.Ilustrarei o que é um otimizador e o que é uma função de perda.
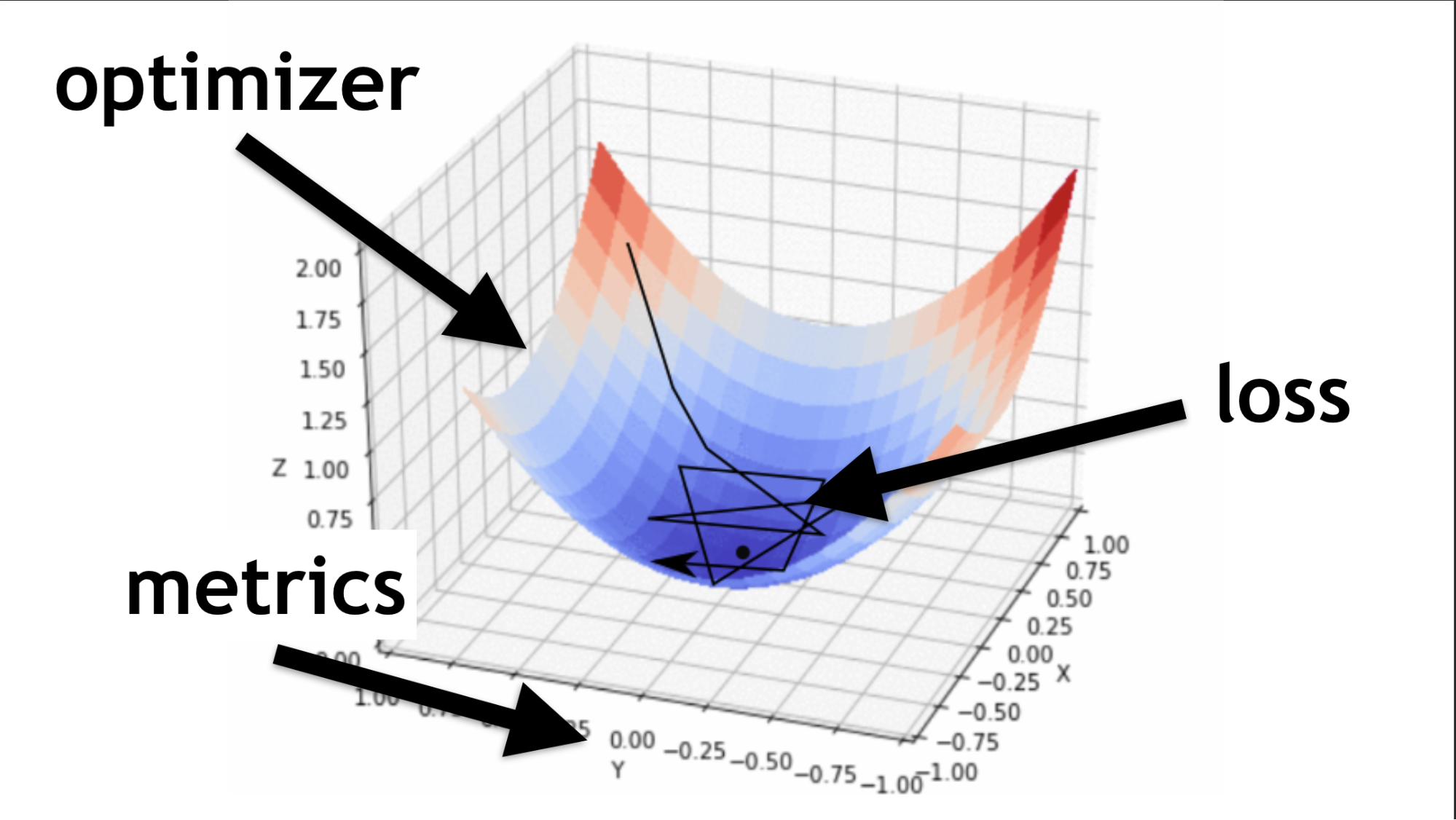
O otimizador é o mapa inteiro. Ele permite que você não apenas busque por valor aleatoriamente, mas faça isso com sabedoria, de acordo com um determinado algoritmo.
A função de perda é a maneira pela qual procuramos o valor ideal (pequena seta preta). Ajuda a entender quais valores de gradiente usar para treinar nossa rede neural.
No futuro, quando você dominar redes neurais, você mesmo escreverá uma função de perda. Grande parte do sucesso de uma rede neural depende de quão bem está escrita essa função. Mas isso é outra história. Vamos começar simples.
Exemplo de aprendizado de rede
Geraremos dados aleatórios e respostas aleatórias (etiquetas). Chamamos o módulo de
fit , passamos os dados, respostas e vários parâmetros importantes:
epochs - 5 vezes, ou seja, 5 vezes, conduziremos um treinamento completo;batchSize , que batchSize quantos pesos podem ser alterados ao mesmo tempo para levantar - quantos elementos processar ao mesmo tempo. Quanto melhor a placa de vídeo, mais memória ela possui, mais batchSize pode ser definido.
Código de todas as últimas etapas.Model.fit assíncrono
Model.fit , retorna promessa. Mas você pode usar async / waitit e aguardar a execução dessa maneira.
Em seguida é o
uso . Nós treinamos nosso modelo, depois pegamos os dados que queremos processar e chamamos o método de
predict , dizemos: “Preveja o que realmente está lá?”. E, graças a isso, obtemos o resultado.
Estrutura padrão
Cada rede neural possui três arquivos principais:
- index.js - arquivo no qual todos os parâmetros da rede neural são armazenados;
- model.js - um arquivo no qual o modelo e sua arquitetura são armazenados diretamente;
- data.js - um arquivo em que os dados são coletados, processados e incorporados ao nosso sistema.
Então, eu falei sobre como aprender o TensorFlow.js. Pequenas empresas, resta
escolher um modelo .
Infelizmente, isso não é inteiramente verdade. De fato, toda vez que você escolhe um modelo, precisa repetir algumas etapas.
- Prepare os dados para isso, faça a incorporação, ajuste-os à arquitetura.
- Defina as configurações do Hyper (depois, informarei o que isso significa).
- Treine / treine cada rede neural (cada modelo pode ter suas próprias nuances).
- Aplique um modelo neural e, novamente, você pode aplicar de diferentes maneiras.
Escolha um modelo
Vamos começar com as opções básicas que você encontrará com frequência.
Sentido profundo
Este é um exemplo popular de uma rede neural profunda. Tudo é feito de maneira simples: existe um conjunto de dados disponível ao público - conjunto de dados MNIST.
São imagens rotuladas com números, com base nas quais é conveniente treinar uma rede neural.
De acordo com a arquitetura da codificação One-Hot, codificamos cada uma das últimas camadas. Dígitos 10 - em conformidade, haverá 10 últimas camadas no final. Simplesmente enviamos fotos em preto e branco para a entrada, tudo isso é muito parecido com o que falamos no começo.
const model = tf.sequential({ layers: [ tf.layers.dense({ inputShape: [784], units: 512, activation: 'relu' }), tf.layers.dense({ units: 256, activation: 'relu' }), tf.layers.dense({ units: 10, activation: 'softmax' }), ] });
Endireitamos a imagem em uma matriz unidimensional, obtemos 784 elementos. Em uma camada 512 matrizes. Função de ativação
'relu' .
A próxima camada de matrizes é um pouco menor (256), a camada de ativação também é
'relu' . Reduzimos o número de matrizes para procurar características mais gerais. A rede neural deve ser solicitada a aprender e forçada a tomar uma decisão geral mais séria, porque ela mesma não fará isso.
No final, criamos 10 matrizes e usamos a ativação softmax para a codificação One-Hot - esse tipo de ativação funciona bem com esse tipo de codificação de resposta.
Redes profundas permitem que você reconheça corretamente de 80 a 90% das fotos - quero mais. Uma pessoa reconhece com uma qualidade de aproximadamente 96%. As redes neurais podem capturar e ultrapassar uma pessoa?
CNN (Rede Neural Convolucional)
As redes convolucionais funcionam incrivelmente simples. No final, eles têm a mesma arquitetura dos exemplos anteriores. Mas no começo, algo mais acontece. As matrizes, em vez de apenas fornecer algumas soluções, reduzem a imagem. Eles participam da imagem e a reduzem, diminuem, para um dígito. Então eles são coletados todos juntos e novamente reduzidos.
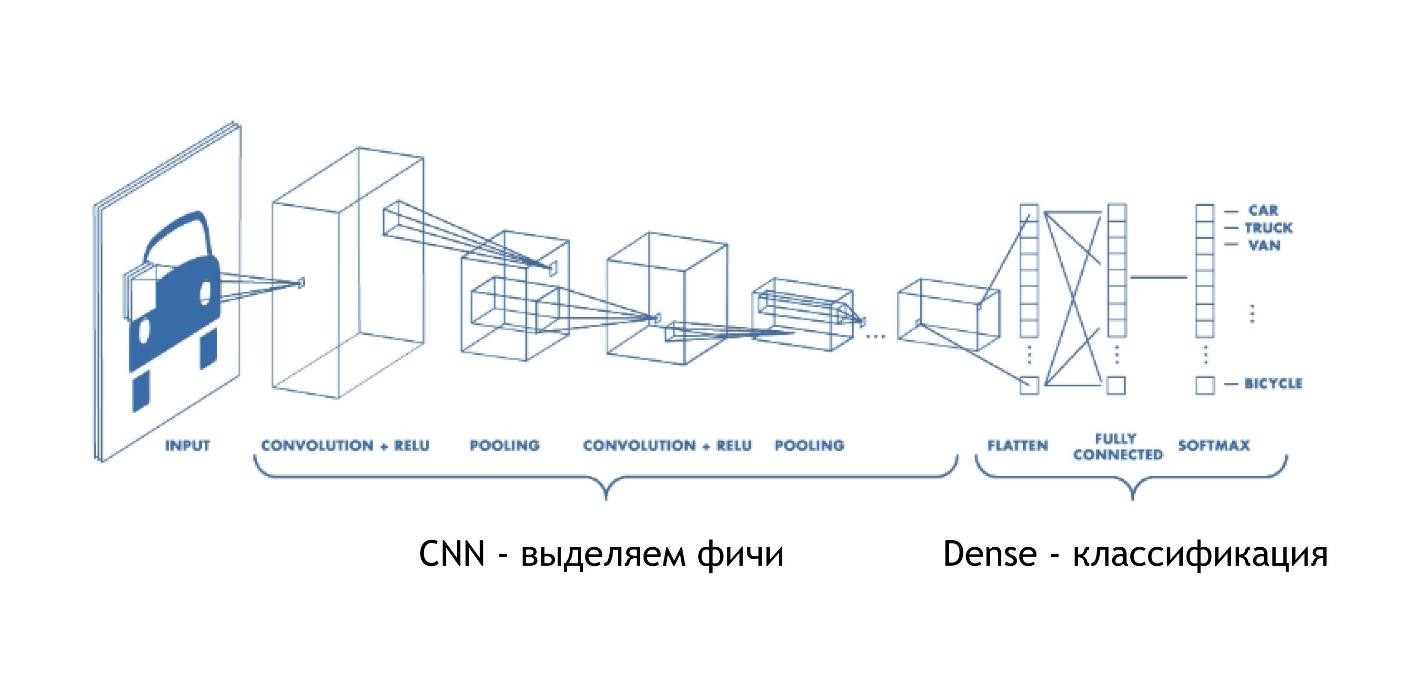
Assim, o tamanho da imagem é reduzido, mas ao mesmo tempo partes da imagem são reconhecidas cada vez melhor. As redes de convolução funcionam muito bem para reconhecimento de padrões, ainda melhor que os humanos.
O reconhecimento de imagens é melhor confiado a um carro do que a uma pessoa. Houve um estudo especial, e a pessoa, infelizmente, perdeu.
As CNNs funcionam de maneira muito simples:
const model = tf.sequential({ layers: [ tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.maxPooling2d({poolSize: [2, 2]}), tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', }) tf.layers.flatten(tf.layers.maxPooling2d({ poolSize: [2, 2] })), tf.layers.dense({units: 512, activation: 'relu'}), tf.layers.dense({units: 10, activation: 'softmax'}) ] });
Introduzimos uma matriz multidimensional específica: uma imagem de 28x28 pixels, mais uma dimensão para brilho; nesse caso, a imagem é em preto e branco; portanto, a terceira dimensão é 1.
Em seguida, definimos o número de
filters e
kernelSize - quantos pixels diminuirão. Função de ativação em todos os lugares
relu .
Existe outra camada
maxPooling2d , necessária para reduzir o tamanho ainda mais eficientemente. As redes convolucionais diminuem gradualmente o tamanho e, muitas vezes, não há necessidade de criar redes convolucionais muito profundas.
Vou explicar por que é impossível criar redes de convolução muito profundas um pouco mais tarde, mas por enquanto, lembre-se: às vezes elas precisam ser enroladas um pouco mais rápido. Existe uma camada maxPooling separada para isso.
No final, há a mesma camada densa. Ou seja, usando redes neurais convolucionais, extraímos vários sinais dos dados, após o que usamos a abordagem padrão e categorizamos nossos resultados, graças aos quais reconhecemos as imagens.
U net
Esse modelo de arquitetura está associado a redes de convolução. Com sua ajuda, muitas descobertas foram feitas no campo do controle do câncer, por exemplo, no reconhecimento de células cancerígenas e glaucoma. Além disso, este modelo pode encontrar células malignas não piores do que um professor nessa área.
Um exemplo simples: entre os dados barulhentos, você precisa encontrar células cancerígenas (círculos).

O U-Net é tão bom que pode encontrá-los quase perfeitamente. A arquitetura é muito simples:
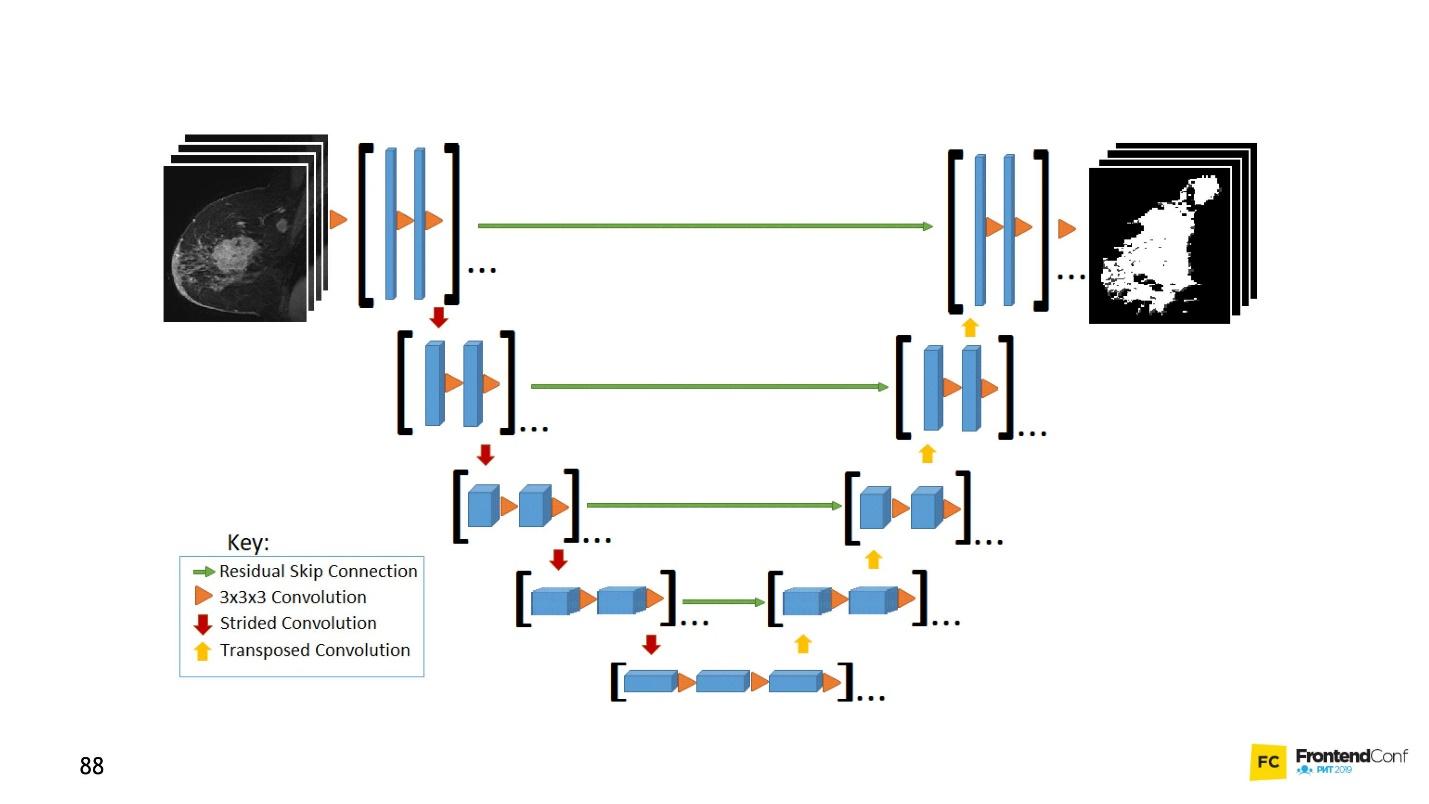
Existem as mesmas redes de convolução, assim como o MaxPooling, que reduz o tamanho. A única diferença: o modelo também usa redes de
varredura - a
rede deconvolucional .
Além da varredura de convolução, cada uma das camadas de alto nível é combinada (início e saída), devido à qual um grande número de relacionamentos aparece. Essa rede U-Net funciona bem mesmo em pequenas quantidades de dados.
Este código é mais fácil de aprender no editor. Em geral, um grande número de redes de convolução é criado aqui e, para implantá-las novamente,
concatenate e mesclamos várias camadas. Isso é apenas uma visualização de uma imagem, apenas na forma de código. Tudo é bem simples - copiar e reproduzir esse modelo é fácil.
LSTM (Memória de Longo Prazo)
Observe que todos os exemplos considerados têm um recurso - o formato dos dados de entrada é fixo. A entrada para a rede, os dados devem ser do mesmo tamanho e coincidir. Os modelos LSTM estão focados em como lidar com isso.
Por exemplo, existe um serviço Yandex.Referats, que gera resumos.
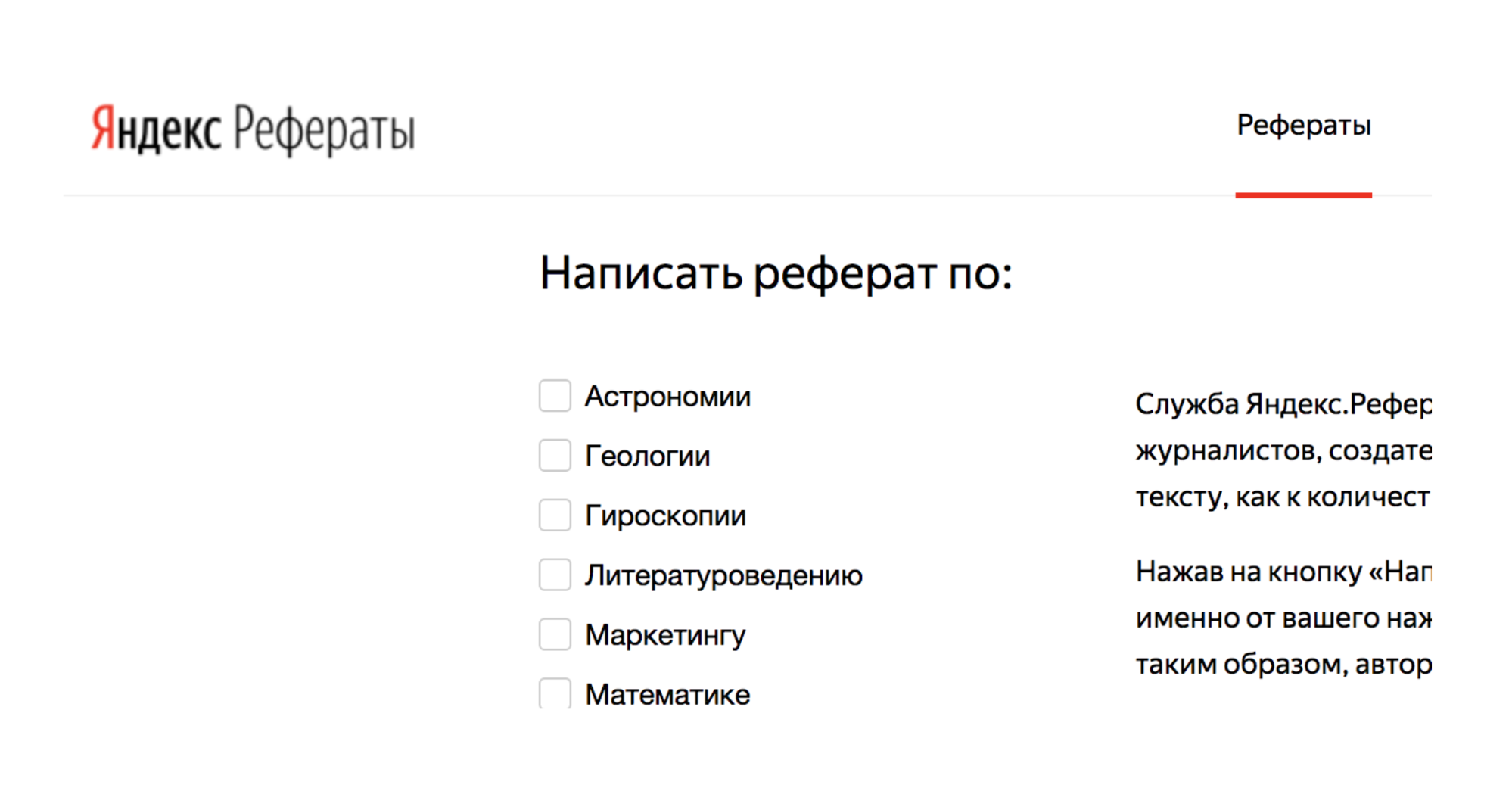
Ele dá um abracadabra completo, mas ao mesmo tempo bastante semelhante à verdade:
Resumo em matemática sobre o tema: "O binômio de Newton como axioma"
De acordo com o anterior, a integral de superfície produz uma integral curvilínea. A função convexa para o fundo ainda está em demanda.
Naturalmente, segue-se que o normal para a superfície ainda está em demanda. De acordo com o anterior, a integral de Poisson especifica essencialmente a integral de Poisson trigonométrica.
O serviço é baseado em redes neurais Seq a Seq. Sua arquitetura é mais complexa.

As camadas são organizadas em um sistema bastante complexo. Mas não se assuste - você não precisa conduzir todas essas flechas sozinho. Se você quiser, pode, mas não é necessário. Existe um ajudante que fará isso por você.
O principal a entender é que cada uma dessas peças é combinada com a anterior. Ele pega os dados não apenas dos dados iniciais, mas também da camada neural anterior. Grosso modo, é possível construir algum tipo de memória - para memorizar uma sequência de dados, reproduzi-la e, devido a esse trabalho, “sequência para sequência”. Além disso, as seqüências podem ter tamanhos diferentes, tanto na entrada quanto na saída.
Tudo parece bonito no código:
tf.sequential({ layers: [ tf.layers.lstm({ units: 512, returnSequences: true, inputShape: [10000, 64] }), tf.layers.lstm({ units: 512, returnSequences: false }), tf.layers.dense({ units: 64, activation: 'softmax' }) ] }) ;
Há um auxiliar especial que diz que temos 512 objetos (matrizes). Em seguida, retorne a sequência e o formulário de entrada (
inputShape: [10000, 64] ). A seguir, apresentamos outra camada, mas não retornamos a sequência (
returnSequences: false ), porque no final dizemos que agora precisamos usar a função de ativação para 64 caracteres diferentes (letras minúsculas e maiúsculas). 64 opções são ativadas usando a codificação One-Hot.
Mais interessante
Agora, você provavelmente está se perguntando: “Isso é tudo, é claro, bom, mas por que eu preciso disso? "Combater o câncer é bom, mas por que eu preciso disso na linha de frente?"
E as danças com um pandeiro começam: para descobrir como aplicar redes neurais ao layout, por exemplo.
Com a ajuda de redes neurais, é possível resolver problemas que antes eram impossíveis de resolver. Alguns que você nem conseguia pensar. Tudo depende de você, sua imaginação e um pouco de prática.
Agora vou mostrar ao vivo exemplos interessantes do uso dos modelos que examinamos.
CNN Equipes de áudio
Usando redes de convolução, você pode reconhecer não apenas imagens, mas também comandos de áudio e com 97% de qualidade de reconhecimento, ou seja, no nível do Google Assistant e Yandex-Alice.
Somente na rede, é claro, não é possível reconhecer frases e frases completas, mas você pode criar um assistente de voz simples.
Mais informações sobre Alice podem ser encontradas no
relatório de Nikita Dubko e sobre o assistente do Google, como trabalhar com voz e os padrões do navegador
aqui .
O fato é que qualquer palavra, qualquer comando pode ser transformado em um espectrograma.
Você pode converter qualquer informação de áudio em um espectrograma. E então você pode codificar o áudio na imagem e aplicar CNN à imagem e reconhecer comandos de voz simples.
U-net. Teste de captura de tela
O U-Net é útil não apenas para o diagnóstico bem-sucedido do câncer, mas também, por exemplo, para testar capturas de tela. Para detalhes, veja o
relatório de Lyudmila Mzhachikh, e eu direi a própria base.
Para testar com capturas de tela, são necessárias duas capturas de tela:
- básico (referência) com o qual estamos comparando;
- captura de tela para teste.

Infelizmente, nos testes de captura de tela, muitas vezes há muitas quedas negativas (falsos positivos). Mas isso pode ser evitado aplicando tecnologias avançadas de controle de câncer no front-end.
Lembre-se, marcamos a imagem na área onde há câncer e não. O mesmo pode ser feito aqui.
Se virmos uma foto com um bom layout, não a marcamos e as fotos com um layout ruim. Assim, você pode testar o layout com uma única imagem. , , , . U-Net .
, , . , U-Net, . , .
LSTM. Twitter — 2000
, , , .
, LSTM . 40 - , :
« — » .
, :

- , ?
— . - :


, «» , , (, ).
:
« » « » .
— .
« ».
:

EPOCS 250
, .
- , , , . , Overfitting — .
, — . , , . , , , .
, , .
, .

, , , . ( , ), . .
— . .
overfitting. , helper-: Dropout; BatchNormalization.
LSTM. Prettier
, — Prettier . , .
const a = 1 . :
[]c co on ns st , , :
[][] []c co on ns st , .
, , .
, , . , , 0 — , - , - . .
, . .
Em vez de conclusões
, , . . , , Deep Neural Network.
. , . . . .
JS, , . , . , JavaScript, . TensorFlow.js.
, . telegram- JS.FrontendConf , 13 . 32 .
, , . Saint AppsConf, . , , , .