Parece que tenho o hábito de escrever sobre
máquinas poderosas , onde muitos núcleos ficam
ociosos devido a bloqueios incorretos. Então ... sim. Mais uma vez sobre isso.
Esta história é especialmente impressionante. De fato, com que freqüência você tem um thread girado por alguns segundos em um ciclo de sete comandos, mantendo um bloqueio que interrompe o trabalho de 63 outros processadores? É simplesmente incrível, em um sentido terrível.
Ao contrário da crença popular, na verdade não tenho uma máquina com 64 processadores lógicos e nunca vi esse problema em particular. Mas meu amigo correu para lá,
esse nerd me enganou, ele pediu ajuda, e eu decidi que o problema era bastante interessante. Ele enviou um
rastreio ETW com informações suficientes para que a mente coletiva no Twitter resolvesse rapidamente o problema.
A reclamação do amigo foi bem simples: ele coletou a compilação usando
ninja . Normalmente, o ninja faz um ótimo trabalho ao aumentar a carga, oferecendo suporte constante aos processos n + 2 para evitar o tempo de inatividade. Mas aqui, o uso da CPU nos primeiros 17 segundos da montagem ficou assim:

Se você der uma olhada mais de perto (uma piada), poderá ver uma linha fina em que a carga total da CPU cai de 100% para 0% em alguns segundos. Em apenas meio segundo, a carga é reduzida de 64 para dois ou três threads. Aqui está um fragmento ampliado de uma dessas quedas - os segundos são marcados ao longo do eixo horizontal:
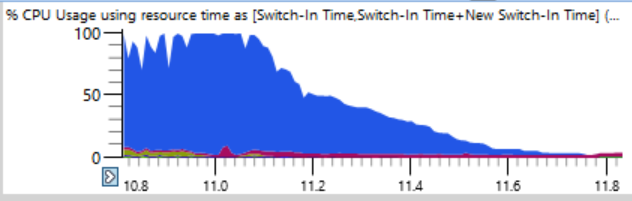
O primeiro pensamento foi que o ninja não pode criar processos rapidamente. Eu já vi isso muitas vezes, geralmente devido à intervenção de um software antivírus. Mas quando eu classifiquei os gráficos no final do período, descobri que durante essas falhas nenhum processo foi concluído, então o ninja não é o culpado.
A tabela
Uso da CPU (Precisa) é ideal para identificar a causa do tempo de inatividade. Os logs de todas as alternâncias de contexto são armazenados lá, incluindo registros precisos de cada início do fluxo, incluindo o local e o tempo limite.
O truque é que não há nada errado com o tempo de inatividade. O problema surge quando realmente queremos que o encadeamento faça o trabalho, mas está ocioso. Portanto, você precisa selecionar certos momentos de inatividade.
Ao analisar, é importante entender que a alternância de contexto ocorre quando um encadeamento retoma a operação. Se olharmos para esses lugares quando a carga do processador começar a cair, não encontraremos nada. Em vez disso, concentre-se em quando o sistema começou a funcionar novamente. Essa fase de rastreamento é ainda mais dramática. Enquanto a queda de carga da CPU leva meio segundo, o processo inverso de um thread usado para um carregamento completo leva apenas doze milissegundos! O gráfico abaixo é bastante ampliado e, no entanto, a transição da ociosidade para a carga é quase uma linha vertical:

Aumentei o zoom para doze milissegundos e encontrei 500 comutadores de contexto, uma análise cuidadosa é necessária aqui.
A tabela de alternância de contexto possui muitas colunas que
documentei aqui . Quando um processo congela, para encontrar o motivo, faço um agrupamento por novos processos, novos threads, novas pilhas de threads, etc. (
discutido aqui ), mas isso não funciona em centenas de processos interrompidos. Se eu estudei algum processo errado, é claro que ele foi preparado pelo processo anterior, que foi preparado pelo anterior, e percorrerei uma longa cadeia para encontrar o primeiro elo que (presumivelmente) mantém uma trava importante por um longo tempo.
Então, tentei um layout de coluna diferente no programa:
- Hora da alternância (quando ocorreu a alternância de contexto)
- Processo de preparação (que liberou o bloqueio depois de esperar)
- Novo processo (quem começou a trabalhar)
- Tempo desde a última vez (há quanto tempo o novo processo está aguardando)
Isso fornece uma lista ordenada por tempo de alternâncias de contexto com uma anotação de quem preparou quem e por quanto tempo os processos estavam prontos para funcionar.
Acabou que isso é suficiente. A tabela abaixo fala por si só, se você souber ler. As primeiras poucas alternâncias de contexto não são interessantes, porque o tempo de espera para um novo processo (Tempo desde a última vez) é muito pequeno, mas na linha destacada (# 4) começa uma coisa interessante:
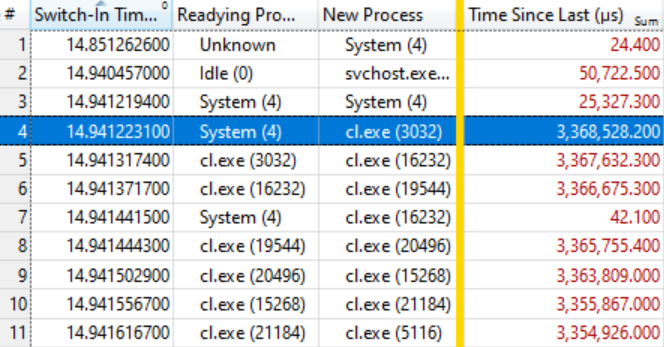
Esta linha diz que o
Sistema (4) preparou o
Exe (3032) , que esperou 3,368 segundos. A linha seguinte diz que em menos de 0,1 ms, o
cl Exe (3032) preparou o
cl.exe (16232) , que esperou 3,367 segundos. E assim por diante
Várias opções de contexto, como na linha 7, não estão incluídas na cadeia de espera, mas simplesmente refletem outros trabalhos no sistema, mas, em geral, a cadeia é esticada para várias dezenas de elementos.
Isso significa que todos esses processos estão aguardando o lançamento do mesmo bloqueio. Quando o processo do
sistema (4) libera o bloqueio (depois de pressioná-lo por 3.368 segundos!), Os processos em espera, por sua vez, o capturam, realizam seu pequeno trabalho e passam o bloqueio. A fila de espera possui cerca de cem processos, o que mostra o grau de influência de um único bloqueio.
Um pequeno estudo do
Ready Thread Stacks mostrou que a maioria das expectativas vem do
KernelBase.dllWriteFile . Pedi ao WPA para exibir os chamadores dessa função, com agrupamento. Lá você pode ver que, em 12 milissegundos dessa catarse, 174 threads saem da espera do
WriteFile e esperaram uma média de 1.184 segundos:
 174 threads aguardando WriteFile, tempo médio de espera 1.184 segundos
174 threads aguardando WriteFile, tempo médio de espera 1.184 segundosEsse é um atraso incrível e, de fato, nem toda a extensão do problema, porque muitos threads de outras funções, como
KernelBase.dll! GetQueuedCompletionStatus, esperam o lançamento do mesmo bloqueio.
O que o sistema faz (4)
Nesse ponto, eu sabia que o progresso da compilação parou porque todos os processos do compilador e outros esperavam o
WriteFile , pois o
System (4) retinha o bloqueio. Outra coluna
Ready Id do segmento mostrou que o segmento 3276 liberou o bloqueio no processo do sistema.
Durante todos os "travamentos" da montagem, o encadeamento 3276 foi 100% carregado, portanto, é claro que ele trabalhou na CPU enquanto mantinha a trava travada. Para descobrir onde o tempo da CPU é gasto, vejamos o
gráfico Uso da
CPU (Amostrado) do thread 3276. Os dados de uso da CPU foram surpreendentemente claros. Quase todo o tempo é necessário o trabalho de uma função
ntoskrnl.exe! RtlFindNextForwardRunClear (o número de amostras é indicado na coluna com números):
 A pilha de chamadas leva ao ntoskrnl.exe! RtlFindNextForwardRunClear
A pilha de chamadas leva ao ntoskrnl.exe! RtlFindNextForwardRunClearA exibição da
ID de thread de preparação da pilha de
threads confirmou que o
NtfsCheckpointVolume liberou o bloqueio após 3.368 s:
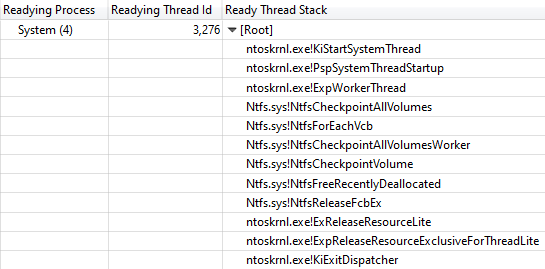 Pilha de chamadas de NtfsCheckpointVolume para ExReleaseResourceLite
Pilha de chamadas de NtfsCheckpointVolume para ExReleaseResourceLiteNesse momento, pareceu-me que estava na hora de usar o rico conhecimento de meus seguidores no Twitter, então postei
essa pergunta e mostrei uma pilha de chamadas completa. Os tweets com essas perguntas podem ser muito eficazes se você fornecer informações suficientes.
Nesse caso, a
resposta certa de
Caitlin Gadd veio muito rapidamente, juntamente com muitas outras ótimas sugestões. Ela desativou o recurso de recuperação do sistema - e de repente a compilação foi duas a três vezes mais rápida!
Mas espere, mais ainda é melhor
Bloquear a execução em todo o sistema por mais de 3 segundos é bastante impressionante, mas a situação é ainda mais impressionante se você adicionar a coluna
Endereço à tabela
Uso de CPU (Amostrada) e classificá-la. Ele mostra onde exatamente
as amostras
RtlFindNextForwardRunClear são obtidas - e 99% delas se enquadram em uma instrução!

Peguei os
arquivos ntoskrnl.exe e
ntkrnlmp.pdb (a mesma versão do meu amigo) e executei o
dumpbin /disasm para visualizar a função de interesse no assembler. Os primeiros dígitos dos endereços são diferentes porque o código é movido na inicialização, mas os últimos quatro valores hexadecimais são os mesmos (eles não mudam após o ASLR):
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx
140064652: 73 0F jae 0000000140064663
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663
140064659: 49 83 C0 04 adicionar r8.4
14006465D: 41 83 C1 20 add r9d, 20h
140064661: EB CE jmp 000000014006464F
...
Vemos que as instruções em ... 4657 estão incluídas em um ciclo de sete instruções, encontradas em outras amostras. O número de tais amostras é indicado à direita:
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx 4
140064652: 73 0F jae 0000000140064663 41
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663 7498
140064659: 49 83 C0 04 adicionar r8.4 2
14006465D: 41 83 C1 20 add r9d, 20h 1
140064661: EB CE jmp 000000014006464F 1
...
Como exercício para o leitor, deixemos a interpretação do número de amostras em um processador superescalar com uma execução extraordinária de instruções, embora algumas boas idéias possam ser encontradas
neste artigo . Nesse caso, temos um AMD Ryzen Threadripper 2990WX de 32 núcleos. Aparentemente, a função de processador do Micro-Up Fusion com a execução de cinco instruções por vez permite que cada ciclo seja concluído em jne, uma vez que a instrução após a instrução mais cara cai na maioria das interrupções na seleção.
Portanto, uma máquina com 64 processadores lógicos para em um ciclo de sete comandos no processo do sistema, mantendo um bloqueio NTFS vital, que é corrigido pela desativação da recuperação do sistema.
Coda
Não está claro por que esse código se comportou mal nessa máquina específica. Suponho que isso esteja relacionado à distribuição de dados em um disco de 2 TB quase vazio. Quando a recuperação do sistema foi reativada, o problema também voltou, mas não tão grave. Talvez haja algum tipo de patologia para discos com enormes fragmentos de espaço vazio?
Outro seguidor no Twitter mencionou o bug Volume Shadow Copy do Windows 7, que permite a
execução durante O (n ^ 2) . Este erro foi corrigido no Windows 8, mas pode ter sido preservado de alguma forma. Meus rastreamentos de pilha mostram claramente que
VspUpperFindNextForwardRunClearLimited (localizando um bit usado nesta área de 16 megabytes) chama
VspUpperFindNextForwardRunClear (procurando o próximo bit usado em qualquer lugar, mas não o retorna se estiver fora da área especificada). Obviamente, isso causa um certo senso de déjà vu. Como eu
disse recentemente , O (n ^ 2) é um ponto fraco de algoritmos pouco escaláveis. Dois fatores coincidem aqui: esse código é rápido o suficiente para entrar em produção, mas lento o suficiente para interromper essa produção.
Houve relatos de que um problema semelhante ocorre com uma
exclusão maciça de arquivos , mas nosso rastreamento não mostra muitas exclusões; portanto, o problema, aparentemente, não é esse.
Concluindo, duplicarei a programação de carregamento da CPU em todo o sistema desde o início do artigo, mas desta vez indicando o uso da CPU pelo processo de problemas do
sistema (em verde abaixo). Nessa imagem, o problema é completamente óbvio. O processo do sistema é tecnicamente visível no gráfico superior, mas nessa escala é fácil perder.
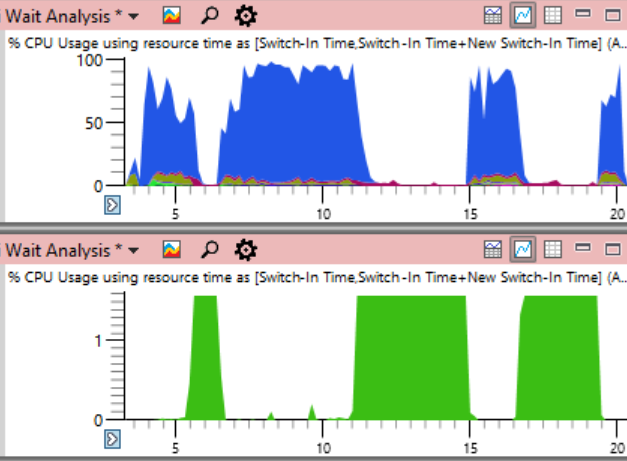
Embora o problema esteja claramente visível no gráfico, na verdade não prova nada.
Como se costuma dizer , a correlação não é uma relação causal. Somente uma análise dos eventos de alternância de contexto mostra que é esse fluxo que mantém o bloqueio crítico - e então você pode ter certeza de que encontramos a causa real, e não apenas uma correlação aleatória.
Inquéritos
Como sempre, concluo esta investigação com uma
chamada para melhor nomear os threads . O processo do sistema possui dezenas de threads, muitos dos quais com uma finalidade especial e nenhum com um nome. O segmento do sistema mais ocupado nesse rastreamento foi o
MiZeroPageThread . Eu mergulhava repetidamente em sua pilha, e cada vez que lembrava que não era do seu interesse. O compilador VC ++ também não nomeia seus threads. Não leva muito tempo para renomear os fluxos e é realmente útil. Apenas dê o nome.
É simples O Chromium ainda inclui uma ferramenta para
listar nomes de fluxos em um processo .
Se alguém da equipe NTFS da Microsoft quiser falar sobre esse tópico, informe-me e eu posso conectá-lo ao autor do relatório original e fornecer um rastreamento ETW.
Referências