
Tolerância a falhas e alta disponibilidade são grandes tópicos; portanto, o RabbitMQ e o Kafka dedicarão artigos separados. Este artigo é sobre o RabbitMQ e o próximo é sobre o Kafka, comparado ao RabbitMQ. O artigo é longo, então fique à vontade.
Considere as estratégias para tolerância a falhas, consistência e alta disponibilidade (HA), bem como as vantagens e desvantagens que cada estratégia deve fazer. O RabbitMQ pode ser executado em um cluster de nós - e depois é classificado como um sistema distribuído. Quando se trata de sistemas distribuídos, geralmente falamos sobre consistência e acessibilidade.
Esses conceitos descrevem como o sistema se comporta no caso de uma falha. Falha na conexão de rede, falha no servidor, falha no disco rígido, indisponibilidade temporária do servidor devido à coleta de lixo, perda de pacotes ou lentidão na conexão de rede. Tudo isso pode levar à perda ou conflito de dados. Acontece que é quase impossível criar um sistema que seja simultaneamente completamente consistente (sem perda de dados, sem discrepâncias de dados) e acessível (ele aceitará operações de leitura e gravação) para todos os tipos de falhas.
Veremos que a consistência e a acessibilidade estão em diferentes extremos do espectro, e você precisa escolher qual caminho otimizar. A boa notícia é que, com o RabbitMQ, essa escolha é possível. Você tem uma espécie de alavancagem "nerd" para mudar a balança em direção a maior coerência ou maior acessibilidade.
Prestaremos atenção especial a quais configurações levam à perda de dados devido a registros confirmados. Existe uma cadeia de responsabilidade entre editores, corretores e consumidores. Depois que a mensagem é transmitida ao corretor, é seu trabalho não perdê-la. Quando o corretor confirma ao editor o recebimento da mensagem, não esperamos que ela se perca. Mas veremos que isso pode realmente acontecer, dependendo da configuração do seu corretor e editor.
As primitivas de estabilidade de um nó
Filas / roteamento sustentados
Existem dois tipos de filas no RabbitMQ: durável / não durável. Todas as filas são armazenadas no banco de dados Mnesia. As filas persistentes são declaradas novamente quando o nó é iniciado e, portanto, sobrevivem a uma reinicialização, falha no sistema ou no servidor (desde que os dados sejam salvos). Isso significa que enquanto você declarar roteamento (troca) e a fila resiliente, a infraestrutura das filas / roteamento retornará online.
Filas voláteis e roteamento são excluídas quando o host é reiniciado.
Mensagens persistentes
Só porque a fila é longa, não significa que todas as suas mensagens sobreviverão à reinicialização do nó. Somente as mensagens definidas pelo editor como persistentes serão restauradas. Mensagens persistentes criam uma carga adicional no broker, mas se a perda de mensagens for inaceitável, não haverá outra maneira.
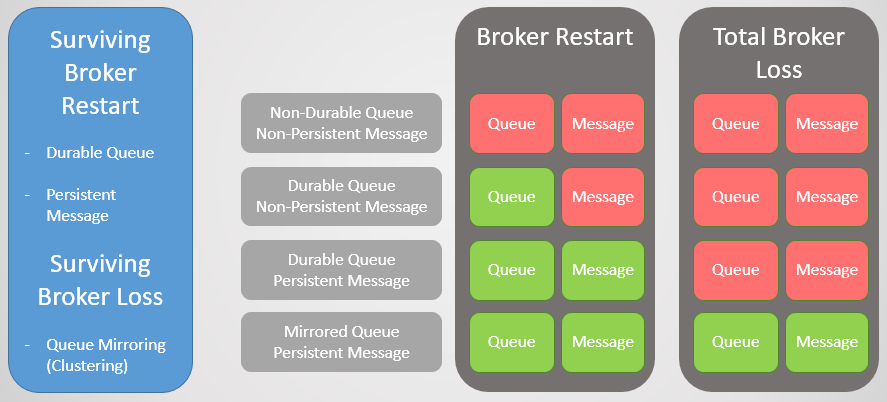 Fig. 1. Matriz de estabilidade
Fig. 1. Matriz de estabilidadeCluster de espelhamento de fila
Para sobreviver à perda de um corretor, precisamos de redundância. Podemos combinar vários nós RabbitMQ em um cluster e adicionar redundância adicional replicando as filas entre vários nós. Assim, se um nó cair, não perderemos dados e permaneceremos disponíveis.
Espelhamento de fila:
- uma fila principal (principal), que recebe todos os comandos de gravação e leitura
- um ou mais espelhos que recebem todas as mensagens e metadados da fila principal. Esses espelhos não existem para dimensionamento, mas apenas para redundância.
 Fig. 2. Espelhando a fila
Fig. 2. Espelhando a filaO espelhamento é definido pela política apropriada. Nele, você pode escolher a taxa de replicação e até os nós nos quais a fila deve ser colocada. Exemplos:
ha-mode: all
ha-mode: exactly, ha-params: 2 (um mestre e um espelho)
ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
Confirmação ao editor
Para obter uma gravação sequencial, o Publisher Confirms deve ser confirmado. Sem eles, há uma chance de perder mensagens. Uma confirmação é enviada ao editor depois de gravar a mensagem no disco. O RabbitMQ grava mensagens no disco não após o recebimento, mas periodicamente, na região de várias centenas de milissegundos. Quando a fila é espelhada, a confirmação é enviada somente após todos os espelhos também terem gravado sua cópia da mensagem no disco. Isso significa que o uso de confirmações aumenta o atraso, mas se a segurança dos dados é importante, elas são necessárias.
Fila de Failover
Quando o broker é encerrado ou falha, todas as filas principais (mestres) nesse nó caem com ele. O cluster seleciona o espelho mais antigo de cada mestre e o promove como um novo mestre.
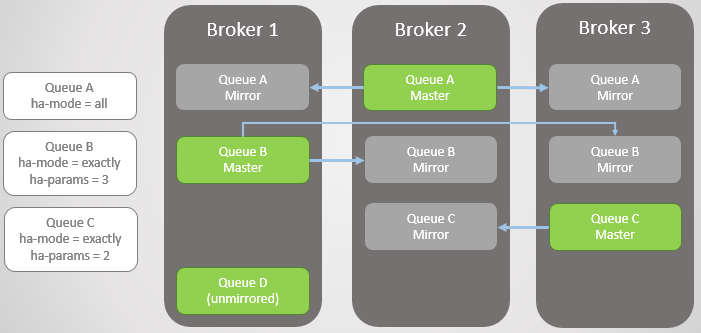 Fig. 3. Várias filas espelhadas e suas políticas
Fig. 3. Várias filas espelhadas e suas políticasCorretor 3 gotas. Observe que o espelho da Fila C no Broker 2 é atualizado para um mestre. Observe também que um novo espelho foi criado para a Fila C no Broker 1. O RabbitMQ sempre tenta manter a taxa de replicação especificada em suas políticas.
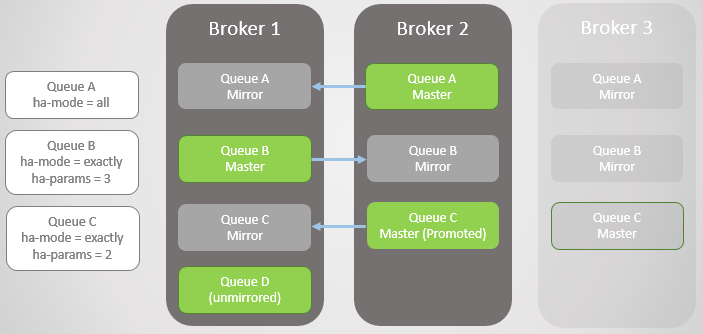 Fig. 4. O Broker 3 cai, causando falha na fila C
Fig. 4. O Broker 3 cai, causando falha na fila CO próximo Broker 1 está caindo! Temos apenas um corretor restante. O espelho da fila B sobe para o mestre.
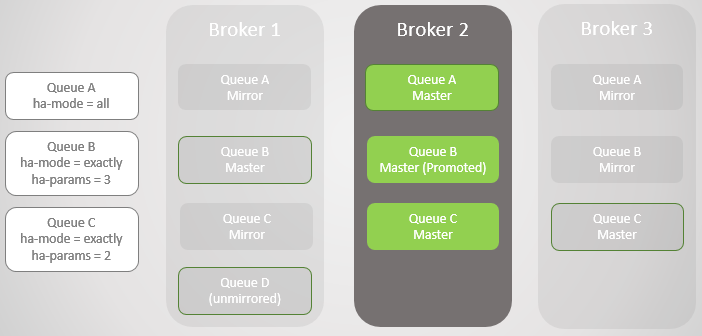 Fig. 5
Fig. 5Retornamos o Broker 1. Não importa com que êxito os dados tenham sobrevivido à perda e recuperação do broker, todas as mensagens da fila espelhada são descartadas na reinicialização. É importante notar, pois haverá consequências. Em breve consideraremos essas consequências. Portanto, o Broker 1 agora é novamente um membro do cluster e o cluster está tentando cumprir as políticas e, portanto, cria espelhos no Broker 1.
Nesse caso, a perda do Broker 1 foi concluída e os dados, portanto, a Fila D não espelhada foi completamente perdida.
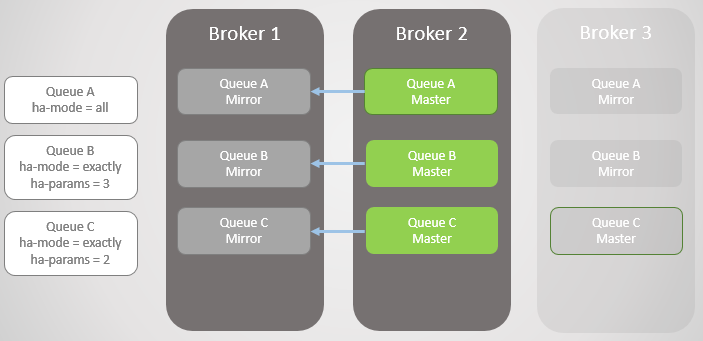 Fig. 6. O Broker 1 está de volta ao serviço
Fig. 6. O Broker 1 está de volta ao serviçoO Broker 3 está de volta à linha, de modo que as linhas A e B recebem espelhos criados nele de acordo com suas políticas de HA. Mas agora todas as linhas principais estão em um nó! Isso não é ideal; uma distribuição uniforme entre os nós é melhor. Infelizmente, não há opções especiais para reequilibrar os mestres. Voltaremos a esse problema mais tarde, pois precisamos considerar a sincronização da fila primeiro.
 Fig. 7. O Broker 3 está de volta ao serviço. Todas as filas principais em um nó!
Fig. 7. O Broker 3 está de volta ao serviço. Todas as filas principais em um nó!Portanto, agora você deve ter uma idéia de como os espelhos fornecem redundância e tolerância a falhas. Isso garante a disponibilidade no caso de falha de um único nó e protege contra a perda de dados. Mas ainda não terminamos, porque na realidade tudo é muito mais complicado.
Sincronizar
Ao criar um novo espelho, todas as novas mensagens sempre serão replicadas para esse espelho e para quaisquer outras. Quanto aos dados existentes na fila principal, podemos replicá-los em um novo espelho, que se torna uma cópia completa do mestre. Também não podemos replicar mensagens existentes e permitir que a fila principal e o novo espelho converjam no tempo em que novas mensagens chegam ao final e as mensagens existentes saem da cabeça da fila principal.
Essa sincronização é realizada automática ou manualmente e é controlada usando uma diretiva de fila. Considere um exemplo.
Temos duas linhas espelhadas. A fila A é sincronizada automaticamente e a fila B manualmente. Ambas as linhas têm dez mensagens cada.
 Fig. 8. Duas filas com diferentes modos de sincronização
Fig. 8. Duas filas com diferentes modos de sincronizaçãoAgora estamos perdendo o Broker 3.
 Fig. 9. O broker 3 caiu
Fig. 9. O broker 3 caiuO Broker 3 está de volta ao serviço. O cluster cria um espelho para cada fila no novo nó e sincroniza automaticamente a nova Fila A com o mestre. No entanto, o espelho da nova curva B permanece vazio. Portanto, temos uma redundância completa da Fila A e apenas um espelho para as mensagens existentes da Fila B.
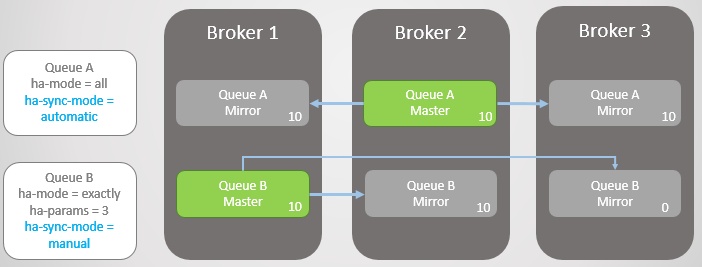 Fig. 10. O novo espelho da Fila A recebe todas as mensagens existentes, mas o novo espelho da Fila B não
Fig. 10. O novo espelho da Fila A recebe todas as mensagens existentes, mas o novo espelho da Fila B nãoAmbas as linhas recebem mais dez mensagens. Em seguida, o Broker 2 cai e a Fila A retorna ao espelho mais antigo, localizado no Broker 1. No caso de uma falha, não há perda de dados. Existem vinte mensagens na Fila B no assistente e apenas dez no espelho, pois essa fila nunca replicou as dez mensagens originais.
 Fig. 11. A linha A é revertida para o Broker 1 sem perder mensagens
Fig. 11. A linha A é revertida para o Broker 1 sem perder mensagensAmbas as linhas recebem mais dez mensagens. O Broker 1. agora trava.A fila A muda para o espelho sem problemas sem perder mensagens. No entanto, a fila B tem problemas. Nesse ponto, podemos otimizar acessibilidade ou consistência.
Se quisermos otimizar a acessibilidade, a política de
promover sob falha deve ser definida como
sempre . Esse é o valor padrão, portanto, você pode simplesmente omitir a política. Nesse caso, de fato, permitimos falhas em espelhos não sincronizados. Isso resultará na perda de mensagens, mas a fila permanece legível e gravável.
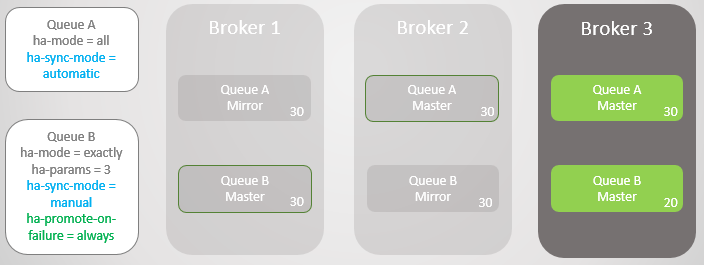 Fig. 12. A linha A é revertida para o Broker 3 sem perder mensagens. A linha B volta ao Broker 3 com a perda de dez mensagens
Fig. 12. A linha A é revertida para o Broker 3 sem perder mensagens. A linha B volta ao Broker 3 com a perda de dez mensagensTambém podemos definir
ha-promote-on-failure como
when-synced . Nesse caso, em vez de reverter para o espelho, a fila aguardará até que o Broker 1 com seus dados retorne ao modo online. Após seu retorno, a fila principal aparece novamente no Broker 1 sem perda de dados. A acessibilidade é sacrificada para segurança dos dados. Mas esse é um modo arriscado, que pode até levar a uma completa perda de dados, que consideraremos em um futuro próximo.
 Fig. 13. A linha B permanece indisponível após a perda do Broker 1
Fig. 13. A linha B permanece indisponível após a perda do Broker 1Você pode fazer uma pergunta: “Talvez seja melhor nunca usar a sincronização automática?”. A resposta é que a sincronização é uma operação de bloqueio. Durante a sincronização, a fila principal não pode executar nenhuma operação de leitura ou gravação!
Considere um exemplo. Agora temos filas muito longas. Como eles podem crescer para esse tamanho? Por várias razões:
- Filas não são usadas ativamente.
- São linhas de alta velocidade e, no momento, os consumidores são lentos
- São filas de alta velocidade, ocorreu uma falha e os consumidores estão alcançando
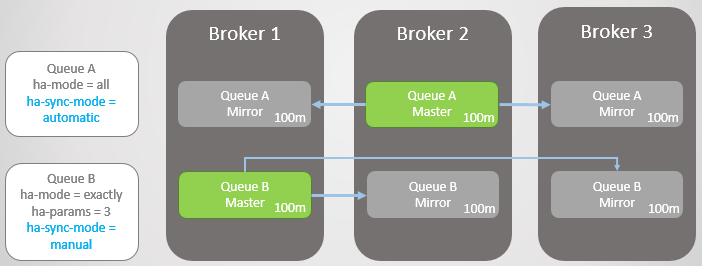 Fig. 14. Duas filas grandes com diferentes modos de sincronização
Fig. 14. Duas filas grandes com diferentes modos de sincronizaçãoAgora o Broker 3 falha.
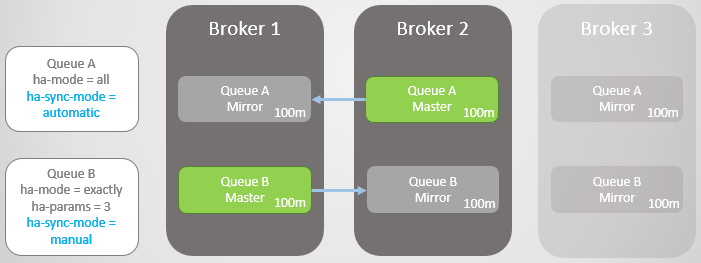 Fig. 15. O corretor 3 cai, deixando um mestre e um espelho em cada fila
Fig. 15. O corretor 3 cai, deixando um mestre e um espelho em cada filaO Broker 3 retorna e novos espelhos são criados. A fila principal A começa a replicar as mensagens existentes para um novo espelho e, durante esse período, a fila A fica indisponível. A replicação de dados requer duas horas, resultando em duas horas de inatividade para esta fila!
No entanto, a linha B permanece disponível durante todo o período. Ela sacrificou alguma redundância por uma questão de acessibilidade.
 Fig. 16. A fila permanece indisponível durante a sincronização
Fig. 16. A fila permanece indisponível durante a sincronizaçãoApós duas horas, a Fila A também fica disponível e pode novamente começar a aceitar operações de leitura e gravação.
Atualizações
Esse comportamento de bloqueio durante a sincronização dificulta a atualização de clusters com filas muito grandes. Em algum momento, o nó com o assistente precisa ser reiniciado, o que significa alternar para o espelho ou desativar a fila durante a atualização do servidor. Se escolhermos uma transição, perderemos mensagens se os espelhos não estiverem sincronizados. Por padrão, quando um broker é desativado, a transição para um espelho não sincronizado não é executada. Isso significa que, assim que o corretor retorna, não perdemos nenhuma mensagem, o único dano foi apenas uma fila simples. A desativação de intermediários é regida pela política de
ha-promote-on-shutdown . Você pode definir um dos dois valores:
always = enabled alternando para espelhos não sincronizados
when-synced = alterna apenas para o espelho sincronizado; caso contrário, a fila se torna inacessível para leitura e gravação. A fila retorna assim que o broker retorna
De uma forma ou de outra, com grandes filas, você deve escolher entre perda e inacessibilidade de dados.
Quando a disponibilidade melhora a segurança dos dados
Antes de tomar uma decisão, mais uma complicação deve ser levada em consideração. Embora a sincronização automática seja melhor para redundância, como isso afeta a segurança dos dados? Obviamente, graças à melhor redundância, o RabbitMQ tem menos chances de perder as mensagens existentes, mas e as novas mensagens dos editores?
Aqui você precisa considerar o seguinte:
- Um editor pode simplesmente retornar um erro e um serviço ou usuário superior tentará novamente mais tarde?
- Um editor pode salvar uma mensagem localmente ou em um banco de dados para tentar novamente mais tarde?
Se o publicador conseguir apenas soltar a mensagem, de fato, melhorar a acessibilidade também aumentará a segurança dos dados.
Portanto, você precisa procurar um equilíbrio, e a decisão depende da situação específica.
Problemas com ha-promover-em-falha = quando sincronizado
A idéia de
ha-promover-em-falha =
quando sincronizado é que impedimos a mudança para um espelho não sincronizado e, assim, evitamos a perda de dados. A fila permanece inacessível para leitura ou gravação. Em vez disso, tentamos retornar um broker caído com dados não danificados para que ele retome o trabalho como mestre sem perda de dados.
Mas (e isso é grande, mas) se o corretor perdeu seus dados, temos um grande problema: a fila está perdida! Todos os dados se foram! Mesmo se você tiver espelhos que alcançam basicamente a fila principal, esses espelhos também serão descartados.
Para incluir novamente um nó com o mesmo nome, pedimos ao cluster para esquecer o nó perdido (com o
comando rabbitmqctl forget_cluster_node ) e inicie um novo broker com o mesmo nome de host. Enquanto o cluster se lembrar do nó perdido, ele se lembrará da fila antiga e dos espelhos não sincronizados. Quando um cluster é solicitado a esquecer um nó perdido, essa fila também é esquecida. Agora você precisa declará-lo novamente. Perdemos todos os dados, embora tivéssemos espelhos com um conjunto de dados parciais. Seria melhor mudar para um espelho não sincronizado!
Portanto, a sincronização manual (e falha de sincronização) em combinação com
ha-promote-on-failure=when-synced , na minha opinião, é bastante arriscada. Os documentos dizem que essa opção existe para segurança de dados, mas é uma faca de dois gumes.
Mestres de reequilíbrio
Como prometido, voltamos ao problema da acumulação de todos os mestres em um ou mais nós. Isso pode acontecer mesmo como resultado das atualizações contínuas do cluster sem interrupção. Em um cluster com três nós, todas as filas principais serão acumuladas em um ou dois nós.
O reequilíbrio dos mestres pode ser problemático por dois motivos:
- Não há boas ferramentas de reequilíbrio
- Sincronização de Filas
Para o reequilíbrio, há um
plug-in de terceiros que não é oficialmente suportado. Em relação aos plug-ins de terceiros, o manual do RabbitMQ
diz : “O plug-in fornece algumas ferramentas adicionais de configuração e relatórios, mas não é suportado e não é testado pela equipe do RabbitMQ. Use por sua conta e risco.
Há outro truque para mover a fila principal pelas políticas de alta disponibilidade. O manual menciona um
script para isso. Funciona da seguinte maneira:
- Exclui todos os espelhos usando uma política temporária com uma prioridade mais alta que a política de alta disponibilidade existente.
- Altera a política temporária de alta disponibilidade para usar o modo de nós com o nó para o qual a fila principal precisa ser movida.
- Sincroniza a fila para migração forçada.
- Após a conclusão da migração, exclui a política temporária. A política inicial de alta disponibilidade entra em vigor e o número necessário de espelhos é criado.
A desvantagem é que essa abordagem pode não funcionar se você tiver filas grandes ou requisitos estritos de redundância.
Agora vamos ver como os clusters RabbitMQ funcionam com partições de rede.
Interrupção da conectividade
Os nós de um sistema distribuído são conectados por links de rede, e os links de rede podem e serão desconectados. A frequência das interrupções depende da infraestrutura local ou da confiabilidade da nuvem selecionada. Em qualquer caso, os sistemas distribuídos devem ser capazes de lidar com eles. Novamente, temos uma escolha entre acessibilidade e consistência, e novamente a boa notícia é que o RabbitMQ fornece os dois (mas não ao mesmo tempo).
Com o RabbitMQ, temos duas opções principais:
- Permitir separação lógica (cérebro dividido). Isso fornece acessibilidade, mas pode causar perda de dados.
- Não permitir separação lógica. Pode resultar em uma perda de disponibilidade a curto prazo, dependendo de como os clientes se conectam ao cluster. Também pode levar à inacessibilidade completa em um cluster de dois nós.
Mas o que é separação lógica? É quando um cluster é dividido em dois devido à perda de conexões de rede. De cada lado, os espelhos sobem para o mestre, portanto, no final, existem vários mestres em cada turno.
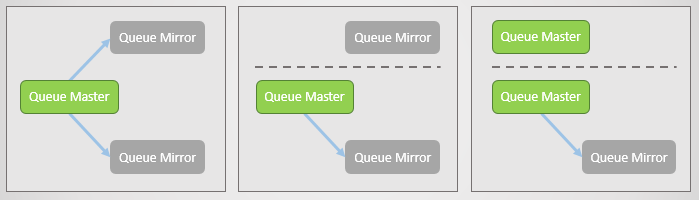 Fig. 17. A linha principal e dois espelhos, cada um em um nó separado. Em seguida, ocorre uma falha na rede e um espelho se separa. O nó desanexado vê que os outros dois caíram e avança seus espelhos para o mestre. Agora, temos duas linhas principais, e ambas permitem escrever e ler.
Fig. 17. A linha principal e dois espelhos, cada um em um nó separado. Em seguida, ocorre uma falha na rede e um espelho se separa. O nó desanexado vê que os outros dois caíram e avança seus espelhos para o mestre. Agora, temos duas linhas principais, e ambas permitem escrever e ler.Se os editores enviarem dados para os dois mestres, obteremos duas cópias divergentes da fila.
Os vários modos RabbitMQ fornecem acessibilidade ou consistência.
Modo Ignorar (padrão)
Este modo fornece acessibilidade. Após a perda da conectividade, ocorre uma separação lógica. Após reconectar, o administrador deve decidir qual partição preferir. O lado perdedor será reiniciado e todos os dados acumulados desse lado serão perdidos.
 Fig. 18. Três publicadores estão associados a três corretores. Internamente, o cluster encaminha todas as solicitações para a fila principal no Broker 2.
Fig. 18. Três publicadores estão associados a três corretores. Internamente, o cluster encaminha todas as solicitações para a fila principal no Broker 2.Agora estamos perdendo o Corretor 3. Ele vê que outros corretores caíram e move o espelho para o mestre. Esta é a separação lógica.
 Fig. 19. Separação lógica (cérebro dividido). Os registros são divididos em duas linhas principais e duas cópias divergem.
Fig. 19. Separação lógica (cérebro dividido). Os registros são divididos em duas linhas principais e duas cópias divergem.A conectividade é restaurada, mas a separação lógica permanece. O administrador deve selecionar manualmente o lado perdedor. No caso a seguir, o administrador reinicia o Broker 3. Todas as mensagens que ele não conseguiu transmitir são perdidas.
 Fig. 20. O administrador desativa o Broker 3.
Fig. 20. O administrador desativa o Broker 3. Fig. 21. O administrador inicia o Broker 3 e ele ingressa no cluster, perdendo todas as mensagens que permaneceram lá.
Fig. 21. O administrador inicia o Broker 3 e ele ingressa no cluster, perdendo todas as mensagens que permaneceram lá.Durante a perda de conectividade e após sua restauração, o cluster e essa fila estavam disponíveis para leitura e gravação.
Modo de recuperação automática
Funciona de maneira semelhante ao modo Ignorar, exceto que o próprio cluster seleciona automaticamente o lado perdedor após dividir e restaurar a conectividade. O lado perdedor retorna ao cluster vazio e a fila perde todas as mensagens enviadas apenas para esse lado.
Pausar modo minoritário
Se não queremos permitir a separação lógica, nossa única opção é recusar a leitura e gravação no lado menor após a partição do cluster. Quando um corretor vê que ele está do lado menor, ele faz uma pausa, ou seja, fecha todas as conexões existentes e recusa quaisquer novas. Uma vez por segundo, ele verifica a reconexão. Depois de restaurada, a conectividade retoma o trabalho e ingressa no cluster.
 Fig. 22. Três publicadores estão associados a três corretores. Internamente, o cluster encaminha todas as solicitações para a fila principal no Broker 2.
Fig. 22. Três publicadores estão associados a três corretores. Internamente, o cluster encaminha todas as solicitações para a fila principal no Broker 2.Em seguida, os Brokers 1 e 2 são separados do Broker 3. Em vez de atualizar seu espelho para um mestre, o Broker 3 faz uma pausa e fica inacessível.
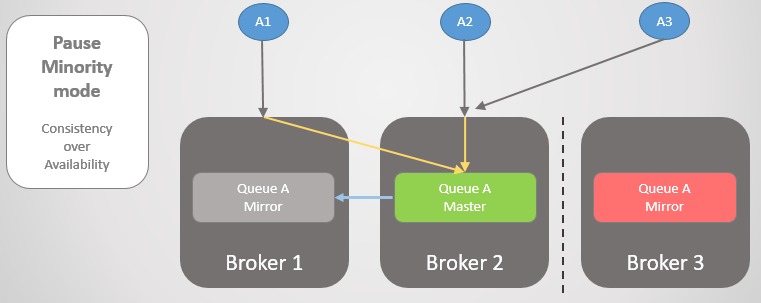 Fig. 23. O Broker 3 faz uma pausa, desconecta todos os clientes e rejeita solicitações de conexão.
Fig. 23. O Broker 3 faz uma pausa, desconecta todos os clientes e rejeita solicitações de conexão.Depois que a conectividade é restaurada, ela retorna ao cluster.
Vejamos outro exemplo, onde a linha principal está no Broker 3.
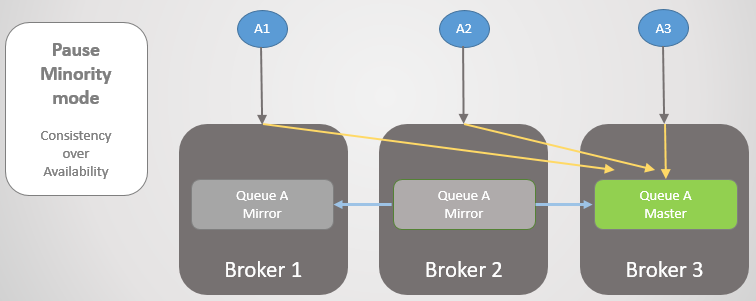 Fig. 24. A linha principal no Broker 3.
Fig. 24. A linha principal no Broker 3.Em seguida, ocorre a mesma perda de conectividade. O Broker 3 faz uma pausa porque está no lado menor. Por outro lado, os nós veem que o Broker 3 caiu, de modo que o espelho mais antigo dos Brokers 1 e 2 sobe para o mestre.
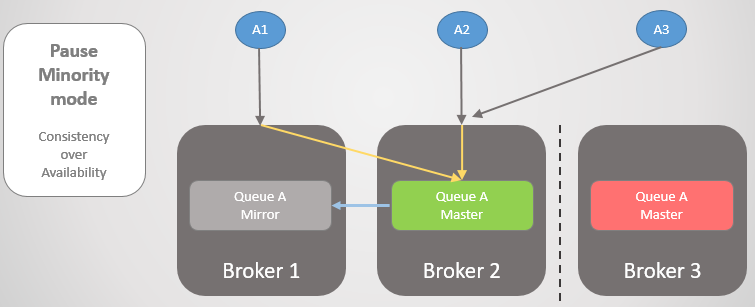 Fig. 25. Transição para o Broker 2 se o Broker 3 não estiver disponível.
Fig. 25. Transição para o Broker 2 se o Broker 3 não estiver disponível.Quando a conectividade é restaurada, o Broker 3 ingressa no cluster.
 Fig. 26. O cluster retornou à operação normal.
Fig. 26. O cluster retornou à operação normal.É importante entender que estamos obtendo consistência, mas também podemos obter acessibilidade
se transferirmos com êxito os clientes para a maior parte da seção. Para a maioria das situações, eu pessoalmente escolheria o modo Pausar Minoria, mas isso realmente depende do caso específico.
Para garantir a disponibilidade, é importante garantir que os clientes se conectem com êxito ao site. Considere nossas opções.
Conectividade do Cliente
Temos várias opções de como, após perder a conectividade, envia os clientes para a parte principal do cluster ou para os nós em funcionamento (após a falha de um nó). Primeiro, lembremos que uma fila específica está hospedada em um host específico, mas o roteamento e as políticas são replicadas em todos os hosts. Os clientes podem se conectar a qualquer nó, e o roteamento interno os direcionará quando necessário. Mas quando um nó é suspenso, ele rejeita a conexão, portanto, os clientes devem se conectar a outro nó. Se um nó cair, ele poderá fazer pouco.
Nossas opções:
- O cluster é acessado usando um balanceador de carga, que simplesmente percorre os nós e os clientes fazem repetidas tentativas de conexão até que sejam concluídos com êxito. , , ( ). , .
- / , . , , .
- , . , , .
- / DNS. TTL.
Conclusões
RabbitMQ . , :
. RabbitMQ , . , . RabbitMQ . RabbitMQ :
, :
ha-promote-on-failure=always
ha-sync-mode=manual
cluster_partition_handling=ignore ( autoheal )
- , , -
( ) :
- Publisher Confirms Manual Acknowledgements
ha-promote-on-failure=when-synced , ! =always .
ha-sync-mode=automatic ( ; , , )
- Pause Minority
; , (, ). Shovel.
- , , .
.
, RabbitMQ Docker Blockade, , .
:
№1 —
habr.com/ru/company/itsumma/blog/416629№2 —
habr.com/ru/company/itsumma/blog/418389№3 —
habr.com/ru/company/itsumma/blog/437446