Nota perev. : O engenheiro líder de Zalando, Henning Jacobs, notou repetidamente problemas com os usuários do Kubernetes no entendimento do objetivo das sondas de vivacidade (e prontidão) e sua aplicação correta. Portanto, ele reuniu seus pensamentos neste artigo amplo, que com o tempo se tornará parte da documentação do K8.
As verificações de saúde, conhecidas no Kubernetes como
sondas de vivacidade
(isto é, literalmente, "testes de viabilidade" - aprox. Transl.) , Podem ser bastante perigosas. Recomendo evitá-las sempre que possível: as únicas exceções são os casos em que são realmente necessárias e você está totalmente ciente das especificidades e conseqüências de seu uso. Esta publicação se concentrará nas verificações de prontidão e prontidão e também explicará em que casos
vale a pena e não vale a pena usá-las.
Meu colega Sandor recentemente compartilhou no Twitter os erros mais comuns que ele encontra, incluindo aqueles relacionados ao uso de testes de prontidão / vivacidade:
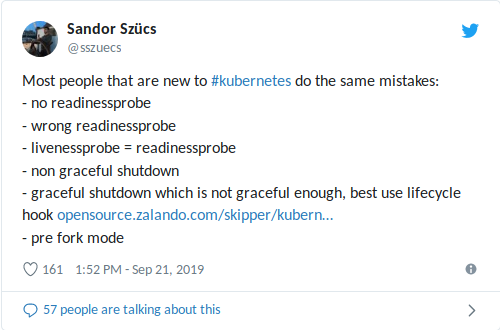
Um
livenessProbe configurado incorretamente pode agravar situações com alta carga (desligamento de avalanche + lançamento potencialmente longo do contêiner / aplicativo) e levar a outras consequências negativas, como uma queda nas dependências
(consulte também meu artigo recente sobre limitação do número de solicitações no pacote K3s + ACME) . Pior ainda, quando um probe animado é combinado com uma verificação de integridade, que atua como um banco de dados externo: a
única falha no banco de dados reiniciará todos os seus contêineres !
A mensagem geral
“Não use sondas de vivacidade” neste caso ajuda um pouco, portanto, consideraremos para que servem as verificações de prontidão e vivacidade.
Nota: A maior parte do teste abaixo foi originalmente incluída na documentação interna dos desenvolvedores do Zalando.Verificações de prontidão e vida
O Kubernetes fornece dois mecanismos importantes chamados
testes de vivacidade e testes de prontidão . Eles executam periodicamente alguma ação - por exemplo, envia uma solicitação HTTP, abre uma conexão TCP ou executa um comando em um contêiner - para confirmar que o aplicativo está funcionando corretamente.
O Kubernetes usa
testes de prontidão para entender quando um contêiner está pronto para receber tráfego. Um pod é considerado pronto para uso, se todos os seus contêineres estiverem prontos. Uma aplicação desse mecanismo é controlar quais pods são usados como back-end para serviços Kubernetes (e especialmente o Ingress).
As análises de vida útil ajudam o Kubernetes a entender quando é hora de reiniciar o contêiner. Por exemplo, essa verificação permite interceptar o impasse quando o aplicativo está "preso" em um só lugar. Reiniciar o contêiner nesse estado ajuda a mover o aplicativo do chão, apesar dos erros, mas também pode levar a falhas em cascata (veja abaixo).
Se você tentar implantar uma atualização em um aplicativo que falhe nas verificações de disponibilidade / prontidão, a implantação será interrompida porque o Kubernetes aguardará o status de
Ready em todos os pods.
Exemplo
Aqui está um exemplo de análise de prontidão que verifica o caminho
/health através do HTTP com configurações padrão (
intervalo : 10 segundos,
tempo limite : 1 segundo,
limite de sucesso : 1,
limite de falha : 3):
# deployment'/ podTemplate: spec: containers: - name: my-container # ... readinessProbe: httpGet: path: /health port: 8080
Recomendações
- Para microsserviços com um ponto de extremidade HTTP (REST, etc.), defina sempre uma análise de prontidão que verifique se o aplicativo (pod) está pronto para receber tráfego.
- Verifique se o probe de prontidão cobre a disponibilidade da porta real do servidor da web :
- Usando portas para necessidades administrativas denominadas “admin” ou “management” (por exemplo, 9090) para
readinessProbe , verifique se o endpoint retorna OK somente se a porta HTTP principal (como 8080) estiver pronta para aceitar tráfego *;
* Conheço pelo menos um caso em Zalando quando isso não aconteceu, ou seja, o readinessProbe verificou a porta de "gerenciamento", mas o próprio servidor não foi iniciado devido a problemas ao carregar o cache. - uma detecção de prontidão suspensa em uma porta separada pode levar ao fato de que o congestionamento na porta principal não será refletido na verificação de integridade (ou seja, o pool de threads no servidor está cheio, mas a verificação de integridade ainda mostra que está tudo bem).
- Garantir a detecção de prontidão permite a inicialização / migração do banco de dados ;
- a maneira mais fácil de conseguir isso é acessar o servidor HTTP somente após a conclusão da inicialização (por exemplo, migração de banco de dados do Flyway , etc.); ou seja, em vez de alterar o status da verificação de integridade, simplesmente não inicie o servidor da web até que a migração do banco de dados * seja concluída.
* Você também pode executar migrações de banco de dados a partir de containers init fora do pod. Ainda sou fã de aplicativos independentes, ou seja, aqueles em que o contêiner de aplicativos, sem coordenação externa, sabe como levar o banco de dados ao estado desejado.
- Use
httpGet para verificações de prontidão através de pontos de extremidade típicos de verificações de saúde (por exemplo, /health ). successThreshold: 1 configurações successThreshold: 1 ( interval: 10s , timeout: 1s , successThreshold: 1 , failureThreshold: 3 ):- os parâmetros padrão significam que o pod ficará indisponível após cerca de 30 segundos (três falhas nas verificações de integridade).
- Use uma porta separada para "admin" ou "management" se a pilha de tecnologia (por exemplo, Java / Spring) permitir que isso separe o gerenciamento de integridade e métricas do tráfego normal:
- mas não se esqueça do parágrafo 2.
- Se necessário, a sonda de prontidão pode ser usada para aquecer / carregar o cache e retornar o código de status 503 até que o contêiner seja "aquecido":
- Também recomendo que você se familiarize com a nova verificação
startupProbe , que apareceu na versão 1.16 (escrevemos sobre isso em russo aqui - aprox. Trad.) .
Advertências
- Não confie em dependências externas (como armazenamento de dados) ao realizar testes de disponibilidade / disponibilidade - isso pode levar a falhas em cascata:
- como exemplo, vamos usar um serviço REST com estado com 10 pods, dependendo de um banco de dados do Postgres: quando a verificação depende de uma conexão de trabalho com o banco de dados, todos os 10 pods podem cair se houver um atraso na rede / no lado do banco de dados - geralmente tudo termina pior do que poderia;
- observe que o Spring Data, por padrão, verifica a conexão com o banco de dados *;
* Esse é o comportamento padrão do Spring Data Redis (pelo menos era como quando verifiquei pela última vez), o que levou a uma falha "catastrófica": quando o Redis ficou indisponível por um curto período de tempo, todos os pods "caíram". - “Externo” nesse sentido também pode significar outros pods do mesmo aplicativo, ou seja, idealmente, a verificação não deve depender do estado de outros pods do mesmo cluster para evitar falhas em cascata:
- os resultados podem variar para aplicativos de estado distribuído (por exemplo, armazenamento em cache na memória em pods).
- Não use o probe liveness para pods (as exceções são casos em que são realmente necessárias e você está totalmente ciente das especificidades e conseqüências de seu uso):
- o probe liveness pode ajudar a recuperar contêineres “travados”, mas como você tem controle total sobre seu aplicativo, idealmente, processos e travamentos “travados” não devem acontecer: a melhor alternativa é interromper o aplicativo intencionalmente e retorná-lo ao estado estacionário anterior;
- uma falha no probe liveness reiniciará o contêiner, exacerbando potencialmente as conseqüências dos erros de carregamento: reiniciar o contêiner resultará em tempo de inatividade (pelo menos durante o tempo de inicialização do aplicativo, digamos, por mais de 30 segundos), causando novos erros, aumentando a carga outros recipientes e aumentando a probabilidade de falha, etc.;
- as verificações de integridade em combinação com uma dependência externa são as piores combinações possíveis, o que pode levar a falhas em cascata: um pequeno atraso no lado do banco de dados fará com que todos os seus contêineres sejam reiniciados!
- Os parâmetros para verificações de disponibilidade e disponibilidade devem ser diferentes :
- você pode usar o probe liveness com a mesma verificação de integridade, mas um limite mais alto (
failureThreshold ), por exemplo, atribui o status de não pronto após 3 tentativas e assume que o probe falhou após 10 tentativas;
- Não use verificações de exec , pois elas estão associadas a problemas conhecidos que levam ao aparecimento de processos zumbis:
Sumário
- Use sondas de prontidão para determinar quando um pod está pronto para receber tráfego.
- Use sondas de vivacidade somente quando forem realmente necessárias.
- O uso incorreto de testes de prontidão / disponibilidade pode levar a disponibilidade reduzida e falhas em cascata.

Materiais adicionais sobre o tópico
Atualização No1 de 29/09/2019
Sobre contêineres init para migração de banco de dados : nota de rodapé adicionada.
EJ me lembrou o PDB: um dos problemas das verificações de vivacidade é a falta de coordenação entre os pods. O Kubernetes possui
Orçamentos de interrupção de pod (PDBs) para limitar o número de falhas simultâneas que um aplicativo pode enfrentar, mas as verificações não levam em consideração os PDBs. Idealmente, podemos solicitar K8s: "Reinicie um pod se a verificação falhar, mas não os reinicie todos para não piorar".
Bryan formulou perfeitamente : “Use um som de animação quando tiver certeza de que a
melhor coisa a fazer é“ matar ”o aplicativo ” (novamente, não se deixe levar).
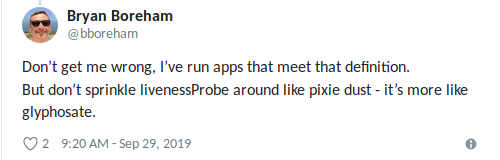
Atualização No.2 de 29/09/2019
Sobre a leitura da documentação antes do uso : Criei uma
solicitação de recurso para suplementar a documentação das análises de vitalidade.
PS do tradutor
Leia também em nosso blog: