Um dos principais problemas no desenvolvimento e operação subseqüente de microsserviços é a configuração competente e precisa de suas instâncias. Na minha opinião, a nova estrutura
microconfig.io pode ajudar. Ele permite resolver de maneira bastante elegante algumas das tarefas rotineiras de configuração de aplicativos.
Se você possui muitos microsserviços e cada um deles possui seus próprios arquivos / configurações, é provável que cometa um erro em um deles, o que sem destreza adequada e sistema de registro pode ser muito difícil de detectar. A principal tarefa que a estrutura define por si mesma é minimizar configurações de instância duplicadas, reduzindo assim a probabilidade de adicionar um erro.
Vejamos um exemplo. Suponha que exista um aplicativo simples com um
arquivo de configuração
yaml . Pode ser qualquer microsserviço em qualquer idioma. Vamos ver como a estrutura pode ser aplicada a este serviço.
Mas primeiro, para maior comodidade, criaremos um projeto vazio no Idea IDE instalando primeiro o plug-in microconfig.io:
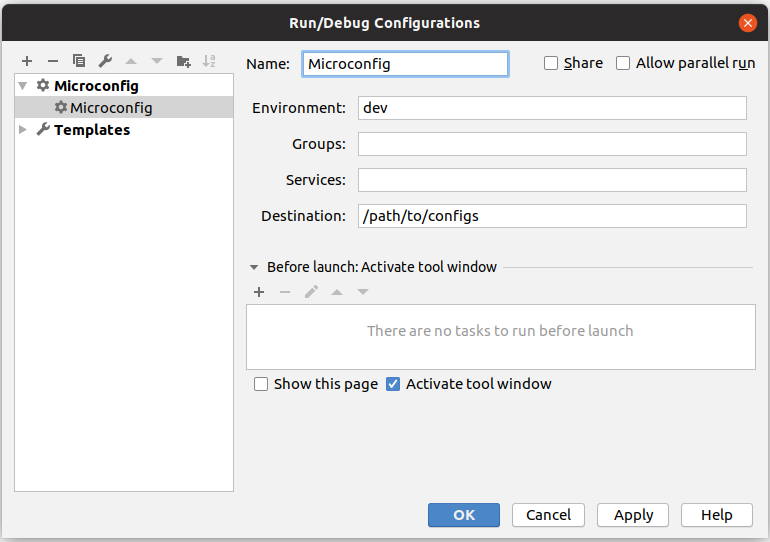
Nós configuramos a configuração de inicialização do plug-in, você pode usar a configuração padrão, como na captura de tela acima.
Nosso serviço é chamado de pedido; em um novo projeto, criaremos uma estrutura semelhante:

Na pasta com o nome do serviço, colocamos o arquivo de configuração -
application.yaml . Todos os microsserviços são lançados em algum tipo de ambiente; portanto, além de criar a configuração do próprio serviço, é necessário descrever o próprio ambiente: para isso, crie a pasta
envs e adicione um arquivo com o nome do nosso ambiente de trabalho. Assim, a estrutura criará arquivos de configuração para serviços no ambiente de desenvolvimento, pois esse parâmetro é definido nas configurações do plug-in.
A estrutura do arquivo
dev.yaml será bastante simples:
mainorder: components: - order
A estrutura trabalha com configurações agrupadas. Para o nosso serviço, selecione um nome para o grupo de
pedidos principais . A estrutura localiza cada grupo de aplicativos no arquivo de ambiente e cria configurações para todos eles nas pastas correspondentes.
No próprio arquivo de configurações do serviço de
pedidos , indicaremos até agora apenas um parâmetro:
spring.application.name: order
Agora execute o plugin e ele irá gerar a configuração desejada do nosso serviço para nós, de acordo com o caminho especificado nas propriedades:
Você pode
fazer sem instalar o plug-in simplesmente baixando o kit de distribuição da estrutura e executando-o na linha de comando.
Esta solução é adequada para uso no servidor de construção.
Vale ressaltar que a estrutura entende perfeitamente a sintaxe da
propriedade , ou seja, os arquivos de propriedades comuns que podem ser usados juntos nas configurações do
yaml .
Adicione mais um serviço de
pagamento e complique o existente ao mesmo tempo.
Em
ordem :
eureka: instance.preferIpAddress: true client: serviceUrl: defaultZone: http://192.89.89.111:6782/eureka/ server.port: 9999 spring.application.name: order db.url: 192.168.0.100
Em
pagamento :
eureka: instance.preferIpAddress: true client: serviceUrl: defaultZone: http://192.89.89.111:6782/eureka/ server.port: 9998 spring.application.name: payments db.url: 192.168.0.100
O principal problema com essas configurações é a presença de uma grande quantidade de pasta de cópia nas configurações de serviço. Vamos ver como a estrutura ajuda a se livrar dela. Vamos começar com o mais óbvio - a presença da configuração
eureka na descrição de cada microsserviço. Crie um novo diretório com o arquivo de configurações e adicione uma nova configuração a ele:

E em cada um de nossos projetos, adicionaremos a linha
#include eureka .
A estrutura encontrará automaticamente a configuração do eureka e a copiará para os arquivos de configuração de serviço, enquanto uma configuração separada do eureka não será criada, pois não a especificaremos no
arquivo de ambiente
dev.yaml .
Ordem de serviço:
#include eureka server.port: 9999 spring.application.name: order db.url: 192.168.0.100
Também podemos fazer as configurações do banco de dados em uma configuração separada, alterando a linha de importação para
#include eureka, oracle .
É importante notar que cada alteração durante a regeneração dos arquivos de configuração que a estrutura monitora e coloca em um arquivo especial ao lado do arquivo de configuração principal. A entrada em seu log é assim: “A propriedade armazenada 1 muda para
order / diff-application.yaml ”. Isso permite detectar rapidamente alterações em grandes arquivos de configuração.
A remoção das partes comuns da configuração permite que você se livre de muitas cópias e colagens desnecessárias, mas não permite que você crie uma configuração flexível para vários ambientes - os pontos de extremidade de nossos serviços são únicos e codificados permanentemente, isso é ruim. Vamos tentar removê-lo.
Uma boa solução seria manter todos os pontos de extremidade em uma configuração que outros pudessem referenciar. Para fazer isso, o suporte para espaços reservados foi introduzido na estrutura. Veja como o arquivo de configuração
eureka muda:
client: serviceUrl: defaultZone: http://${endpoints@eurekaip}:6782/eureka/
Agora vamos ver como esse espaço reservado funciona. O sistema localiza um componente chamado
endpoints e procura por
eurekaip nele e o substitui em nossa configuração. Mas e os diferentes ambientes? Para fazer isso, crie o arquivo de configurações nos
pontos de extremidade do seguinte tipo
application.dev.yaml . A estrutura independentemente, por extensão de arquivo, decide em qual ambiente essa configuração pertence e a carrega:

O conteúdo do arquivo dev:
eurekaip: 192.89.89.111 dbip: 192.168.0.100
Podemos criar a mesma configuração para as portas de nossos serviços:
server.port: ${ports@order}.
Todas as configurações importantes estão em um único local, reduzindo assim a probabilidade de um erro devido aos parâmetros dispersos nos arquivos de configuração.
A estrutura fornece muitos espaços reservados prontos, por exemplo, você pode obter o nome do diretório em que o arquivo de configuração está localizado e atribuí-lo:
#include eureka, oracle server.port: ${ports@order} spring.application.name: ${this@name}
Devido a isso, não há necessidade de especificar adicionalmente o nome do aplicativo na configuração e também pode ser movido para um módulo comum, por exemplo, para o mesmo eureka:
client: serviceUrl: defaultZone: http://${endpoints@eurekaip}:6782/eureka/ spring.application.name: ${this@name}
O arquivo de configuração do
pedido será reduzido para uma linha:
#include eureka, oracle server.port: ${ports@order}
Caso não precisemos de nenhuma configuração da configuração pai, podemos especificá-la em nossa configuração e ela será aplicada durante a geração. Ou seja, se por algum motivo precisarmos de um nome exclusivo para o serviço de pedidos, deixe o parâmetro
spring.application.name .
Digamos que você precise adicionar configurações de log personalizadas ao serviço, que são armazenadas em um arquivo separado, por exemplo,
logback.xml . Crie um grupo separado de configurações para ele:

Na configuração básica, indicaremos a estrutura onde colocar o arquivo de configurações de log necessário, usando o
espaço reservado @ConfigDir:
microconfig.template.logback.fromFile: ${logback@configDir}/logback.xml
No arquivo
logback.xml , configuramos
anexos padrão, que por sua vez também podem conter espaços reservados, que a estrutura mudará durante a geração de configurações, por exemplo:
<file>logs/${this@name}.log</file>
Adicionando a importação de
logback na configuração do serviço, obtemos automaticamente o log configurado para cada serviço:
#include eureka, oracle, logback server.port: ${ports@order}
É hora de se familiarizar com todos os espaços reservados da estrutura disponíveis em mais detalhes:
$ {this @ env} - retorna o nome do ambiente atual.
$ {... @ name} - retorna o nome do componente.
$ {... @ configDir} - retorna o caminho completo para o diretório de configuração do componente.
$ {... @ resultDir} - retorna o caminho completo para o diretório de destino do componente (os arquivos recebidos serão colocados nesse diretório).
$ {this @ configRoot} - retorna o caminho completo para o diretório raiz do armazenamento de configuração.
O sistema também permite obter variáveis de ambiente, por exemplo, o caminho para java:
$ {env @ JAVA_HOME}Ou, como a estrutura é escrita em
JAVA , podemos obter variáveis do sistema semelhantes à chamada
System :: getProperty usando uma construção como esta:
${system@os.name}Vale mencionar o suporte ao idioma de extensão
Spring EL . Na configuração, expressões semelhantes se aplicam:
connection.timeoutInMs: #{5 * 60 * 1000} datasource.maximum-pool-size: #{${this@datasource.minimum-pool-size} + 10}
e você pode usar variáveis locais em arquivos de configuração usando a expressão
#var :
#var feedRoot: ${system@user.home}/feed folder: root: ${this@feedRoot} success: ${this@feedRoot}/archive error: ${this@feedRoot}/error
Assim, a estrutura é uma ferramenta bastante poderosa para a configuração fina e flexível de microsserviços. A estrutura executa perfeitamente sua principal tarefa - eliminar copiar e colar nas configurações, consolidar as configurações e, como resultado, minimizar possíveis erros, além de facilitar a combinação de configurações e alterações para diferentes ambientes.
Se você estiver interessado nessa estrutura, recomendo que você visite sua página oficial e leia a
documentação completa ou procure a fonte
aqui .