Olá Habr!
Como parte da exploração do tópico do C # 8, sugerimos discutir o seguinte artigo sobre as novas regras para implementar interfaces.
 Observando atentamente como as
Observando atentamente como as interfaces são estruturadas
no C # 8 , é necessário considerar que, ao implementar interfaces, você pode quebrar a lenha por padrão.
Suposições relacionadas à implementação padrão podem levar a código corrompido, exceções de tempo de execução e desempenho ruim.Um dos recursos anunciados ativamente das interfaces C # 8 é que você pode adicionar membros a uma interface sem interromper os implementadores existentes. Mas a desatenção, neste caso, está repleta de grandes problemas. Considere o código no qual são feitas as suposições erradas - isso tornará mais claro o quanto é importante evitar esses problemas.
Todo o código deste artigo está publicado no GitHub: jeremybytes / interfaces-in-csharp-8 , especificamente no projeto DangerousAssumptions .
Nota: Este artigo discute os recursos do C # 8, atualmente implementados apenas no .NET Core 3.0. Nos exemplos que usei, Visual Studio 16.3.0 e .NET Core 3.0.100 .
Suposições sobre detalhes de implementaçãoA principal razão pela qual articulo esse problema é a seguinte: Encontrei um artigo na Internet em que o autor oferece código com suposições muito ruins sobre a implementação (não indicarei o artigo porque não quero que o autor seja enrolado com comentários; entrarei em contato com ele pessoalmente) .
O artigo fala sobre o quão boa é a implementação padrão, porque nos permite complementar as interfaces mesmo depois que o código já tiver implementadores. No entanto, várias suposições incorretas são feitas nesse código (o código está na pasta
BadInterface da pasta no meu projeto GitHub)
Aqui está a interface original:
O restante do artigo demonstra a implementação da interface MyFile (para mim, no arquivo
MyFile.cs ):
O artigo mostra como você pode adicionar o método
Rename com a implementação padrão e não interromperá a classe
MyFile existente.
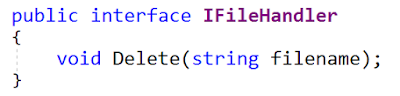
Aqui está a interface atualizada (do arquivo
IFileHandler.cs ):

O MyFile ainda funciona, então está tudo bem. Então Na verdade não.
Suposições ruinsO principal problema com o método Rename é o que uma suposição ENORME está associada a ele: implementações usam um arquivo físico localizado no sistema de arquivos.
Considere a implementação que eu criei para uso em um sistema de arquivos localizado na RAM. (Nota: este é o meu código. Não é de um artigo que eu critico. Você encontrará a implementação completa no arquivo
MemoryStringFileHandler.cs .)

Esta classe implementa um sistema de arquivos formal que usa um dicionário localizado na RAM, que contém arquivos de texto. Não há nada aqui que afete o sistema de arquivos físico; geralmente não há referências ao
System.IO .
Implementador com defeitoApós atualizar a interface, essa classe está danificada.
Se o código do cliente chamar o método Rename, ele gerará um erro de tempo de execução (ou, pior, renomeie o arquivo armazenado no sistema de arquivos).
Mesmo que nossa implementação funcione com arquivos físicos, ela pode acessar arquivos localizados no armazenamento em nuvem e esses arquivos não podem ser acessados através do System.IO.File.
Também existe um problema em potencial quando se trata de teste de unidade. Se o objeto simulado ou falso não for atualizado e o código testado for atualizado, ele tentará acessar o sistema de arquivos ao executar testes de unidade.
Como a suposição errada diz respeito à interface, os implementadores dessa interface estão corrompidos.
Medos irracionais?É inútil considerar esses medos infundados. Quando falo de abusos no código, eles me respondem: "Bem, é que uma pessoa não sabe como programar". Eu não posso discordar disso.
Geralmente faço isso: espero e vejo como isso funcionará. Por exemplo, eu tinha medo de que a possibilidade de "uso estático" fosse abusada. Até agora, isso não teve que ser convencido.
Deve-se ter em mente que essas idéias estão no ar; portanto, está ao nosso alcance ajudar outras pessoas a seguir um caminho mais conveniente, que não será tão difícil de seguir.
Problemas de desempenhoComecei a pensar em quais outros problemas poderiam nos esperar se fizéssemos suposições incorretas sobre os implementadores de interface.
No exemplo anterior, é chamado código que está fora da própria interface (nesse caso, fora do System.IO). Você provavelmente concordará que tais ações são um sino perigoso. Mas, se usarmos as coisas que já fazem parte da interface, tudo ficará bem, certo?
Nem sempre.
Como exemplo expresso, criei a interface IReader.
A interface de origem e sua implementaçãoAqui está a interface IReader original (do arquivo
IReader.cs - embora agora já haja atualizações neste arquivo):

Essa é uma interface genérica de método que permite obter uma coleção de itens somente leitura.
Uma das implementações dessa interface gera uma sequência de números de Fibonacci (sim, tenho um interesse prejudicial em gerar sequências de Fibonacci). Aqui está a interface
FibonacciReader (do arquivo
FibonacciReader.cs - também é atualizada no meu github):
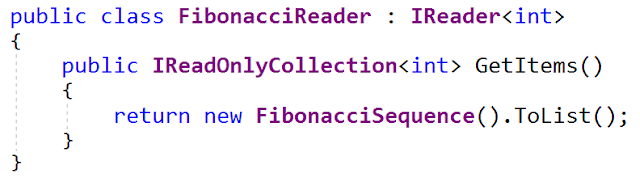
A classe
FibonacciSequence é uma implementação de
IEnumerable <int> (do arquivo FibonacciSequence.cs). Ele usa um número inteiro de 32 bits como tipo de dados, para que o estouro ocorra rapidamente.

Se você estiver interessado nesta implementação, dê uma olhada no meu
TDDing em uma sequência de Fibonacci no artigo
C # .
O projeto DangerousAssumptions é um aplicativo de console que exibe os resultados do FibonacciReader (do arquivo
Program.cs ):

E aqui está a conclusão:
 Interface atualizada
Interface atualizadaEntão agora temos o código de trabalho. Porém, mais cedo ou mais tarde, talvez seja necessário obter um elemento separado do IReader, e não a coleção inteira de uma só vez. Como usamos um tipo genérico com a interface e ainda não temos a propriedade "ID natural" no objeto, estenderemos o elemento localizado em um índice específico.
Aqui está nossa interface à qual o método
GetItemAt é
GetItemAt (da versão final do arquivo
IReader.cs ):

GetItemAt aqui assume uma implementação padrão. À primeira vista - não é tão ruim. Ele usa um membro da interface existente (
GetItems ), portanto, nenhuma suposição "externa" é feita aqui. Com os resultados, ele usa o método LINQ. Sou um grande fã do LINQ, e esse código, na minha opinião, é construído razoavelmente.
Diferenças de desempenhoComo a implementação padrão chama
GetItems , exige que a coleção inteira seja retornada antes que um item específico seja selecionado.
No caso de
FibonacciReader isso implica que todos os valores serão gerados. Em um formulário atualizado, o arquivo
Program.cs conterá o seguinte código:

Então, chamamos
GetItemAt . Aqui está a conclusão:

Se colocarmos um ponto de verificação dentro do arquivo FibonacciSequence.cs, veremos que toda a sequência é gerada para isso.
Após iniciar o programa, encontraremos esse ponto de controle duas vezes: primeiro ao chamar
GetItems e depois ao chamar
GetItemAt .
Suposição prejudicial ao desempenhoO problema mais sério com esse método é que ele requer a recuperação de toda a coleção de elementos. Se esse
IReader for retirá-lo do banco de dados, muitos elementos terão que ser extraídos dele e somente um deles será selecionado. Seria muito melhor se essa seleção final fosse tratada em um banco de dados.
Trabalhando com nosso
FibonacciReader , calculamos cada novo elemento. Assim, a lista inteira deve ser calculada inteiramente para obter apenas um elemento que precisamos. O cálculo da sequência de Fibonacci é uma operação que não carrega muito o processador, mas e se lidarmos com algo mais complicado, por exemplo, calcularemos números primos?
Você pode dizer: “Bem, temos um método
GetItems que retorna tudo. Se funcionar por muito tempo, provavelmente não deveria estar aqui. E esta é uma declaração honesta.
No entanto, o código de chamada não sabe nada sobre isso. Se eu ligar para
GetItems , sei que (provavelmente) minhas informações precisarão passar pela rede e esse processo
GetItems muito tempo. Se eu pedir um único item, por que devo esperar esses custos?
Otimização de desempenho específicaNo caso do
FibonacciReader podemos adicionar nossa própria implementação para melhorar significativamente o desempenho (na versão final do arquivo
FibonacciReader.cs ):

O método
GetItemAt substitui a implementação padrão fornecida na interface.
Aqui eu uso o mesmo método LINQ
ElementAt da implementação padrão. No entanto, eu não uso esse método com a coleção somente leitura que GetItems retorna, mas com FibonacciSequence, que é
IEnumerable .
Como
FibonacciSequence é
IEnumerable , a chamada para
ElementAt terminará assim que o programa atingir o elemento que selecionamos. Portanto, não geraremos a coleção inteira, mas apenas os elementos localizados até a posição especificada no índice.
Para tentar isso, deixe o ponto de controle que criamos acima no aplicativo e execute o aplicativo novamente. Desta vez, encontramos um ponto de interrupção apenas uma vez (ao chamar
GetItems ). Ao chamar
GetItemAt isso não acontecerá.
Um exemplo um pouco artificialEste exemplo é um pouco exagerado, porque, como regra, você não precisa selecionar elementos do conjunto de dados por índice. No entanto, você pode imaginar algo semelhante que poderia acontecer se estivéssemos trabalhando com a propriedade de identificação natural.
Se extraímos itens por ID, não por índice, podemos ter enfrentado os mesmos problemas de desempenho com a implementação padrão. A implementação padrão requer o retorno de todos os elementos, após o qual apenas um deles é selecionado. Se você permitir que o banco de dados ou outro "leitor" puxe um elemento específico por seu ID, essa operação seria muito mais eficiente.
Pense nas suas suposiçõesSuposições são indispensáveis. Se tentássemos levar em conta no código possíveis casos de uso de nossas bibliotecas, nenhuma tarefa seria concluída. Mas você ainda precisa considerar cuidadosamente as suposições no código.
Isso não significa que a implementação
GetElementAt seja necessariamente ruim. Sim, existem possíveis problemas de desempenho. No entanto, se os conjuntos de dados forem pequenos ou os elementos computados forem "baratos", a implementação padrão poderá ser um compromisso razoável.
No entanto, não aceito mudanças na interface depois que ela já possui implementadores. Mas entendo que também existem cenários em que as opções alternativas são preferidas. A programação é a solução de problemas e, ao solucionar problemas, é necessário avaliar os prós e contras inerentes a cada ferramenta e abordagem que usamos.
A implementação padrão pode prejudicar os implementadores de interface (e possivelmente o código que invocará essas implementações). Portanto, você precisa ter um cuidado especial com as suposições relacionadas às implementações padrão.
Boa sorte no seu trabalho!