Carrinho Voador, Afu ChanTrabalho no
Mail.ru Cloud Solutons como arquiteto e desenvolvedor, incluindo minha nuvem. Sabe-se que uma infraestrutura de nuvem distribuída precisa de um armazenamento em bloco produtivo, do qual depende a operação dos serviços e soluções PaaS criados usando eles.
Inicialmente, ao implantar essa infraestrutura, usamos apenas Ceph, mas gradualmente o armazenamento em bloco evoluiu. Queríamos que
nossos bancos de dados , armazenamento de arquivos e vários serviços funcionassem com o desempenho máximo, por isso adicionamos armazenamentos localizados e configuramos o monitoramento avançado do Ceph.
Vou contar como foi - talvez essa história, os problemas que encontramos e nossas soluções sejam úteis para quem também usa o Ceph. A propósito,
aqui está uma versão em vídeo deste relatório.
Dos processos do DevOps à sua própria nuvem
As práticas de DevOps visam implantar o produto o mais rápido possível:
- Automação de processos - todo o ciclo de vida: montagem, teste, entrega ao teste e produtivo. Automatize os processos gradualmente, começando com pequenas etapas.
- A infraestrutura como um código é um modelo quando o processo de configuração da infraestrutura é semelhante ao processo de programação de software. Primeiro eles testam o produto, o produto possui certos requisitos para a infraestrutura e a infraestrutura precisa ser testada. Nesta fase, com o desejo de que ela apareça, eu quero “ajustar” a infraestrutura - primeiro no ambiente de teste, depois no supermercado. No primeiro estágio, isso pode ser feito manualmente, mas eles passam para a automação - para o modelo "infraestrutura como código".
- Virtualização e contêineres - aparecem na empresa quando fica claro que você precisa colocar processos em uma trilha industrial, implantar novos recursos mais rapidamente, com o mínimo de intervenção manual.
 A arquitetura de todos os ambientes virtuais é semelhante: máquinas convidadas com contêineres, aplicativos, redes públicas e privadas, armazenamento.
A arquitetura de todos os ambientes virtuais é semelhante: máquinas convidadas com contêineres, aplicativos, redes públicas e privadas, armazenamento.Gradualmente, mais e mais serviços são implantados na infraestrutura virtual integrada nos processos DevOps e o ambiente virtual está se tornando não apenas um teste (usado para desenvolvimento e teste), mas também produtivo.
Como regra, nos estágios iniciais, eles são ignorados pelas ferramentas básicas de automação mais simples. Porém, à medida que novas ferramentas são atraídas, mais cedo ou mais tarde, é necessário implantar uma plataforma em nuvem completa para usar as ferramentas mais avançadas como a Terraform.
Nesse estágio, a infraestrutura virtual de "hipervisores, redes e armazenamento" se transforma em uma infraestrutura de nuvem completa com ferramentas e componentes desenvolvidos para orquestrar processos. Em seguida, aparece a própria nuvem, na qual ocorrem os processos de teste e entrega automatizada de atualizações dos serviços existentes e a implantação de novos serviços.
A segunda maneira de sua própria nuvem é a necessidade de não depender de recursos externos e provedores de serviços externos, ou seja, fornecendo alguma independência técnica para seus próprios serviços.
 A primeira nuvem parece quase uma infraestrutura virtual - um hipervisor (um ou vários), máquinas virtuais com contêineres, armazenamento compartilhado: se você construir a nuvem não em soluções proprietárias, geralmente é Ceph ou DRBD.
A primeira nuvem parece quase uma infraestrutura virtual - um hipervisor (um ou vários), máquinas virtuais com contêineres, armazenamento compartilhado: se você construir a nuvem não em soluções proprietárias, geralmente é Ceph ou DRBD.Resiliência e desempenho da nuvem privada
A nuvem está crescendo, os negócios dependem cada vez mais, a empresa começa a exigir maior confiabilidade.
Aqui, a distribuição é adicionada à nuvem privada, a infraestrutura de nuvem distribuída aparece: pontos adicionais em que o equipamento está localizado. A nuvem gerencia duas, três ou mais instalações construídas para fornecer uma solução tolerante a falhas.
Ao mesmo tempo, são necessários dados de todos os sites, e há um problema: em um site não há grandes atrasos na transferência de dados, mas entre sites, os dados são transmitidos mais lentamente.
 Sites de instalação e armazenamento comum. Retângulos vermelhos são gargalos no nível da rede.
Sites de instalação e armazenamento comum. Retângulos vermelhos são gargalos no nível da rede.A parte externa da infraestrutura do ponto de vista da rede de gerenciamento ou da rede pública não está tão ocupada, mas na rede interna os volumes de dados transferidos são muito maiores. E em sistemas distribuídos, os problemas começam, expressos em um longo tempo de serviço. Se o cliente chegar a um grupo de nós de armazenamento, os dados deverão ser replicados instantaneamente para o segundo grupo para que as alterações não sejam perdidas.
Para alguns processos, a latência de replicação de dados é aceitável, mas em casos como o processamento de transações, as transações não podem ser perdidas. Se a replicação assíncrona for usada, ocorrerá um intervalo de tempo que poderá levar à perda de parte dos dados, se uma das "falhas" do sistema de armazenamento (sistema de armazenamento de dados) falhar. Se a replicação síncrona for usada, o tempo de serviço aumentará.
Também é bastante natural que, quando o tempo de processamento (latência) do armazenamento aumentar, os bancos de dados comecem a ficar mais lentos e houver efeitos negativos que precisam ser combatidos.
Em nossa nuvem, buscamos soluções equilibradas para manter a confiabilidade e o desempenho. A técnica mais simples é localizar os dados - e adicionamos clusters Ceph localizados adicionais.
 A cor verde indica clusters Ceph localizados adicionais.
A cor verde indica clusters Ceph localizados adicionais.A vantagem de uma arquitetura tão complexa é que aqueles que precisam de entrada / saída rápida de dados podem usar armazenamentos localizados. Os dados para os quais a disponibilidade total é crítica em dois sites estão em um cluster distribuído. Funciona mais devagar - mas os dados são replicados nos dois sites. Se seu desempenho não for suficiente, você poderá usar clusters Ceph localizados.
A maioria das nuvens públicas e privadas acaba chegando ao mesmo padrão de trabalho, quando, dependendo dos requisitos, a carga é implantada em diferentes tipos de armazenamento (tipos diferentes de discos).
Diagnóstico ceph: como criar monitoramento
Quando implantamos e lançamos a infraestrutura, era hora de garantir seu funcionamento, minimizar o tempo e o número de falhas. Portanto, o próximo passo no desenvolvimento da infraestrutura foi a construção de diagnósticos e monitoramento.
Considere toda a tarefa de monitoramento - temos uma pilha de aplicativos em um ambiente de nuvem virtual: um aplicativo, um sistema operacional convidado, um dispositivo de bloco, os drivers desse dispositivo de bloco em um hipervisor, uma rede de armazenamento e o sistema de armazenamento real (sistema de armazenamento). E tudo isso ainda não foi coberto pelo monitoramento.
 Elementos não cobertos pelo monitoramento.
Elementos não cobertos pelo monitoramento.O monitoramento é implementado em várias etapas, começamos com discos. Obtemos o número de operações de leitura / gravação, com certa precisão, o tempo de serviço (megabytes por segundo), a profundidade da fila e outras características, e também coletamos a SMART sobre o estado dos discos.
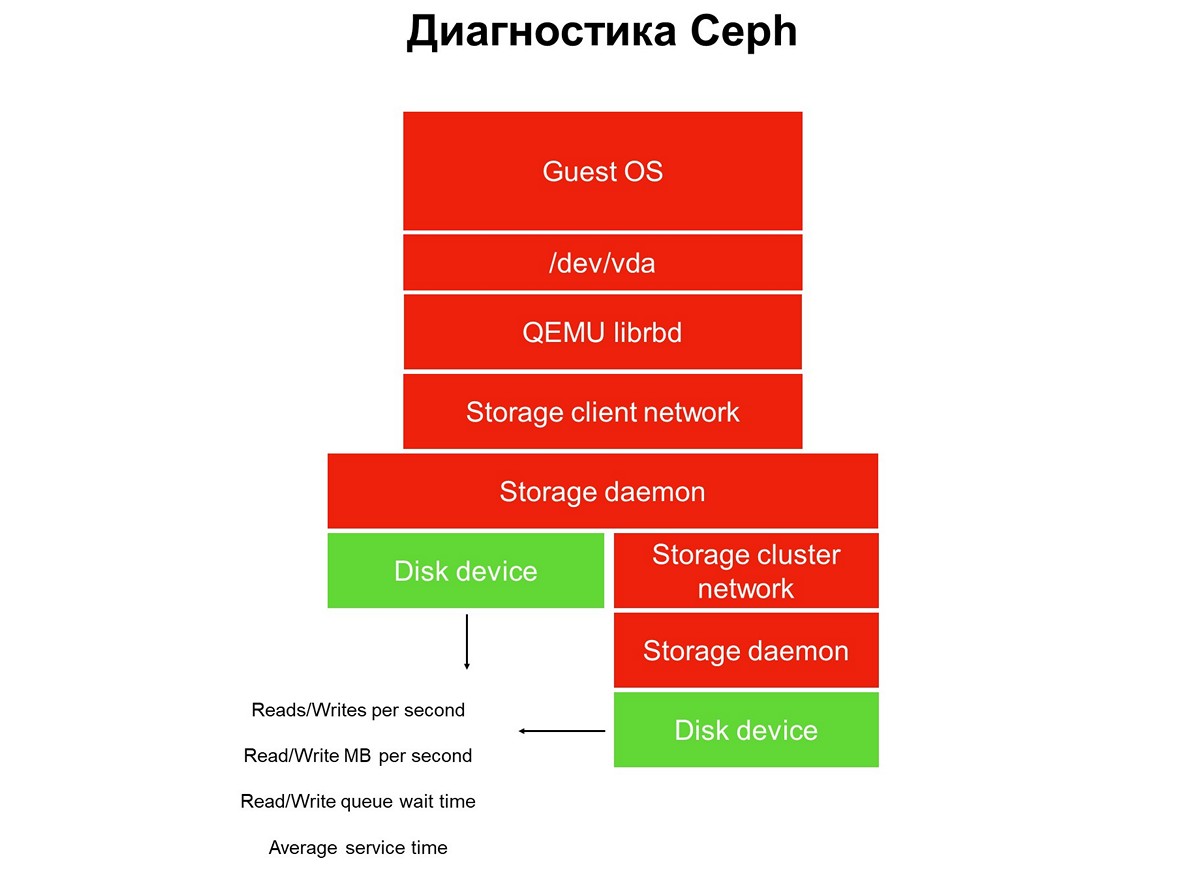 A primeira etapa: cobrimos os discos de monitoramento.
A primeira etapa: cobrimos os discos de monitoramento.O monitoramento de disco não é suficiente para obter uma imagem completa do que está acontecendo no sistema. Portanto, passamos a monitorar um elemento crítico da infraestrutura - a rede do sistema de armazenamento. Na verdade, existem dois deles - o cluster interno e o cliente, que conecta os clusters de armazenamento aos hipervisores. Aqui temos as taxas de transferência de pacotes de dados (megabytes por segundo, pacotes por segundo), o tamanho das filas de rede, buffers e possivelmente caminhos de dados.
 Segunda etapa: monitoramento de rede.
Segunda etapa: monitoramento de rede.Eles costumam parar nisso, mas isso não pode ser feito, porque a maior parte da infraestrutura ainda não foi fechada pelo monitoramento.
Todo o armazenamento distribuído usado em nuvens públicas e privadas é SDS, armazenamento definido por software. Eles podem ser implementados nas soluções de um fornecedor específico, soluções de código aberto, você pode fazer algo usando uma pilha de tecnologias familiares. Mas é sempre SDS, e o trabalho dessas partes do software deve ser monitorado.
 Terceira etapa: monitorando o daemon de armazenamento.
Terceira etapa: monitorando o daemon de armazenamento.A maioria dos operadores do Ceph usa dados coletados dos daemons de monitoramento e controle do Ceph (monitor e gerente, também conhecido como mgr). Inicialmente, seguimos o mesmo caminho, mas rapidamente percebemos que essas informações não eram suficientes - os avisos sobre solicitações suspensas aparecem atrasados: a solicitação foi interrompida por 30 segundos e só então a vimos. Enquanto se trata de monitoramento, enquanto o monitoramento dispara o alarme, pelo menos três minutos se passam. Na melhor das hipóteses, isso significa que parte do armazenamento e aplicativos ficará inativa por três minutos.
Naturalmente, decidimos expandir o monitoramento e passamos ao elemento principal do Ceph - o daemon OSD. Ao monitorar o daemon de armazenamento de objetos, obtemos o tempo aproximado de operação conforme o OSD o vê, além de estatísticas sobre solicitações suspensas - quem, quando, em que PG e por quanto tempo.
Por que apenas Ceph não é suficiente e o que fazer sobre isso
O Ceph por si só não é suficiente por várias razões. Por exemplo, temos um cliente com um perfil de banco de dados. Ele implantou todos os bancos de dados no cluster all-flash, a latência das operações que foram emitidas no local lhe convinha, no entanto, houve queixas de tempo de inatividade.
O sistema de monitoramento não permite que você veja o que está acontecendo dentro dos clientes do ambiente virtual. Como resultado, para identificar o problema, usamos a análise avançada, que foi solicitada usando o utilitário blktrace de sua máquina virtual.
 O resultado de uma análise estendida.
O resultado de uma análise estendida.Os resultados da análise contêm operações marcadas com os sinalizadores W e WS. O sinalizador W é um registro, o sinalizador WS é um registro síncrono, aguardando o dispositivo concluir a operação. Quando trabalhamos com bancos de dados, quase todos os bancos de dados SQL têm um gargalo - WAL (log write-ahead).
O banco de dados sempre grava primeiro os dados no log, recebe a confirmação do disco com buffers de liberação e, em seguida, grava os dados no próprio banco de dados. Se ela não recebeu a confirmação de uma redefinição de buffer, ela acredita que uma redefinição de energia pode apagar uma transação confirmada pelo cliente. Isso é inaceitável para o banco de dados, por isso ele exibe "write SYNC / FLUSH" e depois grava os dados. Quando os logs estão cheios, ocorre a troca e tudo o que entra no cache da página também é piscado à força.
Adicionado: não há redefinição na própria imagem - ou seja, operações com o sinalizador de pré-descarga. Eles se parecem com o FWS - pré-liberação + gravação + sincronização ou FWSF - pré-liberação + gravação + sincronização + FUAQuando um cliente tem muitas transações pequenas, praticamente todas as suas E / S se transformam em uma cadeia seqüencial: write-flush - write-flush. Como você não pode fazer algo com o banco de dados, começamos a trabalhar com o sistema de armazenamento. Neste momento, entendemos que os recursos do Ceph não são suficientes.
Para nós, nesse estágio, a melhor solução era adicionar repositórios locais pequenos e rápidos que não foram implementados usando as ferramentas Ceph (basicamente esgotamos seus recursos). E transformamos o armazenamento em nuvem em algo mais que o Ceph. No nosso caso, adicionamos muitas histórias locais (local em termos do data center, não o hipervisor).
 Repositórios localizados adicionais Destino A e B.
Repositórios localizados adicionais Destino A e B.O tempo de serviço desse armazenamento local é de cerca de 0,3 ms por fluxo. Se estiver em outro datacenter, funcionará mais lentamente - com um desempenho de aproximadamente 0,7 ms. Esse é um aumento significativo em comparação com o Ceph, que produz 1,2 ms e distribuído pelos data centers - 2 ms. O desempenho dessas pequenas fábricas, das quais temos mais de uma dúzia, é de cerca de 100 mil por módulo, 100 mil IOPS por registro.
Após essa alteração na infraestrutura, nossa nuvem reduz menos de um milhão de IOPS para gravação ou cerca de dois a três milhões de IOPS para leitura no total de todos os clientes:

É importante observar que esse tipo de armazenamento não é o principal método de expansão, fazemos a aposta principal no Ceph e a presença de armazenamento rápido é importante apenas para serviços que exigem tempo de resposta do disco.
Novas iterações: aprimoramentos de código e infraestrutura
Todas as nossas histórias são recursos compartilhados. Essa infraestrutura exige que
implementemos uma política de nível de serviço : devemos fornecer um certo nível de serviço e não permitir que um cliente interfira no outro por acidente ou de propósito, desativando o armazenamento.
Para fazer isso, tivemos que fazer a finalização e a implantação não trivial - entrega iterativa ao produtivo.
Esse lançamento foi diferente das práticas usuais do DevOps, quando todos os processos: montagem, teste, lançamento de código, serviço de reinicialização, se necessário, começam com um clique de um botão e tudo funciona. Se você implementar práticas de DevOps na infraestrutura, ela permanecerá até o primeiro erro.
É por isso que a “automação total” não se enraizou particularmente na equipe de infraestrutura. Obviamente, existe uma certa abordagem para automação de testes e entrega - mas ela é sempre controlada e a entrega é iniciada pelos engenheiros de SRE da equipe em nuvem.
Implementamos alterações em vários serviços: no back-end do Cinder, no front-end do Cinder (cliente do Cinder) e no serviço Nova. As alterações foram aplicadas em várias iterações - uma iteração por vez. Após a terceira iteração, as alterações correspondentes foram aplicadas às máquinas convidadas dos clientes: alguém migrou, alguém reiniciou a VM (reinicialização forçada) ou migração planejada para atender os hipervisores.
O próximo problema que surgiu é o
salto na velocidade de gravação . Quando trabalhamos com armazenamento conectado à rede, o hipervisor padrão considera a rede lenta e, portanto, armazena em cache todos os dados. Ele escreve rapidamente, até várias dezenas de megabytes, e depois começa a liberar o cache. Houve muitos momentos desagradáveis por causa de tais saltos.
Descobrimos que se você ativar o cache, o desempenho do SSD diminui em 15% e se você desativar o cache, o desempenho do HDD diminui em 35%. Foi preciso outro desenvolvimento, implementado o gerenciamento de cache gerenciado, quando o armazenamento em cache é explicitamente designado para cada tipo de disco. Isso nos permitiu dirigir SSD sem cache e HDD - com um cache, como resultado, paramos de perder desempenho.
A prática de entregar desenvolvimento a um produtivo é semelhante - iterações. Implementamos o código, reiniciamos o daemon e, conforme necessário, reinicie ou migre máquinas virtuais convidadas, que devem estar sujeitas a alterações. A VM do cliente migrou do HDD, seu cache ativado - tudo funciona ou, pelo contrário, o cliente migrou com SSD, seu cache desativado - tudo funciona.
O terceiro problema é a
operação incorreta de máquinas virtuais implantadas das imagens GOLD no HDD .
Existem muitos clientes, e a peculiaridade da situação é que o trabalho da VM foi ajustado por si só: o problema foi garantido durante a implantação, mas foi resolvido enquanto o cliente alcançava o suporte técnico. Inicialmente, pedimos aos clientes que esperassem meia hora até a VM estar estabilizada, mas depois começamos a trabalhar na qualidade do serviço.
No processo de pesquisa, percebemos que os recursos de nossa infraestrutura de monitoramento ainda não são suficientes.
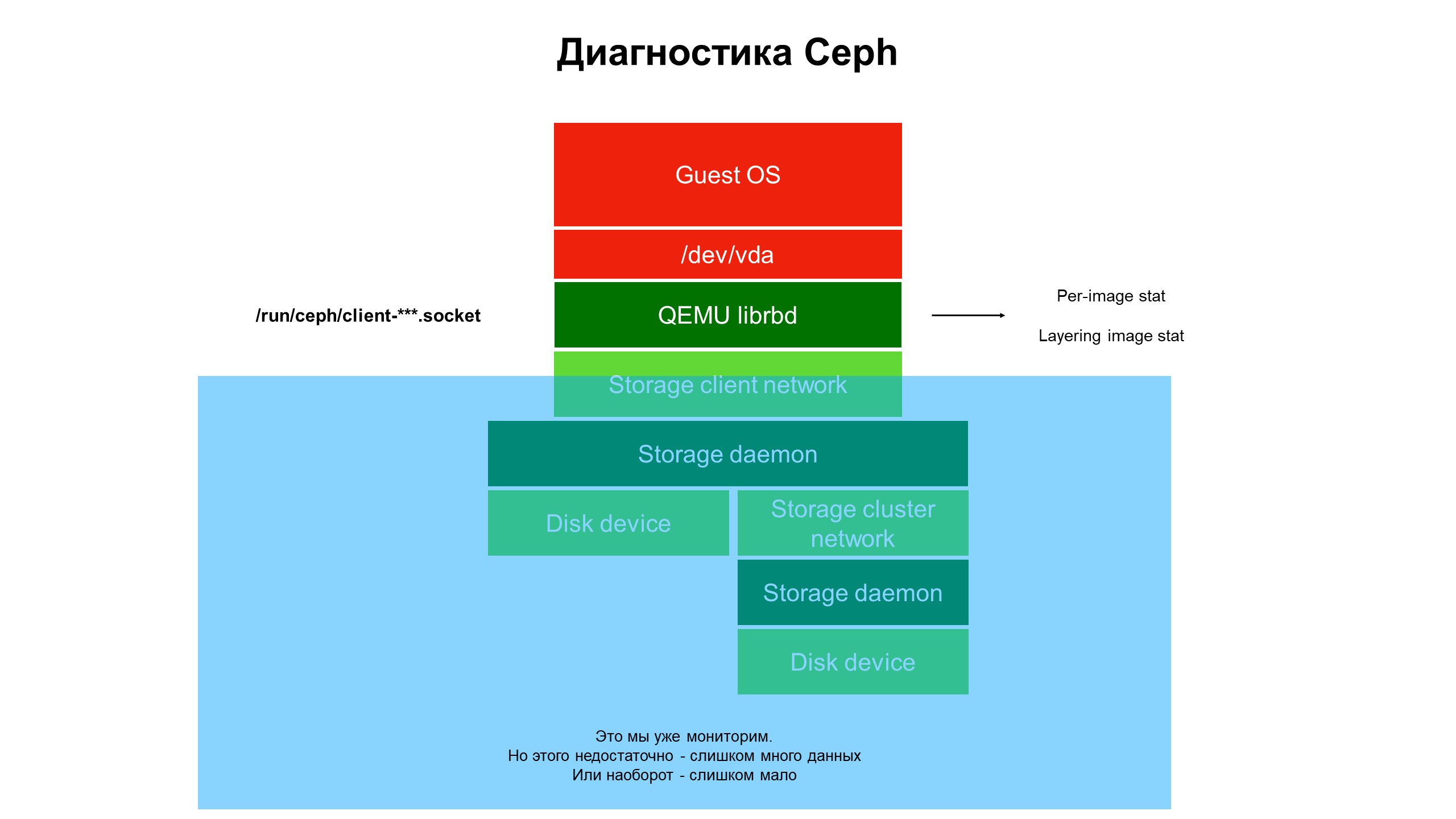 O monitoramento fechou a parte azul e o problema estava no topo da infraestrutura, não coberto pelo monitoramento.
O monitoramento fechou a parte azul e o problema estava no topo da infraestrutura, não coberto pelo monitoramento.Começamos a lidar com o que está acontecendo na parte da infraestrutura que não era coberta pelo monitoramento. Para fazer isso, usamos os diagnósticos avançados do Ceph (ou melhor, uma das variedades do cliente Ceph - librbd). Utilizando ferramentas de automação, fizemos alterações na configuração do cliente Ceph para acessar estruturas de dados internas por meio do soquete do domínio Unix e começamos a coletar estatísticas dos clientes Ceph no hipervisor.
O que vimos? Não vimos estatísticas no cluster Ceph / OSD / cluster, mas estatísticas em cada disco da máquina virtual do cliente cujos discos estavam no Ceph - ou seja, estatísticas associadas ao dispositivo.
 Resultados avançados de estatísticas de monitoramento.
Resultados avançados de estatísticas de monitoramento.Foram as estatísticas expandidas que deixaram claro que o problema ocorre apenas em discos clonados de outros discos.
Em seguida, analisamos as estatísticas das operações, em particular as operações de leitura e gravação. Descobriu-se que a carga nas imagens de nível superior é relativamente pequena e, nas iniciais, de onde o clone provém, é grande, mas sem equilíbrio: uma grande quantidade de leitura sem gravação.
O problema está localizado, agora é necessária uma solução - código ou infraestrutura?
Nada pode ser feito com o código Ceph, é "difícil". Além disso, a segurança dos dados do cliente depende disso. Mas há um problema, ele deve ser resolvido e alteramos a arquitetura do repositório. O cluster do HDD se transformou em um cluster híbrido - uma certa quantidade de SSD foi adicionada ao HDD; as prioridades dos daemons do OSD foram alteradas para que o SSD estivesse sempre em prioridade e se tornasse o OSD principal dentro do grupo de posicionamento (PG).
Agora, quando o cliente implanta a máquina virtual a partir do disco clonado, suas operações de leitura vão para o SSD. Como resultado, a recuperação do disco tornou-se rápida e apenas os dados do cliente, exceto a imagem original, são gravados no disco rígido. Recebemos um aumento de três vezes na produtividade quase gratuitamente (em relação ao custo inicial da infraestrutura).
Por que o monitoramento da infraestrutura é importante
- A infraestrutura de monitoramento deve ser incluída ao máximo em toda a pilha, começando com a máquina virtual e terminando com o disco. Afinal, enquanto um cliente que usa uma nuvem pública ou privada acessa sua infraestrutura e fornece as informações necessárias, o problema muda ou muda para outro local.
- O monitoramento de todo o hipervisor, máquina virtual ou contêiner "em sua totalidade" produz quase nada. Tentamos entender do tráfego de rede o que está acontecendo com o Ceph - é inútil, os dados voam em alta velocidade (de 500 megabytes por segundo), é extremamente difícil selecionar os necessários. É necessário um volume monstruoso de discos para armazenar essas estatísticas e muito tempo para analisá-las.
- , - . : , , — , .
- — . , . — , . , . — , , .
- Cloud MCS Cloud Solutions é uma infraestrutura cujas decisões de evolução são tomadas em grande parte com base nos dados acumulados pelo monitoramento. Melhoramos o monitoramento e usamos seus dados para melhorar o nível de serviço dos clientes.