Estamos preparando a próxima versão principal do Tokio, um ambiente de tempo de execução assíncrono para o Rust. Em 13 de outubro, uma
solicitação de pool com um agendador de tarefas completamente reescrito foi emitida para mesclagem em uma filial. O resultado serão enormes melhorias de desempenho e latência reduzida. Alguns testes registraram uma aceleração de dez vezes! Como sempre, testes sintéticos não refletem benefícios reais na realidade. Portanto, também verificamos como as alterações no agendador afetavam tarefas reais, como
Hyper e
Tonic (spoiler: o resultado é maravilhoso).
Preparando-me para trabalhar em um novo planejador, passei um tempo pesquisando recursos temáticos. Além das implementações reais, nada de especial foi encontrado. Também descobri que o código-fonte para implementações existentes é difícil de navegar. Para consertar isso, tentamos escrever o sheduler do Tokio da maneira mais limpa possível. Espero que este artigo detalhado sobre a implementação do agendador ajude aqueles que estão na mesma posição e, sem sucesso, à procura de informações sobre este tópico.
O artigo começa com uma revisão de alto nível do design, incluindo políticas de captura de trabalho. Depois, mergulhe nos detalhes de otimizações específicas no novo planejador Tokio.
Otimizações consideradas:
Como você pode ver, o tema principal é "redução". Afinal, o código mais rápido é a sua falta!
Também falaremos sobre o
teste do novo agendador . É muito difícil escrever o código paralelo correto, sem bloqueios. É melhor trabalhar devagar, mas corretamente, do que rapidamente, mas com falhas, principalmente se os erros estiverem relacionados à segurança da memória. A melhor opção, no entanto, deve funcionar rapidamente e sem erros, por isso escrevemos o
tear , uma ferramenta de teste de simultaneidade.
Antes de mergulhar no tópico, quero agradecer:
- @withoutboats e outros que trabalharam na função
async / await aguardada no Rust. Você fez um ótimo trabalho. Este é um recurso matador.
- @cramertj e outros que desenvolveram
std::task . Esta é uma grande melhoria em relação ao que era antes. E um ótimo código.
- Flutuante , o criador do Linkerd e , mais importante, o meu empregador. Obrigado por me deixar gastar tanto tempo neste trabalho. Se alguém estiver interessado na malha de serviço, dê uma olhada no Linkerd. Em breve, incluirá todos os benefícios discutidos neste artigo.
- Escolha uma implementação tão boa do planejador.
Tome uma xícara de café e sente-se. Este será um artigo longo.
Como os planejadores funcionam?
A tarefa do sheduler é planejar o trabalho. O aplicativo é dividido em unidades de trabalho, que chamaremos de
tarefas . Uma tarefa é considerada executável quando pode avançar em sua execução, mas não está mais concluída ou no modo inativo, quando está bloqueada em um recurso externo. As tarefas são independentes no sentido de que qualquer número de tarefas pode ser executado simultaneamente. O planejador é responsável pela execução de tarefas em um estado de execução até que retornem ao modo de espera. A execução da tarefa implica atribuir o tempo do processador à tarefa - um recurso global.
O artigo discute agendadores de espaço do usuário, ou seja, trabalhando sobre os encadeamentos do sistema operacional (que, por sua vez, são controlados por um sheduler no nível do kernel). O agendador Tokio executa futuros de Rust, que podem ser considerados como "threads verdes assíncronos". Esse é um padrão de
fluxo misto M: N no qual muitas tarefas da interface do usuário são multiplexadas em vários encadeamentos do sistema operacional.
Existem muitas maneiras diferentes de simular um sheduler, cada um com seus próprios prós e contras. No nível mais básico, o planejador pode ser modelado como uma
fila de execução e um
processador que o separa. Um processador é um pedaço de código que é executado em um encadeamento. No pseudo-código, ele faz o seguinte:
while let Some(task) = self.queue.pop() { task.run(); }
Quando uma tarefa se torna viável, ela é inserida na fila de execução.
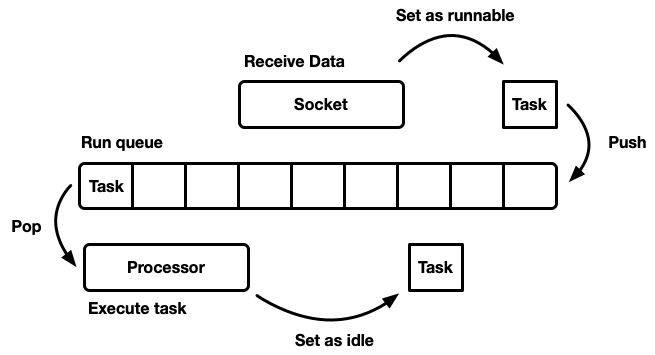
Embora você possa criar um sistema no qual recursos, tarefas e um processador existam no mesmo encadeamento, o Tokio prefere usar vários encadeamentos. Vivemos em um mundo onde um computador possui muitos processadores. O desenvolvimento de um agendador de rosca única levará ao carregamento insuficiente de ferro. Queremos usar todas as CPUs. Existem várias maneiras de fazer isso:
- Uma fila de execução global, muitos processadores.
- Muitos processadores, cada um com sua própria fila de execução.
Uma vez, muitos processadores
Este modelo possui uma fila de execução global. Quando as tarefas são concluídas, elas são colocadas no final da fila. Existem vários processadores, cada um em um thread separado. Cada processador retira uma tarefa do início da fila ou bloqueia o encadeamento se não houver tarefas disponíveis.
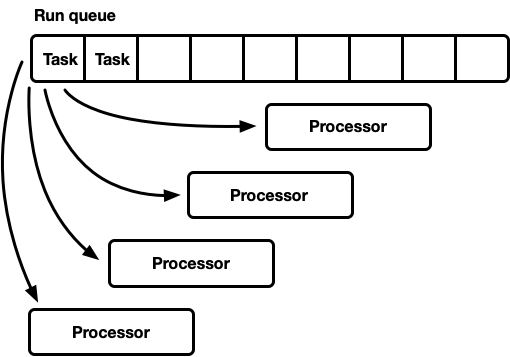
A linha de execução deve ser suportada por muitos fabricantes e consumidores. Geralmente, é usada uma lista
intrusiva , na qual a estrutura de cada tarefa inclui um ponteiro para a próxima tarefa na fila (em vez de agrupar as tarefas em uma lista vinculada). Assim, a alocação de memória para operações push e pop pode ser evitada. Você pode usar
a operação push sem travar , mas para coordenar os consumidores, o mutex é necessário para a operação pop (é tecnicamente possível implementar uma fila de multiusuários sem travar).
No entanto, na prática, a sobrecarga para proteção adequada contra bloqueios é mais do que apenas usar um mutex.
Essa abordagem geralmente é usada para um pool de threads de uso geral, porque possui várias vantagens:
- As tarefas são bastante planejadas.
- Implementação relativamente simples. Uma fila mais ou menos padrão faz interface com o ciclo do processador descrito acima.
Uma breve nota sobre o planejamento justo (eqüitativo). Isso significa que as tarefas são realizadas honestamente: quem veio antes foi quem saiu antes. Planejadores de uso geral tentam ser justos, mas há exceções, como a paralelização por junção de forquilha, em que a velocidade de cálculo do resultado, em vez da justiça para cada subtarefa individual, é um fator importante.
Este modelo tem uma desvantagem. Todos os processadores se candidatam a tarefas do início da fila. Para threads de uso geral, isso geralmente não é um problema. O tempo para concluir uma tarefa excede em muito o tempo para recuperá-la da fila. Quando as tarefas são executadas por um longo período, a competição na fila é reduzida. No entanto, espera-se que as tarefas assíncronas de Rust sejam concluídas muito rapidamente. Nesse caso, os custos indiretos da luta na fila aumentam significativamente.
Simultaneidade e simpatia mecânica
Para alcançar o desempenho máximo, precisamos aproveitar ao máximo os recursos de hardware. O termo “simpatia mecânica” por software foi usado pela primeira vez por
Martin Thompson (cujo blog não é mais atualizado, mas ainda é muito informativo).
Uma discussão detalhada da implementação do paralelismo em equipamentos modernos está além do escopo deste artigo. De um modo geral, o ferro aumenta a produtividade não devido à aceleração, mas devido à introdução de um número maior de núcleos de CPU (até meu laptop tem seis!). Cada núcleo pode executar grandes quantidades de computação em pequenos intervalos de tempo. Ações como acessar o cache e a memória levam
muito mais tempo em relação ao tempo de execução na CPU. Portanto, para acelerar os aplicativos, você precisa maximizar o número de instruções da CPU para cada acesso à memória. Embora o compilador ajude muito, ainda precisamos pensar em coisas como alinhamento e padrões de acesso à memória.
Threads separados funcionam separadamente como um único thread isolado,
até que vários threads modifiquem simultaneamente a mesma linha de cache (mutações simultâneas) ou seja necessária
consistência consistente . Nesse caso, o
protocolo de coerência do cache da
CPU é ativado. Garante a relevância do cache de cada CPU.
A conclusão é óbvia: na medida do possível, evite a sincronização entre os threads, pois é lento.
Muitos processadores, cada um com sua própria fila de execução
Outro modelo são vários agendadores de thread único. Cada processador recebe sua própria fila de execução e as tarefas são fixadas em um processador específico. Isso evita completamente o problema de sincronização. Como o modelo de tarefa Rust requer a capacidade de enfileirar uma tarefa a partir de qualquer encadeamento, ainda deve haver uma maneira segura de encadeamento de inserir tarefas no planejador. A fila de execução de cada processador suporta MPSC (thread-safe push operation) ou cada processador possui
duas filas de execução: não sincronizadas e thread-safe.
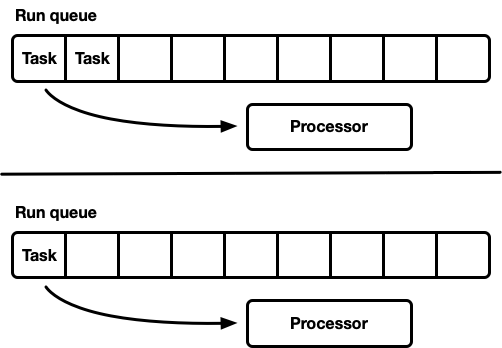
Essa estratégia usa o
Seastar . Como quase completamente evitamos a sincronização, essa estratégia fornece uma velocidade muito boa. Mas ela não resolve todos os problemas. Se a carga de trabalho não for completamente homogênea, alguns processadores estarão com carga, enquanto outros ficarão ociosos, o que levará ao uso não ideal de recursos. Isso acontece porque as tarefas são corrigidas em um processador específico. Quando um grupo de tarefas é planejado em um pacote em um processador, ele cumpre sozinho o pico de carga, mesmo que outros estejam ociosos.
A maioria das cargas de trabalho "reais" não é homogênea. Portanto, planejadores de uso geral geralmente evitam esse modelo.
Agendador de captura de tarefas
O planejador com planejadores de roubo de trabalho é baseado no modelo do planejador fragmentado e resolve o problema do carregamento incompleto de recursos de hardware. Cada processador suporta sua própria fila de execução. As tarefas que são executadas são colocadas na fila de execução do processador atual e funcionam nele. Mas quando o processador está ocioso, ele verifica as filas do processador irmão e tenta pegar algo a partir daí. O processador entra no modo de suspensão somente depois que não consegue encontrar trabalho nas filas de execução ponto a ponto.

No nível do modelo, essa é a melhor abordagem dos dois mundos. Sob carga, os processadores trabalham de forma independente, evitando a sincronização de sobrecarga. Nos casos em que a carga entre os processadores é distribuída de maneira desigual, o planejador pode redistribuí-la. É por isso que esses agendadores são usados em
Go ,
Erlang ,
Java e outras linguagens.
A desvantagem é que essa abordagem é muito mais complicada. O algoritmo de fila deve suportar a captura de tarefas e, para uma execução suave, é necessária
alguma sincronização entre processadores. Se não for implementado corretamente, a sobrecarga para captura poderá ser maior que o ganho.
Considere esta situação: o processador A está atualmente executando uma tarefa e possui uma fila de execução vazia. O processador B está ocioso; ele tenta capturar alguma tarefa, mas falha, então entra no modo de suspensão. Em seguida, 20 tarefas são geradas a partir da tarefa do processador A. Idealmente, o processador B deve acordar e pegar alguns deles. Para isso, é necessário implementar certas heurísticas no planejador, onde os processadores sinalizam para os processadores pares adormecidos sobre a aparência de novas tarefas em sua fila. Obviamente, isso requer sincronização adicional, para que essas operações sejam melhor minimizadas.
Em resumo:
- Quanto menos sincronização, melhor.
- A captura de trabalho é o algoritmo ideal para planejadores de uso geral.
- Cada processador funciona independentemente dos outros, mas é necessária alguma sincronização para capturar o trabalho.
Agendador Tokio 0.1
O primeiro agendador de trabalho do Tokio foi lançado em março de 2018. Esta foi a primeira tentativa, com base em algumas suposições que se mostraram erradas.
Primeiro, o agendador do Tokio 0.1 sugeriu que os threads do processador fossem fechados se estivessem ociosos por um certo período de tempo. O planejador foi criado originalmente como um sistema "de uso geral" para o pool de threads Rust. Naquela época, o tempo de execução dos Tokio ainda estava em um estágio inicial de desenvolvimento. Em seguida, o modelo assumiu que as tarefas de E / S seriam executadas no mesmo encadeamento que o seletor de E / S (epoll, kqueue, iocp ...). Mais tarefas computacionais podem ser direcionadas para o conjunto de encadeamentos. Nesse contexto, a configuração flexível do número de encadeamentos ativos é assumida; portanto, faz mais sentido desabilitar os encadeamentos inativos. No entanto, no planejador com captura de tarefas, o modelo passou a executar
todas as tarefas assíncronas e, nesse caso, faz sentido manter sempre um pequeno número de encadeamentos no estado ativo.
Em segundo lugar, uma linha de
viga cruzada de duas vias foi implementada
lá . Essa implementação é baseada na
linha Chase-Lev bidirecional e não é adequada para o planejamento de tarefas assíncronas independentes pelos motivos descritos abaixo.
Em terceiro lugar, a implementação acabou sendo muito complicada. Isso se deve em parte ao fato de esse ter sido meu primeiro agendador de tarefas. Além disso, fiquei impaciente ao usar atômicos em galhos, onde o mutex teria se saído bem. Uma lição importante é que muitas vezes são os mutexes que funcionam melhor.
Finalmente, houve muitas pequenas falhas na implementação inicial. Nos primeiros anos, os detalhes de implementação do modelo assíncrono de Rust evoluíram significativamente, mas as bibliotecas mantiveram a API estável o tempo todo. Isso levou ao acúmulo de alguma dívida técnica.
Agora, a Tokio está se aproximando do primeiro grande lançamento - e podemos pagar toda essa dívida, além de aprender com a experiência adquirida ao longo dos anos de desenvolvimento. Este é um momento emocionante!
Agendador Tokio da próxima geração
Agora é hora de examinar mais de perto o que mudou no novo planejador.
Novo sistema de tarefas
Primeiro, é importante destacar o que
não faz parte do Tokio, mas é crucial em termos de melhoria da eficiência: este é um
novo sistema de tarefas no
std , originalmente desenvolvido por
Taylor Kramer . Este sistema fornece os ganchos que o planejador deve implementar para executar tarefas assíncronas do Rust, e o sistema é verdadeiramente projetado e implementado de maneira excelente. É muito mais leve e mais flexível que a iteração anterior.
A estrutura
Waker dos recursos sinaliza que há uma tarefa
viável que deve ser colocada na fila do planejador. No novo sistema de tarefas, essa é uma estrutura de dois ponteiros, enquanto antes era muito maior. Reduzir o tamanho é importante para minimizar a sobrecarga de copiar o valor do
Waker em locais diferentes e ocupa menos espaço nas estruturas, o que permite espremer dados mais importantes na linha de cache. O design do
vtable fez várias otimizações, as quais discutiremos mais adiante.
Escolhendo o melhor algoritmo de fila
A fila de execução está no centro do planejador. Portanto, este é o componente mais importante a ser corrigido. O planejador Tokio original usava uma
fila de mão cruzada de duas vias: uma implementação de fonte única (produtor) e muitos consumidores. Uma tarefa é colocada em uma extremidade e os valores são recuperados na outra. Na maioria das vezes, o encadeamento "empurra" os valores do final da fila, mas às vezes outros encadeamentos interceptam o trabalho, executando a mesma operação. A fila de mão dupla é suportada por uma matriz e um conjunto de índices que rastreiam a cabeça e a cauda. Quando a fila está cheia, a introdução dela levará a um aumento no espaço de armazenamento. Uma nova matriz maior é alocada e os valores são movidos para o novo armazenamento.
A capacidade de crescer é alcançada através da complexidade e das despesas gerais. As operações push / pop devem levar em consideração esse crescimento. Além disso, a liberação da matriz original está repleta de dificuldades adicionais. Em uma linguagem de coleta de lixo (GC), a matriz antiga ficará fora do escopo e, eventualmente, o GC a limpará. No entanto, o Rust é enviado sem um GC. Isso significa que nós mesmos somos responsáveis por liberar a matriz, mas os threads podem tentar acessar a memória ao mesmo tempo. Para resolver esse problema, a viga cruzada usa uma estratégia de recuperação baseada em época. Embora não exija muitos recursos, ele adiciona uma sobrecarga não trivial ao caminho principal (caminho ativo). Agora, cada operação deve executar operações de leitura-modificação-gravação atômica (RMW) na entrada e saída de seções críticas para sinalizar para outros segmentos que a memória está em uso e não pode ser limpa.
Devido à sobrecarga do crescimento da fila de execução, faz sentido pensar: o suporte a esse crescimento é realmente necessário? Essa pergunta finalmente me levou a reescrever o planejador. A nova estratégia é ter um tamanho de fila fixo para cada processo. Quando a fila está cheia, em vez de aumentar a fila local, a tarefa se move para a fila global com vários consumidores e vários produtores. Os processadores verificarão periodicamente essa fila global, mas com uma frequência muito menor que a local.
Como parte de uma das primeiras experiências, substituímos a viga
cruzada por
mpmc . Isso não levou a uma melhoria significativa devido à quantidade de sincronização para push e pop. A chave para capturar o trabalho é que quase não há concorrência nas filas sob carga, pois cada processador acessa apenas sua própria fila.
Nesse estágio, decidi estudar cuidadosamente as fontes Go - e descobri que elas usam um tamanho de fila fixo com um fabricante e vários consumidores, com sincronização mínima, o que é muito impressionante. Para adaptar o algoritmo ao agendador Tokio, fiz algumas alterações. Vale ressaltar que a implementação Go usa operações atômicas sequenciais (como eu a entendo). A versão Tokio também reduz o número de algumas operações de cópia em ramificações de código mais raras.
Uma implementação de fila é um buffer circular que armazena valores em uma matriz. A cabeça e a cauda da fila são rastreadas por operações atômicas com valores inteiros.
struct Queue {
O enfileiramento é realizado por um único encadeamento:
loop { let head = self.head.load(Acquire);
Observe que nesta função de
push , as únicas operações atômicas são carregadas com
Acquire pedidos e salvar com
Release pedidos. Não há operações RMW (
compare_and_swap ,
fetch_and ...) ou ordem sequencial, como antes. Isso é importante porque nos chips x86 todos os downloads / salvamentos já são "atômicos". Assim, no nível da CPU,
esta função não será sincronizada . As operações atômicas impedirão certas otimizações no compilador, mas isso é tudo. Provavelmente, a primeira operação de
load pode ser realizada com segurança com pedidos
Relaxed , mas a substituição não carrega nenhuma sobrecarga perceptível.
Quando a fila está cheia,
push_overflow é
push_overflow .
Essa função move metade das tarefas da fila local para a global. A fila global é uma lista intrusiva protegida por um mutex. Ao mover para a fila global, as tarefas são primeiro vinculadas, então um mutex é criado e todas as tarefas são inseridas atualizando o ponteiro na cauda da fila global. Isso economiza um tamanho pequeno de seção crítica.Se você estiver familiarizado com os detalhes do pedido de memória atômica, poderá notar um "problema" em potencial com a função mostrada acima push. A operação de loadordenação atômica é Acquirebastante fraca. Ele pode retornar valores obsoletos, ou seja, uma operação de captura paralela já pode aumentar o valor self.head, mas no cache do fluxopusho valor antigo permanecerá, portanto, não notará a operação de captura. Isso não é um problema com a correção do algoritmo. Da maneira principal (rápida), pushnos preocupamos apenas com a fila local estar cheia ou não. Como apenas o encadeamento atual pode empurrar a fila, uma operação desatualizada loadsimplesmente fará com que a fila pareça mais cheia do que realmente é. Pode determinar incorretamente que a fila está cheia e causar push_overflow, mas essa função inclui uma operação atômica mais forte. Se push_overflowdeterminar que a fila não está realmente cheia, retornará w / Erre a operação pushserá iniciada novamente. Esta é outra razão pela qualpush_overflowmove metade da fila de execução para a fila global. Após esse movimento, esses falsos positivos ocorrem com muito menos frequência.Local pop(do processador ao qual a fila pertence) também é implementado simplesmente: loop { let head = self.head.load(Acquire);
Nesta função, um atômico loade um compare_and_swaps Release. A sobrecarga principal vem compare_and_swap.A função stealé semelhante a pop, mas a self.tailcarga atômica deve ser transferida de . Além disso, da mesma forma push_overflow, a operação stealtenta fingir ser metade da fila em vez de uma única tarefa. Isso tem um bom efeito no desempenho, que discutiremos mais adiante.A última parte que falta é a análise da fila global, que recebe tarefas que transbordam filas locais, bem como a transferência de tarefas para o planejador a partir de threads que não são do processador. Se o processador estiver sob carga, ou seja, houver tarefas na fila local, o processador tentará extrair as tarefas da fila global após cerca de 60 tarefas na fila local. Ele também verifica a fila global quando está no estado de "pesquisa" descrito abaixo.Simplifique modelos de mensagens
Os aplicativos Tokio normalmente consistem em muitas pequenas tarefas independentes. Eles interagem entre si através de mensagens. Esse modelo é semelhante a outros idiomas, como Go e Erlang. Dado o quão comum é o modelo, faz sentido para o planejador otimizá-lo.Suponha que as tarefas A e B. A tarefa A esteja sendo executada e envie uma mensagem para a tarefa B pelo canal de transmissão. Um canal é um recurso no qual a tarefa B está bloqueada no momento; portanto, a ação de enviar uma mensagem fará com que a tarefa B faça a transição para um estado executável - e será colocada na fila de execução do processador atual. Em seguida, o processador deduzirá a próxima tarefa da fila de execução, executará e repetirá esse ciclo até atingir a tarefa B.O problema é que pode haver um atraso significativo entre o envio de uma mensagem e a conclusão da tarefa B. Além disso, dados quentes, como uma mensagem, são armazenados no cache da CPU, mas quando a tarefa é concluída, é provável que os caches correspondentes sejam limpos.Para resolver esse problema, o novo agendador Tokio implementa otimização (como nos agendadores Go e Kotlin). Quando uma tarefa entra em um estado executável, ela não é colocada no final da fila, mas é armazenada em um slot especial de "próxima tarefa". O processador sempre verifica esse slot antes de verificar a fila. Se já houver uma tarefa antiga ao inserir no slot, ela será excluída do slot e será movida para o final da fila. Assim, a tarefa de transmitir uma mensagem será realizada praticamente sem demora.
Captura do acelerador
Em um planejador de captura de tarefas, se a fila de execução do processador estiver vazia, o processador tentará capturar tarefas das CPUs do mesmo nível. Primeiro, uma CPU de mesmo nível aleatória é selecionada; se nenhuma tarefa for encontrada, a próxima será pesquisada e assim por diante, até que as tarefas sejam encontradas.Na prática, vários processadores geralmente terminam de processar a fila de execução aproximadamente ao mesmo tempo. Isso acontece quando um pacote de trabalho chega (por exemplo, quandoepollconsultado a disponibilidade do soquete). Os processadores acordam, recebem tarefas, iniciam-nas e concluem. Isso leva ao fato de que todos os processadores estão tentando capturar simultaneamente as tarefas de outras pessoas, ou seja, muitos threads estão tentando acessar as mesmas filas. Existe um conflito. Uma escolha aleatória do ponto de partida ajuda a reduzir a concorrência, mas a situação ainda não é muito boa.Para contornar esse problema, o novo planejador limita o número de processadores paralelos que executam operações de captura. Chamamos o estado do processador em que ele está tentando capturar as tarefas de outras pessoas como "procura de emprego" ou "busca" para abreviar (mais sobre isso mais tarde). Essa otimização é realizada usando valor atômicoint, que o processador aumenta antes de iniciar a pesquisa e diminui ao sair do estado de pesquisa. O máximo possível em um estado de pesquisa pode ser metade do número total de processadores. Ou seja, o limite aproximado está definido e isso é normal. Não precisamos de um limite rígido para o número de CPUs na pesquisa, apenas para limitar. Sacrificamos a precisão em prol da eficiência do algoritmo.Depois de entrar no estado de pesquisa, o processador tenta capturar o trabalho das CPUs pares e verifica a fila global.Diminuir a sincronização entre threads
Outra parte importante do planejador é notificar as CPUs dos pares sobre novas tarefas. Se o "irmão" estiver dormindo, ele acorda e captura tarefas. As notificações desempenham outro papel importante. Lembre-se de que o algoritmo de fila usa ordenação atômica fraca ( Acquire/ Release). Devido à alocação atômica da memória, não há garantia de que um processador par verá tarefas na fila sem sincronização adicional. Portanto, as notificações também são responsáveis por isso. Por esse motivo, as notificações ficam caras. O objetivo é minimizar seu número para não usar os recursos da CPU, ou seja, o processador tem tarefas e o irmão não pode roubá-las. O número excessivo de notificações leva a um problema de manada de trovões .O planejador original dos Tokio adotou uma abordagem ingênua das notificações. Sempre que uma nova tarefa era colocada na fila de execução, o processador recebia uma notificação. Sempre que a CPU foi notificada e viu a tarefa após acordar, ela notificou outra CPU. Essa lógica levou muito rapidamente todos os processadores a acordar e procurar trabalho (causando um conflito). Muitas vezes, a maioria dos processadores não encontrou trabalho e adormeceu novamente.O novo planejador melhorou bastante esse padrão, semelhante ao planejador Go. As notificações são enviadas como antes, mas apenas se não houver CPU no estado de pesquisa (consulte a seção anterior). Quando o processador recebe uma notificação, ele entra imediatamente no estado de pesquisa. Quando o processador no estado de pesquisa encontra novas tarefas, ele primeiro sai do estado de pesquisa e depois notifica o outro processador.Essa lógica limita a velocidade na qual os processadores são ativados. Se um pacote de tarefas inteiro for planejado imediatamente (por exemplo, quandoepollpesquisada quanto à prontidão do soquete), a primeira tarefa resultará em uma notificação ao processador. Ele está agora em um estado de pesquisa. As demais tarefas agendadas no pacote não notificarão o processador, pois há pelo menos uma CPU no estado de pesquisa. Esse processador notificado capturará metade das tarefas do lote e, por sua vez, notificará o outro processador. Um terceiro processador acorda, encontra as tarefas de um dos dois primeiros e captura metade deles. Isso leva a um aumento suave no número de CPUs em funcionamento, bem como no balanceamento de carga rápido.Reduza a alocação de memória
O novo agendador Tokio requer apenas uma alocação de memória para cada tarefa gerada, enquanto o antigo requer dois. Anteriormente, a estrutura da tarefa era algo assim: struct Task {
A estrutura Tasktambém será destacada em Box. Durante muito tempo, eu quis consertar essa junta (tentei pela primeira vez em 2014). Duas coisas mudaram desde o antigo planejador dos Tokio. Primeiro, estabilizado std::alloc. Em segundo lugar, o futuro sistema de tarefas mudou para uma estratégia explícita de vtable . Finalmente, foram essas duas coisas que estavam faltando para se livrar da ineficiente alocação de memória dupla para cada tarefa.Agora a estrutura Taské apresentada da seguinte forma: struct Task<T> { header: Header, future: T, trailer: Trailer, }
Header ,
Trailer , «» () «» (), . . , , , . «» . , ( 64 128 ). , .
A última otimização discutida neste artigo é reduzir o número de links atômicos. Existem muitas referências à estrutura da tarefa, inclusive do agendador e de cada waker. A estratégia geral para gerenciar essa memória é a contagem de links atômicos . Essa estratégia requer uma operação atômica toda vez que um link é clonado e toda vez que um link é excluído. Quando o último link fica fora do escopo, a memória é liberada.No antigo agendador Tokio, o agendador e todos os wakers continham um link para um descritor de tarefas, aproximadamente: struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Quando a tarefa é ativada, o link é clonado (ocorre um incremento atômico). Em seguida, o link é colocado na fila de execução. Quando o processador recebe a tarefa e conclui sua execução, ele descarta o link, o que leva à redução atômica. Essas operações atômicas (incremento e diminuição) se somam.Esse problema foi identificado anteriormente pelos desenvolvedores do sistema de tarefas std::future. Eles perceberam que, ao ligar, o Waker::wakelink original wakergeralmente não é mais necessário. Isso permite reutilizar o contador de link atômico ao mover uma tarefa para a fila de execução. O sistema de tarefas std::futureagora inclui duas chamadas de API para "ativar":Essa construção de API nos faz usá-la ao chamar wake, evitando incremento atômico. A implementação fica assim: impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Isso evita a sobrecarga de contagens de links adicionais apenas se você puder assumir a responsabilidade de acordar. Na minha experiência, é quase sempre aconselhável acordar &self. O despertar selfimpede a reutilização do waker (útil nos casos em que o recurso envia muitos valores, como canais, soquetes, ...). Também no caso, é selfmais difícil implementar a ativação segura de threads (deixaremos os detalhes para outro artigo).O novo planejador resolve o problema de "despertar self" evitando o incremento atômico wake_by_ref, o que o torna tão eficaz quantowake(self). Para fazer isso, o planejador mantém uma lista de todas as tarefas atualmente ativas (ainda não concluídas). A lista representa o contador de referência necessário para enviar a tarefa para a fila de execução.A complexidade dessa otimização está no fato de que o planejador não removerá tarefas de sua lista até receber uma garantia de que a tarefa será colocada na fila de execução novamente. Os detalhes da implementação desse esquema estão além do escopo deste artigo, mas eu recomendo fortemente que você olhe a fonte.Concorrência em negrito (insegura) com Loom
É muito difícil escrever o código paralelo correto, sem bloqueios. É melhor trabalhar devagar, mas corretamente, do que rapidamente, mas com falhas, principalmente se os erros estiverem relacionados à segurança da memória. A melhor opção, no entanto, deve funcionar rapidamente e sem erros. O novo agendador fez algumas otimizações bastante agressivas e evita a maioria dos tipos stdpor causa da especialização. Em geral, há bastante código inseguro nele unsafe.Existem várias maneiras de testar código paralelo. Uma delas é que os usuários testem e depurem em vez de você (uma opção atraente, com certeza). Outra é escrever testes de unidade que são executados em loop e podem detectar um erro. Talvez até use TSAN. Obviamente, se ele encontrar um erro, ele não poderá ser facilmente reproduzido sem reiniciar o ciclo de teste. Além disso, quanto tempo leva esse ciclo? Dez segundos? Dez minutos? Dez dias? Anteriormente, era necessário testar o código paralelo no Rust.Achamos essa situação inaceitável. Quando liberamos o código, queremos nos sentir confiantes (o máximo possível), especialmente no caso de código paralelo sem bloqueios. Os usuários dos Tokio precisam de confiabilidade.Por isso, desenvolvemos o Loom : uma ferramenta para teste de permutação de código paralelo. Os testes são escritos como de costume, masloomEle será executado muitas vezes, reorganizando todas as opções possíveis de execução e comportamento que o teste pode encontrar em um ambiente de streaming. Ele também verifica o acesso correto à memória, libera memória, etc.Como exemplo, aqui está o teste de tear para o novo planejador: #[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx)));
Parece bastante normal, mas um pedaço de código em um bloco loom::modelé executado milhares de vezes (possivelmente milhões), sempre com uma ligeira mudança de comportamento. Cada execução altera a ordem exata dos encadeamentos. Além disso, para cada operação atômica, o tear tenta todos os diferentes comportamentos permitidos no modelo de memória C ++ 11. Lembre-se de que a carga atômica com Acquireera bastante fraca e poderia retornar valores obsoletos. O teste loomtentará todos os valores possíveis que podem ser carregados.loomtornou-se uma ferramenta inestimável no desenvolvimento de um novo planejador. Ele capturou mais de dez bugs que passaram em todos os testes de unidade, testes manuais e testes de carga., loom « », . . . , . Loom
(dynamic partial-order reduction). , . , ( ). Loom .
Em geral, graças aos extensos testes com o Loom, agora estou muito mais confiante na correção do agendador.Resultados
Então, examinamos o que são os agendadores e como o novo agendador Tokio obteve um enorme aumento de desempenho ... mas que tipo de crescimento? Dado que o novo agendador foi desenvolvido apenas, no mundo real ele ainda não foi totalmente testado. Aqui está o que sabemos.Primeiro, o novo agendador é muito mais rápido em micro benchmarks:Planejador antigo
teste chained_spawn ... banco: 2.019.796 ns / iter (+/- 302.168)
teste ping_pong ... banco: 1.279.948 ns / iter (+/- 154.365)
teste spawn_many ... banco: 10.283.608 ns / iter (+/- 1.284.275)
test yield_many ... bench: 21.450.748 ns / iter (+/- 1.201.337)
Planejador novo
teste chained_spawn ... banco: 168.854 ns / iter (+/- 8.339)
teste ping_pong ... banco: 562.659 ns / iter (+/- 34.410)
teste spawn_many ... banco: 7.320.737 ns / iter (+/- 264.620)
test yield_many ... bench: 14.638.563 ns / iter (+/- 1.573.678)
Esta referência inclui o seguinte:chained_spawn gerar novas tarefas recursivamente, ou seja, gerar uma tarefa que gera outra tarefa, que também gera uma tarefa etc.
ping_pongseleciona um canal oneshote gera uma tarefa que envia uma mensagem nesse canal. A tarefa original está aguardando uma mensagem. Este é o teste mais próximo do "mundo real".
spawn_many Verifica a implementação de tarefas no planejador, ou seja, gera tarefas fora do seu contexto.
yield_many verifica o despertar da tarefa independente.
A diferença nos benchmarks é muito impressionante. Mas como isso será refletido no "mundo real"? É difícil dizer com certeza, mas tentei executar os benchmarks Hyper .Aqui está o servidor Hyper mais simples, cujo desempenho é medido usando wrk -t1 -c50 -d10:Planejador antigo
Executando o teste 10s @ http://127.0.0.1 {000
1 threads e 50 conexões
Estatísticas do segmento Avg Stdev Max +/- Stdev
Latência 371.53us 99.05us 1.97ms 60.53%
Req / Sec 114,61k 8,45k 133,85k 67,00%
1139307 solicitações em 10.00s, 95.61MB de leitura
Pedidos / s: 113923.19
Transferência / s: 9,56MB Planejador novo
Executando o teste 10s @ http://127.0.0.1 {000
1 threads e 50 conexões
Estatísticas do segmento Avg Stdev Max +/- Stdev
Latência 275.05us 69.81us 1.09ms 73.57%
Req / Sec 153.17k 10.68k 171.51k 71.00%
1522671 solicitações em 10.00s, 127.79MB de leitura
Pedidos / s: 152258.70
Transferência / s: 12,78MB Vemos um aumento de 34% nas solicitações por segundo logo após a alteração do agendador! A primeira vez que vi isso, fiquei muito feliz, porque esperava um aumento de no máximo 5-10%. Mas então fiquei triste, porque esse resultado também mostrou que o antigo agendador do Tokio não é tão bom. Lembrei-me de que a Hyper já é líder em classificações do TechEmpower . É interessante ver como o novo planejador afetará as classificações.Tonic , o cliente e servidor gRPC, com o novo agendador acelerou em cerca de 10%, o que é bastante impressionante, considerando que o Tonic ainda não está totalmente otimizado.Conclusão
Estou realmente muito feliz por finalmente concluir este projeto após vários meses de trabalho. Esse é um grande aprimoramento da E / S assíncrona do Rust. Estou muito satisfeito com as melhorias feitas. Ainda há muito espaço para otimização no código Tokio, então ainda não terminamos a melhoria de desempenho.Espero que o material do artigo seja útil para colegas que tentam escrever seu agendador de tarefas.