Oi Habr.
Na última vez, descrevemos Has padrão, descrevemos os problemas que ele resolve e escrevemos algumas instâncias específicas:
instance HasDbConfig AppConfig where getDbConfig = dbConfig instance HasWebServerConfig AppConfig where getWebServerConfig = webServerConfig instance HasCronConfig AppConfig where getCronConfig = cronConfig
Parece bom. Que dificuldades podem surgir aqui?
Bem, vamos pensar em quais outras instâncias podemos precisar. Em primeiro lugar, tipos concretos com uma configuração em si são bons candidatos para a implementação (trivial) dessas classes de tipo, o que nos dá mais três instâncias em que cada método é implementado via id , por exemplo
instance HasDbConfig DbConfig where getDbConfig = id
Eles nos permitem escrever facilmente testes individuais ou utilitários auxiliares independentes de todo o AppConfig .
Isso já é chato, mas ainda continua. É fácil imaginar que alguns testes de integração verifiquem a interação de um par de módulos, e ainda não queremos depender da configuração de todo o aplicativo, então agora precisamos escrever seis instâncias (duas por tipo), cada uma das quais será reduzida para fst ou snd . Por exemplo, para DbConfig :
instance HasDbConfig (DbConfig, b) where getDbConfig = fst instance HasDbConfig (a, DbConfig) where getDbConfig = snd
Horror Espera-se que nunca seja necessário testar a operação de três módulos ao mesmo tempo - caso contrário, você precisará escrever nove instâncias chatas. De qualquer forma, eu pessoalmente já estou muito desconfortável e prefiro passar várias horas automatizando esse assunto do que alguns minutos escrevendo uma dúzia de linhas extras de código.
Além disso, se você estiver interessado em resolver esse problema de uma maneira geral, são tipos dependentes e como tudo acabará parecendo um gato Haskell - Welkom.
Resumindo a classe Has
Primeiro, observe que temos classes diferentes para ambientes diferentes. Isso pode interferir na criação de uma solução universal; portanto, removemos o ambiente em um parâmetro separado:
class Has part record where extract :: record -> part
Podemos dizer que Has part record significa que algum valor do tipo part pode ser extraído do valor do record de tipo. Nesses termos, nosso bom e velho HasDbConfig se torna Has DbConfig e da mesma forma para outras classes de tipo que escrevemos anteriormente. Acontece quase uma mudança puramente sintática e, por exemplo, o tipo de uma das funções de nosso post anterior passa de
doSmthWithDbAndCron :: (MonadReader rm, HasDbConfig r, HasCronConfig r) => ...
em
doSmthWithDbAndCron :: (MonadReader rm, Has DbConfig r, Has CronConfig r) => ...
A única mudança é um par de espaços nos lugares certos.
Além disso, não perdemos muito na inferência de tipo: um timer ainda pode gerar o valor de retorno necessário de extract no contexto circundante na grande maioria dos casos encontrados na prática.
Agora que não nos preocupamos com o tipo específico de ambiente, vamos ver quais registros podem implementar a classe de Has part record para a part fixa. Esta tarefa possui uma boa estrutura indutiva:
- Cada tipo possui: O
Has record record é implementado de maneira trivial ( extract = id ). - Se o
record for um produto dos tipos rec1 e rec2 , o campo Has part record será implementado se e somente se Has part rec1 ou Has part rec2 . - Se
record for a soma dos tipos rec1 e rec2 , o Has part record será implementado se e somente se a Has part rec1 e a Has part rec2 . Embora a prevalência prática deste caso neste contexto não seja óbvia, ainda vale a pena mencionar a sua integralidade.
Portanto, parece que formulamos um esboço de um algoritmo para determinar automaticamente se Has part record implementado para dados de part e record !
Felizmente, esse raciocínio indutivo sobre os tipos se encaixa muito bem no mecanismo de genéricos Haskell. Resumidamente e simplificando, o Generics é um dos métodos de metaprogramação generalizada no Haskell, resultante da observação de que cada tipo é um tipo de soma, um tipo de produto ou um tipo básico de construção única com um campo.
Não vou escrever outro tutorial sobre genéricos, portanto, apenas passe para o código.
Primeira tentativa
Usaremos o método clássico de implementação Generic de nossos Has através da classe auxiliar GHas :
class GHas part grecord where gextract :: grecord p -> part
Aqui grecord é uma representação Generic do nosso tipo de record .
GHas implementações seguem a estrutura indutiva que observamos acima:
instance GHas record (K1 i record) where gextract (K1 x) = x instance GHas part record => GHas part (M1 it record) where gextract (M1 x) = gextract x instance GHas part l => GHas part (l :*: r) where gextract (l :*: _) = gextract l instance GHas part r => GHas part (l :*: r) where gextract (_ :*: r) = gextract r
K1 corresponde ao caso base.M1 - Metadados específicos de genéricos que não precisamos em nossa tarefa, portanto, simplesmente os ignoramos e os analisamos.- A primeira instância do tipo de produto
l :*: r corresponde ao caso em que a parte "esquerda" do produto tem o valor da part de tipo de que precisamos (possivelmente, recursivamente). - Da mesma forma, a segunda instância para o tipo de produto
l :*: r corresponde ao caso em que a parte "correta" do produto tem o valor desejado da part tipo (naturalmente, também, possivelmente, recursivamente).
Somente suportamos tipos de produtos aqui. Minha impressão subjetiva é que as quantias não são usadas com tanta frequência em contextos para o MonadReader e classes semelhantes, portanto podem ser negligenciadas para simplificar a consideração.
Além disso, é útil observar que cada O produto secundário (a1, ..., an) pode ser representado como uma composição pares (a1, (a2, (a3, (..., an)))) , por isso me permito associar tipos de produtos a pares.
Com nosso GHas , você pode escrever uma implementação padrão para Has que usa genéricos:
class Has part record where extract :: record -> part default extract :: Generic record => record -> part extract = gextract . from
Feito.
Ou não?
O problema
Se tentarmos compilar esse código, veremos que ele não taypechaetsya, mesmo sem qualquer tentativa de usar essa implementação por padrão, relatando algumas instâncias sobrepostas lá. Pior, essas instâncias são iguais em alguns aspectos. Parece que é hora de descobrir como o mecanismo para resolver instâncias no Haskell funciona.
Que possamos ter
instance context => Foo barPattern bazPattern where ...
(A propósito, essa coisa depois de => é chamada de instance head.)
Parece natural ler isso como
Vamos precisar escolher uma instância para Foo bar baz . Se o context satisfeito, você poderá selecionar esta instância, desde que bar e baz correspondam a barPattern e bazPattern .
No entanto, isso é uma má interpretação e exatamente o oposto:
Vamos precisar escolher uma instância para Foo bar baz . Se bar e baz corresponderem a barPattern e bazPattern , selecionaremos essa instância e adicionaremos context à lista de constantes que devem ser resolvidas.
Agora é óbvio qual é o problema. Vamos dar uma olhada no seguinte par de instâncias:
instance GHas part l => GHas part (l :*: r) where gextract (l :*: _) = gextract l instance GHas part r => GHas part (l :*: r) where gextract (_ :*: r) = gextract r
Eles têm as mesmas cabeças de instância, portanto, não é de admirar que se cruzem! Além disso, nenhum deles é mais específico que o outro.
Além disso, não há como refinar de alguma forma essas instâncias para que elas deixem de se sobrepor. Bem, além de adicionar mais parâmetros GHas .
Tipos expressivos correm para o resgate!
A solução para o problema é pré-calcular o "caminho" para o valor de seu interesse e usar esse caminho para orientar a escolha das instâncias.
Como concordamos em não oferecer suporte a tipos de soma, um caminho é, literalmente, uma sequência de curvas à esquerda ou à direita nos tipos de produto (ou seja, escolhas do primeiro ou segundo componente de um par), terminando com um grande ponteiro "AQUI", assim que encontrarmos o tipo desejado . Nós escrevemos isso:
data Path = L Path | R Path | Here deriving (Show)
Por exemploConsidere os seguintes tipos:
data DbConfig = DbConfig { dbAddress :: DbAddress , dbUsername :: Username , dbPassword :: Password } data AppConfig = AppConfig { dbConfig :: DbConfig , webServerConfig :: WebServerConfig , cronConfig :: CronConfig }
Quais são alguns exemplos de caminhos do AppConfig ?
- Para
DbConfig ⟶ L Here . - Para
WebServerConfig ® R (L Here) . - Para
CronConfig ® R (R Here) . - Para
DbAddress ⟶ L (L Here) .
Qual poderia ser o resultado de uma pesquisa por um valor do tipo desejado? Duas opções são óbvias: podemos encontrá-lo ou não. Mas, de fato, tudo é um pouco mais complicado: podemos encontrar mais de um valor desse tipo. Aparentemente, o comportamento mais sensato nesse caso controverso também seria uma mensagem de erro. Qualquer escolha de um valor específico terá uma certa quantidade de aleatoriedade.
De fato, considere nosso exemplo padrão de serviço da web. Se alguém quiser obter um valor do tipo (Host, Port) , deve ser o endereço do servidor de banco de dados ou o endereço do servidor da web? É melhor não arriscar.
De qualquer forma, vamos expressar isso no código:
data MaybePath = NotFound | Conflict | Found Path deriving (Show)
Separamos NotFound e Conflict , pois o tratamento desses casos é fundamentalmente diferente: se NotFound em uma das ramificações do nosso tipo de produto, não será prejudicial encontrar o valor desejado em outra ramificação, enquanto Conflict em qualquer ramificação significa imediatamente completo. um fracasso.
Agora, consideramos um caso especial de tipos de produto (que, como concordamos, consideramos como pares). Como encontrar o valor do tipo desejado neles? Você pode executar uma pesquisa recursivamente em cada componente de um par, obter os resultados p1 e p2 respectivamente, e combiná-los de alguma forma.
Como estamos falando sobre a escolha de instâncias de classes de tempo que ocorrem durante a compilação, na verdade precisamos de cálculos em tempo de compilação, que são expressos no Haskell por meio de cálculos em tipos (mesmo que os tipos sejam representados por termos criados no universo usando DataKinds ). Por conseguinte, essa função nos tipos é representada como família de tipos:
type family Combine p1 p2 where Combine ('Found path) 'NotFound = 'Found ('L path) Combine 'NotFound ('Found path) = 'Found ('R path) Combine 'NotFound 'NotFound = 'NotFound Combine _ _ = 'Conflict
Esta função representa vários casos:
- Se uma das pesquisas recursivas for bem-sucedida e a outra
NotFound ao NotFound , seguiremos o caminho da pesquisa bem-sucedida e anexaremos a curva na direção certa. - Se ambas as pesquisas recursivas terminarem com
NotFound , obviamente toda a pesquisa terminará com NotFound . - Em qualquer outro caso, temos
Conflict .
Agora, escreveremos uma função em nível de faixa que leva a part a ser encontrada, e uma representação Generic do tipo em que a part encontrada e as pesquisas:
type family Search part (grecord :: k -> *) :: MaybePath where Search part (K1 _ part) = 'Found 'Here Search part (K1 _ other) = 'NotFound Search part (M1 _ _ x) = Search part x Search part (l :*: r) = Combine (Search part l) (Search part r) Search _ _ = 'NotFound
Observe que obtivemos algo muito semelhante em significado à nossa tentativa anterior com o GHas . Isso é de se esperar, já que estamos realmente reproduzindo o algoritmo que tentamos expressar através das classes de tempo.
GHas , tudo o que resta para nós é adicionar um parâmetro adicional a essa classe, responsável pelo caminho encontrado anteriormente e que servirá para selecionar instâncias específicas:
class GHas (path :: Path) part grecord where gextract :: Proxy path -> grecord p -> part
Também adicionamos um argumento adicional para o gextract para que o compilador possa selecionar a instância correta para o caminho especificado (que deve ser mencionado na assinatura da função).
Agora, escrever instâncias é bem fácil:
instance GHas 'Here record (K1 i record) where gextract _ (K1 x) = x instance GHas path part record => GHas path part (M1 it record) where gextract proxy (M1 x) = gextract proxy x instance GHas path part l => GHas ('L path) part (l :*: r) where gextract _ (l :*: _) = gextract (Proxy :: Proxy path) l instance GHas path part r => GHas ('R path) part (l :*: r) where gextract _ (_ :*: r) = gextract (Proxy :: Proxy path) r
De fato, simplesmente selecionamos a instância desejada com base no path que calculamos anteriormente.
Como agora escrever nossa implementação default da função extract :: record -> part na classe Has ? Temos várias condições:
record deve implementar o Generic para que o mecanismo genérico possa ser aplicado, para obter um Generic record .- A função
Search deve encontrar part no record (ou melhor, na representação Generic do record , que é expressa como Rep record ). No código, isso parece um pouco mais incomum: Search part (Rep record) ~ 'Found path . Esse registro significa a restrição de que o resultado da Search part (Rep record) deve ser igual ao 'Found path para algum path (que, de fato, é interessante para nós). - Deveríamos poder usar
GHas junto com a part , a representação genérica do record e path da última etapa, que se transforma em uma GHas path part (Rep record) .
Reuniremos as duas últimas constantes várias vezes mais, portanto, é útil colocá-las em um sinônimo const separado:
type SuccessfulSearch part record path = (Search part (Rep record) ~ 'Found path, GHas path part (Rep record))
Dado esse sinônimo, obtemos
class Has part record where extract :: record -> part default extract :: forall path. (Generic record, SuccessfulSearch part record path) => record -> part extract = gextract (Proxy :: Proxy path) . from
Agora tudo!
Usando genérico Has
Para analisar tudo isso em ação, escreveremos algumas instâncias gerais para manequins:
instance SuccessfulSearch a (a0, a1) path => Has a (a0, a1) instance SuccessfulSearch a (a0, a1, a2) path => Has a (a0, a1, a2) instance SuccessfulSearch a (a0, a1, a2, a3) path => Has a (a0, a1, a2, a3)
Aqui, SuccessfulSearch a (a0, ..., an) path é responsável pelo fato de que a ocorre entre a0, ..., an exatamente uma vez.
Que possamos agora ter nosso bom e velho
data AppConfig = AppConfig { dbConfig :: DbConfig , webServerConfig :: WebServerConfig , cronConfig :: CronConfig }
e queremos Has DbConfig , Has WebServerConfig e Has CronConfig . Basta incluir as DeriveAnyClass e DeriveAnyClass e adicionar a declaração de deriving correta:
data AppConfig = AppConfig { dbConfig :: DbConfig , webServerConfig :: WebServerConfig , cronConfig :: CronConfig } deriving (Generic, Has DbConfig, Has WebServerConfig, Has CronConfig)
Temos a sorte (ou éramos suficientemente perspicazes) de organizar os argumentos para Has para que o nome do tipo aninhado seja o primeiro, para que possamos confiar no mecanismo DeriveAnyClass para minimizar os rabiscos.
Segurança vem em primeiro lugar
E se não tivermos nenhum tipo?
data AppConfig = AppConfig { dbConfig :: DbConfig , webServerConfig :: WebServerConfig } deriving (Generic, Has CronConfig)
Não, obtemos um erro diretamente no ponto de definição do tipo:
Spec.hs:35:24: error: • Couldn't match type ''NotFound' with ''Found path0' arising from the 'deriving' clause of a data type declaration • When deriving the instance for (Has CronConfig AppConfig) | 35 | } deriving (Generic, Has CronConfig) | ^^^^^^^^^^^^^^
Não é a mensagem de erro mais amigável, mas mesmo assim você ainda pode entender qual é o problema: a frequência ímpar NotFound frequência ímpar CronConfig .
E se tivermos vários campos do mesmo tipo?
data AppConfig = AppConfig { prodDbConfig :: DbConfig , qaDbConfig :: DbConfig , webServerConfig :: WebServerConfig , cronConfig :: CronConfig } deriving (Generic, Has DbConfig)
Não, como esperado:
Spec.hs:37:24: error: • Couldn't match type ''Conflict' with ''Found path0' arising from the 'deriving' clause of a data type declaration • When deriving the instance for (Has DbConfig AppConfig) | 37 | } deriving (Generic, Has DbConfig) | ^^^^^^^^^^^^
Tudo parece estar realmente bom.
Resumir
Então, tentaremos formular brevemente o método proposto.
Suponha que tenhamos algum tipo de classe e queremos exibir automaticamente suas instâncias de acordo com algumas regras recursivas. Em seguida, podemos evitar as ambiguidades (e geralmente expressar essas regras se não forem triviais e não se ajustarem ao mecanismo padrão para resolver instâncias) da seguinte maneira:
- Codificamos regras recursivas na forma de um tipo de dados indutivo
T - Escreveremos uma função em tipos (na forma de família de tipos) para cálculo preliminar do valor
v desse tipo T (ou, em termos de Haskell, tipo v tipo T - onde estão meus tipos dependentes), que descreve a sequência específica de etapas que precisam ser executadas. - Use este
v como um argumento adicional para o auxiliar Generic para determinar a sequência específica de instâncias que agora correspondem aos valores de v .
Bem, é isso!
Nas postagens a seguir, veremos algumas extensões elegantes (bem como limitações elegantes) dessa abordagem.
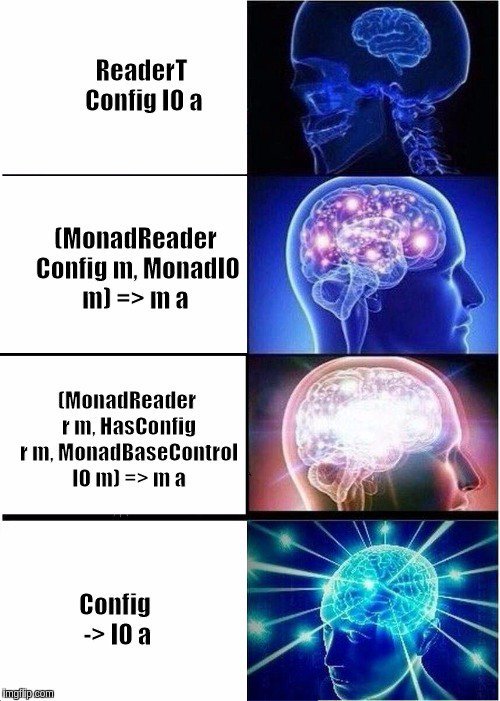
Ah e sim. É interessante rastrear a sequência de nossas generalizações.
- Iniciado com
Env -> Foo . - Não é geral o suficiente, encerre na mônada do
Reader Env . - Não suficientemente geral, reescreva com o
MonadReader Env m . - Não é geral o suficiente, reescreva
MonadReader rm, HasEnv r . - Não é suficientemente genérico,
MonadReader rm, Has Env r escrever MonadReader rm, Has Env r e adicionar genéricos para que o compilador faça tudo lá. - Agora a norma.