Recentemente, encontrei mais e mais informações sobre a
estrutura de aprendizado de máquina Ml.NET . O número de referências a ele se transformou em qualidade, e eu decidi olhar pelo menos com uma espiada de relance que tipo de animal era.
Anteriormente, tentamos resolver o problema mais simples de previsão usando regressão linear no ecossistema .NET. Para isso, usamos o Accord.NET Framework. Para esses fins, um pequeno conjunto de dados foi preparado a
partir de dados abertos sobre apelos dos cidadãos às autoridades executivas e pessoalmente
ao prefeito de Moscou .
Depois de alguns anos em
um conjunto de dados atualizado, tentaremos resolver o
problema mais simples . Usando o modelo de regressão no Ml.NET Framework, prevemos quantas solicitações por mês obtêm uma solução positiva. Ao longo do caminho, compararemos o Ml.NET com o Accord. Bibliotecas NET e Python.
Deseja dominar a força e o poder do preditor? Então você é bem-vindo sob gato.
PS Let S.S. Sobyanin, o artigo não dirá uma palavra sobre política.Conteúdo:
Parte I: introdução e um pouco sobre dadosParte II: escrevendo código C #Parte III: ConclusãoPenso que é necessário avisar imediatamente que não sou profissional em análise e programação de dados em geral, nem estou envolvido com a Prefeitura de Moscou. Portanto, o artigo é mais provável de um iniciante para um iniciante. Mas, apesar do meu conhecimento limitado, espero que o artigo seja útil para você.As pessoas que já estão familiarizadas com artigos anteriores do ciclo podem se lembrar de que já tentamos resolver o problema de prever o número de questões resolvidas positivamente a partir dos apelos dos cidadãos endereçados ao ramo executivo de Moscou. Para isso, usamos o
Python e o
Accord.Net Framework .
Outros artigos do ciclo1. Aprenda o básico:
2. Nós praticamos as primeiras habilidades
De qualquer forma, não será supérfluo analisar o conjunto de dados usado novamente.
Todos os materiais do artigo, incluindo o código e o conjunto de dados, estão
disponíveis gratuitamente no GitHub .
Os dados no GitHub são apresentados no formato csv, contêm 44 entradas e, em princípio, eles podem (e devem) ser usados não apenas para a análise do exemplo.
Colunas de dados significam o seguinte:
- num - índice de registros
- ano - ano de registro
- mês - mês de gravação
- total_appeals - número total de ocorrências por mês
- appeals_to_mayor - número total de recursos para o prefeito
- res_positive- número de decisões positivas
- res_explained - número de chamadas para esclarecimentos
- res_negative - número de chamadas com uma decisão negativa
- El_form_to_mayor - o número de apelações ao prefeito em formato eletrônico
- Pap_form_to_mayor - o número de apelações ao prefeito no papel to_10K_total_VAO ... to_10K_total_YUZAO - o número de apelações por 10.000 habitantes em vários distritos de Moscou
- to_10K_mayor_VAO ... to_10K_mayor_YUZAO - o número de apelações dirigidas ao prefeito e ao governo de Moscou por 10.000 habitantes em vários distritos da cidade
Não encontrei uma maneira de automatizar o processo de coleta de dados e os coletei manualmente, para que eu pudesse me enganar um pouco. Caso contrário, a confiabilidade dos dados será deixada à consciência dos autores.
Atualmente, os dados no site do governo em Moscou são apresentados na íntegra de janeiro de 2016 a agosto de 2019 (alguns dados estão ausentes em setembro). Assim, teremos 44 entradas. Um pouco, é claro, mas para demonstração para nós isso será suficiente.
Antes de começar, apenas algumas palavras sobre o herói do nosso artigo.
ML.NET Framework - desenvolvimento de código aberto da Microsoft. De acordo com a publicidade em mídias sociais, esta é a resposta para as bibliotecas de aprendizado de máquina Python. A estrutura é multiplataforma e permite resolver uma grande variedade de tarefas, desde regressão e classificação simples até aprendizado profundo. No Habr, os camaradas já realizavam a análise do ML.NET e das bibliotecas em Python. Quem se importa, aqui está o
link .
Não darei um guia detalhado sobre a instalação e o uso do Ml.NET porque, em essência, tudo foi
roubado "adaptado" com base em um
livro do site oficial da Microsoft .
Lá, o problema com os preços de uma viagem de táxi foi resolvido e, para ser sincero, há mais benefíciosMas acho que as pequenas explicações não serão supérfluas.
Usei o Visual Studio 2017 com as atualizações mais recentes.
O projeto foi baseado no modelo de aplicativo de console do .NET Core (versão 2.1).
O projeto teve que instalar os pacotes NuGet Microsoft.ML, Microsoft.ML.FastTree. Essa é, de fato, toda a preparação.
Prosseguimos diretamente para o código.
Primeiro, criei a classe MayorAppel, na qual descrevi em ordem as colunas com dados dos arquivos csv.
Não é difícil adivinhar [LoadColumn (0)]
- nos diz qual coluna do arquivo csv usamos.
Em seguida, seguindo o tutorial, criei a classe MayorAppelPrediction - para obter resultados de previsão
Apesar de quase todas as colunas no conjunto de dados terem valores inteiros, para evitar erros no momento de colar dados no pipeline, tive que atribuir a eles um tipo de flutuação (para que todos os tipos de dados sejam iguais).
A lista é grande o suficiente, então coloque-a sob o spoiler.
Código de classe para descrição dos dadosusing Microsoft.ML.Data; namespace app_to_mayor_mlnet { class MayorAppel { [LoadColumn(0)] public float Year; [LoadColumn(1)] public string Month; [LoadColumn(2)] public float TotalAppeals; [LoadColumn(3)] public float AppealsToMayor; [LoadColumn(4)] public float ResPositive; [LoadColumn(5)] public float ResExplained; [LoadColumn(6)] public float ResNegative; [LoadColumn(7)] public float ElFormToMayor; [LoadColumn(8)] public float PapFormToMayor; [LoadColumn(9)] public float To10KTotalVAO; [LoadColumn(10)] public float To10KMayorVAO; [LoadColumn(11)] public float To10KTotalZAO; [LoadColumn(12)] public float To10KMayorZAO; [LoadColumn(13)] public float To10KTotalZelAO; [LoadColumn(14)] public float To10KMayorZelAO; [LoadColumn(6)] public float To10KTotalSAO; [LoadColumn(15)] public float To10KMayorSAO; [LoadColumn(16)] public float To10KTotalSVAO; [LoadColumn(17)] public float To10KMayorSVAO; [LoadColumn(18)] public float To10KTotalSZAO; [LoadColumn(19)] public float To10KMayorSZAO; [LoadColumn(20)] public float To10KTotalTiNAO; [LoadColumn(21)] public float To10KMayorTiNAO; [LoadColumn(22)] public float To10KTotalCAO; [LoadColumn(23)] public float To10KMayorCAO; [LoadColumn(24)] public float To10KTotalYUAO; [LoadColumn(25)] public float To10KMayorYUAO; [LoadColumn(26)] public float To10KTotalYUVAO; [LoadColumn(27)] public float To10KMayorYUVAO; [LoadColumn(28)] public float To10KTotalYUZAO; [LoadColumn(29)] public float To10KMayorYUZAO; } public class MayorAppelPrediction { [ColumnName("Score")] public float ResPositive; } }
Vamos passar para o código principal do programa.
Não se esqueça de adicionar desde o início:
using System.IO; using Microsoft.ML;
A seguir, é apresentada uma descrição dos campos de dados.
namespace app_to_mayor_mlnet { class Program { static readonly string _trainDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "train_data.csv"); static readonly string _testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "test_data.csv"); static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "Model.zip");
Nesses campos, de fato, os caminhos para os arquivos de dados são armazenados; dessa vez, decidi separá-los com antecedência (diferente do caso do Accord.NET)
A propósito, se você estiver executando seu projeto, não se esqueça de definir a opção “Copiar versão posterior” nas propriedades dos arquivos de dados para evitar um erro devido à falta de arquivos de montagem.
Em seguida, vem o desafio dos métodos que formam o modelo, conduzem sua avaliação e nos dão uma previsão.
static void Main(string[] args) { MLContext mlContext = new MLContext(seed: 0); var model = Train(mlContext, _trainDataPath); Evaluate(mlContext, model); TestSinglePrediction(mlContext, model); }
Vamos em ordem
O método Train é necessário para treinar o modelo.
public static ITransformer Train(MLContext mlContext, string dataPath) { IDataView dataView = mlContext.Data.LoadFromTextFile<MayorAppel>(dataPath, hasHeader: true, separatorChar: ','); var pipeline = mlContext.Transforms.CopyColumns(outputColumnName: "Label", inputColumnName: "ResPositive") .Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "MonthEncoded", inputColumnName: "Month")) .Append(mlContext.Transforms.Concatenate("Features", "Year", "MonthEncoded", "TotalAppeals", "AppealsToMayor", "ResExplained", "ResNegative", "ElFormToMayor", "PapFormToMayor", "To10KTotalVAO", "To10KMayorVAO", "To10KTotalZAO", "To10KMayorZAO", "To10KTotalZelAO", "To10KMayorZelAO", "To10KTotalSAO", "To10KMayorSAO" , "To10KTotalSVAO", "To10KMayorSVAO", "To10KTotalSZAO", "To10KMayorSZAO", "To10KTotalTiNAO", "To10KMayorTiNAO" , "To10KTotalCAO", "To10KMayorCAO", "To10KTotalYUAO", "To10KMayorYUAO", "To10KTotalYUVAO", "To10KMayorYUVAO" , "To10KTotalYUZAO", "To10KMayorYUZAO")).Append(mlContext.Regression.Trainers.FastTree()); var model = pipeline.Fit(dataView); return model; }
No início, lemos os dados da amostra de treinamento. Então, na cadeia, determinamos o parâmetro que irá prever (rótulo).
No nosso caso, esse é o número de problemas resolvidos com sucesso em relação aos apelos dos cidadãos por mês.
Como neste caso o modelo de aumento de árvores de decisão com base na regressão é usado, precisamos trazer todos os sinais para valores numéricos.
Diferente do caso do Accord.NET, a solução OneHotEncoding pronta para uso é apresentada imediatamente aqui na documentação.
Depois de formar as colunas, como eu disse acima, todas elas devem ser do mesmo tipo de dados, neste caso, um float.
Em conclusão, formamos e retornamos o modelo acabado.
Em seguida, avaliamos a qualidade da previsão pelo nosso modelo.
private static void Evaluate(MLContext mlContext, ITransformer model) { IDataView dataView = mlContext.Data.LoadFromTextFile<MayorAppel>(_testDataPath, hasHeader: true, separatorChar: ','); var predictions = model.Transform(dataView); var metrics = mlContext.Regression.Evaluate(predictions, "Label", "Score"); Console.WriteLine(); Console.WriteLine($"*************************************************"); Console.WriteLine($"* Model quality metrics evaluation "); Console.WriteLine($"*------------------------------------------------"); Console.WriteLine($"* RSquared Score: {metrics.RSquared:0.##}"); Console.WriteLine($"* Root Mean Squared Error: {metrics.RootMeanSquaredError:#.##}"); }
Carregamos nossa amostra de teste (nos últimos 4 meses do conjunto), obtemos a previsão de nossos dados de teste no modelo treinado usando o método Transform (). Depois calculamos as métricas e as imprimimos. Nesse caso, é o coeficiente de determinação e desvio padrão. O primeiro idealmente deve tender a 1, e o segundo essencialmente a zero.
Em princípio, para fazer uma previsão, não precisamos desse método, mas é bom entender o quanto nosso modelo prevê alguma coisa.
O último método permanece - a própria previsão.
Também vamos escondê-lo sob o spoiler.
método de previsão e dados private static void TestSinglePrediction(MLContext mlContext, ITransformer model) { var predictionFunction = mlContext.Model.CreatePredictionEngine<MayorAppel, MayorAppelPrediction>(model); var MayorAppelSampleMinData = new MayorAppel() { Year = 2019, Month = "August", ResPositive = 0 }; var MayorAppelSampleMediumData = new MayorAppel() { Year = 2019, Month = "August", TotalAppeals = 111340, AppealsToMayor = 17932, ResExplained = 66858, ResNegative = 8945, ElFormToMayor = 14931, PapFormToMayor = 2967, ResPositive = 0 }; var MayorAppelSampleMaxData = new MayorAppel() { Year = 2019, Month = "August", TotalAppeals = 111340, AppealsToMayor = 17932, ResExplained = 66858, ResNegative = 8945, ElFormToMayor = 14931, PapFormToMayor = 2967, To10KTotalVAO = 67, To10KMayorVAO = 13, To10KTotalZAO = 57, To10KMayorZAO = 13, To10KTotalZelAO = 49, To10KMayorZelAO = 9, To10KTotalSAO = 71, To10KMayorSAO = 14, To10KTotalSVAO = 86, To10KMayorSVAO = 27, To10KTotalSZAO = 68, To10KMayorSZAO = 12, To10KTotalTiNAO = 93, To10KMayorTiNAO = 36, To10KTotalCAO = 104, To10KMayorCAO = 24, To10KTotalYUAO = 56, To10KMayorYUAO = 12, To10KTotalYUVAO = 59, To10KMayorYUVAO = 13, To10KTotalYUZAO = 78, To10KMayorYUZAO = 23, ResPositive = 0 }; var predictionMin = predictionFunction.Predict(MayorAppelSampleMinData); var predictionMed = predictionFunction.Predict(MayorAppelSampleMediumData); var predictionMax = predictionFunction.Predict(MayorAppelSampleMaxData); Console.WriteLine($"**********************************************************************"); Console.WriteLine($"Prediction for August 2019"); Console.WriteLine($"Predicted Positive decisions (Minimum Features): {predictionMin.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"Predicted Positive decisions (Medium Features: {predictionMed.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"Predicted Positive decisions (Maximum Features): {predictionMax.ResPositive:0.####}, actual res_positive : 22313"); Console.WriteLine($"**********************************************************************"); }
No exemplo, usamos a classe PredictionEngine, que permite obter uma única previsão com base no modelo treinado e no conjunto de dados de teste.
Criaremos três "probes" com dados para previsão.
O primeiro com um conjunto mínimo de dados (apenas um mês e um ano), o segundo com uma média e o terceiro com um conjunto completo de atributos - respectivamente.
Temos três previsões diferentes e as imprimimos.
Como você pode ver na captura de tela (Windows 10 x64), adicionar dados sobre o número de chamadas por 10.000 residentes nos distritos, neste caso, estraga tudo, mas adicionar o restante dos dados dá um pequeno aumento à precisão da previsão.
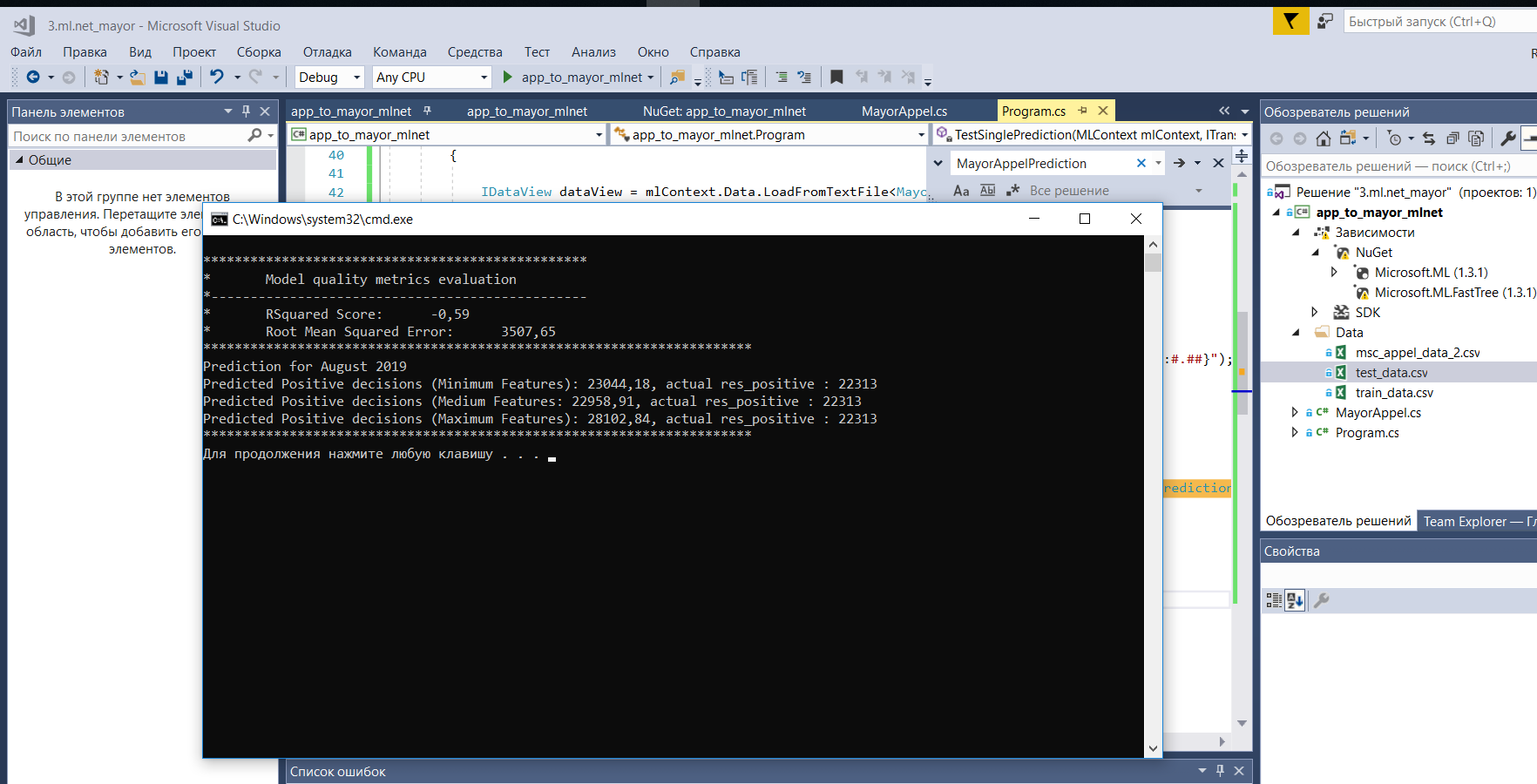
No Linux, o Mint 19 também compila maravilhosamente em Mono.
Acontece que a estrutura é bastante multiplataforma.
Em conclusão, como prometido, darei uma pequena análise comparativa subjetiva do ML.NET com as bibliotecas de aprendizado de máquina Accord.NET e Python.
1. Considera-se que os desenvolvedores estão tentando cumprir as tendências no campo do aprendizado de máquina. Obviamente, no
Python com várias bibliotecas instaladas no Anaconda, essa tarefa pode ser resolvida de forma mais compacta e gastar menos tempo no desenvolvimento. Mas, em geral, parece-me que a abordagem para resolver problemas com o ML.NET é amigável para as pessoas que estão acostumadas a resolver problemas de aprendizado de máquina usando Python.
2. Comparado com o
Accord.NET Framework , o ML.NET parece mais conveniente e promissor para quem tentou o aprendizado de máquina em Python. Lembro-me de que, quando tentei escrever algo no Accord.NET há dois anos, faltava muito explicações e exemplos para algumas classes e métodos. Nesse sentido, o Ml.NET com documentação está se saindo um pouco melhor, apesar do quadro ser muito mais novo que o Accord.NET. Outro fator importante é que o ML.NET, a julgar pela atividade no GitHub, está se desenvolvendo muito mais intensamente que o Accord.NET e possui mais materiais de treinamento no idioma russo.
Como resultado, à primeira vista, o ML.NET parece uma ferramenta conveniente que
complementa o seu arsenal se não for possível usar o Python ou o R (por exemplo, ao trabalhar com APIs de CAD executadas no .NET).
Tenham uma boa semana de trabalho!