Conferência Habr - a história não é estréia. Costumávamos realizar eventos bastante grandes, Torradeira para 300 a 400 pessoas, mas agora decidimos que pequenas reuniões temáticas serão relevantes, cuja direção você também pode definir - por exemplo, nos comentários. A primeira conferência deste formato foi realizada em julho e foi dedicada ao desenvolvimento de back-end. Os participantes ouviram relatórios sobre os recursos da transição do back-end para o ML e sobre o design do serviço Quadrupel no portal de Serviços do Estado e também participaram de uma mesa redonda dedicada ao Serverless. Para aqueles que não puderam participar do evento pessoalmente, neste post dizemos o mais interessante.

Do desenvolvimento de back-end ao aprendizado de máquina
O que os engenheiros de dados de ML fazem? Quais são as semelhanças e diferenças entre as tarefas do desenvolvedor de back-end e do engenheiro de ML? Que caminho você precisa seguir para mudar a primeira profissão para a segunda? Isso foi dito por Alexander Parinov, que entrou no aprendizado de máquina após 10 anos de back-end.
 Alexander Parinov
Alexander ParinovHoje, Alexander trabalha como arquiteto de sistemas de visão computacional no X5 Retail Group e contribui para projetos de código aberto relacionados à visão computacional e aprendizado profundo (github.com/creafz). Suas habilidades são confirmadas por sua participação no top 100 do ranking mundial Kaggle Master (kaggle.com/creafz) - a plataforma mais popular que hospeda competições de aprendizado de máquina.
Por que mudar para o aprendizado de máquina
Há um ano e meio, Jeff Dean, chefe do Google Brain, estudo aprofundado do projeto de pesquisa em inteligência artificial do Google, descreveu como meio milhão de linhas de código no Google Translate foram substituídas por uma rede neural com o Tensor Flow, que consiste em apenas 500 linhas. Após o treinamento da rede, a qualidade dos dados aumentou e a infraestrutura foi simplificada. Parece que este é o nosso futuro brilhante: não precisamos mais escrever código, apenas criar neurônios e jogá-los com dados. Mas, na prática, tudo é muito mais complicado.
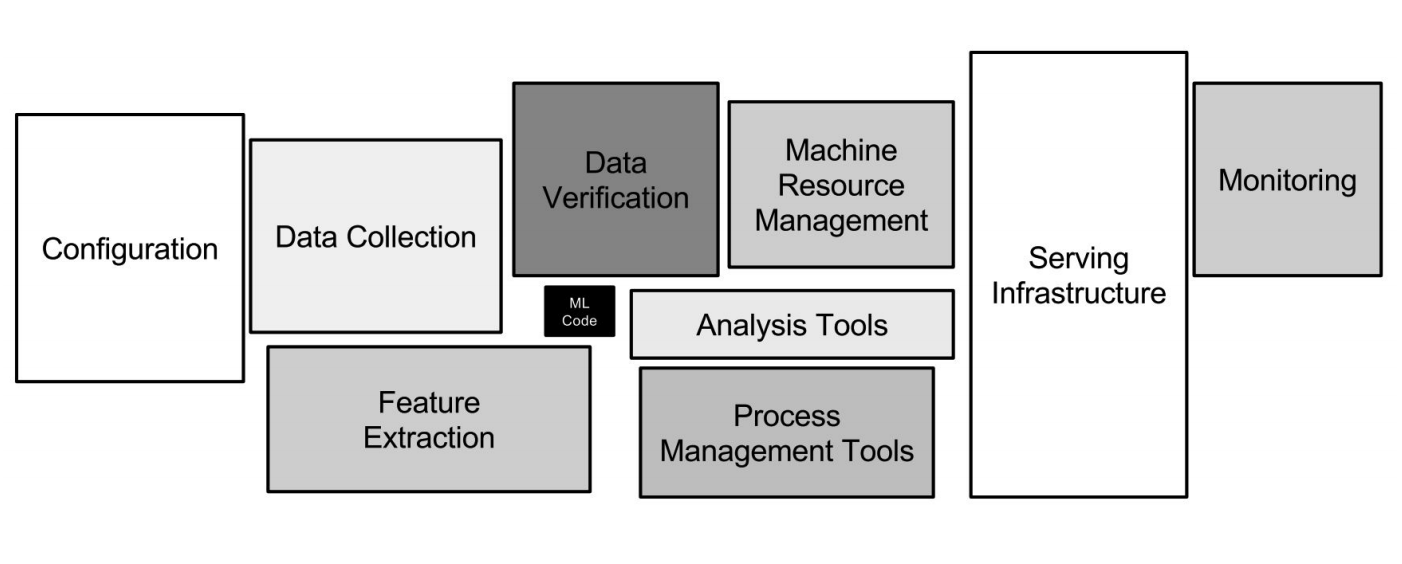 Infraestrutura do Google ML
Infraestrutura do Google MLAs redes neurais são apenas uma pequena parte da infraestrutura (uma pequena caixa preta na imagem acima). Muitos outros sistemas auxiliares são necessários para receber dados, processá-los, armazená-los, verificar a qualidade etc., precisamos da infraestrutura para treinamento, implantação de código de aprendizado de máquina na produção e teste desse código. Todas essas tarefas são exatamente como o que os desenvolvedores de back-end fazem.
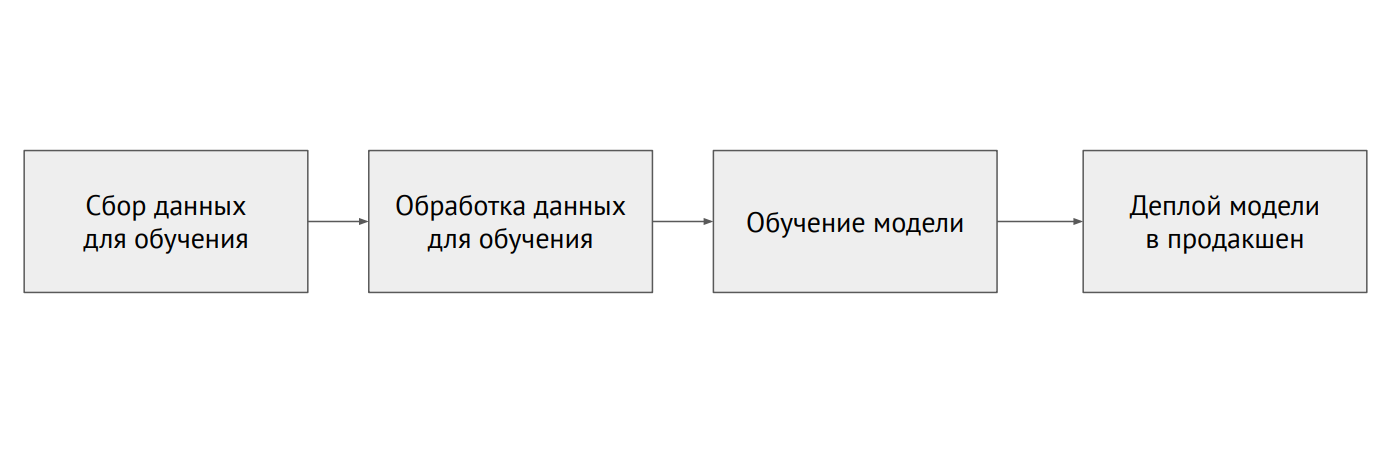 Processo de aprendizado de máquina
Processo de aprendizado de máquinaQual é a diferença entre ML e backend
Na programação clássica, escrevemos código, e isso determina o comportamento do programa. No ML, temos um pequeno código de modelo e muitos dados com os quais descartamos o modelo. Os dados no ML são muito importantes: o mesmo modelo, treinado com dados diferentes, pode mostrar resultados completamente diferentes. O problema é que quase sempre os dados são fragmentados e estão em sistemas diferentes (bancos de dados relacionais, bancos de dados NoSQL, logs, arquivos).
 Versão de dados
Versão de dadosO ML requer a versão não apenas do código, como no desenvolvimento clássico, mas também de dados: é necessário entender claramente em que modelo foi treinado. Você pode usar a popular biblioteca Data Science Version Control (dvc.org) para isso.
 Marcação de dados
Marcação de dadosA próxima tarefa é a marcação de dados. Por exemplo, marque todos os objetos na imagem ou diga a qual classe pertence. Isso é feito por serviços especiais como o Yandex.Tolki, cujo trabalho simplifica bastante a disponibilidade da API. As dificuldades surgem devido ao “fator humano”: é possível melhorar a qualidade dos dados e minimizar os erros confiando a mesma tarefa a vários artistas.
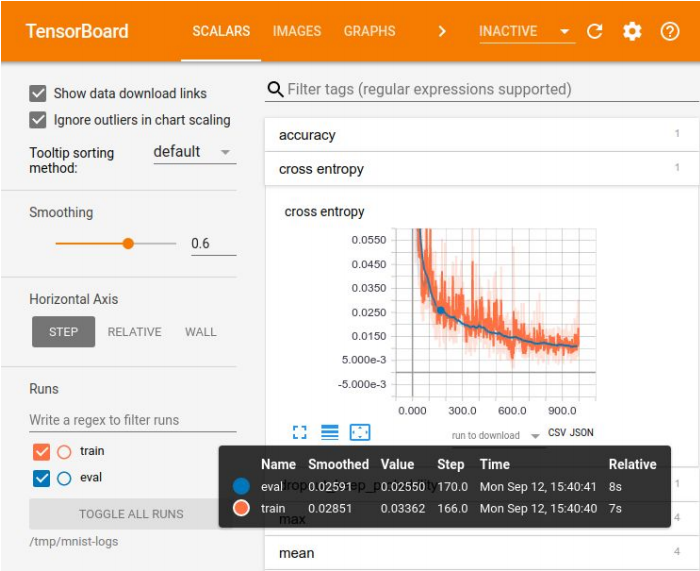 Visualização na placa tensora
Visualização na placa tensoraO registro de experimentos é necessário para comparar resultados, escolhendo o melhor modelo para algumas métricas. Para visualização, há um grande conjunto de ferramentas - por exemplo, Tensor Board. Mas não há métodos ideais para armazenar experimentos. Em pequenas empresas, eles costumam se dar bem com uma placa de excel; em grandes empresas, usam plataformas especiais para armazenar resultados no banco de dados.
 Existem muitas plataformas para aprendizado de máquina, mas nenhuma delas cobre até 70% das necessidades
Existem muitas plataformas para aprendizado de máquina, mas nenhuma delas cobre até 70% das necessidadesO primeiro problema com o qual você deve lidar ao trazer um modelo treinado para a produção está relacionado à sua ferramenta favorita do cientista de dados - o Jupyter Notebook. Não há modularidade, ou seja, a saída é um "pé-cair" de código que não é dividido em partes lógicas - módulos. Tudo está confuso: classes, funções, configurações, etc. Esse código é difícil de versão e teste.
Como lidar com isso? Você pode suportar a Netflix e criar sua própria plataforma que permite executar esses laptops diretamente na produção, transferir dados para eles e obter o resultado. Você pode forçar os desenvolvedores que lançam o modelo em produção a reescrever o código normalmente, dividi-lo em módulos. Mas com essa abordagem, é fácil cometer um erro, e o modelo não funcionará conforme o esperado. Portanto, a opção ideal é proibir o uso do Jupyter Notebook para código de modelo. Se, é claro, os cientistas de dados concordam com isso.
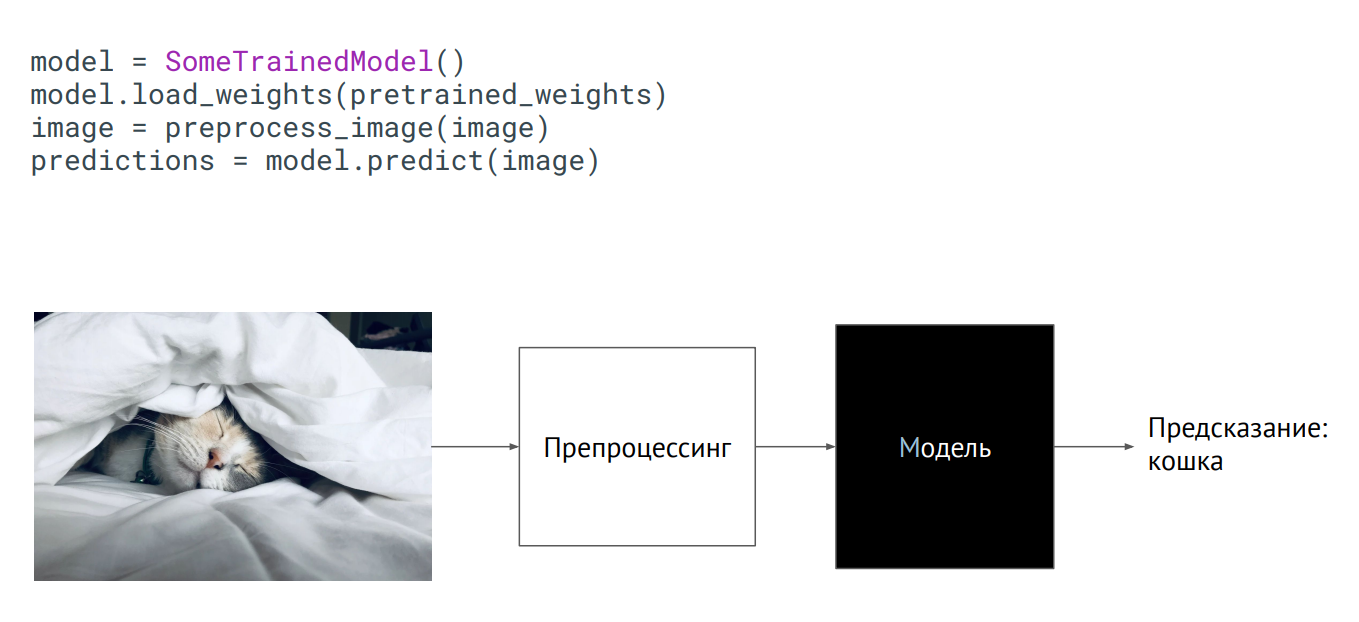 Modelar como uma caixa preta
Modelar como uma caixa pretaA maneira mais fácil de trazer um modelo para a produção é usá-lo como uma caixa preta. Você tem alguma classe do modelo, os pesos do modelo (parâmetros dos neurônios da rede treinada) foram passados para você e, se você inicializar essa classe (chame o método de previsão, coloque uma imagem nela), a saída terá algum tipo de previsão. O que acontece lá dentro não importa.
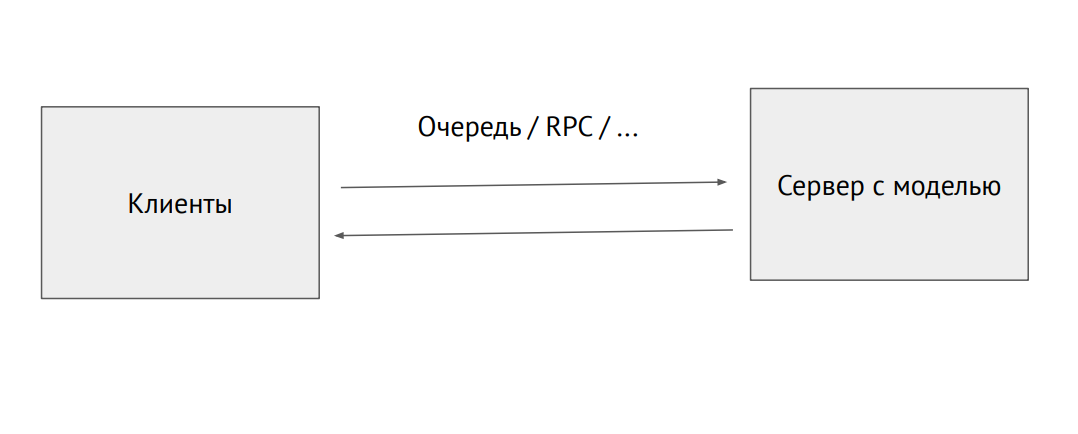 Processo de servidor separado com um modelo
Processo de servidor separado com um modeloVocê também pode pegar um processo separado e enviá-lo pela fila RPC (com imagens ou outros dados de origem. Na saída, receberemos previsões.
Um exemplo de uso do modelo no Flask:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
O problema com essa abordagem é a limitação de desempenho. Suponha que tenhamos um código Phyton escrito por cientistas de dados que diminua a velocidade e desejemos reduzir o desempenho máximo. Para fazer isso, você pode usar ferramentas que convertem o código em nativo ou em outra estrutura, aprimorada para produção. Existem essas ferramentas para cada estrutura, mas não existem ferramentas ideais, você terá que finalizá-lo você mesmo.
A infraestrutura no ML é a mesma de um back-end regular. Existem o Docker e o Kubernetes, apenas no Docker é necessário definir o tempo de execução da NVIDIA, o que permite que os processos dentro do contêiner acessem as placas de vídeo no host. O Kubernetes precisa de um plugin para poder gerenciar servidores com placas de vídeo.
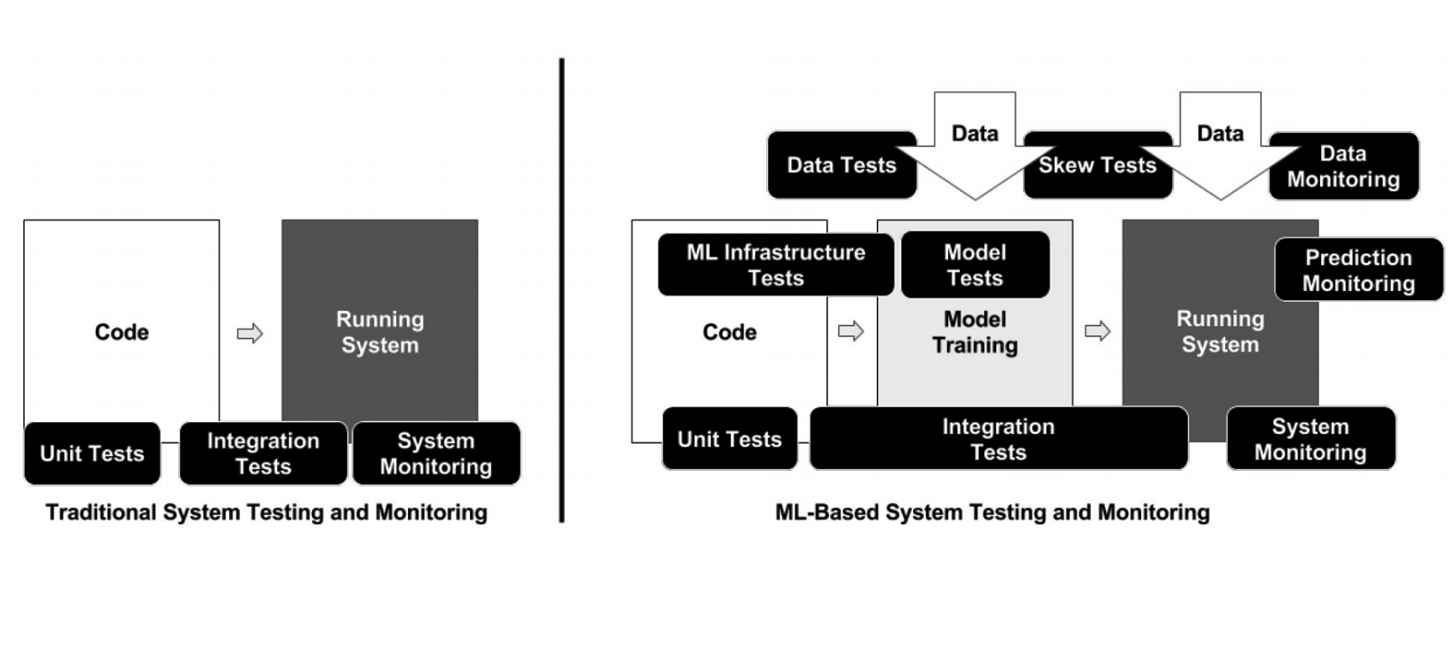
Diferentemente da programação clássica, no caso do ML, a infraestrutura possui muitos elementos móveis diferentes que precisam ser verificados e testados - por exemplo, código de processamento de dados, pipeline de treinamento de modelos e produção (veja o diagrama acima). É importante testar o código que conecta diferentes partes de pipelines: existem muitas e muitos problemas surgem nas bordas dos módulos.
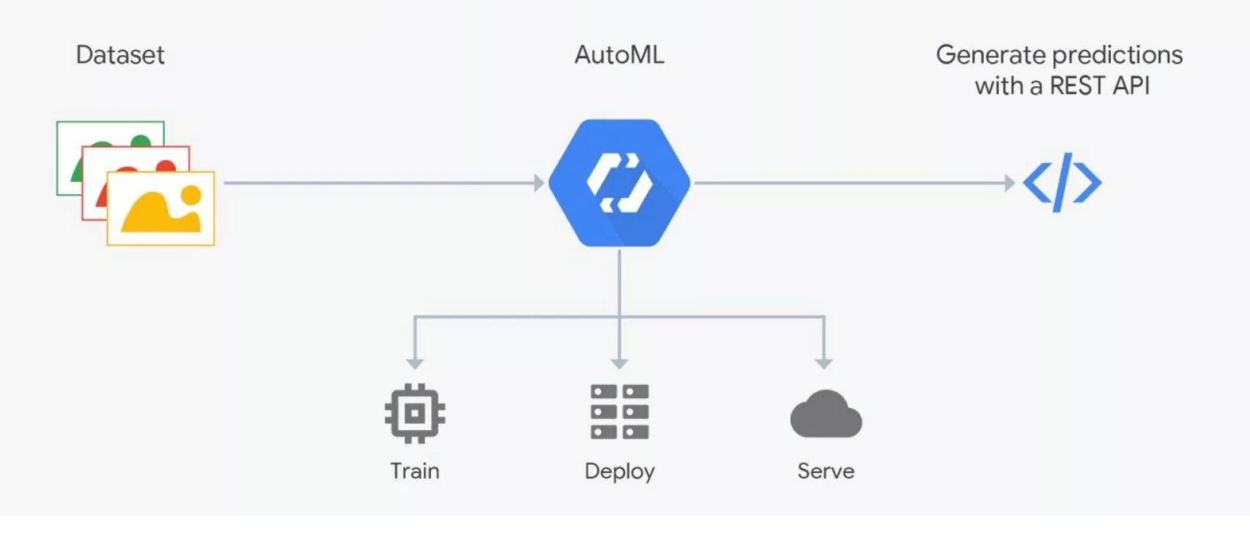 Como o AutoML funciona
Como o AutoML funcionaOs serviços AutoML prometem selecionar o melhor modelo para seus objetivos e treiná-lo. Mas você precisa entender: nos dados de ML é muito importante, o resultado depende de sua preparação. As pessoas estão marcando, que está repleta de erros. Sem um controle rígido, o lixo pode acabar, mas a automação ainda não funciona; verificação por especialistas - cientistas de dados são necessários. É aqui que o AutoML “quebra”. Mas pode ser útil para a seleção da arquitetura - quando você já preparou os dados e deseja realizar uma série de experimentos para encontrar o melhor modelo.
Como entrar no aprendizado de máquina
Entrar no ML é mais fácil se você estiver desenvolvendo no Python, que é usado em todas as estruturas de aprendizado profundo (e estruturas regulares). Esse idioma é praticamente necessário para este campo de atividade. O C ++ é usado para algumas tarefas com visão computacional - por exemplo, em sistemas de controle de veículos não tripulados. JavaScript e Shell - para visualização e coisas estranhas como o lançamento de um neurônio em um navegador. Java e Scala são usados ao trabalhar com Big Data e para aprendizado de máquina. R e Julia são amadas por pessoas que fazem estatísticas.
Adquirir experiência prática é mais conveniente no Kaggle, a participação em um dos concursos da plataforma oferece mais de um ano de estudo da teoria. Nesta plataforma, você pode pegar o código de alguém e comentar e tentar melhorá-lo, otimizar seus objetivos. A classificação de bônus no Kaggle afeta seu salário.
Outra opção é ir como desenvolvedor de back-end para a equipe de ML. Agora, existem muitas startups envolvidas no aprendizado de máquina, nas quais você ganha experiência ajudando colegas na solução de seus problemas. Por fim, você pode ingressar em uma das comunidades de cientistas de dados - Open Data Science (ods.ai) e outras.
O orador colocou informações adicionais sobre o tópico em https://bit.ly/backend-to-ml
“Quadrupel” - o serviço de notificações direcionadas do portal “Serviços do Estado”

Evgeny Smirnov
O próximo palestrante foi Yevgeny Smirnov, chefe do departamento de desenvolvimento de infraestrutura de governo eletrônico, que falou sobre o Quadrupel. Este é um serviço de notificação direcionada do portal Gosuslugi (gosuslugi.ru), o recurso estatal mais visitado na Internet russa. O público diário é de 2,6 milhões, no total, 90 milhões de usuários estão registrados no site, dos quais 60 milhões são confirmados. A carga na API do portal é de 30 mil RPS.
 Tecnologias usadas no backend Gosuslug
Tecnologias usadas no backend Gosuslug“Quádruplo” é um serviço de notificação de endereço, com a ajuda do qual o usuário recebe uma oferta de serviço no momento mais adequado para ele, definindo regras de informações especiais. Os principais requisitos no desenvolvimento do serviço eram configurações flexíveis e tempo adequado para envio.
Como o Quádruplo funciona?

O diagrama acima mostra uma das regras do "Quádruplo" no exemplo de uma situação com a necessidade de substituir uma carteira de motorista. Primeiro, o serviço procura usuários cuja data de validade expira em um mês. Eles colocam um banner com uma oferta para receber o serviço correspondente e enviar uma mensagem de email. Para os usuários que já expiraram, o banner e o email estão mudando. Após uma troca bem-sucedida de direitos, o usuário recebe outras notificações com uma proposta para atualizar os dados no certificado.
Do ponto de vista técnico, esses são scripts groovy nos quais o código é escrito. Na entrada - dados, na saída - verdadeiro / falso, correspondido / não correspondido. No total, mais de 50 regras - desde a determinação do aniversário do usuário (a data atual é igual ao aniversário do usuário) até situações difíceis. Todos os dias, de acordo com essas regras, são determinadas cerca de um milhão de partidas - pessoas que precisam ser notificadas.
 Canais quádruplos de notificação
Canais quádruplos de notificaçãoSob o capô do Quadrupel, há um banco de dados no qual os dados do usuário são armazenados e três aplicações:
- Worker foi projetado para atualizar dados.
- A API Rest pega e entrega os banners ao portal e ao aplicativo móvel.
- O Agendador lança recontagens de banner ou mala direta.
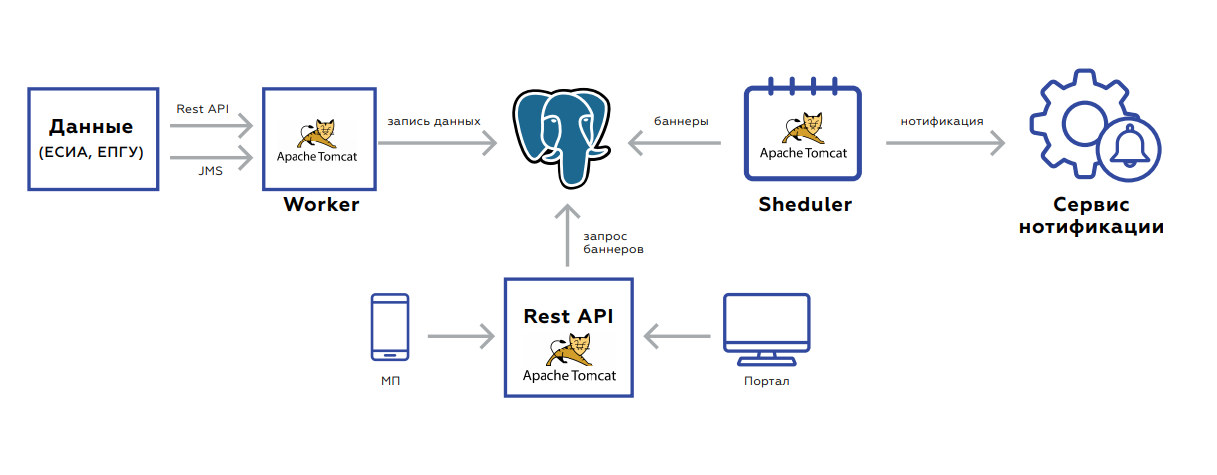
O back-end é orientado a eventos para atualização de dados. Duas interfaces - descanso ou JMS. Existem muitos eventos, antes de serem salvos e processados, eles são agregados para não fazer solicitações desnecessárias. O próprio banco de dados, a placa na qual os dados são armazenados, se parece com o armazenamento de valores-chave - a chave do usuário e o próprio valor: sinalizadores indicando a presença ou ausência de documentos relevantes, seu período de validade, estatísticas agregadas sobre a ordem de serviços por esse usuário e assim por diante.

Após salvar os dados, a tarefa é configurada no JMS para que os banners sejam recontados imediatamente - isso deve ser exibido imediatamente na web. O sistema inicia à noite: no JMS, as tarefas são lançadas em intervalos de usuário, de acordo com o qual você precisa recontar as regras. Isso é captado pelos recuperadores. Além disso, os resultados do processamento caem na próxima fila, que salva os banners no banco de dados ou envia tarefas ao usuário para notificá-lo. O processo leva de 5 a 7 horas, é facilmente escalável devido ao fato de que você sempre pode descartar processadores ou criar instâncias com novos processadores.

O serviço funciona muito bem. Mas a quantidade de dados está crescendo à medida que mais usuários. Isso leva a um aumento na carga no banco de dados - mesmo levando em consideração o fato de a API Rest estar observando a réplica. O segundo ponto é o JMS, que, como se viu, não é muito adequado devido ao grande consumo de memória. Há um alto risco de excesso de fila com falha no JMS e parada de processamento. É impossível gerar o JMS após isso sem limpar os logs.
Está planejado para resolver problemas usando sharding, o que permitirá equilibrar a carga na base. Também há planos para alterar o esquema de armazenamento de dados e alterar o JMS para Kafka - uma solução mais tolerante a falhas que resolverá problemas de memória.
Back-end como serviço vs. Sem servidor
 Da esquerda para a direita: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara Israelyan
Da esquerda para a direita: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara IsraelyanBack-end como um serviço ou solução sem servidor? As seguintes pessoas participaram da discussão desta questão premente na mesa redonda:
- Ara Israelyan, CTO CTO e fundador da Scorocode.
- Nikolay Markov, engenheiro de dados sênior do Aligned Research Group.
- Andrey Tomilenko, Chefe do Departamento de Desenvolvimento da RUVDS.
A conversa foi moderada pelo desenvolvedor sênior Alexander Borgart. Apresentamos o debate, do qual o público participou, em uma versão resumida.
- O que é Serverless na sua compreensão?
Andrei : Este é um modelo computacional - uma função Lambda que deve processar dados para que o resultado dependa apenas dos dados. O termo veio do Google ou da Amazon e de seu serviço AWS Lambda. É mais fácil para o provedor processar essa função alocando um pool de capacidade para isso. Usuários diferentes podem ser considerados independentemente nos mesmos servidores.
Nikolay : se é simples, transferimos parte da nossa infraestrutura de TI, lógica de negócios para a nuvem, para terceirizar.
Ara : Por parte dos desenvolvedores - uma boa tentativa de economizar recursos, por parte dos profissionais de marketing - para ganhar mais dinheiro.
- Sem servidor - o mesmo que microsserviços?
Nikolai : Não, o Serverless é mais uma organização da arquitetura. O microsserviço é uma unidade atômica de uma certa lógica. Sem servidor é uma abordagem, não uma "entidade separada".
Ara : A função sem servidor pode ser empacotada em um microsserviço, mas a partir disso deixará de ser sem servidor, deixará de ser uma função Lambda. No Serverless, uma função é iniciada apenas quando solicitada.
Andrew : Eles diferem no tempo da vida. Lançamos e esquecemos a função Lambda. Funcionou por alguns segundos, e o próximo cliente pode processar sua solicitação em outra máquina física.
- Qual escala melhor?
Ara : Com o dimensionamento horizontal, as funções do Lambda se comportam exatamente da mesma maneira que os microsserviços.
Nikolai : Quantas réplicas você pede - haverá muitas delas, não há problemas com o dimensionamento sem servidor. O Kubernetes criou um conjunto de réplicas, lançou 20 instâncias "em algum lugar" e 20 links anônimos retornaram para você. Vá em frente!
- É possível escrever um back-end no Serverless?
Andrew : Teoricamente, mas não há sentido nisso. As funções do Lambda ficarão contra um único repositório - precisamos fornecer uma garantia. Por exemplo, se o usuário realizou uma determinada transação, na próxima vez em que ele deve ver: a transação foi concluída, os fundos foram creditados. Todas as funções do Lambda serão bloqueadas nesta chamada. De fato, várias funções sem servidor se transformarão em um único serviço com um ponto restrito de acesso ao banco de dados.
- Em que situações faz sentido usar a arquitetura sem servidor?
Andrew : Tarefas nas quais um armazenamento comum não é necessário - a mesma mineração, blockchain. Onde você precisa contar muito. Se você tem muita capacidade de computação, pode definir uma função como “calcular o hash de algo lá ...”. Mas você pode resolver o problema do armazenamento de dados usando, por exemplo, as funções Amazon e Lambda e seu armazenamento distribuído. E acontece que você está escrevendo um serviço regular. As funções do Lambda acessarão o repositório e darão algum tipo de resposta ao usuário.
Nikolai : Os contêineres executados no Serverless são extremamente limitados por recursos. Há pouca memória e tudo mais. Mas se você tiver toda a infraestrutura implantada completamente em algum tipo de nuvem - Google, Amazon - e tiver um contrato permanente com eles, há um orçamento para tudo isso; em algumas tarefas, você poderá usar contêineres sem servidor. É necessário estar localizado exatamente dentro dessa infraestrutura, porque tudo é adaptado para uso em um ambiente específico. Ou seja, se você estiver pronto para vincular tudo à infraestrutura de nuvem, poderá experimentar. A vantagem é que você não precisa gerenciar essa infraestrutura.
Ara : Que o Serverless não exige que você gerencie o Kubernetes, Docker, instale o Kafka e assim por diante, é auto-engano. A mesma Amazon e Google são o gerente e eles colocam. Outra coisa é que você tem um SLA. Com o mesmo sucesso, você pode terceirizar tudo e não programar por conta própria.
Andrew : O servidor sem servidor é barato, mas você precisa pagar muito pelo restante dos serviços da Amazon - por exemplo, um banco de dados. As pessoas já os processaram pelo fato de estarem arrancando dinheiro louco pelo portão da API.
Ara : Se falamos de dinheiro, é necessário considerar este ponto: você precisará implantar 180 graus de toda a metodologia de desenvolvimento na empresa para transferir todo o código para o Serverless. Vai levar muito tempo e dinheiro.
- Existem alternativas decentes ao Amazon sem servidor pago e ao Google?
Nikolay : No Kubernetes, você inicia algum tipo de trabalho, ele realiza e morre - isso é bastante sem servidor do ponto de vista da arquitetura. Se você deseja criar uma lógica de negócios realmente interessante com filas, com bases, precisará pensar um pouco mais sobre isso. Tudo isso é resolvido sem sair do Kubernetes. Eu não começaria a arrastar implementação adicional.
- Qual a importância de monitorar o que está acontecendo no Serverless?
Ara : Depende da arquitetura do sistema e dos requisitos de negócios. De fato, o provedor deve fornecer relatórios que ajudarão o devedor a descobrir possíveis problemas.
Nikolai : Na Amazon, há o CloudWatch, onde todos os logs são transmitidos, inclusive com o Lambda. Integre o encaminhamento de logs e use alguma ferramenta separada para visualizar, alertar e assim por diante. Nos contêineres que você inicia, você pode empinar os agentes.
 - Vamos resumir.
- Vamos resumir.
Andrew : Pensar nas funções do Lambda é útil. Se você criar um serviço no joelho - não um microsserviço, mas aquele que escreve uma solicitação, acessa o banco de dados e envia uma resposta - a função Lambda resolve vários problemas: multithreading, escalabilidade e muito mais. Se sua lógica for criada dessa maneira, no futuro você poderá transferir esses Lambda para microsserviços ou usar serviços de terceiros como a Amazon. A tecnologia é útil, uma ideia interessante. Quanto é justificado para os negócios ainda é uma questão em aberto.
Nikolai: Sem servidor é melhor usar para tarefas operacionais do que calcular algum tipo de lógica comercial. Eu sempre tomo isso como processamento de eventos. Se você tiver na Amazon, se estiver em Kubernetes - sim. Caso contrário, você terá que fazer muitos esforços para elevar o servidor sem servidor. Você precisa assistir a um caso de negócios específico. Por exemplo, agora tenho uma das tarefas: quando os arquivos aparecem em um disco em um determinado formato, você precisa carregá-los no Kafka. Eu posso usar este WatchDog ou Lambda. Logicamente, ambos são adequados, mas o Serverless é mais difícil de implementar, e eu prefiro a maneira mais simples, sem o Lambda.
Ara : Sem servidor - uma idéia interessante, aplicável e tecnicamente bonita. Cedo ou tarde, a tecnologia chegará ao ponto em que qualquer função aumentará em menos de 100 milissegundos. Então, em princípio, não haverá dúvida se o tempo de espera é crítico para o usuário. Ao mesmo tempo, a aplicabilidade do Serverless, como os colegas já disseram, depende completamente da tarefa comercial.
Agradecemos aos nossos patrocinadores que nos ajudaram muito:
- O espaço das conferências de TI " Primavera " por trás da plataforma para a conferência.
- Calendário de eventos de TI Runet-ID e a publicação " Internet em números " para suporte de informações e notícias.
- Akronis para presentes.
- Avito para co-criação.
- RAEC “Association of Electronic Communications” para envolvimento e experiência.
- O principal patrocinador da RUVDS - para tudo!
