Alexey Lizunov, chefe do centro de competência dos canais de serviço remoto da Diretoria de Tecnologias da Informação do CID
Como alternativa à pilha ELK (ElasticSearch, Logstash, Kibana), estamos realizando pesquisas sobre o uso do banco de dados ClickHouse como um armazém de dados para logs.
Neste artigo, gostaríamos de falar sobre nossa experiência no uso do banco de dados ClickHouse e sobre resultados preliminares da operação piloto. Deve-se notar imediatamente que os resultados foram impressionantes.
A seguir, descreveremos com mais detalhes como nosso sistema está configurado e em quais componentes ele consiste. Mas agora eu gostaria de falar um pouco sobre esse banco de dados como um todo e por que você deve prestar atenção nele. O banco de dados ClickHouse é um banco de dados de coluna analítica de alto desempenho da Yandex. É usado nos serviços Yandex, inicialmente é o principal data warehouse para o Yandex.Metrica. O sistema de código aberto é gratuito. Do ponto de vista do desenvolvedor, eu sempre me interessei em como eles o implementaram, porque há dados incrivelmente grandes. E a própria interface de usuário métrica é muito flexível e rápida. No primeiro contato com este banco de dados, a impressão: “Bem, finalmente! Feito "para pessoas"! Começando pelo processo de instalação e terminando com o envio de solicitações. "
Este banco de dados tem um limite de entrada muito baixo. Mesmo um desenvolvedor qualificado médio pode instalar esse banco de dados em alguns minutos e começar a usá-lo. Tudo funciona claramente. Mesmo as pessoas novas no Linux podem passar rapidamente pela instalação e executar operações simples. Anteriormente, quando a palavra Big Data, Hadoop, Google BigTable, HDFS, o desenvolvedor habitual teve a ideia de que eles estavam falando sobre alguns terabytes, petabytes, que alguns super-humanos estavam envolvidos nas configurações e no desenvolvimento desses sistemas, depois com o advento do banco de dados ClickHouse que obtivemos Uma ferramenta simples e compreensível com a qual você pode resolver a gama de tarefas anteriormente inatingível. Apenas um carro razoavelmente médio e cinco minutos para instalar. Ou seja, temos um banco de dados como, por exemplo, MySql, mas apenas para armazenar bilhões de registros! Algum tipo de supervisor SQL. É como se as pessoas recebessem armas de alienígenas.
Sobre o nosso sistema de coleta de logs
Para coletar informações, são usados arquivos de log do IIS de aplicativos da Web de um formato padrão (também estamos envolvidos na análise de logs de aplicativos, mas o principal objetivo no estágio de operação piloto conosco é coletar logs do IIS).
Por várias razões, falhamos em abandonar completamente a pilha ELK e continuamos a usar os componentes LogStash e Filebeat, que se mostraram bem e funcionam de maneira confiável e previsível.
O esquema geral de registro é apresentado na figura abaixo:
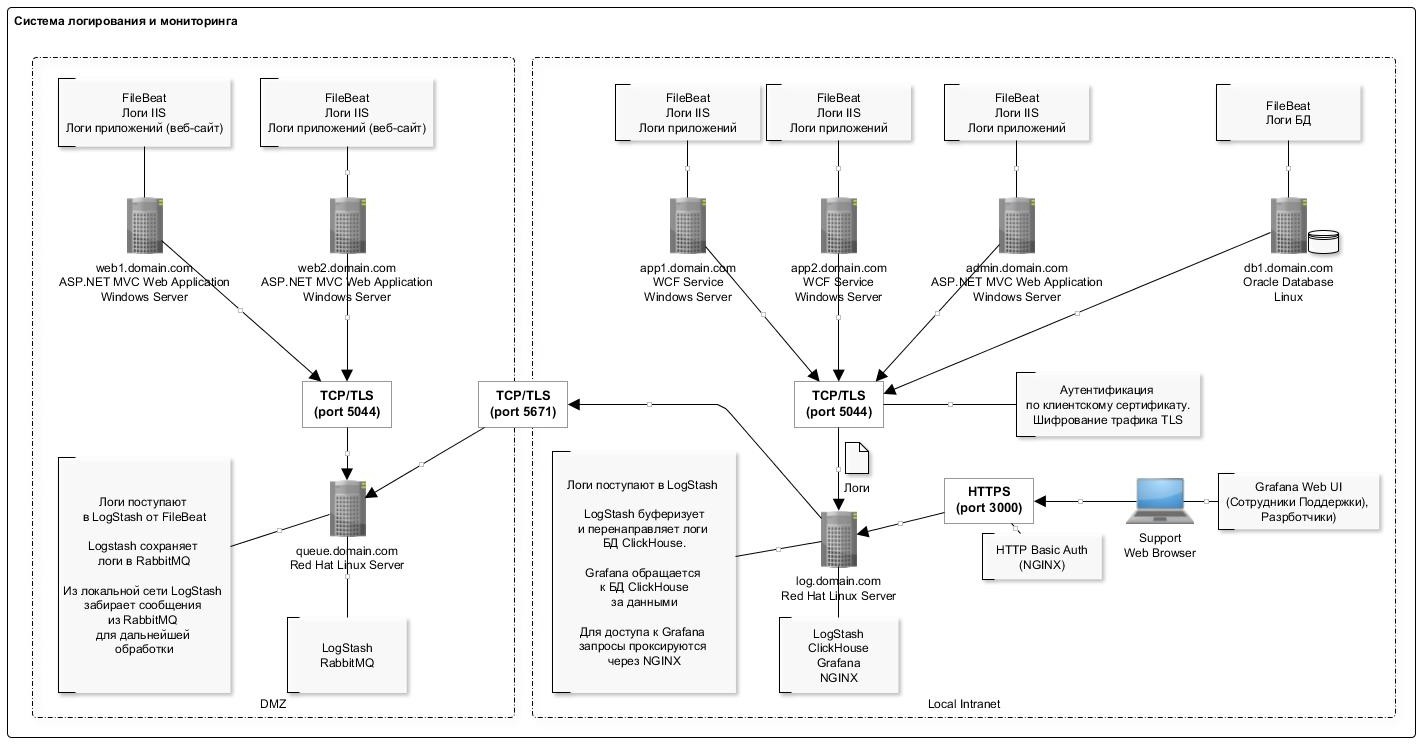
Um recurso de gravação de dados no banco de dados ClickHouse é a inserção pouco frequente (uma vez por segundo) de registros em lotes grandes. Aparentemente, essa é a parte mais "problemática" que você encontra quando experimenta trabalhar com o banco de dados ClickHouse: o esquema é um pouco complicado.
O plug-in LogStash ajudou muito aqui, que insere dados diretamente no ClickHouse. Este componente é implantado no mesmo servidor que o próprio banco de dados. Portanto, de um modo geral, não é recomendável fazê-lo, mas de um ponto de vista prático, para não produzir servidores separados enquanto estiver implantado no mesmo servidor. Não observamos nenhuma falha ou conflito de recursos com o banco de dados. Além disso, deve-se notar que o plug-in possui um mecanismo de recuperação em caso de erros. E, no caso de erros, o plug-in grava no disco um pacote de dados que não pôde ser inserido (o formato do arquivo é conveniente: após a edição, você pode inserir facilmente o pacote corrigido usando o clickhouse-client).
A lista completa de softwares usados no esquema é apresentada na tabela:
A configuração do servidor com o banco de dados ClickHouse é apresentada na tabela a seguir:
Como você pode ver, esta é uma estação de trabalho regular.
A estrutura da tabela para armazenar logs é a seguinte:
log_web.sqlCREATE TABLE log_web ( logdate Date, logdatetime DateTime CODEC(Delta, LZ4HC), fld_log_file_name LowCardinality( String ), fld_server_name LowCardinality( String ), fld_app_name LowCardinality( String ), fld_app_module LowCardinality( String ), fld_website_name LowCardinality( String ), serverIP LowCardinality( String ), method LowCardinality( String ), uriStem String, uriQuery String, port UInt32, username LowCardinality( String ), clientIP String, clientRealIP String, userAgent String, referer String, response String, subresponse String, win32response String, timetaken UInt64 , uriQuery__utm_medium String , uriQuery__utm_source String , uriQuery__utm_campaign String , uriQuery__utm_term String , uriQuery__utm_content String , uriQuery__yclid String , uriQuery__region String ) Engine = MergeTree() PARTITION BY toYYYYMM(logdate) ORDER BY (fld_app_name, fld_app_module, logdatetime) SETTINGS index_granularity = 8192;
Usamos valores padrão para particionamento (por meses) e granularidade do índice. Todos os campos correspondem praticamente às entradas de log do IIS para registrar solicitações http. Separadamente, campos separados para armazenar tags utm (eles são analisados no estágio de inserção na tabela a partir do campo string de consulta).
Também na tabela são adicionados vários campos do sistema para armazenar informações sobre sistemas, componentes, servidores. Veja a tabela abaixo para obter uma descrição desses campos. Em uma tabela, armazenamos logs para vários sistemas.
Isso permite que você crie efetivamente gráficos no Grafana. Por exemplo, visualize solicitações do front-end de um sistema específico. Isso é semelhante ao contador do site no Yandex.Metrica.
Aqui estão algumas estatísticas sobre o uso do banco de dados por dois meses.
Número de registros por sistema e componente SELECT fld_app_name, fld_app_module, count(fld_app_name) AS rows_count FROM log_web GROUP BY fld_app_name, fld_app_module WITH TOTALS ORDER BY fld_app_name ASC, rows_count DESC ┌─fld_app_name─────┬─fld_app_module─┬─rows_count─┐ │ site1.domain.ru │ web │ 131441 │ │ site2.domain.ru │ web │ 1751081 │ │ site3.domain.ru │ web │ 106887543 │ │ site3.domain.ru │ svc │ 44908603 │ │ site3.domain.ru │ intgr │ 9813911 │ │ site4.domain.ru │ web │ 772095 │ │ site5.domain.ru │ web │ 17037221 │ │ site5.domain.ru │ intgr │ 838559 │ │ site5.domain.ru │ bo │ 7404 │ │ site6.domain.ru │ web │ 595877 │ │ site7.domain.ru │ web │ 27778858 │ └──────────────────┴────────────────┴────────────┘ Totals: ┌─fld_app_name─┬─fld_app_module─┬─rows_count─┐ │ │ │ 210522593 │ └──────────────┴────────────────┴────────────┘ 11 rows in set. Elapsed: 4.874 sec. Processed 210.52 million rows, 421.67 MB (43.19 million rows/s., 86.51 MB/s.)
A quantidade de dados no disco SELECT formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed, formatReadableSize(sum(data_compressed_bytes)) AS compressed, sum(rows) AS total_rows FROM system.parts WHERE table = 'log_web' ┌─uncompressed─┬─compressed─┬─total_rows─┐ │ 54.50 GiB │ 4.86 GiB │ 211427094 │ └──────────────┴────────────┴────────────┘ 1 rows in set. Elapsed: 0.035 sec.
O grau de compactação de dados em colunas SELECT name, formatReadableSize(data_uncompressed_bytes) AS uncompressed, formatReadableSize(data_compressed_bytes) AS compressed, data_uncompressed_bytes / data_compressed_bytes AS compress_ratio FROM system.columns WHERE table = 'log_web' ┌─name───────────────────┬─uncompressed─┬─compressed─┬─────compress_ratio─┐ │ logdate │ 401.53 MiB │ 1.80 MiB │ 223.16665968777315 │ │ logdatetime │ 803.06 MiB │ 35.91 MiB │ 22.363966401202305 │ │ fld_log_file_name │ 220.66 MiB │ 2.60 MiB │ 84.99905736932571 │ │ fld_server_name │ 201.54 MiB │ 50.63 MiB │ 3.980924816977078 │ │ fld_app_name │ 201.17 MiB │ 969.17 KiB │ 212.55518183686877 │ │ fld_app_module │ 201.17 MiB │ 968.60 KiB │ 212.67805817411906 │ │ fld_website_name │ 201.54 MiB │ 1.24 MiB │ 162.7204926761546 │ │ serverIP │ 201.54 MiB │ 50.25 MiB │ 4.010824061219731 │ │ method │ 201.53 MiB │ 43.64 MiB │ 4.617721053304486 │ │ uriStem │ 5.13 GiB │ 832.51 MiB │ 6.311522291936919 │ │ uriQuery │ 2.58 GiB │ 501.06 MiB │ 5.269731450124478 │ │ port │ 803.06 MiB │ 3.98 MiB │ 201.91673864241824 │ │ username │ 318.08 MiB │ 26.93 MiB │ 11.812513794583598 │ │ clientIP │ 2.35 GiB │ 82.59 MiB │ 29.132328640073343 │ │ clientRealIP │ 2.49 GiB │ 465.05 MiB │ 5.478382297052563 │ │ userAgent │ 18.34 GiB │ 764.08 MiB │ 24.57905114484208 │ │ referer │ 14.71 GiB │ 1.37 GiB │ 10.736792723669906 │ │ response │ 803.06 MiB │ 83.81 MiB │ 9.582334090987247 │ │ subresponse │ 399.87 MiB │ 1.83 MiB │ 218.4831068635027 │ │ win32response │ 407.86 MiB │ 7.41 MiB │ 55.050315514606815 │ │ timetaken │ 1.57 GiB │ 402.06 MiB │ 3.9947395692010637 │ │ uriQuery__utm_medium │ 208.17 MiB │ 12.29 MiB │ 16.936148912472955 │ │ uriQuery__utm_source │ 215.18 MiB │ 13.00 MiB │ 16.548367623199912 │ │ uriQuery__utm_campaign │ 381.46 MiB │ 37.94 MiB │ 10.055156353418509 │ │ uriQuery__utm_term │ 231.82 MiB │ 10.78 MiB │ 21.502540454070672 │ │ uriQuery__utm_content │ 441.34 MiB │ 87.60 MiB │ 5.038260760449327 │ │ uriQuery__yclid │ 216.88 MiB │ 16.58 MiB │ 13.07721335008116 │ │ uriQuery__region │ 204.35 MiB │ 9.49 MiB │ 21.52661903446796 │ └────────────────────────┴──────────────┴────────────┴────────────────────┘ 28 rows in set. Elapsed: 0.005 sec.
Descrição dos componentes utilizados
FileBeat. Transferência de log de arquivo
Este componente monitora alterações nos arquivos de log no disco e transfere informações para o LogStash. É instalado em todos os servidores em que os arquivos de log são gravados (geralmente IIS). Funciona no modo de cauda (ou seja, transfere apenas registros adicionados a um arquivo). Mas separadamente, você pode configurar toda a transferência de arquivos. Isso é útil quando você precisa baixar dados de meses anteriores. Basta colocar o arquivo de log em uma pasta e ele o lerá na íntegra.
Quando o serviço para, os dados deixam de ser transferidos para o armazenamento.
Um exemplo de configuração é o seguinte:
filebeat.yml filebeat.inputs: - type: log enabled: true paths: - C:/inetpub/logs/LogFiles/W3SVC1
LogStash Coletor de logs
Este componente destina-se a receber entradas de log do FileBeat (ou através da fila RabbitMQ), analisando e inserindo pacotes configuráveis no banco de dados ClickHouse.
Para inserir no ClickHouse, o plug-in Logstash-output-clickhouse é usado. O plug-in Logstash possui um mecanismo para recuperar solicitações, mas com um desligamento regular, é melhor parar o serviço em si. Quando você para, as mensagens se acumulam na fila do RabbitMQ; portanto, se você parar por um longo período, é melhor parar as batidas de arquivo nos servidores. Em um esquema em que o RabbitMQ não é usado (em uma rede local, o Filebeat envia logs diretamente para o Logstash), os Filebeats funcionam de forma razoável e segura, portanto, para eles, a inacessibilidade da saída não tem consequências.
Um exemplo de configuração é o seguinte:
log_web__filebeat_clickhouse.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/logstash/certs/ca.cer", "/etc/logstash/certs/ca-issuing.cer"] ssl_certificate => "/etc/logstash/certs/server.cer" ssl_key => "/etc/logstash/certs/server-pkcs8.key" ssl_verify_mode => "peer" add_field => { "fld_server_name" => "%{[fields][fld_server_name]}" "fld_app_name" => "%{[fields][fld_app_name]}" "fld_app_module" => "%{[fields][fld_app_module]}" "fld_website_name" => "%{[fields][fld_website_name]}" "fld_log_file_name" => "%{source}" "fld_logformat" => "%{[fields][fld_logformat]}" } } rabbitmq { host => "queue.domain.com" port => 5671 user => "q-reader" password => "password" queue => "web_log" heartbeat => 30 durable => true ssl => true
ClickHouse. Armazenamento de log
Os logs de todos os sistemas são salvos em uma tabela (consulte o início do artigo). Destina-se a armazenar informações sobre solicitações: todos os parâmetros são semelhantes para diferentes formatos, por exemplo, logs do IIS, logs do apache e nginx. Para logs de aplicativos nos quais, por exemplo, erros, mensagens informativas e avisos são registrados, uma tabela separada será fornecida com a estrutura correspondente (agora no estágio de design).
Ao projetar uma tabela, é muito importante determinar a chave primária (pela qual os dados serão classificados durante o armazenamento). O grau de compactação de dados e a velocidade da consulta dependem disso. No nosso exemplo, a chave é
ORDER BY (fld_app_name, fld_app_module, logdatetime)
Ou seja, pelo nome do sistema, o nome do componente do sistema e a data do evento. A data original do evento estava em primeiro lugar. Depois de movê-lo para o último local, as consultas começaram a funcionar duas vezes mais rápido. Alterar a chave primária exigirá recriar a tabela e recarregar os dados para que o ClickHouse reorganize os dados no disco. Como é uma operação difícil, é aconselhável pensar com antecedência o que deve ser incluído na chave de classificação.
Também deve ser observado que, nas versões recentes, o tipo de dados LowCardinality apareceu. Ao usá-lo, o tamanho dos dados compactados é bastante reduzido para os campos com baixa cardinalidade (poucas opções).
Agora a versão 19.6 é usada e planejamos tentar atualizar a versão para a mais recente. Eles incluíam recursos maravilhosos como granularidade adaptativa, índices de ignição e o codec DoubleDelta, por exemplo.
Por padrão, durante a instalação, o nível do log de configuração é definido para rastrear. Os logs são rotacionados e arquivados, mas expandem para um gigabyte. Se não houver necessidade, você poderá definir o nível de aviso e o tamanho do log diminuirá acentuadamente. As configurações de log são definidas no arquivo config.xml:
<level>warning</level>
Alguns comandos úteis Debian, Linux Altinity. : https://www.altinity.com/blog/2017/12/18/logstash-with-clickhouse sudo yum search clickhouse-server sudo yum install clickhouse-server.noarch 1. sudo systemctl status clickhouse-server 2. sudo systemctl stop clickhouse-server 3. sudo systemctl start clickhouse-server ( ";") clickhouse-client
LogStash Roteador de log FileBeat para a fila RabbitMQ
Este componente é usado para rotear logs provenientes do FileBeat para a fila RabbitMQ. Existem dois pontos:
- Infelizmente, o FileBeat não possui um plug-in de saída para gravar diretamente no RabbitMQ. E essa funcionalidade, a julgar pelo ish no github, não está planejada para implementação. Existe um plugin para o Kafka, mas por algum motivo não podemos usá-lo em casa.
- Existem requisitos para coletar logs na DMZ. Com base neles, os logs devem primeiro ser adicionados à fila e, em seguida, o LogStash de fora lê as entradas da fila.
Portanto, é precisamente no caso da localização do servidor na DMZ que você precisa usar um esquema um pouco complicado. Um exemplo de configuração é o seguinte:
iis_w3c_logs__filebeat_rabbitmq.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/pki/tls/certs/app/ca.pem", "/etc/pki/tls/certs/app/ca-issuing.pem"] ssl_certificate => "/etc/pki/tls/certs/app/queue.domain.com.cer" ssl_key => "/etc/pki/tls/certs/app/queue.domain.com-pkcs8.key" ssl_verify_mode => "peer" } } output {
RabbitMQ. Fila de mensagens
Este componente é usado para armazenar em buffer as entradas de log na DMZ. A gravação é feita através de um monte de Filebeat → LogStash. A leitura é feita de fora da DMZ via LogStash. Ao operar através do RabboitMQ, cerca de 4 mil mensagens são processadas por segundo.
O roteamento de mensagens é configurado de acordo com o nome do sistema, ou seja, com base nos dados de configuração do FileBeat. Todas as mensagens caem em uma fila. Se, por qualquer motivo, o serviço de fila for parado, isso não levará à perda de mensagens: o FileBeats receberá erros de conexão e suspenderá o envio temporário. E o LogStash, que lê da fila, também receberá erros de rede e aguardará a retomada da conexão. Os dados, é claro, não serão mais gravados no banco de dados.
As seguintes instruções são usadas para criar e configurar filas:
sudo /usr/local/bin/rabbitmqadmin/rabbitmqadmin declare exchange
Grafana Dashboards
Este componente é usado para visualizar os dados de monitoramento. Nesse caso, você deve instalar a fonte de dados ClickHouse para o plugin Grafana 4.6+. Tivemos que ajustá-lo um pouco para aumentar a eficiência do processamento de filtros SQL em um painel.
Por exemplo, usamos variáveis e, se não estiverem configuradas no campo de filtro, gostaríamos que ela não gerasse uma condição no formulário WHERE (uriStem = `` AND uriStem! = ''). Nesse caso, o ClickHouse lerá a coluna uriStem. Em geral, tentamos opções diferentes e, eventualmente, corrigimos o plugin (macro $ valueIfEmpty) para que, no caso de um valor vazio, retornasse 1, sem mencionar a própria coluna.
E agora você pode usar esta consulta para o gráfico
$columns(response, count(*) c) from $table where $adhoc and $valueIfEmpty($fld_app_name, 1, fld_app_name = '$fld_app_name') and $valueIfEmpty($fld_app_module, 1, fld_app_module = '$fld_app_module') and $valueIfEmpty($fld_server_name, 1, fld_server_name = '$fld_server_name') and $valueIfEmpty($uriStem, 1, uriStem like '%$uriStem%') and $valueIfEmpty($clientRealIP, 1, clientRealIP = '$clientRealIP')
que é convertido para esse SQL (observe que os campos vazios do uriStem foram convertidos para apenas 1)
SELECT t, groupArray((response, c)) AS groupArr FROM ( SELECT (intDiv(toUInt32(logdatetime), 60) * 60) * 1000 AS t, response, count(*) AS c FROM default.log_web WHERE (logdate >= toDate(1565061982)) AND (logdatetime >= toDateTime(1565061982)) AND 1 AND (fld_app_name = 'site1.domain.ru') AND (fld_app_module = 'web') AND 1 AND 1 AND 1 GROUP BY t, response ORDER BY t ASC, response ASC ) GROUP BY t ORDER BY t ASC
Conclusão
A aparência do banco de dados ClickHouse se tornou um evento marcante no mercado. Era difícil imaginar que, de graça, em um instante, estávamos armados com uma ferramenta poderosa e prática para trabalhar com big data. Obviamente, com as necessidades crescentes (por exemplo, compartilhamento e replicação em vários servidores), o esquema se tornará mais complexo. Mas, nas primeiras impressões, trabalhar com esse banco de dados é muito bom. Pode-se ver que o produto é feito "para pessoas".
Comparado ao ElasticSearch, o custo de armazenamento e processamento de logs, de acordo com estimativas preliminares, é reduzido de cinco para dez vezes. Em outras palavras, se para a quantidade atual de dados precisarmos configurar um cluster de várias máquinas, ao usar o ClickHouse, precisaremos apenas de uma máquina de baixa energia. Sim, é claro, o ElasticSearch também possui mecanismos para compactar dados no disco e outros recursos que podem reduzir significativamente o consumo de recursos, mas, comparado ao ClickHouse, isso será caro.
Sem otimizações especiais, nas configurações padrão, o carregamento e a recuperação de dados do banco de dados funcionam a uma velocidade incrível. Até o momento, temos poucos dados (cerca de 200 milhões de registros), mas o servidor em si é fraco. No futuro, podemos usar essa ferramenta para outros fins não relacionados ao armazenamento de logs. Por exemplo, para análise de ponta a ponta, no campo da segurança, aprendizado de máquina.
No final, um pouco sobre os prós e contras.
Contras
- Download de registros em pacotes grandes. Por um lado, esse é um recurso, mas você ainda precisa usar componentes adicionais para armazenar registros em buffer. Essa tarefa nem sempre é simples, mas ainda pode ser solucionada. E eu gostaria de simplificar o esquema.
- Algumas funcionalidades exóticas ou novos recursos geralmente quebram em novas versões. Isso gera preocupações, reduzindo o desejo de atualizar para uma nova versão. Por exemplo, o mecanismo de tabela Kafka é um recurso muito útil que permite a leitura direta de eventos do Kafka, sem a implementação de consumidores. Mas, a julgar pelo número de problemas no github, ainda temos o cuidado de usar esse mecanismo na produção. No entanto, se você não fizer movimentos bruscos para o lado e usar a funcionalidade básica, ele funcionará de forma estável.
Prós
- Não diminui a velocidade.
- Baixo limiar de entrada.
- Código aberto
- É grátis
- Escala bem (fragmentação / replicação pronta para uso)
- Está incluído no registro do software russo recomendado pelo Ministério das Comunicações.
- A presença de apoio oficial da Yandex.