
Olá Habr! Continuamos a publicar resenhas de artigos científicos de membros da comunidade Open Data Science no canal #article_essense. Se você deseja recebê-los antes de todos os outros - participe da comunidade !
Artigos para hoje:
- Rotação de camadas: um indicador surpreendentemente poderoso de generalização em redes profundas? (Université catholique de Louvain, Bélgica, 2018)
- Aprendizado de transferência eficiente em parâmetros para PNL (Google Research, Jagiellonian University, 2019)
- RoBERTa: Uma Abordagem de Pré-Treino BERT Robustamente Otimizada (Universidade de Washington, Facebook AI, 2019)
- EfficientNet: Repensando o dimensionamento de modelos para redes neurais convolucionais (Google Research, 2019)
- Como o cérebro transita da percepção consciente para a subliminar (EUA, Argentina, Espanha, 2019)
- Grandes camadas de memória com chaves de produto (Facebook AI Research, 2019)
- Realmente estamos fazendo muito progresso? Uma análise preocupante das recentes abordagens de recomendação neural (Politecnico di Milano, University of Klagenfurt, 2019)
- Omni-Scale Feature Learning for Person Re-Identification (Universidade de Surrey, Universidade Queen Mary, Samsung AI, 2019)
- A reparameterização neural melhora a otimização estrutural (Google Research, 2019)
Links para coleções anteriores da série: 1. Rotação de camada: um indicador surpreendentemente poderoso de generalização em redes profundas?
Autores: Simon Carbonnelle, Christophe De Vleeschouwer (Université catholique de Louvain, Bélgica, 2018)
→ Artigo original
Autor da resenha: Svyatoslav Skoblov (em erro folgado_derivativo)

Neste artigo, os autores chamaram atenção para uma observação bastante simples: distância do cosseno entre os pesos da camada durante a inicialização e após o treinamento (o processo de aumentar a distância durante o treinamento é chamado de rotação da camada). Os senhores dizem que, na maioria dos experimentos, as redes que atingiram uma distância de 1 em todas as camadas são consistentemente superiores em precisão a outras configurações. O artigo também apresenta o algoritmo Layca (quantidade controlada em nível de camada de rotação de peso), que permite o uso dessa taxa de aprendizado em camadas para controlar essa mesma rotação de camada. De fato, difere do algoritmo SGD usual pela presença de projeção ortogonal e normalização. Uma lista detalhada do algoritmo, juntamente com o esquema de treinamento, pode ser encontrada no artigo.
A principal idéia que os autores deduzem é: quanto maiores as rotações da camada, melhor o desempenho da generalização . A maior parte do artigo é um registro de experimentos em que foram estudados vários cenários de treinamento: MNIST, CIFAR-10 / CIFAR-100, pequena ImageNet com arquiteturas diferentes, de uma rede de camada única à família ResNet.
Uma série de experimentos foi dividida em várias etapas:
- Vanilla SGD Verificou- se que, no geral, o comportamento das escalas coincide com a hipótese (grandes mudanças na distância correspondiam aos melhores valores métricos), no entanto, também foram notados problemas: a rotação da camada parou muito antes dos valores desejados; Também foi notada instabilidade na mudança de distância.
- Deterioração de peso SGD + A diminuição da norma de peso melhorou muito a imagem do treinamento: a maioria das camadas alcançou a distância máxima e o desempenho do teste é semelhante ao Layca proposto. A vantagem indubitável do método do autor é a falta de um hiperparâmetro adicional.
- Aquecimentos de LR Acontece que o aquecimento ajuda a SGD a superar o problema da rotação instável das camadas, no entanto, não afeta o Layca.
- Métodos adaptativos de gradiente Além da verdade conhecida (que usando esses métodos é mais difícil alcançar o nível de generalização que o decaimento de peso SGD + pode dar), descobriu-se que os efeitos da rotação de camadas são muito diferentes: o primeiro aumenta a rotação nas últimas camadas, enquanto o SGD nas camadas iniciais . Os autores sugerem que essa pode ser a maldade dos métodos adaptativos. E eles sugerem o uso do Layca em conjunto com eles (melhorando a capacidade de generalizar em métodos adaptativos e acelerando o aprendizado no SGD).
O artigo termina com uma tentativa de interpretar o fenômeno. Para fazer isso, os autores treinaram uma rede com 1 camada oculta em uma versão simplificada do MNIST, após o que visualizaram neurônios aleatórios, chegando a uma conclusão bastante lógica: um maior grau de rotação da camada corresponde a um menor efeito de inicialização e melhor estudo de características, o que contribui para uma melhor generalização.
O código do algoritmo implementado (tf / keras) e o código para reproduzir experimentos são carregados .
2. Aprendizado de transferência eficiente em parâmetros para a PNL
Autores do artigo: Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly (Pesquisa do Google, Universidade Jagiellonian, 2019)
→ Artigo original
Autor do comentário: Alexey Karnachev (em slack zhirzemli)
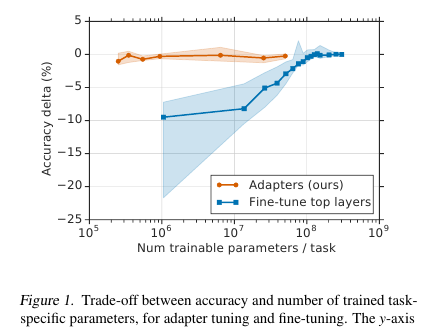
Aqui, os cavalheiros oferecem uma técnica de ajuste fino simples, porém eficaz, para os modelos de PNL (neste caso, BERT). A idéia é incorporar camadas de aprendizado (adaptadores) diretamente na rede. Cada uma dessas camadas é uma rede com um gargalo, que adapta os estados latentes do modelo original a uma tarefa de downstream específica. Os pesos do modelo original, por sua vez, permanecem congelados.
Motivação
Nas condições do treinamento de streaming (ou treinamento quase on-line), onde há muitas tarefas de downstream, não quero realmente arquivar o modelo inteiro. Em primeiro lugar, por um longo período de tempo, e em segundo lugar, é difícil e, em terceiro lugar, mesmo que seja apertado, o modelo precisa ser armazenado de alguma forma: para despejar ou guardar na memória. E não poderemos reutilizar esse modelo para a seguinte tarefa: cada vez que precisarmos ajustar de uma nova maneira. Como resultado, podemos tentar adaptar os estados da rede oculta ao problema atual. Além disso, o modelo original permanece intocado e os adaptadores em si são muito mais amplos que o modelo principal (~ 4% do número total de parâmetros)
Implementação
O problema é resolvido de uma maneira incrivelmente simples: adicionamos 2 adaptadores a cada camada do modelo. Antes da normalização da camada em modelos baseados em transformadores, ocorre a conexão de ignição: a entrada transformada (estado oculto atual) é adicionada à entrada original.
Existem duas seções em cada camada do transformador: uma após atenção múltipla e a segunda após alimentação para a frente. Portanto, os estados ocultos dessas seções são passados adicionalmente pelo adaptador: uma rede rasa com uma camada oculta de 1 gargalo e com saída na mesma dimensão da entrada. A não-linearidade é aplicada ao estado do gargalo e a Entrada (conexão sem fio) é adicionada à saída. Acontece que o número total de parâmetros treinados é: 2md + m + d, em que d é a dimensão do estado oculto do modelo original, m é o tamanho da camada do adaptador de gargalo. Acontece que, para o modelo de base BERT (12 camadas, parâmetros de 110M) e para o tamanho do adaptador, obtemos 4,3% do número total de parâmetros
Resultados
A comparação foi feita com o ajuste completo do modelo. Para todas as tarefas, essa abordagem mostrou uma pequena perda de métricas (em média, menos de 1 ponto), com o número de pesos treinados - 3% do total. Não vou listar as tarefas, existem muitas, há um tablet no artigo.
Ajuste fino
Nesse modelo, apenas a parte do adaptador é ajustada (+ o próprio classificador de saída). Para escalas de adaptadores, eles propõem a inicialização por quase identidade. Assim, um modelo não treinado não alterará os estados da rede oculta de maneira alguma, e isso permitirá já no processo de treinamento do modelo decidir quais estados se adaptarão à tarefa e quais permanecerão inalterados.
A taxa de aprendizado recomenda tomar mais do que com a sintonia fina padrão do BERT. Pessoalmente, na minha tarefa, o 1e-04 lr funcionou bem. Além disso, (já pessoalmente, minha observação) durante o processo de ajuste, o modelo quase sempre explode gradientes, portanto, lembre-se de fazer um recorte. Optimizer - Adam com aquecimento 10%
Código
O código em seu artigo está anexado. Implementação no Tensorflow .
Para o Torch, o autor da revisão transferiu pytorch-transformers e adicionou uma camada Adapter (no início do arquivo README.md, há um pequeno manual de inicialização)
3. RoBERTa: Uma abordagem de pré-formação robusta e otimizada da BERT
Autores: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer e Veselin Stoyanov (Universidade de Washington, Facebook AI, 2019)
→ Artigo original
Autor do comentário: Artem Rodichev (in slack fuckai)
Aumentou dramaticamente a qualidade dos modelos BERT, primeiro lugar na tabela de classificação GLUE e SOTA em muitas tarefas de PNL. Eles sugeriram várias maneiras de treinar o modelo BERT da melhor maneira possível, sem nenhuma alteração na arquitetura do modelo.
Principais diferenças com o BERT original:
- Aumento da construção de trens 10 vezes, de 16 GB de texto bruto para 160 GB
- Mascaramento dinâmico feito para cada amostra
- Removido o uso da próxima frase de previsão de perda
- Aumentou o tamanho do mini-lote de 256 amostras para 8k
- Codificação BPE aprimorada ao converter o banco de dados de Unicode em bytes.
O melhor modelo final foi treinado em 1024 placas Nvidia V100 (128 servidores DGX-1) por 5 dias.
A essência da abordagem:
Dados. Além dos shells do Wiki e do BookCorpus (16 GB no total), que ensinaram o BERT original, eles adicionaram mais 3 shells maiores, todos em inglês:
- SS-News 63 milhões de notícias em 2,5 anos com 76GB
- OpenWebText é a estrutura na qual o OpenAI aprendeu o modelo GPT2. Estes são artigos rastreados para os quais foram fornecidos links em postagens em um reddit com pelo menos três atualizações. Dados de 38GB
- Histórias - Caso de 31 GB CommonCrawl Story
Mascaramento dinâmico. No BERT original, 15% dos tokens são mascarados em cada amostra e esses tokens são previstos usando a parte não mascarada da sequência. Uma máscara é gerada para cada amostra uma vez durante o pré-processamento e não muda. Ao mesmo tempo, a mesma amostra no trem pode ocorrer várias vezes, dependendo do número de épocas no corpo. A idéia do mascaramento dinâmico é criar uma nova máscara para a sequência a cada vez, em vez de usar uma máscara fixa no pré-processamento.
Objetivo da próxima frase de previsão. Vamos apenas cortar esse objetivo e ver se ficou pior? Melhorou ou também permaneceu - nas tarefas SQuAD, MNLI, SST e RACE.
Aumente o tamanho do mini lote. Em muitos lugares, em particular na tradução automática, foi demonstrado que quanto maior o minilote, melhores os resultados finais do trem. Eles mostraram que se você aumentar o minibatch de 256 amostras, como no BERT original, para 2k e depois para 8k, a perplexidade na validação diminui e as métricas no MNLI e SST-2 aumentam.
BPE O BPE da implementação original do BERT usa caracteres Unicode como base para unidades de subpalavras. Isso leva ao fato de que, em casos grandes e diversos, uma parte significativa do dicionário será ocupada por caracteres Unicode individuais. O OpenAI de volta ao GPT2 sugeriu o uso de caracteres não Unicode, mas bytes como base para subpalavras. Se usarmos um dicionário de 50k BPE, não teremos tokens desconhecidos. Comparado com o BERT original, o tamanho do modelo cresceu 15 milhões de parâmetros para o modelo base e 20 milhões para grandes, ou seja, 5 a 10% a mais.
Resultados:
BERT-large e XLNet-large são usados como modelos para comparação. O RoBERTa em si é o mesmo em parâmetros que o BERT-large e, como resultado, eles conquistaram o primeiro lugar no benchmark GLUE. Usamos o ajuste de arquivos de tarefa única, diferentemente de muitas outras abordagens do topo do benchmark GLUE que fazem o ajuste de arquivos de tarefas múltiplas. Nas meninas do GLUE, os resultados de modelo único são comparados, eles obtiveram SOTA em todas as 9 tarefas. No conjunto de teste, o conjunto de modelos é comparado, SOTA para 4 de 9 tarefas e a velocidade final da cola. Em duas versões do SQuAD na rede de desenvolvimento SOTA, no conjunto de teste no nível XLNet. Além disso, ao contrário da XLNet, eles não são pegos em pacotes adicionais de controle de qualidade antes de resolver o SQuAD.

Tarefa SOTA on RACE na qual um pedaço de texto é fornecido, uma pergunta sobre este texto e 4 opções de resposta onde você precisa escolher o caminho certo. Para resolver essa tarefa, eles concatenam o texto, a pergunta e a resposta, executam o BERT, obtêm uma representação do token CLF, aplicam-se a uma camada totalmente conectada e prevêem se a resposta está correta. Isso é feito 4 vezes - para cada uma das opções de resposta.
Publicamos o código e o pré-treino do modelo RoBERTa no nabo fairseq . Você pode usá-lo, tudo parece limpo e simples.
4. EfficientNet: Repensando o Escalonamento de Modelos para Redes Neurais Convolucionais
Autores: Mingxing Tan, Quoc V. Le (Google Research, 2019)
→ Artigo original
Autor do artigo: Alexander Denisenko (na folga Alexander Denisenko)

Eles estudam o dimensionamento (dimensionamento) dos modelos e o equilíbrio entre eles, a profundidade e a largura (número de canais) da rede, bem como a resolução das imagens na grade. Eles oferecem um novo método de dimensionamento que dimensiona uniformemente a profundidade / largura / resolução. Mostre sua eficácia no MobileNet e ResNet.
Eles também usam a Pesquisa de arquitetura neural para criar uma nova malha e escalá-la, obtendo assim uma classe de novos modelos - EfficientNets. Eles são melhores e muito mais econômicos do que as redes anteriores. No ImageNet, o EfficientNet-B7 atinge 84,4% de precisão no top 1 e 97,1% no top 5, sendo 8,4 vezes menor e 6,1 vezes mais rápido em inferência do que o atual ConvNet, o melhor da categoria. Ele transfere bem para outros conjuntos de dados - eles obtiveram SOTA em 5 dos 8 conjuntos de dados mais populares.
Escala de modelo composto
A escala é quando as operações executadas dentro da grade são fixas e apenas a profundidade (número de repetições dos mesmos módulos) d, largura (número de canais em convolução) e resolução r são alteradas. No pager, o dimensionamento é formulado como um problema de otimização - queremos a Precisão máxima (Net (d, w, r)), apesar do fato de não rastrearmos a memória e os FLOPS.
Realizamos experimentos e nos certificamos de que realmente ajuda a dimensionar em profundidade e resolução ao dimensionar em largura. Com os mesmos FLOPS, obtemos um resultado significativamente melhor no ImageNet (veja a figura acima). Em geral, isso é razoável, porque parece que ao aumentar a resolução da imagem da rede, são necessárias mais camadas em profundidade para aumentar o campo receptivo e mais canais para capturar todos os padrões da imagem com uma resolução mais alta.
A essência da escala composta: tomamos o coeficiente composto phi, que escala uniformemente d, we er com este coeficiente: onde - constantes obtidas de uma pequena exibição na grade de origem. - coeficiente que caracteriza a quantidade de recursos computacionais disponíveis.
Rede eficiente
Para criar a grade, utilizamos a pesquisa de arquitetura neural multiobjetivo, precisão e FLOPS otimizados com o parâmetro responsável pela troca entre eles. Essa pesquisa deu ao EfficientNet-B0. Em resumo - Conv seguido por vários MBConv, no final de Conv1x1, Pool, FC.
Em seguida, faça o dimensionamento em duas etapas:
- Para começar, consertamos , faça pesquisa em grade para pesquisa .
- Escale a grade usando as fórmulas para d, we er. Obtive o EffiientNet-B1. Da mesma forma, aumentar , obtenha o EfficientNet-B2, ... B7.
Escalado para diferentes ResNet e MobileNet, em todos os lugares recebeu melhorias significativas no ImageNet, o escalonamento composto proporcionou um aumento significativo em comparação ao escalonamento em apenas uma dimensão. Também conduzimos experimentos com o EfficientNet em oito conjuntos de dados mais populares, em todos os lugares onde obtivemos o SOTA ou um resultado próximo a ele com um número significativamente menor de parâmetros.
Código
5. Como o cérebro transita da percepção consciente para a subliminar
Autores do artigo: Francesca Arese Lucini, Gino Del Ferraro, Mariano Sigman, Hernan A. Makse (EUA, Argentina, Espanha, 2019)
→ Artigo original
Autor da resenha: Svyatoslav Skoblov (em erro folgado_derivativo)
Este artigo é uma continuação e repensar o trabalho de Dehaene, S, Naccache, L, Cohen, L, Le Bihan, D, Mangin, JF, Poline, JB e Rivie`re, D. Mecanismos cerebrais de mascaramento de palavras e priming inconsciente de repetições , em que os autores tentaram considerar os modos de funcionamento cerebral consciente e inconsciente.
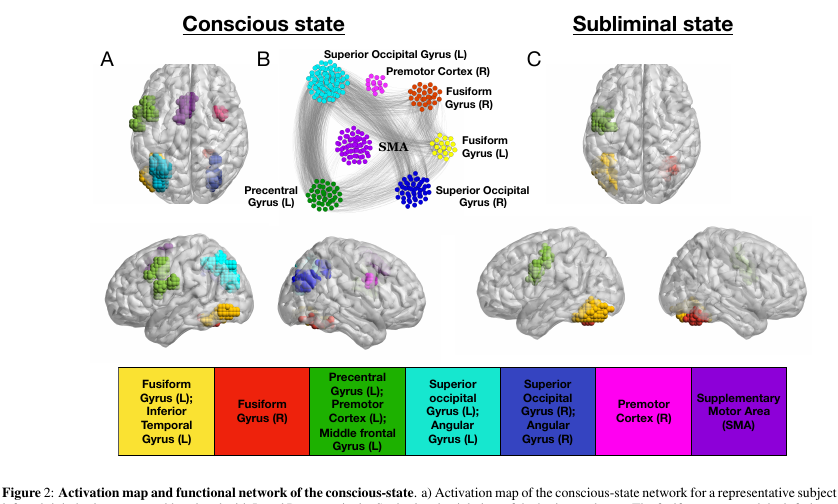
Experiência:
Os voluntários recebem figuras (palavras de 4 letras, uma tela em branco ou rabiscos). Cada um deles é mostrado por 30 ms, em geral, toda a ação dura 5 minutos.
- No modo experimental "consciente", uma tela em branco alterna com palavras, o que permite que uma pessoa perceba conscientemente o texto.
- No modo "inconsciente", as palavras se alternam com rabiscos, o que interfere de maneira bastante eficaz na percepção do texto em um nível consciente.
Dados:
Durante esta apresentação, os cérebros de nossos primatas foram escaneados usando a ressonância magnética. No total, os pesquisadores tiveram 15 voluntários, cada um repetiu o experimento 5 vezes, um total de 75 fluxos de fMRI. Vale ressaltar que a varredura do voxel acabou sendo bastante grande (muito simplificada: o voxel é um cubo 3D que contém um número bastante grande de células) - 4x4x4mm.
Magia:
Vamos chamar o nó de voxel ativo do nosso fluxo. Como o cérebro é um pano de prato modular, introduzimos nele dois tipos de conexões: externa e interna (correspondente ao arranjo espacial dos nós). As conexões são montadas de uma maneira interessante: construímos uma matriz de correlação cruzada entre nós e conectamos os nós a uma conexão se a correlação for maior que algum parâmetro adaptável lambda. Este parâmetro afeta a descarga da nossa rede.
O ajuste dos parâmetros é realizado usando o procedimento de "filtragem". Se influenciarmos nosso lambda um pouco, as transições nítidas entre as dimensões finais da rede se tornarão visíveis (ou seja, uma alteração de parâmetro suficientemente pequena corresponde a um grande incremento de tamanho).
Portanto: as conexões internas são ativadas pelo valor lambda-1, que corresponde ao valor lambda antes de uma transição acentuada. Externo - valor lambda-2 correspondente ao valor lambda imediatamente após uma transição acentuada.
Magia 2:
filtragem k-core. O conceito k-core descreve a conectividade de rede e é formulado de maneira simples: a sub-rede máxima, cujos nós de todos têm pelo menos k vizinhos. Essa sub-rede pode ser obtida pela remoção iterativa de nós com menos de k vizinhos. Como os nós restantes perderão vizinhos, o processo continuará até que não haja nada a ser excluído. O que resta é a rede k-core.
Resultados:
Ao aplicar esta artilharia em nossos cérebros, você pode ver uma série de características muito interessantes.
- O número de nós no núcleo k com k pequeno / muito grande é extremamente grande. Mas para o k médio, pelo contrário, não é suficiente. Na figura, parece uma forma de U, ou seja, essa configuração de rede oferece a maior estabilidade do sistema (resistência a erros locais e globais).
- e os nós mais importantes pertencentes ao k-core com k pequeno podem ser vistos em quase qualquer estado da rede. Mas um núcleo k com k muito grande é característico apenas para as partes do cérebro que estão ativas no estado inconsciente, o giro fusiforme e o giro precentral esquerdo . As mesmas partes do córtex são mais ativas e em estado consciente.
Para verificar o resultado, os autores criaram um milhão de redes aleatórias baseadas em redes reais, realizando a fiação aleatória, mantendo o grau original dos nós (o mesmo que o grau do vértice no gráfico). Redes reais diferiam das aleatórias por valores muito maiores de k máximo. Ao mesmo tempo, a forma em U do número de nós nos clusters permaneceu perceptível em redes aleatórias, o que levou os autores à idéia de que é o grau dos nós que é responsável por esse fenômeno.
Conclusões:
, , , . , , , - ( , , , ).
, , , , , , , - . , , qualia.
6. Large Memory Layers with Product Keys
: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→
: ( belerafon)

, key-value , .
- attention. q, k v. q, k, , value . , . , . , , . - q (, -10). . .
— q k . , "Product Keys". , q , . -10 , , O(N) "" , (sqrt(N)).
key-value . , ( , ). , BERT 28 . , , . : 12- 2 , 24- , perplexity .
( self-attention). , - . , multy-head attention. I.e. query , value, . -.
, , , , BERT . .
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→
: ( netcitizen)

DL , , .
DL top-n. DL KDD, SIGIR, TheWebConf (WWW) RecSys :
- -
- 7/18 (39%)
- “” train/test, ., , , .
- (Variational Autoencoders for Collaborative Filtering (Mult-VAE) ± ) KNN, SVD, PR.
DL, CV, NLP , .
8. Omni-Scale Feature Learning for Person Re-Identification
: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→
: ( graviton)
Person Re-Identification, Face Recognition, , . (Kaiyang Zhou) deep-person-reid , (OSNet), Person Re-Identification. .
Person Re-Identification:

:
- conv1x1 deepwise conv3x3 conv3x3 (figure 3).
- , . ResNeXt , Inception (figure 4).
- “aggregation gate” . , Inception .

OSNet , .. , : ( , ) .
ReID OSNet ( 2 ) (Market: R1 93.6%, mAP 81.0% OSNet R1 87.0%, mAP 69.5% MobileNetV2) ResNet DenseNet (Market: R1 94.8%, mAP 84.9% OSNet R1 94.8%, mAP 86.0% ResNet).
Outro desafio é a adaptação do domínio : modelos treinados em um conjunto de dados têm baixa qualidade em outro. A OSNet também mostra bons resultados nesse segmento sem o uso de "adaptação de domínio não supervisionada" (usando dados de teste de forma não alocada para uniformizar a distribuição dos dados).
A arquitetura também foi testada no ImageNet, onde alcançou precisão semelhante com o MobileNetV2 com menos parâmetros, mas mais operações.
9. Reparameterização neural melhora a otimização estrutural
Autores: Stephan Hoyer, Jascha Sohl-Dickstein, Sam Greydanus (Google Research, 2019)
→ Artigo original
Autor do comentário: Alexey (em Arech slack)
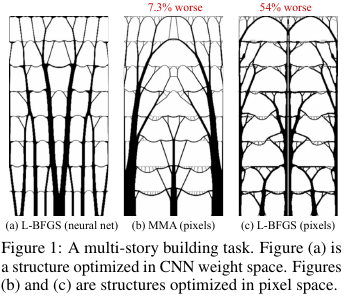
Na construção e outras tecnologias, há tarefas de otimizar a estrutura / topologia de alguma solução. Grosso modo, esta é uma resposta do computador para uma pergunta como, por exemplo, como projetar uma ponte / construção / asa de um avião / lâmina de turbina / blablabla, para que certas restrições sejam cumpridas e a estrutura seja suficientemente forte. Há um conjunto de métodos de solução "padrão" - ele funciona, mas nem sempre tudo é bom lá.
O que esses caras do Google inventaram? Eles disseram: vamos gerar uma solução por uma rede neural (a parte de upsampling da UNet) e, em seguida, usar um modelo físico diferenciável, que calculará o comportamento de uma solução sob a influência de todas as forças e gravidade, calcule a função objetivo - força (mais precisamente, o inverso - conformidade) ) designs. Então, como tudo é automaticamente diferenciável, obtemos o gradiente da função objetivo, que é empurrada por toda a estrutura de volta aos pesos e à entrada da rede neural. Alteramos pesos e entrada e continuamos o ciclo até a convergência para uma solução estável.
Os resultados acabaram sendo pequenos (em termos de tamanho do espaço de possíveis soluções) comparáveis aos métodos tradicionais de otimização de topologias e, para grandes problemas, são visivelmente melhores que os tradicionais (excesso de peso em 99 versus 66 em 116 problemas). Além disso, as soluções resultantes costumam ser significativamente mais tecnológicas e ideais do que as decisões das linhas de base.
I.e. na verdade, eles usaram o NS como uma maneira complicada de parametrizar o modelo físico da estrutura, que implicitamente (devido à arquitetura do NS) é capaz de impor algumas restrições úteis aos valores dos parâmetros (controlado pela remoção do NS do método e otimização direta dos valores de pixel).
Código fonte
Uma visão geral mais detalhada deste artigo no habr.