Continuação da tradução de um pequeno livro:
"Entendendo os Message Brokers",
autor: Jakub Korab, editor: O'Reilly Media, Inc., data de publicação: junho de 2017, ISBN: 9781492049296.
Tradução concluídaParte anterior:
Compreendendo os Message Brokers. Aprendendo a mecânica das mensagens através do ActiveMQ e Kafka. Capítulo 1. IntroduçãoCAPÍTULO 2
Activemq
O ActiveMQ é melhor descrito como um sistema de mensagens clássico. Foi escrito em 2004 para preencher a necessidade de um broker de mensagens de código aberto. Naquele momento, se você desejasse usar mensagens em seus aplicativos, a única opção seria produtos comerciais caros.
O ActiveMQ foi desenvolvido como uma implementação da especificação Java Message Service (JMS). Esta decisão foi tomada para atender aos requisitos para implementar o sistema de mensagens compatível com JMS no projeto Apache Geronimo, um servidor de aplicativos J2EE de código aberto.
Um sistema de mensagens (ou middleware orientado a mensagens, como às vezes é chamado) que implementa a especificação JMS consiste nos seguintes componentes:
CorretorUma parte central do middleware que distribui mensagens.
ClienteA parte do software que envia mensagens através de um broker. Por sua vez, consiste nos seguintes artefatos:
- Código usando a API JMS.
- A API JMS é um conjunto de interfaces para interagir com um broker de acordo com as garantias estabelecidas na especificação JMS.
- A biblioteca do cliente do sistema que fornece a implementação da API e interage com o broker.
O cliente e o intermediário se comunicam através do protocolo da camada de aplicação, também conhecido como
protocolo de interação (Figura 2-1) . A especificação JMS deixou os detalhes deste protocolo para implementações específicas.
 Figura 2-1. Revisão JMS
Figura 2-1. Revisão JMSA JMS usa o termo
provedor para descrever a implementação do fornecedor do sistema de mensagens subjacente à API JMS, que inclui o broker, bem como suas bibliotecas clientes.
A escolha a favor da implementação do JMS teve conseqüências de longo alcance para as decisões de implementação tomadas pelos autores do ActiveMQ. A própria especificação fornece uma orientação clara sobre as responsabilidades do cliente do sistema de mensagens e do broker com quem ele se comunica, dando preferência à obrigação do broker de distribuir e entregar mensagens. A principal responsabilidade do cliente é interagir com o destinatário (fila ou tópico) das mensagens enviadas por ele. A própria especificação visa tornar a interação da API com o broker relativamente simples.
Essa área, como veremos mais adiante, teve um impacto significativo no desempenho do ActiveMQ. Além das complexidades do broker, o pacote de compatibilidade para as especificações fornecidas pela Sun Microsystems tinha muitas nuances, com seu próprio impacto no desempenho. Todas essas nuances devem ter sido levadas em consideração para que o ActiveMQ seja considerado compatível com JMS.
Comunicação
Embora a API e o comportamento esperado tenham sido bem definidos na especificação JMS, o protocolo de comunicação cliente-intermediário real foi deliberadamente excluído da especificação, para que os corretores existentes pudessem ser compatíveis com JMS. Assim, o ActiveMQ estava livre para definir seu próprio protocolo de interação, o OpenWire. O OpenWire é usado pela implementação da biblioteca do cliente ActiveMQ JMS, bem como suas contrapartes em .Net e C ++: NMS e CMS, que são subprojetos do ActiveMQ hospedados pela Apache Software Foundation.
Com o tempo, o suporte para outros protocolos de interação foi adicionado ao ActiveMQ, o que aumentou a capacidade de interagir com outros idiomas e ambientes:
AMQP 1.0O Protocolo Avançado de Enfileiramento de Mensagens (ISO / IEC 19464: 2014) não deve ser confundido com o antecessor 0.X, que é implementado em outros sistemas de mensagens, em particular o RabbitMQ, usando o 0.9.1. O AMQP 1.0 é um protocolo binário de uso geral para troca de mensagens entre dois nós. Ele não tem conceito de clientes ou corretores e inclui funções como controle de fluxo, transações e várias QoS (não mais de uma vez, pelo menos uma vez e exatamente uma vez).
STOMPProtocolo de mensagens orientado a texto simples / de fluxo contínuo, um protocolo fácil de implementar que possui dezenas de implementações de clientes em diferentes idiomas.
XmppMensagens extensíveis e protocolo de presença. (Protocolo extensível de mensagens e presença). Anteriormente chamado de Jabber, esse protocolo baseado em XML foi desenvolvido originalmente para sistemas de bate-papo, mas foi estendido além de seus casos de uso originais para incluir mensagens de publicação / assinatura.
MQTTO protocolo leve de publicação e assinatura (ISO / IEC 20922: 2016) usado para aplicativos Machine-to-Machine (M2M) e Internet das Coisas (IoT).
O ActiveMQ também suporta a imposição dos protocolos acima no WebSockets, que fornece troca de dados full-duplex entre aplicativos em um navegador da web e destinos no broker.
Diante disso, agora, quando falamos sobre o ActiveMQ, não nos referimos mais exclusivamente à pilha de interação baseada nas bibliotecas JMS / NMS / CMS e no protocolo OpenWire. A combinação e seleção de idiomas, plataformas e bibliotecas externas mais adequadas para este aplicativo está se tornando cada vez mais popular. Por exemplo, é possível que um aplicativo JavaScript seja executado em um navegador usando a biblioteca
Eclipse Paho MQTT para enviar mensagens ao ActiveMQ por soquetes da web, e essas mensagens são lidas por um processo do servidor C ++ que usa o AMQP na biblioteca do
Apache Qpid Proton . Nessa perspectiva, o cenário das mensagens está se tornando mais diversificado.
Olhando para o futuro, o AMQP, em particular, terá muito mais oportunidades do que é agora, pois os componentes que não são clientes nem corretores estão se tornando uma parte mais familiar do cenário das mensagens. Por exemplo, o
Apache Qpid Dispatch Router atua como um roteador de mensagens, ao qual os clientes se conectam diretamente, permitindo que destinos diferentes processem endereços diferentes, além de oferecer a possibilidade de fragmentação (separação).
Ao trabalhar com bibliotecas de terceiros e componentes externos, observe que eles têm qualidade variável e podem não ser compatíveis com as funções fornecidas no ActiveMQ. Como um exemplo muito simples - é impossível enviar mensagens para a fila por meio do MQTT (sem configurar o roteamento no broker). Assim, você precisará dedicar algum tempo trabalhando com opções para determinar a pilha do sistema de mensagens mais adequada aos requisitos do seu aplicativo.
A troca entre desempenho e confiabilidade
Antes de nos aprofundarmos nos detalhes de como as mensagens ponto a ponto funcionam no ActiveMQ, precisamos conversar um pouco sobre o que todos os sistemas com processamento pesado de dados enfrentam: uma troca entre desempenho e confiabilidade.
Qualquer sistema que aceite dados, seja um intermediário de mensagens ou um banco de dados, deve receber instruções sobre como processar esses dados no caso de uma falha. O fracasso pode assumir várias formas, mas, por simplicidade, vamos reduzi-lo a uma situação em que o sistema perde energia e desliga imediatamente. Nessa situação, precisamos especular sobre o que acontecerá com os dados que estavam no sistema. Se os dados (nesse caso, as mensagens) estavam na memória ou na parte volátil do ferro, por exemplo, no cache, esses dados serão perdidos. No entanto, se os dados foram enviados para armazenamento não volátil, por exemplo, para disco, eles estarão disponíveis novamente quando o sistema retornar ao trabalho.
Desse ponto de vista, faz sentido que, se não queremos perder mensagens no caso de uma falha do broker, precisamos gravá-las no armazenamento permanente. O custo dessa solução em particular, infelizmente, é bastante alto.
Observe que a diferença entre gravar um megabyte de dados no disco é 100-1000 vezes mais lenta que gravar na memória. Portanto, o desenvolvedor do aplicativo deve decidir se a confiabilidade da mensagem vale a perda de desempenho. Decisões como essas devem ser tomadas com base em um cenário de uso.
A troca entre desempenho e confiabilidade é baseada em uma variedade de opções. Quanto maior a confiabilidade, menor o desempenho. Se você decidir tornar o sistema menos confiável, por exemplo, armazenando mensagens apenas na memória, sua produtividade aumentará significativamente. Por padrão, o JMS está configurado para ter o ActiveMQ pronto para uso, para confiabilidade. Existem muitos mecanismos que permitem configurar o broker e interagir com ele para uma posição nesse espectro mais adequada para cenários específicos de uso do sistema de mensagens.
Esse compromisso é aplicado no nível de corretores individuais. No entanto, após a conclusão da configuração de um broker individual, é possível escalar o sistema de mensagens além desse ponto, examinando cuidadosamente os fluxos de mensagens e compartilhando o tráfego entre vários brokers. Isso pode ser alcançado fornecendo aos destinatários específicos seus próprios intermediários ou dividindo o fluxo geral de mensagens no nível do aplicativo ou usando um componente intermediário. Posteriormente, consideraremos com mais detalhes como levar em conta as topologias dos corretores.
Salvando Mensagens
O ActiveMQ vem com várias estratégias de retenção de mensagens conectáveis. Eles vêm na forma de adaptadores de persistência (persistência), que podem ser considerados como mecanismos de armazenamento de mensagens. Isso inclui soluções baseadas em disco, como KahaDB e LevelDB, além da capacidade de usar o banco de dados por meio do JDBC. Como os primeiros são mais comumente usados, focaremos nossa discussão neles.
Quando um broker recebe mensagens persistentes, elas são primeiro gravadas no disco em um diário. Um diário é uma estrutura de dados em disco na qual você só pode adicionar dados e consistir em vários arquivos. As mensagens recebidas são serializadas pelo broker em uma representação independente do protocolo do objeto e, em seguida, empacotadas em formato binário, que é gravado no final do log. O log contém um log de todas as mensagens recebidas, além de informações sobre as mensagens que foram confirmadas como lidas pelo cliente.
Os adaptadores de disco de persistência suportam arquivos de índice que rastreiam onde as seguintes mensagens encaminhadas estão localizadas no log. Quando todas as mensagens do arquivo de log são lidas, elas serão excluídas ou arquivadas pelo fluxo de trabalho em segundo plano do ActiveMQ. Se esse log for danificado durante a falha do broker, o ActiveMQ o reconstruirá com base nas informações nos arquivos de log.
As mensagens de todas as filas são gravadas nos mesmos arquivos de log, o que significa que, se uma mensagem não for lida, o arquivo inteiro (geralmente o padrão é 32 MB ou 100 MB, dependendo do adaptador de persistência) não poderá ser limpo. Isso pode causar problemas com pouco espaço em disco ao longo do tempo.
Os intermediários de mensagens clássicos não foram projetados para armazenamento a longo prazo - leia suas mensagens!
Os logs são um mecanismo extremamente eficiente para armazenar e recuperar mensagens, pois o acesso ao disco é seqüencial para ambas as operações. Nos discos rígidos convencionais, isso minimiza o número de pesquisas de disco por cilindros, uma vez que as cabeças no disco simplesmente continuam a ler ou gravar setores no substrato rotativo do disco. Da mesma forma, nos SSDs, o acesso seqüencial é muito mais rápido que o acesso aleatório, pois o primeiro faz melhor uso das páginas de memória da unidade.
Fatores de desempenho do disco
Existem vários fatores que determinam a velocidade com que um disco pode funcionar. Para entender isso, considere o método de gravar em um disco através de um modelo mental simplificado de um tubo (
Figura 2-2 ).
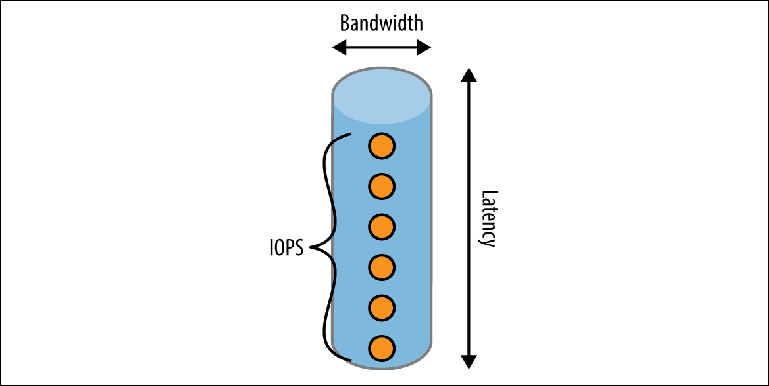 Figura 2-2. Modelo de tubo de desempenho de disco
Figura 2-2. Modelo de tubo de desempenho de discoUm tubo tem três dimensões:
ComprimentoCorresponde à
latência esperada para concluir uma operação. Para a maioria das unidades locais, é muito bom, mas pode se tornar um fator limitante importante em ambientes em nuvem, onde a unidade local está realmente online. Por exemplo, no momento da escrita (abril de 2017), a Amazon garante que a gravação no armazenamento do EBS será "em menos de 2 ms". Se gravarmos sequencialmente, isso fornecerá uma taxa de transferência máxima de 500 registros por segundo.
LarguraDetermina a
capacidade de carga ou largura de banda de uma única operação. Os caches do sistema de arquivos usam essa propriedade combinando muitos registros pequenos em um conjunto menor de operações de gravação maiores executadas no disco.
Largura de banda ao longo do tempoA ideia é apresentada na forma de uma série de eventos que podem estar no canal ao mesmo tempo, expressa por uma métrica chamada
IOPS (o número de operações de E / S por segundo) . O IOPS é comumente usado por fabricantes de armazenamento e provedores de nuvem para medir o desempenho. O disco rígido terá diferentes valores de IOPS em diferentes contextos: se a carga de trabalho consiste principalmente em leitura, gravação ou uma combinação deles e se essas operações são seqüenciais, arbitrárias ou mistas. As medidas de IOPS mais interessantes do ponto de vista do intermediário são operações de leitura e gravação seqüenciais, pois correspondem à leitura e gravação de logs de um log.
A taxa de transferência máxima de um intermediário de mensagens é determinada pela
conquista da primeira dessas restrições, e a configuração do intermediário depende muito da maneira como você interage com os discos. Esse não é apenas um fator de como, por exemplo, o broker está configurado, mas também depende de como os produtores interagem com o broker. Como em tudo relacionado ao desempenho, é necessário testar o broker em uma carga de trabalho representativa (ou seja, o mais próximo possível de mensagens reais) e na configuração de armazenamento real que será usada na PROM. Isso é feito para entender como o sistema se comportará na realidade.
API JMS
Antes de entrarmos nos detalhes de como o ActiveMQ se comunica com os clientes, precisamos primeiro aprender a API JMS. A API define um conjunto de interfaces de programação usadas pelo código do cliente:
ConnectionFactoryEssa é a interface de nível superior usada para estabelecer conexões com o broker. Em um aplicativo de mensagens típico, há apenas uma instância dessa interface. No ActiveMQ, este é um ActiveMQConnectionFactory. No nível superior, esse design informa a localização do intermediário de mensagens, além de detalhes de baixo nível de como interagir com ele. Como o nome indica, ConnectionFactory é o mecanismo pelo qual os objetos de conexão são criados.
LigaçãoEsse é um objeto de longa duração que se assemelha aproximadamente a uma conexão TCP - após a criação, geralmente existe durante todo o ciclo de vida do aplicativo até ser fechado. A conexão é segura para threads e pode funcionar com vários threads simultaneamente. Os objetos de conexão permitem criar objetos de sessão.
SessãoEste é um identificador de fluxo ao interagir com um broker. Os objetos de sessão não são seguros para threads, o que significa que eles não podem ser acessados por vários threads ao mesmo tempo. Session é o principal descritor transacional com o qual o programador pode confirmar e reverter mensagens de reversão se estiver no modo transacional. Usando esse objeto, você cria os objetos Message, MessageConsumer e MessageProducer e também obtém ponteiros (descritores) para os objetos Tópico e Fila.
MessageProducerEssa interface permite enviar uma mensagem ao destinatário.
MessageconsumerEssa interface permite que o desenvolvedor receba mensagens. Existem dois mecanismos de recuperação de mensagens:
- Registre o MessageListener. Essa é a interface do manipulador de mensagens que você implementou, que processará sequencialmente qualquer mensagem emitida pelo broker usando um fluxo.
- Pesquisando mensagens usando o método receive ().
MensagemEssa é provavelmente a estrutura mais importante, pois transfere seus dados. As mensagens no JMS consistem em dois aspectos:
- Metadados da mensagem. A mensagem contém cabeçalhos e propriedades. Tanto isso como isso podem ser considerados como elementos de um mapa. Cabeçalhos são elementos conhecidos definidos pela especificação JMS e disponíveis diretamente por meio da API, como JMSDestination e JMSTimestamp. Propriedades são partes arbitrárias de informações de mensagens configuradas para simplificar o processamento ou roteamento de mensagens sem precisar ler a carga útil da mensagem. Você pode, por exemplo, definir o cabeçalho como AccountID ou OrderType.
- Corpo da mensagem. Na Sessão, vários tipos diferentes de mensagens podem ser criados, dependendo do tipo de conteúdo que será enviado no corpo, sendo os mais comuns o TextMessage para seqüências de caracteres e BytesMessage para dados binários.
Como as filas funcionam: uma história de dois cérebros
Um modelo de trabalho útil, embora impreciso, do ActiveMQ é um modelo de duas metades do cérebro. Uma parte é responsável por receber mensagens do produtor e a outra envia essas mensagens aos consumidores. Os relacionamentos são realmente mais complexos para fins de otimização de desempenho, mas o modelo é suficiente para um entendimento básico.
Enviando mensagens para a fila
Vejamos a interação que ocorre ao enviar uma mensagem.
A Figura 2-3 mostra um modelo simplificado do processo pelo qual as mensagens são recebidas pelo broker. Não corresponde totalmente ao comportamento em cada caso, mas é bastante adequado para obter um entendimento básico.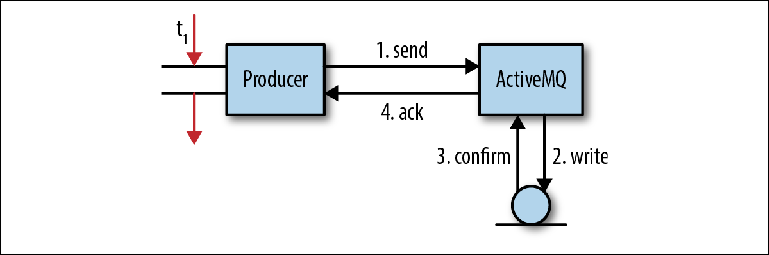 Figura 2-3. Enviando mensagens para JMSEm um aplicativo cliente, um encadeamento recebe um ponteiro para um MessageProducer. Ele cria uma mensagem com uma carga útil estimada da mensagem e chama MessageProducer.send ("orders", message), com a fila como o destino final da mensagem. Como o programador não deseja perder a mensagem se o broker quebrar, o cabeçalho da mensagem JMSDeliveryMode foi configurado como PERSISTENT (comportamento padrão).Neste ponto (1), o fluxo de envio chama a biblioteca cliente e empacota a mensagem no formato OpenWire. Em seguida, a mensagem é enviada ao broker.No intermediário, o fluxo de recebimento remove a mensagem da linha e a remove da distribuição para o objeto interno. Em seguida, o objeto de mensagem é transmitido ao adaptador de persistência, que organiza a mensagem usando o formato Buffers de Protocolo do Google e a grava no armazenamento (2).Após gravar a mensagem no armazenamento, o adaptador de persistência deve receber a confirmação de que a mensagem foi realmente gravada (3). Essa é geralmente a parte mais lenta de toda a interação; mais sobre isso mais tarde.Assim que o corretor garantir que a mensagem foi salva, ele enviará uma resposta de confirmação (4) ao cliente. Depois disso, o encadeamento do cliente que originalmente chamou a operação send () pode continuar seu trabalho.Essa confirmação pendente de mensagens persistentes é a base da garantia fornecida pela API JMS - se você deseja que a mensagem seja salva, provavelmente também é importante para você se a mensagem foi recebida pelo broker em primeiro lugar. Existem várias razões pelas quais isso pode não ser possível, por exemplo, um limite de memória ou disco foi atingido. Em vez de uma falha, o broker suspende a operação de envio, forçando o produtor a aguardar até que recursos suficientes do sistema estejam disponíveis para processar a mensagem (um processo chamado Producer Flow Control), ou ele envia uma confirmação negativa ao produtor, lançando uma exceção. O comportamento exato é personalizável para cada broker.Nesta operação simples, ocorre um número significativo de interações de E / S: duas operações de rede entre o produtor e o broker, uma operação de salvamento e uma etapa de confirmação. A operação de salvamento pode ser uma gravação simples no disco ou outra transição de rede para o servidor de armazenamento.Isso levanta uma questão importante sobre os intermediários de mensagens: o trabalho deles está associado a um fluxo extremamente intenso de operações de E / S e eles são muito sensíveis à infraestrutura usada, principalmente aos discos.Vamos dar uma olhada na etapa de confirmação (3) na interação acima. Se o adaptador de persistência for baseado em arquivo, o armazenamento da mensagem envolverá a gravação no sistema de arquivos. Se sim, por que preciso confirmar que a operação de gravação foi concluída? O ato de concluir uma gravação realmente significa que ocorreu uma gravação?
Figura 2-3. Enviando mensagens para JMSEm um aplicativo cliente, um encadeamento recebe um ponteiro para um MessageProducer. Ele cria uma mensagem com uma carga útil estimada da mensagem e chama MessageProducer.send ("orders", message), com a fila como o destino final da mensagem. Como o programador não deseja perder a mensagem se o broker quebrar, o cabeçalho da mensagem JMSDeliveryMode foi configurado como PERSISTENT (comportamento padrão).Neste ponto (1), o fluxo de envio chama a biblioteca cliente e empacota a mensagem no formato OpenWire. Em seguida, a mensagem é enviada ao broker.No intermediário, o fluxo de recebimento remove a mensagem da linha e a remove da distribuição para o objeto interno. Em seguida, o objeto de mensagem é transmitido ao adaptador de persistência, que organiza a mensagem usando o formato Buffers de Protocolo do Google e a grava no armazenamento (2).Após gravar a mensagem no armazenamento, o adaptador de persistência deve receber a confirmação de que a mensagem foi realmente gravada (3). Essa é geralmente a parte mais lenta de toda a interação; mais sobre isso mais tarde.Assim que o corretor garantir que a mensagem foi salva, ele enviará uma resposta de confirmação (4) ao cliente. Depois disso, o encadeamento do cliente que originalmente chamou a operação send () pode continuar seu trabalho.Essa confirmação pendente de mensagens persistentes é a base da garantia fornecida pela API JMS - se você deseja que a mensagem seja salva, provavelmente também é importante para você se a mensagem foi recebida pelo broker em primeiro lugar. Existem várias razões pelas quais isso pode não ser possível, por exemplo, um limite de memória ou disco foi atingido. Em vez de uma falha, o broker suspende a operação de envio, forçando o produtor a aguardar até que recursos suficientes do sistema estejam disponíveis para processar a mensagem (um processo chamado Producer Flow Control), ou ele envia uma confirmação negativa ao produtor, lançando uma exceção. O comportamento exato é personalizável para cada broker.Nesta operação simples, ocorre um número significativo de interações de E / S: duas operações de rede entre o produtor e o broker, uma operação de salvamento e uma etapa de confirmação. A operação de salvamento pode ser uma gravação simples no disco ou outra transição de rede para o servidor de armazenamento.Isso levanta uma questão importante sobre os intermediários de mensagens: o trabalho deles está associado a um fluxo extremamente intenso de operações de E / S e eles são muito sensíveis à infraestrutura usada, principalmente aos discos.Vamos dar uma olhada na etapa de confirmação (3) na interação acima. Se o adaptador de persistência for baseado em arquivo, o armazenamento da mensagem envolverá a gravação no sistema de arquivos. Se sim, por que preciso confirmar que a operação de gravação foi concluída? O ato de concluir uma gravação realmente significa que ocorreu uma gravação?Na verdade não.
Como geralmente acontece, quanto mais você estuda algo, mais complexo ele se torna. Nesse caso específico, o cache é o culpado .Caches, caches em todos os lugares
Quando um processo do sistema operacional, como um broker, grava dados no disco, ele interage com o sistema de arquivos. Um sistema de arquivos é um processo que abstrai os detalhes da interação com a mídia de armazenamento usada, fornecendo uma API para operações de arquivo como OPEN, CLOSE, READ e WRITE. Uma dessas funções é minimizar o número de operações de gravação armazenando em buffer os dados gravados pelo sistema operacional em blocos que podem ser salvos no disco em uma abordagem. As operações de gravação do sistema de arquivos que parecem interagir com os discos são realmente gravadas nesse cache de buffer .A propósito, é por isso que o seu computador reclama quando você ejeta uma unidade USB com segurança - os arquivos que você copiou podem não ter sido realmente gravados!Assim que os dados ultrapassam o cache do buffer, eles passam para o próximo nível de cache, desta vez no nível do hardware - o cache do controlador de disco . Eles são especialmente importantes para sistemas baseados em RAID e desempenham a mesma função que o cache no nível do sistema operacional: minimize o número de interações necessárias para as próprias unidades. Esses caches se enquadram em duas categorias:gravações de gravaçãosão transferidas para o disco imediatamente após o recebimento.Write-backA gravação é realizada em discos apenas quando o buffer está cheio atinge um certo valor limite.Os dados armazenados nesses caches podem ser facilmente perdidos durante uma falha de energia, porque a memória que eles usam é geralmente volátil (volátil) . Cartões mais caros têm pacotes de bateria redundantes (BBUs) que suportam energia de cache até que todo o sistema possa restaurar a energia, após o que os dados serão gravados no disco.O último nível de cache está nos próprios discos. Caches de discolocalizado em discos rígidos (em discos rígidos padrão e em unidades de estado sólido) e pode ser write-through ou write-back. A maioria das unidades comerciais usa caches de write-back e é volátil, o que novamente significa que os dados podem ser perdidos em caso de falta de energia.Retornando ao intermediário de mensagens, é necessário concluir a etapa de confirmação para garantir que os dados realmente atingiram o disco. Infelizmente, a interação com esses buffers de hardware depende do sistema de arquivos; portanto, tudo o que um processo como o ActiveMQ pode fazer é enviar um sinal ao sistema de arquivos que ele deseja sincronizar todos os buffers do sistema com o dispositivo em uso. Para fazer isso, o broker chama o método java.io.FileDescriptor.sync (), que, por sua vez, inicia a operação POSIX fsync ().Esse comportamento de sincronização é um requisito do JMS para garantir que todas as mensagens marcadas como persistentes sejam realmente salvas no disco e, portanto, executadas após o recebimento de cada mensagem ou conjunto de mensagens relacionadas em uma transação. Portanto, a velocidade na qual um disco pode executar sync () é crítica para o desempenho do broker.Conflitos internos
Usar um log para todas as filas adiciona complexidade extra. A qualquer momento, pode haver vários produtores enviando mensagens simultaneamente. O broker possui vários fluxos que recebem essas mensagens dos soquetes de entrada. Cada encadeamento deve salvar sua mensagem no log. Como vários threads não podem gravar no mesmo arquivo ao mesmo tempo, porque Como os registros entrarão em conflito, os registros deverão ser colocados na fila usando o mecanismo de exclusão mútua. Chamamos esse conflito de thread .Cada mensagem deve ser totalmente registrada e sincronizada antes de processar a próxima mensagem. Essa restrição afeta todas as filas no broker ao mesmo tempo. Assim, a velocidade com que rapidez uma mensagem pode ser recebida é o tempo necessário para gravar no disco, além de qualquer tempo de espera para que outros fluxos concluam a gravação.O ActiveMQ inclui um buffer de gravação, no qual os fluxos de recebimento gravam suas mensagens, aguardando a conclusão da gravação anterior. Em seguida, o buffer é gravado em uma ação quando a mensagem fica disponível. Após a conclusão, os encadeamentos são notificados. Assim, o broker maximiza o uso da largura de banda de armazenamento.Para minimizar o impacto do conflito de encadeamento, os conjuntos de filas podem receber seus próprios logs usando o adaptador mKahaDB. Essa abordagem reduz a latência de gravação, pois a qualquer momento os encadeamentos provavelmente gravam em logs diferentes e não precisam competir entre si pelo acesso exclusivo a um arquivo de log.Transações
A vantagem de usar um único diário para todas as filas é que, do ponto de vista dos autores do corretor, é muito mais fácil implementar transações.Vejamos um exemplo em que várias mensagens são enviadas por um produtor para várias filas. Usar uma transação significa que todo o conjunto de mensagens a serem enviadas deve ser considerado como uma operação atômica. Nessa interação, a biblioteca do cliente ActiveMQ pode fazer algumas otimizações que aumentarão significativamente a velocidade de envio.Na operação mostrada na Figura 2-4, o produtor envia três mensagens, todas em filas diferentes. Em vez da interação usual com o broker, quando cada mensagem é confirmada, o cliente envia todas as três mensagens de forma assíncrona, ou seja, sem aguardar uma resposta. Essas mensagens são armazenadas na memória do broker. Assim que a operação é concluída, o produtor informa suas sessões sobre a necessidade de confirmação, o que por sua vez força o broker a executar um registro grande com uma operação de sincronização.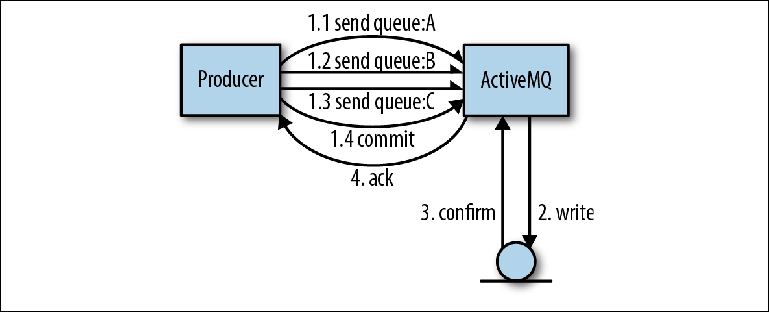 Figura 2-4. Enviando mensagens em transaçõesNesse tipo de operação, o ActiveMQ usa duas otimizações para aumentar a velocidade:
Figura 2-4. Enviando mensagens em transaçõesNesse tipo de operação, o ActiveMQ usa duas otimizações para aumentar a velocidade:- Removendo o tempo de espera antes que o próximo envio pelo produtor seja possível
- Combinando muitas operações de disco pequeno em uma grande - isso permite que você use toda a largura de banda do barramento de disco
Se compararmos isso com a situação em que cada fila é armazenada em seu próprio log, o broker precisará fornecer algo como coordenação de transações entre todos os registros.Subtraindo mensagens da fila
O processo de leitura de mensagens começa quando o consumidor expressa sua vontade de aceitá-las, configurando um MessageListener para processar as mensagens à medida que elas chegam, ou chamando o método MessageConsumer.receive () ( Figura 2-5 ).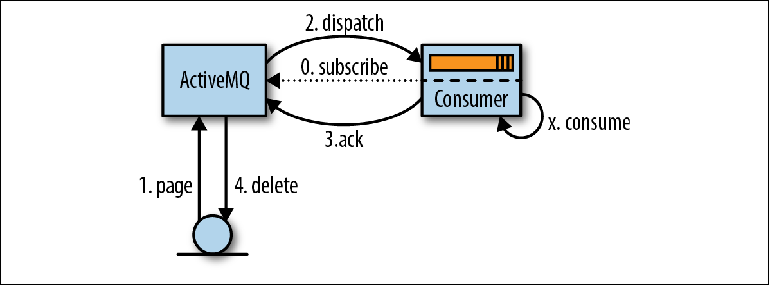 Figura 2-5. Lendo mensagens através do JMSQuando o ActiveMQ toma conhecimento de um consumidor, ele (ActiveMQ) lê (páginas) mensagens página por página, do armazenamento para a memória de distribuição (1). Em seguida, essas mensagens são redirecionadas (despachadas) para o contador (2), geralmente em várias partes para reduzir a quantidade de interação na rede. O intermediário controla quais mensagens foram redirecionadas e para qual consumidor.As mensagens recebidas pelo consumidor não são processadas imediatamente pelo aplicativo, mas são colocadas em uma área de memória conhecida comotampão de pré-busca (tampão de pré-busca) . O objetivo desse buffer é otimizar o fluxo de mensagens para que o broker possa emitir mensagens para o supervisor à medida que elas se tornam disponíveis para envio, enquanto o consumidor pode recebê-las em ordem, uma de cada vez.Em algum momento após entrar no buffer de pré-busca, as mensagens são lidas pela lógica do aplicativo (X) e a confirmação do revisor é enviada ao broker (3). O tempo entre o processamento da mensagem e a confirmação é configurado usando um parâmetro de sessão JMS chamado modo de reconhecimento , que discutiremos um pouco mais adiante.Assim que o broker aceita a confirmação de entrega da mensagem, ela é excluída da memória e do armazenamento de mensagens (4). O termo "exclusão" é um pouco enganador, pois, na realidade, um registro de confirmação é gravado no diário e o índice no índice aumenta. A exclusão real do arquivo de log que contém a mensagem será executada pelo coletor de lixo no encadeamento em segundo plano com base nessas informações.O comportamento descrito acima é uma simplificação para facilitar o entendimento. De fato, o ActiveMQ não apenas lê dados página a página do disco, mas usa o mecanismo do cursor entre as partes de recebimento e redirecionamento do broker para minimizar a interação com o repositório do broker sempre que possível. A paginação, como descrito acima, é um dos modos usados neste mecanismo. Os cursores podem ser visualizados como um cache no nível do aplicativo que precisa ser mantido em sincronia com o repositório do broker. O protocolo de coerência usado é uma parte significativa do que torna o mecanismo de despacho do ActiveMQ muito mais complexo do que o mecanismo Kafka descrito no próximo capítulo.
Figura 2-5. Lendo mensagens através do JMSQuando o ActiveMQ toma conhecimento de um consumidor, ele (ActiveMQ) lê (páginas) mensagens página por página, do armazenamento para a memória de distribuição (1). Em seguida, essas mensagens são redirecionadas (despachadas) para o contador (2), geralmente em várias partes para reduzir a quantidade de interação na rede. O intermediário controla quais mensagens foram redirecionadas e para qual consumidor.As mensagens recebidas pelo consumidor não são processadas imediatamente pelo aplicativo, mas são colocadas em uma área de memória conhecida comotampão de pré-busca (tampão de pré-busca) . O objetivo desse buffer é otimizar o fluxo de mensagens para que o broker possa emitir mensagens para o supervisor à medida que elas se tornam disponíveis para envio, enquanto o consumidor pode recebê-las em ordem, uma de cada vez.Em algum momento após entrar no buffer de pré-busca, as mensagens são lidas pela lógica do aplicativo (X) e a confirmação do revisor é enviada ao broker (3). O tempo entre o processamento da mensagem e a confirmação é configurado usando um parâmetro de sessão JMS chamado modo de reconhecimento , que discutiremos um pouco mais adiante.Assim que o broker aceita a confirmação de entrega da mensagem, ela é excluída da memória e do armazenamento de mensagens (4). O termo "exclusão" é um pouco enganador, pois, na realidade, um registro de confirmação é gravado no diário e o índice no índice aumenta. A exclusão real do arquivo de log que contém a mensagem será executada pelo coletor de lixo no encadeamento em segundo plano com base nessas informações.O comportamento descrito acima é uma simplificação para facilitar o entendimento. De fato, o ActiveMQ não apenas lê dados página a página do disco, mas usa o mecanismo do cursor entre as partes de recebimento e redirecionamento do broker para minimizar a interação com o repositório do broker sempre que possível. A paginação, como descrito acima, é um dos modos usados neste mecanismo. Os cursores podem ser visualizados como um cache no nível do aplicativo que precisa ser mantido em sincronia com o repositório do broker. O protocolo de coerência usado é uma parte significativa do que torna o mecanismo de despacho do ActiveMQ muito mais complexo do que o mecanismo Kafka descrito no próximo capítulo.Modos de confirmação e transação
Vários modos de confirmação, que determinam a ordem entre a revisão e a confirmação, têm um impacto significativo sobre qual lógica precisa ser implementada no cliente. Eles são os seguintes:AUTO_ACKNOWLEDGEEste é o modo mais comumente usado, possivelmente porque possui a palavra AUTO. Esse modo força a biblioteca cliente a reconhecer a mensagem ao mesmo tempo em que a mensagem é lida pela chamada receive (). Isso significa que, se a lógica de negócios iniciada pela mensagem lançar uma exceção, a mensagem será perdida porque já foi excluída no broker. Se a mensagem for lida através do ouvinte, a mensagem será confirmada somente depois que o ouvinte tiver concluído o trabalho com êxito.CLIENT_ACKNOWLEDGEUma confirmação será enviada apenas quando o código do consumidor chamar explicitamente o método Message.acknowledge ().DUPS_OK_ACKNOWLEDGEAqui, as confirmações serão armazenadas em buffer no consumidor antes de enviá-las simultaneamente, a fim de reduzir a quantidade de tráfego de rede. No entanto, se o sistema do cliente for desligado, as confirmações serão perdidas e as mensagens serão reenviadas e processadas pela segunda vez. Portanto, o código deve considerar a probabilidade de mensagens duplicadas.Os modos de confirmação são complementados por ferramentas de leitura transacional. Ao criar uma sessão, ela pode ser marcada como transacional. Isso significa que o programador deve chamar explicitamente Session.commit () ou Session.rollback (). No lado do consumidor, as transações expandem o intervalo de interações que o código pode executar como uma operação atômica. Por exemplo, você pode ler e processar várias mensagens como um todo ou subtrair uma mensagem de uma fila e enviá-la para outra usando o mesmo objeto Session.Expedição e vários consumidores
Até agora, discutimos o comportamento de ler mensagens com um único consumidor. Vamos agora ver como esse modelo é aplicável a vários consumidores.Quando vários consumidores se inscrevem na fila, o comportamento padrão do broker é enviar mensagens de rodízio para os consumidores que têm um lugar nos buffers de pré-busca. As mensagens serão enviadas na ordem em que chegaram na fila - esta é a única garantia FIFO fornecida (primeiro a entrar, primeiro a sair; primeiro a entrar, primeiro a sair).Quando o consumidor desligar repentinamente, todas as mensagens enviadas a ele, mas ainda não confirmadas, serão reenviadas para outro cliente disponível.Isso levanta uma questão importante: mesmo onde as transações do consumidor são usadas, não há garantia de que a mensagem não será processada várias vezes.Considere a seguinte lógica de processamento dentro do consumidor:- A mensagem é subtraída da fila. A transação começa.
- Um serviço da web é chamado com o conteúdo da mensagem.
- A transação está confirmada. Uma confirmação é enviada ao broker.
Se o cliente concluir entre as etapas 2 e 3, a revisão da mensagem já afetou outro sistema chamando o serviço da web. As chamadas de serviço da Web são solicitações HTTP e, como tal, não são transacionais.
Esse comportamento é verdadeiro para todos os sistemas de filas - mesmo que sejam transacionais, eles não podem garantir que não haverá efeitos colaterais ao processar mensagens neles. Depois de examinar o processamento das mensagens em detalhes, podemos dizer com segurança que:
Não existe entrega de mensagens apenas uma vez .As filas fornecem uma garantia de entrega
pelo menos uma vez, e partes sensíveis do código sempre devem considerar a possibilidade de receber mensagens repetidas. Discutiremos mais adiante como um cliente de mensagens pode usar a leitura idempotente para rastrear mensagens que já foram visualizadas e evitar duplicatas.
Classificação da Mensagem
Para um conjunto de mensagens que chegam na ordem de [A, B, C, D] e para dois consumidores C1 e C2, a distribuição normal de mensagens será a seguinte:
C1: [A, C]
C2: [B, D]Como o broker não controla a operação dos processos de leitura e a ordem de processamento é paralela, não é determinística. Se C1 for mais lento que C2, o conjunto inicial de mensagens poderá ser processado como [B, D, A, C].
Esse comportamento pode surpreender os iniciantes que esperam que as mensagens sejam processadas em ordem e, com base nisso, estão desenvolvendo seu próprio aplicativo de mensagens. O requisito de que as mensagens enviadas pelo mesmo remetente sejam processadas em ordem em relação à outra, também conhecido como
ordenação causal , é bastante comum.
Tome o seguinte caso de uso extraído das apostas online como exemplo:
- A conta do usuário está configurada.
- O dinheiro é creditado na conta.
- É feita uma aposta que retira dinheiro da conta.
Aqui faz sentido que as mensagens sejam processadas na ordem em que foram enviadas, para que o estado geral da conta seja levado em consideração. Coisas estranhas podem acontecer se o sistema tentar remover dinheiro de uma conta que não possui fundos. Existem, é claro, maneiras de contornar isso.
O modelo
exclusivo do cliente inclui o envio de todas as mensagens da fila para um cliente. Usando essa abordagem, ao conectar várias instâncias de aplicativos ou threads à fila, eles são assinados usando um parâmetro de destinatário especial:
my.queue?consumer.exclusive=true . Quando você conecta um consumidor monopólio, ele recebe todas as mensagens. Quando o segundo consumidor estiver conectado, ele não receberá nenhuma mensagem até que o primeiro seja desconectado. Esse segundo consumidor é realmente uma reserva quente, enquanto o primeiro consumidor agora receberá mensagens exatamente na ordem em que foram gravadas no diário - em uma ordem causal.
A desvantagem dessa abordagem é que, embora o processamento de mensagens seja consistente, é um gargalo de desempenho, porque todas as mensagens devem ser processadas por um único computador.
Para entender esse caso de uso de maneira mais inteligente, é necessário reconsiderar o problema. Todas as mensagens precisam ser processadas em ordem? No caso de processar lances descritos acima, é necessário processar apenas mensagens relacionadas a uma conta sequencialmente. O ActiveMQ fornece um mecanismo para lidar com essa situação chamada
grupos de mensagens JMS .
Grupos de mensagens é um tipo de mecanismo de particionamento que permite aos produtores distribuir mensagens em grupos que serão processados sequencialmente de acordo com uma chave de negócios. Essa chave de negócios é configurada em uma propriedade de mensagem chamada
JMSXGroupID .
A chave natural no caso de processar lances será o identificador da conta.
Para ilustrar como o envio funciona, considere um conjunto de mensagens que chegam na seguinte ordem:
[(A, Group1), (B, Group1), (C, Group2), (D, Group3), (E, Group2)]
Quando uma mensagem é processada pelo mecanismo de despacho no ActiveMQ e ele vê um
JMSXGroupID que não existia antes, essa chave é atribuída ao consumidor de forma cíclica. A partir de agora, todas as mensagens com essa chave serão enviadas para esse contador.
Aqui, os grupos serão atribuídos entre dois consumidores: C1 e C2, da seguinte maneira:
C1: [Group1, Group3] C2: [Group2]
As mensagens serão redirecionadas e processadas da seguinte maneira:
C2: [B, D] C2: [(C, Group2), (E, Group2)]
Se o consumidor quebrar, todos os grupos atribuídos a ele serão redistribuídos entre os demais consumidores e todas as mensagens não confirmadas serão redirecionadas novamente. Portanto, embora possamos garantir que todas as mensagens relacionadas serão processadas em ordem, não podemos afirmar que elas serão processadas pelo mesmo consumidor.
Alta disponibilidade
O ActiveMQ fornece alta disponibilidade com um master-slave baseado em armazenamento compartilhado. Nesse esquema, dois ou mais intermediários (embora geralmente dois) são configurados em servidores separados e suas mensagens são armazenadas em um armazenamento de mensagens localizado em um local externo. Um armazenamento de mensagens não pode ser usado simultaneamente por várias instâncias de um broker, portanto, sua função secundária (armazém) é atuar como um mecanismo de bloqueio para determinar qual broker obterá acesso exclusivo (
Figura 2-6 ).
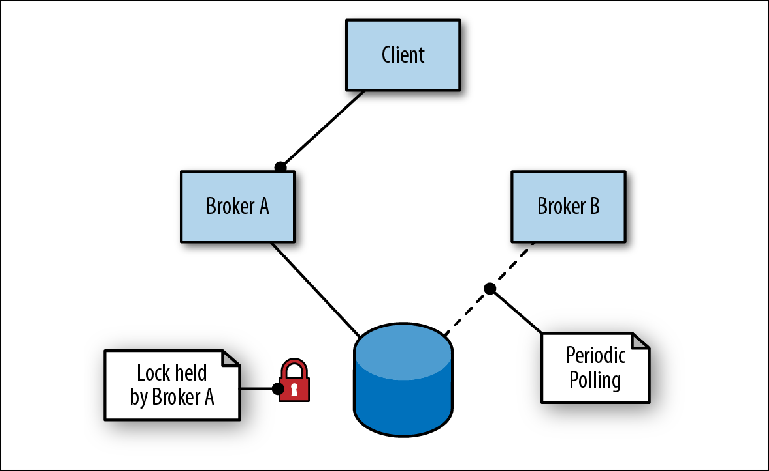 Figura 2-6. O corretor A é o líder; o corretor B está em espera como escravo
Figura 2-6. O corretor A é o líder; o corretor B está em espera como escravoPara conectar-se ao repositório, o primeiro broker (Broker A) assume a função de líder e abre suas portas para o tráfego de mensagens. Quando o segundo broker (Broker B) se conecta ao repositório, ele tenta obter um bloqueio e, como não obtém sucesso, pára por um curto período antes de tentar obter um bloqueio novamente. Isso é chamado de contenção acionada.
Ao mesmo tempo, o cliente alterna os endereços dos dois intermediários na tentativa de se conectar à porta de entrada, conhecida como conector de transporte. Assim que o broker principal se torna disponível, o cliente se conecta à sua porta e pode enviar e ler mensagens.
Quando o Broker A, atuando como líder, falha devido a uma falha no processo (
Figura 2-7 ), ocorrem os seguintes eventos:
- O cliente desconecta e imediatamente tenta se reconectar, alternando os endereços de dois intermediários.
- O bloqueio na mensagem é liberado. O momento disso depende da implementação do armazenamento.
- O corretor B, que estava no modo escravo, periodicamente tentando obter um bloqueio, finalmente consegue e assume o papel de mestre, abrindo suas portas.
- O cliente se conecta ao Broker B e continua seu trabalho.
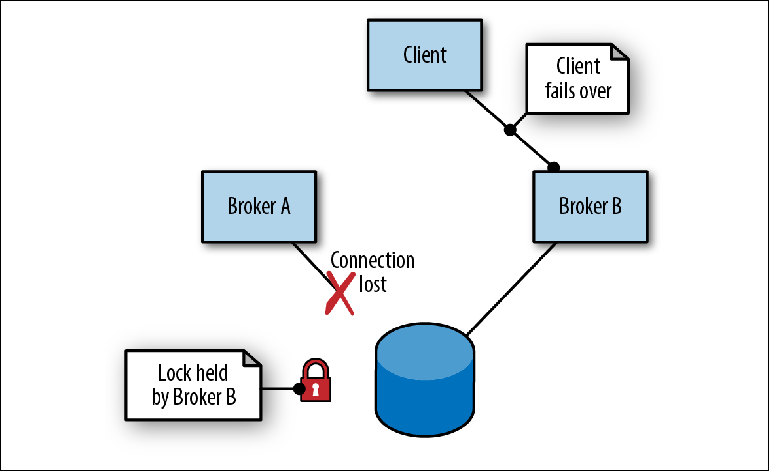 Figura 2-7. O intermediário A termina perdendo a conexão com o repositório. O corretor B assume a liderança
Figura 2-7. O intermediário A termina perdendo a conexão com o repositório. O corretor B assume a liderançaNão é garantido que a lógica de alternância entre vários endereços do broker seja construída na biblioteca do cliente, como é o caso nas implementações JMS / NMS / CMS. Se a biblioteca fornecer apenas reconexão com um único endereço, talvez seja necessário colocar alguns intermediários atrás de um balanceador de carga, que também deve estar altamente disponível.
A principal desvantagem dessa abordagem é que, para simplificar o trabalho de um broker lógico, são necessários vários servidores físicos. Nesse caso, um dos dois servidores do broker está ocioso, aguardando a desconexão do parceiro antes que ele comece a funcionar.
Essa abordagem também possui a complexidade adicional que o armazenamento do broker usado, seja um sistema de arquivos de rede compartilhado ou um banco de dados, também deve ser altamente acessível. Isso gera custos adicionais para equipamentos e administração das configurações do broker. Nesse cenário, é tentador reutilizar repositórios de alta disponibilidade existentes usados por outras partes da infraestrutura, como um banco de dados, mas isso é um erro.
É importante lembrar que o disco é o principal limitador do desempenho geral do broker. Se o próprio disco for usado simultaneamente por um processo diferente do intermediário de mensagens, a interação desse processo com o disco provavelmente diminuirá a gravação do intermediário e, portanto, a velocidade na qual as mensagens podem passar pelo sistema. Essas lentidões são difíceis de diagnosticar e a única maneira de contorná-las é separar os dois processos em diferentes volumes de armazenamento.
Para garantir a operação estável do broker, é necessário um armazenamento dedicado e exclusivo.
Escala vertical e horizontal
Em algum momento da vida do projeto, você pode encontrar uma limitação de desempenho no intermediário de mensagens. Essas limitações geralmente estão relacionadas a recursos, em particular interações do ActiveMQ com o armazenamento usado. Esses problemas geralmente surgem devido a conflitos de volume de mensagens ou largura de banda entre destinatários, por exemplo, quando uma fila excede o broker durante períodos de pico.
Existem várias maneiras de obter mais desempenho da infraestrutura do broker:
- Não use persistência, se não for necessário. Alguns cenários de uso permitem a perda de mensagens durante falhas, especialmente quando um sistema envia outro estado de instantâneo completo para o outro através da fila, periodicamente ou sob demanda.
- Execute o broker em unidades mais rápidas. Em condições reais, foram observadas diferenças significativas na largura de banda de gravação entre o HDD padrão e as alternativas baseadas em memória.
- Faça o melhor uso dos tamanhos de disco. Conforme mostrado no modelo de interação de pipeline de disco descrito acima, é possível obter maior taxa de transferência usando transações para enviar grupos de mensagens, combinando várias operações de gravação em uma maior.
- Use o particionamento de tráfego. Você pode obter maior produtividade dividindo destinos de uma das seguintes maneiras:
- Vários discos em um broker, por exemplo, usando o adaptador de persistência mKahaDB para vários diretórios, cada um dos quais é montado em um disco separado.
- Vários intermediários e o particionamento de tráfego são realizados manualmente pelo aplicativo cliente. O ActiveMQ não fornece nenhuma função nativa para esse fim.
Uma das causas mais comuns de problemas de desempenho do broker é simplesmente uma tentativa de fazer muito com uma instância. Como regra, isso ocorre em situações em que o intermediário é ingenuamente dividido entre vários aplicativos sem levar em conta a carga existente no intermediário ou entender os volumes. Com o tempo, um corretor é carregado cada vez mais até que ele deixa de se comportar adequadamente.
O problema geralmente surge durante a fase de design do sistema, quando o arquiteto do sistema pode propor um esquema como na
Figura 2-8 .
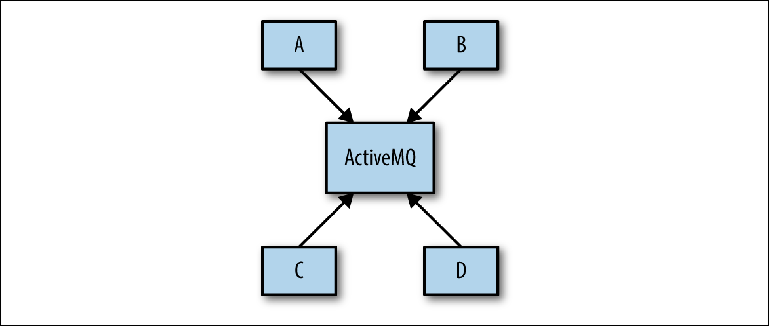 Figura 2-8. Visão conceitual da infraestrutura de mensagens
Figura 2-8. Visão conceitual da infraestrutura de mensagensO objetivo é que vários aplicativos se comuniquem de forma assíncrona por meio do ActiveMQ. O objetivo não é mais especificado e, em seguida, o esquema determina a base da configuração real do broker. Essa abordagem é chamada de Universal Data Pipeline.
Ele não leva em consideração a etapa fundamental da análise entre o projeto conceitual mencionado acima e a implementação física. Antes de prosseguir com a construção de uma configuração específica, é necessário realizar uma análise, que será usada para justificar o projeto físico. A primeira etapa deste processo é determinar quais sistemas interagem entre si - um diagrama bastante simples com retângulos e setas (
Figura 2-9 ).
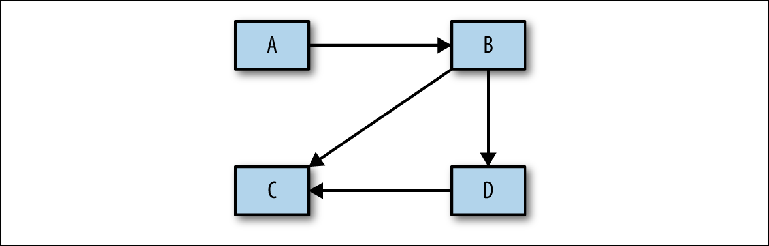 Figura 2-9. Esboçar fluxos de mensagens entre sistemas
Figura 2-9. Esboçar fluxos de mensagens entre sistemasApós a aprovação, você pode acessar os detalhes para responder às seguintes perguntas:
- Quantas filas e tópicos serão usados?
- Quais volumes de mensagens são esperados para cada um deles?
- Qual o tamanho das mensagens em cada destinatário? Mensagens grandes podem causar problemas no processo de paginação, levando a exceder os limites de memória e bloqueando o broker.
- Os fluxos de mensagens serão uniformes ao longo do dia ou haverá picos devido a trabalhos em lote? Lotes grandes em uma fila menos usada podem interferir na gravação oportuna de discos para destinos de alto desempenho.
- Os sistemas estão no mesmo data center ou em diferentes? A comunicação remota envolve algum tipo de agente de rede.
A idéia é definir cenários de mensagens separados que podem ser combinados ou divididos por corretores individuais (
Figura 2-10 ).
Após esse detalhamento, os cenários de uso podem ser simulados combinando-se usando o ActiveMQ Performance Module para identificar quaisquer problemas.
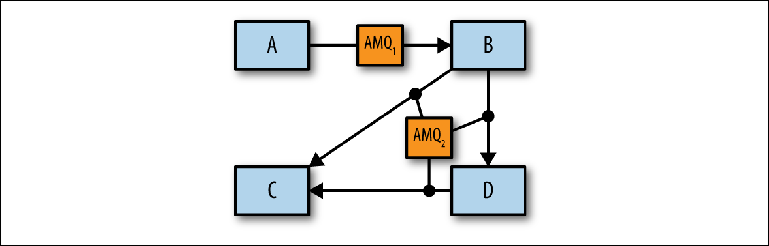 Figura 2-10. Identificação de corretores individuais
Figura 2-10. Identificação de corretores individuaisDepois de determinar o número apropriado de intermediários lógicos, você pode determinar como implementá-los no nível físico usando configurações e redes de intermediários altamente acessíveis.
Sumário
Neste capítulo, examinamos o mecanismo pelo qual o ActiveMQ recebe e distribui mensagens. Discutimos os recursos suportados por essa arquitetura, incluindo balanceamento de carga persistente de mensagens e transações relacionadas. Ao mesmo tempo, introduzimos um conjunto de conceitos comuns a todos os sistemas de mensagens, incluindo protocolos de comunicação e revistas. Também examinamos em detalhes as dificuldades envolvidas na gravação em disco e como os corretores podem usar técnicas como a gravação de pacotes para melhorar o desempenho. Por fim, examinamos como o ActiveMQ pode se tornar altamente disponível e como escalá-lo além dos recursos de um broker individual.
No próximo capítulo, veremos o Apache Kafka e como sua arquitetura redefine o relacionamento entre clientes e corretores para fornecer um pipeline de mensagens incrivelmente robusto com uma largura de banda muitas vezes maior que um corretor de mensagens comum. Discutiremos a funcionalidade usada para atingir esse objetivo e consideraremos brevemente a arquitetura dos aplicativos que fornecem essa funcionalidade.
Próxima parte:
Entendendo os Message Brokers. Aprendendo a mecânica das mensagens através do ActiveMQ e Kafka. Capítulo 3. KafkaTradução concluída: tele.gg/middle_java