
Oi Meu nome é Askhat Nuryev, sou engenheiro de automação líder no DINS.
Trabalho na Dino Systems há 7 anos. Durante esse período, tive que lidar com várias tarefas: desde a criação de testes funcionais automatizados até o desempenho do teste e a alta disponibilidade. Gradualmente, me envolvi mais na organização de testes e otimização de processos em geral.
Neste artigo vou dizer:
- E se os erros já vazaram para a produção?
- Como competir pela qualidade do sistema, se você não pode contar os erros com as mãos e não reconsiderar os olhos?
- Quais são as armadilhas no tratamento automático de erros?
- Quais bônus posso obter ao analisar as estatísticas da consulta?
O DINS é o centro de desenvolvimento do RingCentral, líder de mercado entre os provedores de nuvem das Comunicações Unificadas. O Ringentral fornece tudo para comunicações comerciais, desde telefonia clássica, SMS, reuniões até a funcionalidade de centros de contato e produtos para um trabalho em equipe complexo (à la Slack). Essa solução em nuvem está localizada em seus próprios datacenters e o cliente precisa apenas se inscrever no site.
O sistema, no desenvolvimento do qual participamos, atende a 2 milhões de usuários ativos e processa mais de 275 milhões de solicitações por dia. A equipe na qual estou trabalhando está desenvolvendo a API.
O sistema possui uma API bastante complicada. Com ele, você pode enviar SMS, fazer chamadas, coletar videoconferências, configurar contas e até mesmo enviar faxes (Olá, 2019). De uma forma simplificada, o esquema de interação de serviços se parece com isso. Eu não estou brincando.

É claro que um sistema tão complexo e altamente carregado cria um grande número de erros. Por exemplo, há um ano, recebemos dezenas de milhares de erros por semana. Esses são milésimos de um por cento em relação ao número total de solicitações, mas ainda assim muitos erros são uma bagunça. Nós os capturamos graças ao serviço de suporte desenvolvido, no entanto, esses erros afetam os usuários. Além disso, o sistema está em constante evolução, o número de clientes está crescendo. E o número de erros também.
Primeiro, tentamos resolver o problema de maneira clássica.
Reunimos, solicitamos logs da produção, corrigimos algo, esquecemos algo, criamos painéis em Kibana e Sumologic. Mas no geral não ajudou. Os erros vazavam de qualquer maneira, os usuários reclamavam. Ficou claro que algo estava errado.
Automação
Obviamente, começamos a entender e vimos que 90% do tempo gasto na correção do erro é gasto na coleta de informações. Aqui está o que exatamente:
- Obtenha as informações ausentes de outros departamentos.
- Examine os logs do servidor.
- Investigue o comportamento do nosso sistema.
- Entenda se esse ou aquele comportamento do sistema está incorreto.
E apenas os 10% restantes gastamos diretamente no desenvolvimento.
Pensamos - mas e se criarmos um sistema que encontre erros, os priorize e mostre todos os dados necessários para corrigi-lo?
Devo dizer que a própria idéia de um serviço desse tipo causou algumas preocupações.
Alguém disse: "Se encontrarmos todos os erros, então por que precisamos do controle de qualidade?"
Outros disseram o contrário: "Você se afogará nesta pilha de insetos!".
Em uma palavra, valia a pena prestar um serviço apenas para entender qual deles estava certo.
spoiler(ambos os grupos de céticos estavam enganados)
Soluções prontas
Antes de tudo, decidimos ver quais sistemas semelhantes já estão no mercado. Descobriu-se que existem muitos deles. Você pode destacar Raygun, Sentry, Airbrake, existem outros serviços.
Mas nenhum deles nos convinha, e aqui está o porquê:
- Alguns serviços exigiram que fizéssemos alterações muito grandes na infraestrutura existente, incluindo alterações no servidor. O Airbrake.io precisaria refinar dezenas, centenas de componentes do sistema.
- Outros coletaram dados sobre nossos próprios erros e os enviaram para algum lugar ao lado. Nossa política de segurança não permite isso - os dados de usuário e erro devem permanecer conosco.
- Bem, eles também são muito caros.
Nós fazemos o nosso
Tornou-se óbvio que deveríamos prestar nosso serviço, principalmente porque já construímos uma infraestrutura muito boa para ele:
- Todos os serviços já gravaram logs em um único repositório - Elastic. Nos logs, foram identificados identificadores uniformes de solicitações em todos os serviços.
- As estatísticas de desempenho foram registradas adicionalmente no Hadoop. Trabalhamos com logs usando Impala e Metabase.
De todos os erros do servidor (de
acordo com a classificação dos códigos de status HTTP ), o código 500 é o mais promissor em termos de análise de erros. Em resposta aos erros 502, 503 e 504, em alguns casos, você pode simplesmente repetir a solicitação após algum tempo, sem mostrar a resposta ao usuário. E de acordo com as recomendações da API da plataforma RC, os usuários devem entrar em contato com o suporte se receberem o código de status 500 em resposta a uma chamada.
A primeira versão do sistema coletou logs de execução de consultas, todos os rastreamentos de pilha que surgiram, dados do usuário e colocaram o bug no rastreador; no nosso caso, foi o JIRA.
Logo após a execução do teste, percebemos que o sistema cria um número significativo de erros duplicados. No entanto, entre essas duplicatas, muitas tinham quase os mesmos rastreamentos de pilha.
Foi necessário alterar o método para identificar os mesmos erros. Da análise de dados puramente estatísticos, prossiga para encontrar a causa raiz do erro. Os rastreamentos de pilha caracterizam bem o problema, mas são bastante difíceis de comparar entre si - o número de linhas muda de versão para versão, os dados do usuário e outros ruídos entram neles. Além disso, eles nem sempre entram no log - para alguns pedidos descartados, eles simplesmente não existem.
Em sua forma mais pura, os rastreamentos de pilha são inconvenientes para o rastreamento de erros.
Era necessário selecionar padrões, modelos de rastreios de pilha e limpá-los de informações que frequentemente mudavam. Após uma série de experimentos, decidimos usar expressões regulares para limpar os dados.
Como resultado, lançamos uma nova versão, nela os erros foram identificados por esses modelos exclusivos, se rastreamentos de pilha estivessem disponíveis. E se eles não estavam disponíveis, à moda antiga, pelo método http e pelo grupo API.
E depois disso praticamente não havia duplicatas. No entanto, muitos erros exclusivos foram encontrados.
O próximo passo é entender como priorizar os erros, quais deles precisam ser corrigidos anteriormente. Priorizamos por:
- A frequência do erro.
- O número de usuários que ela está preocupada.
Com base nas estatísticas coletadas, começamos a publicar relatórios semanais. Eles se parecem com isso:
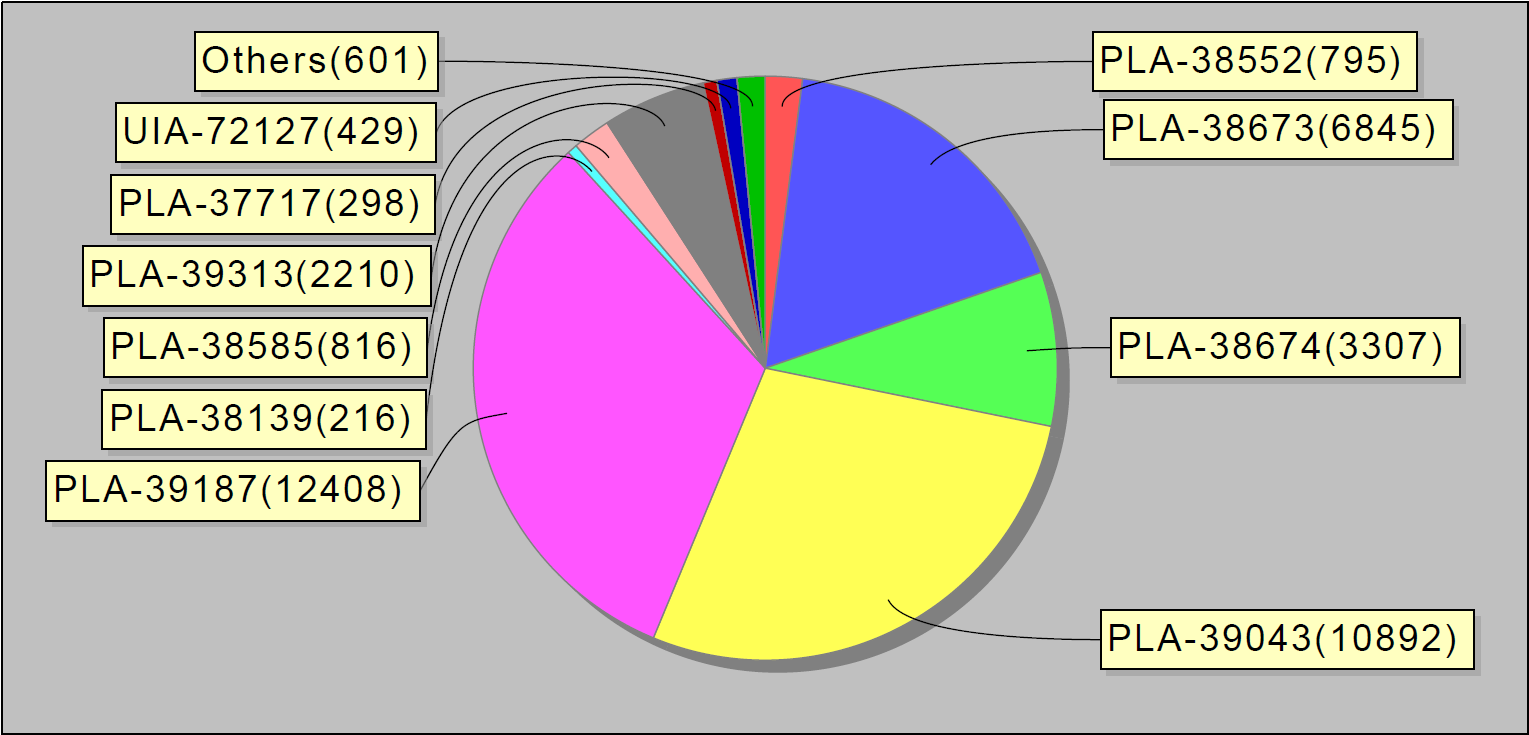
Ou, por exemplo, os 10 principais erros por semana. Curiosamente, esses 10 erros no jira foram responsáveis por 90% dos erros de serviço:
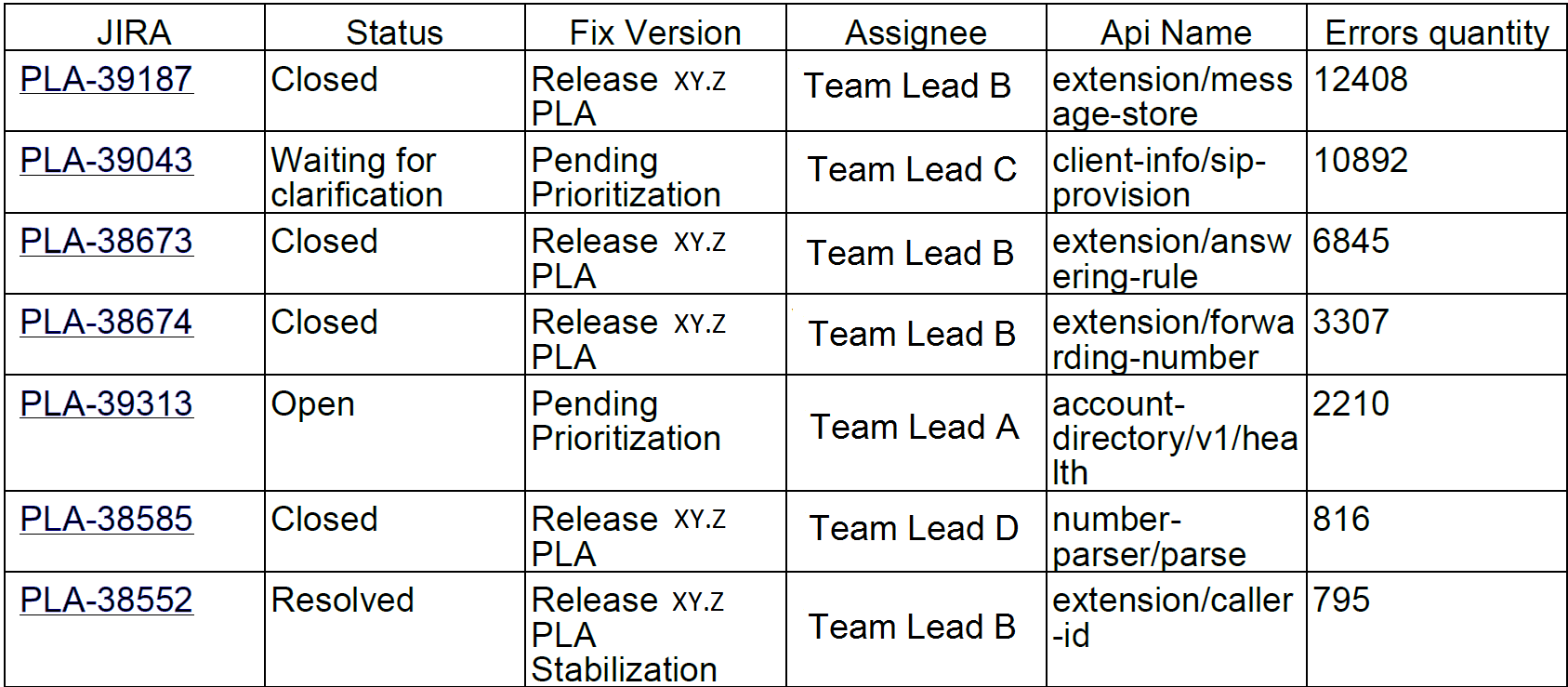
Enviamos esses relatórios para desenvolvedores e líderes de equipe.
Alguns meses após o lançamento do sistema, o número de problemas tornou-se notavelmente menor. Até nosso pequeno MVP (produto minimamente viável) ajudou a resolver melhor os erros.
O problema
Talvez parássemos por aqui, se não fosse por um acidente.
Uma vez, cheguei ao trabalho e notei que o sistema rebenta bugs como bolos quentes: um por um. Após uma breve investigação, ficou claro que dezenas desses erros vieram de um serviço. Para descobrir qual é o problema, fui à sala de bate-papo da equipe de implantação. Havia pessoas envolvidas na instalação de novas versões de serviços na produção e na garantia de que funcionassem conforme o esperado.
Eu perguntei: "Gente, o que aconteceu com este serviço?".
E eles respondem: "Há uma hora, instalamos uma nova versão lá".
Passo a passo, identificamos o problema e encontramos uma solução temporária, ou seja, reiniciamos o servidor.
Ficou claro que o sistema "errado" é necessário não apenas pelos desenvolvedores e engenheiros responsáveis pela qualidade. Os engenheiros responsáveis pelo estado dos servidores em produção, bem como os funcionários que instalam novas versões nos servidores, também estão interessados. O serviço que estamos desenvolvendo mostrará exatamente quais erros ocorrem na produção durante as alterações do sistema, como instalar servidores, aplicar uma nova configuração e assim por diante.
E decidimos fazer outra iteração de desenvolvimento.
No processo de tratamento de erros, adicionamos um registro de estatísticas de reprodução de problemas ao banco de dados e painéis no Grafana. É assim que a distribuição gráfica de erros por dia em todo o sistema se parece:

E assim - erros em serviços individuais.

Também parafusamos gatilhos com escalações para as equipes de engenharia responsáveis - caso haja muitos erros. Também configuramos a coleta de dados uma vez a cada 30 minutos (em vez de uma vez por dia, como antes).
O processo do nosso sistema começou a ficar assim:
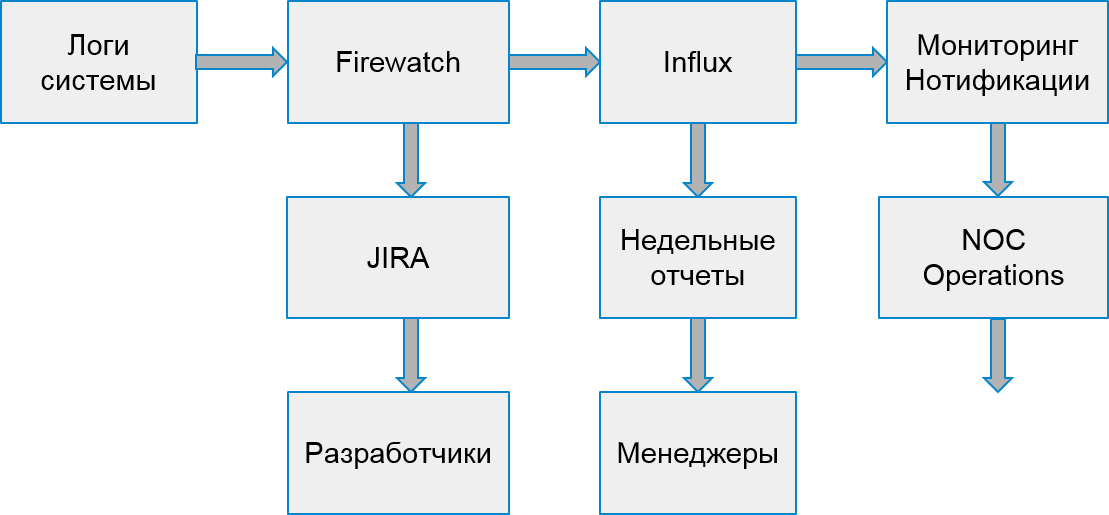
Erros do cliente
No entanto, os usuários sofreram não apenas com erros no servidor. Também ocorreu que o erro ocorreu devido à implementação de aplicativos clientes.
Para lidar com erros do cliente, decidimos criar outro processo de pesquisa e análise. Para fazer isso, escolhemos dois tipos de erros que afetam as empresas: erros de autorização e erros de limitação.
A limitação é uma maneira de proteger o sistema contra sobrecarga. Se o aplicativo ou usuário exceder sua cota de solicitações, o sistema retornará um código de erro 429 e um cabeçalho Retry-After, o valor do cabeçalho indicará o tempo após o qual a solicitação deve ser repetida para uma execução bem-sucedida.
Os aplicativos podem permanecer limitados indefinidamente se parar de enviar novas solicitações. Os usuários finais não podem distinguir esses erros dos outros. Como resultado, isso causa reclamações ao serviço de suporte.
Felizmente, o sistema de infraestrutura e estatística possibilita rastrear até mesmo os erros do cliente. Podemos fazer isso porque os desenvolvedores de aplicativos que usam nossa API devem pré-registrar e receber sua chave exclusiva. Cada solicitação do cliente deve conter um token de autorização, caso contrário, o cliente receberá um erro. Usando esse token, calculamos o aplicativo.
É assim que parece o monitoramento de erros de limitação. Os picos de erros correspondem aos dias da semana e nos fins de semana - pelo contrário, não há erros:

Da mesma forma que no caso de erros internos, com base nas estatísticas do Hadoop, encontramos aplicativos suspeitos. Primeiro, em relação ao número de solicitações bem-sucedidas ao número de solicitações concluídas com o código 429. Se recebemos mais da metade dessas solicitações, pensamos que o aplicativo não estava funcionando corretamente.
Mais tarde, começamos a analisar o comportamento de aplicativos individuais com usuários específicos. Entre os aplicativos suspeitos, encontramos o dispositivo específico no qual o aplicativo está sendo executado e observamos com que frequência ele executa solicitações após receber o primeiro erro de limitação. Se a frequência da solicitação não diminuir, o aplicativo não tratará o erro conforme o esperado.
Parte das aplicações foi desenvolvida em nossa empresa. Portanto, conseguimos localizar imediatamente engenheiros responsáveis e corrigir erros rapidamente. E decidimos enviar os erros restantes para uma equipe que contatou desenvolvedores externos e os ajudou a corrigir seu aplicativo.
Para cada aplicativo, nós:
- Criamos uma tarefa no JIRA.
- Registramos estatísticas no Influx.
- Estamos preparando gatilhos para intervenção cirúrgica no caso de um aumento acentuado no número de erros.
O sistema para trabalhar com erros do cliente tem a seguinte aparência:
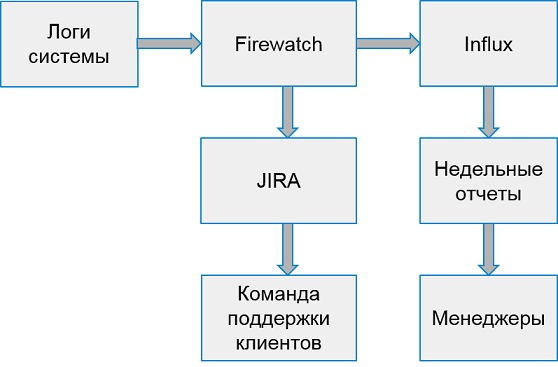
Uma vez por semana, coletamos relatórios das 10 piores aplicações pelo número de erros.
Não pegue, mas avise
Então, aprendemos como encontrar erros no sistema de produção, aprendemos a trabalhar com os erros do servidor e do cliente. Tudo parece estar bem, mas ...
Mas, de fato, respondemos tarde demais - os bugs já afetam os usuários!
Por que não tentar encontrar erros mais cedo?
Obviamente, seria legal encontrar tudo em ambientes de teste. Mas os ambientes de teste são espaços de ruído branco. Eles estão em desenvolvimento ativo, todos os dias várias versões diferentes de servidores funcionam. A captura central de erros neles é muito cedo. Existem muitos erros neles, muitas vezes tudo muda.
No entanto, a empresa possui ambientes especiais em que todos os conjuntos estáveis são integrados para verificar o desempenho, a regressão manual centralizada e os testes de alta disponibilidade. Como regra, esses ambientes ainda não são estáveis o suficiente. No entanto, há equipes interessadas em analisar problemas com esses ambientes.
Mas há mais um obstáculo - o Hadoop não coleta dados desses ambientes! Não podemos usar o mesmo método para detectar erros, precisamos procurar uma fonte de dados diferente.
Após uma breve pesquisa, decidimos processar o fluxo de estatísticas, lendo dados da fila na qual nossos serviços gravam para transferência para o Hadoop. Foi o suficiente para acumular erros exclusivos e processá-los em lotes, por exemplo, uma vez a cada 30 minutos. É fácil estabelecer um sistema de filas que fornece dados - tudo o que restava era refinar o recebimento e o processamento.
Começamos a observar como os erros encontrados se comportam após a detecção. Aconteceu que a maioria dos erros encontrados e não corrigidos aparece mais tarde na produção. Então, nós os encontramos corretamente.
Assim, construímos um protótipo do sistema, instituições e erros de rastreamento. Já em sua forma atual, ele permite melhorar a qualidade do sistema, perceber e corrigir erros antes que os usuários saibam sobre eles. Se anteriormente processamos dezenas de milhares de solicitações erradas por semana, agora são apenas 2-300. E nós os corrigimos muito mais rápido.
O que vem a seguir
Obviamente, não pararemos por aí e continuaremos a melhorar o sistema de busca e rastreamento de erros. Temos planos:
- Análise de mais erros de API.
- Integração com testes funcionais.
- Recursos adicionais para investigar incidentes em nosso sistema.
Mas mais sobre isso da próxima vez.