Encontrei
um artigo no blog da empresa School of Data e decidi verificar o que a biblioteca Fast.ai é capaz no mesmo conjunto de dados mencionado no artigo. Aqui você não encontrará argumentos sobre a importância de diagnosticar a pneumonia oportuna e corretamente, se os radiologistas serão necessários nas condições de desenvolvimento tecnológico, se a previsão de uma rede neural pode ser considerada um diagnóstico médico etc. O objetivo principal é mostrar que o aprendizado de máquina nas bibliotecas modernas pode ser bastante simples (literalmente requer algumas linhas de código) e fornece excelentes resultados. Vamos lembrar o resultado do artigo (precisão = 0,84, recordação = 0,96) e ver o que acontece conosco.
Levamos os dados para o treinamento a
partir daqui . Os dados são 5856 radiografias distribuídas em duas classes - com ou sem sinais de pneumonia. A tarefa da rede neural é fornecer um classificador binário de alta qualidade de imagens de raios-X para determinar os sinais de pneumonia.
Começamos importando as bibliotecas e algumas configurações padrão:
%reload_ext autoreload %autoreload 2 %matplotlib inline from fastai.vision import * from fastai.metrics import error_rate import os
Em seguida, determine o tamanho do lote. Ao aprender sobre a GPU, é importante escolhê-la de forma que sua memória não esteja cheia. Se necessário, pode ser dividido pela metade.
bs = 64
Atualização importante:Conforme observado corretamente nos comentários abaixo, é importante monitorar claramente os dados nos quais o modelo será treinado e nos quais testaremos sua eficácia. Treinaremos o modelo nas imagens nas pastas train e val e validaremos nas imagens na pasta test, semelhante ao que foi feito
aqui .
Determinamos os caminhos para nossos dados
path = Path('storage/chest_xray') path.ls()
e verifique se todas as pastas estão no lugar (a pasta val foi movida para treinamento):
Out: [PosixPath('storage/chest_xray/train'), PosixPath('storage/chest_xray/test')]
Estamos preparando nossos dados para "carregar" na rede neural. É importante observar que no Fast.ai existem vários métodos para corresponder ao rótulo da imagem. O método from_folder nos diz que os rótulos devem ser retirados do nome da pasta em que a imagem está localizada.
O parâmetro size significa que redimensionamos todas as imagens para um tamanho de 299x299 (nossos algoritmos funcionam com imagens quadradas). A função get_transforms nos fornece aumento de imagem para aumentar a quantidade de dados de treinamento (deixamos as configurações padrão aqui).
np.random.seed(5) data = ImageDataBunch.from_folder(path, train = 'train', valid = 'test', size=299, bs=bs, ds_tfms=get_transforms()).normalize(imagenet_stats)
Vejamos os dados:
data.show_batch(rows=3, figsize=(6,6))
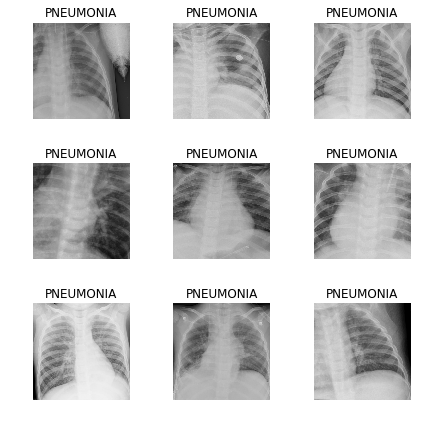
Para verificar, examinamos quais classes recebemos e qual distribuição quantitativa de imagens entre trem e validação:
data.classes, data.c, len(data.train_ds), len(data.valid_ds)
Out: (['NORMAL', 'PNEUMONIA'], 2, 5232, 624)
Definimos um modelo de treinamento baseado na arquitetura Resnet50:
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
e comece a aprender em oito épocas com base na
Política de um ciclo :
learn.fit_one_cycle(8)
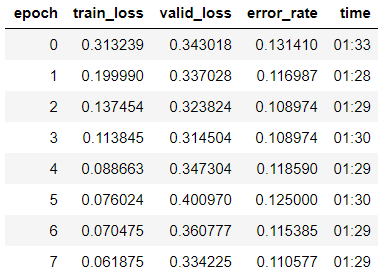
Vimos que já obtivemos uma precisão de 89% na amostra de validação. Anotaremos os pesos do nosso modelo por enquanto e tentaremos melhorar o resultado.
learn.save('step-1-50')
"Descongelar" todo o modelo, porque antes disso, treinamos o modelo apenas no último grupo de camadas e os pesos restantes foram retirados do modelo pré-treinado na Imagenet e “congelado”:
learn.unfreeze()
Estamos buscando a taxa ideal de aprendizado para continuar aprendendo:
learn.lr_find() learn.recorder.plot()
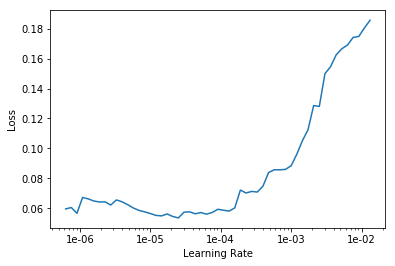
Começamos o treinamento por 10 épocas com diferentes taxas de aprendizado para cada grupo de camadas.
learn.fit_one_cycle(10, max_lr=slice(1e-6, 1e-4))
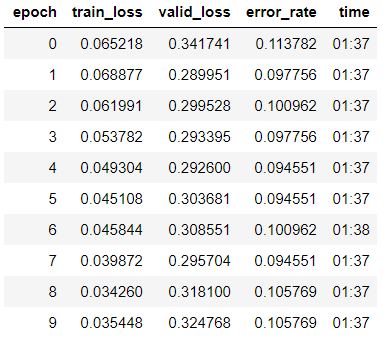
Vemos que a precisão do nosso modelo aumentou ligeiramente para 89,4% na amostra de validação.
Anotamos os pesos.
learn.save('step-2-50')
Criar matriz de confusão:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
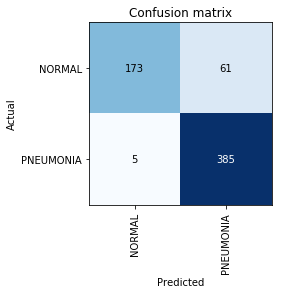
Nesse ponto, lembramos que o parâmetro de precisão por si só é insuficiente, especialmente para classes desequilibradas. Por exemplo, se, na vida real, a pneumonia ocorre apenas em 0,1% das pessoas submetidas a um exame de raios-X, o sistema pode simplesmente dar a ausência de pneumonia em todos os casos e sua precisão estará no nível de 99,9% com absolutamente nenhuma utilidade.
É aqui que as métricas Precision e Recall entram em jogo:
- TP - previsão positiva verdadeira;
- TN - previsão negativa verdadeira;
- FP - previsão de falso positivo;
- FN - Previsão de Falso Negativo.
Vemos que o resultado obtido é ainda um pouco superior ao mencionado no artigo. Em trabalhos adicionais sobre a tarefa, vale lembrar que o Recall é um parâmetro extremamente importante em problemas médicos, porque Os erros de falso negativo são os mais perigosos do ponto de vista dos diagnósticos (o que significa que podemos simplesmente "ignorar" um diagnóstico perigoso).