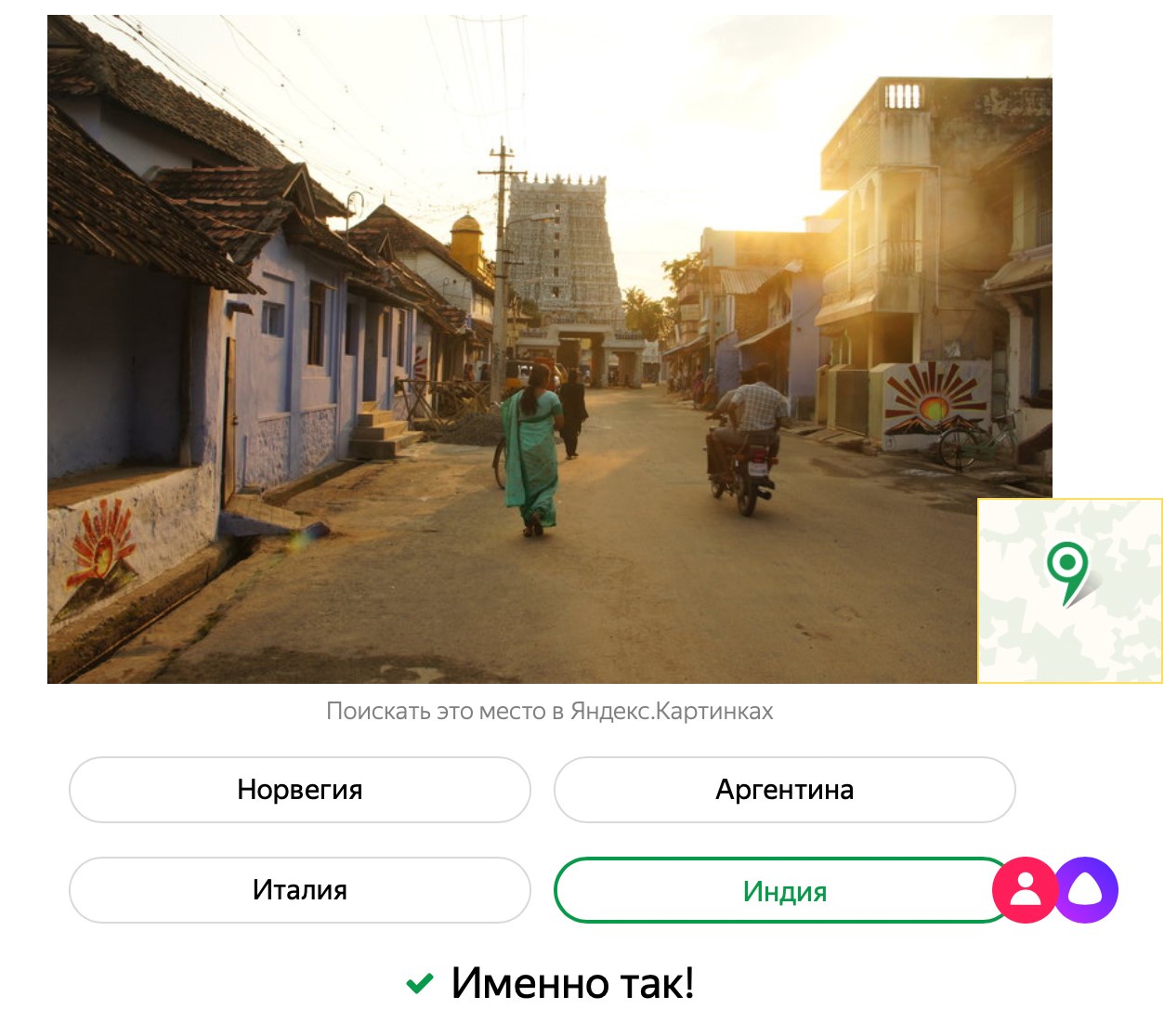
Oi Meu nome é Evgeny Kashin e trabalho no laboratório de inteligência de máquinas Yandex. Recentemente, lançamos um jogo no qual os usuários competem com Alice em países adivinhados a partir de fotografias.
Como as pessoas agem é compreensível: elas reconhecem lugares que viram em viagens ou filmes, confiam na erudição e no senso comum. A rede neural não tem nada disso. Nós nos perguntamos que detalhes nas fotos a levariam a resposta. Realizamos um estudo, cujos resultados compartilharemos hoje com a Habr.
Este post será interessante tanto para especialistas no campo da visão computacional quanto para todos que desejam examinar a "inteligência artificial" e entender a lógica de seu trabalho.

Algumas palavras sobre o jogo "
Adivinhe o país por foto ". Em resumo, tiramos fotos do Yandex.Maps e as dividimos em dois grupos. O primeiro grupo foi mostrado por redes neurais, dizendo onde cada foto foi tirada. Depois de revisar milhares de fotografias, a rede neural fez uma idéia de cada país - isto é, identificou independentemente combinações de sinais pelos quais pode ser reconhecida. Usamos o segundo grupo de fotos no jogo, Alice não as viu e não se lembra delas durante o jogo. Alice joga bem, mas as pessoas têm uma vantagem: não treinamos a rede neural para reconhecer números de máquinas, textos de sinais e sinais, bandeiras de estados.
Para o jogo, treinamos o modelo para prever o país a partir de uma fotografia. Adotamos um modelo de visão computacional
SE-ResNeXt-101 , pré-
treinado em muitas tarefas. Os sinais obtidos da imagem usando essa rede neural convolucional são bastante universais; portanto, para o classificador de país, foi necessário adicionar apenas algumas camadas adicionais (a chamada cabeça). Os dados do Yandex.Mart foram usados para treinamento: aproximadamente 2,5 milhões de fotos. Muitas fotos não se encaixavam no jogo de acordo com o critério de beleza e foram filtradas. A beleza é entendida como uma combinação de fatores: a qualidade da foto, a presença de pessoas, o texto, a floresta, o mar. Fotos semelhantes foram removidas do mesmo local para que o modelo não se lembrasse de vistas específicas. Depois de toda a filtragem, restavam cerca de 1 milhão de fotos. Depois de treinar o modelo nesses dados, obtivemos um classificador bastante preciso, que determina o país apenas por foto, sem usar informações adicionais.
Como a classificação é realizada usando uma rede neural, não podemos obter facilmente uma interpretação das previsões, em contraste com modelos lineares mais simples ou árvores de decisão. Mas queríamos descobrir como uma rede neural determina a partir de uma fotografia regular de uma rua ou de uma casa em que país é. E os casos mais interessantes estão sem atrações no quadro.
Para fazer isso, treinamos a rede neural do zero, alimentando imagens não inteiras, mas apenas pequenos pedaços de colheita (para que o modelo não se lembre de lugares específicos ou objetos grandes).
Assim, a tarefa do modelo tornou-se visivelmente mais difícil (tente adivinhar o país por um pedaço do céu), a precisão do reconhecimento diminuiu bastante. Por outro lado, a rede neural precisava prestar mais atenção aos pequenos detalhes: alvenaria incomum, padrões específicos, tipo de telhado, plantas. O tamanho da colheita aplicada ao modelo mudou e foram obtidos vários modelos que olhavam a foto em diferentes níveis de abstração: quanto menor a colheita, mais difícil a tarefa e mais atento o modelo aos detalhes.

Algoritmos para interpretar previsões podem ser aplicados a modelos que foram treinados em tamanhos de culturas de tamanhos diferentes. Eu gostaria de interpretar as previsões nas fotografias de origem. A maioria das redes de convolução modernas usa o GAP (
Global Average Pooling ) antes da última camada - isso possibilita treinar a rede em um tamanho e aplicá-lo em outro. Isso se deve ao fato de que antes da última camada, os recursos espaciais, distribuídos em largura e altura, são calculados como um número para cada canal (mapa de recursos). Portanto, os modelos treinados no corte (por exemplo, 160 × 160 pixels) podem ser usados nas imagens grandes originais (800 × 800).
De fato, a camada GAP é necessária não apenas para usar o modelo em diferentes resoluções ou para regularização. Também ajuda a rede neural a armazenar informações sobre a posição dos objetos até a última camada (exatamente o que precisamos).
O primeiro método que tentamos é o
mapeamento de ativação de classe (CAM).
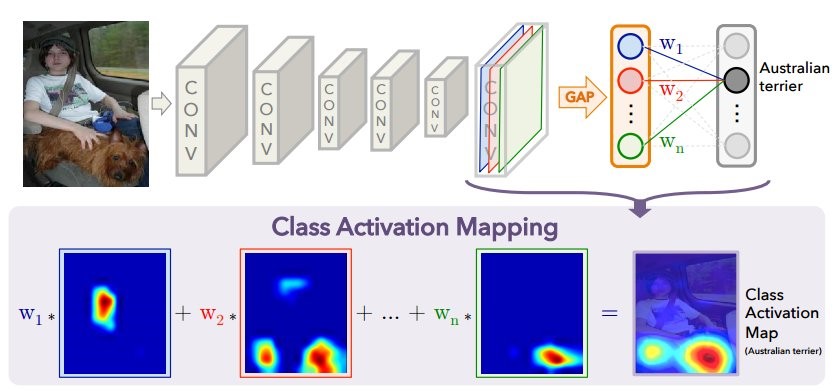
Quando a imagem é inserida na entrada da rede neural, na penúltima camada, uma "imagem" reduzida (na verdade o tensor de ativação) é obtida com os sinais mais importantes para cada classe prevista. Usando o método CAM, você pode alterar as últimas camadas para que a saída seja a probabilidade de cada classe em cada região. Por exemplo, se você deseja prever 60 classes (países), para uma imagem de entrada de 800 × 800, a imagem final consistirá em 60 cartões de ativação com tamanho de 25 × 25. Isso é bem ilustrado na publicação
original .
O diagrama acima mostra o modelo usual com GAP: os recursos espaciais são compactados para um número para cada canal (mapa de recursos), após o qual existe uma camada totalmente conectada que prevê classes que encontram os pesos ideais para cada canal. A seguir, mostramos como alterar a arquitetura para obter o método CAM: a camada GAP é removida e os pesos da última camada totalmente conectada obtida durante o treinamento com GAP (acima no diagrama) são usados para cada canal em cada ponto. Para cada figura, N mapas de ativação são obtidos para todas as classes previstas. Para cada país, quanto mais clara a área no "mapa", maior a contribuição desta seção da imagem para a decisão de escolher um determinado país. O que é interessante: se após esta operação calcularmos a média de cada mapa de ativação (em essência, aplicar o GAP), obteremos apenas a previsão inicial para cada classe.

Na imagem, você vê um mapa de ativação para a classe mais provável (de acordo com o modelo). Foi obtido esticando o mapa de ativação 25 × 25 para o tamanho da imagem original 800 × 800.
Depois de recebermos um mapa para cada imagem, podemos agregar a colheita mais importante para países de diferentes imagens. Isso permite que você veja a coleção de culturas que descreve o país da melhor maneira.
O segundo método, com o qual decidimos comparar o primeiro, é uma pesquisa exaustiva simples. E se pegarmos um modelo treinado em pequenas culturas (por exemplo, 160 × 160 pixels) e prever cada peça em uma imagem grande de 800 × 800 com ela? Passando por uma janela deslizante sobrepondo cada área da imagem, obtemos outra versão do mapa de ativação, mostrando a probabilidade de cada parte da imagem pertencer à classe do país previsto.

A imagem é cortada em pequenas áreas com sobreposição de 160 × 160. Para cada corte, a rede neural faz previsões, o número acima do corte é a probabilidade de pertencer à classe que o modelo finalmente previu.
Como no primeiro método, podemos novamente escolher as peças mais prováveis para cada país. Mas as imagens obtidas pelos dois métodos para o país podem ser uniformes (por exemplo, uma construção de diferentes ângulos ou uma versão da textura). Portanto, a melhor colheita para o país é adicionalmente agrupada - então a maioria das imagens semelhantes será reunida em um agrupamento. Depois disso, será suficiente tirar uma foto de cada cluster com a probabilidade máxima - para cada país, haverá tantas imagens quantas clusters forem especificados. Realizamos clustering com base nas características obtidas na última camada do classificador. Aglomeração aglomerativa no nosso caso provou ser a melhor.

Após receber um pipeline bastante semelhante para os dois métodos, é possível iterar sobre os parâmetros dos algoritmos para encontrar a combinação ideal. Por exemplo, selecionamos o tamanho da colheita e estabelecemos duas opções: 160 e 256 pixels. Culturas menores que 160 deram sinais muito pequenos, segundo os quais uma pessoa geralmente não entende o que é retratado. E a colheita de mais de 256 às vezes continha vários objetos ao mesmo tempo. Vários parâmetros precisam ser selecionados no estágio de agrupamento: a escolha do algoritmo principal, bem como os recursos pelos quais o agrupamento é realizado. Para muitas combinações de parâmetros, ficou imediatamente claro que eles produzem culturas insuficientemente "interessantes". Mas, para selecionar o algoritmo final, realizamos experimentos lado a lado no Tolok para entender qual opção, de acordo com as pessoas, descreve o país específico mais "apropriadamente".
Acabou sendo pouco intuitivo que um método mais simples de encontrar recorte na imagem (pesquisa normal) encontre objetos mais "interessantes". Isso pode ser devido ao fato de que no segundo método (enumeração) a rede neural não vê a parte vizinha da imagem e, no método CAM, o ambiente do ponto afeta o resultado. Como resultado, recebemos uma visualização dos recursos característicos de cada país no modo automático.
Então agora sabemos quais partes do quadro são de importância decisiva para a rede neural e podemos ver o que caiu sobre elas. Por exemplo, a Holanda reconhece uma rede neural pela combinação de paredes de tijolos escuros e contornos de janelas brancas, os Emirados Árabes Unidos - por arranha-céus específicos contra o fundo das palmeiras e o Irã - pelos arcos e ornamentos característicos das fachadas.