O problema da busca automática de texto em imagens existe há muito tempo, pelo menos desde o início dos anos noventa do século passado. Eles poderiam ser lembrados pelos veteranos pela ampla distribuição do ABBYY FineReader, que pode traduzir as digitalizações de documentos em suas versões editáveis.
Os scanners conectados a computadores pessoais funcionam muito bem nas empresas, mas o progresso não pára e os dispositivos móveis dominam o mundo. O intervalo de tarefas para trabalhar com texto também mudou. Agora você precisa procurar o texto não em folhas A4 perfeitamente retas com texto em preto sobre fundo branco, mas em vários cartões de visita, menus coloridos, letreiros de lojas e muito mais sobre o que uma pessoa pode encontrar na selva de uma cidade moderna.
 Um exemplo real do trabalho de nossa rede neural. A imagem é clicável.
Um exemplo real do trabalho de nossa rede neural. A imagem é clicável.Requisitos e limitações básicas
Com uma variedade de condições para a apresentação de texto, algoritmos manuscritos não podem mais lidar. Aqui, redes neurais com sua capacidade de generalizar vêm em socorro. Neste post, falaremos sobre nossa abordagem para criar uma arquitetura de rede neural que detecta texto em imagens complexas com boa qualidade e alta velocidade.
Os dispositivos móveis impõem restrições adicionais à escolha da abordagem:
- Os usuários nem sempre têm a oportunidade de usar uma rede móvel para se comunicar com o servidor devido a tráfego de roaming caro ou problemas de privacidade. Portanto, soluções como o Google Lens não ajudarão aqui.
- Como nos concentramos no processamento de dados local, seria bom para a nossa solução:
- Isso levou pouca memória;
- Ele trabalhou rapidamente usando os recursos técnicos do smartphone.
- O texto pode ser girado e ter um fundo aleatório.
- As palavras podem ser muito longas. Nas redes neurais convolucionais, o escopo do kernel de convolução geralmente não cobre toda a palavra estendida; portanto, é necessário algum truque para contornar essa restrição.

- O tamanho do texto em uma foto pode ser diferente:

Solução
A solução mais simples para o problema de pesquisa de texto que vem à mente é
usar a melhor rede das competições do
ICDAR (Conferência Internacional sobre Análise e Reconhecimento de Documentos), especializadas nesta tarefa e negócio! Infelizmente, essas redes alcançam qualidade devido ao seu volume e complexidade computacional e são adequadas apenas como uma solução em nuvem, que não atende aos parágrafos 1 e 2 de nossos requisitos. Mas e se pegarmos uma rede grande que funcione bem nos cenários que precisamos cobrir e tentar reduzi-la? Essa abordagem já é mais interessante.
Baoguang Shi et al. Em sua rede neural, o
SegLink [1] propôs o seguinte:
- Encontrar não palavras inteiras de uma só vez (áreas verdes na imagem a ), mas suas partes, chamadas segmentos, com a previsão de rotação, inclinação e deslocamento. Vamos emprestar essa ideia.
- Você precisa procurar segmentos de palavras em várias escalas ao mesmo tempo para atender ao requisito 5. Os segmentos são mostrados por retângulos verdes na imagem b .
- Para evitar que uma pessoa invente como combinar esses segmentos, simplesmente fazemos a rede neural prever conexões (links) entre segmentos relacionados à mesma palavra
a. dentro da mesma escala (linhas vermelhas na imagem c )
b. e entre escalas (linhas vermelhas na imagem d ), resolvendo o problema da cláusula 4 dos requisitos.
Os quadrados azuis na imagem abaixo mostram as áreas de visibilidade dos pixels das camadas de saída da rede neural de diferentes escalas, que "veem" pelo menos parte da palavra.
 Exemplos de segmentos e links
Exemplos de segmentos e linksO SegLink usa a conhecida arquitetura VGG-16 como base. A previsão de segmentos e links nele é realizada em 6 escalas. Como o primeiro experimento, começamos com a implementação da arquitetura original. Aconteceu que a rede contém 23 milhões de parâmetros (pesos) que precisam ser armazenados em um arquivo de 88 megabytes de tamanho. Se você criar um aplicativo baseado no VGG, ele será um dos primeiros candidatos a remoção se não houver espaço suficiente e a pesquisa de texto funcionará muito lentamente, portanto a rede precisa perder peso com urgência.
 Arquitetura de rede SegLink
Arquitetura de rede SegLinkO segredo da nossa dieta
Você pode reduzir o tamanho da rede simplesmente alterando o número de camadas e canais, ou alterando a convolução em si e as conexões entre elas. Mark Sandler e associados, a tempo,
adotaram a arquitetura em sua rede
MobileNetV2 [2], para que ela funcione rapidamente em dispositivos móveis,
ocupe pouco espaço e ainda não fique para trás na qualidade do trabalho do mesmo VGG. O segredo para acelerar e reduzir o consumo de memória está em três etapas principais:
- O número de canais com mapas de características na entrada do bloco é reduzido pela convolução do ponto em toda a profundidade (o chamado gargalo) sem uma função de ativação.
- A convolução clássica é substituída por uma convolução separável por canal. Essa convolução requer menos peso e menos computação.
- As cartas de personagem após o gargalo são encaminhadas para a entrada do próximo bloco para soma sem complicação adicional.
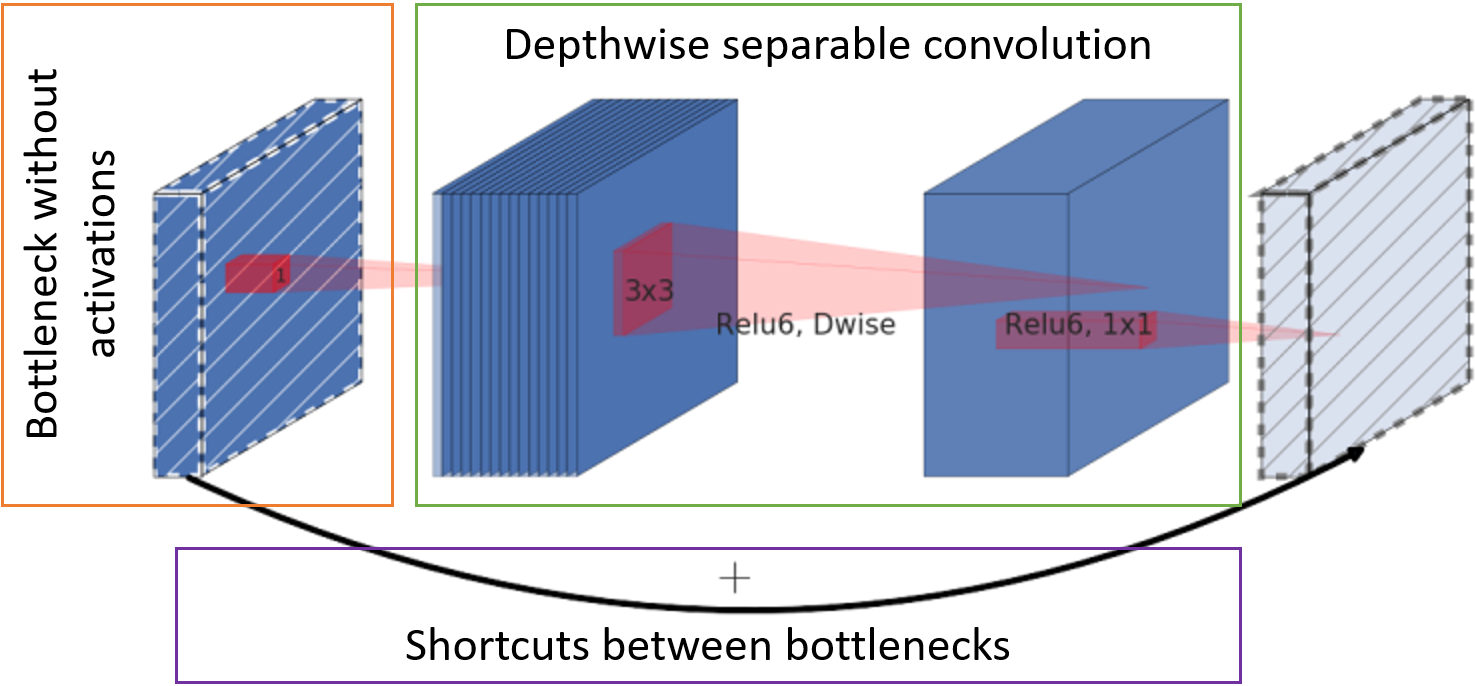 Unidade base MobileNetV2
Unidade base MobileNetV2
Rede neural resultante
Usando as abordagens acima, chegamos à seguinte estrutura de rede:
- Usamos segmentos e links do SegLink
- Substitua o VGG por um MobileNetV2 menos guloso
- Reduza o número de escalas de pesquisa de texto de 6 para 5 para velocidade
 Rede de resumo da pesquisa de texto
Rede de resumo da pesquisa de texto
Descriptografia de valores em blocos de arquitetura de rede
A etapa de passada e o número base de canais nos canais são indicados como s <stride> c <channels>, respectivamente. Por exemplo, s2c32 significa 32 canais com um deslocamento de 2. O número real de canais nas camadas de convolução é obtido multiplicando seu número base por um fator de escala α, que permite simular rapidamente diferentes "espessuras" da rede. Abaixo está uma tabela com o número de parâmetros na rede, dependendo de α.

Tipo de bloco:
- Conv2D - uma operação de convolução completa;
- Conv D-wise - convolução separável por canal;
- Blocos - um grupo de blocos MobileNetV2;
- Saída - convolução para obter a camada de saída. Valores numéricos do tipo NxN indicam o tamanho do campo receptivo do pixel.
Como uma função de ativação, os blocos usam ReLU6.

A camada de saída possui 31 canais:
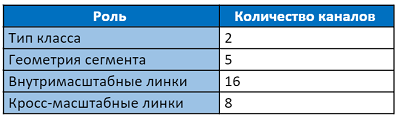
Os dois primeiros canais da camada de saída votam para o pixel pertencer ao texto e não ao texto. Os cinco canais a seguir contêm informações para reconstruir com precisão a geometria do segmento: mudanças verticais e horizontais em relação à posição do pixel, fatores de largura e altura (já que o segmento geralmente não é quadrado) e o ângulo de rotação. 16 valores de links intra-canais indicam se há uma conexão entre oito pixels adjacentes na mesma escala. Os últimos 8 canais nos informam sobre a presença de links para quatro pixels da escala anterior (a escala anterior é sempre 2 vezes maior). A cada 2 valores de segmentos, os links intra e cross-scale são normalizados pela função softmax. O acesso à primeira escala não possui links entre escalas.
Montagem de palavras
A rede prevê se um segmento específico e seus vizinhos pertencem ao texto. Resta coletá-los em palavras.
Para começar, combine todos os segmentos vinculados por links. Para fazer isso, compomos um gráfico em que os vértices são todos os segmentos em todas as escalas e as arestas são links. Então encontramos os componentes conectados do gráfico. Para cada componente, agora é possível calcular o retângulo anexo da palavra da seguinte maneira:
- Calculamos o ângulo de rotação da palavra θ
- Ou como o valor médio das previsões do ângulo de rotação dos segmentos, se houver muitos deles,
- Ou como o ângulo de rotação da linha obtido por regressão nos pontos dos centros dos segmentos, se houver poucos segmentos.
- O centro da palavra é selecionado como o centro de massa dos pontos centrais dos segmentos.
- Expanda todos os segmentos por -θ para organizá-los horizontalmente. Encontre os limites da palavra.
- Os limites esquerdo e direito da palavra são selecionados como os limites dos segmentos mais à esquerda e mais à direita, respectivamente.
- Para obter o limite superior da palavra, os segmentos são classificados pela altura da aresta superior, 20% dos mais altos são cortados e o valor do primeiro segmento da lista restante após a filtragem é selecionado.
- O limite inferior é obtido dos segmentos mais baixos com um ponto de corte de 20% do mais baixo, por analogia com o limite superior.
- Gire o retângulo resultante de volta para θ.
A solução final é chamada
FaSTExt : Extrator de texto rápido e pequeno [3]
Hora da experiência!
Detalhes do treinamento
A própria rede e seus parâmetros foram selecionados para um bom trabalho em uma grande amostra interna, que reflete o cenário principal do uso do aplicativo no telefone - ele apontou a câmera para um objeto com texto e tirou uma foto. Verificou-se que uma grande rede com α = 1 ignora em qualidade a versão com α = 0,5 em apenas 2%. Esta amostra não é de domínio público, portanto, para maior clareza, tive que treinar a rede na amostra pública
ICDAR2013 , na qual as condições de filmagem são semelhantes às nossas. Como a amostra é muito pequena, a rede foi treinada anteriormente em uma enorme quantidade de dados sintéticos do
SynthText no Wild Dataset . O processo de pré-treinamento levou cerca de 20 dias de cálculos para cada experimento no GTX 1080 Ti; portanto, a operação de rede em dados públicos foi verificada apenas pelas opções α = 0,75, 1 e 2.
Como otimizador, foi usada a versão
AMSGrad de Adam.
Funções de erro:
- Entropia cruzada para a classificação de segmentos e links;
- Função de perda de Huber para geometria de segmento.
Resultados
Em termos de qualidade do desempenho da rede no cenário-alvo, podemos dizer que ela não fica muito atrás dos concorrentes em termos de qualidade e supera algumas. A MS é uma rede pesada de concorrentes em várias escalas.
 * No artigo sobre o LESTE, não houve resultados na amostra de que precisávamos, portanto realizamos o experimento.
* No artigo sobre o LESTE, não houve resultados na amostra de que precisávamos, portanto realizamos o experimento.A imagem abaixo mostra um exemplo de como o FaSTExt funciona em imagens do ICDAR2013. A primeira linha mostra que as letras iluminadas da palavra ESPMOTO não foram marcadas, mas a rede conseguiu encontrá-las. A versão menos espaçosa com α = 0,75 lidou com texto pequeno pior que as versões mais "grossas". A linha inferior novamente mostra falhas de marcação na amostra com texto perdido na reflexão. O FaSTExt vê ao mesmo tempo esse texto.

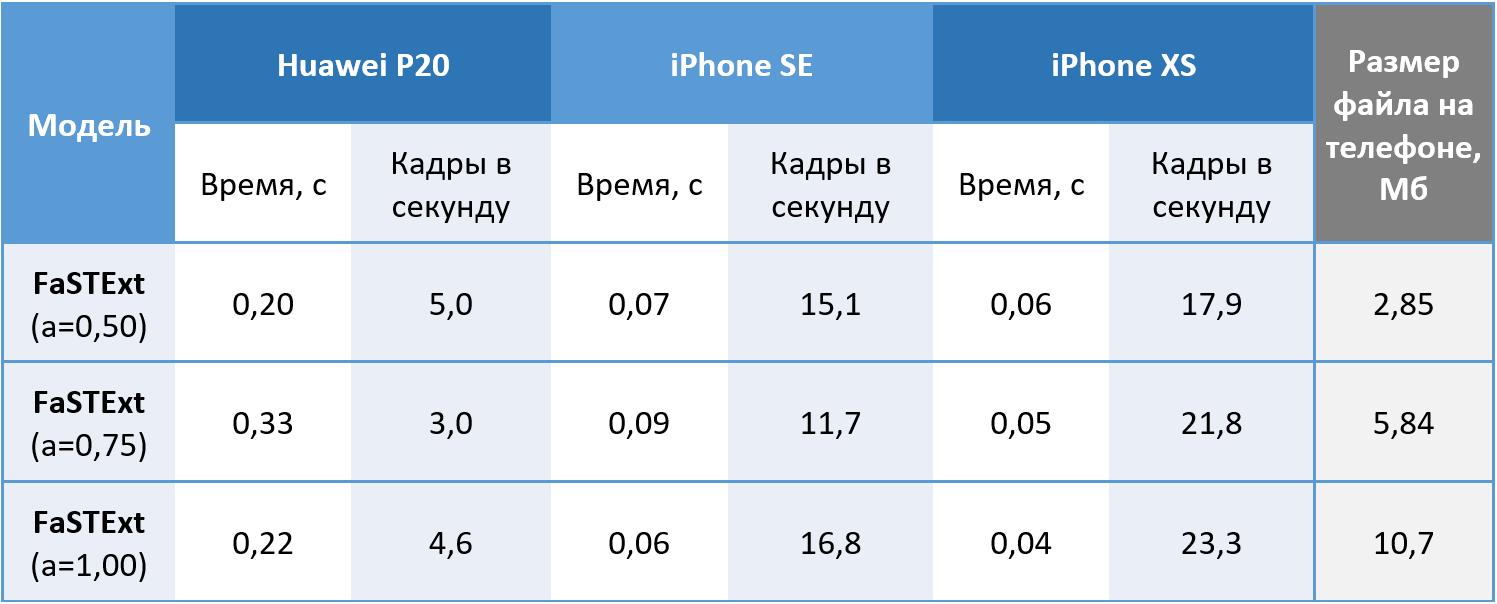
Portanto, a rede executa suas tarefas. Resta verificar se ele realmente pode ser usado em telefones? Os modelos foram lançados em imagens coloridas de 512x512 no Huawei P20 usando a CPU e no iPhone SE e iPhone XS usando a GPU, porque nosso sistema de aprendizado de máquina ainda permite que você use a GPU apenas no iOS. Valores obtidos com média de 100 partidas. No Android, conseguimos atingir uma velocidade de 5 quadros por segundo aceitável para a nossa tarefa. O iPhone XS mostrou um efeito interessante com uma diminuição no tempo médio necessário para os cálculos enquanto complicava a rede. Um iPhone moderno detecta texto com atraso mínimo, o que pode ser chamado de vitória.
Referências
[1] B. Shi, X. Bai e S. Belongie, “Detectando texto orientado em imagens naturais por segmentos
vinculados ”, Havaí, 2017.
link[2] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov e L.-C. Chen, “MobileNetV2: resíduos invertidos e gargalos lineares”, Salt Lake City, 2018.
link[3] A. Filonenko, K. Gudkov, A. Lebedev, N. Orlov e I. Zagaynov, “FaSTExt: Extrator de texto pequeno e rápido”, no 8º Workshop Internacional sobre Análise e Reconhecimento de Documentos Baseados em Câmera, Sydney, 2019
link[4] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu e X. Bai, “Detecção de texto multi-orientada com redes totalmente convolucionais”, Las Vegas, 2016.
link[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. Ele e J. Liang, "ORIENTE: um detector de texto de cena eficiente e preciso", na Conferência IEEE de Computadores de 2017. Visão e Padrão, Honolulu, 2017.
link[6] M. Liao, Z. Zhu, B. Shi, G.-s. Xia e X. Bai, "Regressão sensível à rotação para detecção de texto de cena orientada", na Conferência IEEE / CVF de 2018 sobre visão e padrão de computador, Salt Lake City, 2018.
link[7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao e J. Yan, “Fots: localização rápida de texto orientado com uma rede unificada”, na Conferência IEEE / CVF de 2018 em Visão Computacional e Padrão, Salt Lake City, 2018.
linkGrupo de visão computacional