
Olá Habr! Continuamos a publicar resenhas de artigos científicos de membros da comunidade Open Data Science no canal #article_essense. Se você deseja recebê-los antes de todos os outros - participe da comunidade !
Artigos para hoje:
- Equações diferenciais ordinárias neurais (Universidade de Toronto, 2018)
- Aprendizado semi-não supervisionado com modelos geradores profundos: agrupamento e classificação usando rótulos ultra escassos (Universidade de Oxford, The Alan Turing Institute, Londres, 2019)
- Descobrindo e mitigando o viés algorítmico por meio da estrutura latente aprendida (Massachusetts Institute of Technology, Harvard University, 2019)
- Aprendizado de reforço profundo a partir de preferências humanas (OpenAI, DeepMind, 2017)
- Explorando redes neurais com fio aleatório para reconhecimento de imagens (Facebook AI Research, 2019)
- Photofeeler-D3: uma rede neural com modelagem de eleitores para namorar fotos (Photofeeler Inc., 2019)
- MixMatch: uma abordagem holística do aprendizado semi-supervisionado (Google Reasearch, 2019)
- Divida e conquiste o espaço de incorporação para o aprendizado métrico (Universidade de Heidelberg, 2019)
Links para coleções anteriores da série: 1. Equações diferenciais ordinárias neurais
Autores: Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud (Universidade de Toronto, 2018)
→ Artigo original
O autor da resenha: George Ignatov (na folga a2dy2n7okhtp)
Prêmio NIPS de Melhor Artigo

Os autores do artigo observaram que as redes do tipo ResNet são muito semelhantes ao método de Euler para resolver equações diferenciais. Nesse caso, por que não levar a idéia ao máximo imediatamente: imagine uma rede neural na forma de uma equação diferencial e obtenha
- Uma rede com um número arbitrário de camadas, que pode ser alterado a qualquer momento durante o treinamento e a inferência. Mais camadas -> mais precisão e conversões mais suaves (e vice-versa).
- Um número muito menor de parâmetros, portanto, reduz os custos de memória.
NODE através de analogias:
- - é assim que a definição de saída da camada n em uma rede semelhante a resnet parece, W - parâmetros.
- - isso pareceria uma rede semelhante ao NODE, desde que n seja uma quantidade discreta.
- , - método de Euler.
- - ta-da! Rede neural alimentada por ODE.
Nós o resolvemos com qualquer resolvedor ODE de caixa preta, jogamos os gradientes usando o método de sensibilidade adjacente (Pontryagin et al., 1962). Devido à sua completa diferenciabilidade, o NODE pode ser combinado com redes neurais convencionais. Os autores publicaram o código no pytorch.
O artigo discute três aplicativos:
- Comparação com a arquitetura do tipo ResNet (no MNIST). O NODE funciona quase não pior, enquanto usa três vezes menos parâmetros.
- Substituindo fluxos normalizados pelo NODE - Fluxos Normalizados Contínuos (conjunto de dados sintético). O novo modelo reduz os custos de computação de O (n_hidden_units ^ 3) para linear.
- Modelagem de eventos temporários com observações irregulares (conjunto de dados sintéticos). Um conjunto de dados de trajetórias espirais foi gerado a partir dos quais os pontos amostrados aleatoriamente polvilharam com: salt: ruído gaussiano para plausibilidade. Ele testou o RNN e o NODE usuais, e o segundo novamente provou ser melhor.
Em letras pequenas:
- O treinamento de minibatch causa algum tipo de sobrecarga computacional, mas os autores argumentam que, na prática, isso é quase invisível.
- Aparecem dois novos hiperparâmetros: profundidade da rede e tolerância a erros ao resolver o ODE.
- Para que a solução ODE permaneça única, a rede deve ter pesos finitos e usar não-linearidades de Lipshitz, como tanh ou relu.
Link para uma visão geral mais detalhada sobre habr.
2. Aprendizado semissupervisionado com modelos geradores profundos: agrupamento e classificação usando rótulos ultra escassos
Autores do artigo: Matthew Willetts, Stephen Roberts e Christopher Holmes
(Universidade de Oxford, Instituto Alan Turing, Londres, 2019)
→ Artigo original
Autor do comentário: Alex Chiron (em sliron shiron8bit)
Os autores consideram um caso semissupervisionado para o problema de classificação, quando parte das classes presentes na marcação devido ao viés de seleção não foi rotulada, e poucas foram rotuladas de acordo com as classes de dados conhecidas. Isso cria problemas adicionais, já que a maioria dos modelos geralmente funciona no modo semi-supervisionado / supervisionado (classificação) ou no modo não supervisionado (clustering) e, nesse caso, precisamos considerar as duas opções. Além disso, o uso de algoritmos semi-supervisionados pode levar ao fato de que dados não alocados serão atribuídos de acordo com alguma métrica de proximidade a classes incorretas. Um exemplo hipotético de tais dados é um conjunto de exames de tumor. Participamos dos dados e marcamos todos os tipos de tumores presentes nessa parte, mas verificou-se que outros tipos de tumores estavam presentes nos dados restantes, e a variabilidade das espécies conhecidas na marcação não foi totalmente refletida.
Os autores foram inspirados por modelos generativos profundos (o exemplo mais simples de um modelo com uma profundidade de camada única de variáveis ocultas é um codificador automático variacional, também conhecido como VAE): em trabalhos anteriores, esses modelos lidaram com sucesso com o caso semi-supervisionado (M2, ADGM) e o clustering ( VaDE, GM-VAE).
Por que não resolver 2 problemas ao mesmo tempo (aprendizado semi-supervisionado em classes raramente marcadas e não supervisionadas em classes não colocadas), mantendo o espaço das variáveis latentes aprendidas em comum e combinando idéias dos modelos acima? É essa ideia que fundamenta os modelos GM-DGM / AGM-DGM propostos no artigo.
Considere o modelo M2 em um caso semi-supervisionado. É assim chamado, porque em M1, o criador implicou em treinamento seqüencial do VAE e algum classificador (svm) para as representações latentes resultantes de z, mas M2 já é obtido do VAE adicionando à camada de variáveis ocultas a variável y, responsável pela classe às vezes observada.
,
onde ,
Aqui q é um codificador, p é um decodificador, parte - classificador diretamente treinado.
Para o caso não supervisionado / semi-não supervisionado, M2 não funciona - ocorre um colapso posterior, a parte de classificação q_phi (y | x) entra em colapso com a distribuição a priori p (y). O autor do GM-VAE em seu artigo também mostrou a inoperabilidade do M2 na prática e observou que, muitas vezes, ao implementar o M2, a primeira camada do decodificador h1 é muito semelhante a uma mistura de gaussianos.
Com base nessa observação, o GM-VAE usa uma camada explícita de variáveis ocultas para agrupar uma mistura Gaussiana para agrupamento, o que também é repetido pelos autores deste artigo.Portanto, o modelo GM-DGM, que permite uma operação bem-sucedida no modo semi-não supervisionado, é uma modificação VAE usando uma mistura de gaussianos em uma camada oculta, dependendo de uma variável da classe y, com a função acima de dois termos para contar e maximizar o ELBO.
Os autores do artigo realizaram um experimento em uma versão semi-não supervisionada do Fashion-MNIST: eles removeram os rótulos das 5 primeiras classes, as 5 classes restantes deixaram 5% dos rótulos, enquanto receberam uma precisão total de 77,2% contra 53% para M2. Também foi mostrada a possibilidade de usar o modelo para clustering (o que não é surpreendente, porque é quase GM-VAE).
3. Descobrindo e atenuando o viés algorítmico através da estrutura latente aprendida
Autores: Alexander Amini, Ava Soleimany, Wilko Schwarting, Sangeeta N. Bhatia, Daniela Rus (Instituto de Tecnologia de Massachusetts, Universidade de Harvard, 2019)
→ Artigo original
Autor do comentário: Alex Chiron (em sliron shiron8bit)
Recentemente, cada vez mais na mídia é possível encontrar notícias que abordam o tópico de viés nos dados, principalmente em relação a algoritmos relacionados a indivíduos - com o aumento de sua aplicabilidade, o risco de um forte impacto negativo sobre essas categorias e grupos de pessoas que são insuficientes (ou excessivos) apresentado no conjunto de dados. Um dos exemplos mais recentes é um estudo que mostrou menos precisão na detecção de pedestres com cor de pele escura (no contexto da detecção de objetos nos conjuntos de dados padrão BDD100K e MSCOCO, link ) .Certificações básicas para eliminar vieses:
- Balanceamento de classe usando reamostragem (requer entendimento a priori da estrutura de dados ocultos).
- Geração de dados imparciais (por exemplo, o uso de GAN para gerar indivíduos com uma ampla variedade de tons de pele ).
- Clustering e subsequente reamostragem.
- Ainda é possível aguardar até que o conjunto de dados do IBM Diversity in Faces seja levado aos acadêmictorrents.
Os autores do artigo oferecem uma modificação do VAE e da amostragem, levando em consideração a distribuição da variável latente z, o que pode reduzir a influência do viés nos dados na fase de treinamento.
Portanto, as principais idéias por trás do DB-VAE são:
- Considere um problema de classificação no qual temos um conjunto de dados de treinamento {(x, y)}, x são recursos dimensionais m, y são rótulos dimensionais d, e nossa tarefa é aproximar o mapeamento X-> Y.
- Vamos usar o VAE, mas, além do vetor de variáveis ocultas z da dimensão 2k (lembramos, 2 aqui porque estamos lidando com médias e variações), também aprenderemos o codificador da dimensão d, responsável pelos rótulos acima mencionados. Nesse caso, o decodificador aceita apenas o vetor z como entrada. Assim, obtemos uma aparência de aprendizado semi-supervisionado, onde parte do modelo é aprendida para reconstruir insumos e parte para resolver um problema específico (classificação).
- Controlamos o treinamento do modelo devido à perda combinada, combinando o padrão para perda de VAE (reconstrução + divergência de KL) e a perda para uma tarefa auxiliar (por exemplo, entropia cruzada para o problema de classificação binária).
- É prestada atenção especial ao fato de que você precisa controlar o treinamento em dados que não deseja debisitar (ou seja, não se apóia no decodificador).
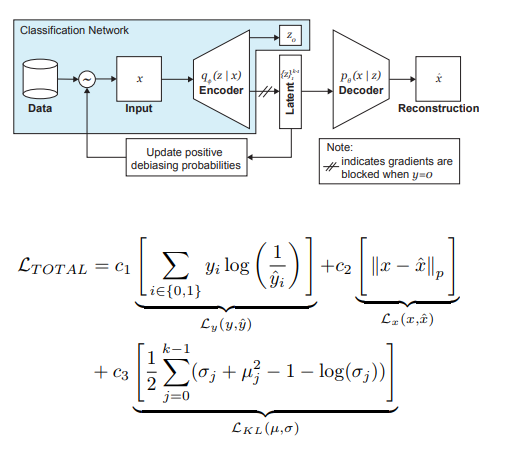
O papel mais importante na eliminação da dor dos negros é desempenhado pela amostragem adaptativa na fase de treinamento. Queremos escolher amostras raras (do ponto de vista de alguns fatores ocultos, não identificados explicitamente), por isso passamos aos histogramas para cada dimensão do espaço das variáveis ocultas z, cujo produto pode aproximar a distribuição Q (z | X) dos dados em todo o espaço Z. Ao formar um novo lote, levaremos em conta a distribuição 'inversa' da Q (z | X) W (z (x) | X), que determina a probabilidade de escolher um exemplo no lote (alfa é um hiperparâmetro que determina o grau de debiasing), atualizando Q (z | X) em todas as épocas. Como você pode ver, o debiasing não é pré-selecionado, mas baseado nas variáveis latentes aprendidas.
Como experimento, os autores resolveram o problema da classificação binária (encontrar o rosto na foto). Para o treinamento, coletamos um conjunto de dados, que consistia em 200 mil pessoas com CelebA e 200 mil não-pessoas com Imagenet, redimensionou imagens para 64x64. Como mencionado anteriormente, durante o treinamento, a retropropagação do decodificador para fotos sem rostos foi bloqueada (y = 0). Após o treinamento, eles foram validados no Benchmark dos Parlamentos Pilotos (PPB) (1270 fotos de pessoas dos parlamentos da África do Sul, Ruanda, Senegal, Suécia, Finlândia, Islândia): para todos os alfa> 0, a precisão de detecção nas categorias homem escuro, mulher escura, mulher clara aumentou em comparação com opção sem debiasing.
4. Aprendizagem profunda por reforço das preferências humanas
Autores: Paul Christiano, Jan Leike, Tom B.Brown, Miljan Martic, Shane Legg e Dario Amodei (OpenAI, DeepMind, 2017)
→ Artigo original
Autor do comentário: Dmitry Nikulin (in dniku slack)
Este artigo é sobre como implementar a velha ideia no contexto da aprendizagem por reforço profundo (RL). Idéia: vamos pedir a uma pessoa para avaliar o comportamento de um agente e, com base nisso, aprenderemos a função de recompensa. O problema é que a RL profunda é muito voraz e o tempo humano é caro. O artigo fornece um conjunto de hacks que permitem reduzir horas humanas para valores razoáveis.
A função de recompensa é uma função em pares (observação, ação). É definido pela média da previsão de um conjunto de redes neurais. Os algoritmos de RL usados (no artigo A2C para Atari e TRPO para Mujoco) acreditam que essa média é uma verdadeira recompensa e são treinados nela. Assim, o artigo enfoca a questão do treinamento desse conjunto.
O conjunto é treinado em avaliações humanas. Cada classificação está estruturada da seguinte forma. A uma pessoa são mostrados dois vídeos de um agente com 1 a 2 segundos de duração. Ele pode classificar esse par de quatro maneiras: esquerda é melhor / direita é melhor / muito semelhante / incomparável. Se uma pessoa disser "incomparável", essa avaliação será descartada. Caso contrário, o triplo (σ¹, σ², μ) é lembrado, onde σⁱ é a trajetória do agente no vídeo correspondente (ou seja, a lista de pares (obs, ato)) e μ é o par (1, 0), (0, 1 ) ou (½, ½). Além disso, acredita-se que a previsão da recompensa para a trajetória seja igual à soma das previsões para cada par (obs, ato). Por fim, simplesmente otimizamos softmax_cross_entropy_with_logits.
Acredita-se que uma pessoa com 10% de probabilidade selecione uma resposta aleatória, e isso é levado em consideração na construção de uma amostra de treinamento. A Seção 2.2.3 do artigo fornece mais alguns truques e escreve todas as fórmulas.
Pares de clipes para demonstração para uma pessoa são selecionados da seguinte forma: um grande número de clipes é amostrado, a dispersão do conjunto é considerada neles e pares aleatórios de clipes com alta dispersão são mostrados às pessoas. Os autores dizem que eu gostaria de escolher de acordo com o valor da informação, mas este é um trabalho futuro.
Os autores executam testes no Atari e Mujoco, com classificações humanas reais (contratadas contratadas) e sintéticas (as classificações são geradas de acordo com a verdadeira função de recompensa) e, ao mesmo tempo, são comparadas com a RL usual. Com números aproximadamente iguais de classificações, os testes sintéticos e reais funcionam da mesma forma. Além disso, surpreendentemente, a RL regular (que vê a verdadeira função de recompensa) não necessariamente funciona melhor.
Finalmente, além de tentar treinar o agente para obter muita recompensa no sentido usual, o artigo também fornece exemplos de duas outras tarefas: o Hopper em Mujoco faz um retorno e a máquina no Atari Enduro não ultrapassa outros carros, mas viaja paralelamente a eles. Acabou resolvendo os dois problemas.
Em conclusão: o exemplo descreve uma tentativa de reproduzir este artigo. A tentativa foi bem-sucedida, mas foram necessários 8 meses de trabalho em tempo livre e 220 horas em tempo puro, dos quais metade foi para depurar a versão mais simples.
5. Explorando redes neurais cabeadas aleatoriamente para reconhecimento de imagens
Autores: Saining Xie, Alexander Kirillov, Ross Girshick, Kaiming He (Facebook AI Research, 2019)
→ Artigo original
Autor do comentário: Egor Panfilov (in slack tutk1ja)
Introdução:
O trabalho levanta a questão de gerar arquitetura de redes neurais. Atualmente, muitos truques de arquitetura são conhecidos (LSTM, Inception, ResNet, DenseNet), que podem melhorar a qualidade de muitas tarefas, mas também introduzem uma certa arquitetura forte antes do modelo. Em vez das soluções mencionadas, o Google está avançando com sua pesquisa de arquitetura neural (NAS), onde a pesquisa de arquitetura para uma tarefa específica é realizada a partir de módulos predefinidos via RL - NASNet, AmoebaNet.
Os autores argumentam que as duas abordagens em que o design é determinado pelo homem e o NAS são muito rígidas antes da arquitetura. Na tentativa de reduzi-lo, eles tentam usar a abordagem generativa paramétrica da rede neural, onde a fiação (conexão) dos elementos é realizada aleatoriamente. Acontece que as abordagens de fiação aleatória têm sido exploradas desde a década de 1940 por cientistas como A. Turing, M. Minsky, F. Rosenblatt. Como mais um argumento, os autores lembram que, em estudos neurocientíficos, foi revelado que a estrutura das conexões neuronais nos organismos de uma espécie é diferente (até certo nível de detalhe, é claro). Isso é verdade tanto para vermes quanto para bebês humanos.Em geral, a idéia de geração procedural de redes neurais parece interessante e promissora, e é disso que se trata o trabalho.
Método:
Vamos tentar modularizar o processo de geração procedural da arquitetura de rede neural por meio de uma abordagem gráfica. Os passos iniciais são os seguintes:
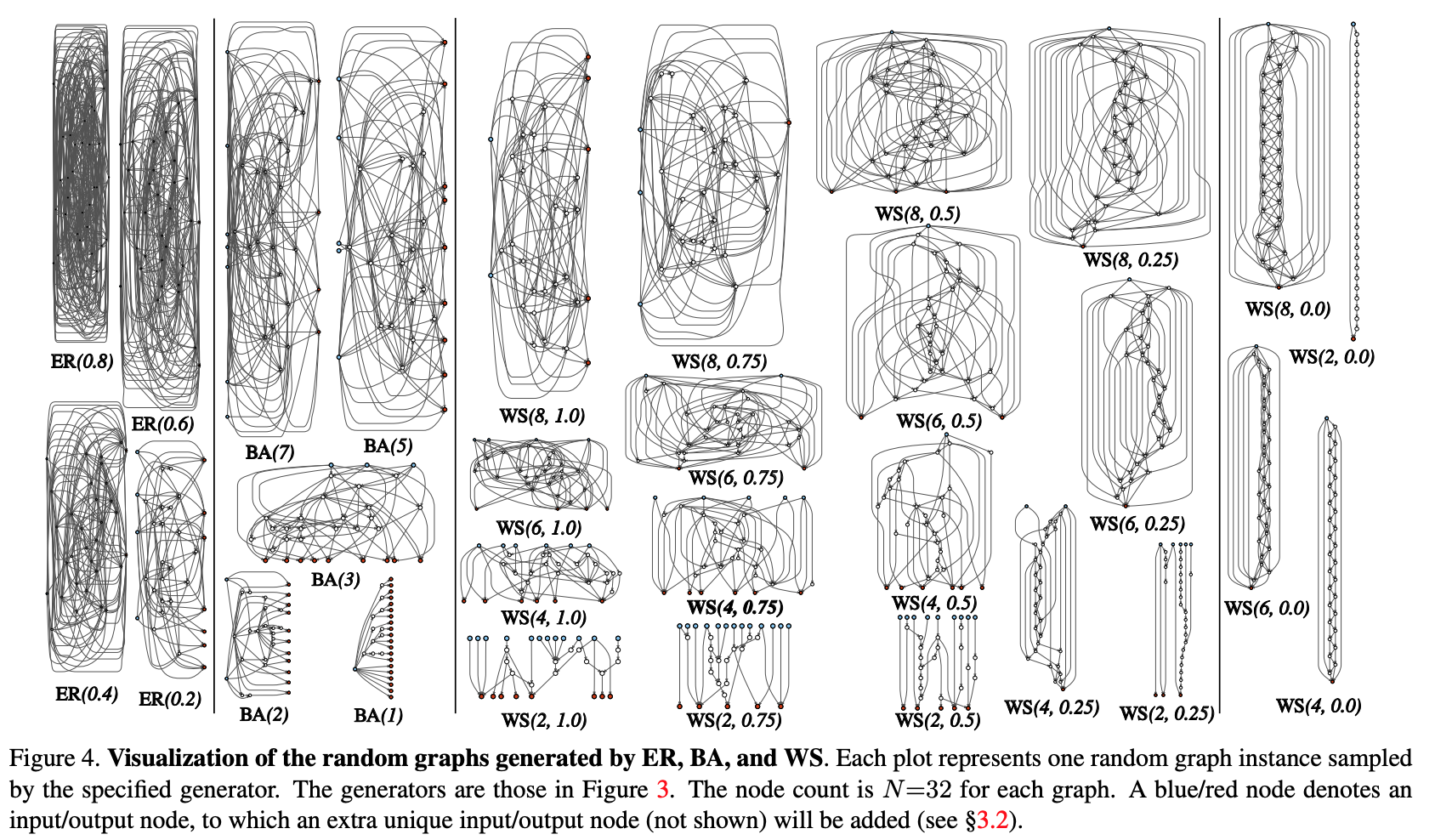
- Um gráfico estocástico é gerado a partir de uma família parametrizada. Métodos clássicos são usados: Erdos-Renyi (ER), Barabasi-Albert (BA) e Watts-Strogatz (WS).
- O gráfico é convertido em uma rede neural:
- presume-se que todas as arestas do gráfico sejam portadoras direcionadas de tensores de dados;
- para cada vértice do gráfico, é determinado o tipo de operação que ele executa: (I) agregação somando com os pesos treinados, (II) transformação - ReLU + convolução + BN, (III) distribuição - transferência do tensor ao longo de cada extremidade da saída;
- de acordo com os resultados da subcláusula anterior, pode haver vários vértices de entrada e saída, mas quero ter 1 ponto de entrada no gráfico e 1 ponto de saída. Esses nós são criados separadamente. A entrada um simplesmente espalha uma cópia do tensor para todos os vértices de entrada do gráfico, a saída considera a média não ponderada de todos os vértices de saída.Como resultado das etapas 1 e 2, de fato, não é criada uma rede completa, mas apenas um dos módulos (como conv_1, ... codificadores convolucionais). Para obter a rede neural completamente:
- Vários módulos são criados e conectados em série. Para reduzir o número de parâmetros de rede, as transformações em todos os vértices de entrada dos módulos são realizadas com uma passada de 2x2. O número de canais na transição para o próximo módulo aumenta 2 vezes.Para conduzir experimentos em uma tarefa específica:
- O cabeçalho da classificação é adicionado à saída da rede.
Resultados:
O teste do método foi realizado no problema de classificação no ImageNet. A qualidade da rede neural gerada ficou parecida com as arquiteturas da SotA, perdendo um pouco para o recente DeepBrain AmoebaNet do Google: (com um número comparável de parâmetros).
Verificamos o que aconteceria se removêssemos um vértice / aresta aleatório do gráfico resultante. Métrica - redução da qualidade, dependendo do número adjacente de arestas de saída / vértices de entrada, respectivamente. Em geral, a qualidade está caindo, mas não é crítica.
Os autores também verificaram se o aprendizado de transferência funciona com essa arquitetura. Na tarefa de detecção de COCO, o backbone Faster R-CNN with FPN foi substituído por uma rede gerada e pré-treinada. Os resultados mostraram que a qualidade do modelo não é pior que a do ResNeXt-50 / -101. Mas mesmo o fato de que o aprendizado de transferência está começando é bastante divertido.
6. Photofeeler-D3: uma rede neural com modelagem eleitoral para namoro
Autores do artigo: Agastya Kalra e Ben Peterson (Photofeeler Inc., 2019)
→ Artigo original
Autor do comentário: Alex Chiron (em sliron shiron8bit)
Os autores sugerem o Photofeeler-D3: uma arquitetura de rede para avaliar fotos de sites de namoro em três direções / características - quão inteligente uma pessoa parece, confiável e atraente (negligencie o efeito halo!). A tarefa surgiu com base em uma pesquisa do The Guardian, segundo a qual 90% das pessoas decidem em uma data futura apenas com base na avaliação de fotos de um potencial satélite
Portanto, a rede consiste nos seguintes blocos:
- ( ) — (GAP ), 10 ( ) — temporary output.
- ( , voter model) - (voter), , temporary output , , 10 v_ij (( 10 [0;1]). v_ij [0.05, 0.15, 0.25...0.95].
- , 200 , .
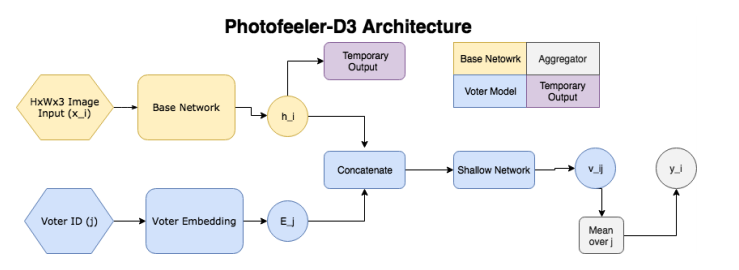
, , , , . Facial Beauty Prediction (FBP) SCUT-FBP Hot-Or-Not, , Photofeeler, . : +100k , 1.2 , (200 ) 200 (50 ). , 600px. 10000 8000 . , 0 3, [0,1] ( , ).
:
- (backbone , , etc) (20000 train, 3000 val, 2311 test), xception 600x600.
- , (temporary output) KL- ( , , 10 [0,1]).
- voter model one-hot .
- voter' , 2 .
- trait' 2 , .:
- ~80% , London Faces , prettyscale.com hotness.ai (81 53 52).
- FBP (SCUT-FBP Hot-Or-Not) , SOTA.
- , , 10
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
: D. Berthelot, N. Carlini, IJ Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→
: ( JanRocketMan)
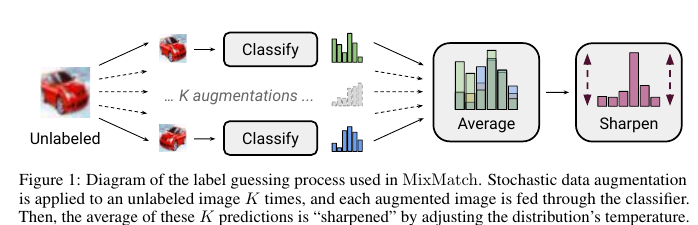
MeanTeacher Mixup- SOT- Semi-Supervised Learning (SSL) . , SSL consistency regularization. , ( ) "" , . Mean Teacher ( — c EMA ), — Mixup ( ). , . :
- unsupervised , .
"" p. - "" , one-hot. : . T , , , ( ), .
- , . , SVHN, STL CIFAR10.
CIFAR10 90% accuracy 250 . — VAT, 60%. SVHN - 96% 250- , VAT Mean Teacher 90.
STL10 90% 1 , - CCGAN, 80. , :
- , ( );
- GridSearch- ;
c. SSL SVHN .
8. Divide and Conquer the Embedding Space for Metric Learning
: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→
: ( Alexander Denisenko)
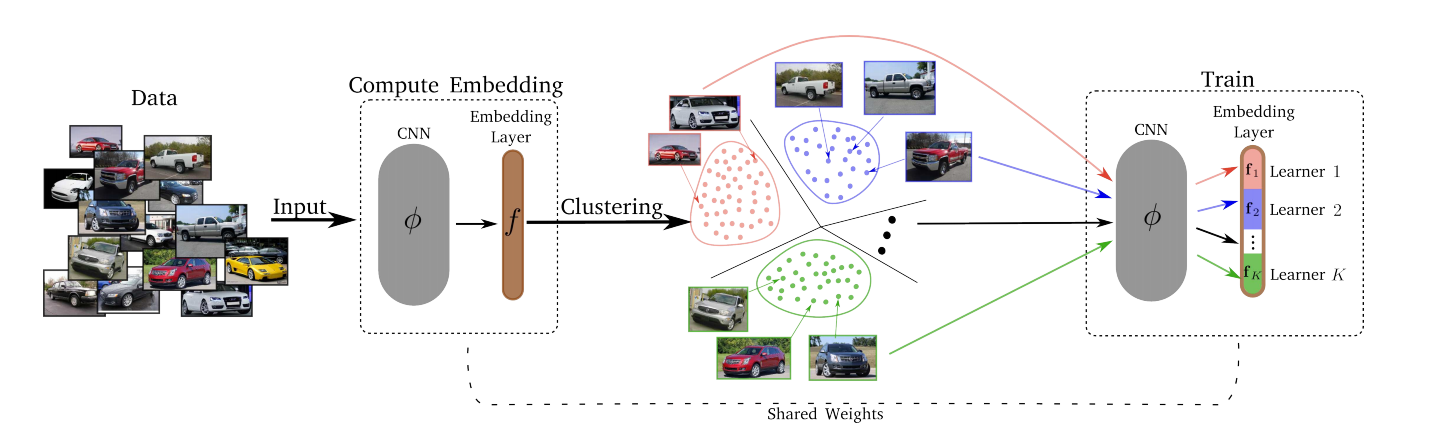
— , . , , – , , , ..
, :
- Divide.
- k-means. . . Embedding layer K . – . d/K (d – ). - Conquiste.
Após o estágio Divide, cada um dos K clusters é mapeado para um dos K Lerners. O Lerners treina, por sua vez, ou seja, a qualquer momento, selecionamos um cluster no qual o treinamento ocorre, um mini-lote é amostrado e o Lerner correspondente minimiza sua perda atualizando seus parâmetros. O espaço das combinações é atualizado ao longo do tempo, para que todas as épocas T, o agrupamento (Divisão) seja realizado novamente. - Merjim - concatenamos todas as Lerners (fatias da camada de incorporação). Em seguida, treinamos a camada de incorporação em todo o conjunto de dados para fazer os amigos de Lerners.
Resultados experimentais: todos venceram em vários conjuntos de dados.
Perda pode ser qualquer coisa - perda de trigêmeos, perda de margem, proxy-NCA, etc.
O número ideal de K Lerners acabou sendo 8 (a dimensão de todo o espaço de incorporação era 128, de modo que cada Lerner resolveu sua subtarefa no espaço 16-dimensional).
Uma mudança em T de 1 para 10 não afetou significativamente nada, então T = 2 foi usado.