
Olá Habr! Lidero o desenvolvimento da plataforma
Vision - esta é a nossa plataforma pública, que fornece acesso a modelos de visão computacional e permite que você resolva tarefas como reconhecer rostos, números, objetos e cenas inteiras. E hoje quero dizer, pelo exemplo da Vision, como implementar um serviço rápido e altamente carregado usando placas de vídeo, como implantá-lo e operá-lo.
O que é a visão?
Esta é essencialmente uma API REST. O usuário gera uma solicitação HTTP com uma foto e a envia ao servidor.
Suponha que você precise reconhecer um rosto em uma imagem. O sistema encontra, corta, extrai algumas propriedades da face, salva no banco de dados e atribui um número condicional. Por exemplo, person42. O usuário então carrega a próxima foto, que tem a mesma pessoa. O sistema extrai propriedades de sua face, pesquisa no banco de dados e retorna o número condicional que foi atribuído à pessoa inicialmente, ou seja, person42.
Hoje, os principais usuários do Vision são vários projetos do Mail.ru Group. A maioria dos pedidos vem do Mail and Cloud.
Na nuvem, os usuários têm pastas nas quais as fotos são carregadas. A nuvem executa arquivos através do Vision e os agrupa em categorias. Depois disso, o usuário pode folhear suas fotos comodamente. Por exemplo, quando você deseja mostrar fotos a amigos ou familiares, pode encontrar rapidamente as que precisa.
O Mail e o Cloud são serviços muito grandes, com milhões de pessoas; portanto, o Vision processa centenas de milhares de solicitações por minuto. Ou seja, é um serviço clássico de alta carga, mas com uma reviravolta: ele possui nginx, um servidor web, um banco de dados e filas, mas no nível mais baixo desse serviço é a inferência - executando imagens através de redes neurais. É o funcionamento das redes neurais que ocupa a maior parte do tempo e requer recursos. As redes de computação consistem em uma sequência de operações da matriz que geralmente levam muito tempo na CPU, mas são perfeitamente paralelas na GPU. Para executar redes com eficiência, usamos um cluster de servidores com placas de vídeo.
Neste artigo, quero compartilhar um conjunto de dicas que podem ser úteis ao criar um serviço desse tipo.
Desenvolvimento de Serviços
Tempo de processamento para uma solicitação
Para um sistema com carga pesada, o tempo de processamento de uma solicitação e a taxa de transferência do sistema são importantes. A alta velocidade do processamento de consultas é fornecida, primeiramente, pela seleção correta da arquitetura de rede neural. No ML, como em qualquer outra tarefa de programação, as mesmas tarefas podem ser resolvidas de maneiras diferentes. Vamos dar uma detecção de rosto: para resolver esse problema, primeiro pegamos redes neurais com arquitetura R-FCN. Eles mostram uma qualidade razoavelmente alta, mas levaram cerca de 40 ms em uma imagem, o que não era adequado para nós.Em seguida, voltamos para a arquitetura MTCNN e obtivemos um aumento duplo de velocidade com uma leve perda de qualidade.
Às vezes, para otimizar o tempo de computação das redes neurais, pode ser vantajoso implementar inferência em outra estrutura, não na que foi ensinada. Por exemplo, às vezes faz sentido converter seu modelo em NVIDIA TensorRT. Aplica várias otimizações e é especialmente bom em modelos bastante complexos. Por exemplo, ele pode de alguma forma reorganizar algumas camadas, mesclar e até jogá-las fora; o resultado não será alterado e a velocidade de cálculo da inferência aumentará. O TensorRT também permite gerenciar melhor a memória e, após alguns truques, pode reduzi-la ao cálculo de números com menos precisão, o que também aumenta a velocidade da inferência de computação.
Baixar placa de vídeo
A inferência de rede é realizada na GPU, a placa de vídeo é a parte mais cara do servidor, por isso é importante usá-la da maneira mais eficiente possível. Como entender, carregamos totalmente a GPU ou podemos aumentar a carga? Esta pergunta pode ser respondida, por exemplo, usando o parâmetro GPU Utilization no utilitário nvidia-smi do pacote padrão do driver de vídeo. Esta figura, é claro, não mostra quantos núcleos CUDA são carregados diretamente na placa de vídeo, mas quantos estão ociosos, mas permite avaliar de alguma forma o carregamento da GPU. Por experiência, podemos dizer que 80-90% de carga é boa. Se o carregamento estiver entre 10 e 20%, isso é ruim e ainda há potencial.
Uma conseqüência importante dessa observação: você precisa tentar organizar o sistema para maximizar o carregamento das placas de vídeo. Além disso, se você tiver 10 placas de vídeo, cada uma com 10 a 20% de carga, provavelmente duas placas de vídeo de alta carga poderão resolver o mesmo problema.
Taxa de transferência do sistema
Quando você envia uma imagem para a entrada de uma rede neural, o processamento da imagem é reduzido a uma variedade de operações da matriz. A placa de vídeo é um sistema com vários núcleos e as imagens de entrada que geralmente enviamos são pequenas. Digamos que haja 1.000 núcleos em nossa placa de vídeo e tenhamos 250 x 250 pixels na imagem. Sozinhos, eles não poderão carregar todos os núcleos devido ao seu tamanho modesto. E se enviarmos essas fotos para o modelo, uma de cada vez, o carregamento da placa de vídeo não excederá 25%.
Portanto, você precisa fazer upload de várias imagens para inferência de uma só vez e formar um lote delas.
Nesse caso, a carga da placa de vídeo aumenta para 95% e o cálculo da inferência levará tempo como para uma única imagem.
Mas e se não houver 10 fotos na fila para que possamos combiná-las em um lote? Você pode esperar um pouco, por exemplo, 50-100 ms na esperança de que as solicitações cheguem. Essa estratégia é chamada de estratégia de latência de correção. Permite combinar solicitações de clientes em um buffer interno. Como resultado, aumentamos nosso atraso em uma quantia fixa, mas aumentamos significativamente a taxa de transferência do sistema.
Inferência de lançamento
Treinamos modelos em imagens de formato e tamanho fixos (por exemplo, 200 x 200 pixels), mas o serviço deve suportar a capacidade de fazer upload de várias imagens. Portanto, todas as imagens antes de enviar para a inferência, você precisa preparar adequadamente (redimensionar, centralizar, normalizar, converter para flutuar etc.). Se todas essas operações forem executadas em um processo que inicia a inferência, seu ciclo de trabalho será mais ou menos assim:
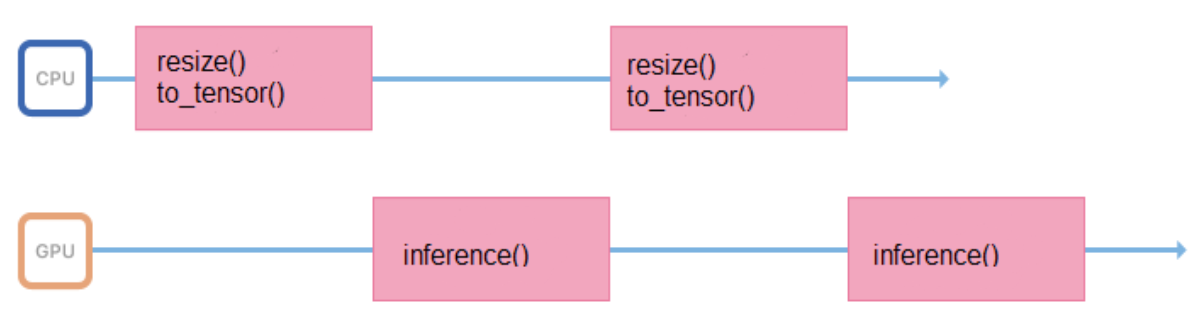
Ele passa algum tempo no processador, preparando os dados de entrada, aguardando uma resposta da GPU. É melhor minimizar os intervalos entre inferências para que a GPU fique ociosa menos.
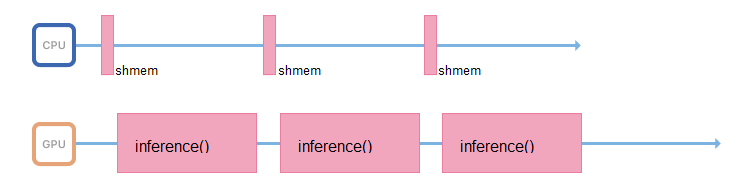
Para fazer isso, você pode iniciar outro fluxo ou transferir a preparação de imagens para outros servidores, sem placas de vídeo, mas com processadores poderosos.
Se possível, o processo responsável pela inferência deve lidar apenas com ele: acessar a memória compartilhada, coletar dados de entrada, copiá-los imediatamente para a memória da placa de vídeo e executar inferência.
Turbo boost
O lançamento de redes neurais é uma operação que consome recursos não apenas da GPU, mas também do processador. Mesmo que tudo esteja organizado corretamente em termos de largura de banda e o encadeamento que realiza a inferência já esteja aguardando novos dados, em um processador fraco, você simplesmente não terá tempo para saturar esse fluxo com novos dados.
Muitos processadores suportam a tecnologia Turbo Boost. Ele permite aumentar a frequência do processador, mas nem sempre é ativado por padrão. Vale a pena conferir. Para isso, o Linux possui o utilitário CPU Power:
$ cpupower frequency-info -m .
Os processadores também possuem um modo de consumo de energia que pode ser reconhecido por esse comando CPU Power:
performance .
No modo de economia de energia, o processador pode acelerar sua frequência e rodar mais devagar. Você deve entrar no BIOS e selecionar o modo de desempenho. Então o processador sempre funcionará na frequência máxima.
Implantação de aplicativo
O Docker é ótimo para implantar o aplicativo, pois permite executar aplicativos na GPU dentro do contêiner. Para acessar as placas de vídeo, primeiro você precisa instalar os drivers da placa de vídeo no sistema host - um servidor físico. Então, para iniciar o contêiner, você precisa fazer muito trabalho manual: jogue corretamente as placas de vídeo dentro do contêiner com os parâmetros corretos. Depois de iniciar o contêiner, ainda será necessário instalar drivers de vídeo dentro dele. E somente depois disso você poderá usar seu aplicativo.

Essa abordagem tem uma ressalva. Os servidores podem desaparecer do cluster e serem adicionados. É possível que servidores diferentes tenham versões diferentes de drivers e sejam diferentes da versão instalada dentro do contêiner. Nesse caso, um Docker simples será interrompido: o aplicativo receberá um erro de incompatibilidade de versão do driver ao tentar acessar a placa de vídeo.

Como lidar com isso? Existe uma versão do Docker da NVIDIA, graças à qual se torna mais fácil e mais agradável usar o contêiner. De acordo com a própria NVIDIA e de acordo com observações práticas, a sobrecarga do uso da nvidia-docker é de cerca de 1%.
Nesse caso, os drivers precisam ser instalados apenas na máquina host. Quando você inicia o contêiner, não precisa jogar nada dentro, e o aplicativo terá acesso imediato às placas de vídeo.

A "independência" do nvidia-docker dos drivers permite executar um contêiner da mesma imagem em máquinas diferentes nas quais versões diferentes de drivers estão instaladas. Como isso é implementado? O Docker possui um conceito chamado docker-runtime: é um conjunto de padrões que descreve como um contêiner deve se comunicar com o kernel do host, como deve iniciar e parar, como interagir com o kernel e o driver. Começando com uma versão específica do Docker, é possível substituir esse tempo de execução. Foi o que a NVIDIA fez: eles substituem o tempo de execução, capturam as chamadas para o driver de vídeo interno e convertem a versão correta em chamadas para o driver de vídeo.
Orquestração
Escolhemos Kubernetes como orquestra. Ele suporta muitos recursos muito úteis que são úteis para qualquer sistema muito carregado. Por exemplo, a descoberta automática permite que os serviços acessem um ao outro em um cluster sem regras complexas de roteamento. Ou tolerância a falhas - quando o Kubernetes sempre mantém vários contêineres prontos e, se algo aconteceu com o seu, o Kubernetes lança imediatamente um novo contêiner.
Se você já possui um cluster Kubernetes configurado, não precisa muito para começar a usar placas de vídeo dentro do cluster:
- drivers relativamente novos
- instalada nvidia-docker versão 2
- tempo de execução do docker definido por padrão como `nvidia` em /etc/docker/daemon.json:
"default-runtime": "nvidia"
- Plug-in instalado
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
Depois de configurar o cluster e instalar o plug-in do dispositivo, você pode especificar uma placa de vídeo como um recurso.
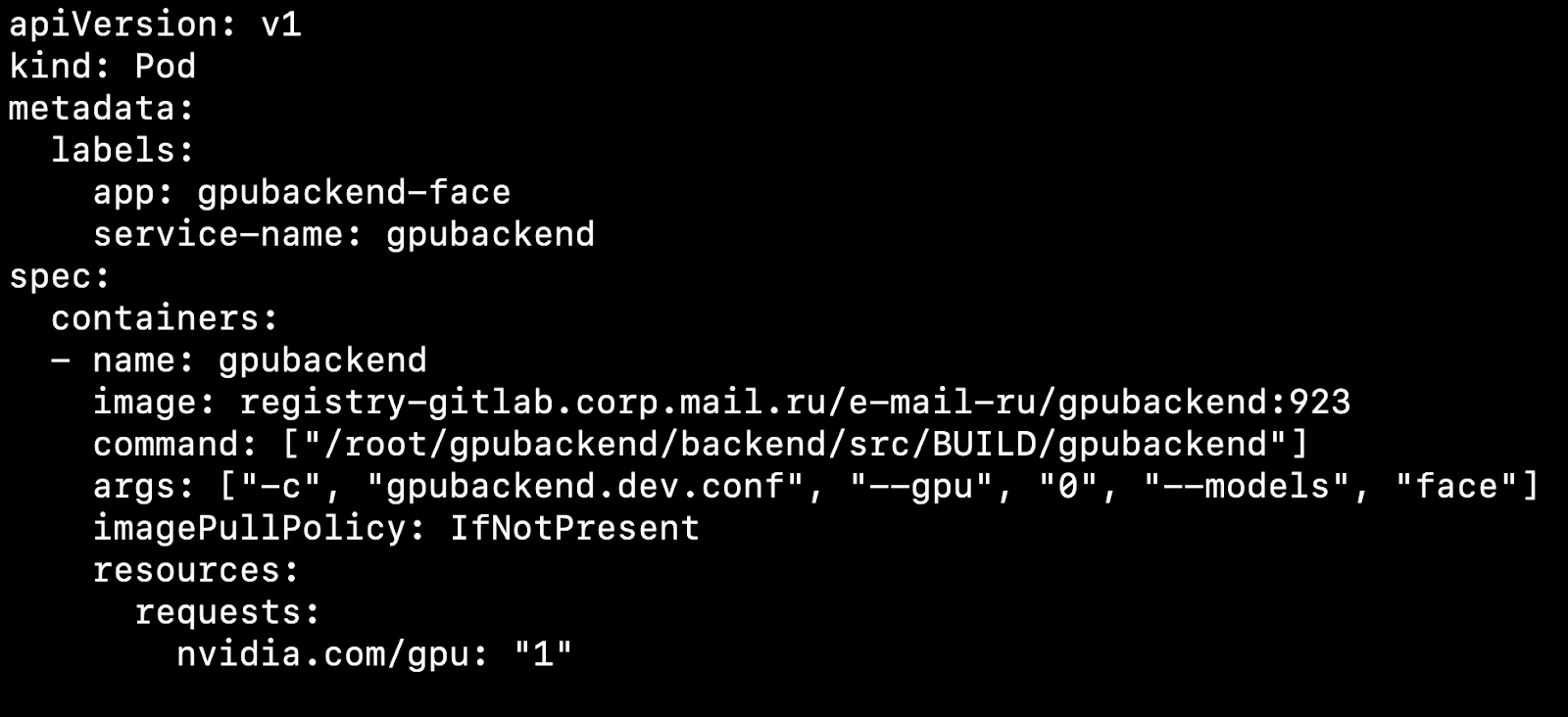
O que isso afeta? Digamos que temos dois nós, máquinas físicas. Por um lado, há uma placa de vídeo, por outro, não. O Kubernetes irá detectar uma máquina com uma placa de vídeo e pegar nosso pod nela.
É importante observar que o Kubernetes não sabe como atrapalhar competentemente uma placa de vídeo entre os pods. Se você possui 4 placas de vídeo e precisa de 1 GPU para iniciar o contêiner, poderá gerar no máximo 4 pods no cluster.
Tomamos como regra 1 Pod = 1 Modelo = 1 GPU.
Há uma opção para executar mais instâncias em 4 placas de vídeo, mas não a consideraremos neste artigo, pois essa opção não sai da caixa.
Se vários modelos girarem ao mesmo tempo, é conveniente criar a Implantação no Kubernetes para cada modelo. Em seu arquivo de configuração, você pode especificar o número de lares para cada modelo, levando em consideração a popularidade do modelo. Se muitas solicitações vierem para o modelo, será necessário especificar muitos pods para ele, se houver poucas solicitações, haverá poucos pods. No total, o número de lares deve ser igual ao número de placas de vídeo no cluster.
Considere um ponto interessante. Digamos que temos 4 placas de vídeo e 3 modelos.
Nas duas primeiras placas de vídeo, suba a inferência do modelo de reconhecimento de rosto, em outro reconhecimento de objetos e em outro reconhecimento de números de carros.
Você trabalha, os clientes vão e vêm e, uma vez, por exemplo, à noite, surge uma situação em que uma placa de vídeo com objetos de inferência simplesmente não é carregada, uma pequena quantidade de solicitações chega e as placas de vídeo com reconhecimento de rosto ficam sobrecarregadas. Eu gostaria de montar um modelo com objetos neste momento e lançar faces em seu lugar para descarregar as linhas.
Para o dimensionamento automático de modelos em placas de vídeo, existem ferramentas dentro do Kubernetes - dimensionamento automático da lareira horizontal (HPA, autoescalador de pod horizontal).
Pronto para uso, o Kubernetes suporta o dimensionamento automático na utilização da CPU. Porém, em uma tarefa com placas de vídeo, será muito mais razoável usar informações sobre o número de tarefas de cada modelo para dimensionamento.
Fazemos isso: coloque solicitações para cada modelo em uma fila. Quando as solicitações são concluídas, nós as removemos dessa fila. Se conseguirmos processar rapidamente solicitações de modelos populares, a fila não aumentará. Se o número de solicitações para um modelo específico aumentar repentinamente, a fila começará a crescer. Torna-se claro que você precisa adicionar placas de vídeo que ajudarão a aumentar a linha.
Informações sobre as filas que proxy através do HPA através do Prometheus:
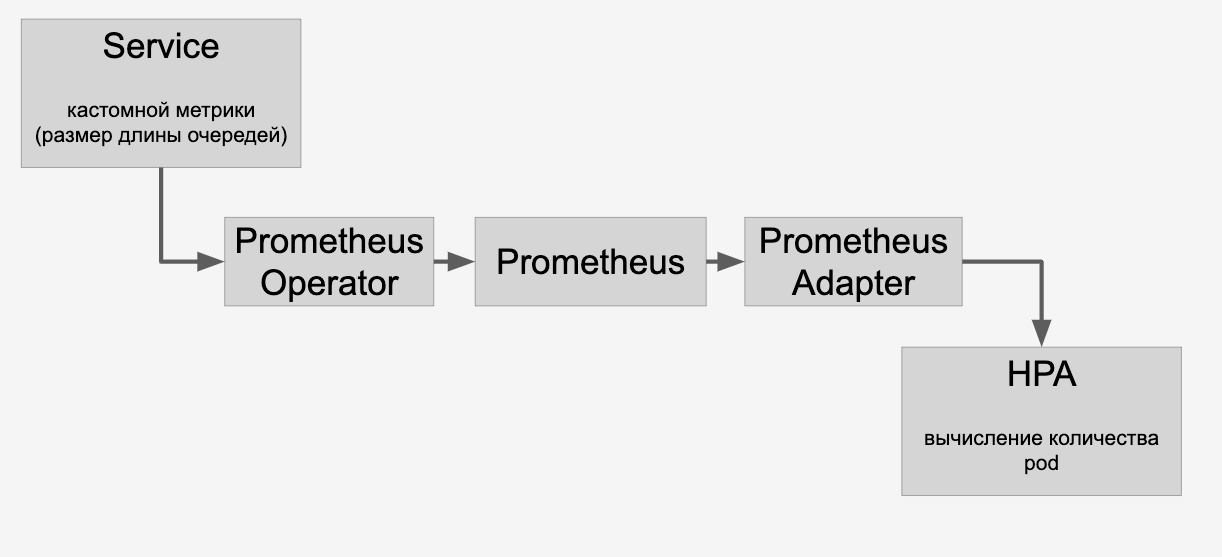
E então fazemos o dimensionamento automático dos modelos nas placas de vídeo no cluster, dependendo do número de solicitações para eles.
CI / CD
Depois de encerrar o aplicativo e envolvê-lo no Kubernetes, você tem literalmente um passo para a parte superior do projeto. Você pode adicionar CI / CD, aqui está um exemplo do nosso pipeline:
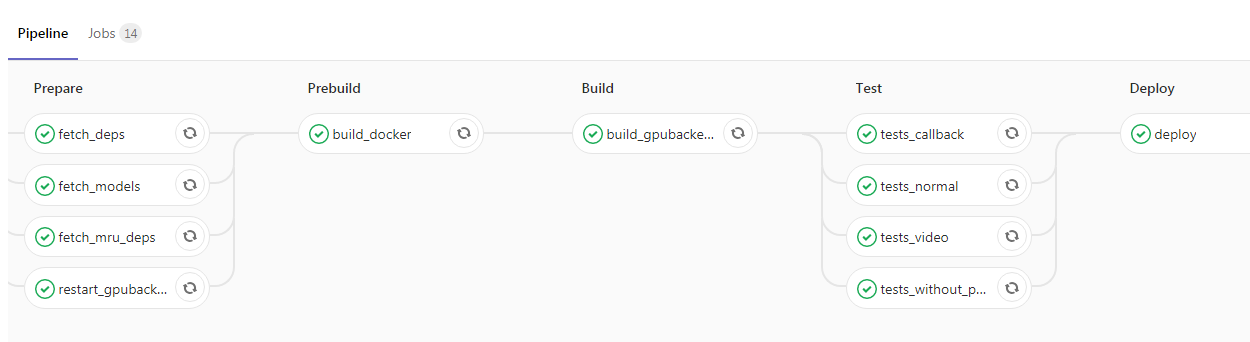
Aqui, o programador lançou o novo código na ramificação principal, após o qual a imagem do Docker com nossos daemons de back-end é coletada automaticamente e os testes são executados. Se todas as marcas de verificação estiverem verdes, o aplicativo será derramado no ambiente de teste. Se não houver problemas, você poderá enviar a imagem para operação sem dificuldades.
Conclusão
No meu artigo, abordamos alguns aspectos do trabalho de um serviço altamente carregado usando uma GPU. Falamos sobre maneiras de reduzir o tempo de resposta de um serviço, como:
- seleção da arquitetura de rede neural ideal para reduzir a latência;
- Aplicativos de estruturas de otimização como o TensorRT.
Levantou os problemas do aumento da taxa de transferência:
- o uso de lotes de imagens;
- aplicar a estratégia de latência de correção para reduzir o número de execuções de inferência, mas cada inferência processaria um número maior de imagens;
- otimização do pipeline de entrada de dados para minimizar o tempo de inatividade da GPU;
- "Combate" com trote do processador, remoção de operações vinculadas à CPU para outros servidores.
Analisamos o processo de implantação de um aplicativo com uma GPU:
- Usando a nvidia-docker dentro do Kubernetes
- escala com base no número de solicitações e HPA (autoscaler horizontal do pod).