
Este é um mito bastante comum no campo do hardware do servidor. Na prática, soluções hiperconvergentes (quando tudo em um) precisam muito para quê. Historicamente, as primeiras arquiteturas foram desenvolvidas pela Amazon e Google por seus serviços. Então, a idéia era criar um farm de computação com os mesmos nós, cada um com suas próprias unidades. Tudo isso foi combinado por algum software de formação de sistema (hypervisor) e já estava dividido em máquinas virtuais. A tarefa principal é o mínimo de esforço para manter um nó e o mínimo de problemas de dimensionamento: acabamos de comprar outros mil ou dois dos mesmos servidores e nos conectar nas proximidades. Na prática, esses são casos isolados e, com muito mais frequência, estamos falando de um número menor de nós e de uma arquitetura ligeiramente diferente.
Mas o plus continua o mesmo - a incrível facilidade de dimensionamento e controle. Menos - tarefas diferentes consomem recursos de maneira diferente, e em algum lugar haverá muitos discos locais, em algum lugar haverá pouca RAM e assim por diante, ou seja, com tipos diferentes de tarefas, a utilização de recursos será reduzida.
Descobriu-se que você paga de 10 a 15% a mais pela facilidade de configuração. Isso causou o mito das manchetes. Pesquisamos por um longo tempo em que a tecnologia seria aplicada da melhor maneira possível e a encontramos. O fato é que Tsiska não tinha seus próprios sistemas de armazenamento, mas eles queriam um mercado completo de servidores. E eles criaram o Cisco Hyperflex, uma solução de armazenamento local em nós.
E isso de repente se tornou uma solução muito boa para data centers de backup (recuperação de desastre). Por que e como - agora vou contar. E eu vou mostrar testes de cluster.
Para onde
A hiperconvergência é:
- Transfira discos para nós de computação.
- Integração completa do subsistema de armazenamento com o subsistema de virtualização.
- Transferência / integração com o subsistema de rede.
Essa combinação permite implementar muitos recursos dos sistemas de armazenamento no nível da virtualização e todos em uma janela de controle.
Em nossa empresa, os projetos para projetar datacenters redundantes são muito populares, e muitas vezes é a solução hiperconvergente que é frequentemente escolhida devido ao monte de opções de replicação (até o cluster metro) prontas para uso.
No caso de data centers de backup, geralmente se trata de uma instalação remota em um site do outro lado da cidade ou em outra cidade em geral. Ele permite restaurar sistemas críticos no caso de uma falha parcial ou completa do data center principal. Os dados de vendas são constantemente replicados lá, e essa replicação pode estar no nível do aplicativo ou no nível do dispositivo de bloco (SHD).
Agora, falarei sobre o dispositivo e os testes do sistema e, em seguida, sobre alguns cenários da vida real com dados de economia.
Testes
Nossa cópia consiste em quatro servidores, cada um com 10 discos SSD por 960 GB. Há um disco dedicado para armazenar em cache as operações de gravação e armazenamento da máquina virtual de serviço. A solução em si é a quarta versão. O primeiro é francamente bruto (a julgar pelas críticas), o segundo é úmido, o terceiro já é bastante estável e este pode ser chamado de release após o término do teste beta para o público em geral. Durante o teste dos problemas que não vi, tudo funciona como um relógio.
Alterações na v4Corrigido um monte de bugs.
Inicialmente, a plataforma só funcionava com o hypervisor VMware ESXi e suportava um pequeno número de nós. Além disso, o processo de implantação nem sempre terminava com êxito, eu tinha que reiniciar algumas etapas, havia problemas ao atualizar a partir de versões antigas, os dados na GUI nem sempre eram exibidos corretamente (embora ainda não esteja feliz em exibir gráficos de desempenho), às vezes havia problemas na interface com a virtualização .
Agora que todas as feridas das crianças foram corrigidas, o HyperFlex pode executar o ESXi e o Hyper-V, além disso, é possível:
- Criando um cluster estendido.
- Criando um cluster para escritórios sem usar o Fabric Interconnect, de dois a quatro nós (compramos apenas servidores).
- Capacidade de trabalhar com armazenamento externo.
- Suporte para contêineres e Kubernetes.
- Criação de zonas de acessibilidade.
- Integração com o VMware SRM, se a funcionalidade incorporada não for adequada.
A arquitetura não é muito diferente das decisões dos principais concorrentes, eles não começaram a criar uma bicicleta. Tudo funciona na plataforma de virtualização VMware ou Hyper-V. Hardware hospedado em servidores proprietários do Cisco UCS. Há quem odeie a plataforma pela relativa complexidade da configuração inicial, muitos botões, um sistema não trivial de modelos e dependências, mas há quem tenha aprendido o Zen, inspirado na idéia e não queira mais trabalhar com outros servidores.
Consideraremos a solução especificamente para a VMware, porque a solução foi criada originalmente para ela e tem mais funcionalidade, o Hyper-V foi adicionado ao longo do caminho para acompanhar os concorrentes e atender às expectativas do mercado.
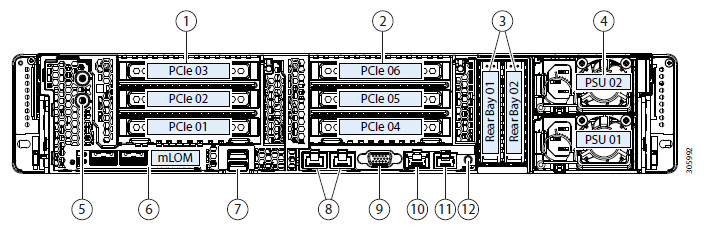
Há um cluster de servidores cheios de discos. Existem discos para armazenamento de dados (SSD ou HDD - conforme seu gosto e necessidade), há um disco SSD para armazenamento em cache. Quando os dados são gravados no armazenamento de dados, os dados são salvos na camada de armazenamento em cache (disco SSD dedicado e RAM da VM de serviço). Paralelamente, o bloco de dados é enviado para os nós no cluster (o número de nós depende do fator de replicação do cluster). Após a confirmação de todos os nós sobre a gravação bem-sucedida, a confirmação da gravação é enviada ao hipervisor e depois à VM. Os dados gravados em segundo plano são deduplicados, compactados e gravados em discos de armazenamento. Ao mesmo tempo, um bloco grande é sempre gravado nos discos de armazenamento e sequencialmente, o que reduz a carga nos discos de armazenamento.
A desduplicação e a compactação estão sempre ativadas e não podem ser desativadas. Os dados são lidos diretamente dos discos de armazenamento ou do cache da RAM. Se uma configuração híbrida for usada, a leitura também será armazenada em cache no SSD.
Os dados não estão vinculados ao local atual da máquina virtual e são distribuídos igualmente entre os nós. Essa abordagem permite carregar igualmente todas as unidades e interfaces de rede. O óbvio menos implora: não podemos minimizar o atraso da leitura, pois não há garantia de disponibilidade de dados localmente. Mas acredito que este é um sacrifício insignificante em comparação com as vantagens recebidas. Além disso, os atrasos na rede atingiram tais valores que praticamente não afetam o resultado geral.
Por toda a lógica do subsistema de disco, uma VM de serviço especial do controlador Cisco HyperFlex Data Platform é responsável, criada em cada nó de armazenamento. Em nossa configuração de VM de serviço, oito vCPUs e 72 GB de RAM foram alocados, o que não é tão pequeno. Deixe-me lembrá-lo de que o host em si possui 28 núcleos físicos e 512 GB de RAM.
A VM de serviço tem acesso aos discos físicos diretamente encaminhando o controlador SAS para a VM. A comunicação com o hypervisor ocorre por meio de um módulo IOVisor especial, que intercepta operações de E / S e usando um agente que permite transferir comandos para a API do hypervisor. O agente é responsável por trabalhar com os instantâneos e clones do HyperFlex.
No hypervisor, os recursos de disco são montados como uma bola NFS ou SMB (dependendo do tipo de hypervisor, adivinhe qual). Além disso, esse é um sistema de arquivos distribuído que permite adicionar recursos de sistemas de armazenamento completos para adultos: alocação de volume fino, compactação e desduplicação, instantâneos usando a tecnologia Redirect-on-Write, replicação síncrona / assíncrona.
A VM de serviço fornece acesso à interface WEB do gerenciamento do subsistema HyperFlex. Há integração com o vCenter, e a maioria das tarefas diárias pode ser executada a partir dele, mas os armazenamentos de dados, por exemplo, são mais convenientes para cortar a partir de uma webcam separada se você já tiver mudado para uma interface rápida HTML5 ou usar um cliente Flash completo com integração total. Na webcam de serviço, você pode ver o desempenho e o status detalhado do sistema.
Há outro tipo de nó em um cluster - nós computacionais. Pode ser servidores em rack ou blade sem unidades internas. Nesses servidores, você pode executar VMs cujos dados são armazenados em servidores com discos. Do ponto de vista do acesso a dados, não há diferença entre os tipos de nós, porque a arquitetura envolve abstrair da localização física dos dados. A proporção máxima de nós de computação e de armazenamento é 2: 1.
O uso de nós computacionais aumenta a flexibilidade ao dimensionar recursos de cluster: não precisamos comprar nós com discos se precisarmos apenas de CPU / RAM. Além disso, podemos adicionar uma cesta blade e economizar espaço no servidor em rack.
Como resultado, temos uma plataforma hiperconvergente com os seguintes recursos:
- Até 64 nós em um cluster (até 32 nós de armazenamento).
- O número mínimo de nós em um cluster é três (dois para um cluster de borda).
- Mecanismo de redundância de dados: espelhamento com fator de replicação 2 e 3.
- Cluster Metro.
- Replicação de VM assíncrona para outro cluster HyperFlex.
- Orquestração de alternar VMs para um data center remoto.
- Instantâneos nativos usando a tecnologia Redirect-on-Write.
- Até 1 PB de espaço utilizável com fator de replicação 3 e sem deduplicação. Não levamos em consideração o fator de replicação 2, pois essa não é uma opção para vendas sérias.
Outra grande vantagem é a facilidade de gerenciamento e implantação. Todas as complexidades da configuração de servidores UCS são tratadas por uma VM especializada preparada pelos engenheiros da Cisco.
Configuração do Testbed:
- 2 x Cisco UCS Fabric Interconnect 6248UP como um cluster de gerenciamento e componentes de rede (48 portas operando no modo Ethernet 10G / FC 16G).
- Quatro servidores Cisco UCS HXAF240 M4.
Recursos do servidor:
Mais opções de configuraçãoAlém do ferro selecionado, as seguintes opções estão disponíveis no momento:
- HXAF240c M5.
- Um ou dois CPUs que variam de Intel Silver 4110 a Intel Platinum I8260Y. A segunda geração está disponível.
- 24 slots de memória, slats de 16 GB RDIMM 2600 a 128 GB LRDIMM 2933.
- De 6 a 23 discos para dados, um disco de cache, um sistema e um disco de inicialização.
Unidades de capacidade- HX-SD960G61X-EV 960GB de 2,5 polegadas Enterprise Value 6G SATA SSD (resistência 1X) SAS 960 GB.
- HX-SD38T61X-EV 3,8 TB Enterprise Value de 2,5 polegadas SSD SATA 6G (resistência 1X) SAS 3,8 TB.
- Armazenando em cache drivers
- HX-NVMEXPB-I375 375GB Unidade Optane Intel de 2,5 polegadas, desempenho e resistência extremos.
- HX-NVMEHW-H1600 * 1,6 TB Ent de 2,5 polegadas Perf NVMe SSD (resistência 3X) NVMe 1,6 TB.
- HX-SD400G12TX-EP 400GB 2,5 polegadas Ent. Perf SSD 12G SAS (resistência 10X) SAS 400 GB.
- HX-SD800GBENK9 ** Ent de 800 GB de 2,5 polegadas Perf SSD SAS SED 12G (resistência 10X) SAS 800 GB.
- HX-SD16T123X-EP 1.6 TB SSD SAS de 12G com desempenho corporativo de 2,5 polegadas (resistência 3X).
Unidades de Sistema / Log- HX-SD240GM1X-EV 240GB 2,5 polegadas Enterprise Value 6G SATA SSD (Requer atualização).
Drivers de inicialização- HX-M2-240GB SSD de 240GB SATA M.2 SATA de 240 GB.
Conexão a uma rede nas portas Ethernet 40G, 25G ou 10G.
Como FI pode ser HX-FI-6332 (40G), HX-FI-6332-16UP (40G), HX-FI-6454 (40G / 100G).
Teste em si
Para testar o subsistema de disco, usei o HCIBench 2.2.1. Este é um utilitário gratuito que permite automatizar a criação de carga a partir de várias máquinas virtuais. A carga em si é gerada por fio regular.
Nosso cluster consiste em quatro nós, fator de replicação 3, todas as unidades Flash.
Para teste, criei quatro datastores e oito máquinas virtuais. Para testes de gravação, supõe-se que o disco de armazenamento em cache não esteja cheio.
Os resultados do teste são os seguintes:
Os valores em negrito são indicados, após os quais não há aumento na produtividade, às vezes até a degradação é visível. Devido ao fato de nos basearmos no desempenho da rede / controladores / unidades.- Leitura sequencial 4432 MB / s.
- Gravação sequencial 804 MB / s.
- Se um controlador falhar (falha na máquina virtual ou no host), o rebaixamento do desempenho será dobrado.
- Se a unidade de armazenamento falhar, o rebaixamento será de 1/3. O disco Rebild consome 5% dos recursos de cada controlador.
Em um pequeno bloco, encontramos o desempenho do controlador (máquina virtual), sua CPU é 100% carregada, enquanto aumenta o bloco em que executamos a largura de banda da porta. 10 Gbps não é suficiente para desbloquear o potencial do sistema AllFlash. Infelizmente, os parâmetros do suporte de demonstração fornecido não permitem a verificação do trabalho em 40 Gb / s.
Na minha impressão dos testes e do estudo da arquitetura, devido ao algoritmo que coloca os dados entre todos os hosts, obtemos um desempenho previsível e escalável, mas isso também é uma limitação na leitura, pois seria possível extrair mais dos discos locais e mais, aqui para salvar uma rede mais produtiva, por exemplo, FIs de 40 Gbps estão disponíveis.
Além disso, um disco para armazenamento em cache e desduplicação pode ser uma limitação; de fato, nesse suporte, podemos escrever em quatro discos SSD. Seria ótimo poder aumentar o número de discos em cache e ver a diferença.
Uso real
Duas abordagens podem ser usadas para organizar um data center de backup (não consideramos colocar o backup em um site remoto):
- Passivo ativo Todos os aplicativos estão hospedados no data center principal. A replicação é síncrona ou assíncrona. No caso de uma queda no data center principal, precisamos ativar o backup. Isso pode ser feito manualmente / scripts / aplicativos de orquestração. Aqui, obtemos um RPO proporcional à frequência de replicação, e o RTO depende da reação e das habilidades do administrador e da qualidade do desenvolvimento / depuração do plano de comutação.
- Ativo Ativo Nesse caso, apenas a replicação síncrona está presente, a disponibilidade dos data centers é determinada por um quorum / árbitro, colocado estritamente na terceira plataforma. RPO = 0 e o RTO pode atingir 0 (se o aplicativo permitir) ou igual ao tempo de failover de um nó em um cluster de virtualização. No nível da virtualização, é criado um cluster estendido (Metro) que requer armazenamento ativo-ativo.
Normalmente, vemos com os clientes uma arquitetura já implementada com armazenamento clássico no data center principal, portanto projetamos outra para replicação. Como mencionei, o Cisco HyperFlex oferece replicação assíncrona e a criação de um cluster de virtualização estendido. Ao mesmo tempo, não precisamos de um sistema de armazenamento de gama média ou superior dedicado com as caras funções de replicação e acesso de dados ativo-ativo em dois sistemas de armazenamento.
Cenário 1: Temos data centers primários e de backup, uma plataforma de virtualização no VMware vSphere. Todos os sistemas produtivos estão localizados principalmente no data center, e a replicação da máquina virtual é realizada no nível do hipervisor, o que permitirá não manter as VMs ativadas no data center de backup. Nós replicamos bancos de dados e aplicativos especiais com ferramentas internas e mantemos as VMs ativadas. Se o data center principal falhar, iniciaremos o sistema no data center de backup. Acreditamos que temos cerca de 100 máquinas virtuais. Enquanto o data center principal estiver em operação, os ambientes de teste e outros sistemas poderão ser iniciados no data center de backup, que poderá ser desativado se o data center principal for alternado. Também é possível usar a replicação bidirecional. Do ponto de vista do equipamento, nada mudará.
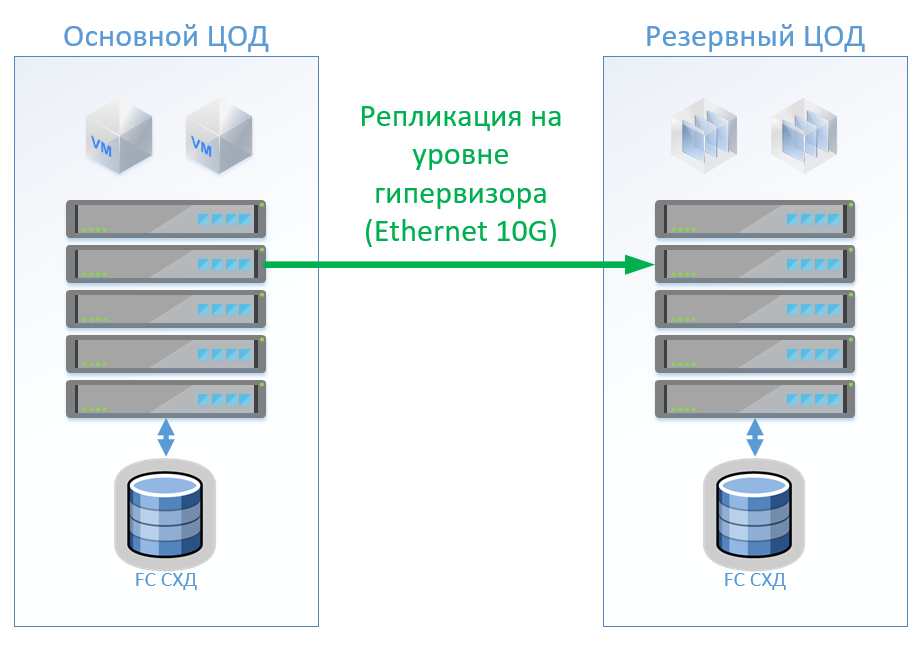
No caso da arquitetura clássica, colocaremos um sistema de armazenamento híbrido em cada data center com acesso via FibreChannel, lacrimejamento, desduplicação e compactação (mas não on-line), 8 servidores por site, 2 switches FibreChannel e Ethernet 10G. Para controle de replicação e comutação em uma arquitetura clássica, podemos usar as ferramentas VMware (Replication + SRM) ou ferramentas de terceiros que serão um pouco mais baratas e às vezes mais convenientes.
A figura mostra um diagrama.
Se você usa o Cisco HyperFlex, obtém a seguinte arquitetura:
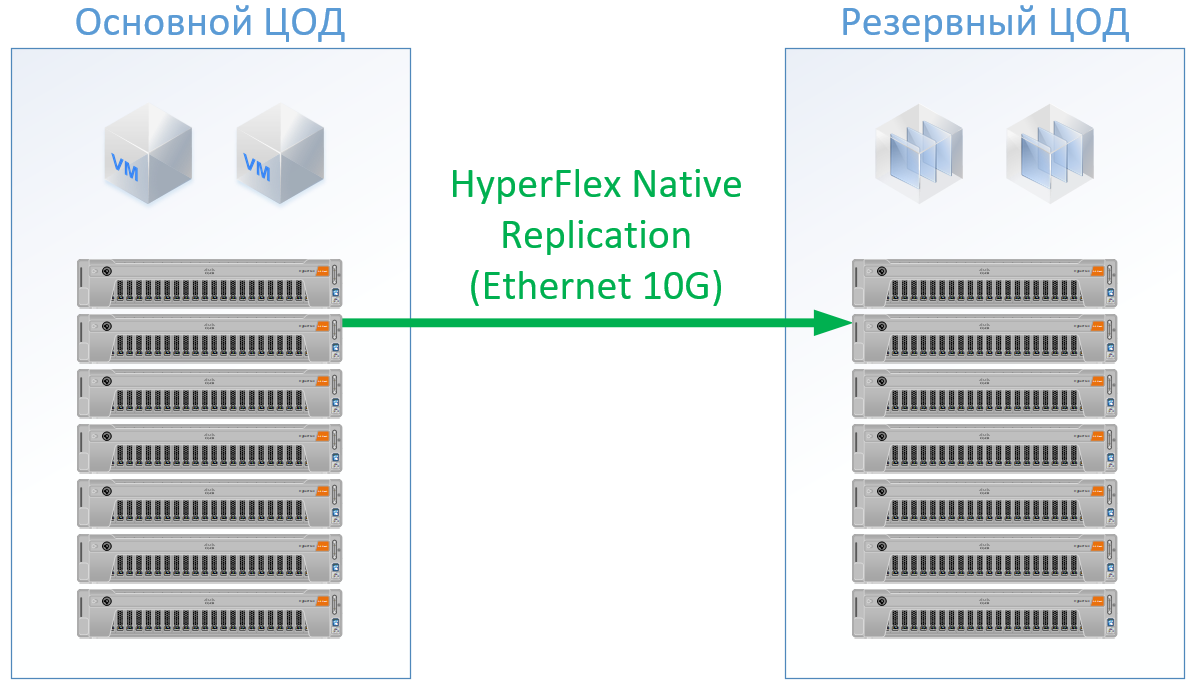
Para o HyperFlex, usei servidores com grandes recursos de CPU / RAM, como parte dos recursos irá para a VM do controlador HyperFlex, até recarreguei um pouco a configuração do HyperFlex na CPU e na memória para não jogar ao lado da Cisco e garantir recursos para o restante das VMs. Mas podemos recusar os comutadores FibreChannel e não precisamos de portas Ethernet para cada servidor, o tráfego local é alternado dentro do FI.
O resultado é a seguinte configuração para cada data center:
Para o Hyperflex, não prometi licenças de software de replicação, pois elas estão disponíveis imediatamente.
Para a arquitetura clássica, peguei um fornecedor que se estabeleceu como um fabricante de qualidade e baixo custo. Para as duas opções, usei um padrão para um skid de solução específico; na saída, obtive preços reais.
A solução no Cisco HyperFlex foi 13% mais barata.
Cenário 2: criando dois data centers ativos. Nesse cenário, projetamos um cluster estendido no VMware.
A arquitetura clássica consiste em servidores de virtualização, SAN (protocolo FC) e dois sistemas de armazenamento que podem ler e gravar no estendido entre eles. Em cada SHD, colocamos uma capacidade útil para a trava.
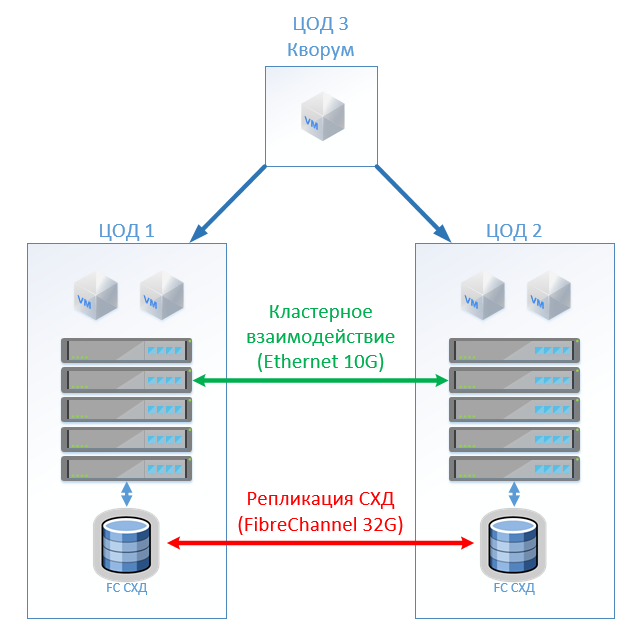
No HyperFlex, simplesmente criamos um Stretch Cluster com o mesmo número de nós nos dois sites. Nesse caso, o fator de replicação 2 + 2 é usado.
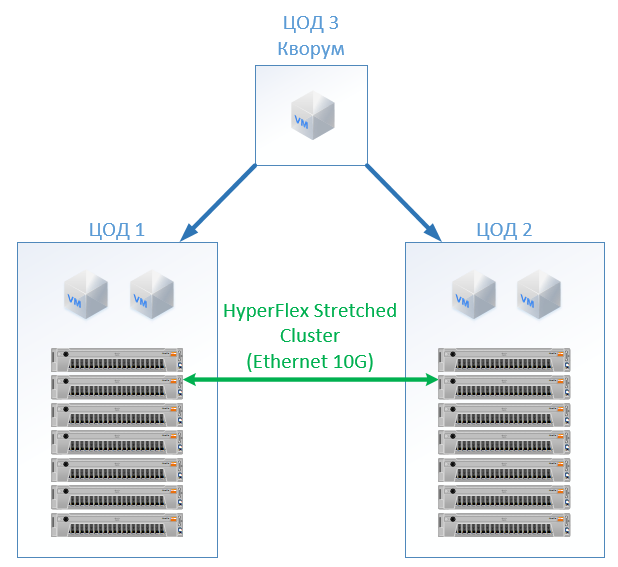
A seguinte configuração acabou:
Em todos os cálculos, não levei em consideração a infraestrutura de rede, os custos do data center, etc .: eles serão os mesmos para a arquitetura clássica e para a solução HyperFlex.
No custo, o HyperFlex acabou por ser 5% mais caro. Vale a pena notar aqui que, para os recursos de CPU / RAM, recebi um viés para a Cisco, porque na configuração ela preencheu os canais dos controladores de memória uniformemente. , , , « », . , Cisco UCS .
SAN , - , (, , — ), ( ), .
, — Cisco. Cisco UCS, , HyperFlex , . , . : « , ?» « - , . !» — , : « » .
Referências