Como testar idéias, arquitetura e algoritmos sem escrever código? Como formular e verificar suas propriedades? O que são verificadores de modelos e localizadores de modelos? O que fazer quando os recursos dos testes não são suficientes?
Oi Meu nome é Vasil Dyadov, agora trabalho como programador em Yandex.Mail, antes de trabalhar na Intel, desenvolvia código RTL (nível de transferência de registro) no Verilog / VHDL para ASIC / FPGA ainda mais cedo. Há muito tempo que gosto do tópico de confiabilidade de software e hardware, matemática, ferramentas e métodos usados para desenvolver software e lógica com propriedades predefinidas garantidas.
Este é o segundo artigo de uma série (o primeiro artigo aqui ), projetado para chamar a atenção de desenvolvedores e gerentes para a abordagem de engenharia do desenvolvimento de software. Recentemente, ele foi imerecidamente ignorado, apesar das mudanças revolucionárias em sua abordagem e ferramentas de suporte.
O primeiro artigo pareceu a alguns leitores muito abstrato. Muitos gostariam de ver um exemplo do uso de uma abordagem de engenharia e especificações formais em condições próximas à realidade.
Neste artigo, veremos um exemplo da aplicação real do TLA + para resolver um problema prático.
Estou sempre aberto para discutir questões relacionadas ao desenvolvimento de software e terei prazer em conversar com os leitores (as coordenadas de comunicação estão no meu perfil).
O que é o TLA +?
Para começar, quero dizer algumas palavras sobre o TLA + e o TLC.
TLA + (Lógica Temporal de Ações + Dados) é um formalismo que se baseia em um tipo de lógica temporal. Desenhado por Leslie Lamport.
Dentro da estrutura desse formalismo, pode-se descrever o espaço das variantes de comportamento do sistema e as propriedades desses comportamentos.
Por uma questão de simplicidade, podemos assumir que o comportamento do sistema é representado por uma sequência de seus estados (como miçangas infinitas, bolas em uma corda), e a fórmula TLA + define uma classe de cadeias que descrevem todas as variantes possíveis do comportamento do sistema (um grande número de miçangas).
O TLA + é adequado para descrever máquinas de estados finitos não determinísticos em interação (por exemplo, a interação de serviços em um sistema), embora sua expressividade seja suficiente para descrever muitas outras coisas (que podem ser expressas na lógica de primeira ordem).
E o TLC é um verificador de modelo de estado explícito: um programa que, de acordo com uma dada descrição do sistema TLA + e fórmulas de propriedades, itera pelos estados do sistema e determina se o sistema atende às propriedades especificadas.
Normalmente, trabalhar com o TLA + / TLC é construído desta maneira: descrevemos o sistema no TLA +, formalizamos propriedades interessantes no TLA +, executamos o TLC para verificação.
Como não é fácil descrever diretamente um sistema mais ou menos complexo no TLA +, foi inventada uma linguagem de nível superior - o PlusCal, que se traduz em TLA +. O PlusCal existe de duas maneiras: com Pascal e sintaxe do tipo C. No artigo que usei a sintaxe semelhante ao Pascal, parece-me melhor ler. O PlusCal em relação ao TLA + é aproximadamente o mesmo que C em relação ao montador.
Aqui não vamos nos aprofundar na teoria. Literatura para imersão em TLA + / PlusCal / TLC é fornecida no final do artigo.
Minha principal tarefa é mostrar a aplicação do TLA + / TLC em um exemplo simples e compreensível da vida real.
Em alguns comentários ao artigo anterior, fui criticado por não ter pintado os fundamentos teóricos das ferramentas, mas o objetivo desta série de artigos era mostrar a aplicação prática de ferramentas para a abordagem de engenharia no desenvolvimento de software.
Eu acho que uma imersão profunda na teoria é de pouco interesse para qualquer pessoa, mas se você estiver interessado, sempre poderá ir ao PM para obter links e explicações e, tanto quanto eu tiver conhecimento suficiente (afinal, eu não sou um matemático teórico, mas um engenheiro de software), tentarei responder .
Declaração do problema
Primeiro, falarei um pouco sobre a tarefa para a qual o TLA + foi usado.
A tarefa está relacionada ao processamento do fluxo de eventos. Ou seja, para criar uma fila para armazenar eventos e enviar notificações sobre esses eventos.
O data warehouse é fisicamente organizado com base no DBMS do PostgreSQL.
A principal coisa que você precisa saber:
- Existem fontes de eventos. Para nossos propósitos, podemos nos limitar ao fato de que cada evento é caracterizado pelo tempo em que seu processamento é planejado. Essas fontes gravam eventos no banco de dados. Normalmente, o tempo de gravação no banco de dados e o tempo do processamento planejado não estão relacionados de forma alguma.
- Existem processos de coordenação que lêem eventos do banco de dados e enviam notificações dos próximos eventos para os componentes do sistema que devem responder a essas notificações.
- Requisito fundamental: não devemos perder eventos. A notificação do evento em casos extremos pode ser repetida, ou seja, deve haver uma garantia pelo menos uma vez . Em sistemas distribuídos, é extremamente difícil obter uma garantia apenas uma vez (pode até ser impossível, mas precisa ser comprovada) sem mecanismos de consenso, e eles (pelo menos tudo o que sei) têm um efeito muito forte no sistema em termos de atraso e taxa de transferência.
Agora, alguns detalhes:
- Existem muitos processos de origem; eles podem gerar milhões (no pior caso) de eventos que caem em um intervalo de tempo estreito.
- Eventos podem ser gerados para o futuro e para o tempo passado (por exemplo, se o processo de origem diminuiu a velocidade e registrou um evento por um momento que já passou).
- A prioridade do processamento de eventos é a tempo, ou seja, devemos primeiro processar os eventos mais antigos.
- Para cada evento, o processo de origem gera um número aleatório worker_id , devido ao qual os eventos são distribuídos entre os coordenadores.
- Existem vários processos de coordenação (escalas de acordo com as necessidades com base na carga do sistema).
- Cada processo do coordenador processa eventos para seu próprio conjunto worker_id , ou seja, devido ao worker_id, evitamos a concorrência entre coordenadores e a necessidade de bloqueios.
Como pode ser visto na descrição, podemos considerar apenas um processo de coordenação e não considerar o worker_id em nossa tarefa.
Ou seja, por simplicidade, assumimos que:
- Existem muitos processos de origem.
- O processo de coordenação é um.
Descreverei a evolução da idéia de resolver esse problema em etapas, para que seja mais compreensível como o pensamento evoluiu de uma implementação simples para uma otimizada.
Decisão na testa
Criaremos uma placa para eventos em que armazenaremos eventos na forma de apenas um carimbo de data / hora (não estamos interessados em outros parâmetros nesta tarefa). Vamos criar um índice no campo timestamp .
Parece ser uma solução perfeitamente normal.
Só há um problema com a escalabilidade: quanto mais eventos, mais lentas as operações do banco de dados.
Os eventos podem ocorrer no passado, portanto o coordenador terá que revisar constantemente toda a linha do tempo.
O problema pode ser resolvido extensivamente dividindo o banco de dados em fragmentos por tempo, etc. Mas essa é uma maneira que consome muitos recursos.
Como resultado, o trabalho dos coordenadores será mais lento, pois você precisará ler e combinar dados de vários bancos de dados.
É difícil implementar o cache de eventos no coordenador para não ir às bases para processar cada evento.
Mais bancos de dados - mais problemas de tolerância a falhas.
E assim por diante
Não vamos nos aprofundar nessa solução frontal em detalhes, pois ela é trivial e desinteressante.
Primeira otimização
Vamos ver como melhorar a solução frontal.
Para otimizar o acesso ao banco de dados, você pode complicar um pouco o índice, adicionar um identificador monotonicamente crescente aos eventos que serão gerados ao confirmar uma transação no banco de dados. Ou seja, o evento agora é caracterizado pelo par {time, id} , em que time é o horário em que o evento está agendado, id é um contador que aumenta monotonamente. Há uma garantia da exclusividade do id para cada evento, mas não há garantia de que os valores do id fiquem sem falhas (ou seja, pode haver uma sequência: 1 , 2 , 7 , 15 ).
Parece que agora podemos armazenar o identificador do último evento de leitura no processo do coordenador e, ao buscar, selecionar eventos com identificadores maiores que o último evento processado.
Mas aqui o problema aparece imediatamente: os processos de origem podem gravar um evento com um carimbo de data / hora no futuro. Em seguida, teremos que levar constantemente em conta o conjunto de eventos com pequenos identificadores no processo de coordenação, cujo tempo de processamento ainda não chegou.
Você pode perceber que os eventos relativos ao horário atual são divididos em duas classes:
- Eventos com registro de data e hora no passado, mas com um identificador grande. Eles foram gravados no banco de dados recentemente, depois que processamos esse intervalo de tempo. Esses são eventos de alta prioridade e precisam ser processados primeiro para que a notificação - que já esteja atrasada - não esteja atrasada.
- Eventos registrados uma vez com carimbos de data e hora próximos ao momento atual. Tais eventos terão um valor baixo de identificador.
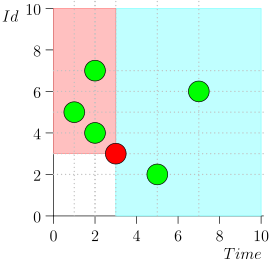
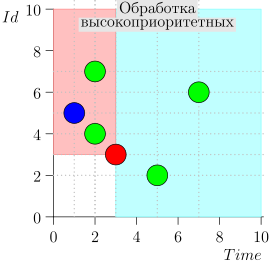
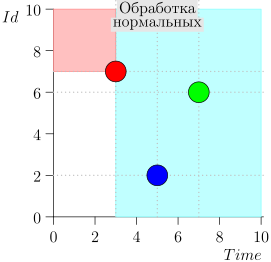
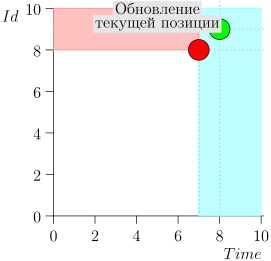
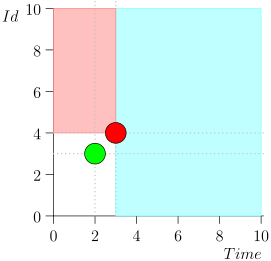
Assim, o estado atual do processo do coordenador é caracterizado pelo par {state.time, state.id}.
Acontece que os eventos de alta prioridade estão à esquerda e acima deste ponto (região rosa) e os eventos normais estão à direita (azul claro):
Fluxograma
O algoritmo de trabalho do coordenador é o seguinte:
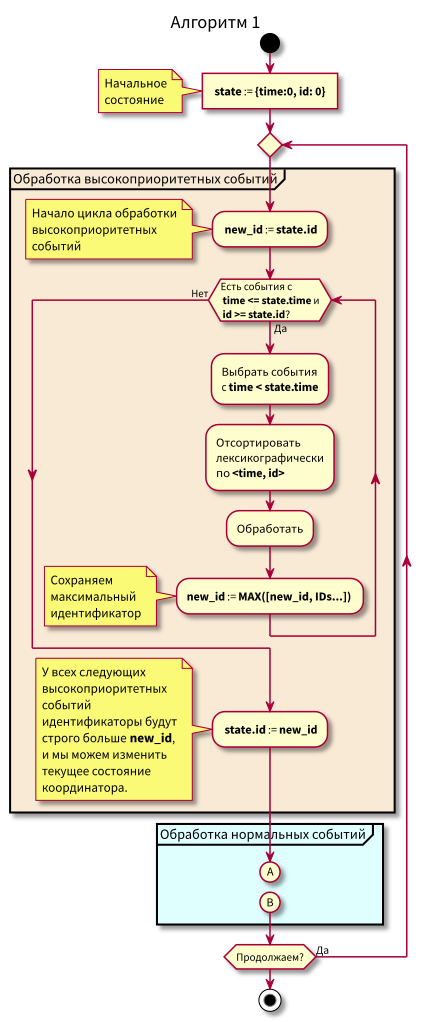
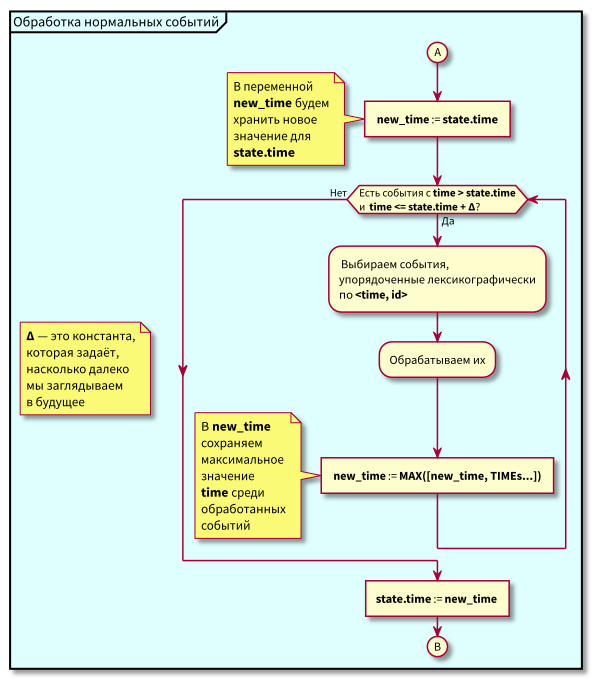
Ao estudar o algoritmo, podem surgir perguntas:
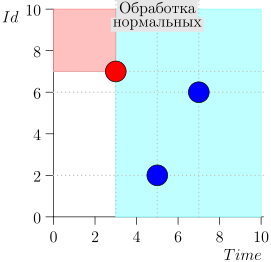
- E se o processamento de eventos normais começar e nesse momento chegarem novos eventos no passado (na região rosa), eles não serão perdidos? Resposta: eles serão processados no próximo ciclo de processamento de eventos de alta prioridade. Eles não podem se perder, pois é garantido que seu ID seja maior que state.id.
- E se, após o processamento de todos os eventos normais - no momento da mudança para o processamento de eventos de alta prioridade - chegarem novos eventos com registros de data e hora do intervalo [state.time, state.time + Delta], não os perderemos? Resposta: eles cairão na área rosa, pois terão tempo <state.time e id > state.id: chegaram recentemente e o id está aumentando monotonicamente.
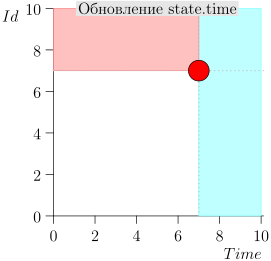
Exemplo de Operação de Algoritmo
Vejamos algumas etapas do algoritmo:
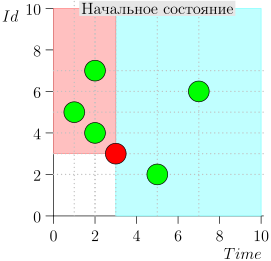
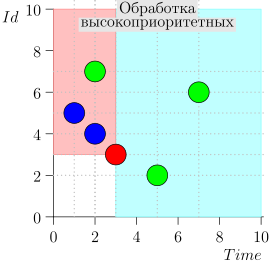
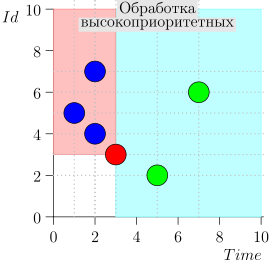
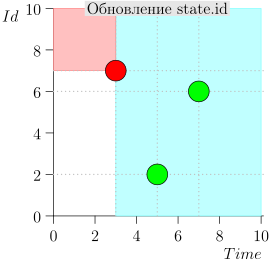
Modelo
Garantiremos que o algoritmo não perca eventos e todas as notificações serão enviadas: comporemos um modelo simples e o verificaremos.
Para o modelo, usamos o TLA +, mais precisamente o PlusCal, que se traduz em TLA +.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* \* (by Daniel Jackson) \* small-scope hypothesis, \* , ́ \* \* \* : \* Events - - , \* [time, id], \* \* \* \* Event_Id - \* id \* MAX_TIME - , \* \* TIME_DELTA - Delta, \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, TIME_DELTA \in 1..3 define \* \* ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x \* fold_left/fold_right RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) (* ( ) *) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) (* : *) ToSet(S) == {S[i] : i \in DOMAIN(S)} (* map *) MapSet(Op(_), S) == {Op(x) : x \in S} (* *) \* id GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) \* time GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) (* SQL *) \* \* ORDER BY EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \* time, id \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) \* SELECT * FROM events \* WHERE time <= curr_time AND id >= max_id \* ORDER BY time, id SELECT_HIGH_PRIO(state) == LET \* \* time <= curr_time \* AND id >= maxt_id selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } IN selected \* SELECT * FROM events \* WHERE time > current_time AND time - Time <= delta_time \* ORDER BY time, id SELECT_NORMAL(state, delta_time) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } IN selected \* Safety predicate \* ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; \* - fair process inserter = "Sources" variable n, t; begin forever: while TRUE do \* get_time: \* \* , , \* with evt_time \in 0..MAX_TIME do t := evt_time; end with; \* ; \* : \* 1. . \* 2. , \* Event_Id - , \* commit: \* either - either Events := Events \cup {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process coordinator = "Coordinator" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do \* high_prio: events := SELECT_HIGH_PRIO(state); \* process_high_prio: \* , \* Events, \* state.id := MAX({state.id} \union GetIds(events)) || \* , \* Events := Events \ events || \* events , \* events := {}; \* - normal: events := SELECT_NORMAL(state, TIME_DELTA); process_normal: state.time := MAX({state.time} \union GetTimes(events)) || Events := Events \ events || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ================================
Como você pode ver, a descrição é relativamente pequena, apesar da seção bastante volumosa de definições (define), que pode ser retirada em um módulo separado e depois reutilizada.
Nos comentários, tentei explicar o que está acontecendo no modelo. Espero que isso
Eu consegui e não há necessidade de pintar o modelo com mais detalhes.
Gostaria apenas de esclarecer um ponto sobre a atomicidade das transições entre estados e recursos de modelagem.
A modelagem é realizada executando etapas atômicas dos processos. Em uma transição, uma etapa atômica de um processo é realizada, na qual essa etapa pode ser realizada. A escolha da etapa e do processo é não determinística: durante a modelagem, todas as cadeias possíveis de etapas atômicas de todos os processos são classificadas.
A questão pode surgir: o que dizer da modelagem do verdadeiro paralelismo, quando realizamos simultaneamente várias etapas atômicas em diferentes processos?
Esta questão, Leslie Lamport, tem sido respondida há muito tempo no livro Especificando Sistemas e outros trabalhos.
Não vou citar a resposta completamente, em resumo a essência é esta: se não houver escala de tempo exata em que cada evento esteja vinculado a um momento específico, não haverá diferença na modelagem de eventos paralelos como sequenciais de ocorrência não determinística, porque sempre podemos assumir que um evento ocorreu antes de outro valor infinitesimal.
Mas o que é realmente importante é a alocação competente de etapas atômicas. Se houver muitos deles, ocorrerá uma explosão combinatória do espaço de estados. Se você executar menos etapas do que o necessário ou selecioná-las incorretamente, ou seja, a probabilidade de perder um estado / transição inválido (ou seja, perderemos os erros no modelo).
Para decompor corretamente os processos em etapas atômicas, você precisa ter uma boa idéia de como o sistema funciona em termos da dependência dos processos nos dados e nos mecanismos de sincronização.
Como regra, dividir processos em etapas atômicas não causa grandes problemas. E, se sim, indica uma falta de entendimento do problema, e não de problemas com a compilação do modelo e a gravação da especificação TLA +. Essa é outra característica muito útil das especificações formais: elas exigem um estudo e análise aprofundados.
um problema Como regra, se a tarefa for significativa e bem compreendida, não haverá problemas com sua formalização.
Verificação do modelo
Para modelagem, usarei o TLA-toolbox. Obviamente, você pode executar tudo na linha de comando, mas o IDE ainda é mais conveniente, especialmente para começar a aprender sobre modelagem usando o TLA +.
A criação do projeto está bem descrita em manuais, artigos e livros, os links que citei no final do artigo, para não me repetir. A única coisa que chamarei sua atenção são as configurações de simulação.
O TLC é um verificador de modelo com verificação explícita de estado. É claro que o espaço de estado deve ser limitado por limites razoáveis. Por um lado, deve ser grande o suficiente para poder verificar propriedades que nos interessam e, por outro lado, pequeno o suficiente para que a simulação seja concluída em um período de tempo razoável, usando recursos aceitáveis.
Este é um ponto bastante delicado, aqui você precisa entender as propriedades do sistema e do modelo. Mas rapidamente vem com a experiência. Para iniciantes, você pode simplesmente definir os limites máximos possíveis que ainda são aceitáveis em termos de tempo e recursos de simulação consumidos.
Há também um modo de verificar não todo o espaço de estados, mas cadeias seletivas até uma certa profundidade. Às vezes também é possível e necessário usar.
Retornamos às configurações de simulação.
Primeiro, definimos as restrições no espaço de estados do sistema. As limitações são definidas na seção Configurações avançadas da simulação Opções / restrição de estado .
Aí indiquei uma expressão TLA +: Cardinality(Events) <= 5 /\ Event_Id <= 5 ,
em que Event_Id é o limite superior do valor do identificador de evento, Cardinality(Events) é o tamanho do conjunto de registros de eventos (limitado ao modelo base
dados por cinco registros em uma placa).
Na simulação, o TLC examinará apenas os estados em que essa fórmula é verdadeira.
Você ainda pode permitir transições de estado válidas ( opções avançadas / restrição de ação ),
mas não precisamos disso.
Em seguida, indicamos a fórmula TLA + que descreve nosso sistema: Visão geral do modelo / fórmula temporal = Spec , em que Spec é o nome da fórmula TLA + gerada automaticamente pelo PlusCal (no código do modelo acima, não é: para economizar espaço, não citei o resultado da tradução do PlusCal em TLA +) .
A próxima configuração que vale a pena prestar atenção é a verificação do impasse.
(marca de seleção em Visão geral do modelo / Impasse ). Quando esse sinalizador é ativado, o TLC verificará o modelo quanto a estados "paralisados", ou seja, aqueles dos quais não há transições de saída. Se houver tais estados no espaço de estados, isso significa um erro claro no modelo. Ou no TLC, que, como qualquer outro programa não trivial, não está imune a erros :) Na minha prática (não tão grande), ainda não encontrei impasses.
E, finalmente, para o início de todos esses testes, a fórmula de segurança em Visão geral do modelo / Invariantes = ALL_EVENTS_PROCESSED(state) .
O TLC verificará a validade da fórmula em cada estado e, se ela se tornar falsa,
exibirá uma mensagem de erro e mostrará a sequência de estados que levaram ao erro.
Depois de iniciar o TLC, depois de trabalhar por cerca de 8 minutos, ele relatou "Sem erros". Isso significa que o modelo é testado e atende às propriedades especificadas.
O TLC também exibe muitas estatísticas interessantes. Por exemplo, para este modelo, foram obtidos 7 677 824 estados únicos; no total, a TLC analisou 27 109 029 estados; o diâmetro do espaço de estados é 47 (este é o comprimento máximo da cadeia de estados antes da repetição,
duração máxima do ciclo de estados não repetidos no gráfico de estado e de transição).
Se dividirmos 27 milhões de estados em 8 minutos, obteremos cerca de 56 mil estados por segundo, o que pode não parecer muito rápido. Mas lembre-se de que eu executei a simulação em um laptop que funcionava no modo de economia de energia (forcei a frequência do núcleo para 800 MHz, porque estava viajando naquele momento em um trem elétrico) e não otimizei o modelo para a velocidade da simulação.
Existem várias maneiras de acelerar a simulação: desde transportar parte do código do modelo TLA + para Java e conectar-se ao TLC em tempo real (é útil acelerar todos os tipos de funções auxiliares) até executar o TLC nas nuvens e nos clusters (o suporte à nuvem da Amazon e Azure está embutido no próprio TLC).
Segunda otimização
No algoritmo anterior, está tudo bem, exceto por alguns problemas:
- Até processarmos todos os eventos da zona azul no intervalo
[state.time, state.time + Delta] , não podemos passar para eventos de alta prioridade. Ou seja, eventos tardios se atrasarão ainda mais. E geralmente o atraso é imprevisível. Por esse motivo, state.time pode ficar muito atrás do horário atual e essa é a causa do próximo problema. - Eventos chegando na região de eventos normais podem estar atrasados ( id > state.id). Eles já são de alta prioridade e devem ser considerados eventos da região rosa, e ainda os consideramos normais e os tratamos como normais.
- É difícil organizar o cache de eventos e a reposição de cache (leitura do banco de dados).
Se os dois primeiros pontos forem óbvios, o terceiro provavelmente levantará o maior número de perguntas. Vamos insistir nisso com mais detalhes.
Suponha que desejemos primeiro ler um número fixo de eventos na memória e depois processá-los.
Após o processamento, queremos marcar os eventos no banco de dados com as consultas de bloco como processadas, pois se você trabalhar não com blocos, mas com eventos únicos, não haverá grande ganho com o cache.
Suponha que tenhamos processado parte dos blocos e desejamos complementar o cache. Então, se eventos atrasados de alta prioridade chegarem durante o processamento, podemos processá-los mais cedo.
Ou seja, é muito desejável poder ler eventos em pequenos blocos para processar os atrasados o mais rápido possível, mas atualizar o atributo de processamento no banco de dados com grandes blocos de uma só vez - para obter eficiência.
O que fazer neste caso?
Tente trabalhar com o banco de dados em pequenos blocos com uma área azul e rosa e mova o ponto de estado em pequenas etapas.
Assim, o cache foi introduzido e lido nos dados do banco de dados; após cada leitura, o ponto de estado foi deslocado para não reler os eventos já lidos.
Agora, o algoritmo se tornou um pouco mais complicado, começamos a ler em porções limitadas.
Fluxograma
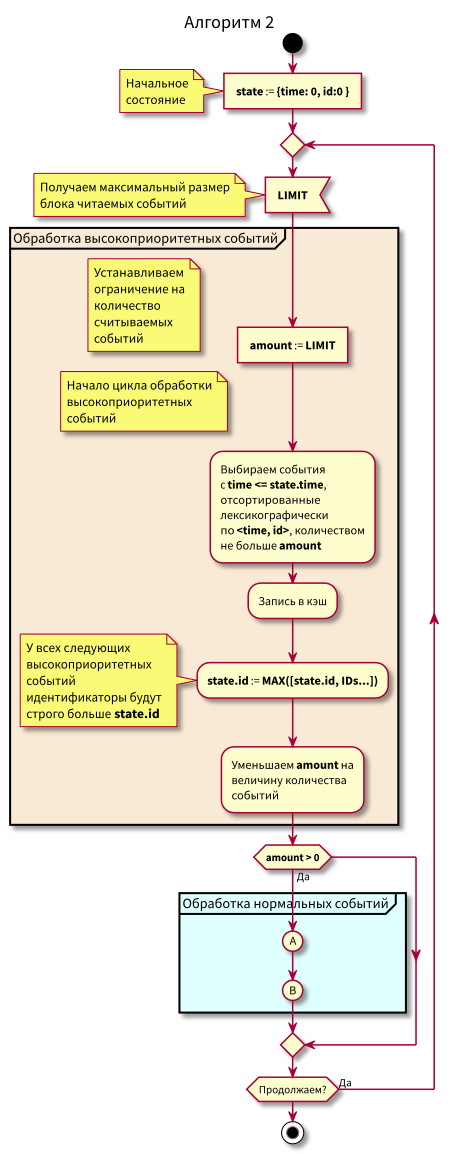
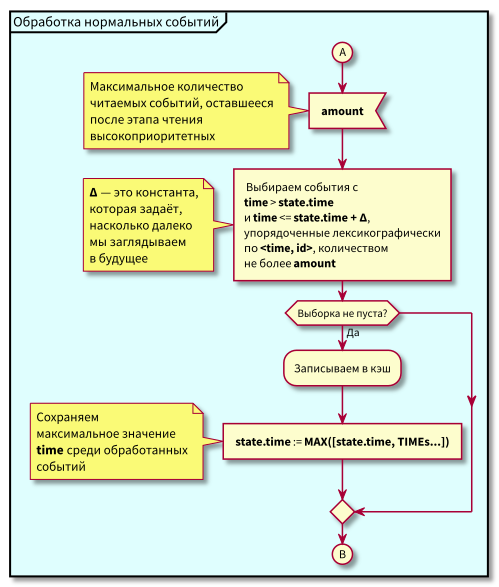
Nesse algoritmo, pode-se observar que, devido à restrição de blocos de eventos legíveis, o atraso máximo na transição do processamento de baixa prioridade para o processamento de alta prioridade será igual ao tempo máximo de processamento do bloco.
Ou seja, agora podemos ler eventos no cache em pequenos blocos e controlar o atraso máximo na transição para o processamento de eventos de alta prioridade através do controle do tamanho máximo do bloco para leitura.
Exemplo de Operação de Algoritmo
Vejamos o algoritmo no trabalho, em etapas. Por conveniência, tome LIMIT = 2 .
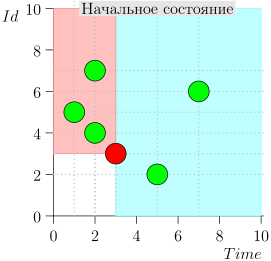
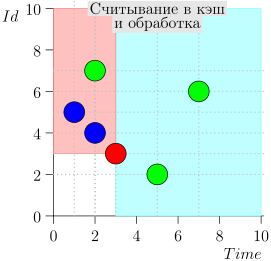
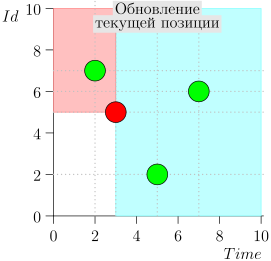
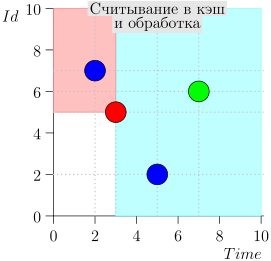
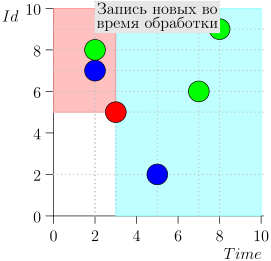
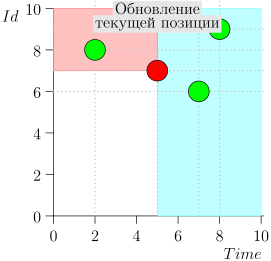
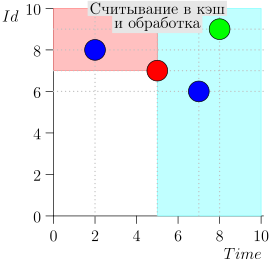
Acontece que o problema está resolvido? Mas não. (É claro que, se o problema foi completamente resolvido nesta fase, então
este artigo não teria sido :))
O erro?
Nesta forma, o algoritmo funcionou por um longo tempo. Todos os testes foram bem. Também não houve problemas na produção.
Mas o desenvolvedor do algoritmo e sua implementação (meu colega Peter Reznikov) é muito experiente e, intuitivamente, sentiu que havia algo errado aqui. Portanto, um verificador foi feito próximo ao código principal, que verificava de vez em quando em um cronômetro para ver se havia algum evento perdido, e
se houver, eu os processei.
Nesta forma, o sistema funcionou com sucesso. É verdade que ninguém mantinha estatísticas sobre o número de eventos selecionados pelo verificador. Infelizmente, não sabemos quantas falhas foram associadas ao processamento prematuro de eventos.
Eu implementei uma fila semelhante de objetos com limite de tempo. Discutindo a implementação e otimização de algoritmos com Peter Reznikov, falamos sobre esse algoritmo para trabalhar com eventos. Eles duvidaram que o algoritmo esteja correto. Decidimos fazer um modelo pequeno para confirmar ou dissipar dúvidas. Como resultado, encontramos um erro.
Modelo
Antes de desmontar o rastreamento com um erro, fornecerei o código fonte do modelo no qual o erro foi detectado.
As diferenças em relação ao modelo anterior são muito pequenas, há apenas um limite no tamanho dos blocos de leitura: o operador Limit é adicionado e, portanto, os operadores de seleção de eventos são alterados.
Para economizar espaço, deixei comentários apenas nas partes alteradas do modelo.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* LIMIT, \* \* \* variables Events = {}, Event_Id = 0, MAX_TIME = 5, LIMIT \in 1..3, TIME_DELTA \in 1..2 define ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) Limit(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result \* SELECT * FROM events \* WHERE time <= curr_time AND id > max_id \* ORDER BY id \* LIMIT limit SELECT_HIGH_PRIO(state, limit) == LET selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } \* Id sorted == SortSeq(ToSeq(selected), EventsOrderById) \* limited == Limit(sorted, limit) IN ToSet(limited) \* SELECT * FROM events \* WHERE time > current_time \* AND time - Time <= delta_time \* ORDER BY time, id \* LIMIT limit SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events: /\ e.time <= state.time + delta_time /\ e.time > state.time } \* sorted == SortSeq(ToSeq(selected), EventsOrder) \* limited == Limit(sorted, limit) IN ToSet(limited) ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, LIMIT) new_limit == LIMIT - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, TIME_DELTA, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events))] || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Um leitor atento pode perceber que, além de introduzir Limit, os rótulos em event_processor também foram alterados. O objetivo é um pouco melhor para simular código real que duas seleções executam em uma transação, ou seja, pode-se dizer que a seleção de eventos é realizada atomicamente.
Bem, se encontrarmos um erro em um modelo com operações atômicas maiores, isso praticamente garante que o mesmo erro ocorra no mesmo modelo, mas com etapas atômicas menores (uma afirmação bastante forte, mas acho que é intuitiva; embora deve ser bom se não for provado e depois verificado em uma ampla seleção de modelos).
Verificação do modelo
Iniciamos a simulação com os mesmos parâmetros da primeira modalidade.
E temos uma violação da propriedade ALL_EVENTS_PROCESSED na 19ª etapa da simulação ao pesquisar em largura.
Para dados iniciais fornecidos (esse é um espaço de estado muito pequeno), o erro na 19ª etapa indica que o erro é muito raro e difícil de detectar, pois antes disso todas as cadeias de estados com comprimento inferior a 19 eram examinadas.
Portanto, esse erro é difícil de detectar nos testes. Somente se você souber onde procurar e selecione especificamente testes e cabanas temporárias.
Não trago a rota inteira para economizar espaço e tempo. Aqui está um segmento de vários estados junto com um erro:
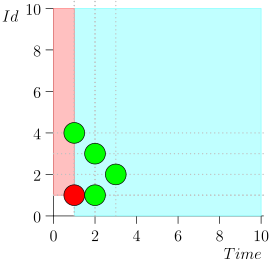

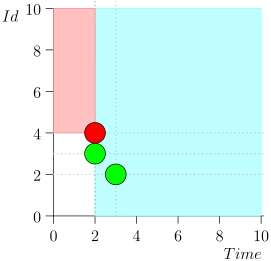
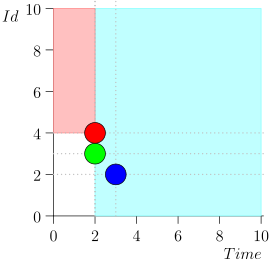
Análise e Correção
O que aconteceu?
Como você pode ver, o erro se manifestou no fato de termos perdido o evento {2, 3} devido ao fato de que o limite terminou no evento {2, 1} e, depois disso, alteramos o estado do coordenador. Isso pode acontecer apenas se em um momento houver vários eventos.
É por isso que o erro foi ilusório nos testes. Para sua manifestação, é necessário que coisas muito raras coincidam:
- Vários eventos atingiram o mesmo ponto no tempo.
- O limite na seleção de eventos terminou antes do momento de ler todos esses eventos.
O erro pode ser corrigido com relativa facilidade se o estado do coordenador for expandido um pouco: adicione a hora e o identificador do último evento de leitura da área normal do evento com o ID máximo se o horário desse evento corresponder ao próximo valor state.time.
Se não houver esse evento, definimos o estado extra (extra_state) para um estado inválido (UNDEF_EVT) e não o levamos em consideração ao trabalhar.
Os eventos da região normal que não foram processados na etapa anterior do coordenador, consideraremos já alta prioridade e, portanto, corrigiremos a seleção do predicado de alta prioridade e segurança.
Seria possível introduzir outra área intermediária entre alta prioridade e normal e alterar o algoritmo. Primeiro, ele processa os de alta prioridade, depois os intermediários, e depois passa para os normais com a subsequente mudança de estado.
Mas essas mudanças levariam a um volume maior de refatoração com benefícios não óbvios (o algoritmo será um pouco mais claro; outras vantagens não são visíveis imediatamente).
Portanto, decidimos ajustar apenas levemente o estado atual e a seleção de eventos do banco de dados.
Modelo ajustado
Aqui está o modelo corrigido.
------------------- MODULE events ------------------- EXTENDS Naturals, FiniteSets, Sequences, TLC \* CONSTANTS MAX_TIME, LIMIT, TIME_DELTA (* --algorithm Events variables Events = {}, Limit \in LIMIT, Delta \in TIME_DELTA, Event_Id = 0 define \* \* , extra_state UNDEF_EVT == [time |-> MAX_TIME + 1, id |-> 0] ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) TakeN(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result (* SELECT * FROM events WHERE time <= curr_time AND id > max_id ORDER BY id Limit limit *) SELECT_HIGH_PRIO(state, limit, extra_state) == LET \* \* time <= curr_time \* AND id > maxt_id selected == {e \in Events : \/ /\ e.time <= state.time /\ e.id >= state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id} sorted == \* SortSeq(ToSeq(selected), EventsOrderById) limited == TakeN(sorted, limit) IN ToSet(limited) SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } sorted == SortSeq(ToSeq(selected), EventsOrder) limited == TakeN(sorted, limit) IN ToSet(limited) \* extra_state UpdateExtraState(events, state, extra_state) == LET exact == {evt \in events : evt.time = state.time} IN IF exact # {} THEN CHOOSE evt \in exact : \A e \in exact: e.id <= evt.id ELSE UNDEF_EVT \* extra_state ALL_EVENTS_PROCESSED(state, extra_state) == \A e \in Events: \/ e.time >= state.time \/ e.id > state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable events = {}, state = ZERO_EVT, extra_state = UNDEF_EVT; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, Limit, extra_state) new_limit == Limit - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, Delta, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events)) ]; extra_state := UpdateExtraState(events, state, extra_state) || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* TLA+, PlusCal \* END TRANSLATION ===================================================
Como você pode ver, as alterações são muito pequenas:
- Dados extras adicionados ao estado extra_state.
- Alterada a seleção de eventos de alta prioridade.
- UpdateExtraState extra_state.
- safety - .
, . , (, , , ).
, , TLA+/TLC . :)
Conclusão
, , ( , , , ).
, , TLA+/TLC, . , .
TLA+/TLC , , ( , ) .
, , , TLA+/TLC .
Livros
, , , . .
Michael Jackson Problem Frames: Analysing & Structuring Software Development Problems
( !), . , . , .
Hillel Wayne Practical TLA+: Planning Driven Development
TLA+/PlusCal . , . . : .
MODEL CHECKING.
. , , . , .
Leslie Lamport Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers
TLA+. , . : , . , TLA+ , .
Formal Development of a Network-Centric RTOS
TLA+ ( RTOS ) TLC.
, . , TLA+ , , RTOS — Virtuoso. , .
, (, , , , ).
w Amazon Web Services Uses Formal Methods
TLA+ AWS. : http://lamport.azurewebsites.net/tla/amazon-excerpt.html
Hillel Wayne ( "Practical TLA+")
. , . , - .
Ron Pressler
. . , TLA+. TLA+, computer science .
Leslie Lamport
TLA+ computer science . TLA+ .
. . , . . , . . .
, , .
TLA+,
, TLA+. , TLA+.
Hillel Wayne
Hillel Wayne . .
Ron Pressler
, Hillel Wayne, . , . Ron Pressler . ́ , , .
TLA toolbox + TLAPS : TLA+
. Alloy Analyzer .