Decodificação do relatório “Implementação típica de monitoramento” por Nikolay Sivko.
Meu nome é Nikolai Sivko. Eu também faço monitoramento. Okmeter é o 5 monitoramento que eu faço. Decidi salvar todas as pessoas do inferno do monitoramento e salvar alguém desse sofrimento. Eu sempre tento não anunciar um okmeter nas minhas apresentações. Naturalmente, as imagens serão de lá. Mas a idéia do que quero dizer é que tornamos o monitoramento uma abordagem um pouco diferente da que todos costumam fazer. Nós conversamos muito sobre isso. Quando tentamos convencer cada pessoa disso, no final, ele se convence. Eu quero falar sobre nossa abordagem precisamente para que, se você mesmo faça o monitoramento, evite nosso rake.

Sobre o Okmeter em poucas palavras. Fazemos o mesmo que você, mas existem todos os tipos de chips. Fichas:
- detalhamento;
- um grande número de gatilhos pré-configurados com base nos problemas de nossos clientes;
- Configuração automática

Um cliente típico vem até nós. Ele tem duas tarefas:
1) entender que tudo quebrou com o monitoramento, quando não há nada.
2) conserte-o rapidamente.
Ele vem para monitorar as respostas do que está acontecendo com ele.
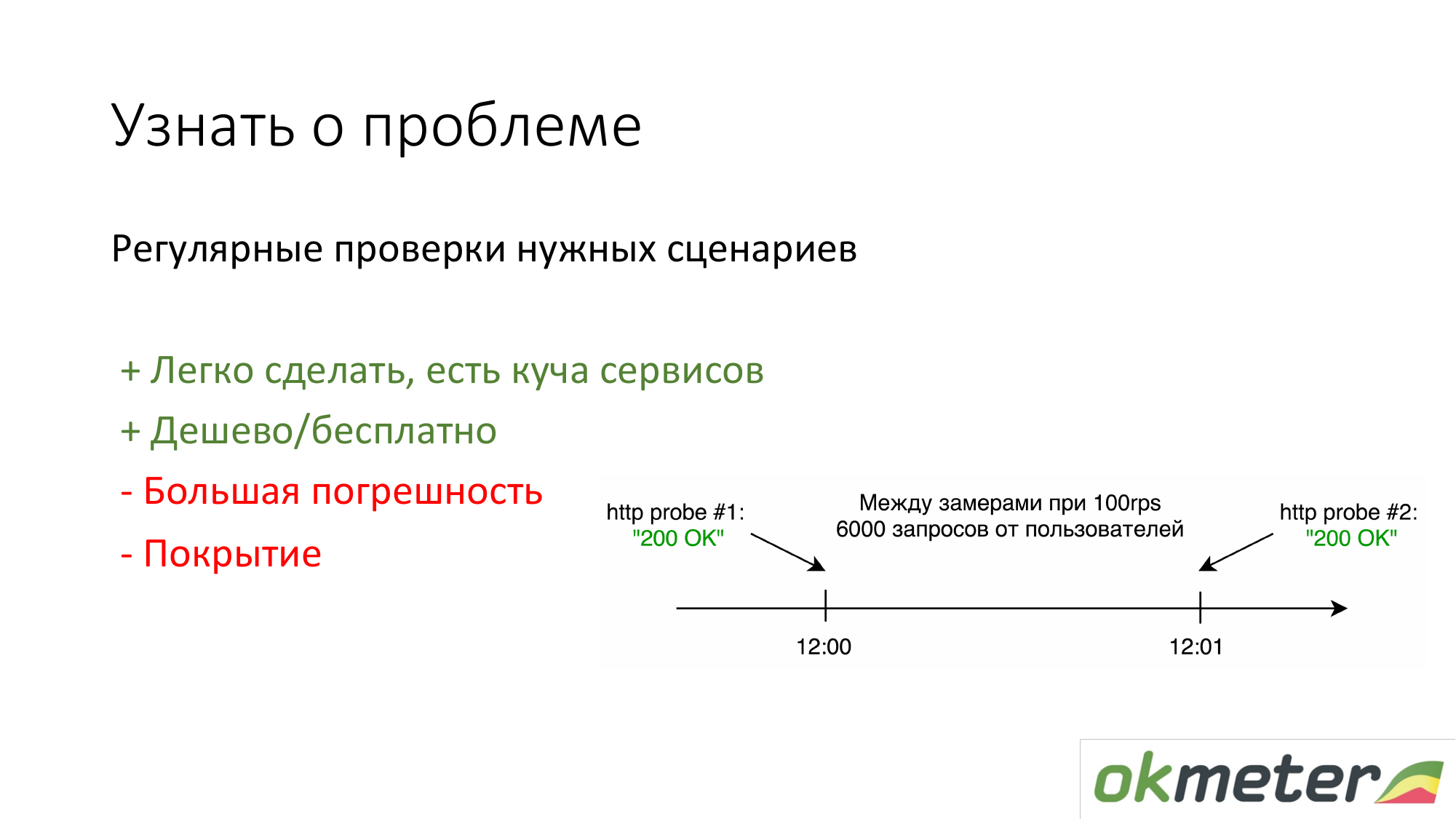
A primeira coisa que as pessoas que não têm nada a fazer é colocar https://www.pingdom.com/ e outros serviços para verificação. A vantagem desta solução é que ela pode ser feita em 5 minutos. Você não aprenderá mais sobre o problema através de chamadas de clientes. Existem problemas de precisão para que eles ignorem os problemas. Mas para sites simples, isso é suficiente.

A segunda coisa que defendemos é contar pelos logs de acordo com estatísticas de usuários reais. É assim que um usuário em particular obtém erros 5xx. Qual é o tempo de resposta dos usuários. Existem desvantagens, mas, em geral, isso funciona.

Sobre o nginx: fizemos isso para que qualquer cliente que vier imediatamente coloque o agente no frontend e tudo seja captado automaticamente por ele, ele começará a analisar, os erros começarão a aparecer e assim por diante. Ele não tem quase nada para configurar.

Mas a maioria dos clientes não possui timers nos logs nginx padrão. Esses 90% dos clientes não querem saber o tempo de resposta do site. Somos confrontados com isso o tempo todo. É necessário expandir o log nginx. Então, fora da caixa, automaticamente começamos a mostrar histogramas fora da caixa. Este é provavelmente um aspecto importante do fato de que o tempo deve ser medido.

O que estamos tirando de lá? Na prática, adotamos métricas em tais dimensões. Essas não são métricas planas. A métrica é chamada index.request.rate - o número de consultas por segundo. É detalhado por:
- o host do qual você removeu os logs;
- o log do qual esses dados foram obtidos;
- http por método;
- status http;
- status do cache.
Este NÃO é todo URL específico com todos os argumentos. Não queremos remover 100.000 métricas do log.

Queremos tomar 1000 métricas. Portanto, estamos tentando normalizar a URL, se possível. Pegue o URL principal. E para URLs significativos, mostramos um gráfico de barras separado, separadamente 5xx.

Aqui está um exemplo de como essa métrica simples se transforma em gráficos utilizáveis. Este é o nosso DSL no topo. Eu tentei esse DSL para explicar a lógica aproximada. Pegamos todas as solicitações de nginx por segundo e as distribuímos em todas as máquinas que possuímos. Obteve conhecimento sobre como equilibramos, quanto temos RPS total (solicitação por segundo, solicitações por segundo).

Por outro lado, podemos filtrar essa métrica e mostrar apenas 4xx. Em um gráfico 4xx, eles podem ser dispostos de acordo com o status real. Lembro que essa é a mesma métrica.

No gráfico, você pode mostrar 4xx por URL. Essa é a mesma métrica.

Também gravamos um histograma dos logs. Um histograma é a métrica response_time.histrogram, que na verdade é RPS com um parâmetro de nível adicional. Este é apenas um tempo limite no qual a solicitação é recebida.
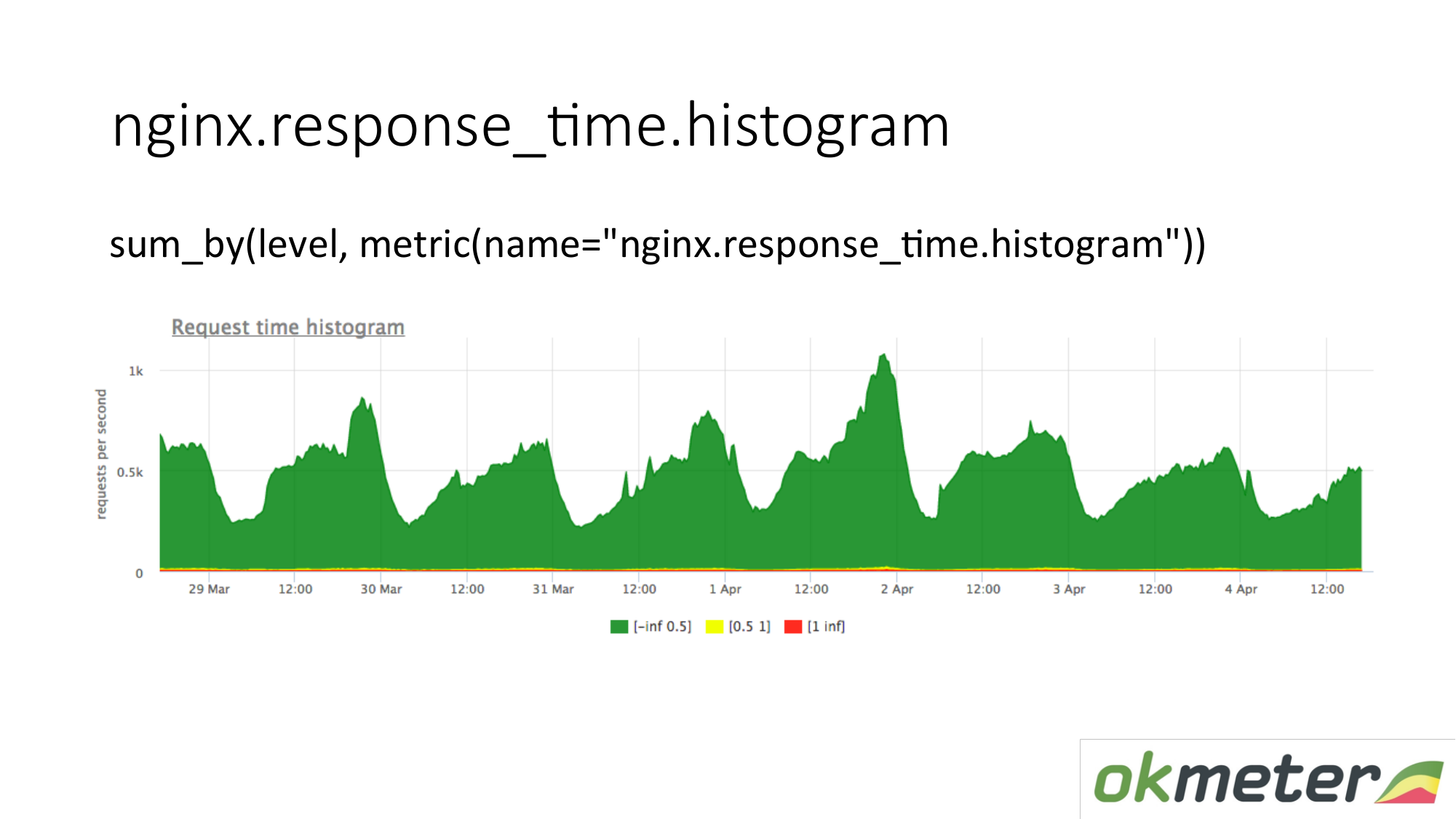
Desenhamos uma solicitação: resuma todo o histograma e classifique-o em níveis:
- Pedidos lentos
- pedidos rápidos;
- consultas médias;
Temos uma imagem que já foi resumida pelos servidores. A métrica é a mesma. Seu significado físico é compreensível. Mas tiramos vantagem disso de maneiras completamente diferentes.
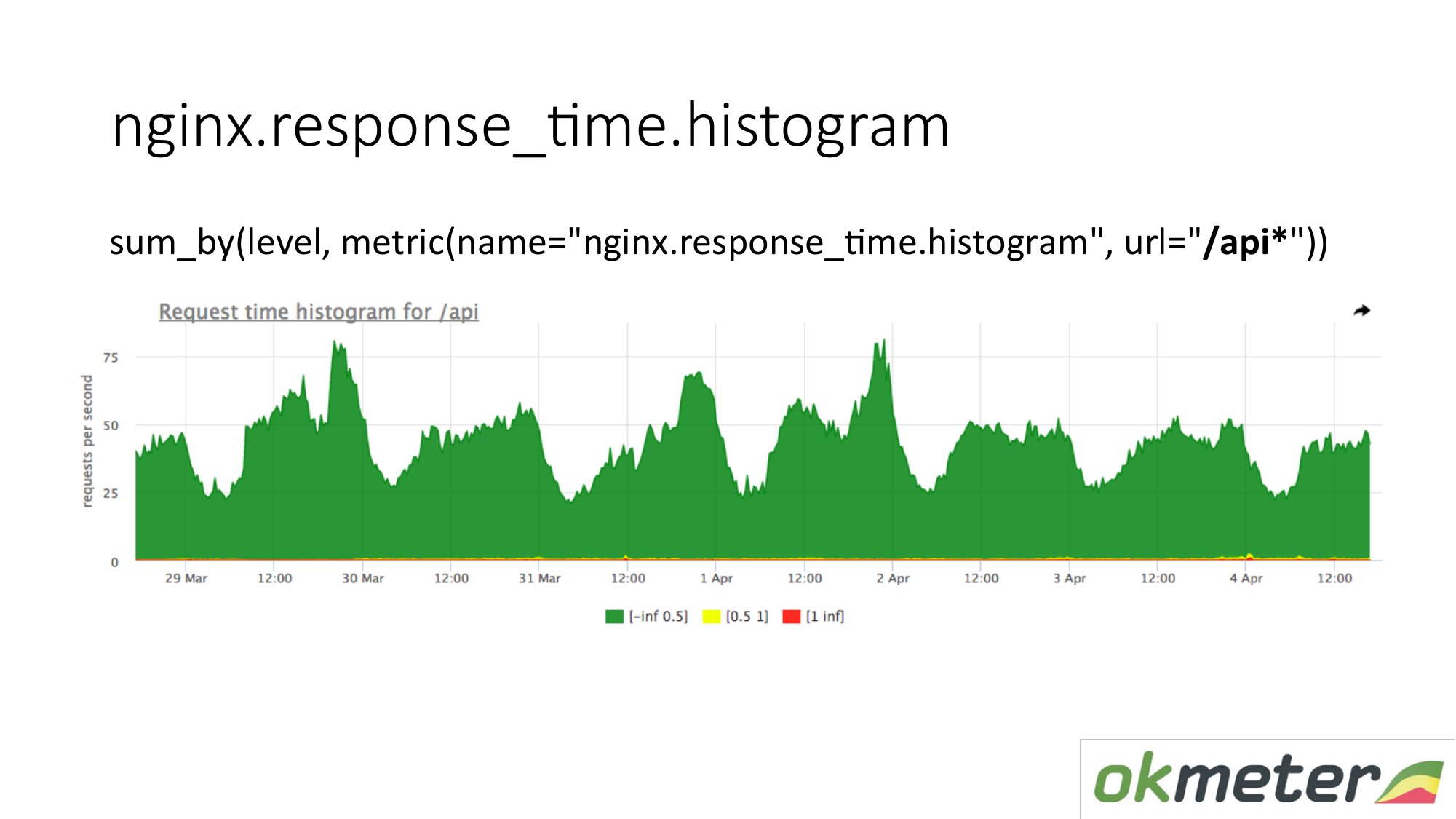
No gráfico, você pode mostrar o histograma apenas pelo URL começando com "/ api". Assim, examinamos o histograma separadamente. Nós olhamos o quanto neste momento. Vemos quantos RPS estavam no URL "/ api". A mesma métrica, mas um aplicativo diferente.

Algumas palavras sobre horários no nginx. Há request_time, que inclui o horário desde o início da solicitação até a transferência do último byte para o soquete para o cliente. E há upstream_response_time. Eles precisam ser medidos ambos. Se simplesmente removermos request_time, você verá atrasos devido a problemas de conectividade do cliente com o seu servidor; você verá atrasos se houver um pedido limite c burst configurado e o cliente no banho. Você não entenderá se precisa reparar o servidor ou ligar para o hoster. Por conseguinte, removemos ambos e é aproximadamente claro o que está acontecendo.

Com a tarefa de entender se o site está funcionando ou não, acredito que tenhamos resolvido mais ou menos isso. Existem erros. Existem imprecisões. Os princípios gerais são os seguintes.
Agora, sobre o monitoramento da arquitetura multicamada. Porque até a loja on-line mais simples tem pelo menos um front-end, seguido por um bitrix e uma base. Já existem muitos links. O ponto geral é que você precisa disparar em alguns indicadores de cada nível. Ou seja, o usuário está pensando em frontend. O front-end está pensando em back-end. O back-end pensa no back-end vizinho. E todos pensam na base. Então, por camadas, por dependências, examinamos. Cobrimos tudo com algum tipo de métrica. Temos algo na saída.

Por que não se limitar a uma camada? Normalmente, entre as camadas há uma rede. Uma grande rede sob carga é uma substância extremamente instável. Portanto, tudo acontece lá. Além disso, as medidas que você faz em qual camada pode estar. Se você realizar medições na camada "A" e na camada "B", e se elas interagirem uma com a outra através da rede, você poderá comparar suas leituras, encontrar algumas anomalias e inconsistências.

Sobre back-end. Queremos entender como monitorar o back-end. O que fazer com ele para entender rapidamente o que está acontecendo. Lembro que já passamos à tarefa de minimizar o tempo de inatividade. E sobre o back-end, sugerimos padronizar o entendimento:
- Quanto esse recurso come?
- Somos esbarrados em algum limite?
- O que está acontecendo com o tempo de execução? Por exemplo, a plataforma de tempo de execução da JVM, o tempo de execução Golang e outro tempo de execução.
- Quando já cobrimos tudo isso, é interessante para nós já mais perto do nosso código. Podemos usar intrumetria automática (statsd, * -metric), o que nos mostrará tudo isso. Ou instrua-se definindo temporizadores, contadores, etc.
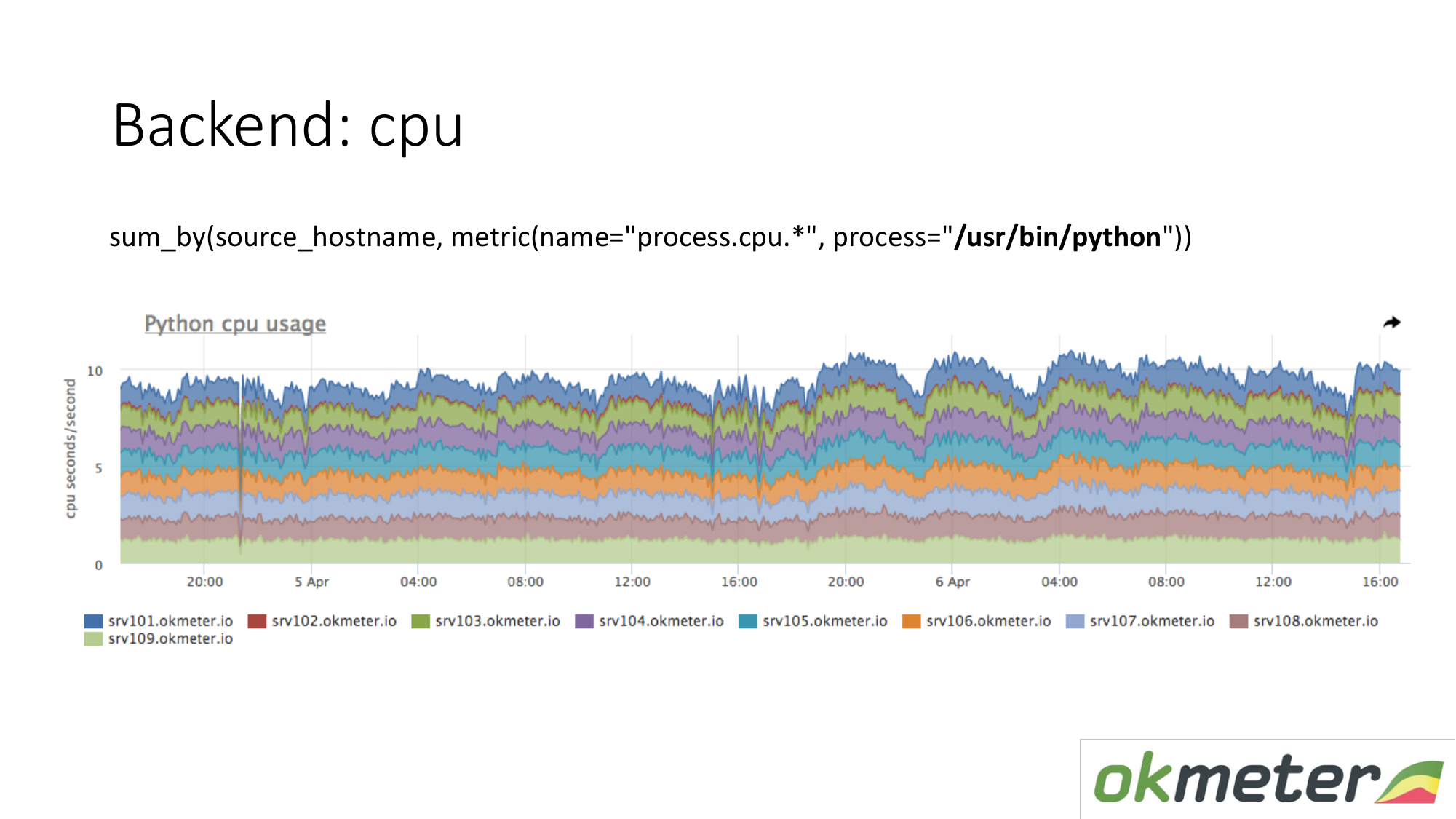
Sobre os recursos. Nosso agente padrão remove o consumo de recursos por todos os processos. Portanto, para o back-end, não precisamos capturar dados separadamente. Tomamos e vemos quanto a CPU consome o processo, por exemplo, Python nos servidores mascarados. Mostramos todos os servidores no cluster no mesmo gráfico, porque queremos entender se temos desequilíbrios e se algo explodiu na mesma máquina. Vemos o consumo total de ontem a hoje.
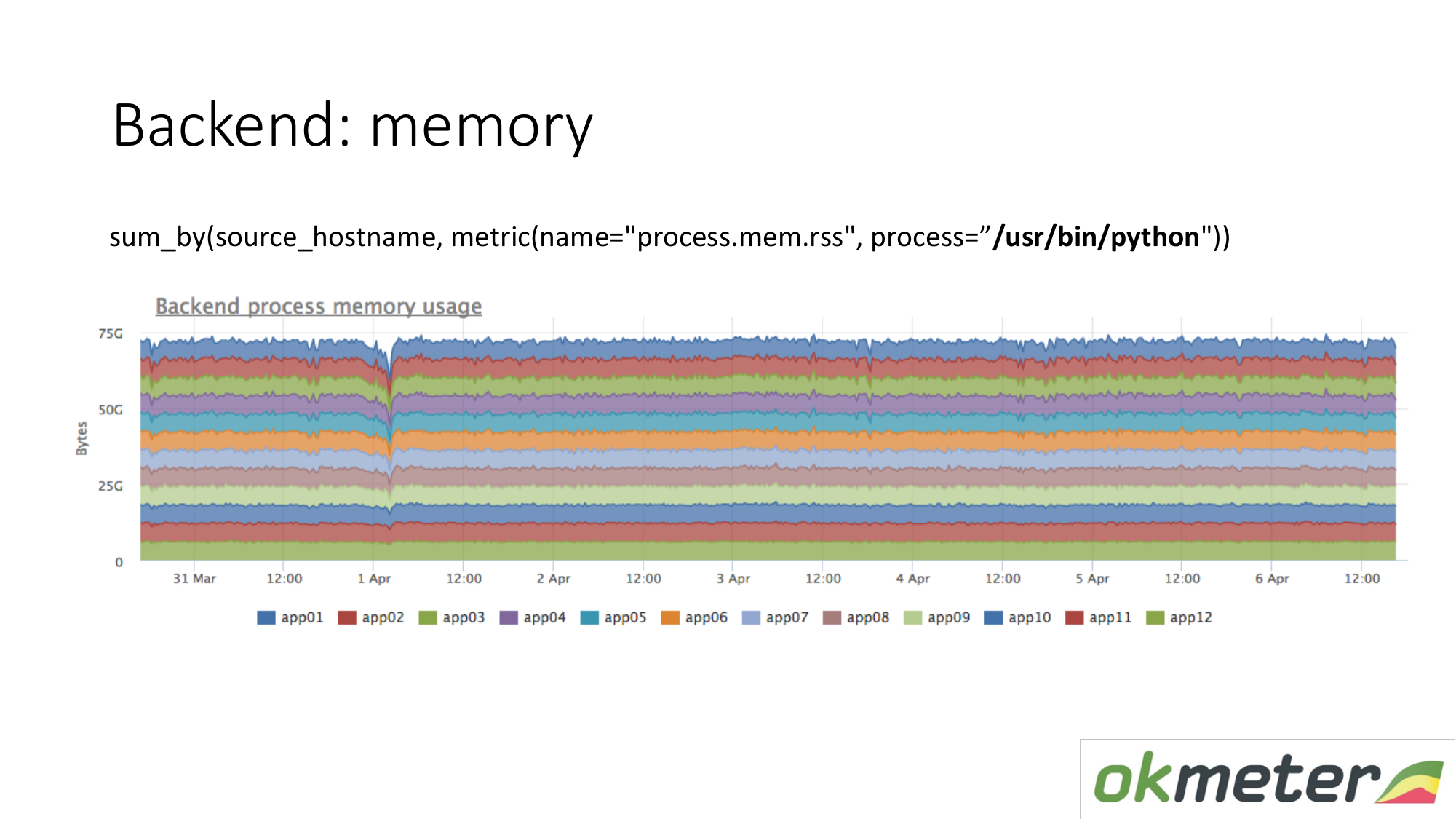
O mesmo vale para a memória. Quando a desenhamos assim. Selecionamos o Python RSS (RSS é o tamanho das páginas de memória alocadas ao processo pelo sistema operacional e atualmente localizadas na RAM). Soma por host. Não olhamos para lugar nenhum a memória flui. Em todos os lugares, a memória é distribuída uniformemente. Em princípio, recebemos uma resposta para nossas perguntas.
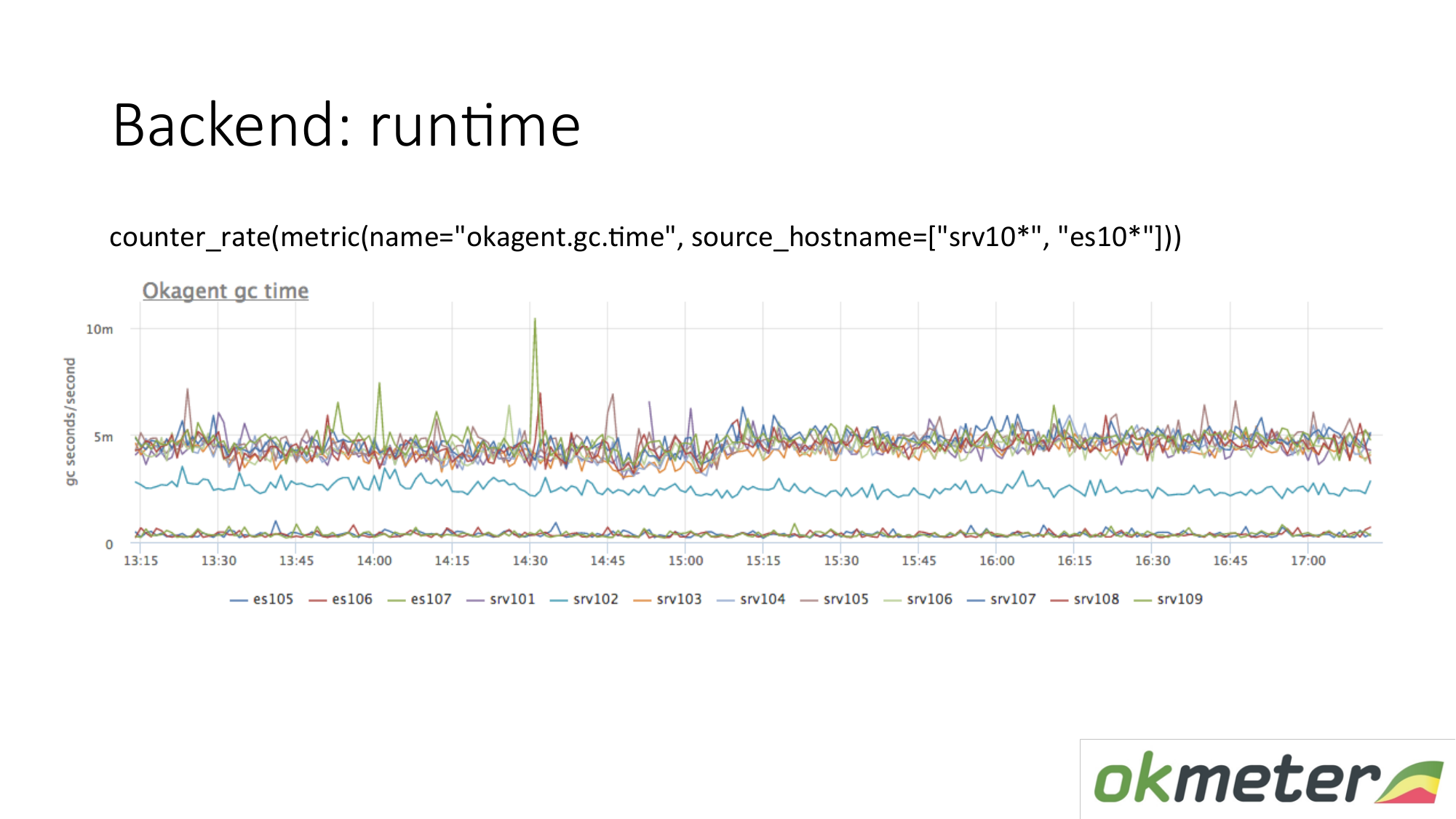
Exemplo de tempo de execução. Nosso agente está escrito em Golang. O agente Golang envia para si próprio métricas de seu tempo de execução. Esse é, em particular, o número de segundos gastos pelo coletor de lixo de Golang na coleta de lixo por segundo. Vemos aqui que alguns servidores têm métricas diferentes de outros servidores. Vimos uma anomalia. Estamos tentando explicar isso.
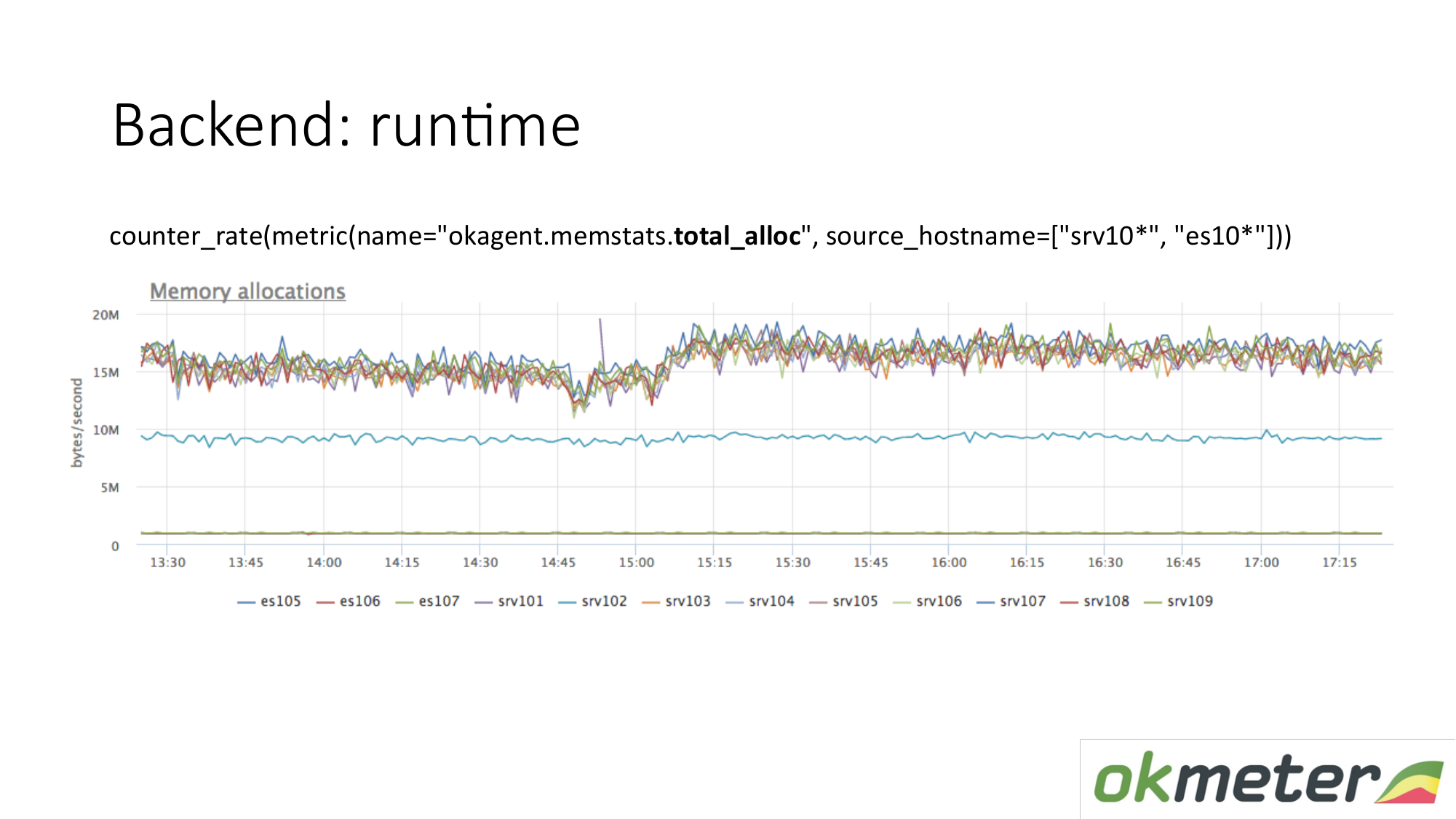
Há outra métrica de tempo de execução. Quanta memória é alocada por unidade de tempo. Vemos que agentes com um tipo que está no topo alocam mais memória do que agentes que baixam. Abaixo estão os agentes com um Garbage Collector menos agressivo. Isso é lógico. Quanto mais memória passa por você, é alocada e liberada, maior a carga no Garbage Collector. Além disso, de acordo com nossas métricas internas, entendemos por que queremos tanta memória nessas máquinas e menos nessas máquinas.
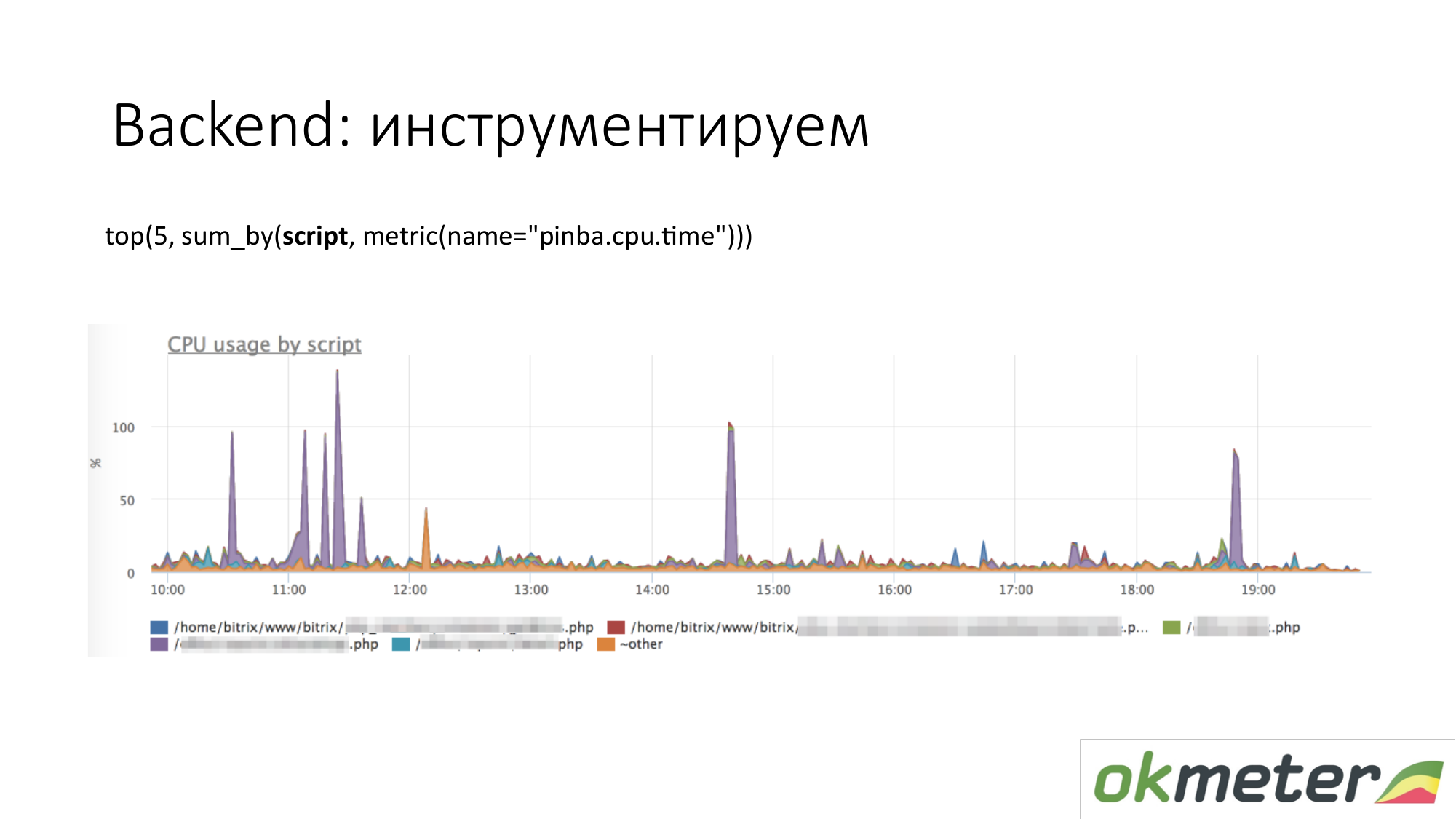
Quando falamos sobre instrumentação, todos os tipos de ferramentas como http://pinba.org/ para php vêm. O Pinba é uma extensão para php do Badoo, que você instala e conecta ao php. Ele permite remover e enviar imediatamente o protobuf pelo UDP. Eles têm um servidor pinba. Mas criamos um servidor Pinba incorporado no agente. O PHP envia para si mesmo quanto gastou CPU e memória para esses scripts, quanto tráfego é fornecido por esses scripts e assim por diante. Aqui está um exemplo com o Pinba. Mostramos os 5 principais scripts sobre o consumo da CPU. Vemos um outlier violeta que é um ponto borrado do PHP. Vamos reparar o ponto manchado do PHP ou entender por que ele consome a CPU. Já reduzimos o escopo do problema para entendermos as etapas a seguir. Vamos examinar o código e repará-lo.

O mesmo vale para o tráfego. Nós olhamos para os 5 principais scripts de tráfego. Se isso é importante para nós, então vamos entender.

Este é um gráfico sobre nossas ferramentas internas. Quando definimos o cronômetro através do statsd e medimos as métricas. Fizemos isso para que a quantidade de tempo total gasto na CPU ou na antecipação de algum recurso seja definida de acordo com o manipulador que estamos processando atualmente e de acordo com os estágios importantes do seu código: eles esperaram pelo cassander, aguardaram pela elasticsearch. O gráfico mostra os cinco principais estágios do manipulador / metric / query. No gráfico, você pode mostrar os 5 principais manipuladores para consumo de CPU, então o que está acontecendo lá dentro. Está claro o que consertar.
Sobre o back-end, você pode ir mais fundo. Há coisas que fazem rastreamento. Ou seja, você pode ver essa solicitação de usuário específica com um cookie e o IP e assim gerados tantas solicitações para o banco de dados, que esperaram tanto tempo. Não somos capazes de rastrear. Nós não estamos rastreando. Ainda podemos acreditar que não fazemos aplicativos e monitoramento de desempenho.

Sobre o banco de dados. A mesma coisa Bancos de dados são o mesmo processo. Ele consome recursos. Se a base for muito sensível à latência, haverá recursos ligeiramente diferentes. Sugerimos verificar se não há menos recursos, não há degradação de recursos. É ideal entender que, se a base começar a consumir mais do que consumia, entenda o que exatamente mudou no seu código.
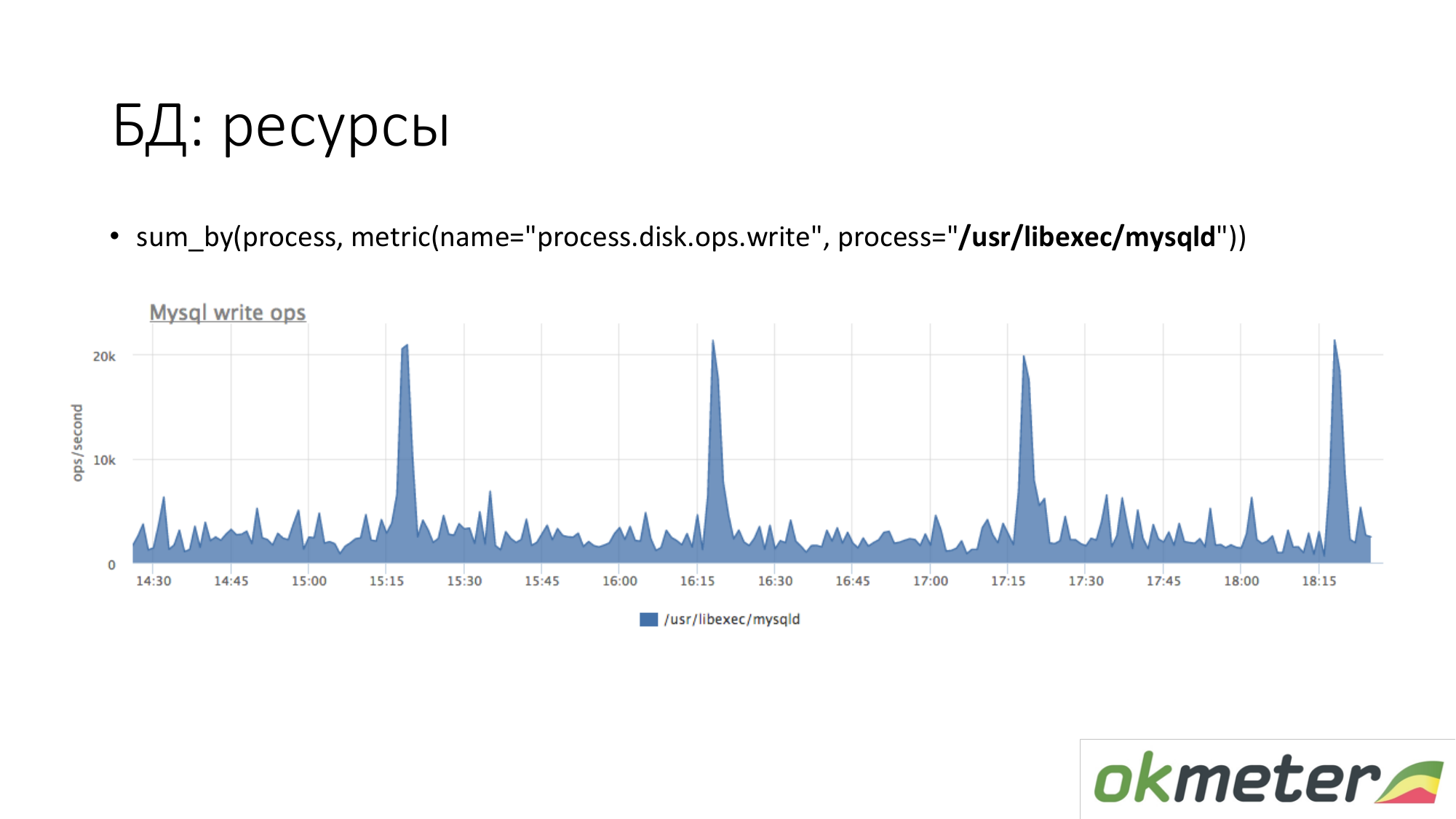
Sobre os recursos. Da mesma forma, olhamos o quanto o processo MySQL gera em nosso disco. Vemos que, em média, há muito, mas alguns picos acontecem. Por exemplo, muitas inserções entram e começam a gravar no disco às 15.15, 16.15, 17.15.
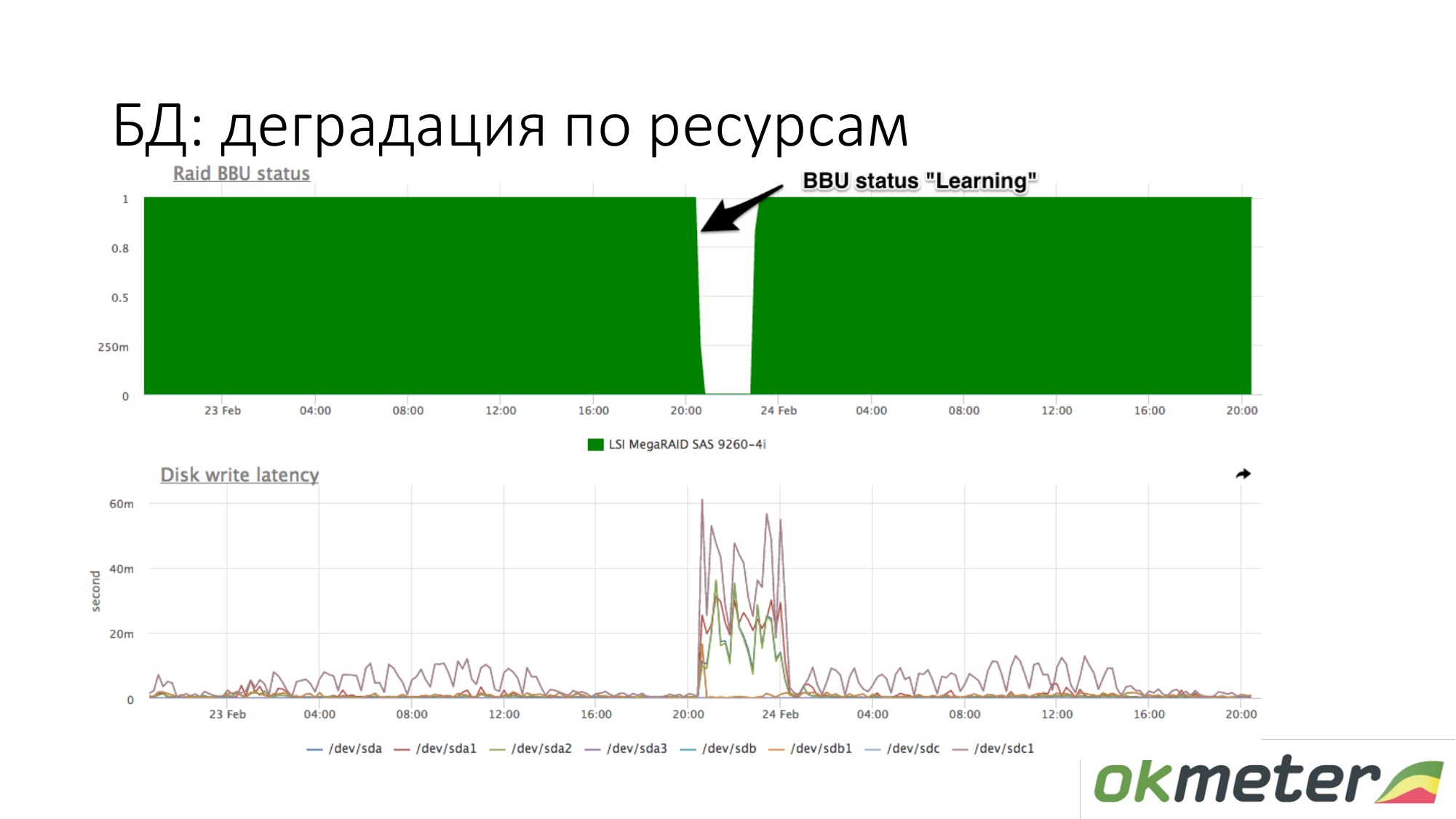
Sobre a degradação de recursos. Por exemplo, uma bateria RAID entrou no modo de manutenção. Ela deixou de ser um controlador como uma bateria viva. Nesse ponto, o cache de gravação é desconectado, o tempo de latência dos discos de gravação aumenta. Nesse momento, se o banco de dados começar a ficar sem graça enquanto aguarda o disco, e você souber aproximadamente que com a mesma carga na gravação na latência do disco era diferente, verifique a bateria no RAID.

Recursos sob Demanda. Não é tão simples aqui. Depende da base. A base deve ser capaz de dizer sobre si mesma: quais solicitações gasta recursos, etc. O líder nisso é o PostgreSQL. Ele tem pg_stat_statements. Você pode entender que tipo de solicitação você tem usando muita CPU, disco de leitura e gravação e tráfego.
No MySQL, para ser sincero, tudo é muito pior. Possui performance_schema. De alguma forma, funciona a partir da versão 5.7. Diferentemente de uma única visualização no PostgreSQL, performance_schema é uma tabela de visualização do sistema de 27 ou 23 no MySQL. Às vezes, se você fizer consultas nas tabelas erradas (na visão errada), poderá desperdiçar o MySQL.
Redis tem estatísticas da equipe. Você vê que um determinado comando usa muita CPU, etc.
Cassandra tem tempo para consultar tabelas específicas. Porém, como o cassandra foi projetado para que um tipo de consulta seja feito na tabela, isso é suficiente para o monitoramento.
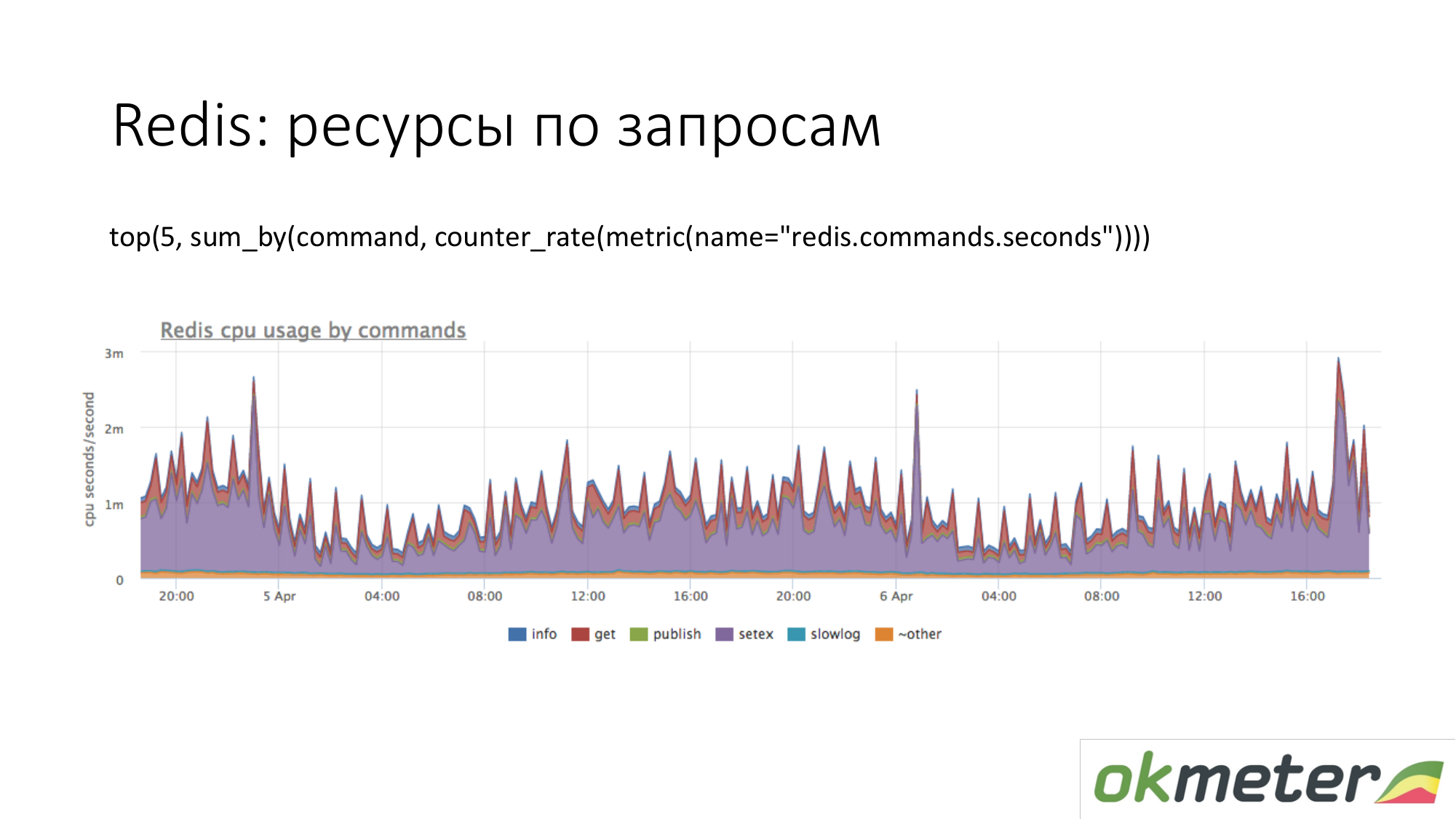
Este é Redis. Vemos que o roxo usa muita CPU. Violet é um setex. Setex - registro de chave com instalação TTL. Se isso é importante para nós, vamos lidar com isso. Se isso não for importante para nós, apenas sabemos para onde vão todos os recursos.
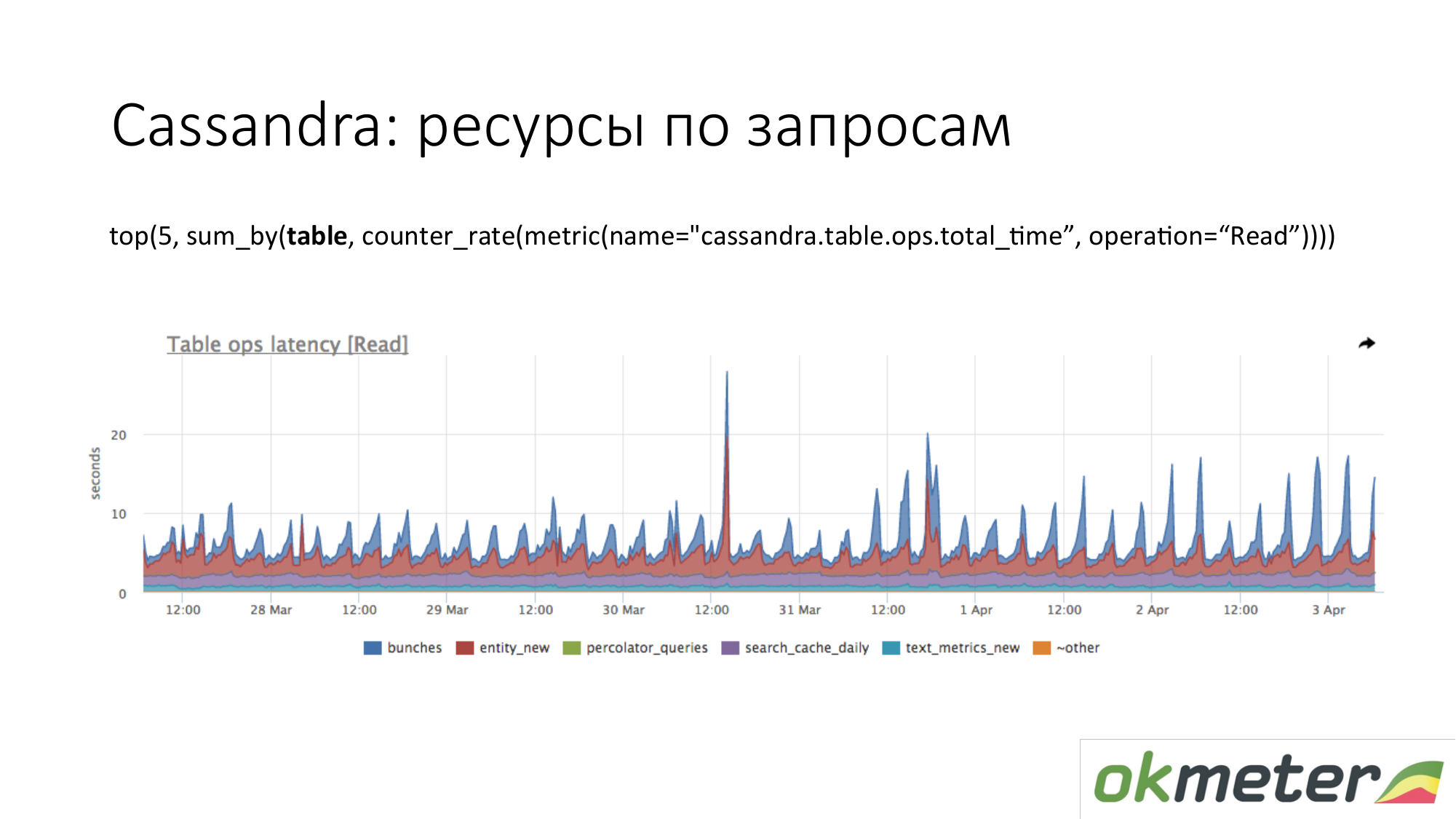
Cassandra. Vemos as 5 principais tabelas para solicitações de leitura pelo tempo total de resposta. Nós vemos essa onda. Essas são consultas à tabela, e entendemos aproximadamente que uma consulta nessa tabela cria um pedaço de código. Cassandra não é um banco de dados SQL no qual podemos fazer consultas diferentes em tabelas. Cassandra está se tornando cada vez mais infeliz.

Algumas palavras sobre o fluxo de trabalho funcionam com incidentes. Como eu vejo.
Sobre alerta. Nossa visão do fluxo de trabalho de incidentes é diferente do que geralmente é aceito.

Severy Critical. Notificamos você por SMS e todos os canais de comunicação em tempo real.
Severy Info é uma lâmpada que pode ajudá-lo com alguma coisa ao trabalhar com incidentes. As informações não são notificadas em nenhum lugar. A informação simplesmente trava e informa que algo está acontecendo.
Severy Warning é algo que pode ser notificado, talvez não.

Exemplos críticos.
O site não funciona de todo. Por exemplo, 5xx 100% ou o tempo de resposta aumentou e os usuários começaram a sair.
Erros de lógica de negócios. O que é crítico. É necessário medir dinheiro por segundo. Dinheiro por segundo é uma boa fonte de dados para a Critical. Por exemplo, o número de pedidos, promoção de anúncios e outros.

Fluxo de trabalho com Crítico, para que este incidente não possa ser adiado. Você não pode clicar em OK e voltar para casa. Se a Critical veio até você e você está pegando o metrô, deve sair do metrô, sair, tomar um banco e começar a consertar. Caso contrário, não é crítico. A partir dessas considerações, construímos a gravidade restante para o atributo residual.

Atenção. Exemplos de aviso.
- O espaço em disco acaba.
- O serviço interno funciona por um longo tempo, mas se você não tiver um Critical, isso significa que você é condicional de qualquer maneira.
- Muitos erros na interface de rede.
- O mais controverso é o servidor não estar disponível. De fato, se você tiver mais de um servidor e o servidor estiver indisponível, isso é Aviso. Se você não possui um back-end em 100, é estúpido acordar do SMS e você receberá administradores nervosos.
Todos os outros Severy foram projetados para ajudá-lo a lidar com a Critical.

Atenção. Defendemos essa abordagem para trabalhar com o Warning. De preferência Aviso fechado durante o dia. A maioria dos nossos clientes desativou a notificação de aviso. Assim, eles não têm a chamada cegueira de monitoramento. Isso significa dobrar letras no correio sem ler um diretório separado. Os clientes desativaram o alerta de aviso.
(Pelo que entendi, o monitoramento puro são alertas e gatilhos desnecessários adicionados a exceções - observação do autor da postagem)
Se você usar a técnica de monitoramento puro, se tiver 5 novos avisos, poderá repará-los em um modo silencioso. Eles não tiveram tempo para corrigi-lo hoje, mas adiaram para amanhã, se não de forma crítica. Se o Aviso acender e se extinguir, isso deve ser distorcido no monitoramento, para que você não se incomode mais. Então você será mais tolerante com eles e, consequentemente, a vida melhorará.

Exemplos de informações. É discutível que a alta utilização da CPU de muitos críticos. De fato, se nada afetar, você poderá ignorar esta notificação.

Atenção (talvez eu veja Info - uma observação do autor do post) estas são as luzes que acendem quando você vem para reparar o Critical. Você vê dois sinais de aviso lado a lado (talvez haja um link Informações - observação do autor da postagem). Eles podem ajudá-lo a resolver o incidente com o Critical. Por que não está claro o alto uso da CPU separadamente no SMS ou em uma carta.
Informações inúteis também são ruins. Se você configurá-los como uma exceção, adorará demais o Info.

Princípios gerais para design de alerta. O alerta deve mostrar o motivo. Isto é perfeito. Mas isso é difícil de conseguir. Aqui estamos trabalhando em tempo integral na tarefa e isso resulta em alguma parte do sucesso.
Todo mundo está falando sobre a necessidade de dependência, auto-magia. De fato, se você não receber notificações de algo que não lhe interessa, não haverá muito. Na minha prática, as estatísticas mostram que uma pessoa olha no momento de um incidente crítico com os olhos cerca de cem lâmpadas na diagonal. Ele encontrará o caminho certo e não pensará que a dependência ocultou lâmpadas que me ajudariam agora. Na prática, isso funciona. Tudo o que você precisa fazer é limpar alertas desnecessários.

(Aqui o vídeo foi ignorado - nota do autor da publicação)

Seria bom classificar esses períodos de inatividade para que você possa trabalhar com eles mais tarde. Por exemplo, tire conclusões organizacionais. Você precisa entender por que estava mentindo. Propomos classificar / dividir nas seguintes classes:
- homem feito
- configuração do hoster
- veio bots
Se você os classificar, todos serão felizes.

O SMS chegou. O que estamos fazendo? Primeiro, corremos para consertar tudo. Até agora, nada é importante para nós, exceto o término do tempo de inatividade. Porque somos motivados a mentir menos. Então, quando o incidente foi fechado, ele deveria ser fechado para o sistema de monitoramento. Acreditamos que o incidente deve ser verificado pelo monitoramento. Se o seu monitoramento não estiver configurado, basta garantir que o problema acabou. Isso deve ser torcido. Depois que o incidente é fechado, ele não é realmente fechado. Ele espera enquanto você chega ao fundo da razão. De fato, qualquer líder precisa antes de tudo garantir que os problemas não se repitam. Para que os problemas não se repitam, você precisa entender o motivo. Depois de entendermos o motivo, temos dados para classificá-los. Analisamos as razões. Então, ao chegarmos ao ponto mais baixo, precisamos fazer isso no futuro para que o incidente não se repita:
- são necessárias duas pessoas por quarto para escrever essa e essa lógica no back-end.
- precisa colocar mais réplicas.
É necessário garantir que exatamente o mesmo incidente não ocorra. Quando você trabalha nesse fluxo de trabalho por meio de N iterações, a felicidade espera por você, um bom tempo de atividade.
Por que os classificamos? Podemos pegar as estatísticas do trimestre e entender o que o tempo de inatividade deu a você. Então trabalhe nessa direção. Você pode trabalhar em todas as frentes não será muito eficaz, especialmente se você tiver poucos recursos lá.

Calculamos que ficamos por tanto tempo, por exemplo 90% por causa do hoster. Cobramos que mudemos este hoster. Se as pessoas mexem conosco, nós as enviamos para os cursos. , - — . . , . , .

. :
, , . , , .

: , . : , , . False Positive ( ), , . ?
: . 10- frontend , . 9 frontend nginx, 10- , warning alert . . , . . .
: . , , load avarage 4 , - load avarage 20 .
: load avarage. 100 . CPU usage Hadoop . . . . , , . PostgreSQL autovacuum, worker autovacuum . 99 . Warning . Critical . Critical 10 5 , Critical.
Pergunta: Em que momento e como o limite é determinado? Quem está fazendo isso?
Resposta: Você vem até nós e diz: queremos perguntar a alguns críticos do nosso projeto. Se você colocar 10 5xx por segundo agora, quantas notificações você receberá uma semana atrás.
Pergunta: Qual é o ônus de todo esse bom monitoramento?
Resposta: Em geral, geralmente é invisível. Mas se você analisar 50.000 RPS, será de 1% a 10% de uma CPU. Como estamos apenas monitorando, otimizamos nosso agente. Medimos o desempenho do agente. Se você não tiver os recursos para monitorar no servidor, estará fazendo algo errado. Sempre deve haver recursos para monitorar. Caso contrário, você ficará cego ao administrar seu projeto.