Pavel Selivanov, arquiteto de soluções da Southbridge e palestrante da Slurm, fez uma apresentação no DevOpsConf 2019. Este relatório é parte do curso aprofundado do Kubernetes, Slur Mega.
Slurm Basic: Uma introdução ao Kubernetes ocorre em Moscou, de 18 a 20 de novembro.
Slurm Mega: Nós olhamos sob o capô de Kubernetes - Moscou, de 22 a 24 de novembro.
Slurm Online: Os dois cursos do Kubernetes estão sempre disponíveis.
Sob o recorte - transcrição do relatório.
Boa tarde, colegas e simpatizantes. Hoje vou falar sobre segurança.
Vejo que hoje existem muitos seguranças no salão. Peço desculpas antecipadamente se não usarei os termos do mundo da segurança da mesma maneira que você aceitou.
Aconteceu que cerca de seis meses atrás eu entrei nas mãos de um grupo público de Kubernetes. Público - significa que existe um enésimo número de espaços para nome; nesse espaço para nome, há usuários isolados em seu espaço para nome. Todos esses usuários pertencem a diferentes empresas. Bem, supunha-se que esse cluster deveria ser usado como uma CDN. Ou seja, eles fornecem um cluster, eles fornecem o usuário lá, você vai lá no seu namespace, implementa suas frentes.
Eles tentaram vender esse serviço para minha empresa anterior. E me pediram para cutucar um cluster sobre o assunto - essa solução é adequada ou não.
Eu vim para este cluster. Eu recebi direitos limitados, espaço para nome limitado. Lá, os caras entenderam o que era segurança. Eles leram o que o Kubernetes tinha RBAC (Controle de Acesso Baseado em Função) - e o distorceram para que eu não pudesse executar pods separadamente da implantação. Não me lembro da tarefa que estava tentando resolver executando abaixo sem implantação, mas eu realmente queria executar logo abaixo. Decidi, com sorte, ver quais direitos tenho no cluster, o que posso, o que não posso, o que eles estragaram lá. Ao mesmo tempo, mostrarei o que eles configuraram no RBAC incorretamente.
Aconteceu que, dois minutos depois, consegui um administrador para o cluster, examinei todos os namespaces vizinhos, vi as frentes de produção de empresas que já haviam comprado o serviço e ficaram presas lá. Mal me detive, para não encontrar alguém na frente e não colocar nenhuma palavra obscena na página principal.
Vou lhe contar com exemplos como eu fiz isso e como me proteger disso.
Mas primeiro, me apresento. Meu nome é Pavel Selivanov. Sou arquiteto em Southbridge. Eu entendo Kubernetes, DevOps e todo tipo de coisas sofisticadas. Os engenheiros da Southbridge e eu estamos construindo tudo isso, e eu aconselho.
Além do nosso negócio principal, lançamos recentemente projetos chamados Slory. Estamos tentando levar nossa capacidade de trabalhar com os Kubernetes para as massas, para ensinar outras pessoas a trabalhar com os K8s também.
Sobre o que vou falar hoje. O tópico do relatório é óbvio - sobre a segurança do cluster Kubernetes. Mas quero dizer imediatamente que esse tópico é muito grande - e, portanto, quero estipular imediatamente o que não falarei com certeza. Não falarei sobre termos hackeados que já são cem vezes oprimidos na Internet. Qualquer RBAC e certificados.
Vou falar sobre como meus colegas e eu estamos cansados de segurança no cluster Kubernetes. Vemos esses problemas tanto com fornecedores que fornecem clusters Kubernetes quanto com clientes que vêm até nós. E mesmo com clientes que chegam até nós de outras empresas de consultoria em administração. Ou seja, a escala da tragédia é realmente muito grande.
Literalmente três pontos, sobre os quais falarei hoje:
- Direitos do usuário versus direitos do pod. Direitos do usuário e direitos da lareira não são a mesma coisa.
- Coleta de informações de cluster. Mostrarei que no cluster você pode coletar todas as informações necessárias sem ter direitos especiais nesse cluster.
- Ataque de negação de serviço no cluster. Se não podemos coletar informações, podemos colocar o cluster em qualquer caso. Vou falar sobre ataques de DoS em controles de cluster.
Outra coisa comum que mencionarei é onde testei tudo e posso dizer com certeza que tudo funciona.
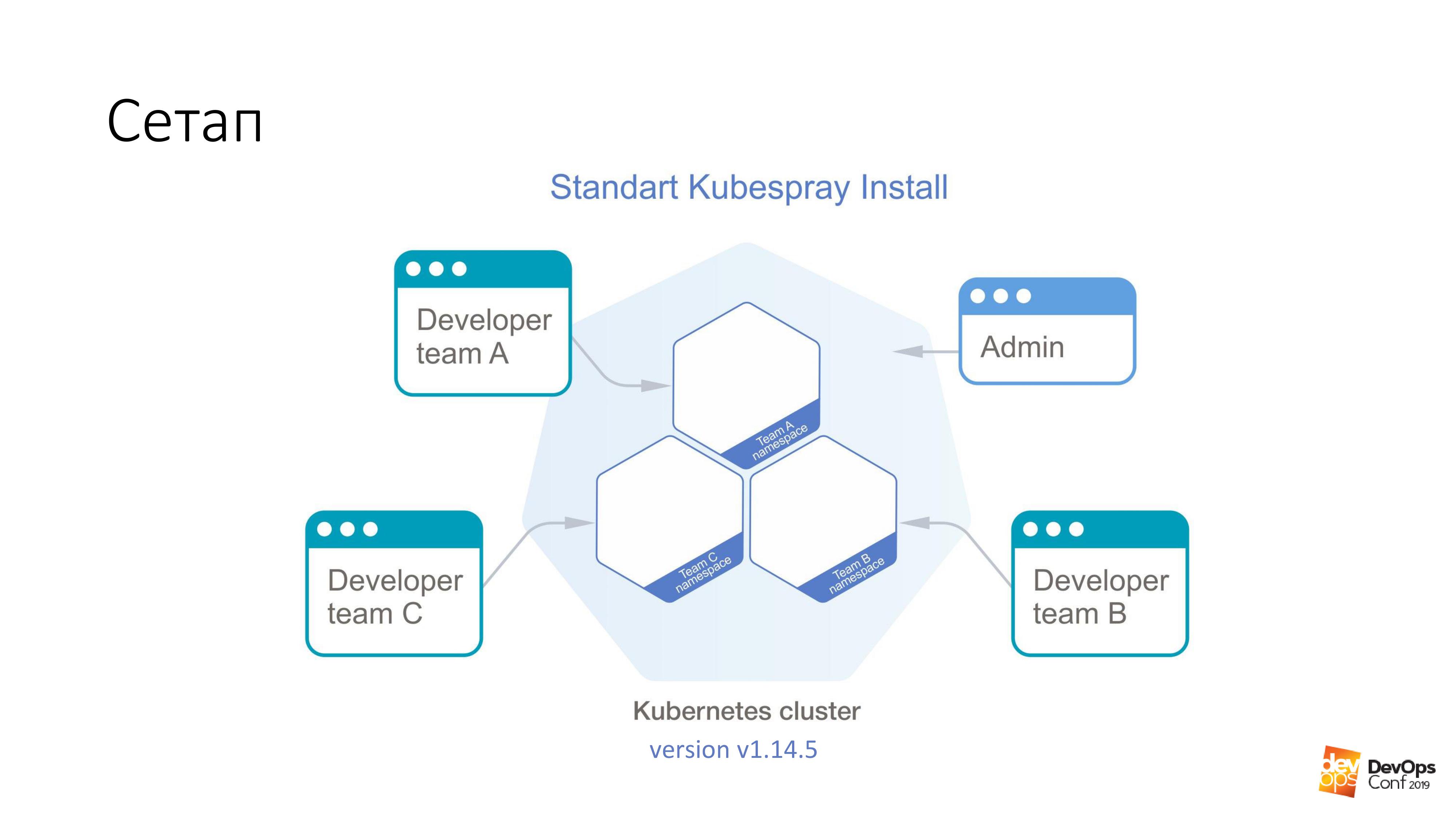
Como base, tomamos a instalação de um cluster Kubernetes usando o Kubespray. Se alguém não sabe, esse é realmente um conjunto de papéis para o Ansible. Estamos constantemente usando-o em nosso trabalho. O bom é que você pode rolar em qualquer lugar - nas glândulas e em algum lugar na nuvem. Um método de instalação é adequado em princípio para tudo.
Neste cluster, terei o Kubernetes v1.14.5. Todo o cluster de Cuba, que consideraremos, é dividido em namespaces, cada namespace pertence a uma equipe separada e os membros dessa equipe têm acesso a cada namespace. Eles não podem ir para namespaces diferentes, apenas para os seus próprios. Mas há uma conta de administrador que possui direitos para todo o cluster.
Prometi que a primeira coisa que teremos é obter direitos de administrador no cluster. Precisamos de um pod especialmente preparado que quebre o cluster Kubernetes. Tudo o que precisamos fazer é aplicá-lo ao cluster Kubernetes.
kubectl apply -f pod.yaml
Este pod chegará a um dos mestres do cluster Kubernetes. E depois disso, o cluster retornará felizmente um arquivo chamado admin.conf para nós. Em Cuba, todos os certificados de administrador são armazenados nesse arquivo e, ao mesmo tempo, a API do cluster está configurada. Acho que é assim que você pode obter acesso de administrador a 98% dos clusters do Kubernetes.
Repito, esse pod foi feito por um desenvolvedor em seu cluster que tem acesso para implantar suas propostas em um pequeno espaço para nome; ele é todo preso pelo RBAC. Ele não tinha direitos. No entanto, o certificado retornou.
E agora sobre a lareira especialmente preparada. Execute em qualquer imagem. Por exemplo, considere debian: jessie.
Temos uma coisa dessas:
tolerations: - effect: NoSchedule operator: Exists nodeSelector: node-role.kubernetes.io/master: ""
O que é tolerância? Os mestres no cluster Kubernetes geralmente são marcados com uma coisa chamada contaminação ("infecção" em inglês). E a essência dessa "infecção" - ela diz que os pods não podem ser atribuídos aos nós principais. Mas ninguém se preocupa em indicar de qualquer maneira que ele é tolerante com a "infecção". A seção Toleration apenas diz que se o NoSchedule estiver em algum nó, a infecção por essa infecção será tolerante - e sem problemas.
Além disso, dizemos que nosso baixo não é apenas tolerante, mas também quer cair especificamente sobre o mestre. Porque os mestres são os mais deliciosos que precisamos - todos os certificados. Portanto, dizemos nodeSelector - e temos um rótulo padrão nos assistentes, o que nos permite selecionar exatamente os nós que são assistentes de todos os nós do cluster.
Com essas duas seções, ele definitivamente chegará ao mestre. E ele poderá morar lá.
Mas apenas vir ao mestre não é suficiente para nós. Não vai nos dar nada. Portanto, ainda temos essas duas coisas:
hostNetwork: true hostPID: true
Indicamos que nosso under, que estamos iniciando, viverá no namespace do kernel, no namespace da rede e no namespace PID. Assim que for iniciado no assistente, ele poderá ver todas as interfaces reais e ativas desse nó, ouvir todo o tráfego e ver o PID de todos os processos.
Em seguida, é pequeno. Pegue o etcd e leia o que você deseja.
O mais interessante é esse recurso do Kubernetes, que está presente lá por padrão.
volumeMounts: - mountPath: /host name: host volumes: - hostPath: path: / type: Directory name: host
E sua essência é que podemos dizer que queremos criar um volume do tipo hostPath no pod que executamos, mesmo sem os direitos para esse cluster. Significa seguir o caminho do host no qual iniciaremos - e tomá-lo como volume. E depois chame-o de nome: host. Todo esse hostPath que montamos dentro da lareira. Neste exemplo, para o diretório / host.
Repito mais uma vez. Dissemos ao pod para chegar ao mestre, obter hostNetwork e hostPID lá - e montar toda a raiz do mestre dentro desse pod.
Você entende que no debian temos o bash rodando, e esse bash funciona sob a nossa raiz. Ou seja, acabamos de obter a raiz do mestre, embora não tenhamos nenhum direito no cluster Kubernetes.
A tarefa toda é entrar no subdiretório / host / etc / kubernetes / pki; se não me engano, pegue todos os certificados mestres do cluster e, consequentemente, torne-se o administrador do cluster.
Se você olhar dessa maneira, esses são alguns dos direitos mais perigosos dos pods, apesar dos direitos do usuário:

Se eu tiver direitos para executar em algum espaço para nome do cluster, esse sub possui esses direitos por padrão. Eu posso executar pods privilegiados, e isso geralmente é todos os direitos, praticamente root no nó.
O meu favorito é usuário root. E o Kubernetes tem essa opção Executar como Não-Raiz. Este é um tipo de proteção contra hackers. Você sabe o que é o "vírus da Moldávia"? Se você é um hacker e vem ao meu cluster do Kubernetes, nós, administradores pobres, perguntamos: “Por favor, indique nos seus pods com os quais você invadirá meu cluster, execute como não raiz. E acontece que você inicia o processo em seu coração sob a raiz, e será muito fácil para você me invadir. Por favor, proteja-se de si mesmo.
Volume do caminho do host - na minha opinião, a maneira mais rápida de obter o resultado desejado do cluster Kubernetes.
Mas o que fazer com tudo isso?
Pensamentos que devem chegar a qualquer administrador normal que encontre o Kubernetes: “Sim, eu lhe disse, o Kubernetes não funciona. Existem buracos nele. E todo o cubo é besteira. " De fato, existe documentação e, se você procurar lá, há uma seção Política de Segurança do Pod .
Este é um objeto yaml - podemos criá-lo no cluster Kubernetes - que controla os aspectos de segurança na descrição dos lares. Na verdade, ele controla esses direitos para usar todos os tipos de hostNetwork, hostPID, certos tipos de volume, que estão nos pods na inicialização. Com a Política de Segurança do Pod, tudo isso pode ser descrito.
O mais interessante na Política de Segurança do Pod é que, no cluster Kubernetes, todos os instaladores do PSP simplesmente não são descritos de forma alguma, eles são simplesmente desativados por padrão. A Política de Segurança do Pod é ativada usando o plug-in de admissão.
Ok, vamos terminar com um cluster da Política de Segurança do Pod, digamos que temos algum tipo de pod de serviço no espaço para nome, ao qual apenas os administradores têm acesso. Digamos que em todos os outros pods eles têm direitos limitados. Como provavelmente, os desenvolvedores não precisam executar pods privilegiados no seu cluster.
E tudo parece estar bem conosco. E nosso cluster Kubernetes não pode ser invadido em dois minutos.
Há um problema. Provavelmente, se você tiver um cluster Kubernetes, o monitoramento será instalado no seu cluster. Eu até presumo prever que, se houver monitoramento no seu cluster, ele será chamado de Prometheus.
O que vou lhe dizer agora será válido tanto para o operador Prometheus quanto para o Prometheus entregue em sua forma pura. A questão é que, se não consigo acessar o administrador tão rapidamente no cluster, significa que preciso procurar mais. E eu posso pesquisar usando seu monitoramento.
Provavelmente, todo mundo lê os mesmos artigos sobre Habré, e o monitoramento está em monitoramento. O gráfico de leme é chamado aproximadamente o mesmo para todos. Presumo que, se você instalar o stable / prometheus, obterá aproximadamente os mesmos nomes. E ainda mais provavelmente não precisarei adivinhar o nome DNS no seu cluster. Porque é padrão.
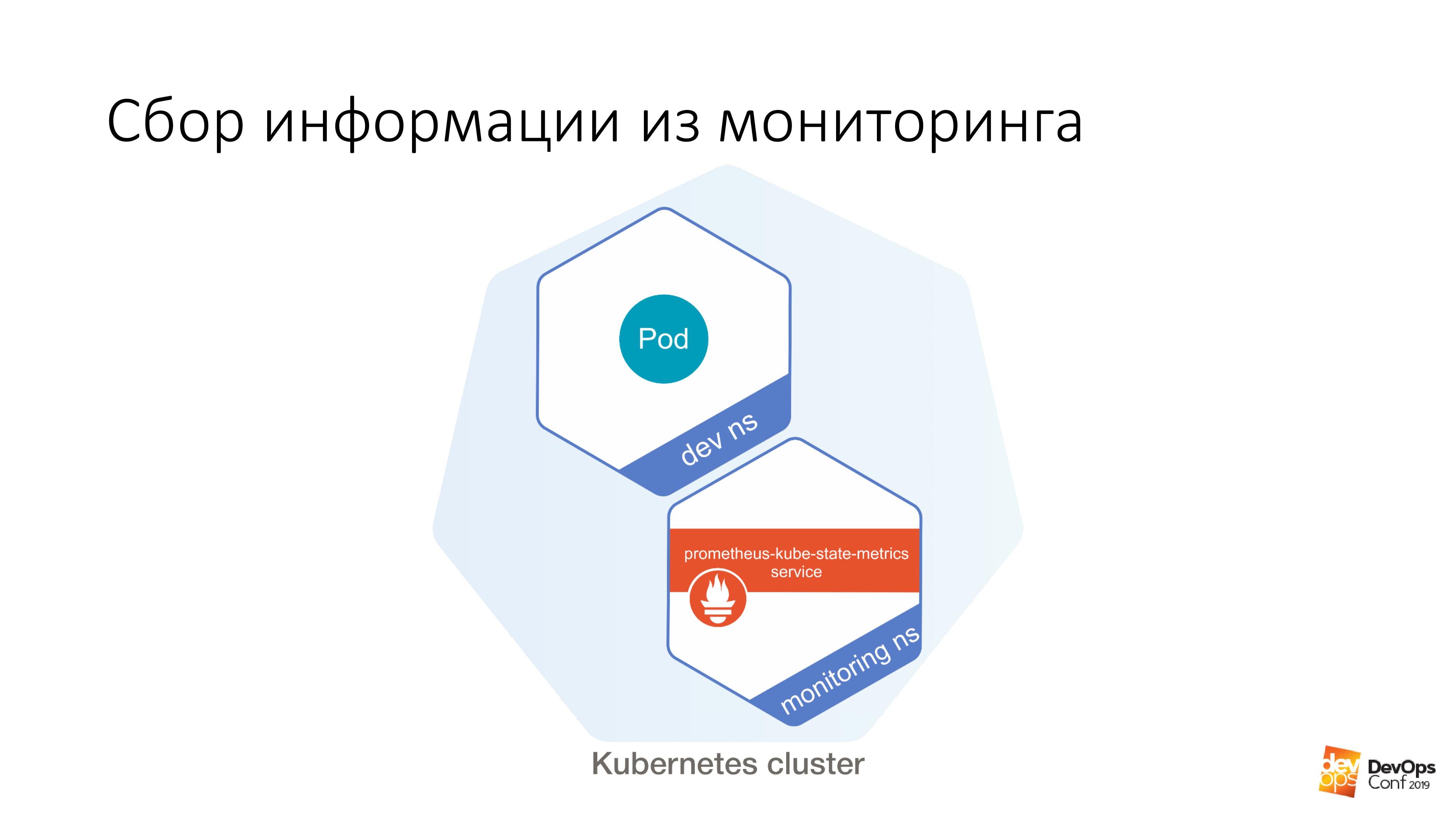
Além disso, temos alguns dev ns, nele é possível lançar um certo abaixo. Além disso, é muito fácil fazer assim:
$ curl http://prometheus-kube-state-metrics.monitoring
prometheus-kube-state-metrics é um dos exportadores de prometheus que coleta métricas da API do Kubernetes. Há muitos dados em execução no cluster, quais são, quais problemas você tem com ele.
Como um exemplo simples:
kube_pod_container_info {namespace = "kube-system", pod = "kube-apiserver-k8s-1", container = "kube-apiserver", imagem =
"gcr.io/google-containers/kube-apiserver:v1.14.5"
, Image_id = "docker-pullable: //gcr.io/google-containers/kube- apiserver @ sha256: e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989", container_id = "janela de encaixe: // 7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b"} 1
Depois de fazer uma solicitação de curvatura simples a partir de um arquivo não privilegiado, você pode obter essas informações. Se você não souber em qual versão do Kubernetes está executando, será fácil informar.
E o mais interessante é que, além do fato de você recorrer às métricas de estado de cubo, também pode se aplicar diretamente ao próprio Prometheus. Você pode coletar métricas a partir daí. Você pode até criar métricas a partir daí. Mesmo teoricamente, você pode criar essa solicitação a partir de um cluster no Prometheus, que simplesmente a desativa. E seu monitoramento geralmente deixa de funcionar no cluster.
E aqui surge a questão de saber se algum monitoramento externo monitora seu monitoramento. Acabei de ter a oportunidade de atuar no cluster Kubernetes sem nenhuma consequência para mim. Você nem sabe que estou atuando lá, já que não há mais monitoramento.
Assim como no PSP, parece que o problema é que todas essas tecnologias da moda - Kubernetes, Prometheus - elas simplesmente não funcionam e estão cheias de buracos. Na verdade não.
Existe uma coisa - Política de Rede .
Se você é um administrador normal, provavelmente na Política de Rede sabe que esse é outro yaml, que no cluster já está em execução. E algumas políticas de rede definitivamente não são necessárias. E mesmo que você leia o que é a Política de Rede, qual é o yaml-firewall do Kubernetes, ele permite restringir os direitos de acesso entre os espaços para nome, entre os pods, e certamente você decidiu que o firewall do tipo yaml no Kubernetes está nas próximas abstrações ... Não, não . Definitivamente, isso não é necessário.
Mesmo que seus especialistas em segurança não tenham informado de que, usando o Kubernetes, você pode criar um firewall com muita facilidade e simplicidade, e é muito granular. Se eles ainda não sabem disso e não o puxam: "Bem, dê, dê ..." Em qualquer caso, você precisará da Política de Rede para bloquear o acesso a alguns locais de serviço que você pode extrair do cluster sem nenhuma autorização.
Como no exemplo que citei, você pode extrair as métricas do estado do kube de qualquer espaço para nome no cluster Kubernetes sem ter nenhum direito. As políticas de rede fecharam o acesso de todos os outros namespaces ao monitoramento do namespace e, por assim dizer, tudo: sem acesso, sem problemas. Em todos os gráficos existentes, tanto o prometeus padrão quanto o prometeus que está no operador, simplesmente nos valores do leme há uma opção para simplesmente ativar as políticas de rede para eles. Você só precisa ligá-lo e eles funcionarão.
Há realmente um problema aqui. Sendo um administrador barbudo normal, você provavelmente decidiu que não são necessárias políticas de rede. E depois de ler todos os tipos de artigos sobre recursos como Habr, você decidiu que a flanela, especialmente com o modo host-gateway, é a melhor coisa que você pode escolher.
O que fazer
Você pode tentar reimplementar a solução de rede que está no seu cluster Kubernetes, substituí-la por algo mais funcional. Na mesma chita, por exemplo. Mas imediatamente quero dizer que a tarefa de alterar a solução de rede no cluster de trabalho do Kubernetes não é trivial. Eu o resolvi duas vezes (no entanto, teoricamente, ambas as vezes), mas até mostramos como fazer isso nos Slurms. Para nossos alunos, mostramos como alterar a solução de rede no cluster Kubernetes. Em princípio, você pode tentar garantir que não haja tempo de inatividade no cluster de produção. Mas você provavelmente não terá sucesso.
E o problema é realmente resolvido de maneira muito simples. Existem certificados no cluster e você sabe que seus certificados ficarão ruins em um ano. Bem, e geralmente uma solução normal com certificados no cluster - por que vamos usar o vapor, criaremos um novo cluster ao lado, deixaremos apodrecer no antigo e refazeremos tudo. É verdade que, quando tudo der errado, tudo se acalmará em nossos dias, mas depois um novo cluster.
Quando você criar um novo cluster, ao mesmo tempo, insira Calico em vez de flanela.
O que fazer se você possui certificados emitidos por cem anos e não deseja agrupar novamente o cluster? Existe uma coisa chamada Kube-RBAC-Proxy. Este é um desenvolvimento muito interessante, pois permite incorporar-se como um contêiner lateral a qualquer lareira no cluster Kubernetes. E ela realmente adiciona autorização através do Kubernetes RBAC a este pod.
Há um problema. Anteriormente, o Kube-RBAC-Proxy era incorporado ao prometheus do operador. Mas então ele se foi. Agora, as versões modernas dependem do fato de você ter uma diretiva de rede e fechar usando-as. E então você tem que reescrever um pouco o gráfico. De fato, se você for a este repositório , há exemplos de como usá-lo como sidecars e precisará reescrever os gráficos minimamente.
Há outro pequeno problema. Não apenas Prometheus fornece suas métricas para quem as recebe. Também temos todos os componentes do cluster Kubernetes, eles podem fornecer suas métricas.
Mas como eu disse, se você não conseguir acessar o cluster e coletar informações, poderá pelo menos causar algum dano.
Então, mostrarei rapidamente duas maneiras de estragar o cluster do Kubernetes.
Você vai rir quando eu lhe contar, esses são dois casos da vida real.
O primeiro caminho. Ficar sem recursos.
Lançamos mais um especial. Ele terá essa seção.
resources: requests: cpu: 4 memory: 4Gi
Como você sabe, as solicitações são a quantidade de CPU e memória reservada no host para pods específicos com solicitações. Se tivermos um host de quatro núcleos no cluster Kubernetes e quatro CPUs chegarem com solicitações, significa que não haverá mais pods com solicitações para esse host.
Se eu executar isso em baixo, vou fazer um comando:
$ kubectl scale special-pod --replicas=...
Então ninguém mais poderá implantar no cluster Kubernetes. Porque em todos os nós as solicitações terminarão. E assim eu paro seu cluster Kubernetes. Se fizer isso à noite, posso parar a implantação por algum tempo.
Se olharmos novamente para a documentação do Kubernetes, veremos uma coisa chamada Limit Range. Ele define recursos para objetos de cluster. Você pode escrever um objeto Limit Range no yaml, aplicá-lo a determinados namespaces - e ainda mais nesse namespace, você pode dizer que possui os recursos para os pods padrão, máximo e mínimo.
Com a ajuda de uma coisa dessas, podemos limitar os usuários em espaços de nomes de produtos específicos de equipes na capacidade de indicar qualquer coisa desagradável em seus pods. Mas, infelizmente, mesmo se você disser ao usuário que é impossível executar pods com solicitações de mais de uma CPU, existe um comando de escala maravilhoso, bem, ou através do painel eles podem escalar.
E daqui vem o método número dois. Lançamos 11 111 111 111 111 lares. São onze bilhões. Não é porque eu criei esse número, mas porque eu mesmo o vi.
A verdadeira história. No final da noite, eu estava prestes a sair do escritório. Eu vejo, um grupo de desenvolvedores está sentado no canto e fazendo algo freneticamente com laptops. Vou até os caras e pergunto: "O que aconteceu com você?"
Um pouco antes, às nove da noite, um dos desenvolvedores estava indo para casa. E ele decidiu: "Vou pular minha inscrição até uma agora". Eu cliquei um pouco, e a Internet um pouco chata. Ele mais uma vez clicou na unidade, pressionou a unidade, clicou em Enter. Brincou com tudo o que pôde. Então a Internet ganhou vida - e tudo começou a crescer até essa data.
É verdade que essa história não ocorreu em Kubernetes, na época era nômade. Terminou com o fato de que, depois de uma hora de nossas tentativas de impedir Nomad de tentativas obstinadas de permanecer juntos, Nomad respondeu que ele não parava de grudar e que não fazia mais nada. "Estou cansado, estou indo embora." E enrolado.
Naturalmente, tentei fazer o mesmo no Kubernetes. Os onze bilhões de pods de Kubernetes não ficaram satisfeitos, ele disse: "Não posso. Excede os protetores bucais internos. " Mas 1.000.000.000 de lares podiam.
Em resposta a um bilhão, o Cubo não entrou. Ele realmente começou a escalar. Quanto mais o processo passava, mais tempo levava para ele criar novos lares. Mas ainda assim o processo continuou. O único problema é que, se eu puder executar pods indefinidamente no meu espaço para nome, mesmo sem solicitações e limites, posso iniciar um número tão grande de pods com algumas tarefas que, com essas tarefas, os nós começarão a adicionar da memória a partir da CPU. Quando eu corro tantos lares, as informações deles devem ir para o repositório, ou seja, etcd. E quando muita informação chega lá, o armazém começa a ceder muito lentamente - e em Kubernetes, as coisas monótonas começam.
E mais um problema ... Como você sabe, os elementos de controle do Kubernetes não são apenas uma coisa central, mas vários componentes. Lá, em particular, há um gerenciador de controladores, agendador e assim por diante. Todos esses caras começarão a fazer um trabalho estúpido desnecessário ao mesmo tempo, o que com o tempo começará a demorar cada vez mais. O gerente do controlador criará novos pods. O Agendador tentará encontrar um novo nó para eles. É provável que novos nós no seu cluster terminem em breve. O cluster Kubernetes começará a trabalhar mais devagar e lentamente.
Mas eu decidi ir ainda mais longe. Como você sabe, no Kubernetes existe uma coisa chamada serviço. Bem, e por padrão em seus clusters, provavelmente, o serviço funciona usando tabelas IP.
Se você administra um bilhão de lares, por exemplo, e usa o script para forçar o Kubernetis a criar novos serviços:
for i in {1..1111111}; do kubectl expose deployment test --port 80 \ --overrides="{\"apiVersion\": \"v1\", \"metadata\": {\"name\": \"nginx$i\"}}"; done
Em todos os nós do cluster, aproximadamente novas regras do iptables serão geradas aproximadamente simultaneamente. Além disso, para cada serviço, um bilhão de regras de tabelas de ip será gerado.
Eu verifiquei tudo isso em vários milhares, até uma dúzia. E o problema é que já nesse limite o ssh no nó é bastante problemático. Como os pacotes, passando por um número tão grande de cadeias, começam a não se sentir muito bem.
E tudo isso também é resolvido com a ajuda do Kubernetes. Existe um objeto de cota de recurso. Define o número de recursos e objetos disponíveis para um espaço para nome em um cluster. Podemos criar um objeto yaml em cada espaço para nome do cluster Kubernetes. Usando esse objeto, podemos dizer que alocamos um certo número de solicitações, limites para esse espaço para nome e, em seguida, podemos dizer que é possível criar 10 serviços e 10 pods nesse espaço para nome. E um único desenvolvedor pode pelo menos se espremer à noite. Kubernetes dirá a ele: "Você não pode aumentar seus pods a tal quantidade porque excede a cota de recursos". Tudo, o problema está resolvido. A documentação está aqui .
Um ponto problemático surge em conexão com isso. Você sente como é difícil criar um espaço para nome no Kubernetes. Para criá-lo, precisamos considerar várias coisas.
Cota de recursos + Intervalo de limite + RBAC
• Crie um espaço para nome
• Criar limite interno
• Criar dentro da quota de recursos
• Crie uma conta de serviço para o IC
• Crie uma associação de rolagem para IC e usuários
• Opcionalmente, execute os pods de serviço necessários
Portanto, aproveitando esta oportunidade, gostaria de compartilhar meus desenvolvimentos. Existe uma coisa chamada operador de SDK. Esta é uma maneira no cluster Kubernetes de escrever operadores para ele. Você pode escrever instruções usando Ansible.
Primeiro, ele foi escrito em Ansible e, em seguida, verifiquei que havia um operador SDK e reescrevi a função Ansible no operador. Este operador permite criar um objeto no cluster Kubernetes chamado equipe. yaml . , - .
.
. ?
. Pod Security Policy — . , , - .
Network Policy — - . , .
LimitRange/ResourceQuota — . , , . , .
, , , . .
. , warlocks , .
, , . , ResourceQuota, Pod Security Policy . .
.