Apresentamos uma lista exaustiva, onde dizemos em palavras simples o que a inteligência artificial “cria” e como tudo funciona.
Qual é a diferença entre Inteligência Artificial, Aprendizado de Máquina e Ciência de Dados?
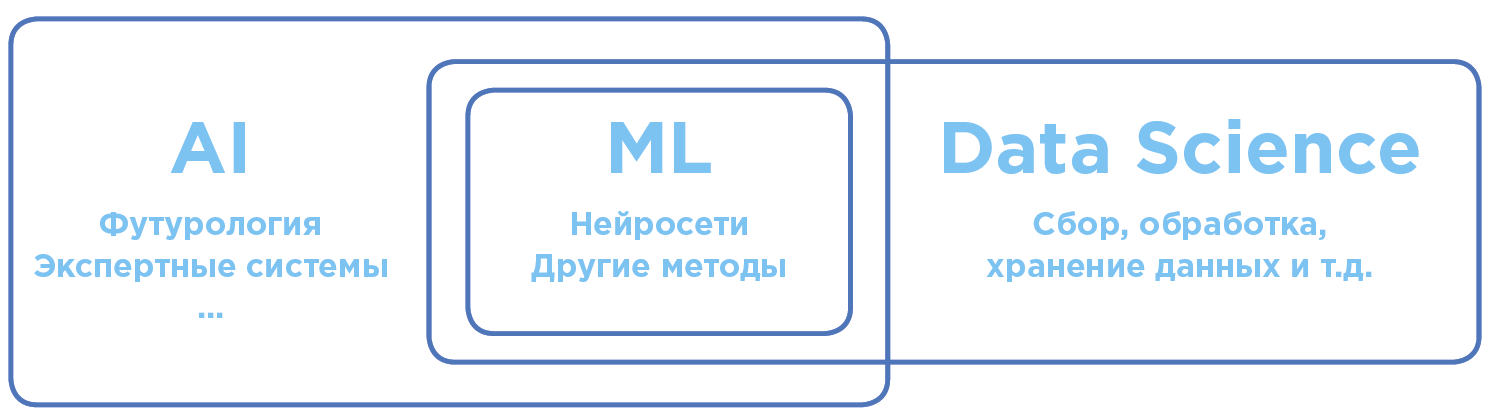 Diferenciação de conceitos no campo da inteligência artificial e análise de dados.
Diferenciação de conceitos no campo da inteligência artificial e análise de dados.Inteligência Artificial - AI (Inteligência Artificial)
No sentido universal global, AI é o termo o mais amplo possível. Inclui teorias científicas e práticas tecnológicas específicas para criar programas próximos à inteligência humana.
Machine Learning - ML (aprendizado de máquina)
Seção AI, ativamente aplicada na prática. Hoje, quando se trata de usar a IA nos negócios ou na fabricação, na maioria das vezes queremos dizer Machine Learning.
Os algoritmos de ML, como regra, funcionam com base no princípio de um modelo matemático de aprendizado que realiza análises com base em uma grande quantidade de dados, enquanto conclusões são tiradas sem seguir regras rigidamente definidas.
O tipo mais comum de tarefa no aprendizado de máquina é aprender com um professor. Para resolver esse tipo de problema, o treinamento é usado em uma matriz de dados cuja resposta é conhecida antecipadamente (veja abaixo).
Ciência de Dados - DS (Ciência de Dados)
A ciência e prática de analisar grandes volumes de dados usando todos os tipos de métodos matemáticos, incluindo aprendizado de máquina, além de resolver tarefas relacionadas à coleta, armazenamento e processamento de matrizes de dados.
Os cientistas de dados são especialistas em dados, em particular, que analisam usando o aprendizado de máquina.

Como o aprendizado de máquina funciona?
Considere o trabalho de ML no exemplo da tarefa de pontuação bancária. O Banco possui dados sobre clientes existentes. Ele sabe se alguém tem pagamentos em atraso. A tarefa é determinar se um novo cliente em potencial fará pagamentos no prazo. Para cada cliente, o banco possui uma combinação de certas características / características: sexo, idade, renda mensal, profissão, local de residência, educação etc. Entre as características podem estar parâmetros mal estruturados, como dados de redes sociais ou histórico de compras. Além disso, os dados podem ser enriquecidos com informações de fontes externas: taxas de câmbio, dados de agências de crédito, etc.
Uma máquina vê qualquer cliente como uma combinação de recursos:
. Onde por exemplo
- idade
- renda e
- o número de fotos de compras caras por mês (na prática, como parte de uma tarefa semelhante, o Data Scientist trabalha com mais de cem recursos). Cada cliente tem mais uma variável -
com dois resultados possíveis: 1 (há pagamentos em atraso) ou 0 (sem pagamentos em atraso).
Totalidade de todos os dados
e
- existe um conjunto de dados. Usando esses dados, o Data Scientist cria um modelo
, selecionando e modificando o algoritmo de aprendizado de máquina.
Nesse caso, o modelo de análise fica assim:
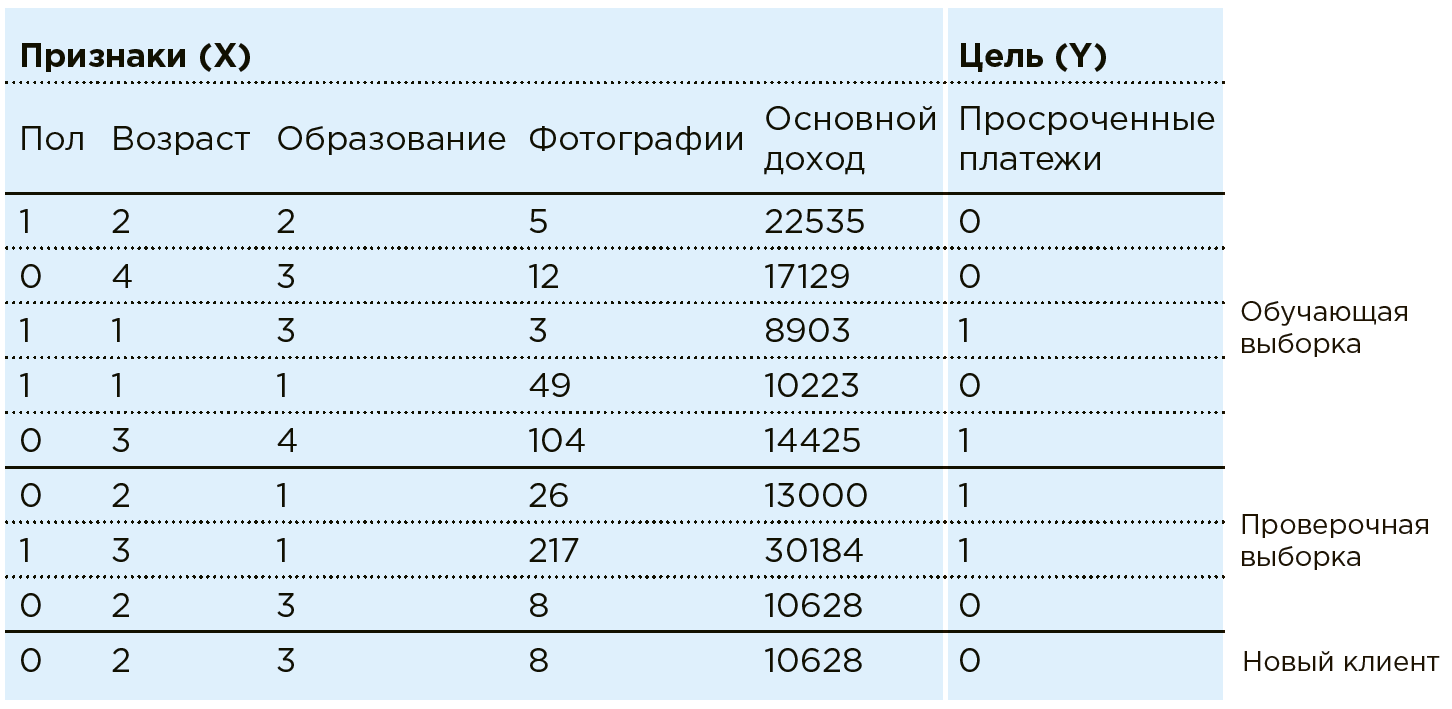
Os algoritmos de aprendizado de máquina implicam uma aproximação em fases das respostas do modelo
às respostas verdadeiras (que são conhecidas antecipadamente no conjunto de dados de treinamento). Isso é treinar com um professor em uma amostra específica.
Na prática, na maioria das vezes a máquina aprende apenas em uma parte da matriz (80%), usando o restante (20%) para verificar a correção do algoritmo selecionado. Por exemplo, um sistema pode ser treinado em uma matriz a partir da qual os dados de um par de regiões são excluídos, nos quais a precisão do modelo é verificada depois.
Agora, quando um novo cliente chega ao banco, segundo o qual
o banco ainda não é conhecido, o sistema informará a confiabilidade do pagador com base nos dados conhecidos sobre ele
.
No entanto, ensinar com um professor não é a única classe de problemas que a ML pode resolver.
Outra variedade de tarefas é o cluster, capaz de separar objetos de acordo com seus atributos, por exemplo, para identificar diferentes categorias de clientes para que eles façam ofertas individuais.
Além disso, com a ajuda dos algoritmos ML, são resolvidas tarefas como modelar a comunicação de um especialista em suporte ou criar obras de arte indistinguíveis das criações humanas (por exemplo, redes neurais pintam quadros).
Uma classe nova e popular de tarefas é o treinamento por reforço, que ocorre em um ambiente limitado que avalia as ações dos agentes (por exemplo, usando esse algoritmo, foi criado o AlphaGo que derrotou a pessoa em Go).

Rede neural
Um dos métodos de aprendizado de máquina. Um algoritmo inspirado na estrutura do cérebro humano, que é baseada em neurônios e nas conexões entre eles. No processo de aprendizado, as conexões entre os neurônios são ajustadas de forma a minimizar erros de toda a rede.
Uma característica das redes neurais é a presença de arquiteturas adequadas para quase todos os formatos de dados: redes neurais convolucionais para análise de imagens, redes neurais recorrentes para análise de textos e seqüências, codificadores automáticos para compactação de dados, redes neurais generativas para criação de novos objetos etc.
Ao mesmo tempo, quase todas as redes neurais têm uma limitação significativa - para seu treinamento, é necessária uma grande quantidade de dados (ordens de magnitude maiores que o número de conexões entre neurônios nessa rede). Devido ao fato de que recentemente os volumes de dados prontos para análise cresceram significativamente, o escopo também está aumentando. Com a ajuda das redes neurais atuais, por exemplo, as tarefas de reconhecimento de imagem são resolvidas, como determinar a idade e o sexo de uma pessoa em um vídeo ou ter um capacete no trabalhador.
Interpretação do resultado
A seção Ciência de Dados, que permite entender os motivos da escolha de uma ou outra solução pelo modelo de ML.
Existem duas áreas principais de pesquisa:
- Estudando o modelo como uma caixa preta. Analisando os exemplos carregados nele, o algoritmo compara os recursos desses exemplos e as conclusões do algoritmo, tirando conclusões sobre a prioridade de qualquer um deles. No caso de redes neurais, geralmente é usada uma caixa preta.
- Estudando as propriedades do próprio modelo. O estudo das características que o modelo utiliza para determinar o grau de sua importância. Geralmente aplicado a algoritmos com base no método da árvore de decisão.
Por exemplo, ao prever defeitos na produção, sinais de objetos
- são os dados sobre as configurações das máquinas, a composição química das matérias-primas, indicadores de sensores, vídeo do transportador, etc. E as respostas
- estas são as respostas para a pergunta se haverá um casamento ou não.
Naturalmente, a produção está interessada não apenas na previsão do casamento em si, mas também na interpretação do resultado, ou seja, as razões do casamento para sua subsequente eliminação. Pode ser uma longa ausência de manutenção da máquina, a qualidade das matérias-primas ou simplesmente leituras anormais de alguns sensores que o técnico deve prestar atenção.
Portanto, na estrutura do projeto de previsão do casamento em produção, um modelo de BC não deve apenas ser criado, mas também deve ser feito um trabalho para interpretá-lo, ou seja, para identificar os fatores que afetam o casamento.

Quando o aprendizado de máquina é eficaz?
Quando existe um grande conjunto de dados estatísticos, mas é impossível ou muito trabalhoso encontrar dependências usando métodos matemáticos especialistas ou clássicos. Portanto, se houver mais de mil parâmetros na entrada (entre os quais são numéricos e de texto, além de vídeo, áudio e imagens), é impossível encontrar a dependência do resultado neles sem uma máquina.
Por exemplo, além das próprias substâncias que entram na interação, uma reação química é influenciada por muitos parâmetros: temperatura, umidade, o material do recipiente em que ocorre etc. É difícil para um químico levar em consideração todos esses sinais para calcular com precisão o tempo de reação. Muito provavelmente, ele levará em conta vários parâmetros importantes e será baseado em sua experiência. Ao mesmo tempo, com base nos dados de reações anteriores, o aprendizado de máquina poderá levar em conta todos os sinais e fornecer uma previsão mais precisa.
Como o Big Data e o aprendizado de máquina estão relacionados?
Para criar modelos de aprendizado de máquina, em diferentes casos, são necessários dados numéricos, textuais, de foto, vídeo, áudio e outros. Para armazenar e analisar essas informações, existe toda uma área da tecnologia - Big Data. Para melhor armazenamento e análise de dados, eles criam o “Data Lake” - armazenamento distribuído especial para grandes volumes de informações mal estruturadas baseadas nas tecnologias de Big Data.
Dobro digital como passaporte eletrônico
Um duplo digital é uma cópia virtual de um objeto, processo ou organização material real, que permite simular o comportamento do objeto / processo estudado. Por exemplo, é possível visualizar preliminarmente os resultados de alterações na composição química na fábrica após alterações nas configurações das linhas de produção, alterações nas vendas após uma campanha publicitária com certas características, etc. Nesse caso, as previsões são feitas por um duplo digital com base nos dados acumulados e os cenários e situações futuras são modelados incluindo métodos de aprendizado de máquina.
O que é necessário para o aprendizado de máquina de qualidade?
Data Scientiest! São eles que criam o algoritmo de previsão: estudam os dados disponíveis, apresentam hipóteses, constroem modelos com base no conjunto de dados. Eles devem ter três grupos principais de habilidades: alfabetização em TI, conhecimento matemático e estatístico e experiência substantiva em um campo específico.
O aprendizado de máquina se baseia em três pilares
Recuperação de dadosPodem ser usados dados de sistemas relacionados: horário de trabalho, plano de vendas. Os dados também podem ser enriquecidos por fontes externas: taxas de câmbio, clima, calendário de feriados etc. É necessário desenvolver uma metodologia para trabalhar com cada tipo de dados e pensar em um pipeline para convertê-los em um formato de modelo de aprendizado de máquina (um conjunto de números).
CaracterizaçãoÉ realizado em conjunto com especialistas da área requerida. Isso ajuda a calcular dados adequados para fins de previsão: estatísticas e alterações no número de vendas do mês passado para previsão de mercado.
Modelo de aprendizado de máquinaO método de resolver esse problema de negócios é escolhido pelo cientista de dados de forma independente, com base em sua experiência e nos recursos de vários modelos. Para cada tarefa específica, você precisa escolher um algoritmo separado. A velocidade e a precisão do resultado do processamento de dados de origem dependem diretamente do método selecionado.
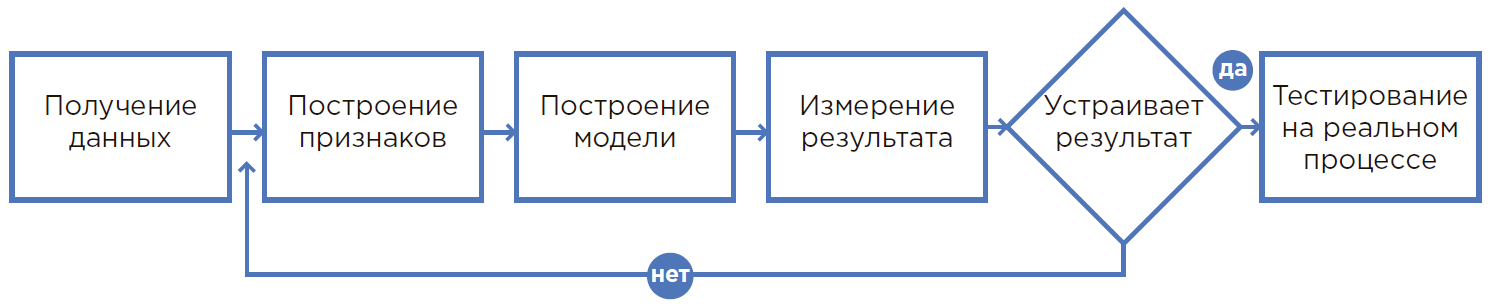 O processo de criação de um modelo de ML.
O processo de criação de um modelo de ML.Da hipótese ao resultado
1. Tudo começa com uma hipótese
Nasce uma hipótese ao analisar o processo do problema, a experiência dos funcionários ou com uma nova visão da produção. Normalmente, uma hipótese afeta um processo em que uma pessoa é fisicamente incapaz de levar em consideração muitos fatores e usa arredondamentos, suposições ou simplesmente faz como sempre.
Nesse processo, o uso do aprendizado de máquina permite que você use significativamente mais informações ao tomar decisões, portanto, é possível obter resultados significativamente melhores. Além disso, a automação de processos usando ML e a redução da dependência de uma pessoa específica minimizam significativamente o fator humano (doença, baixa concentração, etc.).
2. Avaliação da hipótese
Com base na hipótese formulada, os dados necessários para o desenvolvimento de um modelo de aprendizado de máquina são selecionados. É feita uma pesquisa dos dados relevantes e é determinada uma avaliação de sua adequação para incorporar o modelo nos processos atuais, quem serão seus usuários e devido ao qual o efeito é alcançado. Se necessário, mudanças organizacionais e outras são feitas.
3. O cálculo do efeito econômico e retorno do investimento (ROI)
A avaliação do efeito econômico da solução implementada é realizada por especialistas em conjunto com os departamentos relevantes: eficiência, finanças, etc. Nesta fase, você precisa entender qual é exatamente a métrica (número de clientes corretamente identificados / aumento na produção / economia de consumíveis, etc.) e articular claramente o objetivo medido.
4. A formulação matemática do problema
Depois de entender o resultado do negócio, é necessário alterá-lo para o plano matemático - para definir métricas e restrições de medição que não podem ser violadas. Data estágios de dados
Um cientista atua em conjunto com um cliente comercial.
5. Coleta e análise de dados
É necessário coletar dados em um único local, analisá-los, considerando várias estatísticas, entender a estrutura e os relacionamentos ocultos desses dados para formar sinais.
6. Criando um protótipo
É, de fato, um teste de hipótese. Esta é uma oportunidade para criar um modelo com dados atuais e verificar inicialmente os resultados de seu trabalho. Normalmente, é feito um protótipo nos dados existentes sem desenvolver integrações e trabalhar com um fluxo em tempo real.
A prototipagem é uma maneira rápida e barata de verificar se um problema está sendo resolvido. Isso é muito útil quando é impossível entender antecipadamente se será possível obter o efeito econômico desejado. Além disso, o processo de criação de um protótipo permite avaliar melhor o escopo e os detalhes do projeto para implementar a solução, a fim de preparar uma justificativa econômica para essa implementação.
DevOps e DataOps
Durante a operação, um novo tipo de dados pode aparecer (por exemplo, outro sensor aparecerá na máquina ou um novo tipo de mercadoria aparecerá no armazém) e o modelo precisará ser treinado. O DevOps e o DataOps são metodologias que ajudam a configurar processos de colaboração e ponta a ponta entre as equipes de ciência de dados, engenheiros de preparação de dados, serviços de desenvolvimento e operação de TI e ajudam a tornar essas adições parte do processo atual rapidamente, sem erros e sem resolver cada vez que é único problemas
7. Criando uma solução
Nesse momento, quando os resultados do trabalho do protótipo demonstram a conquista confiável de indicadores, é criada uma solução completa em que o modelo de aprendizado de máquina é apenas um componente dos processos estudados. Em seguida, integração, instalação do equipamento necessário, treinamento da equipe, mudança dos processos de tomada de decisão, etc.
8. Operação piloto e industrial
Durante a operação de teste, o sistema opera no modo de aconselhamento, enquanto o especialista ainda repete as ações usuais, sempre dando feedback sobre as melhorias necessárias no sistema e aumentando a precisão das previsões.
A parte final é a operação industrial, quando os processos estabelecidos passam para a manutenção totalmente automática.
Você pode baixar a folha de dicas no
link .
Amanhã, no fórum sobre sistemas de inteligência artificial
RAIF 2019 , das 09:30 às 10:45, haverá um painel de discussão: "IA para as pessoas: entendemos em palavras simples".
Nesta seção, em um formato de debate, os palestrantes explicarão tecnologias complexas com palavras simples em exemplos da vida. E também discuta sobre os seguintes tópicos:
- Qual é a diferença entre Inteligência Artificial, Aprendizado de Máquina e Ciência de Dados?
- Como o aprendizado de máquina funciona?
- Como as redes neurais funcionam?
- O que é necessário para o aprendizado de máquina de qualidade?
- O que é marcação, rotulagem de dados?
- O que é um duplo digital e como trabalhar com cópias virtuais de objetos materiais reais?
- Qual é a essência da hipótese? Como sair do modo como é colocado na avaliação e interpretação do resultado?
A discussão é assistida por:
Nikolay Marine, diretor de tecnologia, IBM na Rússia e na CEI
Alexey Natekin, Fundador, Open Data Science x Data Souls
Alexey Hakhunov, diretor de tecnologia, Dbrain
Evgeny Kolesnikov, Diretor, Centro de aprendizado de máquina, Jet Infosystems
Pavel Doronin, CEO, AI Hoje
A discussão estará disponível no
canal do YouTube da Jet Infosystems no final de outubro.