Um dos recursos mais interessantes do iPhone X é o método de desbloqueio: FaceID. Este artigo discute o princípio de operação desta tecnologia.

A imagem do rosto do usuário é capturada usando uma câmera infravermelha, mais resistente a mudanças de luz e cor do ambiente. Usando um treinamento aprofundado, um smartphone é capaz de reconhecer o rosto do usuário nos mínimos detalhes, "reconhecendo" o proprietário toda vez que ele pega o telefone. Surpreendentemente, a Apple disse que esse método é ainda mais seguro que o TouchID: a taxa de erro é de 1: 1 000 000.
Este artigo explora o princípio de um algoritmo semelhante ao FaceID usando Keras. Também são apresentados alguns dos desenvolvimentos finais criados usando o Kinect.
Noções básicas sobre o FaceID
"... as redes neurais nas quais a tecnologia FaceID se baseia não apenas executam a classificação."
O primeiro passo é analisar como o FaceID funciona no iPhone X. A
documentação técnica pode nos ajudar com isso. Com o TouchID, o usuário teve que registrar suas impressões digitais primeiro tocando no sensor várias vezes. Após 10 a 15 toques diferentes, o smartphone conclui o registro.
Da mesma forma com o FaceID: o usuário deve registrar seu rosto. O processo é bastante simples: o usuário simplesmente olha para o telefone como faz diariamente e depois lentamente vira a cabeça em círculo, registrando o rosto em diferentes poses. Isso encerra o registro e o telefone está pronto para desbloquear. Esse procedimento de registro incrivelmente rápido pode dizer muito sobre os algoritmos básicos de aprendizado. Por exemplo, as redes neurais nas quais a tecnologia FaceID se baseia não executam apenas a classificação.
Realizar uma classificação para uma rede neural significa a capacidade de prever se a pessoa que ela está "vendo" no momento é o rosto do usuário. Portanto, ela deve usar alguns dados de treinamento para prever "verdadeiro" ou "falso", mas, diferentemente de muitos outros aplicativos de aprendizado profundo, essa abordagem não funcionará aqui.
Primeiro, a rede deve treinar do zero, usando novos dados recebidos do rosto do usuário. Isso exigiria muito tempo, energia e muitos dados de pessoas diferentes (não sendo o rosto do usuário) para ter exemplos negativos. Além disso, esse método não permitirá que a Apple treine uma rede mais complexa “offline”, ou seja, em seus laboratórios, e depois a envie já treinada e pronta para uso em seus telefones. Acredita-se que o FaceID seja baseado na rede neural convolucional siamesa, treinada “offline” para exibir rostos em um espaço oculto de baixa dimensão, formado para maximizar a diferença entre rostos de pessoas diferentes, usando a perda de contraste. Você obtém uma arquitetura que pode fazer um treinamento único, conforme mencionado no Keynote.

Do rosto aos números
A rede neural siamesa consiste basicamente em duas redes neurais idênticas, que também compartilham todos os pesos. Essa arquitetura pode aprender a distinguir distâncias entre dados específicos, como imagens. A ideia é que você transmita pares de dados através de redes siamesas (ou apenas transfira dados em duas etapas diferentes pela mesma rede), a rede os exibe nas características de baixa dimensão do espaço, como uma matriz n-dimensional, e então você treina a rede, fazer tal comparação que os dados de pontos de diferentes classes fossem o mais longe possível, enquanto os dados de pontos da mesma classe fossem o mais próximo possível.
Por fim, a rede aprenderá a extrair as funções mais significativas dos dados e compactá-las em uma matriz, criando uma imagem. Para entender isso, imagine como você descreveria raças de cães usando um vetor pequeno para que cães semelhantes tivessem vetores quase semelhantes. Você provavelmente usaria um número para codificar a cor do cachorro, o outro para indicar o tamanho do cachorro, o terceiro para o comprimento da pelagem, etc. Assim, cães iguais terão vetores semelhantes. Uma rede neural siamesa pode fazer isso por você, assim como um
codificador automático .
Usando essa tecnologia, é necessário um grande número de indivíduos para treinar essa arquitetura para reconhecer as mais semelhantes. Com o orçamento e o poder de computação adequados (como a Apple), você também pode usar exemplos mais sofisticados para tornar a rede resiliente a situações como gêmeos, máscaras etc.
Qual é a vantagem final dessa abordagem? Por fim, você tem um modelo plug and play que pode reconhecer vários usuários sem nenhuma preparação adicional, mas simplesmente calcula a localização da face de um usuário em um mapa de faces oculto formado após a configuração do FaceID. Além disso, o FaceID é capaz de se adaptar às mudanças na sua aparência: repentinas (por exemplo, óculos, chapéu, maquiagem) e “gradual” (cabelos em crescimento). Isso é feito adicionando vetores de suporte de face calculados com base em sua nova aparência no mapa.

Implementando o FaceID com Keras
Para todos os projetos de aprendizado de máquina, a primeira coisa que precisamos é de dados. Criar seu próprio conjunto de dados exigirá tempo e cooperação de muitas pessoas, portanto, isso pode ser difícil. Existe um site
com um conjunto de dados de faces RGB-D. Consiste em uma série de fotos RGB-D de pessoas em poses diferentes e expressões faciais diferentes, como seria o caso do iPhone X. Para ver a implementação final, aqui está um link para o
GitHub.Uma rede de convolução é criada com base na arquitetura
SqueezeNet . Como entrada, a rede aceita imagens RGBD de pares de faces e imagens de 4 canais e exibe as diferenças entre os dois anexos. A rede aprende com perda significativa, o que minimiza a diferença entre imagens da mesma pessoa e maximiza a diferença entre imagens de rostos diferentes.
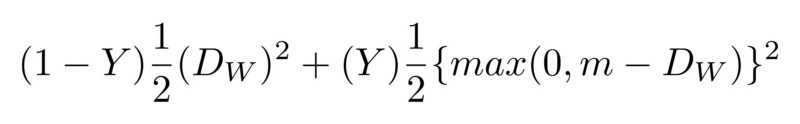
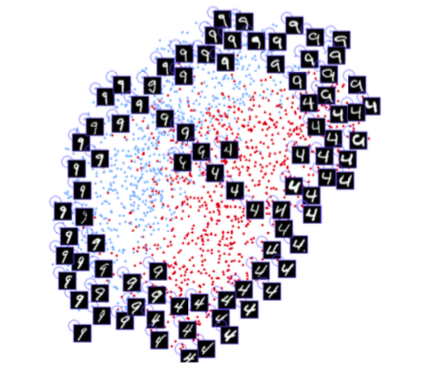
Após o treinamento, a rede pode converter rostos em matrizes de 128 dimensões, para que as fotos da mesma pessoa sejam agrupadas. Isso significa que, para desbloquear o dispositivo, a rede neural simplesmente calcula a diferença entre a imagem necessária durante o desbloqueio e as imagens armazenadas durante a fase de registro. Se a diferença corresponder a um valor específico, o dispositivo será desbloqueado.
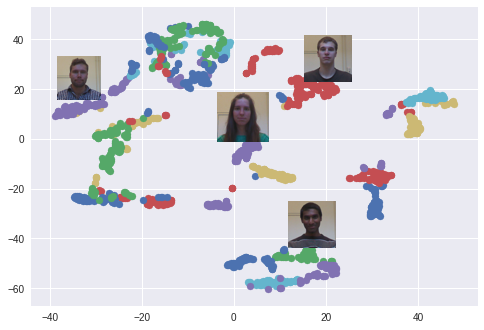
O algoritmo t-SNE é usado. Cada cor corresponde a uma pessoa: como você pode ver, a rede aprendeu a agrupar essas fotos com bastante força. Um gráfico interessante também surge ao usar o algoritmo PCA para reduzir a dimensão dos dados.

Um experimento
Agora vamos tentar ver como esse modelo funciona, simulando um loop FaceID normal. Primeiro, registre a pessoa. Em seguida, desbloqueá-lo-emos em nome do usuário e de outras pessoas que não devem desbloquear o dispositivo. Como mencionado anteriormente, a diferença entre a pessoa que "vê" o telefone e a pessoa registrada tem um certo limite.
Vamos começar com o registro. Tire uma série de fotografias da mesma pessoa do conjunto de dados e simule a fase de registro. Agora, o dispositivo calcula os anexos para cada uma dessas poses e os salva localmente.


Vamos ver o que acontece se o mesmo usuário tentar desbloquear o dispositivo. Diferentes poses e expressões faciais do mesmo usuário alcançam uma baixa diferença, uma média de cerca de 0,30.

Por outro lado, imagens de pessoas diferentes têm uma diferença média de cerca de 1,1.

Portanto, um valor limite de aproximadamente 0,4 deve ser suficiente para impedir que estranhos desbloqueiem o telefone.
Neste post, mostrei como implementar o conceito de teste de mecânica de desbloqueio do FaceID com base na incorporação de faces e redes de convolução siamesas. Espero que a informação tenha sido útil para você. Você pode encontrar
todo o código Python
relativo aqui.
Mais análises de novas tecnologias - no
canal Telegram .
Todo conhecimento!