
1. Introdução
Olá queridos Khabrovites!
Os últimos dois anos do meu trabalho na
Synesis estão intimamente ligados ao processo de criação e desenvolvimento do
Synet - uma biblioteca aberta para a execução de redes neurais convolucionais pré-treinadas na CPU. No processo deste trabalho, tive de encontrar vários pontos interessantes relacionados à otimização de algoritmos de propagação direta de sinal em redes neurais. Parece-me que uma descrição desses pontos seria muito interessante para os leitores de Habrahabr. O que eu quero dedicar uma série de meus artigos. A duração do ciclo dependerá do seu interesse neste tópico e, é claro, da minha capacidade de superar a preguiça. Quero começar o ciclo com uma descrição da própria
bicicleta de quadro. As questões dos algoritmos subjacentes a ela serão divulgadas nos artigos seguintes:
- Camada de convolução: técnicas de otimização de multiplicação de matrizes
- Camada convolucional: convolução rápida de acordo com o método de Shmuel Vinograd
Respostas às perguntas
Antes de iniciar uma descrição detalhada da estrutura, tentarei responder imediatamente a uma série de perguntas que os leitores provavelmente terão. A experiência sugere que é melhor fazer isso com antecedência, pois muitos começam imediatamente a escrever comentários irados, sem ter lido até o fim.
A primeira pergunta que geralmente surge nesses casos:
quem agora administra redes em processadores convencionais, quando existem aceleradores gráficos e aceleradores de tensores (matriz)?Responderei que sim - não é realmente aconselhável realizar o treinamento de redes neurais na CPU, mas a execução de redes neurais prontas é bastante uma demanda, especialmente se a rede for pequena o suficiente. Os motivos para isso podem ser diferentes, mas os principais:
- CPUs são mais comuns. Nem todas as máquinas possuem uma GPU, especialmente servidores.
- Em redes neurais pequenas, os ganhos com o uso da GPU são pequenos e às vezes completamente ausentes.
- O envolvimento eficaz da GPU para acelerar as redes neurais geralmente requer uma estrutura de aplicativos significativamente mais complexa.
A próxima pergunta possível:
Por que usar uma solução especializada para iniciar quando há Tensorflow , Caffe ou MXNet ?Você pode responder o seguinte:
- Uma variedade de estruturas nem sempre é boa - portanto, se houver vários modelos treinados em estruturas diferentes em um projeto, será necessário incorporá-los a uma solução pronta, o que é muito inconveniente.
- As estruturas clássicas foram projetadas para treinar modelos de GPU - e certamente são boas nisso! Mas, para executar modelos treinados na CPU, sua funcionalidade é redundante e não é ideal.
- A confirmação da necessidade de uma solução especializada é a popularidade do OpenVINO - uma estrutura da Intel, que executa a mesma função.
Aqui imediatamente surge uma pergunta lógica sobre a invenção da bicicleta:
por que usar sua embarcação quando existe uma solução completamente profissional de um líder mundial reconhecido?Minha resposta é:
- No início dos trabalhos no Synet, o OpenVINO ainda estava em sua infância. E, na verdade, se naquele momento o OpenVINO estivesse em seu estado atual, com um alto grau de probabilidade, eu não me envolveria em meu próprio projeto.
- Você pode adaptar sua própria estrutura às suas necessidades. Portanto, no meu caso, o principal requisito era o desempenho máximo de thread único.
- Você pode fornecer suporte para novas funcionalidades o mais rápido possível, se precisar repentinamente (por exemplo, adicione uma nova camada e elimine um erro de desempenho).
- Fácil de integrar em uma solução pronta para uso.
- O funcionamento da biblioteca em plataformas diferentes de x86 / x86_64 - por exemplo, no ARM.
É provável que os leitores tenham outras perguntas ou objeções - mas ainda não as posso prever e, portanto, responderei nos comentários ao artigo. Enquanto isso, vamos começar com uma descrição direta do Synet.
Breve descrição do Synet
O Synet é escrito em
C ++ e contém apenas
arquivos de cabeçalho . Otimizações
específicas de plataforma de baixo nível são implementadas no
Simd , outro projeto de código aberto dedicado a acelerar o processamento de imagens em uma CPU. E essa é a única dependência externa da Synet (esse esquema foi escolhido para facilitar a integração da biblioteca em projetos de terceiros). Para lançar redes neurais, modelos de seu próprio formato interno são usados.
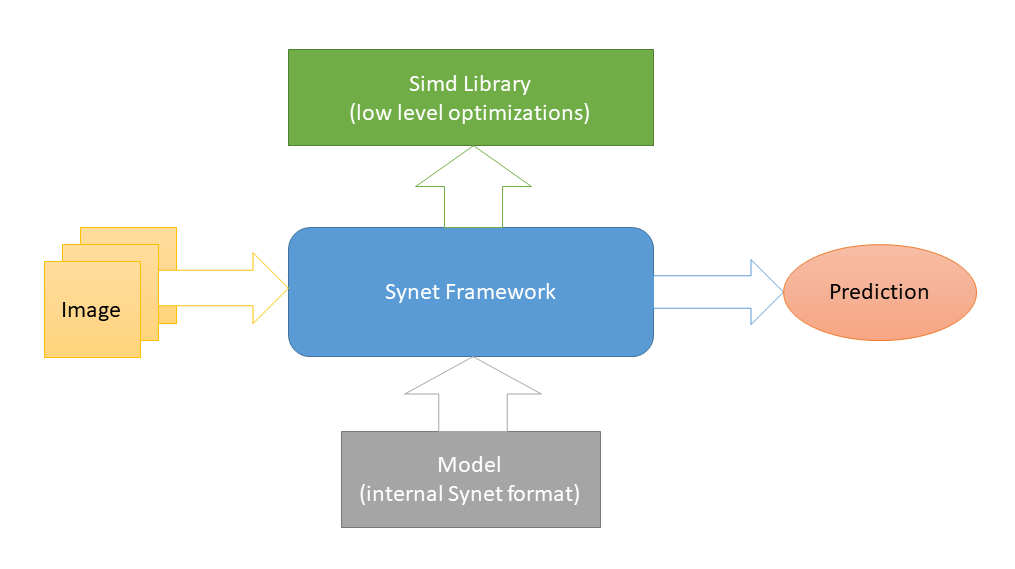
A conversão de modelos pré-treinados para o formato interno é realizada de acordo com um esquema de duas etapas: 1) Primeiro, converta o modelo no formato do Inference Engine (bom
O OpenVINO possui todas as
ferramentas necessárias para isso). 2) A partir dessa representação intermediária, converta diretamente para o formato Synet interno.

O modelo Synet contém dois arquivos: 1) * .XML - um arquivo com uma descrição da estrutura do modelo. 2) * .BIN - um arquivo com pesos treinados.

Exemplo de Synet
A seguir, é apresentado um exemplo do uso do Synet para detectar rostos. O modelo original do Inference Engine é obtido
aqui .
#define SYNET_SIMD_LIBRARY_ENABLE #include "Synet/Network.h" #include "Synet/Converters/InferenceEngine.h" #include "Simd/SimdDrawing.hpp" typedef Synet::Network<float> Net; typedef Synet::View View; typedef Synet::Shape Shape; typedef Synet::Region<float> Region; typedef std::vector<Region> Regions; int main(int argc, char* argv[]) { Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin"); Net net; net.Load("synet.xml", "synet.bin"); net.Reshape(256, 256, 1); Shape shape = net.NchwShape(); View original; original.Load("faces_0.ppm"); View resized(shape[3], shape[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea); net.SetInput(resized, 0.0f, 255.0f); net.Forward(); Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f); uint32_t white = 0xFFFFFFFF; for (size_t i = 0; i < faces.size(); ++i) { const Region & face = faces[i]; ptrdiff_t l = ptrdiff_t(face.x - face.w / 2); ptrdiff_t t = ptrdiff_t(face.y - face.h / 2); ptrdiff_t r = ptrdiff_t(face.x + face.w / 2); ptrdiff_t b = ptrdiff_t(face.y + face.h / 2); Simd::DrawRectangle(original, l, t, r, b, white); } original.Save("annotated_faces_0.ppm"); return 0; }
Como resultado do exemplo, uma imagem com rostos anotados deve aparecer:

Agora vamos dar um exemplo das etapas:
- Primeiro, o modelo é convertido do formato do Inference Engine para Synet:
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
Na realidade, essa etapa é feita uma vez e, em seguida, o modelo já convertido é usado em qualquer lugar. - Faça o download do modelo convertido:
Net net; net.Load("synet.xml", "synet.bin");
- Uma etapa opcional para redimensionar a imagem de entrada e o lote (naturalmente, o modelo deve suportar o redimensionamento da imagem de entrada):
net.Reshape(256, 256, 1);
- Carregando uma imagem e trazendo-a para o tamanho de entrada do modelo:
View original; original.Load("faces_0.ppm"); View resized(net.NchwShape()[3], net.NchwShape()[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea);
- Carregando imagem no modelo:
net.SetInput(resized, 0.0f, 255.0f);
- Iniciando a propagação direta do sinal na rede:
net.Forward();
- Obtendo um conjunto de regiões com faces encontradas:
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
Comparação de desempenho
Provavelmente não seria inteiramente correto comparar o Synet com estruturas clássicas para aprendizado de máquina, por exemplo, o Inference Engine as
ignora várias vezes em vários testes .
Portanto, a seguir, é apresentado um exemplo de comparação do desempenho de thread único do Inference Engine (um produto de funcionalidade semelhante) e do Synet em uma amostra de um
conjunto de modelos abertos :
Como pode ser visto na tabela, nesses testes em uma máquina com suporte para AVX2 (i7-6700), o desempenho do Synet geralmente corresponde ao desempenho do Inference Engine (embora varie bastante de modelo para modelo). Em uma máquina com suporte para o AVX-512 (i9-7900X), o desempenho da Synet é 25% maior que o do Inference Engine.
Todas as medições foram realizadas pelo aplicativo de teste, que está no Synet. Portanto, se desejado, os leitores poderão reproduzir os testes eles mesmos:
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet cd synet ./build.sh inference_engine ./test.sh
Vantagens e desvantagens
Vou começar com os profissionais:
- O projeto é pequeno, facilmente implementado em projetos de terceiros.
- Mostra alto desempenho de thread único.
- Funciona em processadores móveis (suporta ARM-NEON).
Bem e contras, onde sem eles:
- Não há suporte para GPU e outros aceleradores especiais.
- Paralelização deficiente de uma tarefa em CPUs com vários núcleos.
- Não há suporte para INT8 (quantização de pesos).
Conclusão
Atualmente, a Synet está sendo usada como parte do projeto
Kipod , uma plataforma baseada em nuvem para análise de vídeo. Talvez ele tenha outros usuários, mas isso não é certo :). No futuro, à medida que o projeto se desenvolver, gostaria de adicionar o seguinte:
- Suporte para novos modelos, camadas, algoritmos.
- Suporte para cálculos inteiros no formato INT8 (pesos quantizados).
- Suporte de computação GPU.
- Converta do formato ONNX.
Esta lista está longe de estar completa e gostaria de complementá-la, levando em consideração a opinião da comunidade - portanto, estou aguardando o seu feedback! Tornar a ferramenta útil não apenas para nossa empresa, mas também para uma ampla gama de usuários. Além disso, o autor não recusaria a assistência da comunidade no processo de desenvolvimento.
Ao descrever o Synet, que fiz neste artigo, deliberadamente não mergulhei nos detalhes de sua implementação interna - existem muitos algoritmos saborosos, mas gostaria de divulgar os detalhes de sua implementação nos seguintes artigos da série:
- Camada de convolução: técnicas de otimização de multiplicação de matrizes
- Camada convolucional: convolução rápida de acordo com o método de Shmuel Vinograd