Vamos dar uma olhada no tópico da programação orientada a protocolo. Por conveniência, o material foi dividido em três partes.
Este material é uma tradução de comentários da apresentação da WWDC 2016 . Ao contrário da crença comum de que as coisas "ocultas" deveriam permanecer ali, às vezes é extremamente útil descobrir o que está acontecendo lá. Isso ajudará a usar o item corretamente e para a finalidade a que se destina.
Esta parte abordará questões importantes na programação orientada a objetos e como o POP as soluciona. Tudo será considerado nas realidades da linguagem Swift, os detalhes serão considerados "compartimento do motor" dos protocolos.
Problemas de POO e por que precisamos de POP
Sabe-se que no POO existem várias fraquezas que podem "sobrecarregar" a execução do programa. Considere o mais explícito e comum:
- Alocação: Stack ou Heap?
- Contagem de referência: mais ou menos?
- Envio de método: estático ou dinâmico?
1.1 Alocação - Pilha
A pilha é uma estrutura de dados bastante simples e primitiva. Podemos colocar no topo da pilha (push), podemos tirar do topo da pilha (pop). A simplicidade é que isso é tudo o que podemos fazer com isso.
Para simplificar, vamos supor que cada pilha tenha uma variável (ponteiro da pilha). É usado para rastrear o topo da pilha e armazena um número inteiro (Inteiro). Daqui resulta que a velocidade das operações com a pilha é igual à velocidade de reescrever Inteiro nessa variável.
Empurre - coloque na parte superior da pilha, aumente o ponteiro da pilha;
pop - reduz o ponteiro da pilha.
Tipos de valor
Vamos considerar os princípios de operação de pilha no Swift usando estruturas (struct).
No Swift, os tipos de valor são estruturas (struct) e enumerações (enum), e os tipos de referência são classes (classe) e funções / fechamentos (func). Os tipos de valor são armazenados na pilha, os tipos de referência são armazenados no heap.
struct Point { var x, y: Double func draw() {...} } let point1 = Point(...)

- Colocamos a primeira estrutura no Stack
- Copie o conteúdo da primeira estrutura
- Alterar a memória da segunda estrutura (a primeira permanece intacta)
- Fim de uso. Memória livre
1.2 Alocação - Heap
Heap é uma estrutura de dados semelhante a uma árvore. O tópico de implementação de heap não será afetado aqui, mas tentaremos compará-lo com a pilha.
Por que, se possível, vale a pena usar Stack em vez de Heap? Aqui está o porquê:
- contagem de referência
- administração de memória livre e sua busca por alocação
- reescrevendo a memória para desalocação
Tudo isso é apenas uma pequena parte do que faz o Heap funcionar e claramente o pesa em comparação com o Stack.
Por exemplo, quando precisamos de memória livre na pilha, apenas pegamos o valor do ponteiro da pilha e aumentamos (porque tudo acima do ponteiro da pilha na pilha é memória livre) - O (1) é uma operação constante no tempo.
Quando precisamos de memória livre no Heap, começamos a procurá-la usando o algoritmo de pesquisa apropriado na estrutura da árvore de dados - na melhor das hipóteses, temos uma operação O (logn) que não é constante no tempo e depende de implementações específicas.
De fato, o Heap é muito mais complicado: seu trabalho é fornecido por uma série de outros mecanismos que vivem nas entranhas dos sistemas operacionais.
Também é importante notar que o uso do Heap no modo multithreading agrava significativamente a situação, pois é necessário garantir a sincronização do recurso compartilhado (memória) para diferentes threads. Isso é conseguido usando bloqueios (semáforos, spinlocks, etc.).
Tipos de referência
Vamos ver como o Heap funciona no Swift usando classes.
class Point { var x, y: Double func draw() {...} } let point1 = Point(...)
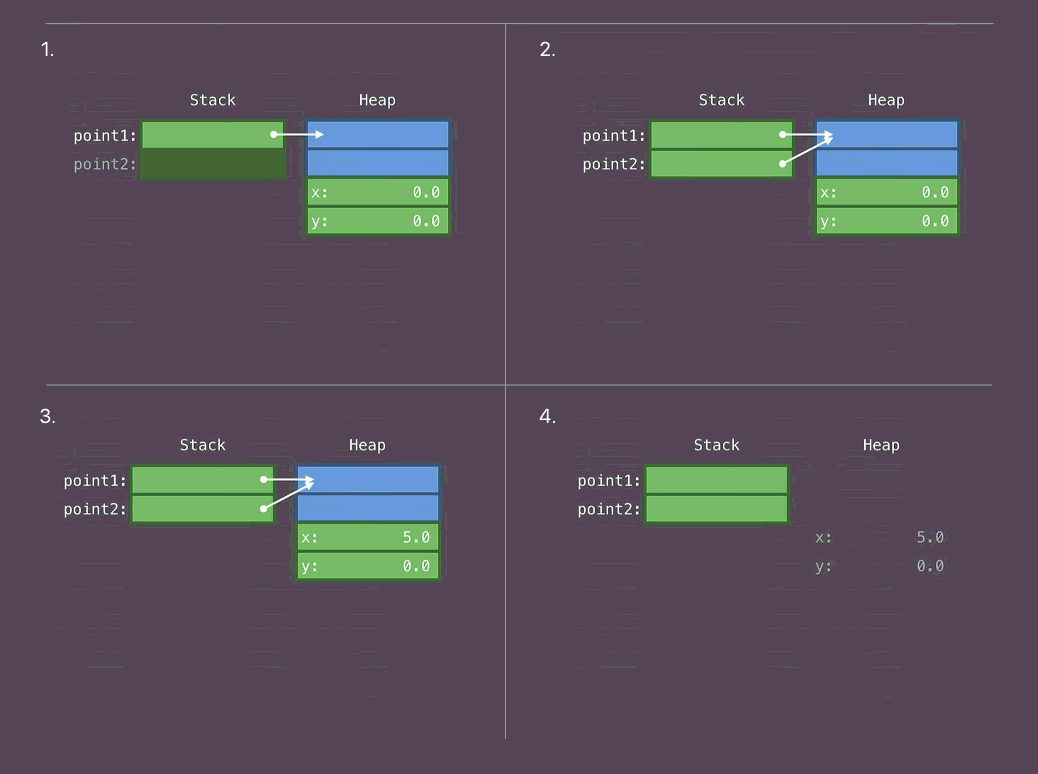
1. Coloque o corpo da classe no Heap. Coloque o ponteiro para esse corpo na pilha.
- Copie o ponteiro que se refere ao corpo da classe
- Mudamos um corpo de classe
- Fim de uso. Memória livre
1.3 Alocação - um exemplo pequeno e "real"
Em algumas situações, escolher Stack não apenas simplifica o tratamento da memória, mas também melhora a qualidade do código. Considere um exemplo:
enum Color { case red, green, blue } enum Orientation { case left, right } enum Tail { case none, tail, bubble } var cache: [String: UIImage] = [] func makeBalloon(_ color: Color, _ orientation: Orientation, _ tail: Tail) -> UIImage { let key = "\(color):\(orientation):\(tail)" if let image = cache[key] { return image } ... }
Se o dicionário de cache tiver um valor com a tecla key, a função retornará simplesmente a UIImage em cache.
Os problemas deste código são:
Não é uma boa prática usar String como uma chave em cache, porque String no final "pode vir a ser qualquer coisa".
String é uma estrutura de copiar na gravação, para implementar seu dinamismo, ele armazena todos os seus caracteres no Heap. Assim, String é uma estrutura e é armazenada na Stack, mas armazena todo o seu conteúdo no Heap.
Isso é necessário para fornecer a capacidade de alterar a linha (remova parte da linha, adicione uma nova linha a esta linha). Se todos os caracteres da string fossem armazenados na pilha, essas manipulações seriam impossíveis. Por exemplo, em C, as strings são estáticas, o que significa que o tamanho de uma string não pode ser aumentado em tempo de execução, pois todo o conteúdo é armazenado na Stack. Para copiar na gravação e analisar mais detalhadamente as linhas no Swift, clique aqui .
Solução:
Use a estrutura bastante óbvia aqui, em vez da string:
struct Attributes: Hashable { var color: Color var orientation: Orientation var tail: Tail }
Alterar dicionário para:
var cache: [Attributes: UIImage] = []
Livrar-se de String
let key = Attributes(color: color, orientation: orientation, tail: tail)
Na estrutura de atributos, todas as propriedades são armazenadas na pilha, pois a enum é armazenada na pilha. Isso significa que não há uso implícito do Heap aqui e agora as chaves do dicionário de cache estão definidas com muita precisão, o que aumentou a segurança e a clareza desse código. Também nos livramos do uso implícito do Heap.
Veredicto: Stack é muito mais fácil e rápido que o Heap - a escolha para a maioria das situações é óbvia.
2. Contagem de referência
Para que?
Swift deve saber quando é possível liberar um pedaço de memória no Heap, ocupado, por exemplo, por uma instância de uma classe ou função. Isso é implementado por meio de um mecanismo de contagem de links - cada instância (classe ou função) hospedada no Heap possui uma variável que armazena o número de links. Quando não há links para uma instância, o Swift decide liberar um pedaço de memória alocado para ela.
Deve-se notar que, para uma implementação "de alta qualidade" desse mecanismo, são necessários muito mais recursos do que para aumentar e diminuir o ponteiro de pilha. Isso se deve ao fato de o valor do número de links poder aumentar a partir de diferentes threads (porque você pode se referir a uma classe ou função de diferentes threads). Além disso, não se esqueça da necessidade de garantir a sincronização do recurso compartilhado (número variável de links) para diferentes threads (spinlocks, semáforos etc.).
Stack: localizando memória livre e liberando memória usada - operação de ponteiro de pilha
Heap: pesquisando memória livre e liberando o algoritmo de pesquisa em árvore de memória usado e a contagem de referência.
Na estrutura de atributos, todas as propriedades são armazenadas na pilha, pois a enum é armazenada na pilha. Isso significa que não há uso implícito do Heap aqui e agora as chaves do dicionário de cache estão definidas com muita precisão, o que aumentou a segurança e a clareza desse código. Também nos livramos do uso implícito do Heap.
Pseudo código
Considere um pequeno pedaço de pseudocódigo para demonstrar como a contagem de links funciona:
class Point { var refCount: Int var x, y: Double func draw() {...} init(...) { ... self.refCount = 1 } } let point1 = Point(x: 0, y: 0) let point2 = point1 retain(point2)
Struct
Ao trabalhar com estruturas, um mecanismo como a contagem de referência simplesmente não é necessário:
- struct não armazenado no heap
- struct - copiado na atribuição, portanto, nenhuma referência
Copiar links
Novamente, struct e qualquer outro tipo de valor no Swift são copiados na atribuição. Se a estrutura armazenar links em si, eles também serão copiados:
struct Label { let text: String let font: UIFont ... init() { ... text.refCount = 1 font.refCount = 1 } } let label = Label(text: "Hi", font: font) let label2 = label retain(label2.text._storage)
label e label2 compartilham instâncias comuns hospedadas no Heap:
Portanto, se a estrutura armazena links em si mesma, ao copiar essa estrutura, o número de links dobra, o que, se não for necessário, afeta negativamente a "facilidade" do programa.
E novamente o exemplo "real":
struct Attachment { let fileUrl: URL
Os problemas dessa estrutura são os seguintes:
- 3 Alocação de Heap
- Como String pode ser qualquer string, a segurança e a clareza do código são afetadas.
Ao mesmo tempo, uuid e mimeType são coisas estritamente definidas:
uuid é uma sequência de formato xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
mimeType é uma string de formato de tipo / extensão.
Solução
let uuid: UUID
No caso de mimeType, enum funciona bem:
enum MimeType { init?(rawValue: String) { switch rawValue { case "image/jpeg": self = .jpeg case "image/png": self = .png case "image/gif": self = .gif default: return nil } } case jpeg, png, gif }
Ou melhor e mais fácil:
enum MimeType: String { case jpeg = "image/jpeg" case png = "image/png" case gif = "image/gif" }
E não se esqueça de mudar:
let mimeType: MimeType
3.1 Despacho do método
- este é um algoritmo que procura o código do método chamado
Antes de falar sobre a implementação desse mecanismo, vale a pena determinar o que são uma "mensagem" e "método" neste contexto:
- uma mensagem é o nome que enviamos ao objeto. Os argumentos ainda podem ser enviados junto com o nome.
circle.draw(in: origin)
A mensagem é draw - o nome do método. O objeto receptor é um círculo. Origem também é um argumento passado.
- O método é o código que será retornado em resposta à mensagem.
Então o método Dispatch é um algoritmo que decide qual método deve ser dado a uma mensagem específica.
Mais especificamente sobre o método Dispatch no Swift
Como podemos herdar da classe pai e substituir seus métodos, Swift deve saber exatamente qual implementação desse método precisa ser chamada em uma situação específica.
class Parent { func me() { print("parent") } } class Child: Parent { override func me() { print("child") } }
Crie algumas instâncias e chame o método me:
let parent = Parent() let child = Child() parent.me()
Um exemplo bastante óbvio e simples. E se:
let array: [Parent] = [Child(), Child(), Parent(), Child()] array.forEach { $0.me()
Isso não é tão óbvio e requer recursos e um certo mecanismo para determinar a implementação correta do método me. Os recursos são o processador e a RAM. Um mecanismo é uma expedição de método.
Em outras palavras, o método Dispatch é como o programa determina qual implementação de método chamar.
Quando um método é chamado no código, sua implementação deve ser conhecida. Se ela é conhecida por
No momento da compilação, esse é o envio estático. Se a implementação for determinada imediatamente antes da chamada (em tempo de execução, no momento da execução do código), será o Dynamic Dispatch.
3.2 Envio de método - Envio estático
O mais ideal, pois:
- O compilador sabe qual bloco de código (implementação de método) será chamado. Graças a isso, ele pode otimizar esse código o máximo possível e recorrer a um mecanismo como o inlining.
- Além disso, no momento da execução do código, o programa simplesmente executará esse bloco de código conhecido pelo compilador. Não serão gastos recursos e tempo na determinação da implementação correta do método, o que acelerará a execução do programa.
3.3 Despacho de método - Despacho dinâmico
Não é o mais ideal, pois:
- A implementação correta do método será determinada no momento da execução do programa, o que requer recursos e tempo
- Nenhuma otimização do compilador está fora de questão
3.4 Despacho de método - Inlining
Um mecanismo como o inlining foi mencionado, mas o que é? Considere um exemplo:
struct Point { var x, y: Double func draw() {
- O método point.draw () e a função drawAPoint serão processados por meio do Static Dispatch, uma vez que não há dificuldade em determinar a implementação correta para o compilador (já que não há herança e redefinição é impossível)
- como o compilador sabe o que será feito, ele pode otimizar isso. Primeiro, otimiza o drawAPoint, simplesmente substituindo a chamada de função pelo seu código:
let point = Point(x: 0, y: 0) point.draw()
- otimiza point.draw, já que a implementação desse método também é conhecida:
let point = Point(x: 0, y: 0)
Criamos um ponto, executamos o código do método draw - o compilador simplesmente substituiu o código necessário por essas funções em vez de chamá-las. No Dynamic Dispatch, isso será um pouco mais complicado.
3.5 Despacho de método - polimorfismo baseado em herança
Por que preciso do Dynamic Dispatch? Sem ele, é impossível definir métodos substituídos por classes filho. Polimorfismo não seria possível. Considere um exemplo:
class Drawable { func draw() {} } class Point: Drawable { var x, y: Double override func draw() { ... } } class Line: Drawable { var x1, y1, x2, y2: Double override func draw() { ... } } var drawables: [Drawable] for d in drawables { d.draw() }
- matriz de drawables pode conter Point and Line
- intuitivamente, o Static Dispatch não é possível aqui. d no loop for pode ser Line, ou talvez Point. O compilador não pode determinar isso e cada tipo tem sua própria implementação de draw
Então, como funciona o Dynamic Dispatch? Cada objeto tem um campo de tipo. Então Ponto (...) .Tipo será igual a Ponto, e Linha (...) .Tipo será igual a Linha. Também em algum lugar na memória (estática) do programa há uma tabela (tabela virtual), onde para cada tipo há uma lista com suas implementações de método.
No Objective-C, o campo de tipo é conhecido como o campo isa. Está presente em todos os objetos Objective-C (NSObject).
O método de classe é armazenado na tabela virtual e não tem idéia de si mesmo. Para usar o self dentro desse método, ele precisa ser passado para ele (self).
Assim, o compilador alterará esse código para:
class Point: Drawable { ... override func draw(_ self: Point) { ... } } class Line: Drawable { ... override func draw(_ self: Line) { ... } } var drawables: [Drawable] for d in drawables { vtable[d.type].draw(d) }
No momento da execução do código, você precisa olhar para a tabela virtual, encontrar a classe d lá, pegar o método draw da lista resultante e passá-lo como um objeto do tipo d. É um trabalho decente para uma invocação simples de método, mas é necessário garantir que o polimorfismo funcione. Mecanismos semelhantes são usados em qualquer linguagem OOP.
Envio de método - Resumo
- métodos de classe são processados por padrão através do Dynamic Dispatch. Mas nem todos os métodos de classe precisam ser manipulados por meio do Dynamic Dispatch. Se o método não for substituído, você poderá encabeçá-lo com a palavra-chave final, e o compilador saberá que esse método não pode ser substituído e o processará através do Static Dispatch
- métodos que não são de classe não podem ser substituídos (uma vez que struct e enum não suportam herança) e são processados através do Static Dispatch
Problemas de POO - Resumo
É necessário prestar atenção a ninharias como:
- Ao criar uma instância: onde ela estará localizada?
- Ao trabalhar com esta instância: como a contagem de links funcionará?
- Ao chamar um método: como ele será processado?
Se pagarmos pelo dinamismo sem percebê-lo e sem a necessidade dele, isso afetará negativamente o programa que está sendo implementado.
Polimorfismo é uma coisa muito importante e útil. No momento, tudo o que se sabe é que o polimorfismo no Swift está diretamente relacionado às classes e tipos de referência. Por sua vez, dizemos que as aulas são lentas e pesadas, e a estrutura é simples e fácil. O polimorfismo realizado através de estruturas é possível? A programação orientada a protocolo pode fornecer uma resposta para essa pergunta.