
Boa tarde, quero compartilhar com você minha experiência em configurar e usar o serviço AWS EKS (Serviço Elástico Kubernetes) para contêineres do Windows, ou melhor, sobre a impossibilidade de usá-lo, e o bug encontrado no contêiner do sistema AWS, para aqueles que estão interessados neste serviço para contêineres do Windows, por favor sob gato.
Eu sei que os contêineres de janelas não são um tópico popular, e poucas pessoas os usam, mas mesmo assim decidiram escrever este artigo, pois havia alguns artigos sobre kubernetes e janelas no Habré e ainda existem essas pessoas.
Iniciar
Tudo começou com o fato de que, nos serviços da nossa empresa, foi decidido migrar para o kubernetes, são 70% de janelas e 30% de linux. Para isso, o serviço em nuvem do AWS EKS foi considerado como uma das opções possíveis. Até 8 de outubro de 2019, o AWS EKS Windows estava na Visualização pública, comecei com ele, a versão do kubernetes usava o antigo 1.11, mas decidi verificar de qualquer maneira e ver em que estágio esse serviço em nuvem está funcionando, se ele estava funcionando, não estava. um bug com a adição de remoção de lareiras, enquanto os antigos pararam de responder via ip interno a partir da mesma sub-rede que o nó do operador do Windows.
Portanto, foi decidido abandonar o uso do AWS EKS em favor de seu próprio cluster em kubernetes no mesmo EC2, apenas todo o balanceamento e HA teriam que ser descritos por mim mesmo por meio do CloudFormation.
Suporte para contêiner do Amazon EKS para Windows agora disponível em geral
por Martin Beeby | em 08 OUT 2019Não tive tempo de adicionar um modelo ao CloudFormation para o meu próprio cluster, pois vi essas notícias
Suporte para contêiner do Amazon EKS para Windows agora disponível em geralObviamente, adiei todos os meus desenvolvimentos e comecei a estudar o que eles fizeram para o GA e como tudo mudou com a Visualização pública. Sim Os companheiros da AWS atualizaram as imagens do nó de trabalho do Windows para a versão 1.14, bem como a versão de cluster 1.14 no EKS agora com suporte para nós do Windows. Eles fecharam o projeto Public Preview no
github e disseram que agora usam a documentação oficial aqui:
Suporte do EKS para WindowsIntegrando um cluster EKS na VPC e nas sub-redes atuais
Em todas as fontes, no link acima do anúncio e também na documentação, foi proposto implantar o cluster por meio do utilitário proprietário eksctl ou por meio do CloudFormation + kubectl depois, usando apenas sub-redes públicas na Amazon, além de criar uma VPC separada para um novo cluster.
Essa opção não é adequada para muitos; em primeiro lugar, uma VPC separada é o custo adicional de seu custo + tráfego de peering para sua VPC atual. O que fazer para aqueles que já possuem uma infraestrutura pronta na AWS com suas múltiplas contas, VPC, sub-redes, tabelas de rotas, gateway de trânsito e assim por diante? Obviamente, não quero desmembrar ou refazer tudo, e preciso integrar o novo cluster EKS à infraestrutura de rede atual usando a VPC existente e, para dividir, criar novas sub-redes para o cluster.
No meu caso, esse caminho foi escolhido, usei a VPC existente, adicionei apenas 2 sub-redes públicas e 2 sub-redes privadas ao novo cluster, é claro, todas as regras foram levadas em conta de acordo com a documentação para
Crie seu Amazon EKS Cluster VPC .
Havia também uma condição para nenhum nó de trabalho nas sub-redes públicas usando o EIP.eksctl vs CloudFormation
Farei uma reserva imediatamente de que tentei os dois métodos de implantação do cluster, nos dois casos a imagem era a mesma.
Vou mostrar um exemplo apenas com o uso do eksctl, pois o código é mais curto aqui. Usando o cluster eksctl deploy em 3 etapas:
1.Crie o próprio cluster + nó de trabalho do Linux no qual os contêineres do sistema e o infeliz controlador vpc serão colocados posteriormente.
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
Para implantar em uma VPC existente, basta especificar o ID de suas sub-redes e o eksctl determinará a própria VPC.
Para que seu nó de trabalho implante apenas na sub-rede privada, é necessário especificar --node-private-networking para o grupo de nós.
2. Instale o vpc-controller em nosso cluster, que processará nossos nós de trabalho contando o número de endereços IP livres, bem como o número de ENI na instância, adicionando e removendo-os.
eksctl utils install-vpc-controllers --name yyy --approve
3. Depois que os contêineres do sistema foram iniciados com êxito no nó do trabalhador Linux, incluindo o controlador vpc, resta apenas criar outro grupo de nós com os trabalhadores do Windows.
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
Depois que seu nó foi conectado com êxito ao cluster e tudo parece estar bem, ele está no status Pronto, mas não.
Erro no controlador vpc
Se tentarmos executar pods no nó do operador do Windows, obteremos um erro:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
Olhando mais profundamente, vemos que nossa instância da AWS se parece com isso:

E deve ser assim:

A partir disso, fica claro que o vpc-controller não funcionou por algum motivo e não pôde adicionar novos endereços IP à instância para que os pods pudessem usá-los.
Escalamos para olhar os logs de pod do controlador vpc e é isso que vemos:
kubectl log <vpc-controller-deployment> -n kube-system I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
As pesquisas no Google não levaram a nada, já que aparentemente ninguém havia detectado um bug desse tipo, bem, ou postado um problema nele, tive que pensar primeiro em todas as opções. A primeira coisa que veio à mente é que talvez o vpc-controller não possa ficar sóbrio com o ip-10-xxx.ap-xxx.compute.internal e chegar até ele e, portanto, os erros caem.
Sim, na verdade, usamos servidores DNS personalizados na VPC e, em princípio, não usamos servidores Amazon, portanto, mesmo o encaminhamento não foi configurado neste domínio ap-xxx.compute.internal. Marquei esta opção e ela não trouxe nenhum resultado, talvez o teste não estivesse limpo e, portanto, ao me comunicar com o suporte técnico, sucumbi à ideia deles.
Como não havia nenhuma idéia, todos os grupos de segurança foram criados pelo próprio eksctl, então não havia dúvida de que eles estavam funcionando, as tabelas de rotas também estavam corretas, nat, dns, também havia acesso à Internet com nós de trabalho.
Ao mesmo tempo, se você implantar o nó de trabalho na sub-rede pública sem usar --node-private-networking, esse nó foi imediatamente atualizado pelo vpc-controller e tudo funcionaria como um relógio.
Havia duas opções:
- Entre e espere que alguém descreva esse bug na AWS e eles o consertarão e você poderá usar o AWS EKS Windows com segurança, porque eles entraram no GA (demorou 8 dias no momento da escrita), provavelmente muitos seguirão o mesmo caminho que eu .
- Escreva para o Suporte da AWS e explique a eles a essência do problema com todo o conjunto de logs de todos os lugares e prove a eles que o serviço deles não funciona ao usar sua VPC e sub-redes; não foi em vão que contamos com suporte comercial, devemos usá-lo pelo menos uma vez :-)
Comunicação com engenheiros da AWS
Depois de criar um ticket no portal, escolhi responder-me por engano na Web - e-mail ou centro de suporte. Por essa opção, eles podem responder depois de alguns dias, apesar do fato de o meu ticket ter o Sistema de Gravidade prejudicado, o que implicava uma resposta dentro de <12 horas e, como o plano de suporte de negócios tem suporte 24 horas por dia, 7 dias por semana, eu esperava o melhor, mas acabou como sempre.
Meu ingresso chegou de Não atribuído de sexta a segunda-feira, então decidi escrevê-lo novamente e escolhi a opção de resposta de bate-papo. Após uma breve espera, Harshad Madhav foi nomeado para mim, e então começou ...
Debatemos com ele on-line por 3 horas seguidas, transferindo logs, implantando o mesmo cluster no laboratório da AWS para emular o problema, recriando o cluster da minha parte e assim por diante, a única coisa que viemos foi que os logs mostraram que a resolução não estava funcionando Os nomes de domínio interno da AWS, como escrevi acima, e Harshad Madhav me pediram para criar encaminhamento, supostamente usamos DNS personalizado e isso pode ser um problema.
Encaminhamento
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
O que foi feito, o dia acabou, Harshad Madhav cancelou a assinatura do cheque e ele deve funcionar, mas não, a resolução não ajudou.
Então houve uma conversa com mais dois engenheiros, um acabou de sair do bate-papo, aparentemente com medo de um caso complicado, o segundo passou meu dia novamente em um ciclo de depuração completo, enviando logs, criando agrupamentos de ambos os lados, no final, ele apenas disse bem, funciona para mim, aqui estou eu documentação oficial Eu faço tudo passo a passo e você e você terão sucesso.
Para o qual eu educadamente pedi que ele fosse embora e atribua outro ao meu bilhete, se você não souber onde procurar o problema.
Final
No terceiro dia, um novo engenheiro Arun B. foi designado para mim e, desde o início da comunicação com ele, ficou imediatamente claro que esses não eram três engenheiros anteriores. Ele leu toda a história e imediatamente pediu para coletar os logs com seu próprio script no ps1, que estava no seu github. Em seguida, todas as iterações de criação de clusters, saída dos resultados das equipes, coleta de logs seguiram novamente, mas Arun B. estava se movendo na direção certa, a julgar pelas perguntas feitas a mim.
Quando chegamos a incluir -stderrthreshold = debug em seu vpc-controller, e o que aconteceu depois? certamente não funciona) o pod simplesmente não inicia com esta opção, apenas -stderrthreshold = info funciona.
Foi aí que terminamos e Arun B. disse que tentaria reproduzir meus passos para obter o mesmo erro. No dia seguinte, recebi uma resposta de Arun B. Ele não retirou esse caso, mas assumiu o código de revisão do controlador vpc e encontrou o mesmo local onde funciona e por que não funciona:
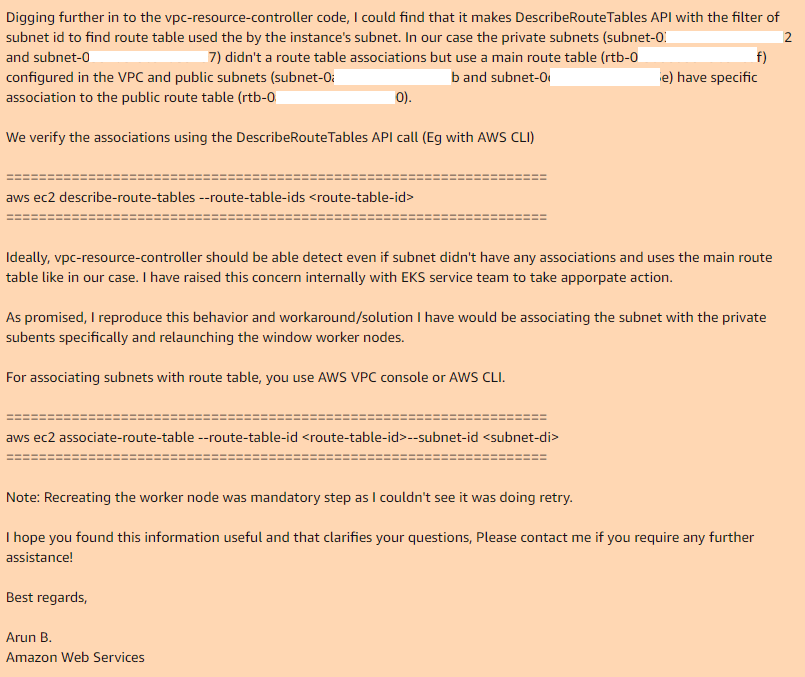
Portanto, se você usar a tabela de rotas principal em sua VPC, por padrão, ela não terá associações com as sub-redes necessárias; portanto, o controlador vpc necessário, no caso da sub-rede pública, possui uma tabela de rotas personalizada que possui uma associação.
Ao adicionar manualmente associações para a tabela de rotas principal com as sub-redes desejadas e recriar o grupo de nós, tudo funciona perfeitamente.
Espero que Arun B. realmente relate esse bug aos desenvolvedores do EKS e que vejamos uma nova versão do vpc-controller, e onde tudo funcione imediatamente. Atualmente, a versão mais recente: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
tem esse problema.
Obrigado a todos que leram até o final, teste tudo o que você usará na produção antes da implementação.
Atualização: Novo bug # 2
Depois de encontrar uma solução para o primeiro problema, continuamos a preparar esse serviço para nossas necessidades e, agora, no último estágio, encontramos outro bug incompatível com a vida.
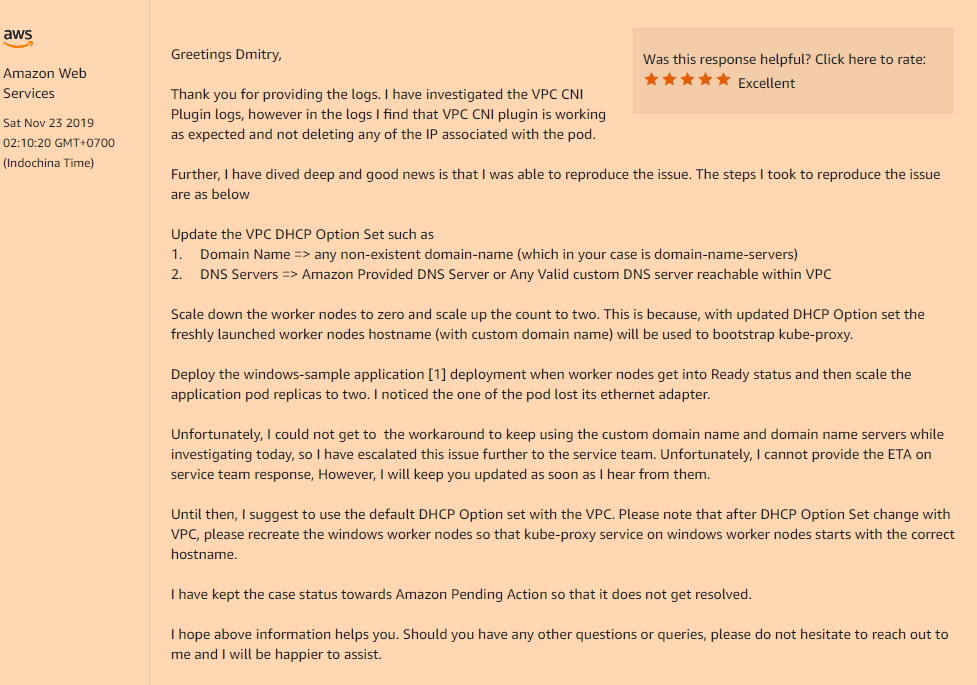
Problema:Implante o aplicativo no Kubernetes, defina sua implantação, réplicas> 1 e veja a figura a seguir. O novo pod inicia normalmente e funciona, enquanto o pod antigo perde sua interface de rede. Sim, sim, o pod antigo completamente sem rede, embora continue travando no estado Running. Reduza ou aumente réplicas, exclua os pods para que você nem sempre faça apenas o pod em que o último entrou no estado Em execução, o resto não funcionará. Independentemente disso, os pods ou em diferentes iniciam no mesmo nó.
Solução:Sim, novamente, o problema estava na configuração personalizada de nossa VPC, a saber, se você usar o conjunto de opções DHCP, que indica o valor personalizado do campo nome do domínio, ou estiver completamente vazio (como no meu caso, alterei apenas servidores de nomes de domínio, Eu não precisava do resto), você terá um problema incompreensível com o desaparecimento das interfaces de rede nos seus pods após o lançamento.
Você precisa registrá-lo no seu conjunto de opções DHCP:
domain-name = <aws-region-name>.compute.internal;
E depois disso é reinstalar todos os nós de trabalho para que durante a inicialização todos os componentes registrem as configurações corretas.
Abaixo estão os detalhes de como essa opção de nome de domínio afeta os nós do trabalhador:
Dessa vez, pedi que adicionassem pelo menos documentação ao AWS EKS para Windows, esses "recursos" de seus serviços.