 Equipamento de laboratório de simulação híbrida. A foto mostra o painel de controle do SDS 9300, que, juntamente com vários computadores analógicos, realizou simulações do módulo de comando e do módulo lunar.
Equipamento de laboratório de simulação híbrida. A foto mostra o painel de controle do SDS 9300, que, juntamente com vários computadores analógicos, realizou simulações do módulo de comando e do módulo lunar.Anos antes da Apollo 11, quando o sistema de controle estava sendo desenvolvido, eles pensavam no software incorporado como algo que poderia ser feito por último: "Hal fará isso", disseram eles. De fato, dezenas de pessoas e centenas de funcionários de suporte estavam fazendo isso, mas Hal Laning primeiro precisou descobrir como organizar as inúmeras funções do software para que elas pudessem ser executadas quase simultaneamente em tempo real no computador de bordo da espaçonave, que tinha tamanho e velocidade limitados. .
A arquitetura de Hal evitou as armadilhas de um sistema operacional no qual os cálculos deveriam ser claramente divididos entre períodos de tempo. Tais sistemas são bastante difíceis de implementar, porque as tarefas podem mudar arbitrariamente. Quando tarefas são adicionadas ou alteradas durante o processo de desenvolvimento, pode ser necessária uma alteração no planejamento da tarefa. O pior é que o sistema operacional existente do computador de bordo é muito frágil, no sentido de que falha completamente se a tarefa levar mais tempo do que o que foi alocado.
Em vez disso, Leining desenvolveu um sistema no qual as funções do programa são distribuídas na forma de "tarefas", que podem ser de qualquer tamanho necessário para executar essas funções. Cada tarefa recebe uma prioridade. O sistema operacional sempre executa a tarefa com a maior prioridade. Se uma tarefa com baixa prioridade for executada e uma tarefa com alta prioridade for atribuída nesse momento, a tarefa com baixa prioridade será suspensa até que a tarefa com alta prioridade seja concluída. Esse sistema nos dá a ilusão de que as tarefas são executadas simultaneamente, embora, na realidade, é claro, as tarefas sejam executadas por sua vez. Esse sistema não é determinístico, mas suas funções são compreensíveis e podem ser verificadas, além de aumentar a confiabilidade, a segurança, a flexibilidade no uso e, em particular, a facilidade de desenvolvimento.
Executive (
o sistema operacional em tempo real AGC e LGC. Aprox. Transl. ) Organizou a execução de tarefas de forma que cada tarefa retivesse seu estado na forma de um conjunto de registros e o estado fosse mantido enquanto a tarefa estivesse sendo executada com alta prioridade. O LGC contém uma matriz de oito conjuntos de 12 registros cada, 15 bits por registro. Um conjunto de registros desse tamanho é suficiente para executar muitas tarefas, mas as tarefas que usam o intérprete (uma
linguagem de interpretação interna para tarefas que operam com números de precisão dupla. Aprox. Transl. ) Para executar cálculos de vetores e matrizes, é necessário mais espaço. Para essas tarefas, uma matriz separada de 43 registros é alocada. O LGC contém cinco desses arrays (Vector Accumulator, VAC).
Com um conjunto tão limitado de matrizes para manter o contexto das tarefas, o lançamento de tarefas para execução deve ser feito com muito cuidado. As funções executadas seqüencialmente uma após a outra foram combinadas em uma tarefa. A grande tarefa do SERVICER esteve ativa durante toda a fase de pouso e outras fases do voo com o motor ligado, e incluiu navegação usando acelerômetros, equações de movimento, controle do acelerador do motor, dados sobre a posição do navio, outros dados no visor e cada um deles. a função usou a saída dos anteriores.
O número de matrizes de registro disponíveis e o VAC limita o número de tarefas que podem ser enfileiradas para execução em oito, das quais até cinco podem usar matrizes de VAC. Durante a operação normal, o número de tarefas em execução permanece constante, embora as tarefas iniciadas para uma única execução ou de forma assíncrona possam causar flutuações na carga do sistema.
No entanto, se o número de tarefas iniciadas for mais do que concluído, o número de matrizes de registro usadas e o VAC aumentará. Se essa situação continuar por um tempo suficientemente longo, o número acabará e a solicitação para iniciar a próxima tarefa não poderá ser atendida.
Voltaremos um ano antes, antes do lançamento do Apollo 11, quando nós, os engenheiros de software, pensávamos que já tínhamos coisas suficientes, e fomos obrigados a escrever um software para pousar na Lua de modo que pudesse literalmente ser desligado e ligado novamente. sem interromper o processo de pouso e outras manobras vitais! Isso foi chamado de "proteção de reinicialização". Além da interferência de energia, outros fatores podem causar a reinicialização do sistema. A reinicialização ocorre se o hardware considerar que o programa travou em um loop infinito ou se ocorreu um erro de paridade ao ler a ROM ou por vários outros motivos.
A proteção de reinicialização foi implementada registrando “pontos de referência” em pontos adequados do programa, organizados de forma que o retorno ao último “ponto de referência” não causasse um erro, conforme mostrado no exemplo a seguir:
NEW_X = X + 1
X = NEW_XObviamente, sem registrar o waypoint, a execução desse código uma segunda vez fará com que o X seja incrementado novamente.
Após a reinicialização, esse programa retoma seu trabalho. Cada tarefa começa com o último waypoint registrado. se várias cópias da mesma tarefa estiverem na fila, somente a última continuará. Algumas tarefas não têm status vital e não estão protegidas contra reinicialização. Eles simplesmente desaparecem.
A proteção de reinicialização funcionou muito bem. No painel de controle do nosso simulador híbrido em Cambridge, havia um botão que causou o reinício do AGC. Ao testar o software, algumas vezes pressionávamos esse botão em momentos aleatórios, quase esperando que a falha nos levasse a outro bug. Invariavelmente, sempre que a proteção contra reinicialização era acionada e o trabalho continuava sem parar.
(O simulador híbrido continha um computador digital SDS 9300 e um computador analógico Beckmann, um computador AGC real e modelos de cockpit realistas para os módulos de comando e lua.)
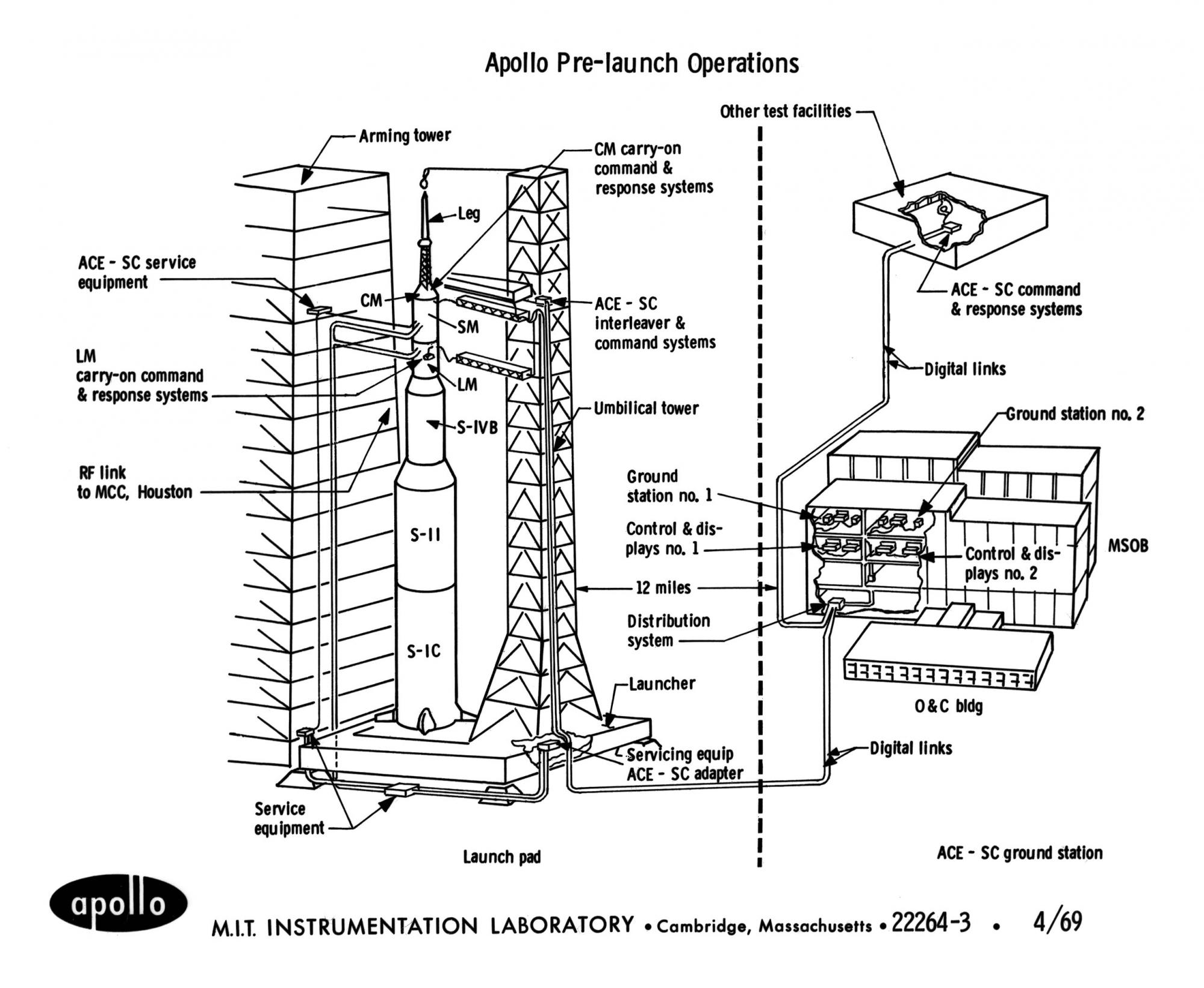 Pré-lançamento da preparação da Apollo.
Pré-lançamento da preparação da Apollo.Não apenas o ferro poderia causar uma reinicialização, como também poderia ser chamado programaticamente se o programa chegasse a um ponto em que o computador não sabia como continuar executando o programa. Isso aconteceu ao transferir o controle sob a tag BAILOUT no módulo Alarmes e interrupções. A chamada foi acompanhada por um código de erro.
Essas ações foram executadas pelo sistema executivo se os recursos fossem esgotados. Se a tarefa não puder ser definida devido ao fato de não haver matrizes livres para salvar registros, o Executive chamou BAILOUT com o código de erro 1202. Se não houvesse VAC livre, o BAILOUT com o código 1201 foi chamado.
Nem todas as funções executadas pelo LGC foram executadas como "tarefas". Além deles, havia interrupções de hardware que podiam ocorrer a qualquer momento (se elas não fossem explicitamente proibidas) que executavam funções de alta prioridade; as interrupções eram atribuídas a determinados dispositivos, incluindo piloto automático digital, "uplink" e "downlink" (
dispositivo de transmissão e recepção) dados no canal de rádio com a Terra. aproximadamente transl. ) e o teclado.
Outras interrupções podem ser usadas para executar trechos de código que devem ser executados em um horário específico. Tais funções foram chamadas de tarefas e foram agendadas em uma sub-rotina chamada WAITLIST. As "tarefas" deveriam ter um prazo de entrega muito curto.
Enquanto “tarefas” foram planejadas para execução com uma certa prioridade, “tarefas” foram planejadas para lançamento em um determinado momento. Tarefas e tarefas eram frequentemente compartilhadas. A tarefa pode ser iniciada para ler as leituras do sensor, que devem ser lidas em um horário estritamente definido, e a tarefa, por sua vez, inicia uma tarefa com uma certa prioridade para o processamento dessas leituras.
Quando Hal Lane projetou Executive e Waitlist em meados da década de 1960, ele fez tudo do zero, sem depender de nenhum exemplo. E seus princípios são verdadeiros hoje. A distribuição de funções por um número limitado de processos assíncronos, sob o controle de um ambiente executivo com multitarefa preventiva com base em intervalos de tempo e prioridades, tudo isso ainda está na base dos modernos sistemas de computadores em tempo real para aplicações espaciais.
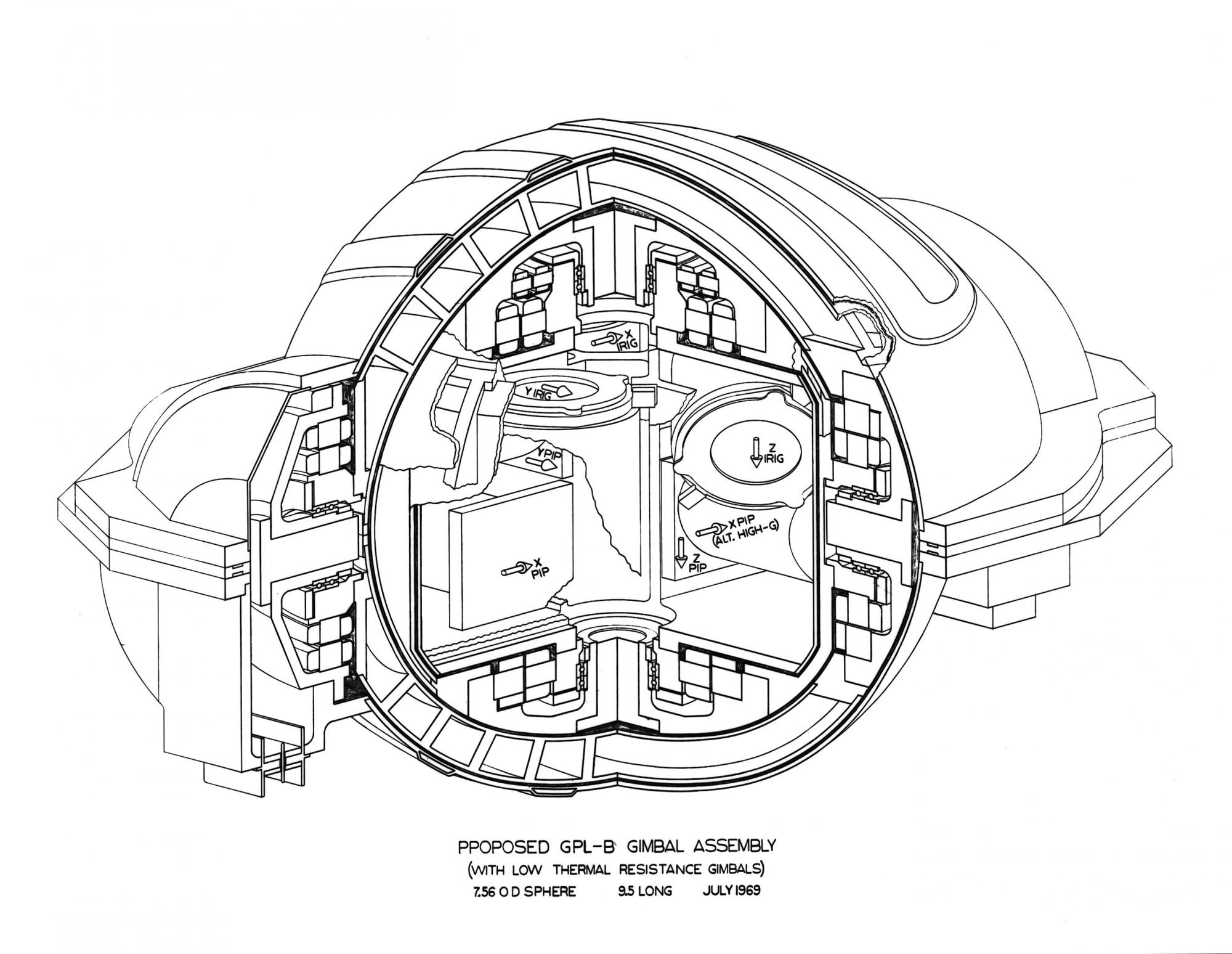 Montagem de giroscópios.
Montagem de giroscópios.* * *
Para entender a causa raiz dos alarmes na Apollo 11 durante a descida, é necessário considerar o procedimento de aproximação com o módulo de comando, que segue após a elevação do módulo lunar da superfície lunar para a órbita lunar. Assim como usamos um radar de pouso para medir altitude e velocidade em relação à superfície lunar ao pousar na Lua, aproximar-se do módulo de comando em órbita lunar exige medir a distância, velocidade e direção em relação à segunda nave usando o radar de aproximação.
O radar de proximidade possui vários modos de operação definidos pelo comutador de modo. Esses modos são os seguintes: SLEW, AUTO e LGC. Nos modos SLEW e AUTO, o radar opera sob controle de comando, independentemente do LGC. Este modo de operação pode ser usado durante a decolagem e a aproximação no caso de uma falha do sistema de navegação principal. No modo SLEW, a antena do radar é guiada manualmente, o resto do tempo está estacionária. Quando a antena está apontada para o alvo, você pode alternar o modo para AUTO (rastreamento automático) e ele rastreará o alvo. O radar de proximidade mede a distância e a velocidade, e os ângulos de rotação dos eixos nos quais a antena gira são exibidos nos displays da cabine e nos indicadores na forma de escalas verticais. Além disso, os dados de distância e velocidade entraram no sistema de orientação de cancelamento (AGS), um computador com apenas 6144 palavras de memória que duplicaram o sistema PGNS principal ao pousar na lua e decolar da lua.
(Os nomes dos três modos de operação do radar de aproximação foram uma fonte de vergonha para alguns comentaristas. A pedido da tripulação, as designações foram alteradas após a missão LM-1 e antes da missão pousar na lua. O modo que a Apollo 11 chamou LGC era anteriormente chamado de AUTO. foi chamado AUTO no Apollo 11, anteriormente chamado MANUAL.O nome do modo SLEW permaneceu inalterado.Embora isso não tenha contribuído para o problema no Apollo 11, a documentação LUMINÁRIA interna na seção referente ao canal discreto 33, na época ainda chamada de re Referência LGC com o radar de proximidade ativado pelo RR AUTO-POWER ON.)
Se o sistema PGNS funcionasse (como realmente era), o LGC controlava o radar; nesse caso, a chave de modo do radar de proximidade estava configurada para LGC. A eletrônica da interface do radar permitiu que o software obtivesse dados sobre a distância e a velocidade medidas pelo radar, bem como os ângulos do eixo de rotação da antena, a partir do qual a direção do alvo pode ser encontrada. O programa LGC usou essas informações para aproximar o LGC do módulo de comando.
Verificou-se que o radar de aproximação também pode funcionar durante a descida, e isso foi feito durante a descida da Apollo 11. As instruções da tripulação exigiam que o radar fosse ligado imediatamente antes do início da fase P63 e permanecesse no modo SLEW ou AUTO durante toda a manobra de pouso.
Muitas explicações foram dadas sobre o motivo pelo qual o radar foi sintonizado dessa maneira para pousar na lua. Por exemplo, algumas pessoas em Houston podem ter considerado um esquema sofisticado de monitoramento de aterrissagem comparando os dados do radar com um gráfico das leituras esperadas. No entanto, há uma explicação mais simples: o radar foi ativado antes do pouso apenas para permanecer aquecido em caso de acidente durante a interrupção e estava no modo AUTOMÁTICO (se o módulo lunar estava em uma posição que permite rastrear o módulo de comando) ou SLEW (em outros momentos), apenas para impedir movimentos inúteis da antena.
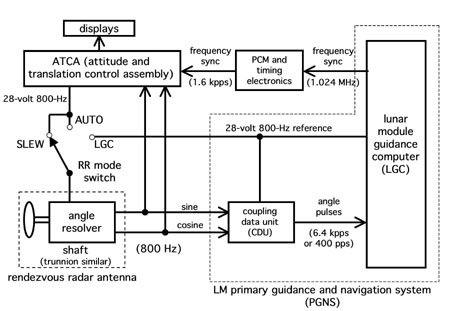
Figura 7.
Interfaces de radar PGNS, ATCA e proximidadeEsse problema costumava ser atribuído (inclusive pelo autor anterior) simplesmente como um erro na lista de verificação. Essa é uma redação imprecisa, assim como é impreciso chamar um desligamento prematuro do monitor
O mecanismo delta-V do módulo lunar é um "erro de computador", enquanto na verdade o erro estava na documentação. De fato, a posição do comutador de radar de proximidade Apollo 11 não deve ter causado problemas. Mas a partir daqui você pode rastrear outro caso de erros na documentação.
Anos antes, a documentação foi escrita no documento de controle de interface (ICD), que define a interface elétrica entre o PGNS e o sistema eletrônico ATCA (conjunto de controle de atitude e tradução), fornecido pela Grumman Aerospace, empresa que construiu o módulo de pouso. O ICD determinou que os circuitos de fonte de alimentação de 28V com uma frequência de 800 Hz em dois sistemas devem estar alinhados em frequência, mas não está escrito que eles devem ser sincronizados em fase. De fato, os dois sistemas estavam alinhados com o sinal de "sincronização de frequência" enviado pela LGC. Eles tinham um relacionamento de fase constante. No entanto, a fase entre as duas tensões era uma variável completamente aleatória, dependendo do momento em que o LGC, que sempre foi acionado após o ACTA, começou a enviar um sinal de sincronização. Essas interfaces são mostradas na fig. 7)
Um problema com a fase de 800 Hz foi detectado ao testar o módulo de pouso LM-3 e está documentado, mas nunca foi corrigido. Como resultado, quando o interruptor do modo de radar estava na posição AUTO ou SLEW, o mecanismo rotativo do radar era excitado por um sinal de 800 Hz do ATCA, que com alta probabilidade não coincide em fase com o sinal de 800 Hz, usado como referência em CDUs que convertem sinais de um mecanismo para transformar dados no computador e diminuir (ou diminuir) os contadores no computador que informam ao programa como a antena é girada.
No Apollo 11, no entanto, as CDUs funcionavam de maneira diferente. Como eles usaram a tensão gerada separadamente como sinal de referência, os sinais do sensor de ângulo da antena recebidos pela CDU mostraram um ângulo desconhecido. O erro era maior se a diferença de fase estivesse próxima de 90 ou 270 graus, e a Apollo 11, obviamente, atingisse um desses pontos interessantes. Em resposta, a CDU começou a aumentar ou diminuir os contadores de LGC a uma velocidade quase constante, cerca de 6400 pulsos por segundo para cada um dos cantos. Isso acontecia toda vez que o interruptor estava no modo SLEW ou AUTO, independentemente de o radar de proximidade estar ligado.
Os contadores de CDU no LGC foram incrementados ou diminuídos por sinais externos que foram processados no computador. Isso consumia tempo, nesse caso, um ciclo de memória de 11,7 µs cada. Se os contadores aumentassem na velocidade máxima, levaria cerca de 15% do tempo total (esse tempo perdido é chamado de TLOSS). Atualmente, estamos fornecendo uma estimativa conservadora do tempo gasto de 13%, o que é consistente com o comportamento observado.
Após o vôo da Apollo 11, os engenheiros da Grumman realizaram testes na tentativa de reproduzir o comportamento do computador observado em vôo. Eles confirmaram que, mesmo no pior caso, as CDUs não podiam enviar pulsos na velocidade máxima. Eles chegaram à conclusão de que a carga máxima do computador com esses medidores (TLOSS) poderia ser de 13,36%. Durante a simulação, foram reproduzidos erros semelhantes aos que ocorreram em voo. Portanto, o valor TLOSS citado é a melhor estimativa documentada da carga do computador Apollo 11. [Clint Tillman, “Simulando a Interface RR-CDU Quando o RR está no modo SLEW ou AUTO (não LGC) no laboratório FMES / FCI”, 9 de agosto 1969]
Sou grato ao especialista em sistema de orientação do módulo lunar George Silver por sua explicação paciente da interface do radar de aproximação do módulo lunar. Ele desempenhou um papel central na missão Apollo 11. No momento do lançamento, ele estava em Cabo Canaveral, depois voou para Boston, para Cambridge, para assumir o dever de monitorar a decolagem da Lua. Ele assistiu a lua pousando em casa na TV em 20 de julho. Ele ouviu os sons dos alarmes, imaginou que algo estava consumindo o tempo do computador e lembrou-se de um caso que ele havia visto enquanto testava os sistemas LM-3, quando o radar de proximidade causava atividade frenética dos contadores. Após algumas análises adicionais da equipe de monitoramento de missões de Cambridge, Silver finalmente entrou em contato com os representantes do MIT em Houston na manhã de 21 de julho, menos de uma hora antes da decolagem da lua.
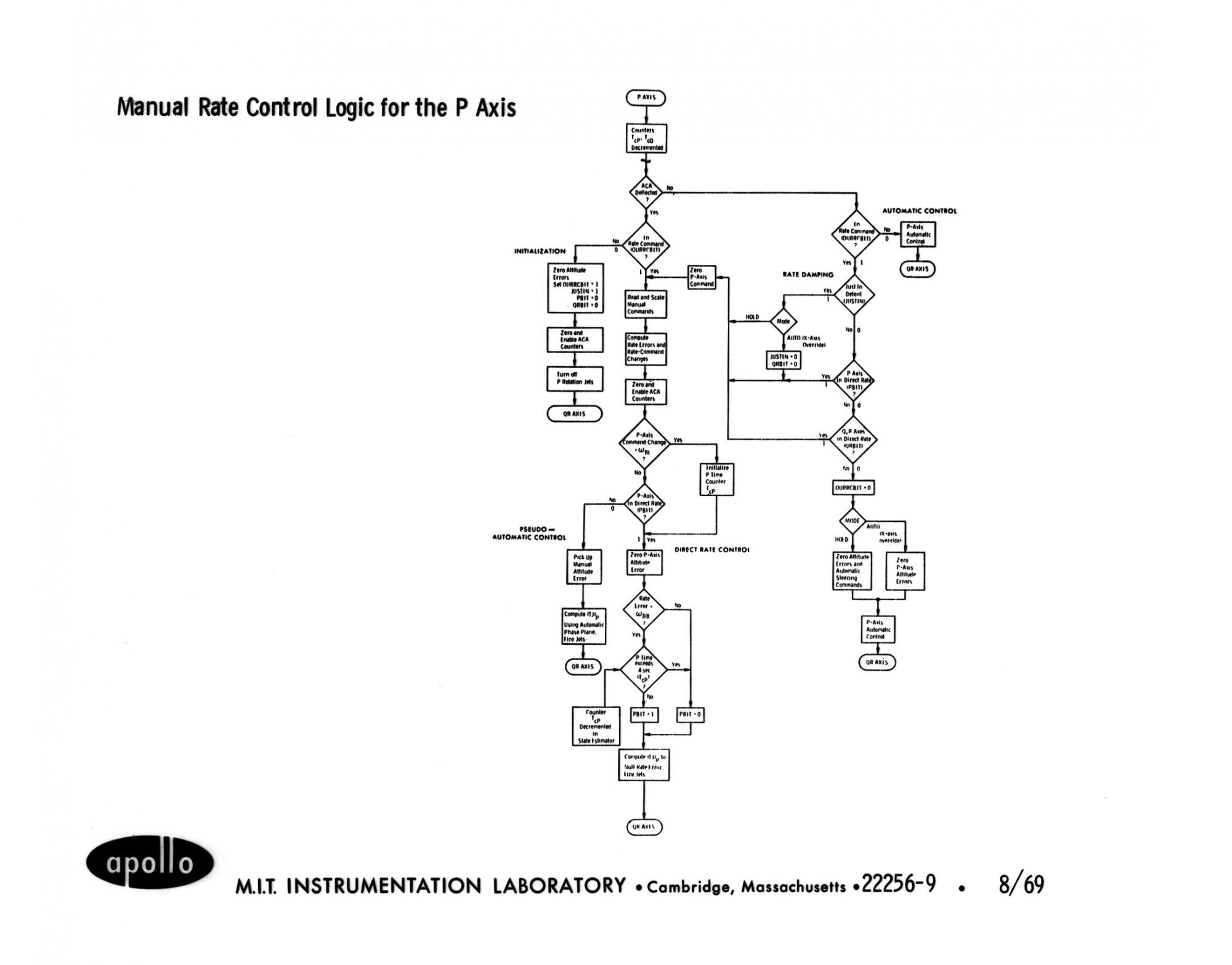 Fragmento de controle manual
Fragmento de controle manual* * *
Aterragem na lua foi a fase mais intensa do voo. O sistema de controle de pouso tinha que atingir uma meta com certas coordenadas, com uma certa velocidade, aceleração, grau de sacudidela (grau de mudança / aceleração). Klumpp chamou a taxa de variação brusca de "snap" e os dois próximos derivativos foram chamados de "crackle" e "pop". Na fase de visibilidade (
ou seja, quando a superfície da lua estava visível em vigia do navio. aprox. transl. ) o programa permitiu à tripulação mudar o local de pouso. O acelerador era controlado continuamente. A navegação incluía medições usando o radar de pouso. A Fig. 8. mostra um perfil de carga típico entre a escolha da fase P63 e o contato com a superfície da lua.

Fig. 8:
Carga durante o pouso (dados do simulador)Mesmo sob essas condições, tentamos tornar nossos programas rápidos o suficiente para ter tempo suficiente no caso de um TLOSS grande. A principal limitação foi o período de dois segundos, que foi incorporado ao programa "G médio" usado durante a fase de vôo.
Esse foi o período durante o qual a tarefa READACCS leu as leituras dos acelerômetros e lançou a tarefa SERVICER, que usou esses valores como dados iniciais para uma nova iteração dos cálculos de trajetória, estrangulando o motor, determinando a posição do navio e exibindo-o no visor. Durante o pouso, o grau de carga do computador simplesmente mostrava quanto tempo era gasto em tarefas e interrupções durante cada período de dois segundos.Durante a fase de frenagem, até que o radar de pouso visse a superfície, o tempo de reserva era de pelo menos 15%. Depois que o radar é colocado em operação, começam os cálculos adicionais, associados à transferência de coordenadas do sistema de referência de radar para o sistema de coordenadas de navegação, o que reduz a margem em 13%. Quando a exibição é iniciada (verbo 16, substantivo 68), a margem diminui para 10% ou menos. Baz Aldrin ficou perceptivo quando disse depois do sinal 1202: "parece que ele apareceu quando entramos em 1668" [16].Quando a margem é de 10% e 13% é retirada, o LGC não tem tempo de processador suficiente para executar todas as funções necessárias. Devido à flexibilidade do design executivo, e ao contrário do que aconteceria com a arquitetura rígida, não houve desastre.Tabela 1. Tarefas ativas ao pousar na lua. A Tabela 1 lista as tarefas que estão ativas ao aterrar o Apollo 11. SERVICER tem a menor prioridade e executa a mais longa. Tarefas de alta prioridade podem interromper o SERVICER, mas possuem um prazo de execução relativamente curto.Como o SERVICER tinha baixa prioridade devido ao seu tamanho grande, ele foi interrompido devido à falta de tempo de computação. Com uma margem negativa no tempo, o SERVICER não conseguiu dar uma resposta quando o READACCS, que começou com um cronograma, começou novamente e iniciou o SERVICER novamente. Como a cópia anterior do SERVICER não terminou o cálculo, não liberou as matrizes de registro e VAC, e o READACCS chamou o FINDVAC para o Executivo para alocar um novo registro e matriz VAC e iniciar o SERVICER. Este SERVICER também não concluiu o trabalho a tempo. Após um curto ciclo dessas operações, as matrizes de registro e VAC foram encerradas. Quando a seguinte solicitação chegou ao Executive, o BAILOUT foi chamado com o código 1201 ou 1202.
A Tabela 1 lista as tarefas que estão ativas ao aterrar o Apollo 11. SERVICER tem a menor prioridade e executa a mais longa. Tarefas de alta prioridade podem interromper o SERVICER, mas possuem um prazo de execução relativamente curto.Como o SERVICER tinha baixa prioridade devido ao seu tamanho grande, ele foi interrompido devido à falta de tempo de computação. Com uma margem negativa no tempo, o SERVICER não conseguiu dar uma resposta quando o READACCS, que começou com um cronograma, começou novamente e iniciou o SERVICER novamente. Como a cópia anterior do SERVICER não terminou o cálculo, não liberou as matrizes de registro e VAC, e o READACCS chamou o FINDVAC para o Executivo para alocar um novo registro e matriz VAC e iniciar o SERVICER. Este SERVICER também não concluiu o trabalho a tempo. Após um curto ciclo dessas operações, as matrizes de registro e VAC foram encerradas. Quando a seguinte solicitação chegou ao Executive, o BAILOUT foi chamado com o código 1201 ou 1202.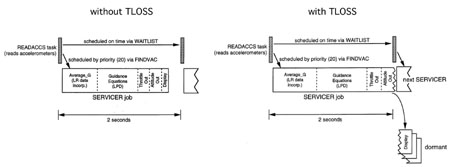 Fig. 9: Operação do SERVICER sem e com o TLOSS
Fig. 9: Operação do SERVICER sem e com o TLOSSFig.
A Figura 9 mostra como o SERVICER se comporta com um TLOSS forte e na fig. A Figura 10 mostra uma comparação dos registradores e conjuntos de VAC durante operação normal e com TLOSS forte, durante o qual ocorre o reinício.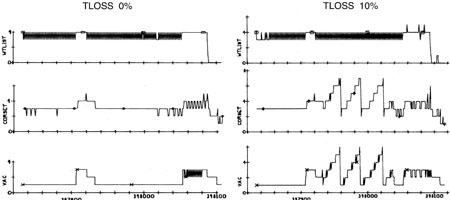
Fig.
10. O efeito produzido pelo TLOSS nos recursos Executive e Waitlist durante o pouso na lua (os dados do simulador começam na fase P63 antes de receber dados de velocidade do radar e terminam no pouso [17].)Um efeito interessante dessa sequência de eventos durante a fase P63 , foi que o problema se eliminou. Uma reinicialização do software restaurou apenas a cópia mais recente da tarefa SERVICER e excluiu todas as cópias incompletas do SERVICER. Além disso, ele concluiu todas as funções que não possuem proteção contra reinicialização porque não são críticas, incluindo o monitor DELTAH (verbo 16, substantivo 68). Isso fez com que o visor mudasse de "substantivo 68" para "substantivo 63" após dois alarmes em P63.O sistema de proteção contra reinicialização foi desenvolvido originalmente devido a possíveis falhas de hardware e proporcionou uma redução na carga computacional com um grande TLOSS. O sistema em tempo real que desenvolvemos acabou sendo tolerante a falhas em determinadas condições.Durante a fase P64, a situação foi diferente. Além das equações usuais de movimento, foi adicionado um processamento adicional que incluía a capacidade de reatribuir o local de pouso. Recursos adicionais de software deixam uma margem de tempo inferior a 10%. Os alarmes continuaram a surgir. Três alarmes de 1201 e 1202 ocorreram em 40 segundos. A cada vez, o software era reiniciado, limpando a fila de tarefas, mas não podia reduzir a carga.Hora da missão 102: 43: 08, antecipando o próximo alarme, Armstrong trocou o piloto automático do modo AUTO para ATT HOLD, enfraquecendo a carga computacional e depois entrou no modo semi-manual P66, no qual a carga do computador era baixa. Após 2 minutos e 20 segundos de manobra na fase P66, o módulo lunar sentou-se.