
Todos os dias, os usuários do 2GIS nos ajudam a manter a precisão dos dados: eles informam sobre novas empresas, adicionam eventos de tráfego, enviam fotos e escrevem críticas. Anteriormente, só podíamos agradecê-los com palavras ou organizar uma oferta. Mas, com o tempo, as palavras são esquecidas e nem todos recebem presentes. Portanto, decidimos garantir que todos aqueles que se preocupam com o 2GIS vejam sua contribuição para o produto e nossa gratidão por isso.
Portanto, houve prêmios - medalhas virtuais que acumulamos para vários tipos de tarefas: fazer upload de fotos em cartões de café, escrever resenhas sobre teatros, especificar o horário de trabalho das organizações e assim por diante. Os usuários veem as recompensas recebidas em seu perfil 2GIS pessoal e na guia "My 2GIS" no aplicativo móvel. Aqui, mostramos quanto resta até a próxima conquista.
Para implementar esse recurso, aprendemos como processar um fluxo de eventos com um volume de 500 mil registros por hora (em locais de até 50 mil registros por segundo) e analisar dados de vários serviços. E também - eles adicionaram um pouco de metaprogramação para simplificar a configuração ao desenvolver novos prêmios.
Juntamente com o
Rapter , informaremos o que está por
trás do processo de premiação.
Conceito
Para entender a complexidade do recurso, você precisa entender como o problema técnico soou. Então - considere a idéia de implementação e o esquema geral dos componentes do sistema. É isso que faremos nesta seção.
Requisitos para Resumos
Requisitos - uma coisa bastante chata, para não pintarmos todas as nuances, vamos nos concentrar nas coisas mais importantes:
- os prêmios são emitidos apenas para usuários autorizados;
- atualizar o progresso de uma recompensa deve ser o mais rápido possível;
- recompensa - o resultado de um usuário executar um conjunto de ações no produto: fazer upload de uma foto, escrever uma crítica, encontrar instruções etc. etc. Existem muitas fontes de dados.
Ideia arquitetônica
A ideia de implementação não é muito complicada. Pode ser expresso tese:
- o prêmio consiste em tarefas cujos resultados são combinados de acordo com a fórmula especificada na configuração do prêmio;
- a tarefa responde a eventos sobre ações do usuário vindas de fora, os filtra e registra a alteração em andamento na forma de contadores;
- “Eventos externos” são gerados por sistemas mestre (foto, feedback, serviços de aprimoramento etc.) ou serviços auxiliares que transformam ou filtram os fluxos de eventos já existentes;
- o processamento de eventos ocorre de forma assíncrona e pode ser interrompido a qualquer momento, se necessário;
- o usuário vê o status atual de seus prêmios;
- tudo o resto são os detalhes ...
Entidades-chave
O diagrama abaixo mostra as principais entidades da área de assunto e seu relacionamento:

Duas zonas são distinguidas no diagrama:
- Esquema - uma zona para descrever a estrutura dos prêmios e as regras para seu acúmulo;
- Dados - área de premiação para usuários específicos e dados relacionados ao seu status atual.
As entidades no diagrama:
- Alcançar - informações sobre o prêmio que pode ser obtido. Inclui meta-informações e uma descrição de como combinar os resultados das tarefas - uma estratégia.
- Objetivo - uma tarefa cujas condições devem ser cumpridas para avançar no recebimento de um prêmio.
- UserAchieve - o estado atual da recompensa para um usuário específico.
- UserObjective - o estado atual do trabalho de recompensa do usuário.
- Usuário - informações sobre o usuário, necessárias para notificações e entendimento de seu status atual (recompensas remotas e banidas não são necessárias).
- ProcessingLog - um log de acumulações para tarefas. Contém informações sobre como uma ação específica influenciou o progresso da tarefa.
- Evento - a informação mínima necessária sobre um evento que de alguma forma influenciou o progresso das tarefas do usuário.
Estrutura de serviço
Agora considere os principais componentes do serviço e suas dependências:

- Barramento de Eventos - um barramento de eventos que pode ser usado para concluir tarefas. Estamos usando o Apache Kafka.
- Os bancos de dados mestre e escravo são o principal data warehouse. Nesse caso, um cluster do PostgreSQL.
- ConsumingWorkers - manipuladores de eventos de barramento. A principal tarefa é ler eventos de uma fonte específica (fotos, críticas etc.), aplicá-los às tarefas do usuário e salvar o resultado.
- AchievesWorker - relata o progresso nas recompensas do usuário de acordo com o status das tarefas.
- NotificationWorkers - um conjunto de manipuladores para agendar e enviar notificações sobre o recebimento de prêmios, anúncios de novas conquistas possíveis etc.
- API pública - uma interface REST pública para aplicativos da Web e móveis.
- API privada - interface REST para o painel de administração, que ajuda na investigação de incidentes e no suporte a serviços. Está disponível para desenvolvedores e equipes de suporte.
Cada um dos componentes é isolado em termos de lógica e áreas de responsabilidade, o que evita integrações e impasses desnecessários ao modificar dados. Abaixo, consideramos apenas parte do esquema associado ao processamento de eventos e à conversão deles em recompensas.
Manipulação de eventos
Conteúdo
As recompensas são principalmente um serviço de agregação de dados. Cada sistema mestre gera vários tipos de eventos. Como regra, cada tipo de evento está intimamente relacionado ao estado do conteúdo, seu modelo de status. Assim, uma foto pode ser moderada, excluída, bloqueada, oculta ou ativa. Todos esses eventos são tratados por um trabalhador separado, especializado em uma fonte específica. No momento, há uma interação com as seguintes fontes (sistemas mestre):
- Foto - gera vários eventos relacionados às operações executadas pelos usuários nas fotografias.
- Revisões - eventos relacionados a operações nas revisões de usuários.
- Datafeedback - eventos relacionados a operações de refinamento. Esclarecimento é uma alteração nas informações sobre um objeto em um mapa, seja uma empresa ou um monumento.
- Cheque - eventos relacionados ao aplicativo 2GIS Check.
- BSS são eventos de análise que geram aplicativos 2GIS. Por exemplo, a abertura de uma determinada empresa, viagens no navegador etc.

Os eventos gerados pelo sistema mestre se enquadram no tópico Kafka na ordem de alteração de status, o que torna possível avançar o progresso do prêmio para o usuário não apenas para a frente, mas também para revertê-lo. Por exemplo, se a foto estava no status "ativo" e, por algum motivo, adquiriu o status de "bloqueado", o progresso no prêmio deve mudar para baixo. O progresso do prêmio é uma interpretação de objetos internos chamados contadores de conteúdo.
Os contadores podem variar para dados diferentes. Por exemplo, para eventos sobre a foto, são os seguintes: o número de aprovados, o número com moderação, o número de bloqueados e para eventos de cartões de abertura, é necessário considerar apenas o número de cartões abertos pelo usuário. Com base nos valores atuais dos contadores de conteúdo, para um usuário específico, dentro da estrutura de um prêmio específico, são determinadas as respostas para as seguintes perguntas:
- O prêmio começou?
- qual é o progresso
- A recompensa está totalmente concluída?
Filtros e regras
Os contadores de tarefas de um prêmio específico são alterados apenas se um evento chegar com o tipo de conteúdo desejado, bem como com os dados necessários para receber o prêmio.
Para ignorar apenas o conteúdo adequado ao prêmio, realizamos cada evento por meio de uma série de filtros e regras.
Um filtro é uma certa restrição imposta ao conteúdo. Ele só se preocupa em responder à pergunta: "Um novo evento se encaixa nessa condição ou não?"
Uma regra é um filtro especial, cujo objetivo é dizer: "Se um evento se encaixa na condição, como os contadores devem mudar?" A regra inclui um algoritmo para alterar contadores. Cada prêmio contém apenas uma regra.
A implementação de filtros e regras está no código do projeto e a descrição de quais filtros (regra) pertencem a um prêmio específico está no banco de dados no formato JSON. Não chegamos a essa decisão imediatamente. Inicialmente, não era possível definir filtros e regras usando a configuração por meio do banco de dados, o prêmio foi totalmente descrito no código, apenas seu identificador foi armazenado na tabela. Esta decisão deu uma série de desvantagens significativas:
- O problema de suportar vários ambientes. Se você deseja implementar um estado da lista de prêmios no ambiente de teste e enviar outro para a batalha, será necessário conhecer o ambiente no código do projeto ou ter um arquivo de configuração com a lista de prêmios. Ao mesmo tempo, não é possível usar bancos de dados diferentes para esta tarefa, embora eles já existam para cada ambiente.
- Capacidade de configurar a filtragem apenas pelo desenvolvedor. Como tudo está descrito no código, apenas uma pessoa que conhece o projeto e a linguagem de programação pode fazer alterações, gostaria que fosse possível fazer isso simplesmente através da API ou banco de dados privados.
- A desvantagem da visualização. Existem muitas recompensas, às vezes você precisa ver os filtros que eles usam. Cada vez, fazer isso olhando o código é bastante entediante.
No início do aplicativo, correspondemos pelo nome dos filtros carregados do banco de dados e os colocamos em uma recompensa específica. Exemplo de descrição do filtro:
[ { "name":"SourceFilter", "config":{ "sources":["reviews"] } }, { "name": "ReviewsLengthFilter", "config": { "allowed_length": 100 } } ]
Nesse caso, faremos apenas essas revisões (isso é indicado pelo primeiro objeto de descrição da matriz de filtros), cujo texto contém mais de 100 caracteres (o segundo filtro na lista).
Descrição da regra de exemplo:
{"name": "ReviewUniqueByObjectRule","config":{}}
Esta regra permitirá que você altere os contadores apenas se o usuário tiver escrito uma revisão para o objeto, enquanto apenas uma revisão será levada em consideração para um objeto.
Bss
Vamos nos concentrar separadamente no trabalho com o fluxo de eventos do BSS. Há pelo menos três razões para isso:
- Os eventos de análise não podem ser revertidos, não há um modelo de status neles, o que, em geral, é lógico, pois dirigir por um navegador ou criar uma rota não pode ser cancelado. A ação estava lá ou não.
- Volumes. Deixe-me lembrá-lo de que o público total de 2GIS é de mais de 50 milhões de usuários por mês. Juntos, eles fazem mais de 1,5 bilhão de consultas de pesquisa, além de muitas outras ações: iniciar o aplicativo, visualizar o cartão do objeto etc. No pico, o número de eventos pode chegar a 50.000 por segundo. Devemos passar todas essas informações através de filtros, a fim de recompensar o usuário.
- Os eventos do Analytics têm recursos: vários formatos, uma grande variedade de tipos.
Tudo isso influenciou bastante o processamento de dados do tópico BSS, pois se precisamos de tempo real, precisamos de um tempo de processamento muito próximo.
Para reduzir as diferenças descritas, foi criado um serviço separado que prepara esses eventos. O serviço pode trabalhar com toda a variedade de formatos de mensagens provenientes da análise. A essência de seu trabalho é a seguinte: todo o fluxo de eventos do BSS é lido, do qual apenas os necessários para os prêmios são retirados. Esse filtro de serviço reduz significativamente a carga (após a filtragem, a taxa de fluxo é de ~ 300 eventos por segundo) do Rewards do processador de fluxo BSS e também gera eventos em um único formato, nivelando a desvantagem associada ao histórico da análise interna.
Prémios
Então, descobrimos como lidar com eventos e calcular o progresso nas atribuições. Agora é hora de dar uma olhada no processo de emissão de recompensas para os usuários.
A primeira pergunta que surge é: por que alocar a saída para um trabalhador separado, ela não pode ser recontada ao processar cada evento? Resposta: possível, mas não vale a pena.
Há vários motivos para alocar extradição para um processo separado:
- Transferindo a recontagem para cada ConsumingWorker, obtemos a Condição de Corrida para a operação de atualização do progresso por recompensa, porque cada manipulador tentará atualizar o progresso com base no estado conhecido das tarefas, e outros mudarão ativamente esse estado.
- Cada lote do ConsumingWorker processa eventos do Kafka em uma transação. Ao adicionar uma inserção à tabela de recompensas do usuário, chamaremos bloqueios extras no nível do banco de dados, o que inibirá outros manipuladores.
- No processo de emissão de prêmios, existe uma lógica para o envio de notificações, o que desacelerará o processamento do fluxo de eventos, o que é indesejável.
As razões para o surgimento de um AchievesWorker separado (manipulador para emitir prêmios) foram resolvidas. Agora você precisa lidar com duas partes importantes do processamento:
- Há um conjunto de missões na recompensa. Há um conjunto de contadores para essas tarefas. Como entender o quanto o prêmio é concedido e como expressá-lo em código?
Exemplo: você precisa escrever 3 revisões ou fazer upload de 3 fotos. O usuário possui 1 avaliação e 2 fotos. Qual é o progresso do prêmio? Resposta: 3, porque o usuário definitivamente terá certeza de que você precisa de 3 no total. - Temos um manipulador separado para emitir prêmios. A cada vez, é improvável que se reconheça várias dezenas de prêmios para cada usuário autorizado, ou seja, várias dezenas de milhões, com êxito rápido. Como ele pode aprender sobre o progresso de quais usuários específicos e quais tarefas foram alteradas desde o último processamento?
Vamos considerar cada parte separadamente.
Fluxo de progresso
Para uma melhor compreensão de como você pode descrever como transformar o progresso das tarefas em progresso por recompensa, dividimos as recompensas em categorias e analisamos as transformações.
"Conclua uma tarefa por X unidades." Exemplo: Dirija 10 km no navegador.
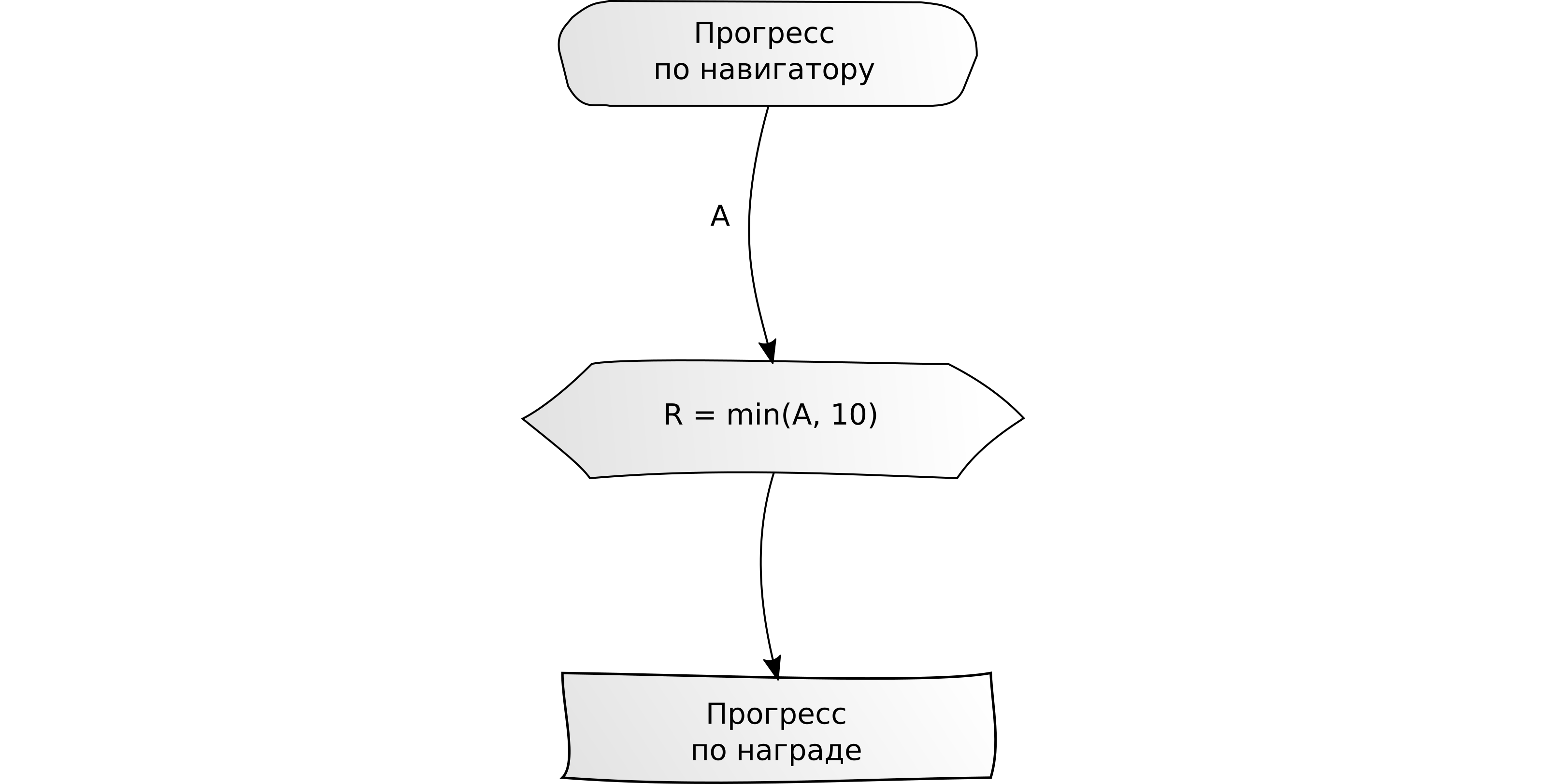 "Conclua várias tarefas para X unidades cada."
"Conclua várias tarefas para X unidades cada." Exemplo: faça upload de 5 fotos e escreva 5 resenhas em cartões - apenas 10 unidades de conteúdo.
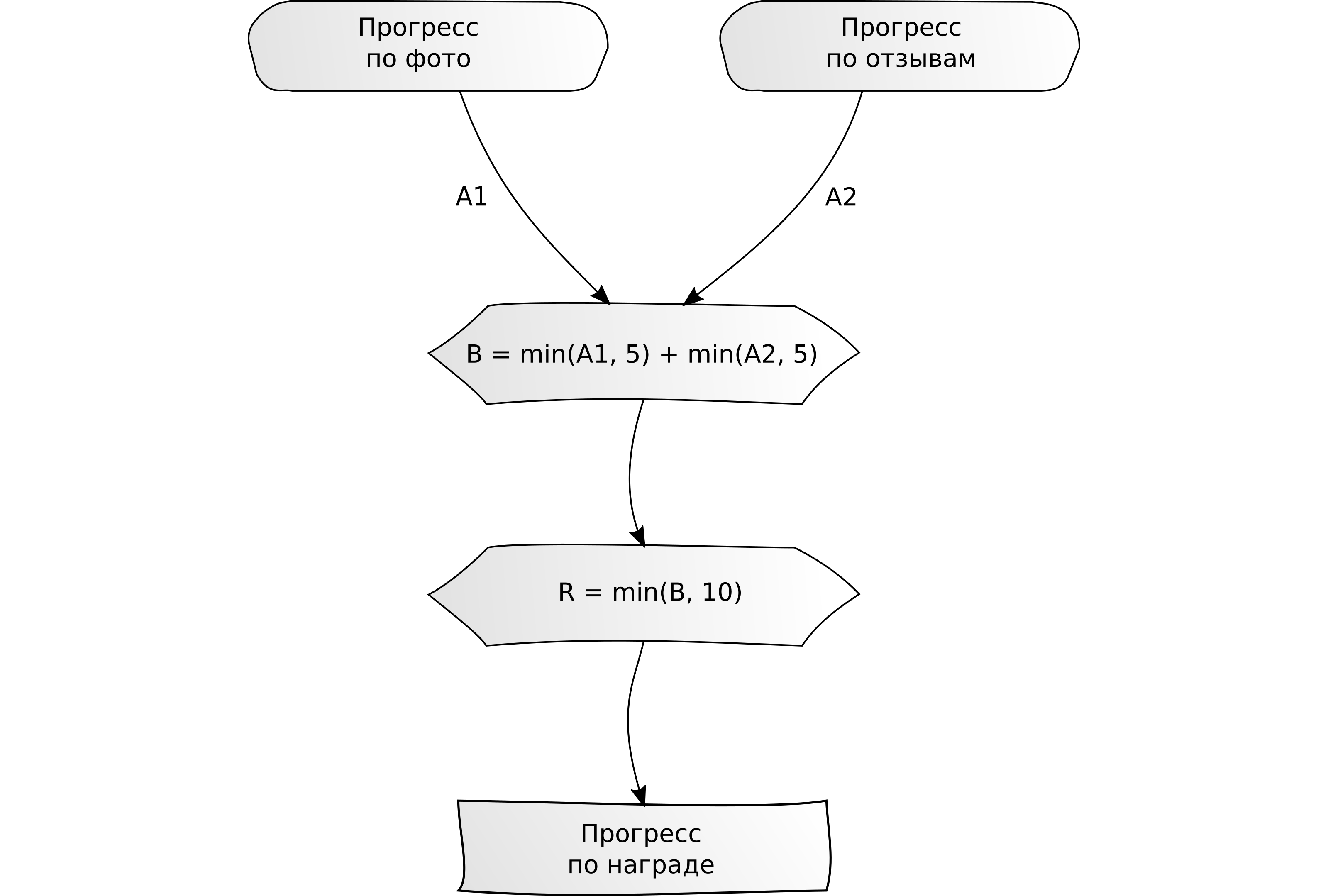 "Conclua várias tarefas para X unidades no total."
"Conclua várias tarefas para X unidades no total." Exemplo: escreva 5 comentários ou faça upload de 5 fotos.
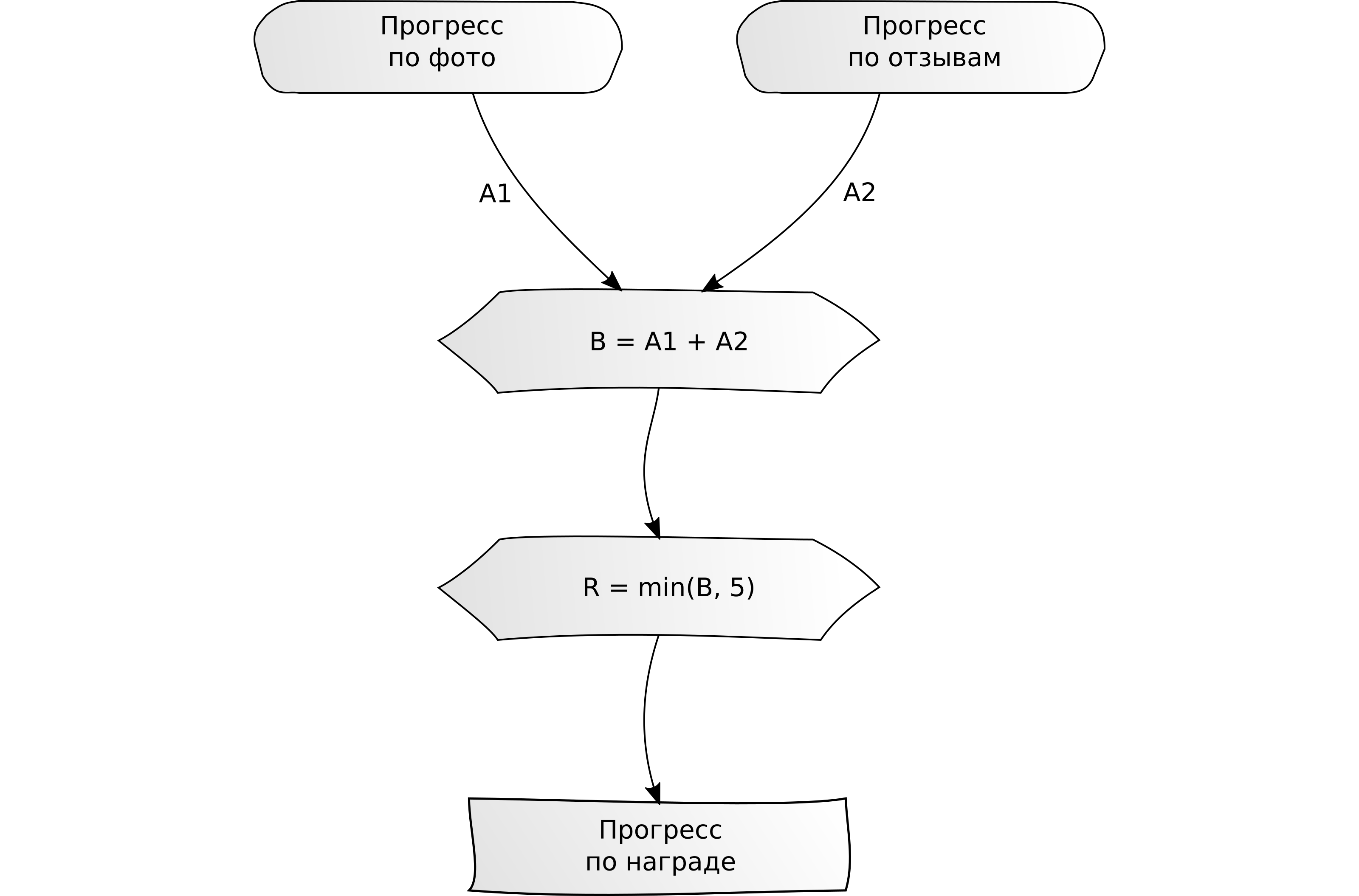 "Conclua várias tarefas agrupadas por tipo."
"Conclua várias tarefas agrupadas por tipo." Exemplo: faça upload de 5 unidades de conteúdo (fotos ou críticas) e dirija 10 km no navegador.

Teoricamente, poderia haver combinações aninhadas mais complexas. No entanto, em condições reais, não é possível explicar ao usuário em duas ou três frases a combinação lógica complexa que deve ser realizada para receber o prêmio. Portanto, na maioria dos casos, essas opções são suficientes.
Chamamos o método de conversão de estratégia e tentamos torná-lo mais ou menos universal, elaborando uma descrição formal na forma de um objeto JSON. Você poderia, é claro, pensar em escrever na forma de uma fórmula, mas então você teria que usar as semelhanças de eval ou descrever a gramática e implementá-la, e isso é claramente uma complicação excessiva. Armazenar a estratégia no código-fonte para cada prêmio não é muito conveniente, porque a descrição do prêmio (parte do banco de dados e parte do código) será rasgada e também não permitirá a coleta de prêmios de componentes prontos no futuro sem a participação do desenvolvimento.
A estratégia é apresentada na forma de uma árvore, em que cada nó:
- Refere-se ao progresso atual da atribuição ou é um grupo de outros nós.
- Pode ter uma restrição máxima - na verdade, uma indicação da necessidade de usar min ().
- Pode ter um coeficiente de normalização. Necessário para conversões simples, multiplicando o resultado por um número. Viemos a calhar para converter metros em quilômetros.
Para descrever os exemplos acima, uma operação é suficiente - soma. A soma é ótima para mostrar claramente o progresso do usuário com um único número, mas outras operações podem ser usadas, se desejado.
Aqui está um exemplo de descrição da estratégia para a última categoria:
{ "goal": 15, "operation": "sum", "strategy": [ { "goal": 5, "operation": "sum", "strategy": [ { "objective_id": "photo" }, { "objective_id": "reviews" } ] }, { "goal": 10, "operation": "sum", "strategy": [ { "objective_id": "navi", "normalization_factor": 0.001 } ] } ] }
Atualizações necessárias
Existem vários manipuladores que analisam incansavelmente os eventos dos usuários e aplicam alterações ao andamento das tarefas. Uma pesquisa regular de todos os usuários com cada prêmio levará a uma análise de várias dezenas de milhões de prêmios - não muito encorajador, desde que as atualizações reais sejam medidas em milhares. Como aprender apenas sobre milhares e não desperdiçar milhões de CPU?
A idéia de como recalcular o progresso apenas nos prêmios que realmente mudaram veio rapidamente. É baseado no uso de relógios vetoriais.
Antes da descrição, lembrarei das entidades:
- UserObjective - dados sobre o progresso do usuário, definindo o prêmio.
- UserAchieve - recompensa dados de progresso do usuário.
A implementação é assim:
- Obtemos o campo de versão para UserObjective e UserAchieve e Sequence no PostgreSQL.
- Cada atualização da entidade UserObjective altera sua versão. O valor é retirado da sequência (é comum a todos os registros).
- O valor da versão para UserAchieve será determinado como o máximo das versões do UserObjective associado.
- Em cada ciclo de processamento, o AchievesWorker procura esse UserObjective para o qual não há UserAchieve ou UserAchieve.version <UserObjective.version. O problema é resolvido por uma única consulta no banco de dados.
Vale ressaltar que a solução tem limitações no número de entradas nas tabelas de prêmios e atribuições, bem como na frequência das alterações em andamento nas atribuições, mas com algumas dezenas de milhões de prêmios e o número de atualizações inferiores a mil por minuto, é possível conviver com essa solução. De alguma forma, contaremos separadamente como otimizamos a emissão do concurso "
Agentes 2GIS ".
Conclusões
Apesar do artigo ser bastante volumoso, muitas nuances permaneceram nos bastidores, uma vez que não seria possível falar brevemente sobre eles.
Que conclusões tiramos graças aos prêmios:
- O princípio de "dividir e conquistar", neste caso, jogou em nossas mãos. A alocação de manipuladores de eventos para cada fonte nos ajuda a dimensionar quando necessário. Seu trabalho é isolado de acordo com os dados e se cruza apenas em pequenas áreas. Destacar a lógica da recompensa permite reduzir a sobrecarga nos manipuladores de eventos.
- Se você precisar digerir muitos dados e o processamento for bastante caro, pense imediatamente em como filtrar o que definitivamente não é necessário. A experiência com a filtragem de um fluxo BSS é um exemplo.
- Mais uma vez, estávamos convencidos de que a integração de serviços por meio de um barramento de evento comum é muito conveniente e permite evitar cargas desnecessárias em outros serviços. Se o serviço Rewards recebesse dados dos serviços Foto, Críticas etc. por meio de solicitações http, vários serviços teriam que ser preparados para uma carga adicional.
- Um pouco de metaprogramação pode ajudar a manter a integridade da configuração de dados e separar ambientes arbitrariamente. O armazenamento de filtros, regras e estratégias no banco de dados simplificou o processo de desenvolvimento e liberação de novos prêmios.